小滴课堂-学习笔记:手把手剖析并发底层原理和最佳实践
 愿景:"让编程不再难学,让技术与生活更加有趣"
愿景:"让编程不再难学,让技术与生活更加有趣"
更多架构课程请访问 xdclass.net
目录
第1集 并发编程核心底层AQS你知道不
第2集 源码剖析并发编程ReentrantLock实现原理
第3集 你可以说清ReentrantLock和synchronized的差别不
第4集 读写锁ReentrantReadWriteLock你是否知道
第5集 阻塞队列BlockingQueue是否知道
第6集 并发队列ConcurrentLinkedQueue是否掌握
第7集 说说你认为的并发编程最佳实践
第8集 线程池里面的坑你踩过吗?
第9集 ThreadPoolExecutor核心参数是否掌握
干货文档
第1集 并发编程核心底层AQS你知道不
简介: 常见的并发编程AQS考查
-
考点:考查是否知道并发编程AQS
-
难度:【 ** ** * 】
-
知道AQS吗?能否介绍下,它的核心思想是什么
AQS的全称为(AbstractQueuedSynchronizer),这个类在java.util.concurrent.locks包下面。它是一个Java提高的底层同步工具类,比如CountDownLatch、ReentrantLock,Semaphore,ReentrantReadWriteLock,SynchronousQueue,FutureTask等等皆是基于AQS的 只要搞懂了AQS,那么J.U.C中绝大部分的api都能轻松掌握 简单来说:是用一个int类型的变量表示同步状态,并提供了一系列的CAS操作来管理这个同步状态对象 一个是 state(用于计数器,类似gc的回收计数器) 一个是线程标记(当前线程是谁加锁的), 一个是阻塞队列(用于存放其他未拿到锁的线程) 例子:线程A调用了lock()方法,通过CAS将state赋值为1,然后将该锁标记为线程A加锁。如果线程A还未释放锁时,线程B来请求,会查询锁标记的状态,因为当前的锁标记为 线程A,线程B未能匹配上,所以线程B会加入阻塞队列,直到线程A触发了 unlock() 方法,这时线程B才有机会去拿到锁,但是不一定肯定拿到 acquire(int arg) 源码讲解,好比加锁lock操作 tryAcquire()尝试直接去获取资源,如果成功则直接返回,AQS里面未实现但没有定义成abstract,因为独占模式下只用实现tryAcquire-tryRelease,而共享模式下只用实现tryAcquireShared-tryReleaseShared,类似设计模式里面的适配器模式 addWaiter() 根据不同模式将线程加入等待队列的尾部,有Node.EXCLUSIVE互斥模式、Node.SHARED共享模式;如果队列不为空,则以通过compareAndSetTail方法以CAS将当前线程节点加入到等待队列的末尾。否则通过enq(node)方法初始化一个等待队列 acquireQueued()使线程在等待队列中获取资源,一直获取到资源后才返回,如果在等待过程中被中断,则返回true,否则返回false release(int arg)源码讲解 好比解锁unlock 独占模式下线程释放指定量的资源,里面是根据tryRelease()的返回值来判断该线程是否已经完成释放掉资源了;在自义定同步器在实现时,如果已经彻底释放资源(state=0),要返回true,否则返回false unparkSuccessor方法用于唤醒等待队列中下一个线程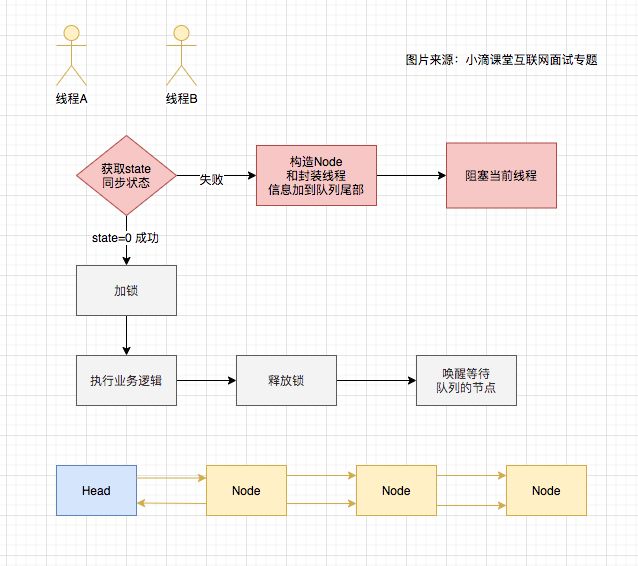
-
你知道的AQS有几种同步方式,实现同步器一般要覆盖哪些方法
