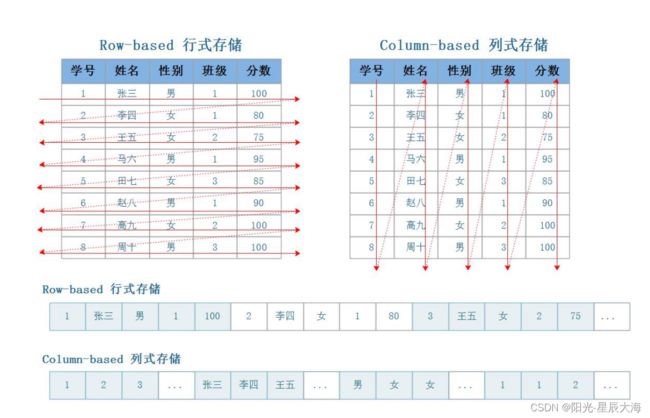
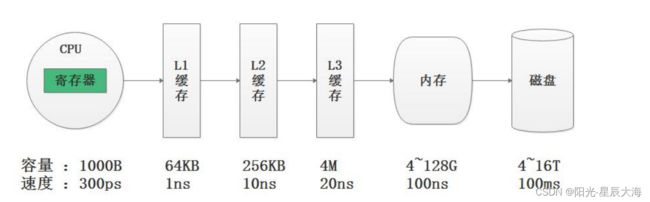
通过以上案例可以看到,压缩的本质是按照一定步长对数据进行匹配扫描,当发现重复 部分的时候就进行编码转换。例如:(5,3)代表从下划线往前数 5 个字节,会匹配上 3 个 字节长度的重复项,即:“BCD”。当然,真实的压缩算法比以上举例更复杂,但压缩的本 质就是如此,数据中重复性项越多,则压缩率越高,压缩率越高,则数据体量越小,而数据 体量越小,则数据在网络中的传输越快,对网络带宽和磁盘 IO 的压力也就越小。
何为向量化执行?向量化执行,可以简单地看作一项消除程序中循环的优化。
为了 制作 n 杯果汁,非向量化执行的方式是用 1 台榨汁机重复循环制作 n 次,而向量化执行的
方式是用 n 台榨汁机只执行 1 次。
为了实现向量化执行,需要利用 CPU 的 SIMD 指令, SIMD 的全称是 Single
Instruction Multiple Data ,即用单条指令操作多条数据。现代计算机系统概念中,
它是通过数据并行以提高性能的一种实现方式 ( 其他的还有指令级并行和线程级并行 ) ,它
的原理是在 CPU 寄存器层面实现数据的并行操作。 ClickHouse 列式存储除了降低 IO 和存储的压力之外,还为向量化执行做好了铺垫, 除了读取磁盘速度快之外, ClickHouse 还利用 SSE4.2 指令集实现向量化执行,为处理 数据提升很大效率。
CLICKHOUSE支持的类型
支持关系模型和标准SQL查询,大小写敏感
ClickHouse完全使用 SQL 作为查询语言(支持 GROUP BY、ORDER BY、JOIN、IN 等大部分标准 SQL),ClickHouse 提 供了标准协议的 SQL 查询接口,可以与第三方分析可视化系统无缝集成对接。在 SQL 解析 方面,ClickHouse 是大小写敏感,SELECT a 和 SELECT A 所代表的语义不同。
支持多样化的表引擎
支持多线程和分布式
向量化执行是通过数据级并行的方式提升了性能,多线程处理是通过线程级并行的方式
实现了性能的提升。相比基于底层硬件实现的向量化执行 SIMD ,线程级并行通常由更高层
次的软件层面控制,目前市面上的服务器都支持多核心多线程处理能力。由于 SIMD 不适合
用于带有较多分支判断的场景, ClickHouse 也大量使用了多线程技术以实现提速,以此
和向量化执行形成互补。 ClickHouse 在数据存取方面,既支持分区 ( 纵向扩展,利用多线
程原理 ) ,也支持分片 ( 横向扩展,利用分布式原理 ) ,可以说是将多线程和分布式的技术
应用到了极致。
ClickHouse则采用Multi-Master 多主架构,集群中的每个节点角色对等,客户端访问任意一个节点都能得到相同的效果。这 种多主的架构有许多优势,例如对等的角色使系统架构变得更加简单,不用再区分主控节点、 数据节点和计算节点,集群中的所有节点功能相同。所以它天然规避了单点故障的问题,非 常适合用于多数据中心、异地多活的场景。
交互式查询
数据分片与分布式查询
数据分片是将数据进行横向切分,这是一种在面对海量数据的场景下,解决存储和查询
瓶颈的有效手段,是一种分治思想的体现。 ClickHouse 支持分片,而分片则依赖集群。
每个集群由 1 到多个分片组成,而每个分片则对应了 ClickHouse 的 1 个服务节点。分片
的数量上限取决于节点数量( 1 个分片只能对应 1 个服务节点)。
ClickHouse 拥有高度自动化的分片功能。 ClickHouse 提供了本地表 ( Local
Table )与分布式表( Distributed Table )的概念。一张本地表等同于一份数据的分
片。而分布式表本身不存储任何数据,它是本地表的访问代理,其作用类似分库中间件。借
助分布式表,能够代理访问多个数据分片,从而实现分布式查询
CLICKHOUSE安装
