黑马2021最新版 SpringCloud基础篇全技术栈导学(RabbitMQ+Docker+Redis+搜索+分布式)
前言
基础篇全部代码和资料已上传到gitee,大家需要可自取: https://gitee.com/da-ji/full_stack_developer
点个Star,后续更新高级篇和面试篇不迷路 _
本笔记基于:
1、 尚硅谷 2020.3 SpringCloud(H版&alibaba)框架开发教程
2、 黑马 2021.8 SpringCloud*+RabbitMQ+Docker+Redis+搜索+分布式
代码和资料基于:
黑马 2021.8 SpringCloud*+RabbitMQ+Docker+Redis+搜索+分布式
第一套教程是经典的尚硅谷阳哥的教程,好处是经过时间的沉淀,已经非常成熟,网上大神的笔记也多,只要是人类出现的问题网上一搜都有答案;非常适合自学。
第二套教程是黑马程序员的2021年8月份最新版教程,截止到发稿时应该是全网最最新的教程,在计算机技术日新月异的今天,尽可能往前学最新的技术至少没错。而且该套教程有一个特点在于,将课程分为实用篇和高级篇:
- 实用篇基本上以微课堂的形式出现,平均视频时长也就10分钟左右,易于接受,涵盖了80%开箱上手就能用的知识;
- 而高级篇就比较深入和复杂了,为应对企业的复杂工作设计,每个视频长度都为一小时左右,同时也是面试常问的地方。
由于本人已经工作了,为了在工作中快速拿起来就能用,我选择的学习路线是:先刷黑马程序员的实用篇,以最少的时间快速掌握SpringCloud的相关知识,然后视情况而定深入学尚硅谷的教程或是黑马程序员的高级篇。
最后,这两篇教程虽然都非常好,但是都没有推出面试篇(源码深入讲解),如果大家经济上允许,可以支持一波培训机构内部课程;经济不允许也可以自学,当然我也会在博客和Gitee中陆续更新一些更高深的技术。
为方便大家速查,后文中这种颜色的字体,代表知识点在对应模块代码中的位置
为方便大家速查,后文中这种颜色的字体,代表知识点在对应模块代码中的位置
为方便大家速查,后文中这种颜色的字体,代表知识点在对应模块代码中的位置
课程资料链接:https://pan.baidu.com/s/169SFtYEvel44hRJhmFTRTQ 提取码:1234
课程资料链接:https://pan.baidu.com/s/169SFtYEvel44hRJhmFTRTQ 提取码:1234
课程资料链接:https://pan.baidu.com/s/169SFtYEvel44hRJhmFTRTQ 提取码:1234
目录
- 前言
- 一、微服务技术栈导学
- 二、Dubbo&Zookeeper
- 三、微服务远程调用Demo——RestTemplate基本使用
- 四、Eureka注册中心
- 五、Ribbon负载均衡
- 六、Nacos注册中心
-
- 6.1 安装启动
- 6.2 Nacos自定义负载均衡策略
- 6.3 Nacos实现配置热更新
- 6.4 Nacos集群
- 七、Feign远程调用
-
- 7.1 还原事故现场
- 7.2 Feign自定义配置
- 7.3 Feign性能优化
- 7.4 Feign最佳实践
- 八、统一Gateway网关
-
- 8.1 概述
- 8.2 搭建网关服务
- 8.3 路由过滤
-
- 8.3.1 断言工厂:对请求进行过滤
- 8.3.2 过滤器GatewayFilter:对请求和响应进行过滤
- 8.3.3 全局过滤器GlobalFilter:可以自定义过滤逻辑代码实现
- 8.3.4 过滤器链执行顺序
- 8.4 网关跨域问题处理
- 九、Docker
-
- 9.1 Docker概念
- 9.2 Docker常用命令
- 十、MQ(Message Queue)消息队列
-
- 10.1 概述
- 10.2 RabbitMQ安装
- 10.3 常见消息模型
-
- 10.3.1 简单队列模型
- 10.4 Spring AMQP
-
- 10.3.2 WorkQueue模型
- 10.3.3 发布-订阅模型
-
- A. Fanout Exchange
- B. Direct Exchange
- C. Topic Exchange
- 10.3.4 消息转换器
- 十一、ElasticSearch分布式搜索
-
- 11.1 ES基础概念
- 11.2 安装部署ES
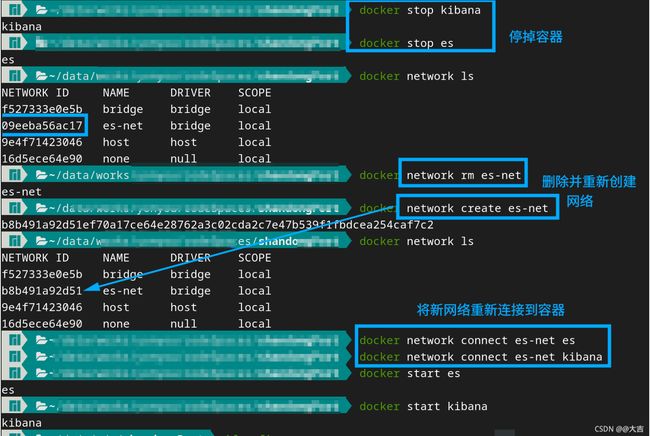
- [Debug] 停止ES容器(或是重启Linux)后,如何恢复Docker网络:
- 11.3 索引库操作
- 11.4 文档操作
- 11.5 RestClient操作索引库和文档
- 11.6 DSL查询语法
- 11.7 Java RestClient查询语法
- 11.8 ES综合案例:黑马旅游
- 11.9 ES数据聚合
- 11.10 ES数据补全
- 11.11 ES与MySQL之间数据同步(面试常问)
- 11.12 搭建高可用ES集群
- 后记
一、微服务技术栈导学
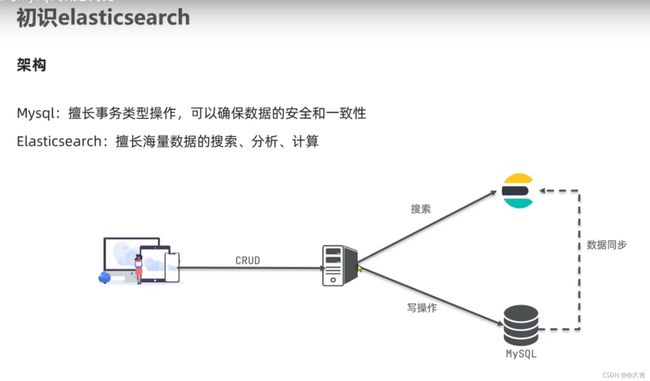
从单体架构过度到微服务架构,需要一系列中间技术支撑,其中重要的部分包括:
- 注册中心:Eureka 、Zookeeper、Nacos
- 服务网关:Zuul 、Gateway
- 微服务远程调用:RestTemplate、Feign
- 容器化技术 Docker
- 消息队列 MQ(多种实现方式)
- 负载均衡 Ribbon 、 Nginx
- 分布式搜索技术:ElasticSearch
尚硅谷阳哥的SpringCloud版本选型:

黑马程序员的SpringCloud版本选型:

可以看到,黑马的版本明显较新,本文采用黑马程序员的版本(Hoxton.SR10 + SpringBoot 2.3.x)
二、Dubbo&Zookeeper
核心代码位置:在模块 dubbo+zookeeper 下
这部分是跟狂神说Java学习的(黑马版直接跳过了这两个技术),Zookeeper与Eureka 、Nacos一样也是一种注册中心。
三、微服务远程调用Demo——RestTemplate基本使用
核心代码位置:在模块 01-cloud-demo 下的order-service 和 user-service
核心代码如下图:实现了跨服务远程调用
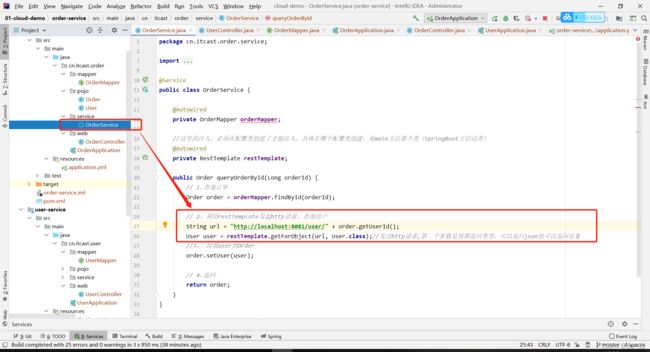
总结:RestTemplate微服务调用方式
基于RestTemplate发起的http请求实现远程调用
http请求做远程调用是与语言无关的调用,只要知道对方
的ip、端口、接口路径、请求参数即可。
四、Eureka注册中心
核心代码位置:在模块 01-cloud-demo 下的eureka-server(注册的是order-service 和 user-service)
Eureka的作用:
- 消费者该如何获取服务提供者具体信息
- 服务提供者启动时向eureka注册自己的信息
- eureka保存这些信息
- 消费者根据服务名称向eureka拉取提供者信息
- 如果有多个服务提供者,消费者该如何选择
- 服务消费者利用负载均衡算法,从服务列表中挑选一个
- 消费者如何感知服务提供者健康状态
- 服务提供者会每隔30秒向EurekaServer发送心跳请求,报告健康状态
- eureka会更新记录服务列表信息,心跳不正常会被剔除
- 消费者就可以拉取到最新的信息
注意点:
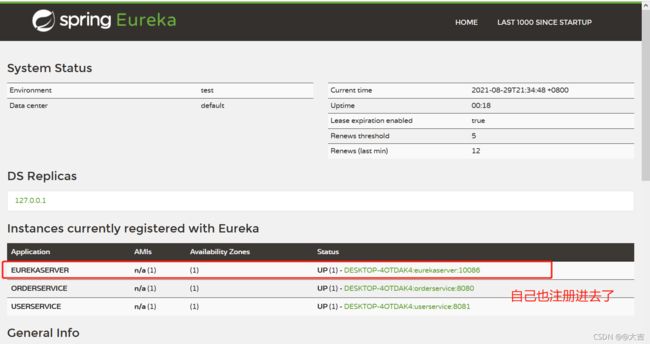
Eureka自己也是一个微服务,Eureka启动时,要把自己也注册进去。这是因为如果后续搭建Eureka集群时做数据交流:
server:
port: 10086 # 服务端口
spring:
application:
name: eurekaserver # eureka的服务名称
eureka:
client:
service-url: # eureka的地址信息
defaultZone: http://127.0.0.1:10086/eureka
上段代码块中,defaultZone,将自己也注册进去了。效果如下图:
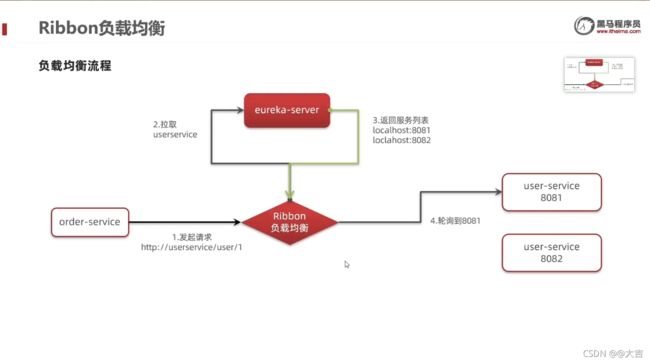
五、Ribbon负载均衡
两个疑问:
- 如果有多个服务提供者,服务调用者如何知道究竟调用哪个服务呢?
- 而且服务调用者为何不用写死服务提供者的链接(ip和端口),只需要写服务名称即可?为什么我们只输入了服务名称就可以访问了呢?
(String url = "http://userservice/user/" + order.getUserId(); //由于已经在Eureka里面配置了服务,这里只需要写配置的服务名即可)
这都是Ribbon的负载均衡做到的,针对问题一,通过跟断点得知,Ribbon是通过几种不同的负载均衡算法实现的这一个机制(比如轮询算法);针对问题二,Ribbon会根据服务名称去Eureka注册中心拉取服务,如下两个图所示:
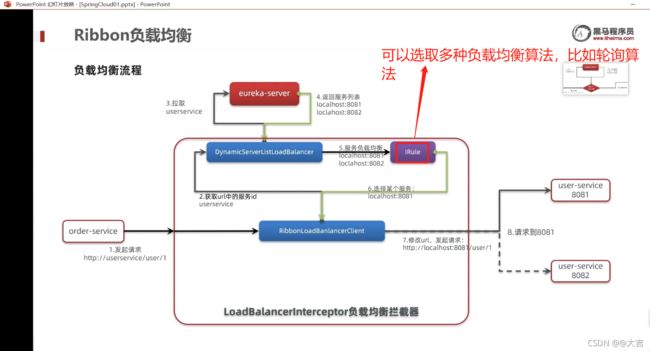
Ribbon 负载均衡策略
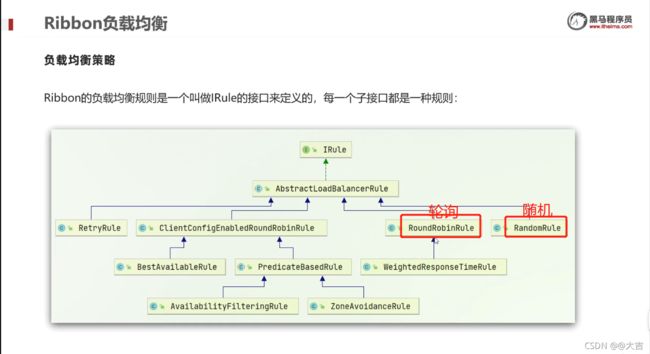
RoundRobin —— 意为轮询,操作系统也有类似的概念(CPU时间片轮转)

