基于Python实现的数据质量检查
目录
1:应用场景
2:外部数据数据质量评估
解决方案构思一:
2.1:评估维度——“三率”
2.2:评估维度——“三性”
2.3:评估维度——“三度”
2.4:外部数据质量检查案例
3:内部数据数据清洗及转换
3.1:时间戳格式转换
3.2:时间格式指定转换及清洗
3.3:异常日期类型&不规则日期类型 转换为指定日期类型
3.4:一致性检验
3.5:异常值过滤
3.6:行缺失&列缺失信息
1:应用场景
数据分析工程师 & 算法工程师主要工作流程大体可分为:数据获取 -> 数据分析 -> 业务决策(通常算法工程师会多一项数据建模过程)。数据获取是前提,数据获取可以是通过数仓宽表进行多级关联得到的结构化数据,也可以是通过爬虫解析后获取的原始数据,后者可能未经过完整的ETL数据清洗过程,原始数据很可能存在空值、异常值、错误字符等情况。
在整个纵向的工作流程中,如果使用的基础数据有问题,基于这些数据得到的产出都是低价值甚至可能得出错误的结论,Garbage in... Garbage out...。而对于数据分析、数据挖掘而言,高质量的基础数据,才可以保证做出正确有用的决策。因此在引入外部数据之前,需要从多个维度评估数据的综合应用效果,从而为企业是否采用此数据产品提供理论依据与业务采纳参考。
本文分别从外部数据、内部数据,两个维度介绍基于Python实现的数据质量检查的基本思路和方法,具体包括:从哪些角度检查数据质量问题、发现数据质量问题后如何处理。
2:外部数据数据质量评估
解决方案构思一:
2.1:评估维度——“三率”
- 维度1——覆盖率:已匹配数据样本数量 / 分析样本总数
- 维度2——缺失率:特征缺失值样本数量 / 分析样本总数
- 维度3——准确率:验证一致样本数量 / 分析样本总数
2.2:评估维度——“三性”
- 维度4——相关性:特征相关性Pearson、Spearman系数
- 维度5——预测性:特征对目标变量的信息贡献度指标IV
- 维度6——解释性:特征分布趋势与实际业务理解是否匹配
2.3:评估维度——“三度”
- 维度7——区分度:模型区分度指标KS、AUC、Gini等
- 维度8——重要度:特征重要系数(importance、shap_value)
- 维度9——稳定度:特征在不同样本的分布稳定性PSI
2.4:外部数据质量检查案例
以下是经过某公开数据,id表示用户编号;date表示对应日期;flag表示业务上对应的用户标签;is_blacklist 表示是否为黑名单;credit_ability表示履约能力指数;consume_ability表示消费能力指数;travel_ability表示出行能力指数;stable_ability表示稳定能力指数。
其中,id和date表示自有业务中的相关数据,从外部三方数据中,通过关联关系得到对应的is_blacklist、credit_ability、consume_ability、travel_ability、stable_ability等信息。
总体数据概览:

可以看到,样本总数为8000个。is_blacklist、credit_ability、consume_ability、travel_ability、stable_ability这几个字段存在缺失值。
进一步,由于数据量比较小,可利用pandas_profiling,生成可视化数据分析报告,对数据分布,缺失,最大最小值、相关性热度图等分布,有更直观的认识,同时支持生成html文件方式,可进行预览分析。
import pandas_profiling
data_test = pd.read_csv("test_data.csv")
pandas_profiling.ProfileReport(data_test)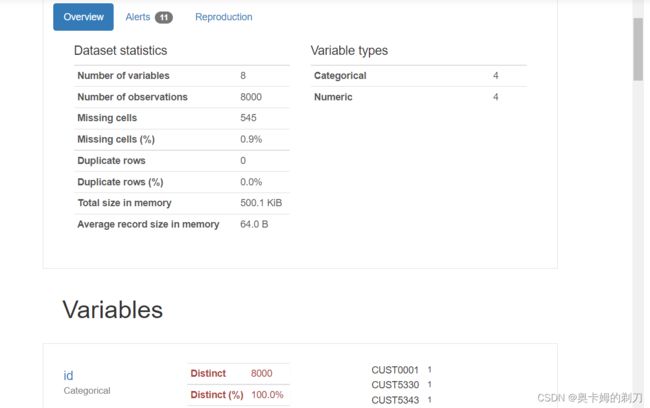
维度1查看覆盖率:
定义:如果以上缺失字段同时为空,则表示该条数据没有从外部数据中获取到对应用户的数据:
miss_all = data_test[data_test['is_blacklist'].isnull()
& data_test['credit_ability'].isnull()
& data_test['consume_ability'].isnull()
& data_test['travel_ability'].isnull()
& data_test['stable_ability'].isnull()]
print(f'覆盖率为:{(len(data_test)-len(miss_all))/len(data_test)}') # 结果为 0.99025 维度2查看缺失率:
查看各个字段的缺失率:
miss_rate = data_test.isnull().sum()
miss_rate = miss_rate.reset_index()
miss_rate = miss_rate.rename(columns={'index': 'varname', 0: 'miss_num'})
miss_rate['miss_rate'] = miss_rate['miss_num'] / len(data_test)miss_rate :
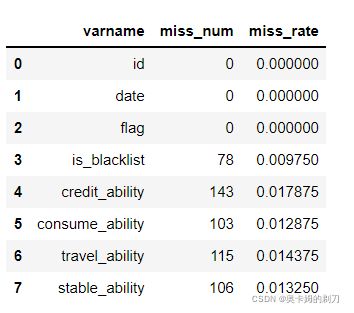
维度3查看准确率:
准确率计算逻辑:检查自有业务中的flag 标签与is_blacklist 黑名单信息是否匹配,如同时为好用户(数值为0),同时为坏用户(数值为1)。
verify_true = data_test[((data_test['is_blacklist'] == 1) & (data_test['flag'] == 1))
| ((data_test['is_blacklist'] == 0) & (data_test['flag'] == 0))]
print(f'准确率为:{(len(verify_true))/len(data_test)}') # 结果为 0.780875维度4相关性:
var_corr = data_test[['is_blacklist',
'credit_ability',
'consume_ability',
'travel_ability',
'stable_ability']].corr(method='pearson')
