金仓数据库KingbaseES主备和读写分离集群使用手册(概述)
目录
2.1. 主要特征 ¶
2.2. 基本概念 ¶
2.2.1. 数据库模式 ¶
2.2.2. 数据库状态 ¶
2.2.3. WAL(REDO日志) ¶
2.2.4. LSN介绍 ¶
2.2.5. 归档介绍 ¶
2.2.6. 脑裂 ¶
2.2.7. 数据节点 ¶
2.2.8. witness节点 ¶
2.2.9. 命令行工具 ¶
2.2.10. 守护进程 ¶
2.2.11. 远程通信工具 ¶
2.3. 主备集群 ¶
2.3.1. 主要功能 ¶
2.3.2. 主备的同步流程 ¶
2.4. 读写分离集群 ¶
2.4.1. 实现原理 ¶
2.4.2. 事务一致性 ¶
金仓读写分离集群是基于硬件,软件系统不可靠,一定会有故障的假设设计的,是基于单台计算机无足够能力处理大量数据设计的。
只要数据副本数量大于一,无论是硬件的升级、还是软件的迁移、单机的宕机或软件错误都无需停止对外服务,极大的保证系统的正常运行,并且降低了系统管理员和运维人员的工作量。
2.1. 主要特征 ¶
1)丰富的同步模式
KingbaseES高可用集群可根据业务数据保护级别灵活支持多种数据复制模式。比如:实时(sync)模式、异步(async)模式、优选同步(quorum)模式。
2)高效切换
KingbaseES高可用集群支持便捷高效的主备集群切换,切换过程仅需秒级完成。对计划内维护等切换需求提供了高效灵活的实施方法。
3)全面数据保护
KingbaseES高可用集群内的任意一个备库均为一个完整的冗余数据库,且可以同时配置多个备库,为数据安全提供全方位的保护。
4)平衡资源负载
KingbaseES高可用集群内的任意一个备库均可配置为读访问,支持用户访问备库,执行查询、报表统计分析、作为ETL数据源进行数据抽取,减轻主库的系统负载,提升资源利用率。
5)故障转移
当主库(计划外)发生故障时,KingbaseES高可用集群支持自动切换,实现了库级和中心级的自动容灾功能。
6)强大的业务连续性保障机制
KingbaseES高可用集群引入VIP设计,VIP将始终运行于主库服务器,当主库或主库所在服务器发生故障,VIP将自动随数据库切换而漂移(至新主库服务器)。极大地保障了业务系统的连续性。
7)多种自动恢复模式
KingbaseES高可用集群可以配置不同的自动恢复模式来处理故障数据库,满足用户不同层次的需求,包括:关闭自动恢复功能,自动恢复备数据库,自动恢复主数据。
2.2. 基本概念 ¶
2.2.1. 数据库模式 ¶
KingbaseES只有两种数据库模式:主库primary或备库standby。
主库primary
提供正常的数据库读写服务,能正常生成WAL日志,如果有备库standby连接此数据库,还能将本地生产WAL日志传输给备库。
备库standby
提供只读服务,不能生成WAL日志,可以连接某一个主库primary,从主库接收WAL日志并重做。
可以通过SQL语句切换为primary。
SELECT sys_promote();
主库primary不能切换为备库。
2.2.2. 数据库状态 ¶
KingbaseES数据库有以下几种状态:
DB_STARTUP
数据库刚启动时的状态,此时数据库正在重放WAL,用户不可连接。
DB_SHUTDOWNED
主数据库正常关闭后的状态。
DB_SHUTDOWNED_IN_RECOVERY
备数据库正常关闭后的状态。
DB_SHUTDOWNING
数据库正在关闭过程中的状态。
DB_IN_CRASH_RECOVERY
主数据库崩溃(意外退出)后刚启动时的状态。
DB_IN_ARCHIVE_RECOVERY
备数据库正常运行时的状态,或者主数据库PITR时的状态。
DB_IN_PRODUCTION
主数据库正常运行时的状态。
2.2.3. WAL(REDO日志) ¶
REDO日志在KingbaseES数据库系统中一般指WAL(Write-Ahead Logging,预写式日志),其是保证数据完整性的标准解决方案——任何对数据页面的修改都必须先记录WAL并持久化到存储上。
WAL中按顺序记录了所有对数据页面的修改,每一条修改记录称为一条Record。一个事务包含至少一条SQL语句,而一条SQL会记录一条或多条record。事务提交时只需要保证将WAL从内存写入磁盘就可以完成,而不需要保证所有更改的数据文件都写入磁盘。WAL是按顺序写入文件,而数据文件的更改大部分是随机位置,所以WAL写入磁盘的成本更低,这种方案减少了事务提交时磁盘写入的次数,提高了事务并发性能。
当数据库系统发生崩溃后,可以读取磁盘中的WAL并按顺序重放日志来恢复数据文件,保证了数据的可靠性。
WAL的文件组织形式是按wal_segment_size进行划分的,默认情况下wal_segment_size为16MB,即WAL是由一系列16MB大小的文件组成的。每个文件称为WAL段文件,段文件的名称是24字符的十六进制字符串,分别是8字符时间线、16字符段文件号,例如:000000010000000A0000002C。