可以使用如下代码配置对某个服务的负载均衡策略(在 application.yml里配置)
userservice: # 给某个微服务配置负载均衡规则,这里是userservice服务为例
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule # 负载均衡规则
Ribbon开启饥饿加载
Ribbon默认是采用懒加载,即第一次访问时才会去创建LoadBalanceClient,请求时间会很长。
而饥饿加载则会在项目启动时创建,降低第一次访问的耗时,通过下面配置开启饥饿加载:
ribbon:
eager-load:
enabled: true # 开启饥饿加载
clients:
- userservice # 指定饥饿加载的服务名称
- xxxxservice # 如果需要指定多个,需要这么写
六、Nacos注册中心
和前面的Eureka、Zookeeper是同类型技术
6.1 安装启动
下载地址:https://github.com/alibaba/nacos/releases
本文选用1.4.1版本
解压完成后,cd到nacos的bin目录下,然后输入命令:
startup.cmd -m standalone
关闭的话,如果是linux系统,就运行shutdown.sh即可
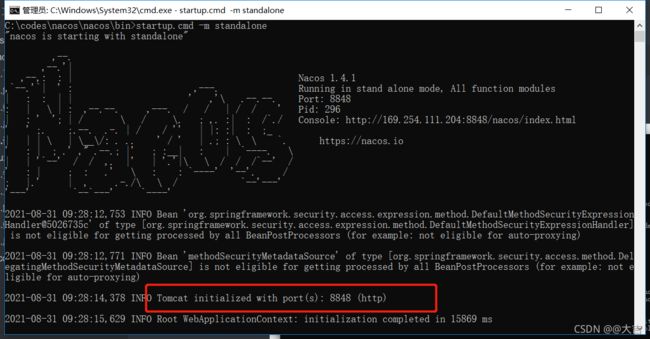
出现如上图所示界面,说明启动成功。通过上图也可知它的默认端口是8848(国人做的注册中心果然不一样 8848氪金手机~)
输入地址http://127.0.0.1:8848/nacos 即可访问主页,用户名和密码都是nacos
 核心代码位置:在模块 01-cloud-demo 下注册了order-service 和 user-service,同时注释掉了两个模块的Eureka代码(包括pom.xml也注释了,毕竟是同类技术)
核心代码位置:在模块 01-cloud-demo 下注册了order-service 和 user-service,同时注释掉了两个模块的Eureka代码(包括pom.xml也注释了,毕竟是同类技术)
注意,必须将之前的Eureka代码和pom都注释掉,而且把SpringCloud也注释掉(因为已经用了SpringCloudAlibaba),否则有可能报:APPLICATION FAILED TO START这个错误
对比之前的Eureka,我们是在idea里面专门启动了一个Eureka的工程,所以 Eureka不需要下载,就可以通过端口号访问Eureka的注册中心。而Nacos是 下载并运行的,所以不需要在idea启动某个模块,直接通过运行Nacos的startup.cmd即可通过端口号访问Nacos的注册中心。
6.2 Nacos自定义负载均衡策略
也是使用的Ribbon,下面一个例子将Nacos配置成同集群优先的负载均衡策略:
默认的ZoneAvoidanceRule并不能实现根据同集群优先来实现负载均衡。
Nacos中提供了一个NacosRule的实现,可以优先从同集群中挑选实例。
1)给order-service配置集群信息
修改order-service的application.yml文件,添加集群配置:
spring:
cloud:
nacos:
server-addr: localhost:8848
discovery:
cluster-name: HZ # 集群名称
2)修改负载均衡规则
修改order-service的application.yml文件,修改负载均衡规则:
userservice:
ribbon:
NFLoadBalancerRuleClassName: com.alibaba.cloud.nacos.ribbon.NacosRule # 负载均衡规则
配置完成之后,就可以实现同集群优先的 负载均衡了
6.3 Nacos实现配置热更新
有两种方式,都在代码中配置了,具体位置在:
核心代码位置:在模块 01-cloud-demo 下 user-service,第一种方式是通过配置文件方式(PatternProperties.java);第二种方式是通过注解@Value(“${yaml里定义的键值对}”)的方式
-
热更新注意点:
你在Nacos中配置的:
 你在bootstrap.yaml里配置的:
你在bootstrap.yaml里配置的:
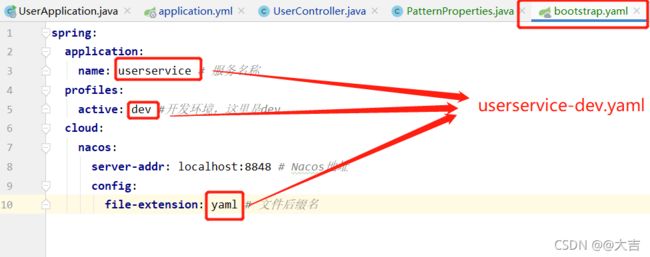 这两张图应该是一致的,注意
这两张图应该是一致的,注意 -和.的区别!!! -
热更新优先级
Nacos带环境的配置 > Nacos不带环境的配置 > 本地yaml文件配置很好理解,Nacos带环境可以理解为专属化配置(开发环境和生产环境)、肯定优先于Nacos不带环境的全局配置;本地yaml文件配置则肯定低于Nacos的配置。
6.4 Nacos集群
位置:在模块 01-cloud-demo 下根目录,有一个叫Nacos集群搭建.md的文件
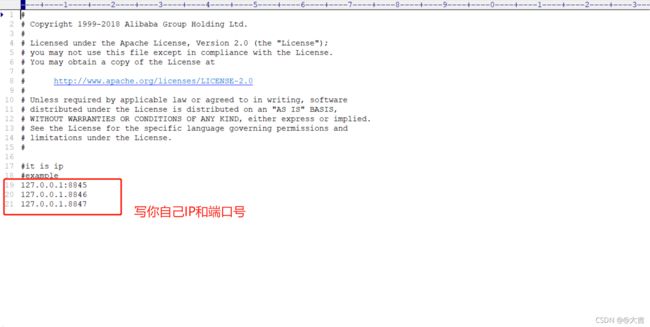
注意点:修改两个配置文件:
- 修改cluster.conf
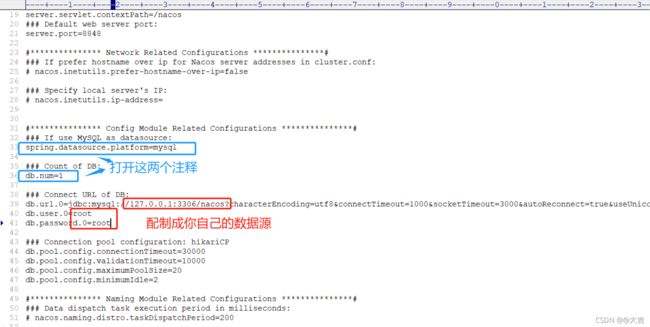
- 修改Nacos的application.properties(不是你的application.properties)
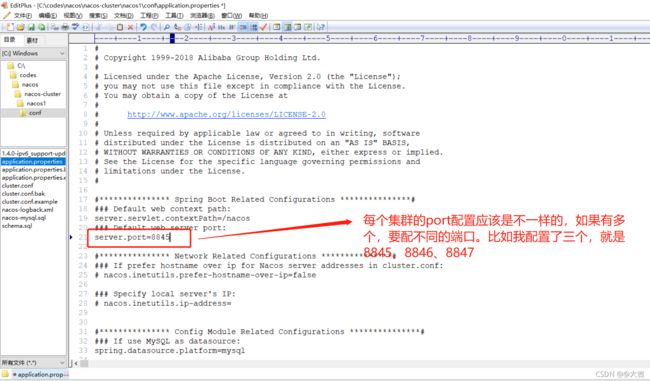
修改完成后保存即可。
- 使用Nginx对Nacos做反向代理
这里需要Nginx前置知识,可以看我以下这一篇文章:Nginx入门:通俗理解反向代理和负载均衡,简单配置Nginx
如果你的Nacos配置集群死活报下图的错误:
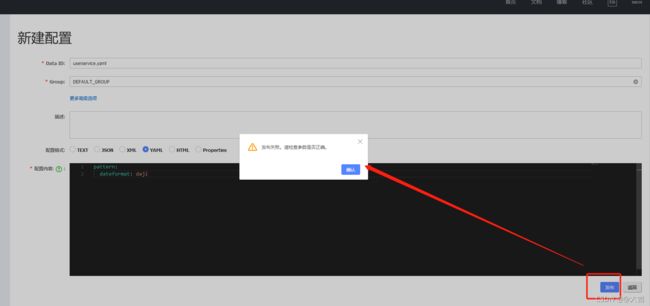
请检查你的MySQL版本,需要在5.7及以上,而且在8.0以下(比较苛刻)
七、Feign远程调用
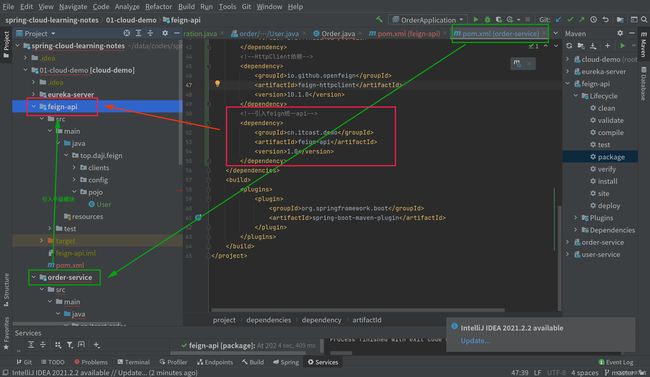
核心代码位置:如下图所示:
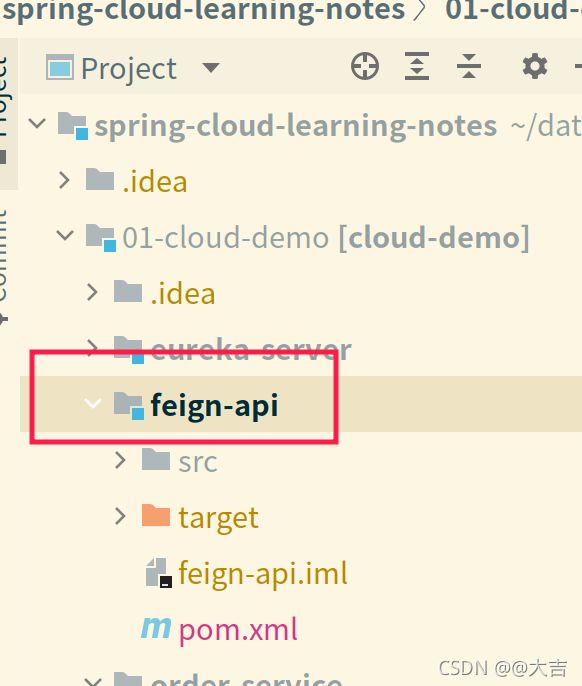
order-service会引入上图的feign-api,实现远程调用
7.1 还原事故现场
由于上一章(第六章)做了Nacos集群,但是整个第七章是基于单体的注册中心。所以要把集群恢复成单体。
- nacos不使用集群启动,恢复你standalone环境,主要是修改配置文件的nacos端口
- 这样做的目的是让微服务注册进注册中心。你用nacos还原事故现场也行,用eureka还原事故现场也行。反正能还原即可。
- 打开你的数据库服务
引入feign版本报错bug问题解决:
我手工指定了一个版本,版本号是:
org.springframework.cloud
spring-cloud-starter-openfeign
2.2.9.RELEASE
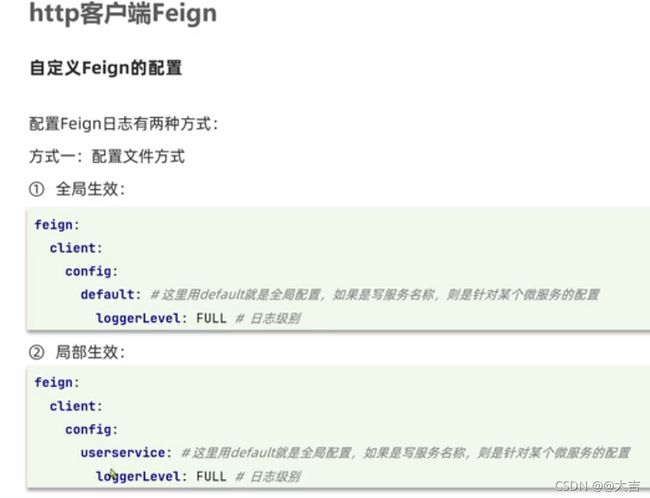
7.2 Feign自定义配置
分为配置文件方式和代码方式。
- 配置文件方式:
- 代码方式(新建一个配置类):
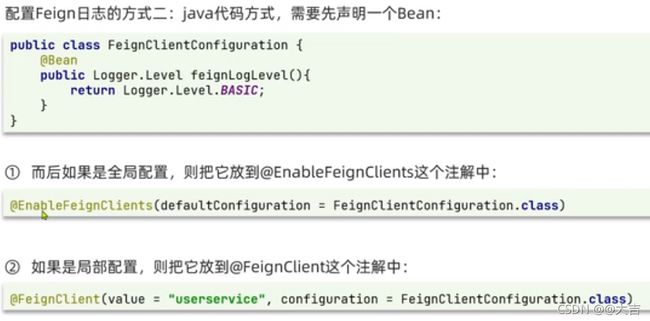
我们采用的是代码方式,并全局生效(新建一个配置类)
7.3 Feign性能优化
底层的客户端实现是:
- URLConnection:默认实现,不支持连接池
- Apache HttpClient: 支持连接池(常用)
- OKHttp:支持连接池
第一种方式是默认的,不支持连接池。所以这里的性能优化指的是:换成第二种方式或者第三种方式。
其中第二种方式 Apache HttpClient 常用于模拟postman的样式,发送一个form-data样式的post请求,也可在这个post请求里上传文件。我们也采用的是这种方式
性能优化步骤:
1、引入jar包:
io.github.openfeign
feign-httpclient
10.1.0
2、在配置文件yml中配置:
feign:
httpclient:
enabled: true # 支持HttpClient的开关
max-connections: 200 # 最大连接数
max-connections-per-route: 50 # 单个路径的最大连接数
这里的改动都是在order-service模块下
7.4 Feign最佳实践
打成jar包方式:
java中的JAR包
1、在项目中添加单独的jar包步骤:
写好自己的maven项目后,执行clean package,即可得到一个jar包
2、在项目中引入单独的jar包图解:
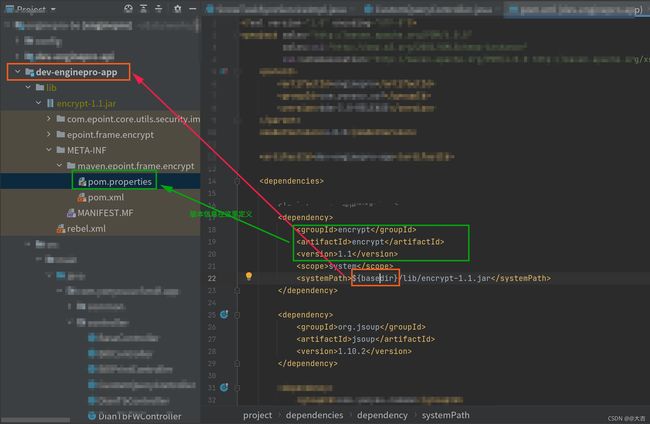
上图其实是在项目的根目录创建了一个叫lib的文件夹,里面存着自定义jar包。然后即可引入。
3、针对1和2的补充,有的时候没必要非得打jar包,可以写一个子模块引入呀,如下图所示:
这块看不懂,可以自行搜索maven的jar包引入方式和顺序
八、统一Gateway网关
8.1 概述
三大功能:
- 身份认证和权限校验
- 服务路由、负载均衡
- 请求限流
在SpringCloud中网关技术包括两种:gateway和zuul
其中Zuul是基于Servlet的实现,属于阻塞式编程,而Gateway则是基于SPring5中提供的WebFlux,属于响应式编程的实现,具备更好的性能。
8.2 搭建网关服务
核心代码位置:如下图
步骤:
-
新建模块
-
编写配置文件yml:
- 注册进nacos的配置
- 网关自身的端口号
- 网关路由配置
server:
port: 10010
spring:
application:
name: gateway
cloud:
nacos:
server-addr: 127.0.0.1:8848 # nacos地址
gateway:
routes:
- id: user-service # 路由标识,必须唯一
uri: lb://userservice # 路由的目标地址 lb就是负载均衡,后面跟着是服务名称
predicates: # 路由断言,判断请求是否符合规则
- Path=/user/** # 路径断言,判断路径是否是以/user开头,如果是则符合规则
- id: order-service
uri: lb://orderservice
predicates:
- Path=/order/**
除了上面这些,还可以配置路由过滤器。后面会讲到。
配置完毕后,启动你的网关服务和你的user-service和order-service服务,即可通过网关访问到user-service和order-service
工作原理总结
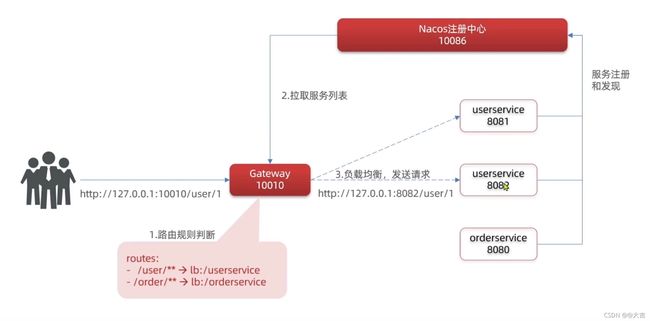
8.3 路由过滤
8.3.1 断言工厂:对请求进行过滤