var_corr
维度5和6: 预测性及可解释性(针对建模人员)
def cal_iv(data:pd.DataFrame, cut_num:int, feature:str, target:str):
data_cut = pd.cut(data[feature], cut_num)
cut_group_all = data[target].groupby(data_cut).count()
cut_y = data[target].groupby(data_cut).sum()
cut_n = cut_group_all - cut_y
df = pd.DataFrame()
df['sum'] = cut_group_all
df['bad_count'] = cut_y
df['good_count'] = cut_n
df['bad_rate'] = df['bad_count'] / df['bad_count'].sum()
df['good_rate'] = df['good_count'] / df['good_count'].sum()
df['woe'] = np.log(df['bad_rate'] / df['good_rate'])
df['iv'] = df['woe'] * (df['bad_rate'] - df['good_rate'])
iv = df['iv'].sum()
print(feature, 'IV:', iv)
cal_iv(data_test,10,'credit_ability','flag')
维度7区分度:以二分类模型评估指标ks值为例(针对建模人员)
def cal_ks(data:pd.DataFrame, cut_num, feature:str, target:int) ->pd.DataFrame:
data_cut = pd.cut(data[feature], cut_num)
cut_group_all = data[target].groupby(data_cut).count()
cut_y = data[target].groupby(data_cut).sum()
cut_n = cut_group_all - cut_y
df = pd.DataFrame()
df['sum'] = cut_group_all
df['bad_count'] = cut_y
df['good_count'] = cut_n
df['bad_rate'] = df['bad_count'] / df['bad_count'].sum()
df['good_rate'] = df['good_count'] / df['good_count'].sum()
df['good_rate_sum'] = df['good_rate'].cumsum()
df['bad_rate_sum'] = df['bad_rate'].cumsum()
df['ks'] = abs(df['good_rate_sum'] - df['bad_rate_sum'])
ks = df['ks'].max()
print(feature, 'KS:', ks)
cal_ks(data_test, 10, 'credit_ability', 'flag')维度8重要度:以决策树(faeture importance) 值为例(针对建模人员)
from sklearn.ensemble import ExtraTreesClassifier
#缺失值处理
import copy
data_test_s = copy.deepcopy(data_test)
data_test_s['credit_ability'] = data_test['credit_ability'].fillna(data_test['credit_ability'].mean())
data_test_s['consume_ability'] = data_test['consume_ability'].fillna(data_test['consume_ability'].mean())
data_test_s['travel_ability'] = data_test['travel_ability'].fillna(data_test['travel_ability'].mean())
data_test_s['stable_ability'] = data_test['stable_ability'].fillna(data_test['stable_ability'].mean())
data_test_s['is_blacklist'] = data_test['is_blacklist'].fillna(data_test['is_blacklist'].mean())
miss_rate = data_test_s.isnull().sum()
data_x=data_test_s.loc[:,['credit_ability','consume_ability','travel_ability',
'stable_ability','is_blacklist']]
data_y=data_test_s.loc[:,['flag']]
model = ExtraTreesClassifier()
model.fit(data_x,data_y)
var_importance = model.feature_importances_
for feature, importance in zip(data_x.columns, model.feature_importances_):
print(feature,'importance',importance)
维度9稳定度:以批量计算PSI为例(针对建模人员)
def cal_psi(data:pd.DataFrame, feature:str, cut_num:int):
data_bin = pd.cut(data[feature], cut_num)
data_test_n = data.loc[:, ['date', feature]]
data_bin = data_bin.reset_index()
data_test_n = data_test_n.reset_index()