独占式: 比如ReentrantLock 共享式:比如Semaphore 存在组合:组合式的如ReentrantReadWriteLock,AQS为使用提供了底层支撑,使用者可以自由组装实现 1. boolean tryAcquire(int arg) 2. boolean tryRelease(int arg) 3. int tryAcquireShared(int arg) 4. boolean tryReleaseShared(int arg) 5. boolean isHeldExclusively() 不需要全部实现,根据获取的锁的种类可以选择实现不同的方法,比如 实现支持独占锁的同步器应该实现tryAcquire、 tryRelease、isHeldExclusively 实现支持共享获取的同步器应该实现tryAcquireShared、tryReleaseShared、isHeldExclusively 注意:线程获取锁成功后直接返回,不会进入等待队列里面,只有失败的时候才会 //线程获取锁成功后 直接返回,不会进入等待队列里面,只有失败的时候才会 public final void acquire(int arg) { if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg)) selfInterrupt(); } ========= //获取失败则将当前线程封装为Node.EXCLUSIVE的Node节点插入AQS阻塞队列的尾部 final boolean acquireQueued(final Node node, int arg) { boolean failed = true; try { boolean interrupted = false; for (;;) { final Node p = node.predecessor(); if (p == head && tryAcquire(arg)) { setHead(node); p.next = null; // help GC failed = false; return interrupted; } if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt()) interrupted = true; } } finally { if (failed) cancelAcquire(node); } } ================== //调用LockSupport.park(this)方式阻塞自己 private final boolean parkAndCheckInterrupt() { LockSupport.park(this); return Thread.interrupted(); }
第2集 源码剖析并发编程ReentrantLock实现原理
简介: 源码解析ReentrantLock实现原理
- 考点:考查是否知道ReentrantLock底层实现 (如果对上集AQS不熟悉,可以看这集后再去回顾AQS)
- 难度:【 ** ** * 】
- java里面的公平锁和非公平锁你知道多少,有没看过ReentrantLock源码?
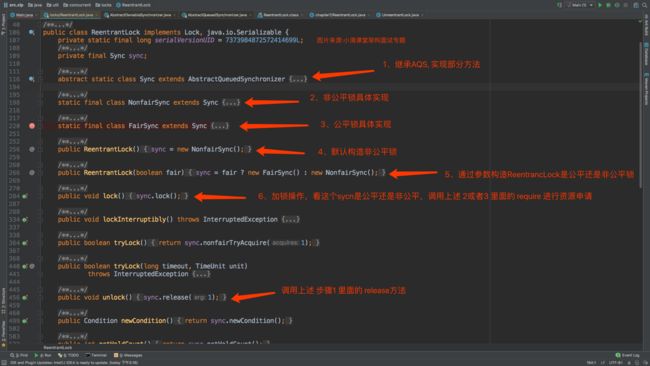
- 公平锁和非公平锁核心区别
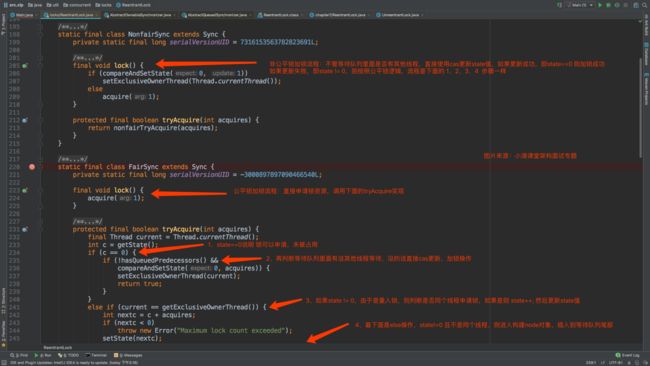
第3集 你可以说清ReentrantLock和synchronized的差别不
简介: 源码解析ReentrantLock实现原理
- 考点:考查ReentrantLock和synchronized的掌握情况
- 难度:【 ** ** 】
-
ReentrantLock和synchronized使用的场景是什么,实现机制有什么不同
ReentrantLock和synchronized都是独占锁 synchronized: 1、是悲观锁会引起其他线程阻塞,java内置关键字, 2、无法判断是否获取锁的状态,锁可重入、不可中断、只能是非公平 3、加锁解锁的过程是隐式的,用户不用手动操作,优点是操作简单但显得不够灵活 4、一般并发场景使用足够、可以放在被递归执行的方法上,且不用担心线程最后能否正确释放锁 5、synchronized操作的应该是对象头中mark word,参考原先原理图片 ReentrantLock: 1、是个Lock接口的实现类,是悲观锁, 2、可以判断是否获取到锁,可重入、可判断、可公平可不公平 3、需要手动加锁和解锁,且 解锁的操作尽量要放在finally代码块中,保证线程正确释放锁 4、在复杂的并发场景中使用在重入时要却确保重复获取锁的次数必须和重复释放锁的次数一样,否则可能导致 其他线程无法获得该锁。 5、创建的时候通过传进参数true创建公平锁,如果传入的是false或没传参数则创建的是非公平锁 6、底层不同是AQS的state和FIFO队列来控制加锁
