hadoop HA与Hbase HA的详细安装与配置(从0开始)
文章目录
- 前言
- 一、hadoop ha与hbase ha是什么?
- 二、使用步骤
-
- 1.前提环境
- 2.节点准备(master,master2,slave1)
- 3.操作master节点
- 4.zookeeper安装(三节点)
- 5.配置环境配件(三节点)
- 6.配置jdk(三节点)
- 7.安装Hadoop(先在master1)
- 8.安装Hbase(先在master1)
- 9.启动hbase ha
- 10.Web页面
- 总结
前言
一、hadoop ha与hbase ha是什么?
概述:是一个高 可靠 性、高性能、面向列、可伸缩的 分布式存储系统 ,利用HBase技术可在廉价PC Server上搭建起大规模 结构 化 存储 集群。
二、使用步骤
1.前提环境
- virtualBoxubuntu20.04
hadoop2.10.1
jdk1.8
zookeeper3.5.10
hbase2.2.2
2.节点准备(master,master2,slave1)
2.1 安装一个即可,后再进行复制就行(注意要修改ip)
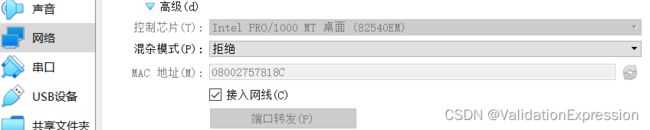
2.2 IP修改位置(不然会出现ip冲突)
3.操作master节点
3.1 对master节点创建新用户hadoop
Sudo useradd -m hadoop -s /bin/bash
Sudo passwd hadoop
Sudo adduser hadoop sudo //将用户加入到sudo组
3.2 切换用户hadoop
3.3 更新apt和vim
Sudo apt-get update
Sudo apt-get install vim
3.4 更新查询ip工具
Sudo apt-get install net-tools
3.5 启动各个节点,并对修改主机名。
Sudo vim /etc/hostname
此时三个节点的主机名分别为master1, master2, slave1
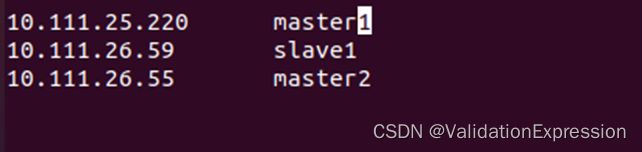
3.6 三节点建立连接ping --查看ip
ifconfig
Sudo vim /etc/hosts
三个节点都如下
3.7 安装ssh和配置ssh免密登录(三个节点)
Sudo apt-get install openssh-server
切换目录
Cd ~/.ssh
Ssh-keygen -t rsa //生成密钥
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys //将密钥加入到authorized_keys
切换节点
创建ssh用于保存密钥—加入密钥(进入master2,slave1)
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys //加入密钥
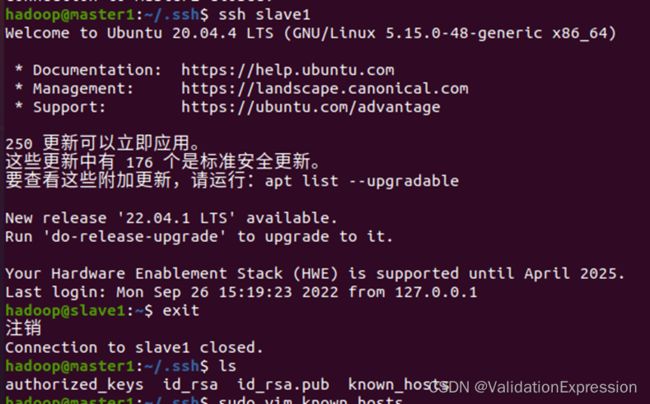
master1 ,master2之间可以互相登录
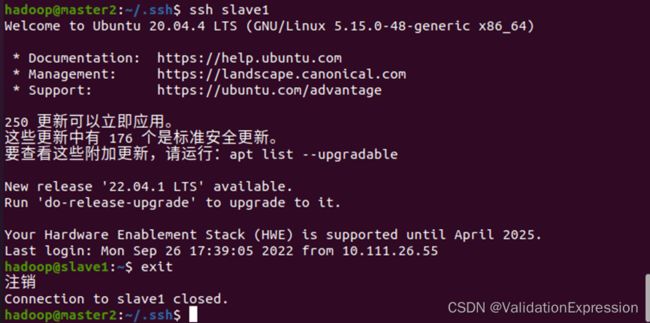
master1可以登录到slave1
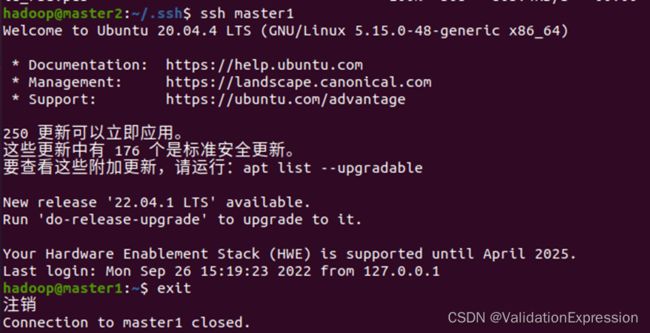
master2可以登录到slave1
master1
Master2
4.zookeeper安装(三节点)
4.1 master1节点
解压: sudo tar -zxvf apache-zookeeper-3.5.10-bin.tar.gz -C /usr/local
赋予权限:sudo chown -R hadoop ./apache-zookeeper-3.5.10-bin
修改文件名:sudo mv apache-zookeeper-3.5.10-bin zookeeper
![]()
4.2 配置文件
修改文件名