data_bin = data_bin.rename(columns={feature: 'bin'})
data_test_bin = data_test_n.merge(data_bin, on='index', how='inner')
data_test1 = data_test_bin[(data_test_bin['date'] == '2021/06') | (data_test_bin['date'] == '2021/07')]
data_test2 = data_test_bin[(data_test_bin['date'] == '2021/08') | (data_test_bin['date'] == '2021/09')]
data_test1 = data_test1.loc[:, [feature, 'bin']]
data_test2 = data_test2.loc[:, [feature, 'bin']]
var_bin1 = pd.DataFrame()
var_bin1 = data_test1.groupby(['bin']).count()
var_bin1 = var_bin1.reset_index()
var_bin1 = var_bin1.rename(columns={feature: 'date1_count'})
var_bin2 = pd.DataFrame()
var_bin2 = data_test2.groupby(['bin']).count()
var_bin2 = var_bin2.reset_index()
var_bin2 = var_bin2.rename(columns={feature: 'date2_count'})
var_bin3 = var_bin1.merge(var_bin2, on='bin', how='inner')
var_bin3.loc['10'] = ['nan', 4188 - var_bin3['date1_count'].sum(), 3812 - var_bin3['date2_count'].sum()]
var_bin3['date1_pct'] = var_bin3['date1_count'] / 4188
var_bin3['date2_pct'] = var_bin3['date2_count'] / 3812
var_bin3['psi'] = (np.log(var_bin3['date1_pct'] / var_bin3['date2_pct'])) * (
var_bin3['date1_pct'] - var_bin3['date2_pct'])
var_bin3['psi_sum'] = var_bin3['psi'].sum()
psi = var_bin3['psi'].sum()
print(feature, 'PSI:', psi)3:内部数据数据清洗及转换
这里内部数据指的是业务自有数据、数据库沉淀数据,该部分数据质量分析主要涉及数据清洗、数据转换,异常值过滤等。
3.1:时间戳格式转换
import time
import numpy as np
from math import isnan
# 输入毫秒级的时间,转出正常格式的时间
def timeStamp(timeNum):
if timeNum is None or timeNum is np.nan or isnan(timeNum):
return np.nan
else:
timeStamp = float(timeNum/1000)
timeArray = time.localtime(timeStamp)
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
return otherStyleTime
timeStamp(142343433244)3.2:时间格式指定转换及清洗
import calendar
from datetime import datetime
from dateutil.relativedelta import relativedelta
class DateTimeUtil():
def get_cur_month(self):
# 获取当前月
return datetime.now().strftime("%Y-%m")
def get_last_month(self, number=1):
# 获取前几个月
month_date = datetime.now().date() - relativedelta(months=number)
return month_date.strftime("%Y-%m")
def get_next_month(self, number=1):
# 获取后几个月
month_date = datetime.now().date() + relativedelta(months=number)
return month_date.strftime("%Y-%m")
def get_cur_month_start(self):
# 获取当前月的第一天
month_str = datetime.now().strftime('%Y-%m')
return '{}-01'.format(month_str)
def get_cur_month_end(self):
# 获取当前月的最后一天
'''
param: month_str 月份,2021-04
'''
# return: 格式 %Y-%m-%d
month_str = datetime.now().strftime('%Y-%m')
year, month = int(month_str.split('-')[0]), int(month_str.split('-')[1])
end = calendar.monthrange(year, month)[1]
return '{}-{}-{}'.format(year, month, end)
def get_last_month_start(self, month_str=None):
# 获取上一个月的第一天
'''
param: month_str 月份,2021-04
'''