第4集 读写锁ReentrantReadWriteLock你是否知道
简介: 讲解ReentrantReadWriteLock读写锁的掌握情况
- 考点:考查ReentrantReadWriteLock读写锁的掌握情况
- 难度:【 ** ** * 】
-
知道ReentrantReadWriteLock吗?和ReentrantLock有啥不同?
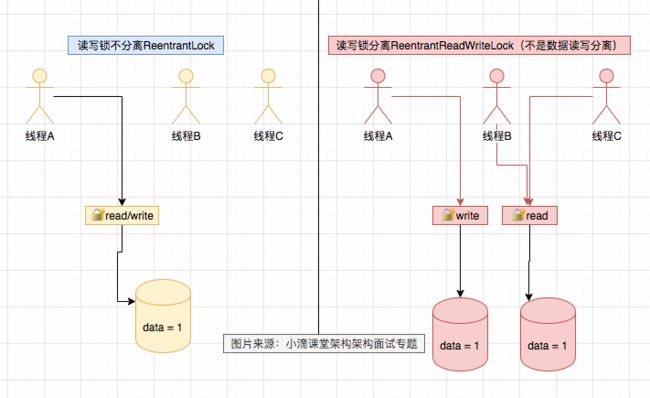
ReentrantReadWriteLock 1、读写锁接口ReadWriteLock接口的一个具体实现,实现了读写锁的分离, 2、支持公平和非公平,底层也是基于AQS实现 3、允许从写锁降级为读锁 流程:先获取写锁,然后获取读锁,最后释放写锁;但不能从读锁升级到写锁 4、重入:读锁后还可以获取读锁;获取了写锁之后既可以再次获取写锁又可以获取读锁 核心:读锁是共享的,写锁是独占的。 读和读之间不会互斥,读和写、写和读、写和写之间才会互斥,主要是提升了读写的性能 ReentrantLock是独占锁且可重入的,相比synchronized而言功能更加丰富也更适合复杂的并发场景,但是也有弊端,假如有两个线程A/B访问数据,加锁是为了防止线程A在写数据, 线程B在读数据造成的数据不一致; 但线程A在读数据,线程C也在读数据,读数据是不会改变数据没有必要加锁,但是还是加锁了,降低了程序的性能,所以就有了ReadWriteLock读写锁接口 场景:读多写少,比如设计一个缓存组件 或 提高Collection的并发性 class CachedData { * Object data; * volatile boolean cacheValid; * final ReentrantReadWriteLock rwl = new ReentrantReadWriteLock(); * * void processCachedData() { * rwl.readLock().lock(); * if (!cacheValid) { * // Must release read lock before acquiring write lock * rwl.readLock().unlock(); * rwl.writeLock().lock(); * try { * // Recheck state because another thread might have * // acquired write lock and changed state before we did. * if (!cacheValid) { * data = ... * cacheValid = true; * } * // Downgrade by acquiring read lock before releasing write lock * rwl.readLock().lock(); * } finally { * rwl.writeLock().unlock(); // Unlock write, still hold read * } * } * * try { * use(data); * } finally { * rwl.readLock().unlock(); * } * } * }} class RWDictionary { * private final Map
第5集 阻塞队列BlockingQueue是否知道
简介: 讲解阻塞队列BlockingQueue的掌握情况
-
考点:考查阻塞队列BlockingQueue的掌握情况
-
难度:【 ** ** 】
-
并发编程里面解决生产消费者模型你知道哪几种方式?
