kafka3.x学习
本文主要学记录了kafka3.x的一些知识。
文章目录
- 一、概述
-
- 消息队列的两种模式:
- 二、Kafka基础架构
- 三、kafka-3.1.0集群安装
- 四、Kafka的基本命令
- 五、Kafka生产者发送流程
- 六、生产者分区策略
- 七、幂等性原理
- 八、kafka事务原理
- 九、数据有序/乱序
- 十、kafka broker工作原理
- 十一、节点的服役/退役
- 十二、kafka故障处理
-
-
- Follower故障处理
- Leader故障处理
-
- 十三、kafka文件存储机制
-
-
- kafka的数据存储
- 手动调整分区副本存储策略
- 日志清除策略
-
- 十四、kafka消费者
-
- 消费者组的分区分配流程:
- 消费者组的数据拉取流程:
- 消费者分配分区策略:
- 消费者offset位置维护:
- 指定offset位置/时间消费:
- 漏消费和重复消费:
-
- 消费者提高吞吐量:
- 十五、生产调优
-
- 1、提高生产者的吞吐量:
- 2、ACKS应答级别调优:
-
- 数据可靠性保障:
- 3、手动调整分区副本存储策略
一、概述
Kafka是分布式的基于发布/订阅模式的消息队列,主要应用于大数据实时处理领域。
消息队列的两种模式:
- 点对点模式:
一个生产者对应一个消费者,消费者主动拉取消息,确认收到消息之后,删除对应的消息。
- 发布订阅模式:
一个生产者可以对应多个消费者,多个消费者之间相互独立,消息按照主题(topic)分类,消费者主动拉取消息后不删除消息,其他消费者依旧可以再次消费这个消息。
二、Kafka基础架构
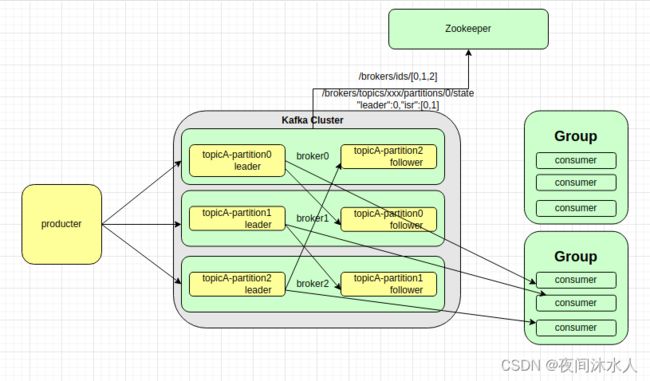
架构特点:
- 为方便扩展,提高吞吐量,一个topic分为多个partition(分区)。
- 为配合多个分区的设计,引入了消费者组(consumer group)的概念。
- 为提高可用性,每个topic分区增引入了副本的机制,并且副本之间存在leater和follower区分。
- Kafka2.8之前必须依赖zk,zk中记录着Kafka集群中所有的节点的信息,以及每个topic分区中的leater和follower。
三、kafka-3.1.0集群安装
下载kafka-3.1.0压缩包,解压后即可完成安装,修改以下配置文件,修改后,分发到node-01,node-02,node-03三台机器上,即可完成kafka集群的安装:
// kafka每个broker的身份标识,必须唯一
broker.id=2
// kafka数据存放地址
log.dirs=/orkasgb/data/kafka
// 指定zookeeper的地址
zookeeper.connect=node-01:2181,node-02:2181,node-03:2181
// 安装好集群之后,分别执行以下命令启动kafka
$KAFKA_HOME/bin/kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
四、Kafka的基本命令
- kafka-topics.sh:
| 基本参数 | 说明 |
|---|---|
| –bootstrap-server |
指定kafka集群地址,可以有多个,必选,格式为:node-01:9092,node-02:9092 |
| –topic |
指定链接的topic(topic) |
| –create | 创建主题 |
| –delete | 删除主题 |
| –alter | 修改主题,一般只能修改分区数 |
| –list | 列出所有的主题 |
| –describe | 描述当前主题的详细信息 |
| –partitions |
创建主题时指定分区数,必选 |
| –replication-factor |
创建主题时指定副本数,必选 |
| –config |
指定配置文件位置 |
# 创建一个topic-orkasgb-test主题,分区数为2,副本数为3
[root@node-01 ~]# kafka-topics.sh --bootstrap-server node-01:9092,node-02:9092 --topic topic-orkasgb-test --create --partitions 2 --replication-factor 3
Created topic topic-orkasgb-test.