# return: 格式 %Y-%m-%d
if not month_str:
month_str = datetime.now().strftime('%Y-%m')
year, month = int(month_str.split('-')[0]), int(month_str.split('-')[1])
if month == 1:
year -= 1
month = 12
else:
month -= 1
return '{}-{}-01'.format(year, month)
def get_next_month_start(self, month_str=None):
# 获取下一个月的第一天
'''
param: month_str 月份,2021-04
'''
# return: 格式 %Y-%m-%d
if not month_str:
month_str = datetime.now().strftime('%Y-%m')
year, month = int(month_str.split('-')[0]), int(month_str.split('-')[1])
if month == 12:
year += 1
month = 1
else:
month += 1
return '{}-{}-01'.format(year, month)
def get_last_month_end(self, month_str=None):
# 获取上一个月的最后一天
'''
param: month_str 月份,2021-04
'''
# return: 格式 %Y-%m-%d
if not month_str:
month_str = datetime.now().strftime('%Y-%m')
year, month = int(month_str.split('-')[0]), int(month_str.split('-')[1])
if month == 1:
year -= 1
month = 12
else:
month -= 1
end = calendar.monthrange(year, month)[1]
return '{}-{}-{}'.format(year, month, end)
def get_next_month_end(self, month_str=None):
# 获取下一个月的最后一天
'''
param: month_str 月份,2021-04
'''
# return: 格式 %Y-%m-%d
if not month_str:
month_str = datetime.now().strftime('%Y-%m')
year, month = int(month_str.split('-')[0]), int(month_str.split('-')[1])
if month == 12:
year += 1
month = 1
else:
month += 1
end = calendar.monthrange(year, month)[1]
return '{}-{}-{}'.format(year, month, end)
if __name__ == '__main__':
# 获取当前月
print('当前月', DateTimeUtil().get_cur_month())
# 获取上一个月
print('上一个月', DateTimeUtil().get_last_month())
# 获取上两个月
print('上两个月', DateTimeUtil().get_last_month(number=2))
# 获取下一个月
print('下一个月', DateTimeUtil().get_next_month())
# 获取下两个月
print('下两个月', DateTimeUtil().get_next_month(number=2))
# 获取当前月的第一天
print('当前月的第一天', DateTimeUtil().get_cur_month_start())
# 获取当前月的最后一天
print('当前月的最后一天', DateTimeUtil().get_cur_month_end())
# 获取上个月的第一天
print('上个月的第一天', DateTimeUtil().get_last_month_start())
# 获取下个月的第一天
print('下个月的第一天', DateTimeUtil().get_next_month_start())
# 获取上个月的最后一天
print('上个月的最后一天', DateTimeUtil().get_last_month_end())
# 获取下个月的最后一天
print('下个月的最后一天', DateTimeUtil().get_next_month_end())3.3:异常日期类型&不规则日期类型 转换为指定日期类型
str1='2019-01-08'
str2='2019-1-8 00:00:00'
str3='2019年1月8日'
str4='2019年01月08日'
str5='2019/1/8'
str6='2019/01/08 00:00'
str7='2019-1-8'
def strToDate(str_date):
str_date=str_date.strip()
year=1900
month=1
day=1
if(len(str_date)>11):
str_date=str_date[:11]
if(str_date.find('-')>0):
year=str_date[:4]
if(year.isdigit()):
year=int(year)
else:
year=0
month=str_date[5:str_date.rfind('-')]
if(month.isdigit()):
month=int(month)
else:
month=0
if(str_date.find(' ')==-1):
day=str_date[str_date.rfind('-')+1:]
else:
day=str_date[str_date.rfind('-')+1:str_date.find(' ')]
if(day.isdigit()):
day=int(day)
else:
day=0