根据上述的dtaDir位置,创建data文件夹-并创建myid文件—写入1
目录/usr/loccal/zookeeper/data
sudo vim myid
4.3 将master1节点的zookeeper內容打包发送到master2, slave1节点
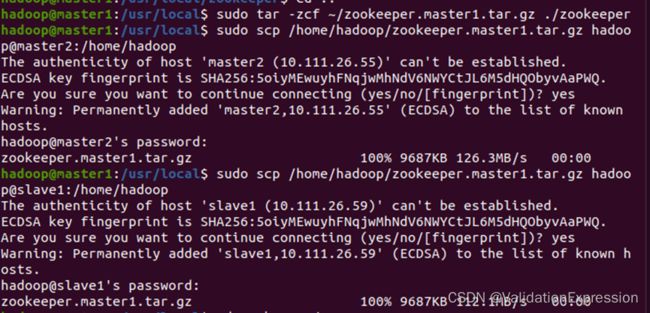
Master2,slave1相同(进行解压)
 Sudo chown -R hadoop ./data 修改权限
Sudo chown -R hadoop ./data 修改权限

修改/usr/local/zookeeper/data/myid文件的內容
Sudo vim myid
Master2对应的是2
Slave1对应的是3
5.配置环境配件(三节点)
一次性把环境变量配置完全
sudo vim ~/.bashrc
# jdk
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_341
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
# hadoop
export HADOOP_HOME=/usr/local/hadoop
export PATH=/usr/local/hadoop/bin:$PATH
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lin/native
export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
# hbase
export HBASE_HOME=/usr/local/hbase
export PATH=${HBASE_HOME}/bin:$PATH
# zookeeper
export ZOOKEEPER_INSTALL=/usr/local/zookeeper/
export PATH=$PATH:$ZOOKEEPER_INSTALL/bin
最后要进行生效
source ~/.bashrc
6.配置jdk(三节点)
我将jdk安装在/usr/lib/jvm
创建目录sudo mkdir jvm
解压:sudo tar -zxvf jdk-8u341-linux-x64.tar.gz -C /usr/lib/jvm

检验:java -version

在此可以先验证zookeeper是否安装成功
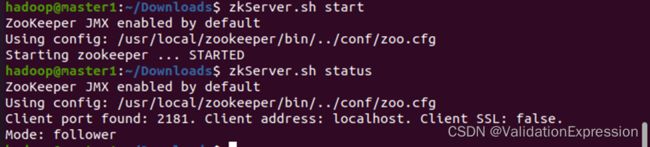
启动zookeeper(注意启动顺序master1, master2, slave1)
zkServer.sh start
master1
Master2