[root@node-01 ~]#
# 查看当前kafka集群中的topic
[root@node-01 ~]# kafka-topics.sh --bootstrap-server node-01:9092,node-02:9092 --list
__consumer_offsets
topic-orkasgb-test
[root@node-01 ~]#
# 查看topic-orkasgb-test主题的详细信息
[root@node-01 ~]# kafka-topics.sh --bootstrap-server node-01:9092,node-02:9092 --topic topic-orkasgb-test --describe
Topic: topic-orkasgb-test TopicId: k6OqKVFcQgCFrahkJOyWbQ PartitionCount: 2 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: topic-orkasgb-test Partition: 0 Leader: 2 Replicas: 2,1,3 Isr: 2,1,3
Topic: topic-orkasgb-test Partition: 1 Leader: 3 Replicas: 3,2,1 Isr: 3,2,1
[root@node-01 ~]#
- kafka-console-producer.sh :
| 基本参数 | 说明 |
|---|---|
| –bootstrap-server |
指定kafka集群地址,可以有多个,必选,格式为:node-01:9092,node-02:9092 |
| –topic |
指定链接的topic(topic) |
| –producer.config |
指定配置文件位置 |
# 创建一个消费者,将数据发送到topic-orkasgb-test主题中
[root@node-03 bin]# kafka-console-producer.sh --bootstrap-server node-01:9092,node-02:9092 --topic topic-orkasgb-test --producer.config /orkasgb/software/kafka-3.1.0/config/producer.properties
>hello kafka
>
- kafka-console-consumer.sh :
| 基本参数 | 说明 |
|---|---|
| –bootstrap-server |
指定kafka集群地址,可以有多个,必选,格式为:node-01:9092,node-02:9092 |
| –topic |
指定链接的topic(topic) |
| –consumer.config |
指定配置文件位置 |
# 创建一个消费者,用于消费发往topic-orkasgb-test主题中的数据
[root@node-01 ~]# kafka-console-consumer.sh --bootstrap-server node-01:9092,node-02:9092 --topic topic-orkasgb-test --consumer.config /orkasgb/software/kafka-3.1.0/config/consumer.properties
hello kafka
- kafka-consumer-groups.sh:
# 列出整个集群中的消费组
[root@node-02 bin]# kafka-consumer-groups.sh --bootstrap-server node-01:9092,node-02:9092 --list
test-consumer-group
[root@node-02 bin]#
# 查看test-consumer-group属组中的主题消费情况
[root@node-02 bin]# kafka-consumer-groups.sh --bootstrap-server node-01:9092,node-02:9092 --group test-consumer-group --describe
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
test-consumer-group topic-orkasgb-test 0 0 0 0 console-consumer-b234bb08-4374-498d-9cfe-192de9f9cdd3 /192.168.137.223 console-consumer
test-consumer-group topic-orkasgb-test 1 1 1 0 console-consumer-b234bb08-4374-498d-9cfe-192de9f9cdd3 /192.168.137.223 console-consumer
[root@node-02 bin]#
五、Kafka生产者发送流程
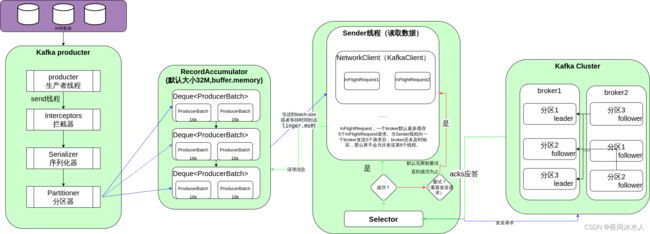
- batch.size:用来控制数据量大小,当数据量大小达到该值时,才会唤醒Sender线程去发送数据,默认16k。
- linger.ms:数据发送延迟设置,当数据还未达到batch.size,但是已经到达延迟时间(linger.ms),也会唤醒Sender线程去发送数据,默认为0,没有延迟。
- ack应答:
- 0:生产者发送数据后,立即给客户端返回应答响应,不管leader是否已经落盘处理。
- 1:生产者发送数据后,需要等待leader落盘处理后并ack应答成功后才给客户端返回应答响应。
- -1(all):生产者发送数据后,需要等待leader和follower都落盘处理后并ack应答成功后才给客户端返回应答响应。
异步发送消息代码:
@Test
public void producter() throws ExecutionException, InterruptedException {
// 创建生产者配置文件
HashMap<String, Object> config = new HashMap<>();
// 集群地址
config.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "node-01:9092,node-02:9092,node-03:9092");
// KEY的序列化器
config.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
// VALUE的序列化器
config.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
// 创建Producter对象
DefaultKafkaProducerFactory<String, String> producerFactory = new DefaultKafkaProducerFactory<>(config);
Producer<String, String> producer = producerFactory.createProducer();
for (int i = 0; i < 5; i++) {
// 同步发送数据
// RecordMetadata recordMetadata = producer.send(new ProducerRecord<>("topic-orkasgb-test", "test" + i)).get();
// System.out.println(recordMetadata.toString());
// 同步发送数据
// RecordMetadata recordMetadata = producer.send(new ProducerRecord<>("topic-orkasgb-test", "test" + i)).get();
// System.out.println(recordMetadata.toString());
// 异步发送数据
Future<RecordMetadata> send = producer.send(new ProducerRecord<>("topic-orkasgb-test", "哈哈哈哈" + i));
producer.flush();
System.out.println(send.toString());
// 带回调函数的异步发送数据
// Future send = producer.send(new ProducerRecord<>("topic-orkasgb-test", "哈哈哈哈" + i), new Callback() {
// @Override
// public void onCompletion(RecordMetadata metadata, Exception exception) {
//
// }
// });
// System.out.println(send.toString());
}
producer.close();
}
六、生产者分区策略
kafka生产者存在默认的分区策略,如果记录中指定了分区,则使用指定的分区策略,如果未指定分区但是在发送消息时指定了key,则根据key的hash选择分区,如果未指定分区或key,则选择在批处理已满时才更改的粘性分区策略。
- 指定分区号:当指定分区的时候,直接将消息发送到指定的分区中。例如,指定分区为0,那么直接会将消息发送到0号分区。
- 未指定分区号但是指定了key:当未指定分区号但是指定了key的时候,会根据key的hash值与topic的partition数进行取余计算出分区号。例如,如果key1的hash值为4,key2的hash值为5,topic的partition数为2,那么key1对应的消息直接发送到0号分区,key2对应的消息直接发送到1号分区.