核心:要保证生产者不会在缓冲区满时放入数据,消费者也不会在缓冲区空时消耗数据 常用的同步方法是采用信号或加锁机制 1、wait() / notify()方法 2、await() / signal()方法 用ReentrantLock和Condition实现等待/通知模型 3、Semaphore信号量 4、BlockingQueue阻塞队列 ArrayBlockingQueue LinkedBlockingQueue put方法用来向队尾存入元素,如果队列满,则阻塞 take方法用来从队首取元素,如果队列为空,则阻塞 你知道阻塞队列BlockingQueue不?介绍下常见的阻塞队列 BlockingQueue: j.u.c包下的提供了线程安全的队列访问的接口,并发包下很多高级同步类的实现都是基于阻塞队列实现的 1、当阻塞队列进行插入数据时,如果队列已满,线程将会阻塞等待直到队列非满 2、从阻塞队列读数据时,如果队列为空,线程将会阻塞等待直到队列里面是非空的时候 常见的阻塞队列 ArrayBlockingQueue: 基于数组实现的一个阻塞队列,需要指定容量大小,FIFO先进先出顺序 LinkedBlockingQueue: 基于链表实现的一个阻塞队列,如果不指定容量大小,默认 Integer.MAX_VALUE, FIFO先进先出顺序 PriorityBlockingQueue: 一个支持优先级的无界阻塞队列,默认情况下元素采用自然顺序升序排序,也可以自定义排序实现 java.lang.Comparable接口 DelayQueue: 延迟队列,在指定时间才能获取队列元素的功能,队列头元素是最接近过期的元素,里面的对象必须实现 java.util.concurrent.Delayed 接口并实现CompareTo和getDelay方法
第6集 并发队列ConcurrentLinkedQueue是否掌握
简介: 讲解非阻塞队列ConcurrentLinkedQueue的掌握情况
-
考点:考查非阻塞队列ConcurrentLinkedQueue的掌握情况
-
难度:【 ** ** 】
-
你知道非阻塞队列ConcurrentLinkedQueue不,它怎么实现线程安全的?
线程安全原因: ConcurrentLinkedQueue是基于链表实现的无界线程安全队列,采用FIFO进行排序 保证线程安全的三要素:原子、有序、可见性 1、底层结构是Node,链表头部和尾部节点是head和tail,使用节点变量和内部类属性使用volatile声明保证了有序和可见性 2、插入、移除、更新操作使用CAS无锁操作,保证了原子性 3、假如多线程并发修改导致 CAS 更新失败,采用for循环插入保证更新操作成功
第7集 说说你认为的并发编程最佳实践
简介: 并发编程常用的最佳实践
-
考点:考查是否有用多线程,总结个人的最佳实践
-
难度:【 *** 】
-
平时多线程用的挺多的,写出3条你遵循的多线程最佳实践
给不同模块的线程起名称,方便后续排查问题 使用同步代码块或者同步的方法的时候,尽量减小同步范围 多用并发集合少用同步集合 支持线程安全 同步集合:Hashtable/Vector/同步工具类包装Collections.synXXX 并发集合:ConcurrentHashMap、CopyOnWriteArrayList 线上业务需要使用多线程,优先考虑线程池是否更加合适,然后判断哪种线程池比较好,最后才是自己创建单一线程 -
用过线程池不? 有什么好处, java里有哪些是常用的线程池
好处:重用存在的线程,减少对象创建销毁的开销,有效的控制最大并发线程数,提高系统资源的使用率,同时避免过多资源竞争,避免堵塞,且可以定时定期执行、单线程、并发数控制,配置任务过多任务后的拒绝策略等功能 类别 newFixedThreadPool 一个定长线程池,可控制线程最大并发数 newCachedThreadPool 一个可缓存线程池 newSingleThreadExecutor 一个单线程化的线程池,用唯一的工作线程来执行任务 newScheduledThreadPool 一个定长线程池,支持定时/周期性任务执行
第8集 线程池里面的坑你踩过吗?