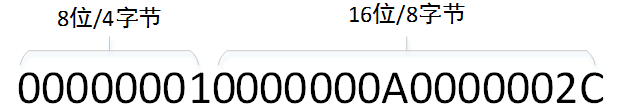
2.2.4. LSN介绍 ¶
数据库每产生一条Record都会按LSN大小顺序追加到WAL文件中,插入位置就是LSN(Log Sequence Number)。LSN是uint64类型数值,随着record单调递增。LSN对外的显示形式是"%08X/%08X",范围为0/0到FFFFFFFF/FFFFFFFF。
每一条Record都有一个LSN值表示其起始字节位置,Record的结束位置就是下一个Record的起始位置,那么相邻两条Record的LSN的差值就是前一条Record的字节长度。
2.2.5. 归档介绍 ¶
WAL段文件存储在数据目录的sys_wal下,开启归档功能后,每完成一个WAL段文件,数据库会执行archive_command将该文件进行归档。可以通过配置archive_command将WAL段文件拷贝到其他目录或其他设备上。
每当一个WAL段文件完成后,会在sys_wal/archive_status下生成一个同名的ready空文件,例如:000000010000000A0000002C.ready。开启归档后,KingbaseES数据库会有一个archiver进程专门负责WAL段文件的归档。该进程会不断扫描sys_wal/archive_status目录,寻找ready文件,当发现ready文件后,尝试执行archive_command归档ready文件对于的WAL段文件。
archive_command可以配置为任意命令,KingbaseES推荐配置命令格式为:test ! -f /mnt/server/archivedir/%f && cp %p
/mnt/server/archivedir/%f。其中,%p和%f由归档进程archiver在执行归档命令前自动替换,%p表示需要归档的文件路径(包括文件名),%f表示文件名称。
完成archive_command后,归档进程archiver会将ready文件重命名为done文件,表示归档完成,例如:000000010000000A0000002C.done。当然archive_command也可能执行失败,表示归档失败,失败后归档进程会不断重试,直到成功为止。
开启归档后,如果WAL段文件未被归档,该文件不会被KingbaseES回收。
2.2.6. 脑裂 ¶
在主备集群或读写分离集群中,都应该有且只有一个primary节点,其他节点都为standby。如果主备集群或读写分离集群中有多个primary节点,此场景称为脑裂。
脑裂问题会导致数据分歧,无法保证数据一致性。
2.2.7. 数据节点 ¶
数据节点指集群中有primary或standby数据库的节点,应用访问的是数据节点。
2.2.8. witness节点 ¶
witness节点,也称为仲裁节点、观察节点,应用不访问此节点,此节点主要作为集群故障自动切换时的仲裁。
2.2.9. 命令行工具 ¶
管理、控制集群的命令行工具主要有repmgr和kbha,这两个命令行工具提供了大量丰富的能力用来维护、管理集群。
详细介绍请参考 2111repmgr 和 kbha 章节。
2.2.10. 守护进程 ¶
集群每个节点都存在两个守护进程。
数据库的守护进程为repmgrd,主要负责数据库的状态检查和故障处理,包括:故障自动切换、故障自动恢复等。而另一个守护进程kbha主要负责repmgrd进程的状态监控,以及一些环境的检查,包括:信任网关检查、存储检测等。
2.2.11. 远程通信工具 ¶
集群由多个节点组成,分布在不同的服务器上。除了数据库之间利用TCP进行数据同步,集群的守护进程以及一些命令行工具还需要利用远程通信工具来跨节点执行命令。
详细介绍请参考 远程通信工具 章节。
2.3. 主备集群 ¶
主备集群是由主库、备库和守护进程组成的集群,主库提供数据库读写服务,备库和主库通过流复制同步数据作为备份,守护进程检查各个数据库状态以及环境状态,当主库故障后可以进行故障转移将备库提升为主库继续对外提供服务,确保主备集群持续提供服务。
2.3.1. 主要功能 ¶
流复制同步数据
应用连接主库更改数据,主库生成WAL日志并写入磁盘,同时主库的walsender进程实时从存储读取WAL日志并通过数据流的方式发送给备库,备库接收到WAL日志流后写入存储并REDO。通过同步WAL日志的方式,主备数据达到一致。
数据库状态监控
守护进程会实时监控主备集群的状态,包括主库、备库状态、流复制状态等。发生任何故障时,守护进程实施合适的措施以保证主备集群能够持续的对外提供服务。
VIP管理
VIP又叫浮动IP、虚拟IP,集群在发生故障转移、主备切换等事件时,VIP始终跟随主库。应用程序使用VIP访问数据库,可以尽量减少某些故障对应用的影响。
故障自动转移