如果你不会写匹配表达式,可以去spring官网查:
如果你的请求不符合路由断言,那你的请求就会被拒绝,返回一个404. 我们可以通过配置路由断言工厂的方式来过滤某些请求。
8.3.2 过滤器GatewayFilter:对请求和响应进行过滤
它和8.3.1讲述的断言工厂一样,都配置在yaml里
- GatewayFilter 和 8.3.1讲述的断言工厂的区别:
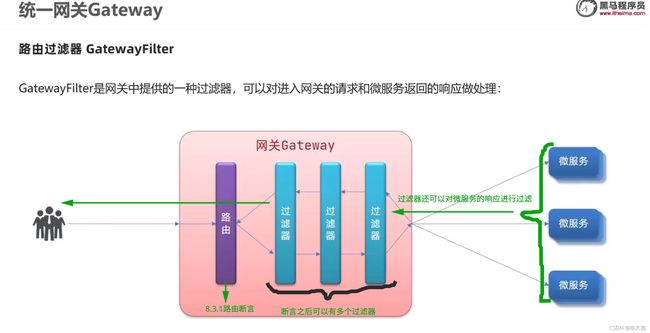
- 与断言工厂类似,spring也为我们提供了过滤器工厂:

GatewayFilter可以针对某一类路由标识单独配置,也可以配置成全局配置(所有路由id都生效),具体可自行百度,但是过滤器链执行顺序有变化,可以看8.8.4详解
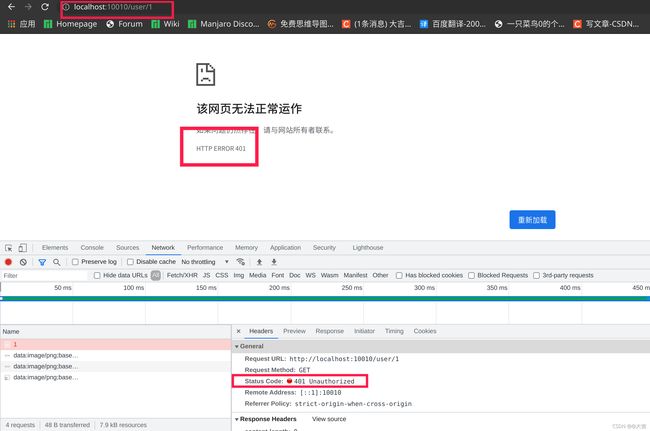
8.3.3 全局过滤器GlobalFilter:可以自定义过滤逻辑代码实现


案例正确执行的效果图:
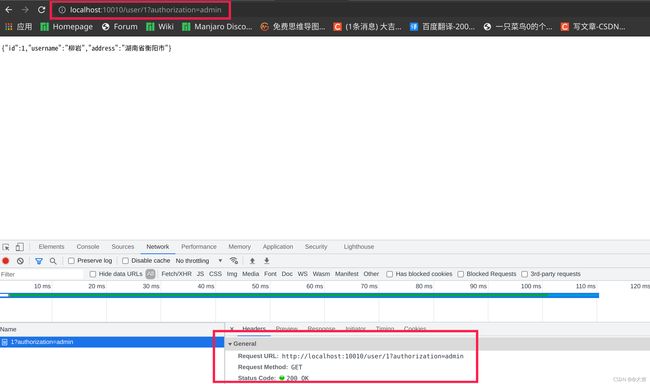
不加参数被过滤器拦截:
加了参数,不被拦截,正确获得响应!
8.3.4 过滤器链执行顺序
原理:关键词 适配器模式
顺序:

8.4 网关跨域问题处理
域名不一致就是跨域:
- 域名不同 比如www.baidu.com 和 www.bilibili.com
- 域名相同,端口不同
跨域是一个前端的概念,浏览器禁止请求的发起者和服务端发生跨域ajax请求,该请求会被浏览器拦截。
解决方案:CORS
之所以之前的user-service调用order-service不存在跨域,是因为不是ajax请求。因为这是一个浏览器行为,只有ajax请求会被拦截
处理方法:
简单配置即可:
spring:
cloud:
gateway:
globalcors: # 全局的跨域处理
add-to-simple-url-handler-mapping: true # 解决options请求被拦截问题
corsConfigurations:
'[/**]':
allowedOrigins: # 允许哪些网站的跨域请求
- "http://localhost:8090"
- "http://www.leyou.com"
allowedMethods: # 允许的跨域ajax的请求方式
- "GET"
- "POST"
- "DELETE"
- "PUT"
- "OPTIONS"
allowedHeaders: "*" # 允许在请求中携带的头信息
allowCredentials: true # 是否允许携带cookie
maxAge: 360000 # 这次跨域检测的有效期
如果想要演示,需要启动一个前端工程模拟一个ajax请求。
九、Docker
Docker命令居多,可以看我下面两张思维导图,包含了概念理解和常用命令。
9.1 Docker概念
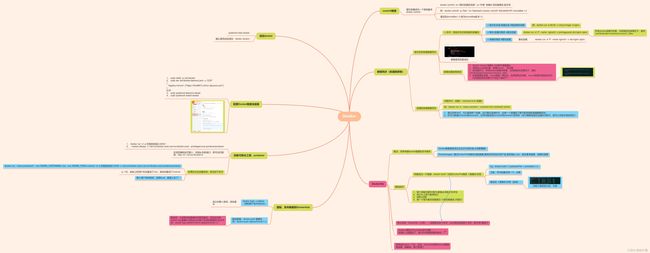
9.2 Docker常用命令
十、MQ(Message Queue)消息队列
10.1 概述
-
事件驱动架构的概念:
MQ是事件驱动架构的实现形式,MQ其实就是事件驱动架构的Broker。 -
异步应用场景:
如果是传统软件行业:虽然不需要太高并发,但是涉及到和其它系统做对接,我方系统处理速度(50ms)远快于对方系统处理速度(1-3s),为了兼顾用户的体验,加快单据处理速度,故引入MQ。
用户只用点击我方系统的按钮,我方按钮发送到MQ即可给用户返回处理成功信息。背后交由对方系统做处理即可。至于处理失败,补偿机制就不是用户体验要考虑的事情了,这样可以大大提升用户体验。 -
异步通讯优缺点:
- 优点:
- 耦合度低
- 吞吐量提升
- 故障隔离
- 流量削峰
- 缺点:
- 依赖于MQ的可靠性,安全性,吞吐能力(因为加了一层MQ,当然高度依赖它)
- 业务复杂了,业务没有明显的流程线,不好追踪管理
- 优点:
-
MQ常见技术介绍:
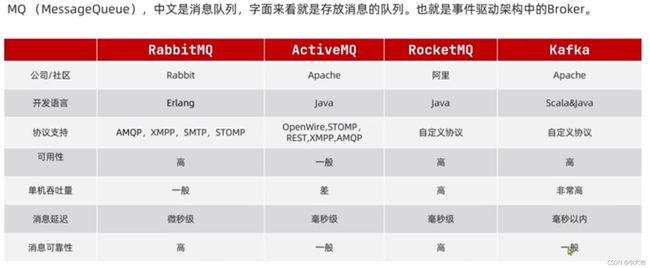
10.2 RabbitMQ安装
如何安装,见下图文件:RabbitMQ部署指南.md
执行MQ容器的命令和简单说明:
docker run
-e RABBITMQ_DEFAULT_USER=root #用户名
-e RABBITMQ_DEFAULT_PASS=root # 密码
--name mq
--hostname mq1 # 主机名,将来做集群部署要用
-p 15672:15672 # 端口映射,映射RabbitMQ管理平台端口
-p 5672:5672 # 端口映射,消息通信端口
-d # 后台运行
rabbitmq:3-management # 镜像名称
#号不被识别,下面提供一个没有#的版本
docker run
-e RABBITMQ_DEFAULT_USER=root
-e RABBITMQ_DEFAULT_PASS=root
--name mq
--hostname mq1
-p 15672:15672
-p 5672:5672
-d
rabbitmq:3-management
最后在浏览器地址栏输入:你的端口号:15672
如果看到上图页面,就说明成功了!
虚拟主机,租户隔离的概念,重要!!!
vitural host:虚拟主机,是对queue、exchange等资源的逻辑分组
10.3 常见消息模型
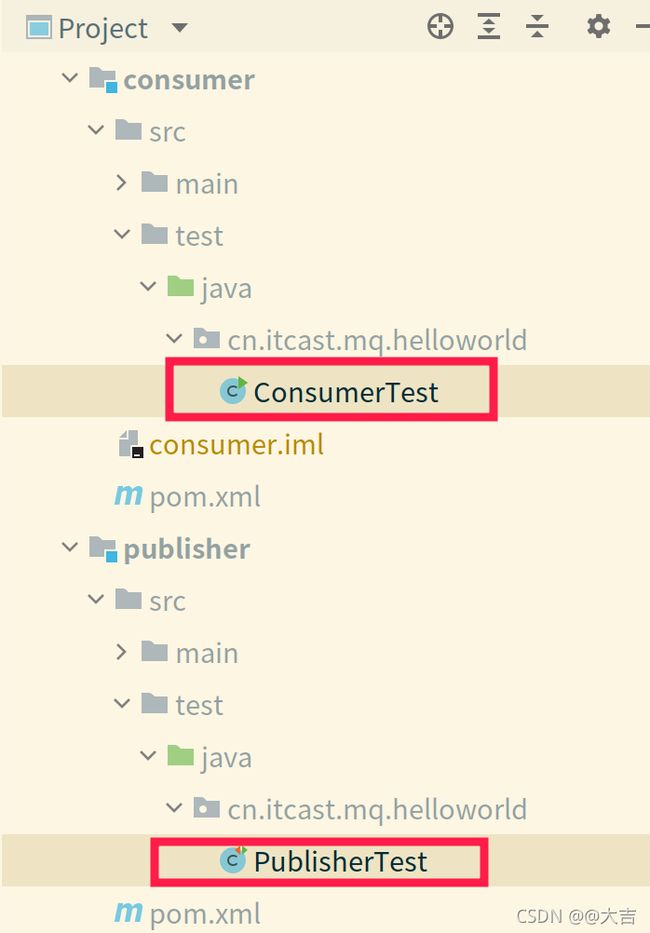
10.3.1 简单队列模型
核心代码位置:下图所示
10.4 Spring AMQP
概述
AMQP(Advanced Message Queuing Protocol),是用于在应用程序之间传递业务信息的开放标准,该协议与语言和平台无关,更符合微服务中独立性的要求
SpringAMQP就是Spring基于AMQP定义的一套API规范。
使用Spring AMQP实现简单队列模型步骤:
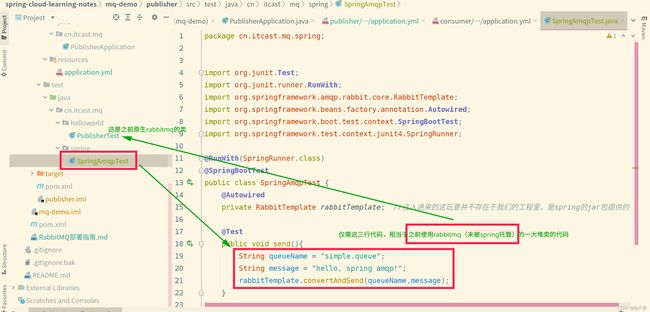
以生产者为例:
由于这玩意已被spring托管了,所以对比之前rabbitmq demo的方式,不需要在代码里写配置了,直接在spring的application.yml里写配置文件即可.
配置如下:
# 1.1.设置连接参数,分别是:主机名、端口号、用户名、密码、vhost
spring:
rabbitmq:
host: 127.0.0.1
port: 5672
username: root
password: root
virtual-host: /
然后编写测试类,以及测试代码,位置如下图所示:
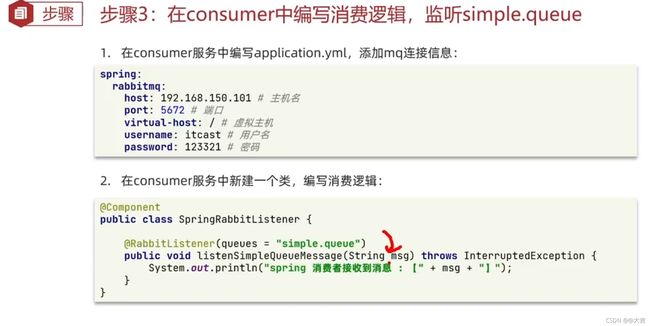
消费者一侧,和生产者类似。不再赘述,如下图进行配置即可:
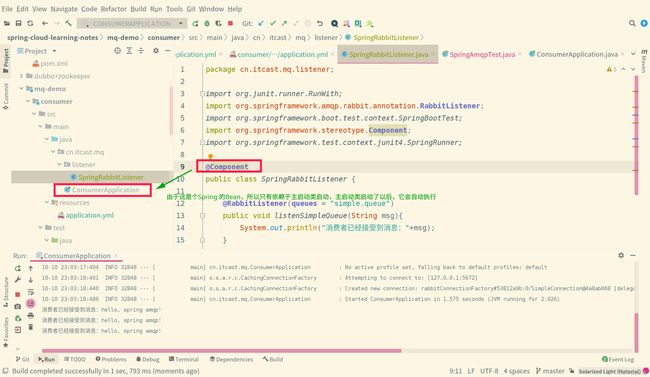
至于如何启动消费者 一侧?如下图所示:
10.3.2 WorkQueue模型
之所以 10.3.2 放在 10.4章,因为demo模型的演示,今后就是以 Spring AMQP为例了
概述
其实就是一个队列,绑定了多个消费者,一条消息只能由一个消费者进行消费,默认情况下,每个消费者是轮询消费的。区别于下文的发布-订阅模型(该模型允许将同一消息发给多消费者)
案例:

10.3.3 发布-订阅模型
概念
允许将同一个消息发给多个消费者。
其实就是加了一层交换机而已,如下图所示:
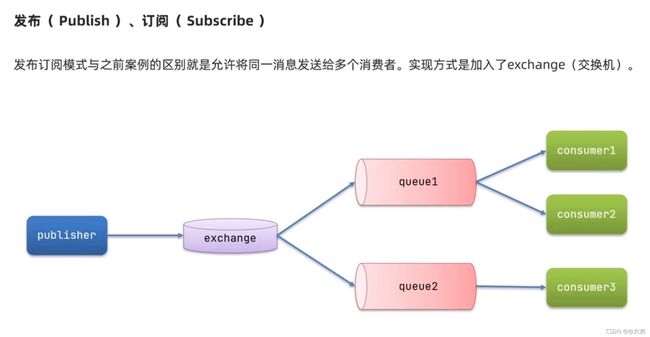
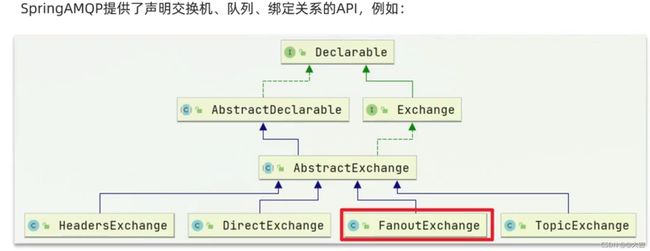
交换机类型有很多,下文逐一介绍。下图表示了各交换机类型的继承关系
最后,交换机只能做消息的转发而不是存储,如果将来路由(交换机和消息队列queue的连接称作路由)没有成功,消息会丢失
A. Fanout Exchange
位置如下图,注意一定要放在consumer包下,因为是消费者消费行为:

生产者添加代码位置如下图:
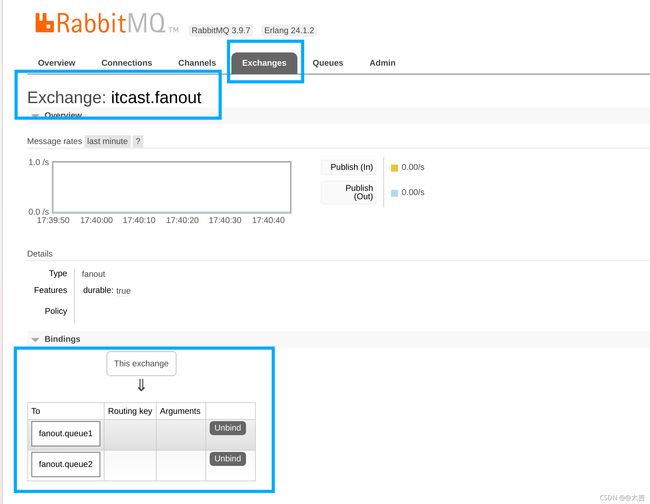
队列绑定成功后,打开mq可视化页面,会看到如下图所示:
写好代码后,分别启动生产方,消费方,即可看到调试成功信息输出:

概念:
这种模型中生产者发送的消息所有消费者都可以消费。
案例:
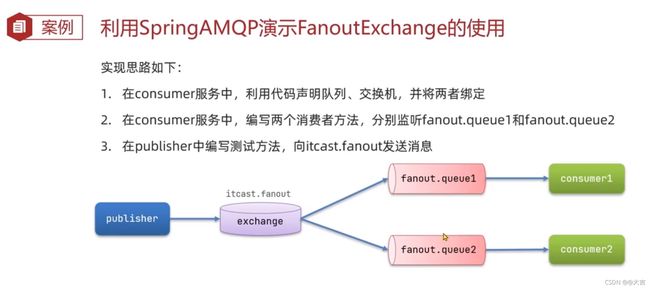
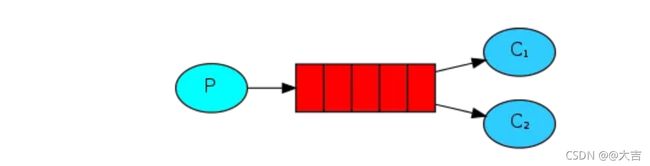
总结:workQueue模式和FanoutQueue模式区别:
P代表生产者,C代表消费者 X代表交换机,红色部分代表消息队列
workQueue:
FanoutQUeue:
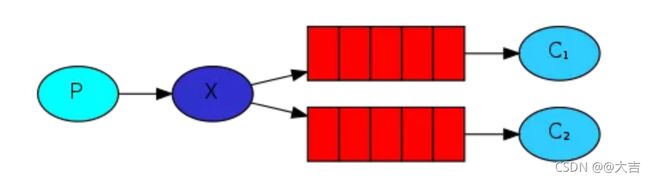
可以发现,FanoutQueue增加了一层交换机,可以多个队列对应多个消费者。而且比起WorkQueue,FanoutQueue生产者是先发送到交换机; 而WorkQueue是直接发送到队列
B. Direct Exchange
概念:DirectExchange 会将接收到的消息根据规则路由到指定的queue,因此称为路由模式,如下图所示:
P代表生产者,C代表消费者 X代表交换机,红色部分代表消息队列
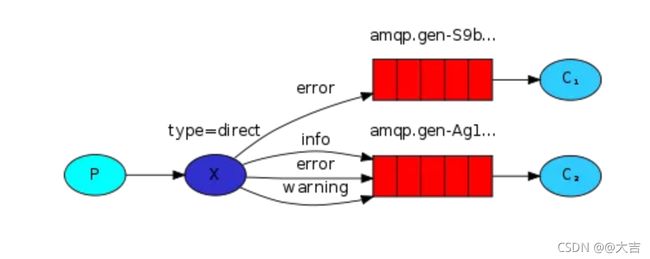
- 每一个queue都会与Exchange设置一个BindingKey
- 将来发布者发布消息时,会指定消息的RoutingKey
- Exchange将消息路由到BingingKey与RoutingKey一致的队列
- 实际应用时,可以绑定多个key。
- 如果所有queue和所有Exchange绑定了一样的key,那生产者所有符合key的消息消费者都会消费。如果这样做,那DirectExchange就相当于FanoutExchange了(Direct可以模拟Fanout的全部功能)
案例如图:
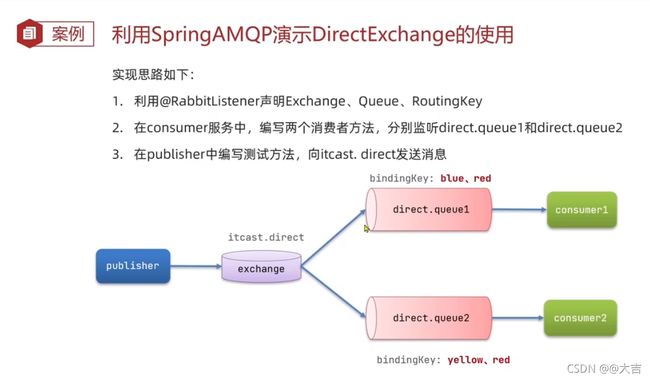
消费者添加代码位置如下图:

发送队列添加代码位置如下图:

这次的案例,我们用注解的方式声明队列和绑定交换机,之前Fanout的Demo是手写了个配置类。 直接在监听队列里面声明如下图注解即可:
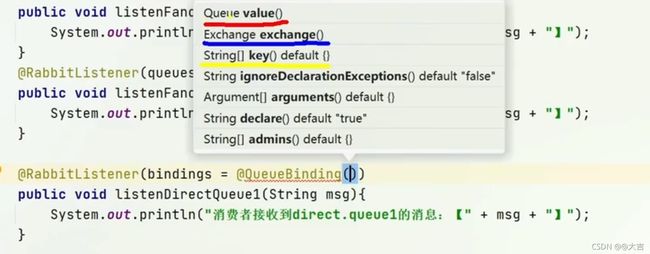
上图的@QueueBinding点进去:
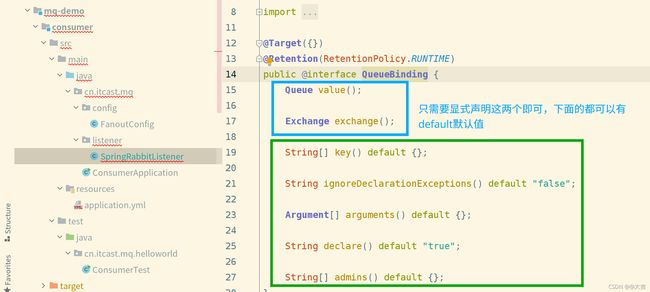
上面的key是个数组,可以写多个key。
写完代码后启动消费者的SpiringBoot主启动类(报错信息不用管),然后进入rabbitMQ可视化控制台,出现下图则说明配置成功:
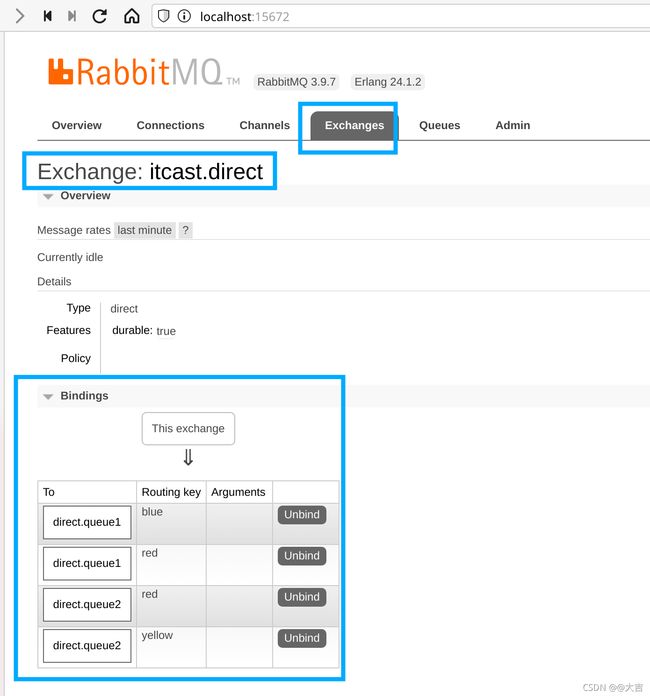
随后运行发送队列的Test代码,打开消费者的控制台,出现如下图输出,则说明案例测试通过:
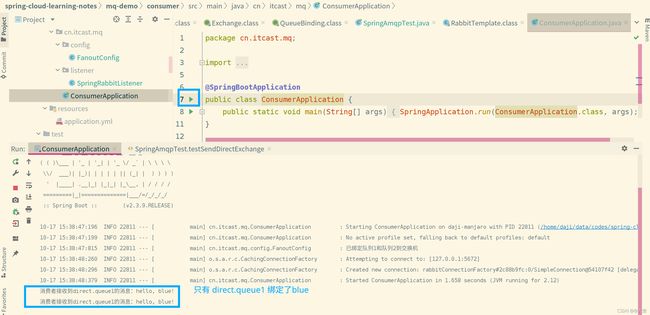
C. Topic Exchange
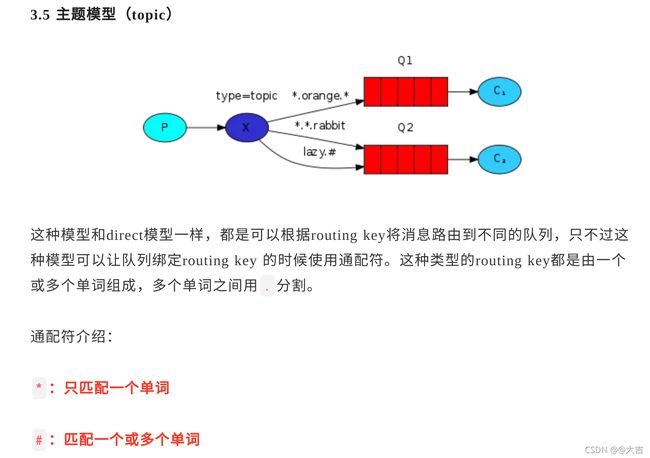
概念: 和上面的Direct Exchange及其相似:
(下图来源于Java旅途 ,作者大尧)
案例:
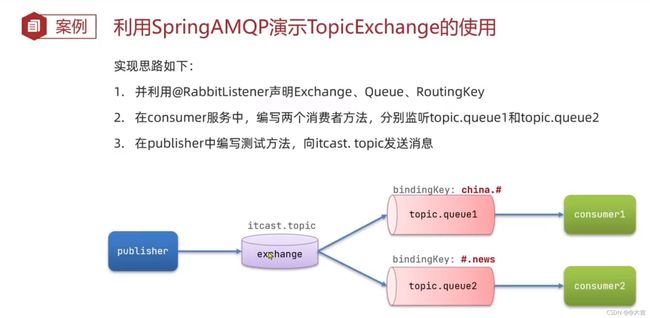
发送队列、消费者的添加代码位置和上面的DirectExchange位置一致,就在DirectExchange代码下面。
写完代码后启动消费者的SpiringBoot主启动类(报错信息不用管),然后进入rabbitMQ可视化控制台,出现下图则说明配置成功:
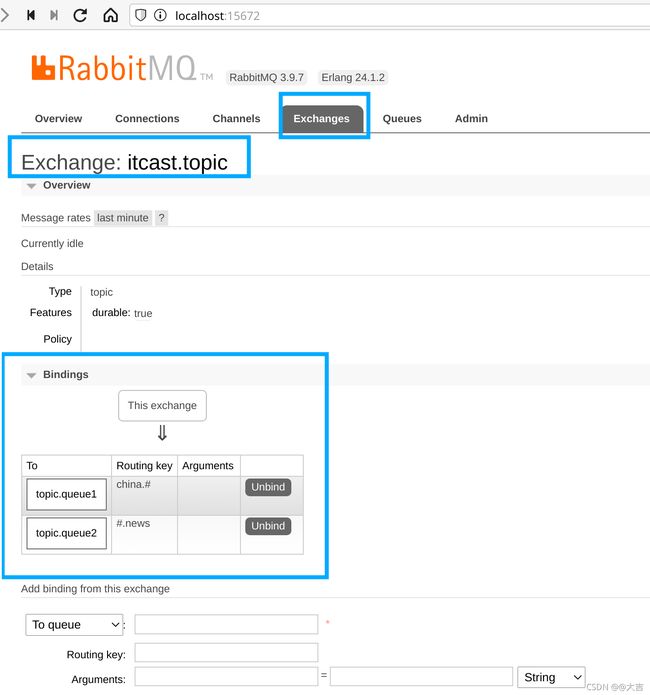
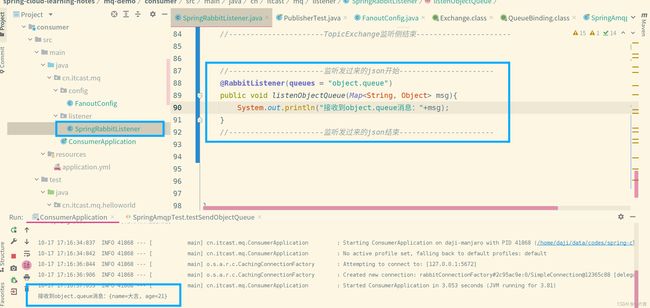
10.3.4 消息转换器
引入:
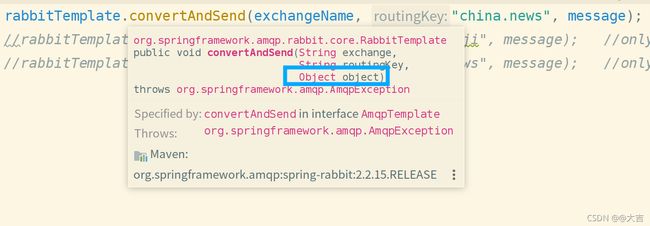
在之前的案例中,我们发送到队列的都是String类型,但是实际上,我们可以往消息队列中扔进去任何类型。我们看下图,convertAndSend这个方法,第三个参数也是Object。这说明可以发送任何类型给消息队列:
案例:
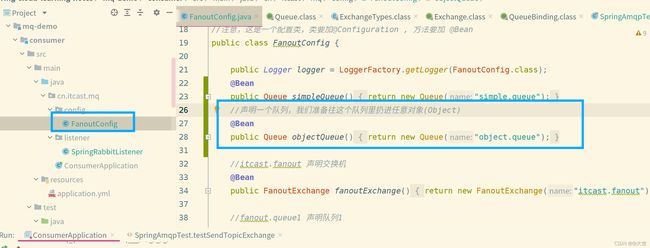
创建一个队列,向该队列扔一个任意对象(Object类型)
创建队列位置、发送队列的添加代码位置如下图
创建队列位置:
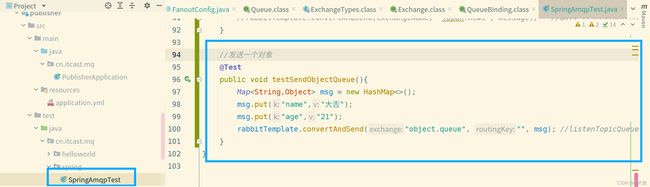
发送:
写完代码后启动发送的Test,去看RabbitMQ控制台,发现我们发过来的对象在内部被序列化(ObjectOutPutStream)了,如下图所示:
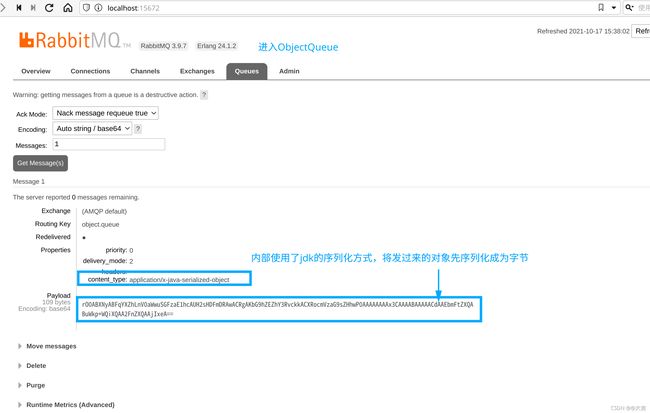
如果不知道什么是ObjectOutPutStream可自行百度:

上面说的ObjectOutPutStream这个序列化方式,缺点很多(性能差、长度太长、安全性有问题)。我们可以在这里调优一下,推荐JSON的序列化方式。于是引出了这一节的正文:自定义消息转换器(覆盖了原有的Bean配置):
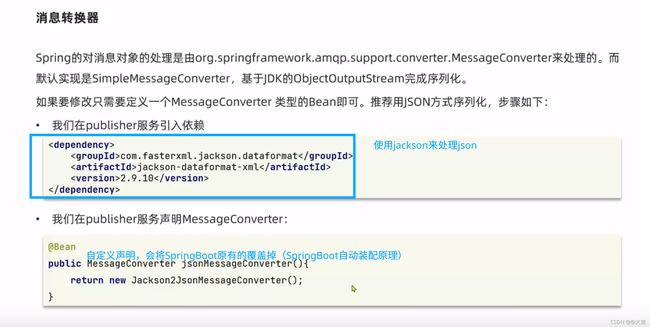
声明配置位置如下图
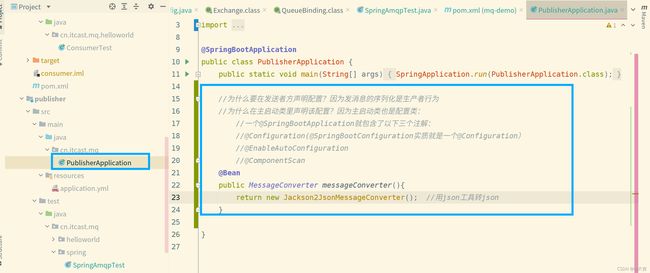
配置了消息转换器转换成json,然后重复之前的步骤,使用发送者发送一条消息到队列,发送完成后打开RabbitMQ控制台,出现如下图所示:
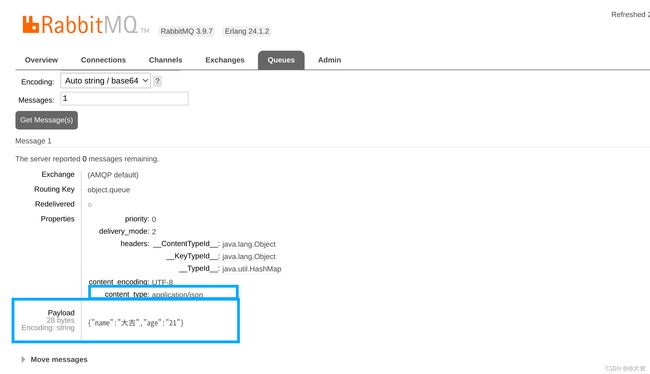
该对象被成功序列为json格式了!!!!!
- 对刚才发送过来的json格式消息进行接收,需要修改消费者一侧的代码。并不复杂,如下图所示:
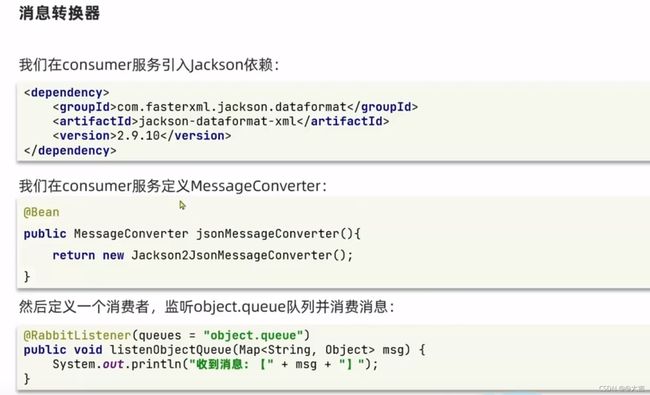
消费者配置、监听消息位置如下2图:
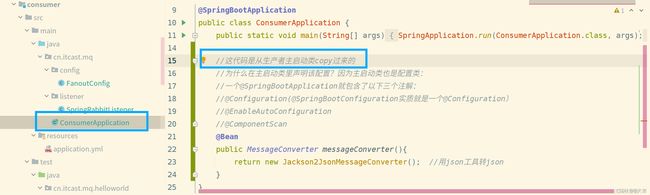
总结
- 消息序列化和反序列化使用MessageConverter实现
- SpringAMQP的消息序列化默认底层是使用JDK的序列化
- 我们可以手动配置成其它的序列化方式(覆盖MessageConverter配置Bean),推荐json
- 发送方和接收方必须使用相同的MessageConverter
十一、ElasticSearch分布式搜索
11.1 ES基础概念
ES概述:
ELK(Elastic Stack)是以Elastic为核心的技术栈,如下图所示:

ElasticSearch底层是Lucene(侧面说明了ES和Hadoop千丝万缕的关系)
推荐下面一篇文章:深入浅出大数据(From Zhihu)https://zhuanlan.zhihu.com/p/54994736
这个Lucene使用java写成的,其实就是个jar包,我们引入之后就可以使用这个Lucene的API。而ES就是基于Lucene的二次开发,对其API进行进一步封装:

倒排索引基础概念:
先了解传统MySQL的正向索引:

倒排索引基本概念:
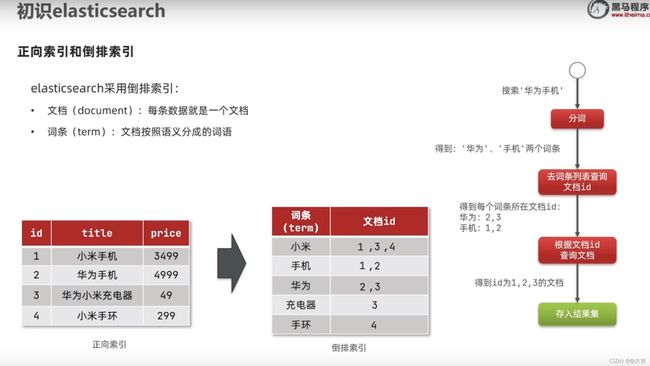
这个倒排索引其实和生活中字典相当像,你拿到一本字典的目录,肯定不会傻到先找页码,你肯定是先大略看一眼目录的关键字,然后找到关键字之后,去看关键字旁边的页码,最后再根据页码翻到书对应的那一页。
倒排索引其实就是上面的例子。
然而MySQL这种正向索引,就是基于文档id创建索引,查询词条的时候必须先找到文档,然后根据文档内容判断是否包含词条。
倒排索引正式一点的说法就是:对文档内容分词,对词条创建索引,并记录词条所在文档的信息,查询时先根据词条查询文档id,然后根据id找到该文档。
文档和词条的概念:
每一条数据就是一个文档,对文档的内容分词,得到的词语就是词条。
ES 和 MySQL 概念对比

11.2 安装部署ES
见课前资料的:安装elasticsearch.md
使用docker容器化部署,这里针对启动容器命令解析一下:
-e “ES_JAVA_OPTS=-Xms512m -Xmx512m” 配置堆内存(JVM)。因为ES底层是java实现的,所以要配置jvm内存大小。默认值是1T,对于轻量级服务器太大了,所以适当减少为512M(但是不能再弄少了,再少的话可能跟着视频走,会出现内存不足的问题)
-e “discovery.type=single-node” 单点模式运行(区别于集群模式运行)
两个-v参数:数据卷挂载,分别是数据保存目录(data),和插件目录(plugins)
–network es-net 将ES容器加入到刚刚创建的docker网络中
-p 9200:9200 和 -p 9300:9300 是暴露的端口,9200是用户访问的http协议端口,9300是ES容器节点互联的端口
elasticsearch:7.12.1 镜像名称
docker run -d
--name es
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m"
-e "discovery.type=single-node"
-v es-data:/usr/share/elasticsearch/data
-v es-plugins:/usr/share/elasticsearch/plugins
--privileged
--network es-net
-p 9200:9200
-p 9300:9300
elasticsearch:7.12.1
-
安装部署kibana(数据可视化界面)
黑马官方的kibana的tar包有问题,建议自己从docker hub拉下来镜像。但是拉下来之前要注意 ES 和 kibana的版本对应关系:
找到对应版本后(我已经找好了),执行命令:docker pull kibana:7.12.1从官网拉下来,这个过程比较慢,慢慢等
-
什么是分词器?为什么要安装分词器?
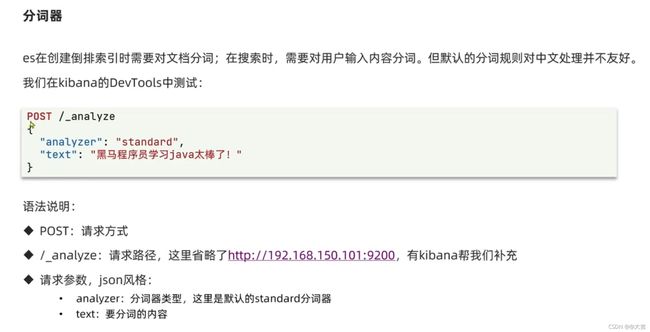
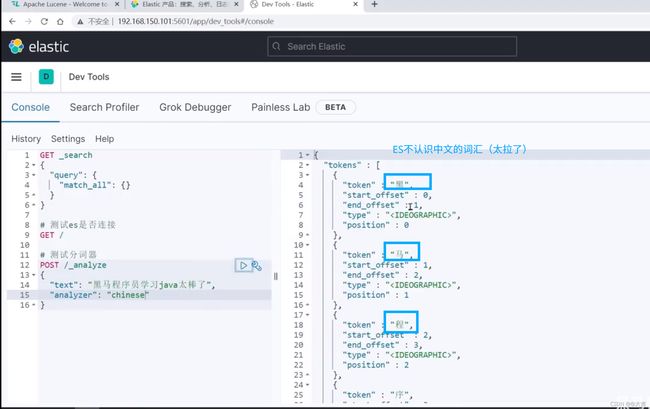
分词器我们选择IK分词器(来源于github,专门适配了中文)
该分词器的具体安装也在文档里有写。 -
分词器总结

[Debug] 停止ES容器(或是重启Linux)后,如何恢复Docker网络:
11.3 索引库操作
先给出ES官方帮助文档地址:
https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
索引库相当于MySQL中的Table。具体操作有两个:
- Mapping映射属性
- 索引库的CRUD
先介绍Mapping映射属性:

-
创建索引库

一个简单的创建索引库的语句:创建索引库
PUT /heima
{
“mappings”: {
“properties”: {
“info”: {
“type”: “text”,
“analyzer”: “ik_smart”
},
“email”: {
“type”: “keyword”,
“index”: false
},
“name”: {
“type”: “object”,
“properties”: {
“firstName”: {
“type”: “keyword”
},
“lastName”: {
“type”: “keyword”
}
}
}
}
}
} -
查看、修改、删除索引库
查看索引库:GET /索引库名
删除索引库:DELETE /索引库名
修改索引库从设计上被禁止了,索引库和mapping一旦创建无法修改,但是可以添加新的字段 (该字段必须是全新的字段) 。
它们的语法如下:
# 查询
GET /heima
# 修改(必须添加一个全新的字段)
PUT /heima/_mapping
{
"properties":{
"age":{
"type": "integer"
}
}
}
# 删除
DELETE /heima
11.4 文档操作
索引库相当于数据库的table,文档就相当于数据库的行。
-
添加文档