Slave1
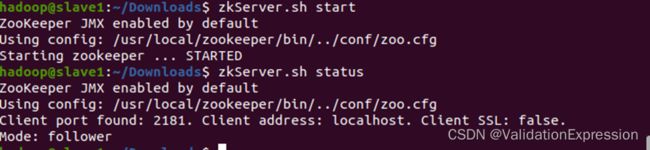
7.安装Hadoop(先在master1)
解压:
sudo tar -zxf~/download/hadoop-2.10.1.tar.gz -C /usr/lcoal //将Hadoop解压到/usr/lcoal
cd /usr/local
sudo mv ./hadoop-2.10.1 ./hadoop //修改文件名为hadoop
sudo chown -R hadoop ./hadoop //修改文件权限
7.1 查看版本
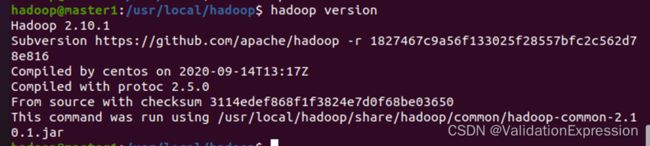
7.2 配置文件
sudo vim core-site.xml
sudo vim hdfs-site.xml
sudo vim mapred-site.xml
sudo vim yarn-site.xml

Sudo vim slaves

7.3 对hadoop进行打包发送到master2, slave1
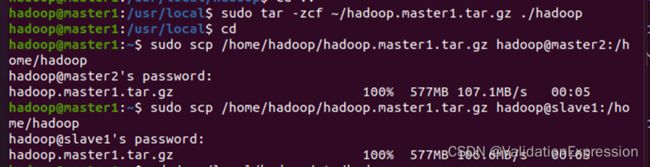
Master2
![]()
Slave1(同master2一样解压)

8.安装Hbase(先在master1)
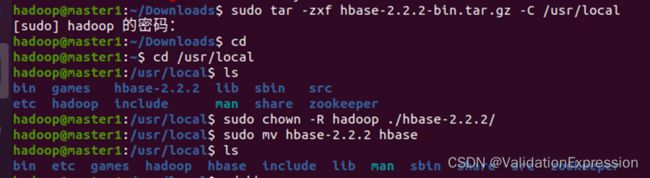
8.1 解压sudo tar -zxf hbase-2.2.2-bin.tar.gz -C /usr/local
修改名字,权限
8.2 将hadoop中的hdfs-site.xml复制到HBase的conf路径下
sudo cp /usr/local/hadoop/etc/hadoop/hdfs-site.xml /usr/local/hbase/conf/

配置hbase-env.sh
//目录/usr/local/hbase/conf
//进入sudo vim hbase-env.sh
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_341
export HBASE_HOME=/usr/local/hbase
export HADOOP_HOME=/usr/local/hadoop
export HBASE_MANAGES_ZK=false
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:${HADOOP_HOME}/lib/native:/usr/local/lib/
export HBASE_LIBRARY_PATH=${HBASE_LIBRARY_PATH}:/usr/local/lib/:${HADOOP_HOME}/lib/native/
配置hbase-site.xml
<property>
<name>hbase.rootdir</name>
<!--mucluster集群名称,与hadoop中的配置保持一致-->
<value>hdfs://mtcluster/user/hbase</value>
</property>
<property>
<name>zookeeper.znode.parent</name>
<value>/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/home/hadoop/data01/hbase/hbase_tmp</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hadoop/data01/hbase/zookeeper_data</value>
</property>
<property>
<name>hbase.master.port</name>
<value>61000</value>
</property>
<!--hbase的web页面-->
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master1,master2,slave</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
配置 regionservers
sudo vim regionservers (添加master1, master2, slave1)
创建backup-masters (添加master2) – conf目录
sudo vim backup-masters