Clickhouse 仅支持 Linux 系统 且 cpu 必须支持 SSE4.2 指令集,可以通过以下命令查询 Linux 是否支持
grep -q sse4_2 /proc/cpuinfo && echo "SSE 4.2 supported" || echo "SSE 4.2 not supported"
服务器不支持 SSE4.2 指令集,则不能下载预编译安装包,需要通过源码编译特 定版本进行安装。
单节点安装
rpm -ivh clickhouse-common-static-20.8.3.18-1.el7.x86_64.rpm
rpm -ivh clickhouse-server-common-20.8.3.18-1.el7.x86_64.rpm
rpm -ivh clickhouse-server-20.8.3.18-1.el7.x86_64.rpm
rpm -ivh clickhouse-client-20.8.3.18-1.el7.x86_64.rpm
rpm -ivh ./clickhouse-*.rpm
配置文件
/etc/clickhouse-server : 服务端的配置文件目录,包括全局配置 config.xml 和用户配置 users.xml。 /var/lib/clickhouse : 默认的数据存储目录,通常会修改,将数据保存到大容 量磁盘路径中。 /var/log/cilckhouse-server : 默认保存日志的目录,通常会修改,将数据保 存到大容量磁盘路径中。 在/usr/bin 下会有可执行文件: clickhouse:主程序可执行文件
clickhouse-server:一个指向 clickhouse 可执行文件的软连接,供服务端启动 使用。
clickhouse-client:一个指向 clickhouse 可执行文件的软连接,供客户端启动 使用
启动&停止服务
启动 clickhouse-server 服务:service clickhouse-server start
client 客户端连接到 ch 服务:clickhouse-client
client客户端使用的命令:clickhouse-client --host localhost --port 9000
查看9000端口占用情况:yum install net-tools
查看端口是否启动:netstat -tunlp | grep 9000
停止ClickHouse服务:service clickhouse-server stop
分布式安装
1、选择三台 clickhouse 节点,在每台节点上安装 clickhouse 需要的安装包
2、需要使用 Zookeeper 去实现集群副本之间的同步
3、配置外网可以访问:在每台 clickhouse 节点中配置/etc/clickhouse-server/config.xml 文
::
4、在每台./etc目录下面创建metrika.xml文件 编辑文件中的内容
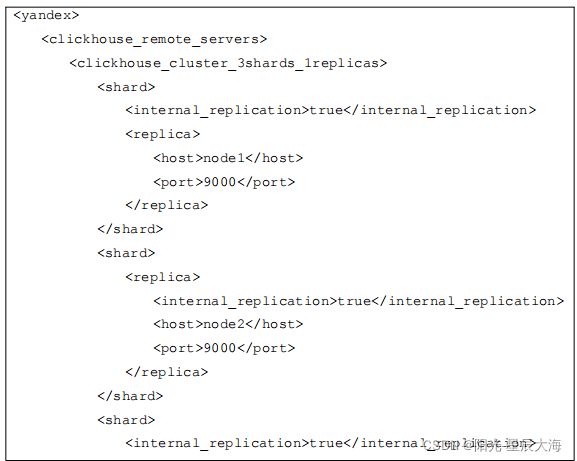


配置文件说明:
clickhouse_remote_servers :
clickhouse 集群配置标签,固定写法。
clickhouse_cluster_3shards_1replicas:
配置 clickhouse 的集群名称,可自由定义名称,注意集群名称中不能包含点号。这
里代表集群中有 3 个分片,每个分片有 1 个副本。
分片是指包含部分数据的服务器,要读取所有的数据,必须访问所有的分片。
副本是指存储分片备份数据的服务器,要读取所有的数据,访问任意副本上的数据即可。
shard :
分片,一个 clickhouse 集群可以分多个分片,每个分片可以存储数据,这里 分片可
以理解为 clickhouse 机器中的每个节点 。这里可以配置一个或者任意多个分片,在每个
分片中可以配置一个或任意多个副本,不同分片可配置不同数量的副本。如果只是配置一个