简介:常见线程池里面坑是否知道
-
考点:是否知道线程池里面的坑
-
难度:【 ** ** 】
-
【阿里巴巴编码规范】 线程池不允许使用 Executors 去创建,要通过 ThreadPoolExecutor的方式原因?
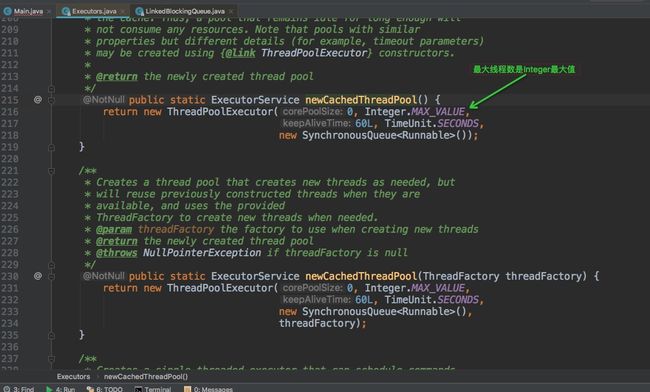
Executors创建的线程池底层也是调用 ThreadPoolExecutor,只不过使用不同的参数、队列、拒绝策略等,如果使用不当,会造成资源耗尽问题; 直接使用ThreadPoolExecutor让使用者更加清楚线程池允许规则,常见参数的使用,避免风险 常见的线程池问题: newFixedThreadPool和newSingleThreadExecutor: 队列使用LinkedBlockingQueue,队列长度为 Integer.MAX_VALUE,可能造成堆积,导致OOM newScheduledThreadPool和newCachedThreadPool: 线程池里面允许最大的线程数是Integer.MAX_VALUE,可能会创建过多线程,导致OOM

第9集 ThreadPoolExecutor核心参数是否掌握
简介: 并发编程里面的ThreadPoolExecutor参数考查
-
考点:ThreadPoolExecutor常见参数的掌握
-
难度:【 ** ** *】
简介: 并发编程里面的ThreadPoolExecutor参数考查
-
考点:ThreadPoolExecutor常见参数的掌握
-
难度:【 ** ** *】
ThreadPoolExecutor构造函数里面的参数你是否掌握,能否解释下各个参数的作用
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
corePoolSize:核心线程数,线程池也会维护线程的最少数量,默认情况下核心线程会一直存活,即使没有任务也不会受存keepAliveTime控制
坑:在刚创建线程池时线程不会立即启动,到有任务提交时才开始创建线程并逐步线程数目达到corePoolSize
maximumPoolSize:线程池维护线程的最大数量,超过将被阻塞
坑:当核心线程满,且阻塞队列也满时,才会判断当前线程数是否小于最大线程数,才决定是否创建新线程
keepAliveTime:非核心线程的闲置超时时间,超过这个时间就会被回收,直到线程数量等于corePoolSize
unit:指定keepAliveTime的单位,如TimeUnit.SECONDS、TimeUnit.MILLISECONDS
workQueue:线程池中的任务队列,常用的是 ArrayBlockingQueue、LinkedBlockingQueue、SynchronousQueue
threadFactory:创建新线程时使用的工厂
handler: RejectedExecutionHandler是一个接口且只有一个方法,线程池中的数量大于maximumPoolSize,对拒绝任务的处理策略,默认有4种策略AbortPolicy、CallerRunsPolicy、DiscardOldestPolicy、DiscardPolicy 干货文档