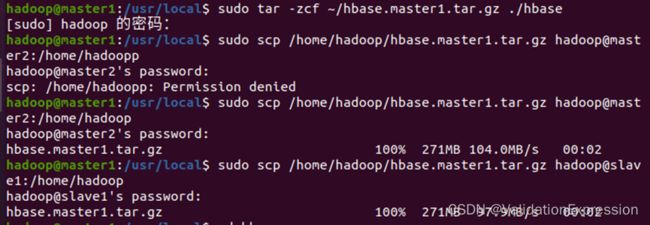
8.3 将hbase的所有文件打包发送到master2, slave1
9.启动hbase ha
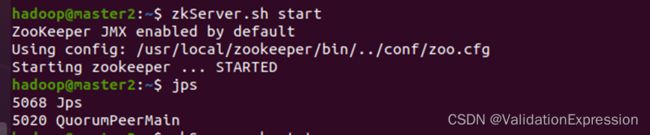
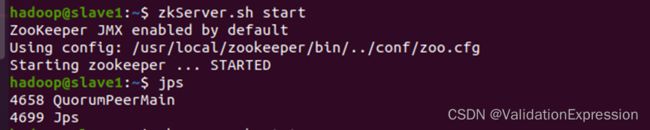
9.1 启动zookeeper进程(三个节点注意顺序master1, master2, slave1)
zkServer.sh start
zkServer.sh status //查看状态
master1

master2
slave1
 查看zookeeper 状态
查看zookeeper 状态
zkServer.sh status
master1

Master2

Slave1

(2)启动journalnode进程(三个节点)
hdfs --daemon start journalnode
master1
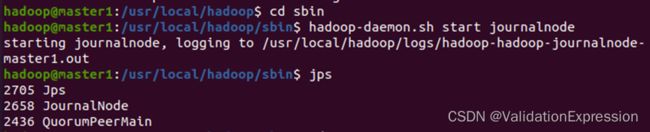
Master2

Slave1

(3)初始化namenode(主节点master1)
hdfs -namenode -format
 (4)格式化ZKFC(主节点master1)
(4)格式化ZKFC(主节点master1)
hdfs zkfc -formatZK
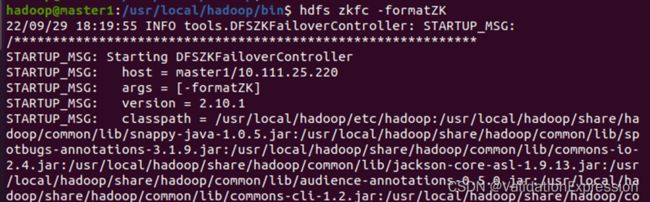
(5)复制master1元数据到master2节点
scp -r /usr/local/hadoop/tmp/data01/nn hadoop@master2:/usr/local/hadoop/tmp/data01

(6)master2节点启动备用名称节点
hadoop-daemon.sh start namenode

(7)启动DFSZKFailoverController进程(master1, master2)
hdfs --daemon start zkfc
master1 (这个地方出现namenode是因为我在前面启动了一下)
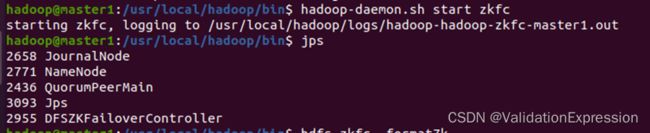
Master2
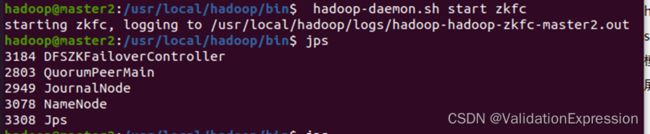
(8)启动hadoop(master1节点)
Start-dfs.sh
Start-yarn.sh
Master1
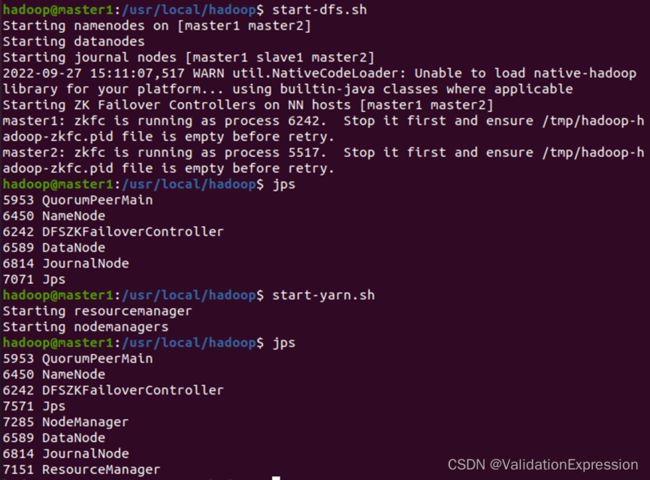
Master2
 Slave1
Slave1