分片,这种情况下查询操作应该称为远程查询,而不是分布式查询。
replica :
每个分片的副本,默认每个分片配置了一个副本。也可以配置多个。如果配置了副本,
读取操作可以从每个分片里选择一个可用的副本。如果副本不可用,会依次选择下个副本进
行连接。该机制利于系统的可用性。
internal_replication :
默认为 false, 写数据操作会将数据写入所有的副本,设置为 true, 写操作只会选择
一个正常的副本写入数据,数据的同步在后台自动进行。
zookeeper-servers :
配置的 zookeeper 集群
macros :
区分每台 clickhouse 节点的宏配置,每台 clickhouse 需要配置不同名称。
networks :
这里配置 ip 为“ ::/0 ”代表任意 IP 可以访问,包含 IPv4 和 IPv6 。
注意:允许外网访问还需配置 /etc/clickhouse-server/config.xml 参照第三 步骤
clickhouse_compression :
MergeTree 引擎表的数据压缩设置, min_part_size :代表数据部分最小大小。
min_part_size_ratio :数据部分大小与表大小的比率。 method :数据压缩格式。
注意:需要在每台 clickhouse 节点上配置 metrika.xml 文件,并且修改每个节点
的 macros 配置名称。
在每台节点上启动 clickhouse 服务
首先启动 zookeeper 集群,然后分别在 node1 、 node2 、 node3 节点上启动
clickhouse 服务,这里每台节点和单节点启动一样。启动之后, clickhouse 集群配置
完成
在每台机器上启动clickhouse服务
service clickhouse-server start
检查集群配置是否完成: 在 node1 、 node2 、 node3 任意一台节点进入 clickhouse 客户端,查询集群配置
clickhouse-client
select * from system.clusters;
rpm包的其他安装方式
yum -y install yum-utils
rpm --import https://repo.yandex.ru/clickhouse/CLICKHOUSE-KEY.GPG
yum-config-manager --add-repo https://repo.yandex.ru/clickhouse/rpm/stable/x86_64
yum -y install clickhouse-server clickhouse-client
centeros7中yum源安装启动ck的命名为:systemctl start clickhouse-server
客户端链接CK的方式
--host , -h:
使 用 -h 指 定 ip 或 者 host 名 称 时 , 需 要 在
/etc/clickhouse-server/config.xml 配 置 文 件 中 114 行 配 置 :
:: ,代表可以任意 ip 可访问。配置完成后需要重启
当期 clickhouse 节点生效。
--query , -q
clickhouse-client -q "show databases"
--database, -d:
clickhouse-client -d "system" -q "show tables"
--multiline, -m:
clickhouse-client -m
select
:-] 1+1
:-] ;
--time, -t:
clickhouse-client -t -q "show databases"
--stacktrace:
clickhouse-client --stacktrace
--multiquery , -n
clickhouse-client -n -q "show databases;use default;"