elif(str_date.find('年')>0):
year=str_date[:4]
if(year.isdigit()):
year=int(year)
else:
year=0
month=str_date[5:str_date.rfind('月')]
if(month.isdigit()):
month=int(month)
else:
month=0
day=str_date[str_date.rfind('月')+1:str_date.rfind('日')]
if(day.isdigit()):
day=int(day)
else:
day=0
elif(str_date.find('/')>0):
year=str_date[:4]
if(year.isdigit()):
year=int(year)
else:
year=0
month=str_date[5:str_date.rfind('/')]
if(month.isdigit()):
month=int(month)
else:
month=0
if(str_date.find(' ')==-1):
day=str_date[str_date.rfind('/')+1:]
else:
day=str_date[str_date.rfind('/')+1:str_date.find(' ')]
if(day.isdigit()):
day=int(day)
else:
day=0
else:
year=1900
month=1
day=1
if month<10:
month='0'+str(month)
if day<10:
day='0'+str(day)
return '%s-%s-%s' % (year,month,day)
if __name__ == '__main__':
print(strToDate('2017/12/22 a'))
print(strToDate('2017/12/22'))
print(strToDate('2017-12-22 a'))
print(strToDate('2017-12-22 -- '))
print(strToDate(' 2017-12-22'))
print(strToDate('2017年12月22日 a'))
print(strToDate('2017年12月22日'))
print(strToDate('2017年12月22日 '))3.4:一致性检验
def feature_Percentage(data_frame:pd.DataFrame,percentage:float,col_remain:list)->pd.DataFrame:
set1 = set()
feature_more_data = []
feature_remain = []
for col in data_frame.columns:
res = data_frame[col].value_counts()
for value in res.values:
if value/data_frame.shape[0] > percentage:
set1.add(col)
if(isinstance(data_frame,pd.DataFrame)):
feature_more_data = list(set1)
for col in data_frame.columns:
if col not in feature_more_data:
if col not in col_remain:
feature_remain.append(col)
feature_remain.extend(col_remain)
return data_frame[feature_remain]
else:
return 0
return data_frame[feature_remain]3.5:异常值过滤
def outlier_processing(df:pd.DataFrame, col:str)->pd.DataFrame:
"""
离群值处理
:param df:
:param col:
:return:
"""
s = df[col]
oneQuoter = s.quantile(0.25)
threeQuote = s.quantile(0.75)
irq = threeQuote-oneQuoter
min = oneQuoter-1.5*irq
max = threeQuote+1.5*irq
df = df[df[col] <= max]
df = df[df[col] >= min]
return df3.6:行缺失&列缺失信息
过滤掉指定字段中,缺失值占比超过指定比例的字段
# 统计列缺失
def analyseColLackPer(data:pd.DataFrame,number:float)->pd.DataFrame:
col_percent = data.apply(lambda x : np.sum(x.isna())/len(data))
col_lack_list = list(col_percent[col_percent > number].index)
col_remian = [col for col in data.columns if col not in col_lack_list]
return data[col_remian]
data = analyseColLackPer(data,0.6)
过滤掉指定行记录中,缺失值占比超过指定比例的字段
# 统计行缺失
def analyseRowLackPer(data:pd.DataFrame,percentage:float)->pd.DataFrame:
row_percent = data.isnull().sum(axis = 1)
row_index = []
for number,value in enumerate(row_percent):
percent = value/data.shape[1]
if(percent > percentage):
row_index.append(number)
data = data.drop(index = row_index)
return data
data = analyseRowLackPer(data,0.5)