插入一个文档
POST /heima/_doc/1
{
“info”: “黑马程序员java讲师”,
“email”: “[email protected]”,
“name”:{
“firstName”:“云”,
“lastName”:“赵”
}
} -
查看、删除文档

查询
GET /heima/_doc/1
删除
DELETE /heima/_doc/1
每次写操作的时候,都会使得文档的"_version"字段+1
- 修改文档方式1 全量修改
它会删除旧文档,新增新文档
语法:和新增的语法完全一致,只不过新增是POST,全量修改是PUT
示例:
# 插入一个文档
PUT /heima/_doc/1
{
"info": "黑马程序员java讲师",
"email": "[email protected]",
"name":{
"firstName":"云",
"lastName":"赵"
}
}
如果id在索引库里面不存在,并不会报错,而是直接新增,如果索引库存在该记录,就会先删掉该记录,然后增加一个全新的。
-
修改文档方式2 增量修改
只修改某记录的指定字段值
语法:局部修改文档字段
第三行,必须跟一个doc
POST /heima/_update/1
{
“doc”: {
“email”:“[email protected]”
}
}
文档操作总结

11.5 RestClient操作索引库和文档
-
概念
ES官方为各种语言操作ES提供了客户端API,用来操作ES。其实本质都是组装ES语句,通过http请求发送给ES。 官方文档地址:https://www.elastic.co/guide/en/elasticsearch/client/index.html
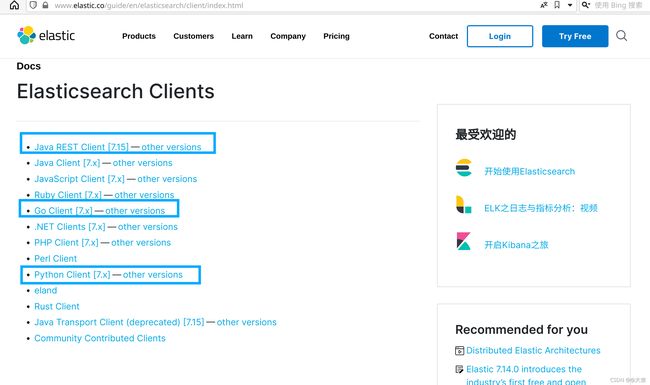
可以看到有很多语言的版本。 -
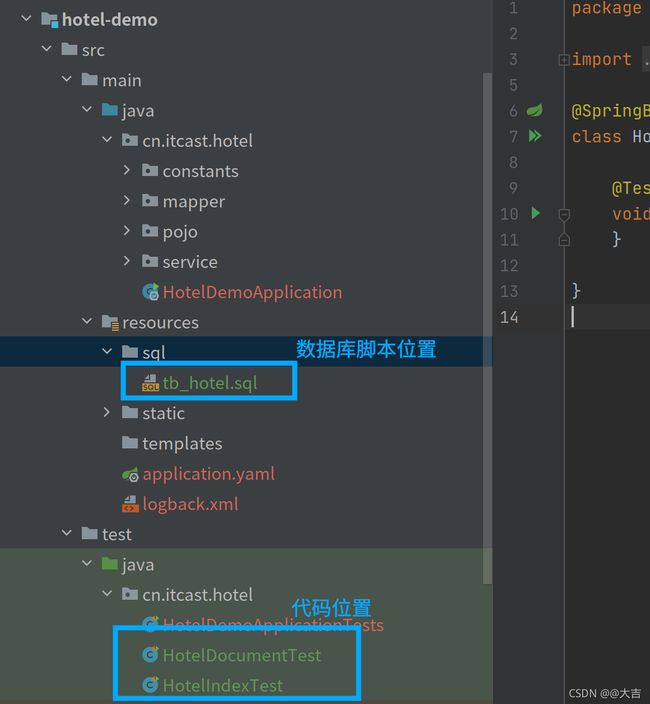
案例和代码位置

代码位置(大量代码写在测试类中),该案例需要导入数据库,数据库执行脚本位置同代码目录:
- 编写DSL语句,创建索引库(相当与MySQL中建表)
语句如下:
# 酒店的mapping
PUT /hotel
{
"mappings": {
"properties": {
"id":{
"type": "keyword"
},
"name":{
"type": "text"
, "analyzer": "ik_max_word",
"copy_to": "all"
},
"address":{
"type": "keyword"
, "index": false
},
"price":{
"type": "integer"
},
"score":{
"type": "integer"
},
"brand":{
"type": "keyword",
"copy_to": "all"
},
"city":{
"type": "keyword"
},
"starName":{
"type": "keyword"
},
"business":{
"type": "keyword",
"copy_to": "all"
},
"location":{
"type": "geo_point"
},
"pic":{
"type": "keyword"
, "index": false
},
"all":{
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
有时候可能会疑惑,同样的一个文本型字段,有的用text,有的用keyword。到底怎么选择呢?首先要了解索引和分词的概念:
- 索引(参与搜索,排序筛选等操作)
- 分词(把词看作一个整体还是把词用某种规则分开)
- 比如 : 上海,北京这种字段,不需要分词(这种字段在一个整体才有意义,分词就乱套了)
- “震惊!卢bw将于2022年复出” 这种就需要分词搜索,既然要分词了,肯定要选择分词器。
了解了上面的概念,再看一下下图(图来源于博客园——瘦风的南墙):

备注1:index如果设置成false,则既不参与索引也不参与分词。
备注2:索引库的id总是被要求成keyword(也就是String)类型,即使数据库的主键id可能是int
字段参数(用于聚合):copy to ;
地理位置特殊数据类型:geo_point
使用RestClient操作文档(索引库相当于数据库的table,文档就相当于数据库的行。),全都写在demo代码中,还是那句话:Java的API本质都是组装ES语句,通过http请求发送给ES。
11.6 DSL查询语法
先给出帮助文档,帮助文档永远是学东西最准确的方式:
https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
- 快速入门—简单查询:



全文检索查询例:
# match 和 multi_match
GET /hotel/_search
{
"query": {
"match": {
"address": "如家外滩"
}
}
}
GET /hotel/_search
{
"query": {
"multi_match": {
"query": "外滩如家",
"fields": ["brand","name","business"]
}
}
}

精确查询例:
# 精确查询(term查询)
GET /hotel/_search
{
"query": {
"term": {
"city": {
"value": "上海"
}
}
}
}
# 精确查询(范围range)
GET /hotel/_search
{
"query": {
"range": {
"price": {
"gte": 100,
"lte": 300
}
}
}
}
地理查询例:
# distance查询
GET /hotel/_search
{
"query": {
"geo_distance":{
"distance": "5km",
"location": "31.21, 121.5"
}
}
}
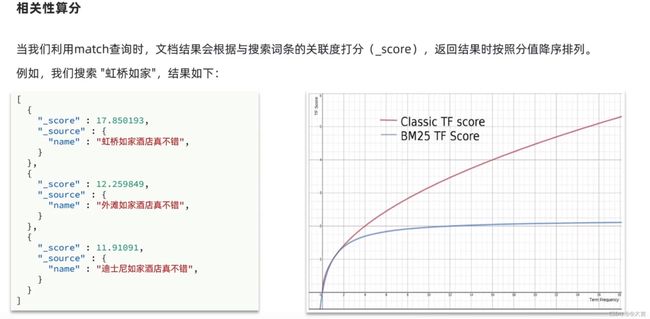
- 快速入门—打分算法:
打分算法(重点):
对默认算分方式进行修改:
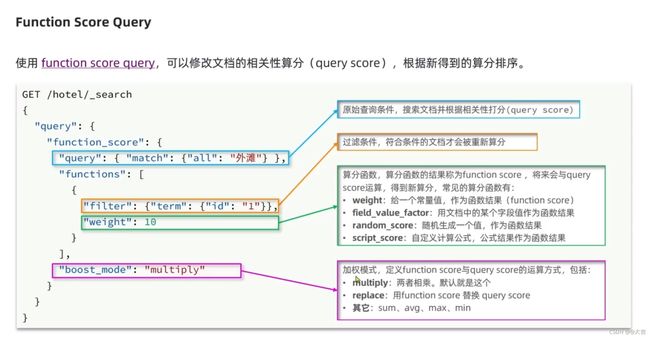
组合查询-function score 对应的Java RestClient代码:


上面例子的查询语句:
GET /hotel/_search
{
"query": {
"function_score": {
"query": {
"match": {
"address": "外滩"
}
},
"functions": [
{
"filter": {
"term": {
"brand": "如家"
}
},"weight": 10
}
]
}
}
}
- 快速入门—复合查询:
复合查询可以将其它简单查询组合起来,实现更复杂的搜索逻辑。
Boolean Query

注意,算分条件越多,性能就会越差。所以能使用filter的就别使用must,能不算分就不算分
案例:搜索名字包含“如家”,价格不高于400,在坐标31.21,121.5周围10km范围内的酒店
参考答案:
GET /hotel/_search
{
"query": {
"bool": {
"must": [
{"match": {
"name": "如家"
}}
],
"must_not": [
{"range": {
"price": {
"gt": 400
}
}}
],
"filter": [
{
"geo_distance": {
"distance": "100km",
"location": {
"lat": 31.21,
"lon": 121.5
}
}
}
]
}
}
}
- 快速入门—搜索结果处理:
搜索结果的处理主要包括排序、分页、高亮。默认ES是根据得分排序的,但是你如果指定了按某种字段排序,就会按你指定的方法排序。
A.排序

案例:
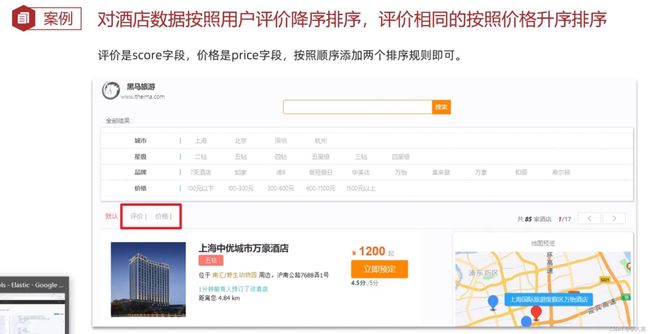
查询语句实现:
# sort排序
GET /hotel/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"score": "desc"
},
{
"price": "asc"
}
]组合查询-function score 对应的Java RestClient代码:
}
案例2:
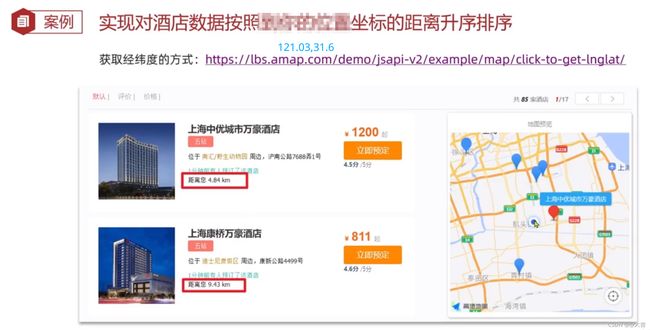
查询语句实现2:
GET /hotel/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"_geo_distance": {
"location": {
"lat": 31.03,
"lon": 121.61
},
"order": "asc"
, "unit": "km"
}
}
]
}
地理位置排序对应的java restclient代码:
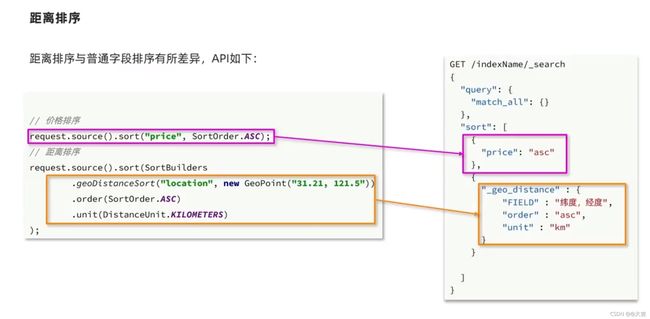
注意:一旦指定了某种排序之后,ES就会放弃打分。因为打分没意义了:
B.分页
ES默认情况只返回10条数据,如果想返回更多条数据,则需修改分页参数。
分页语法(有点像MySQL的limit):

示例:
GET /hotel/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"price": "asc"
}
],
"from": 20
, "size": 5
}
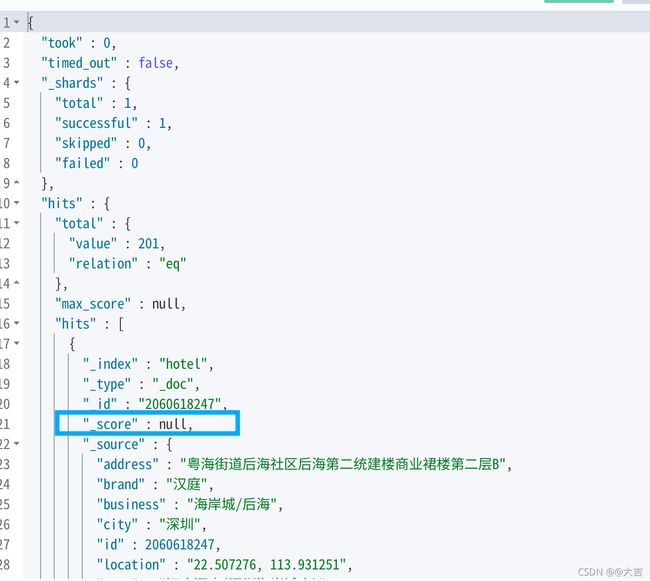
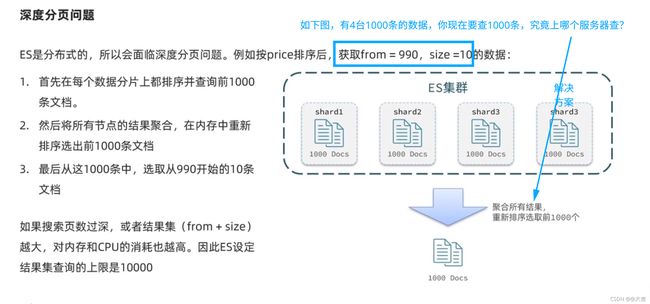
分页出现的问题:ES底层是倒排索引,不利于分页,所以分页查询是一种逻辑上的分页。比如现在要查从990开始,截取10条数据(990~1000这10条),对ES来讲,是先查出来0~1000条数据,查出来之后逻辑分页截取10条给你。这么做如果是单体,最多只是效率问题,但是如果是集群,就会坏事。如下图所示:
针对只能查询10000条结果的解决方案:

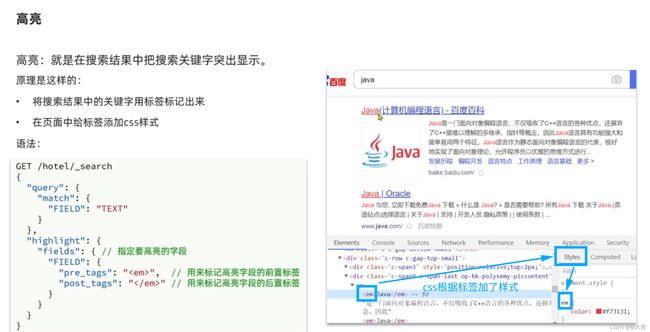
C.高亮
示例:
# 高亮查询,默认情况下ES搜索字段必须与高亮字段一致
GET /hotel/_search
{
"query": {
"match": {
"name": "如家"
}
},"highlight": {
"fields": {
"name": {
}
}
}
}
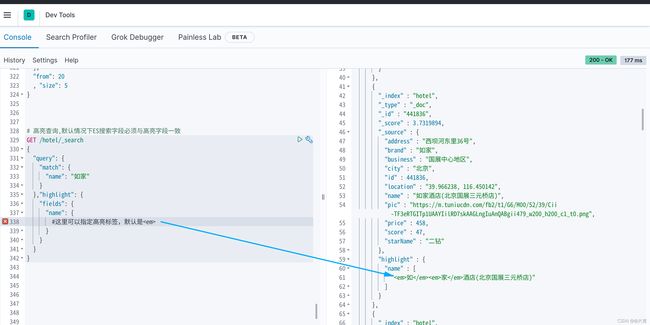
总结:
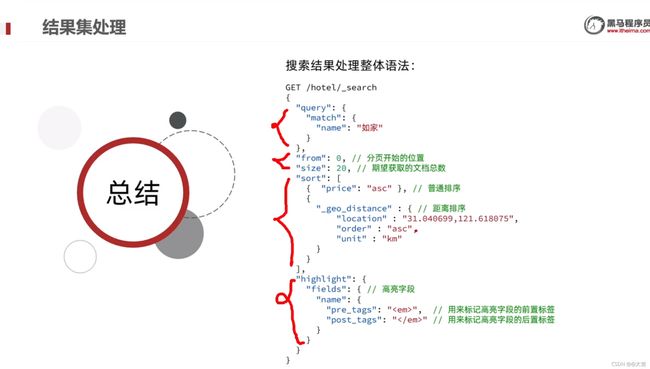
11.7 Java RestClient查询语法
要构建查询条件,只要记住一个类:QueryBuilders。
要构建搜索DSL,只需记住一个API:SearchRequest的source()方法(支持链式编程)
核心代码位置:
这里只有一个注意点:高亮结果的解析,比较麻烦。代码要配合下图理解:
11.8 ES综合案例:黑马旅游
代码位置:就是11.7那个类,直接启动SpringBoot主启动类,然后访问localhost:8089即可访问到前端页面
要实现的功能:
- 酒店搜索和分页
- 酒店结果过滤
- 我周边的酒店
- 酒店竞价排名
视频可能出现的bug:
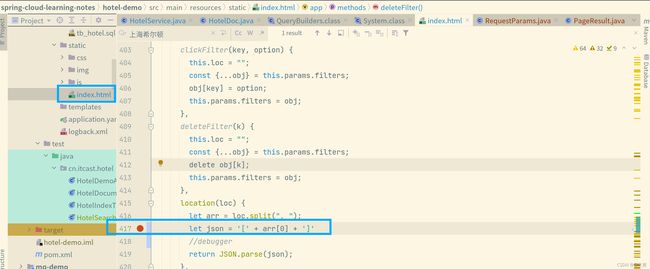
bug1 : 如果前端显示异常(搜索不生效),根据前端debug信息,修改index.html的第417行代码修改成如下图所示:
bug2: 黑马旅游网的酒店竞价排名实现不了
由于在视频里创建索引库里并没有创建isAD这个字段,我们需要手动追加该字段。在kibana控制台执行如下代码即可修复:
# 给索引库新增一个叫isAD的字段,类型是布尔类型
PUT /hotel/_mapping
{
"properties":{
"isAD":{
"type": "boolean"
}
}
}
# 给索引库id为45845的记录赋值,让其isAD字段为true(用于测试广告竞价排名,该记录会靠前)
POST /hotel/_update/45845
{
"doc": {
"isAD":true
}
}
GET hotel/_doc/45845
11.9 ES数据聚合
聚合,类似于MySQL的group by(对数据的统计分析和计算)。聚合不能是text类型,不能分词
聚合一共有几十种,在官方文档可以查到,但是主要分为三大类:

管道聚合 可以理解为linux的 |
1、Bucket聚合

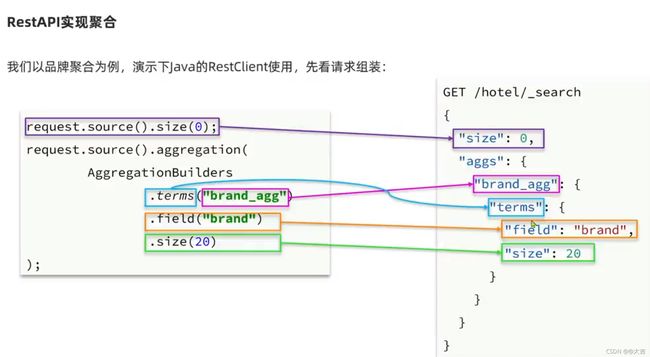
查询实例:
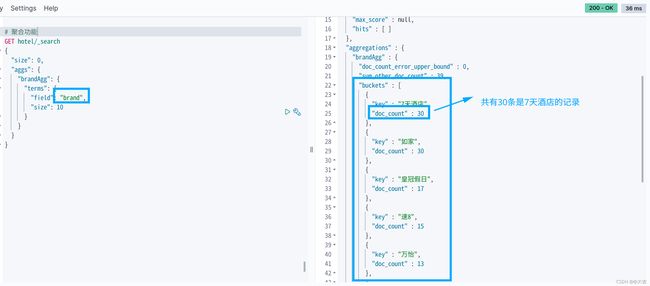
上图图例的结果是由count进行降序排列的,如果想让其升序排列,只需如下代码:
# 聚合功能
GET hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 10,
"order": {
"_count": "asc" #结果按照count升序排列
}
}
}
}
}
限定聚合范围:

2、Metrics聚合

示例:
# 嵌套聚合metric
GET hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 10,
"order": {
"scoreAgg.avg": "asc" # 根据下面的子聚合结果的avg进行升序排序
}
},
"aggs": {
"scoreAgg": {
"stats": {
"field": "score"
}
}
}
}
}
}
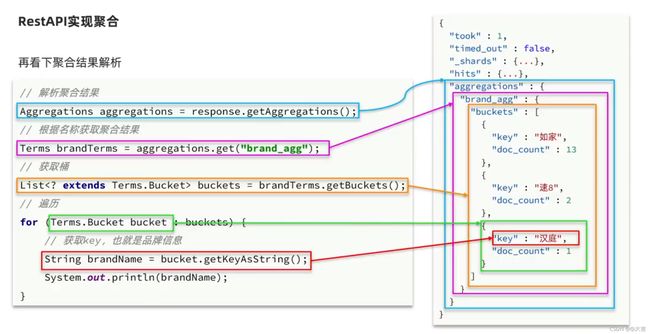
使用Java Restclient实现上面几种聚合方式,位置如下:
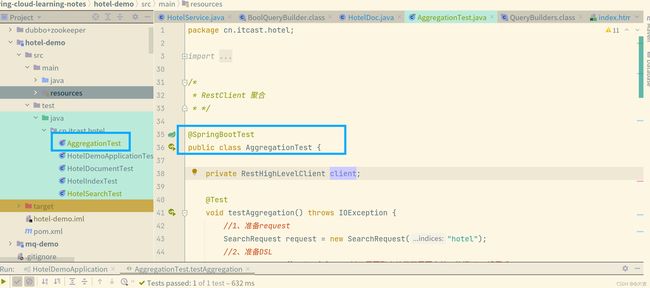
Java Restclient对应Json的图例:
Java代码对应结果解析的图例:
3、聚合案例:
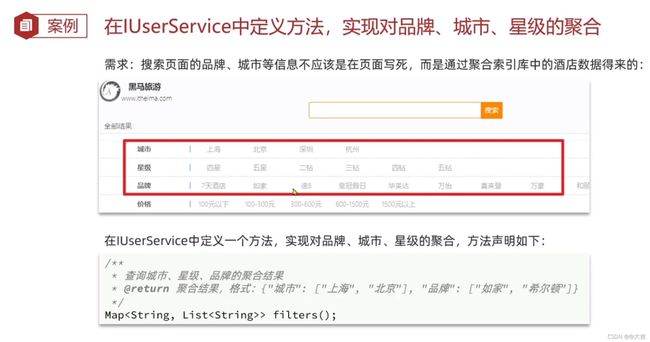
案例位置同上面的 ES综合案例:黑马旅游
11.10 ES数据补全
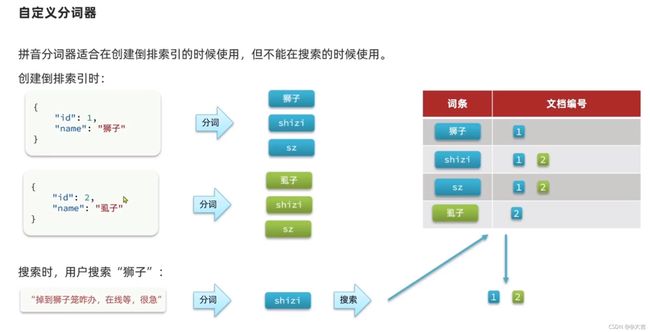
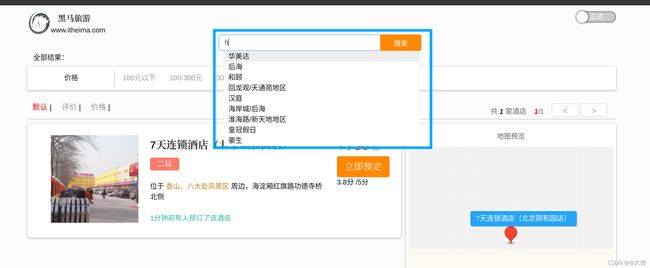
比如你在京东输入 sj 这两个字母,搜索框就会猜测出你想输入手机。这个就是数据补全
安装数据补全分词器:
分词器在课前资料里有

测试你的分词器是否生效:
POST _analyze
{
"text": ["卢本伟"],
"analyzer": "pinyin"
}
自定义配置分词器:
概念:
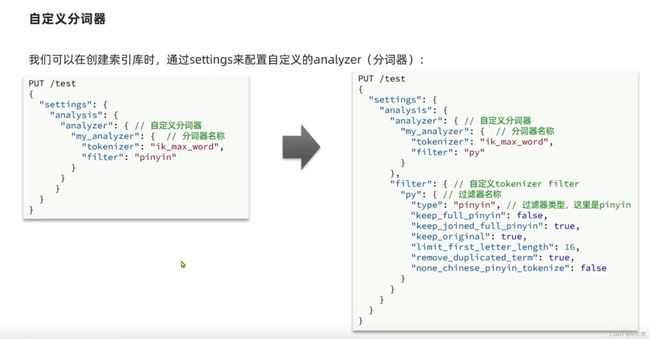

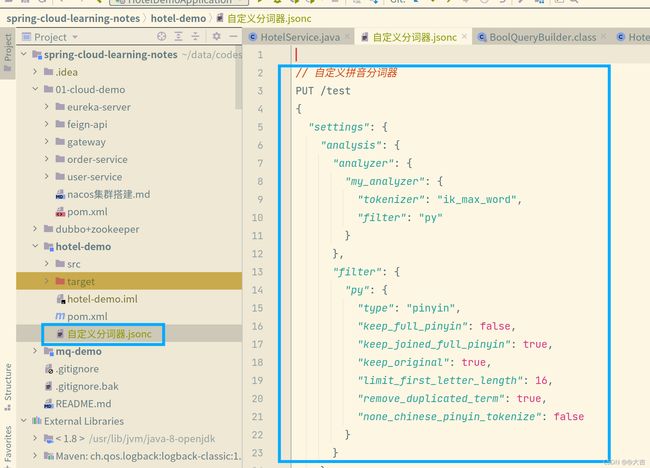
将下图位置的自定义配置分词器的第一段粘贴至kibana控制台,即可完成自定义配置:
Completion Suggester查询实现自动补全:

Completion Suggester语法:
// 自动补全查询
GET /test/_search
{
"suggest": {
"title_suggest": {
"text": "s", // 关键字
"completion": {
"field": "title", // 补全字段
"skip_duplicates": true, // 跳过重复的
"size": 10 // 获取前10条结果
}
}
}
}
总结:
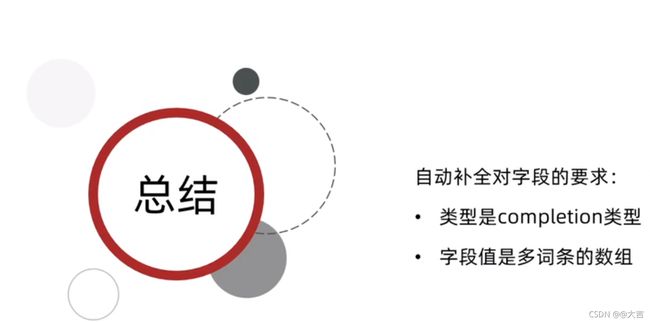
自动补全对字段的要求:
类型是completion类型;字段值是多词条的数组。
案例:实现hotel索引库的自动补全、拼音搜索功能:

找到下图位置,复制粘贴进kibana控制台并且执行(这一步是重建酒店数据索引库,在此之前要删掉原有的酒店数据索引库):
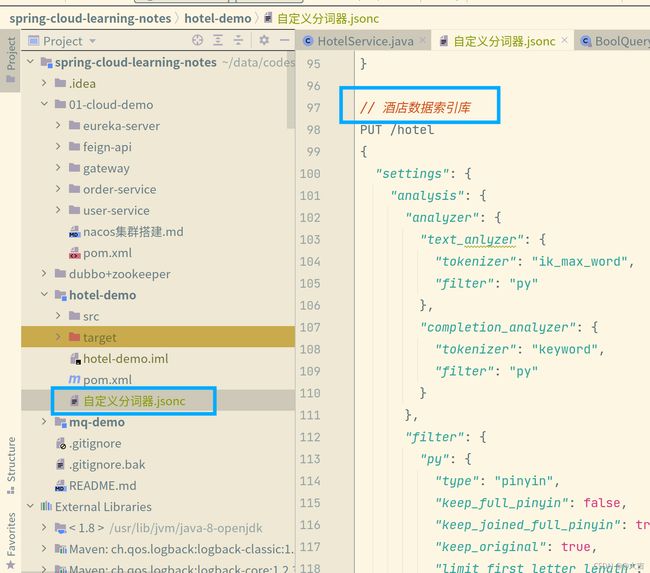
注意事项:
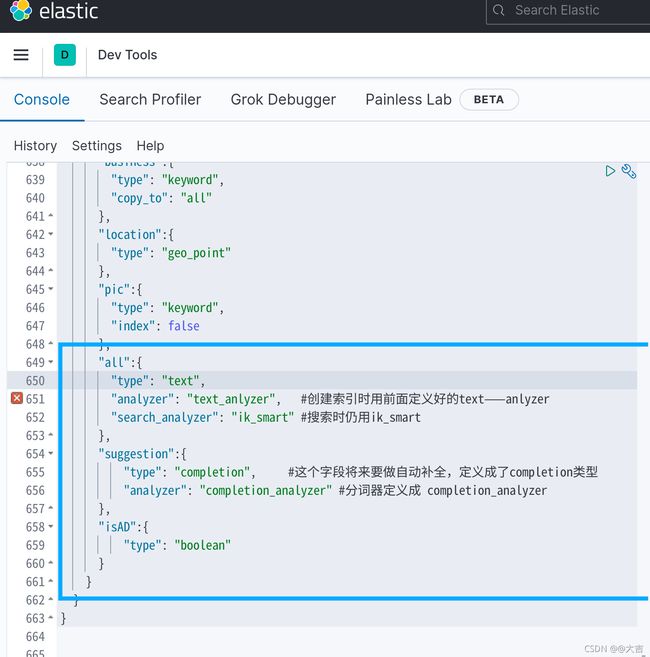
在Java代码中重新定义转换实体的操作,定义一个新的字段suggestion,并且在kibana控制台进行测试:
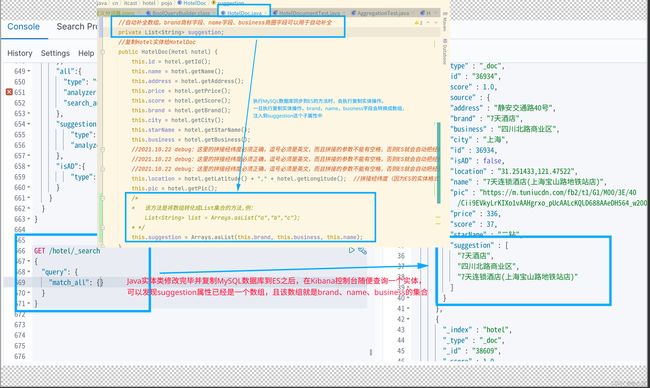
经过上面一番操作后,类型为completion类型的suggestion字段就有了我们想要自动补全的例子,然后执行下面的查询语句:
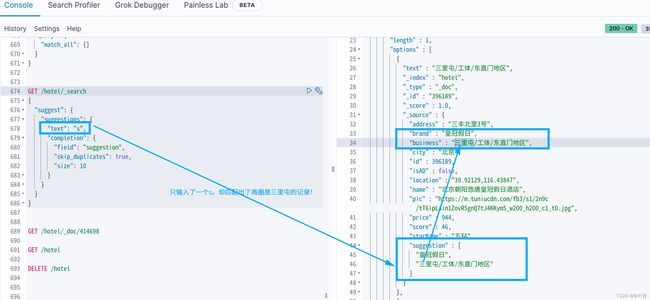
至此,自动补全、拼音搜索的demo已成功展示!
对上图的DSL语句在Java RestAPI里面进行发送:

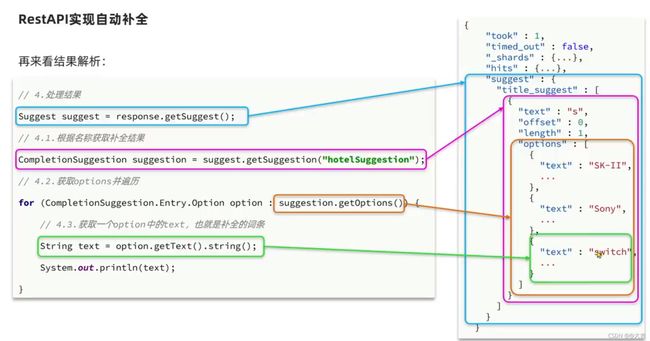
使用Java Restclient实现上面自动补全方式,位置如下:
案例效果:
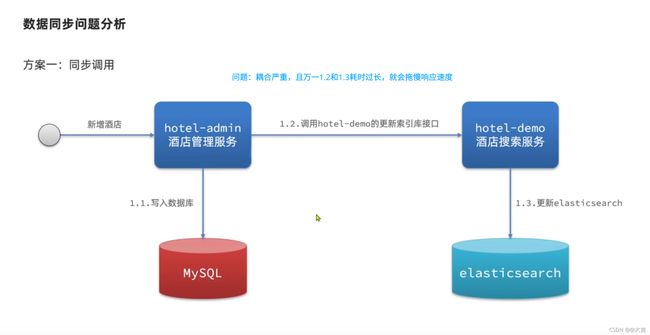
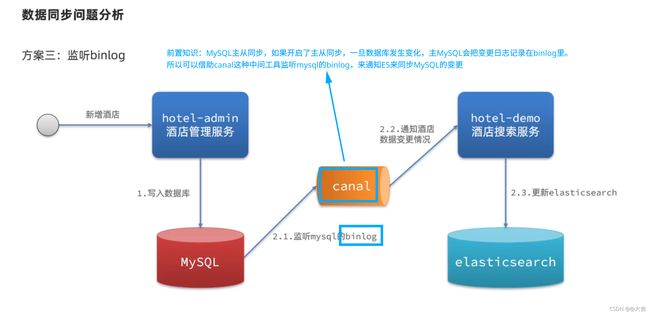
11.11 ES与MySQL之间数据同步(面试常问)
概念
ES中的酒店数据来自于MySQL索引库,因此mysql数据发生改变时,ES的值也会跟着改变,这个就是ES和MySQL的数据同步。
思考:在微服务中,操作MySQL的业务和操作ES的业务可能在不同的微服务上,这种情况应该怎么实现数据同步呢?
解决方案:
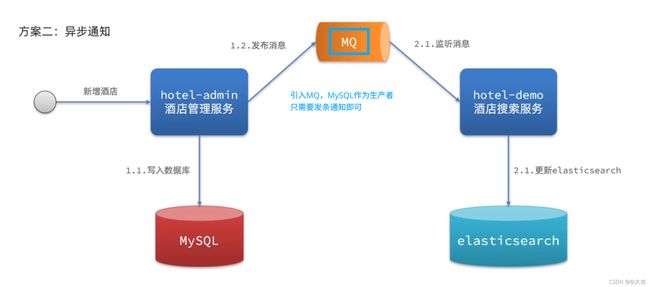
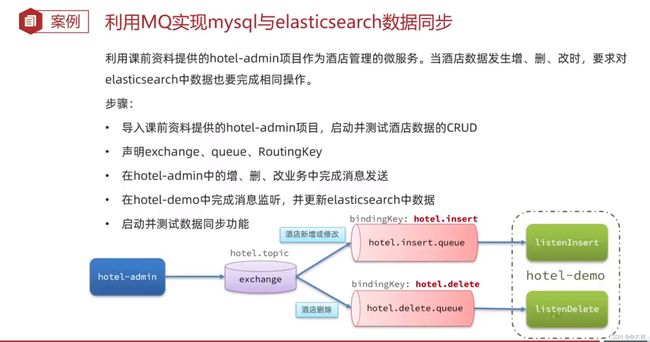
案例:利用MQ实现mysql与es的数据同步

思路:
数据同步案例后台管理页面代码位置如下图(数据库就用之前的ES综合案例:黑马旅游):
数据同步案例前端显示代码就是之前的ES综合案例:黑马旅游。前后端的微服务是分离的,端口号也不同。
实际上,这个项目hotel-admin项目相当于生产者,负责发送数据库增删改消息;hotel-demo(之前的黑马旅游前端项目)相当于消费者,负责监听消息并更新ES中的数据。
这样就实现了在微服务中,操作MySQL的业务和操作ES的业务在不同的微服务上的跨服务数据同步
用心跟着代码走,这个案例是完全可以做完并实现视频全部功能的,没有一句废话多余。
11.12 搭建高可用ES集群
概念
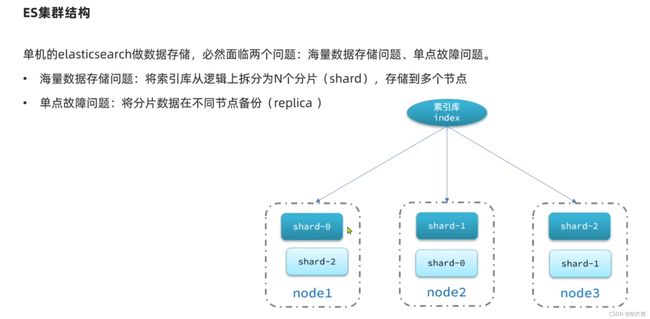
搭建ES集群
位置同之前的elasticsearch.md,找到该文档第四节:部署ES集群
集群脑裂问题
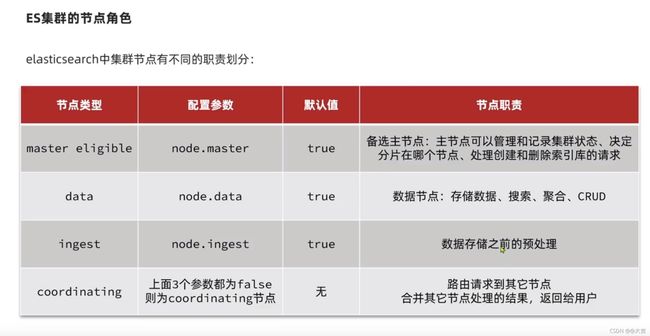
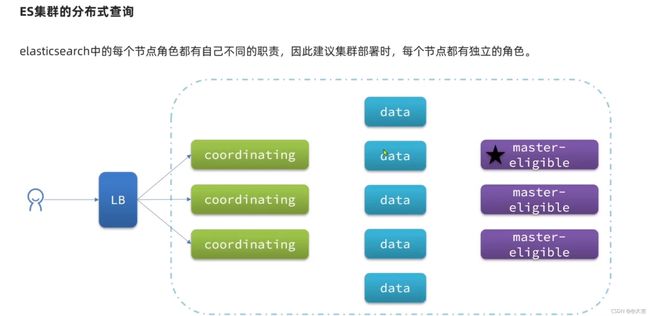
脑裂问题:一个集群出现了2个主节点:
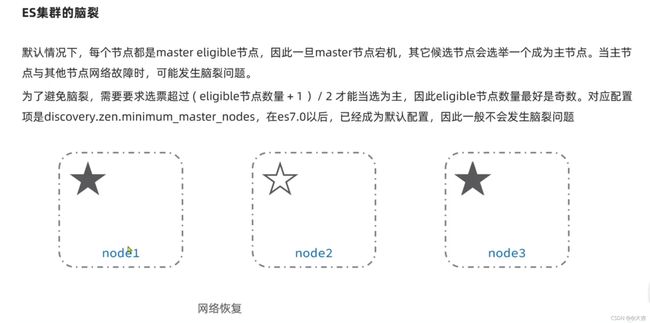
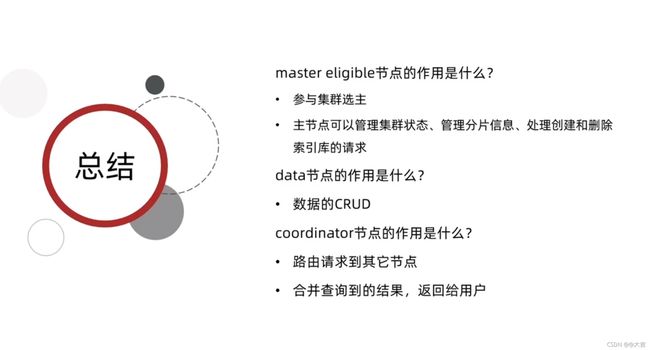
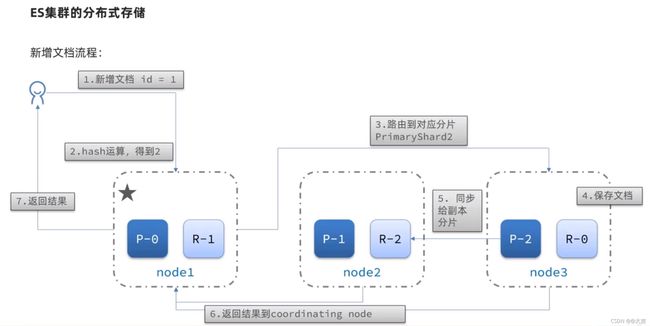
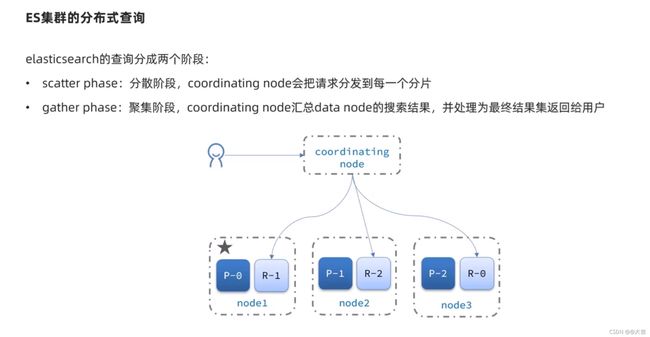
集群分布式存储和分布式查询

集群故障转移
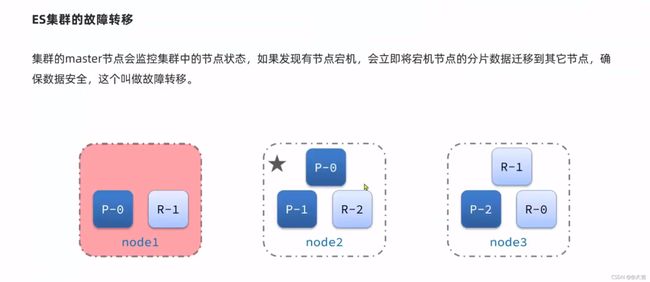
集群故障转移总结:
- Master挂掉后,EligibleMaster选举为新的主节点
- master节点监控分片,节点状态,将故障节点的分片转移到正常节点,确保数据安全。
后记
黑马 SpringCloud 2021 基础篇笔记和代码已更新完毕,不得不说黑马的这套课程的确是良心之作,而且官方居然还开源出来让大家都可以学习,实在是难能可贵。
如果大家在学习基础篇的同时有疑问,欢迎在评论区讨论和留言,也可以关注我,日后我还会陆续更新完高级篇和面试篇。
先自我介绍一下,小编13年上师交大毕业,曾经在小公司待过,去过华为OPPO等大厂,18年进入阿里,直到现在。深知大多数初中级java工程师,想要升技能,往往是需要自己摸索成长或是报班学习,但对于培训机构动则近万元的学费,着实压力不小。自己不成体系的自学效率很低又漫长,而且容易碰到天花板技术停止不前。因此我收集了一份《java开发全套学习资料》送给大家,初衷也很简单,就是希望帮助到想自学又不知道该从何学起的朋友,同时减轻大家的负担。添加下方名片,即可获取全套学习资料哦