守护进程监控到主库故障后,自动选择一个备库将其提升为主库,继续对外提供服务。
故障自动恢复
守护进程监控到备库故障后,不影响主库对外提供服务,同时尝试将备库自动恢复正常。
2.3.2. 主备的同步流程 ¶
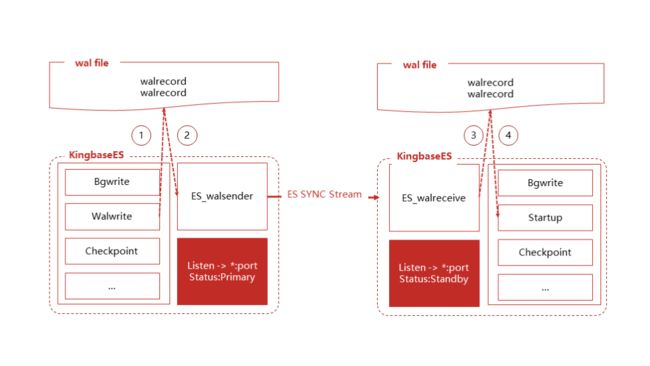
流程说明
① 数据库WalWriter把产生的WAL日志写入磁盘;
② WAL日志写入磁盘后,由walsender进程将新增的日志读取出来并通过流的形式发送给备库;
③ 备库walreceiver进程将接收到的WAL日志写入本地WAL段文件;
④ 备库startup进程读取WAL日志进行重放,完成数据同步。
实时主备
实时主备是指主备数据最终一致,发生任何故障都不会丢失数据。从上图和上述流程看,要达到实时同步,需要主库等待WAL日志同步到③或④的流程,主库才能继续。实时主备为了保证数据最终一致,牺牲了部分性能。
异步主备
异步主备不能保证主备数据最终一致,一旦主库发生故障,备库可能没有同步完成主库已经写入的WAL日志,导致丢失部分数据。从上图和上述流程看,异步主备情况下,主库只需要WAL日志同步到流程①或②就可以继续。那么异步主备比实时主库拥有更好的性能。
2.4. 读写分离集群 ¶
读写分离集群在主备集群基础上,实现了备库可读、读写分离、负载均衡等新特性,简称KingbaseRWC。
一般情况下,应用系统中查询等只读操作远多于写入操作,KingbaseRWC为了保证集群在高并发、高压力下性能不下降,需要借助读写分离将读操作分发到备库来分担业务压力,从而减轻主库压力,提升集群的整体吞吐量。
读写分离集群通过配置JDBC来实现。
2.4.1. 实现原理 ¶
JDBC的配置项:
| JDBC配置集群节点信息 |
节点地址 |
建议连接字符串写主节点的地址,备节点地址 通过SLAVE_ADD和SLAVE_PORT进行配置。 |
| 节点名称 |
节点名称通过nodeList指定,节点名称可通过 repmgr cluster show 查询。开启读写分离时 必须配置nodeList,并且节点名称顺序必须和 节点地址配置的顺序完全一致。各节点名称间 逗号分隔,如:nodeList=node1,node2,node3。 |
|
| 读写分离开启 和主机负载 |
#打开读写分离功能 USEDISPATCH=true #主机负载率,备机之间轮询评分 HOSTLOADRATE=33 |
JDBC的配置方式:
| 连接串配置 |
只用连接串开启 JDBC读写分离 一主两备 |
jdbc:kingbase8://192.168.0.100:54321/test?USE DISPATCH=true&SLAVE_ADD=192.168.0.101,192.168.0.102 &SLAVE_PORT=54321,54321&nodeList=node1,node2,node3 |
| 连接串+配置文件 |
连接串+配置文件 开启JDBC读写分 离一主两备 |
jdbc:kingbase8://192.168.0.100:54321/test?Con figurePath=jdbc.conf |
| jdbc.conf配置文件 USEDISPATCH=true SLAVE_ADD=192.168.0.101,192.168.0.102 SLAVE_PORT=54321,54321 nodeList=node1,node2,node3 |
另请参阅
其它更多参数和解释参见 《KingbaseES客户端编程接口指南-JDBC》 手册中的“JDBC连接属性” 章节。
2.4.2. 事务一致性 ¶
| 事务1 |
事务2 |
|---|---|
| transaction1: update Test set C1=3 where C2=0; commit; update Test set C1=3 where C2=0; |
transaction2: Rs = select C1 from Test where C2=0; Fetch C1 from Rs INTO var_x; insert into TX values(var_x); commit; |
tx1在主库执行,tx2的select会先在备库执行,insert 在主库执行,并且insert语句插入的值,是之前查询结果集中获取。
在数据库异步模式下,备库事务会有一定延迟性,可能会插入一个历史值,数据库不做保证,因此不建议在异步模式中使用一个事务内既有读又有写语句。
在同步模式(remote_apply)下:
1) tx2执行select时,tx1的commit还没执行;查询结果是var_X=1;
2) tx2执行select时,tx1的commit已经执行完成。查询结果都是tx1更新表之后的值,var_x=2;
3) tx2执行select时,tx1正在执行commit,此时tx2的查询结果,与两个语句在系统内部的执行顺序相关,无论返回1或者2,都符合读事务隔离级。