10.Web页面
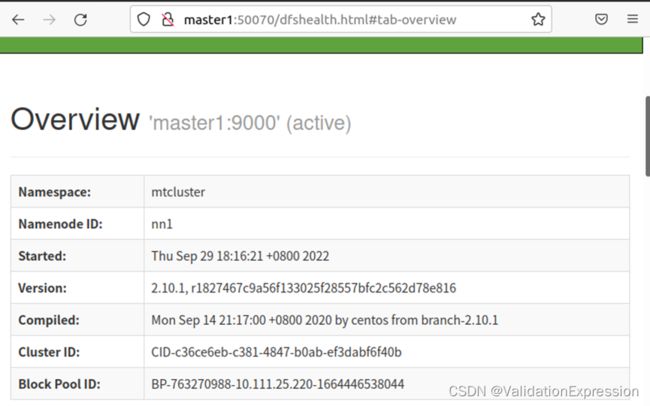
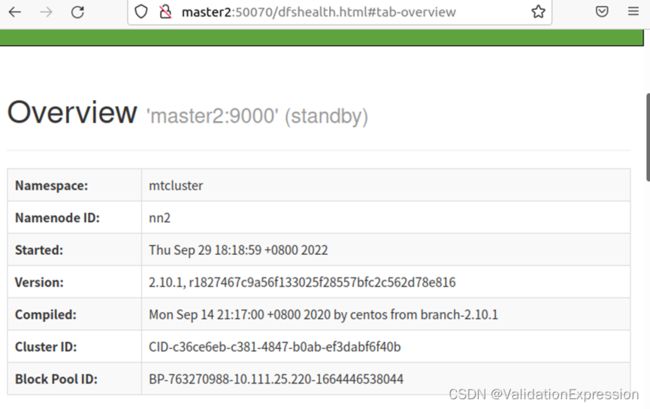
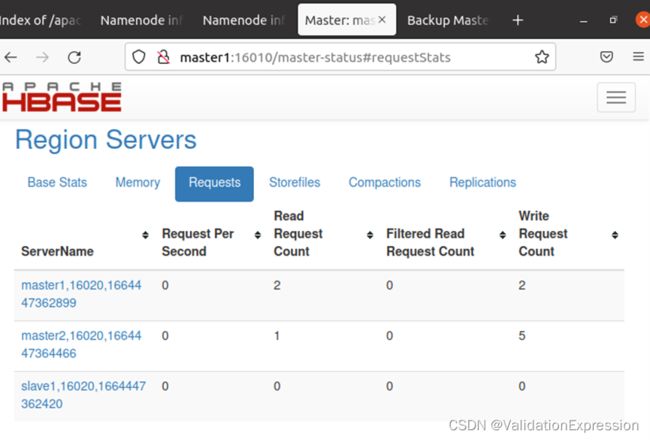
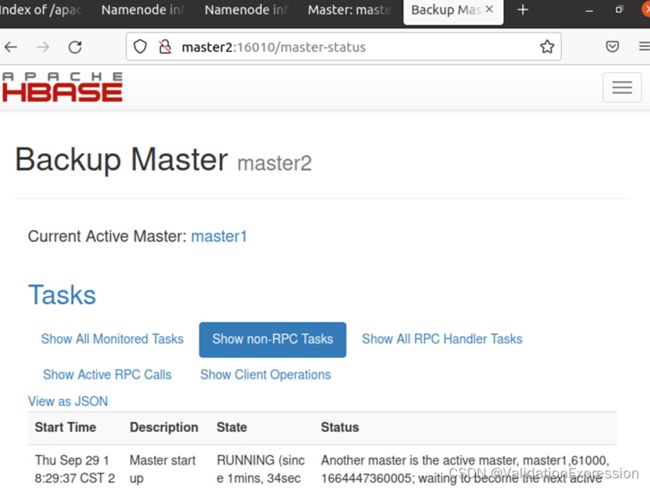
总结
再一次配置hbase ha 从中收获颇多,也更加熟练。配置hbase ha一定要注意版本匹配问题,当时对于这个原因找了好久才发现对此我在这里警告—版本匹配,版本匹配,版本匹配。
在这希望大家也可以配置成功。
如果可以希望可以关注博主。