- 未指定分区号也未指定key:当未指定分区号也未指定key的时候,kafka内部自行采用黏性分区策略,随机选择一个分区号,并且尽可能将本批次的所有消息都发送到该分区,直到该分区的bach.size已满或者innger.ms时间到,才会随机再次选择另外一个分区号(必须和上次选择的分区号不一致)。例如,如果上一次选择的分区号为1,那么直到该分区的bach.size已满或者innger.ms时间到,那么会随机再次选择另外一个分区号,如果选择的还是0,那么会一直选择,直到和上一次不一致为止。
自定义分区器:
// 在生产者配置文件中指定自定义分区器
config.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, UserPartition.class);
/**
* 自定义分区器,继承Partitioner类,重写partition方法即可。
*/
public class UserPartition implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// 如果消息中包含了orkasgb字符串,就将这条消息发送到0好分区,否则就发送到1号分区
return StringUtils.contains(value.toString(), "orkasgb") ? 0 : 1;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
七、幂等性原理
幂等性是指,不管producter向broker发送多少条重复数据,broker只会持久化一条。幂等性判断数据重复的标准为以

八、kafka事务原理
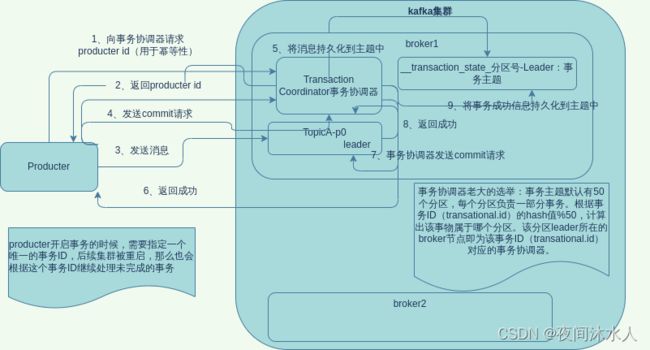
- 开启事务,必须开启幂等性,事务的底层就是幂等性。
- _transaction_state-分区-Leader为存储事务信息的特殊主题,默认有50个分区。
- kafka集群内部选举主事务协调器。选举方式为:根据事务ID(transational.id)的hash值%50,计算出该事物属于哪个分区。该分区leader所在的broker节点即为该事务ID(transational.id)对应的事务协调器。
- producter开启事务的时候,需要指定一个唯一的事务ID,后续集群被重启,那么也会根据这个事务ID继续处理未完成的事务。
- producter会向kafka集群请求一个producter id,该id主要用于幂等性。
- producter向集群发送消息到topicA-partition0中,并发送commit请求。
- 事务协调器接受到commit请求之后,将commit请求持久化到事务主题中,并且还会发送一个commit请求到topicA-partition0中,判断消息时候处理成功。
- topicA-partition0返回处理成功的消息之后,事务协调器会将该消息处理成功的信息持久化到_transnnaction_state-分区-Leader中。
九、数据有序/乱序
- kafka数据有序,保证单分区内部有序。
- 在kafka1.x之前,要保证数据单分区内部有序,只需要设置max.in.flight.requests.per.connection=1即可。
- 在kafka1.x之后,要保证数据单分区内部有序,如果没有开启幂等性,只需要设置max.in.flight.requests.per.connection=1即可。如果开启了幂等性,需要设置max.in.flight.requests.per.connection<=5,(默认为5)即可。因为在开启幂等性的之后,kafka集群会缓存5(max.in.flight.requests.per.connection)个请求,正常情况下,请求是按照顺序发送到kafka集群,但是如果顺序错乱了,也就是说的数据乱序,那么kafak集群会等待,直到5个请求全部发送过来,kafka集群内部会对这5个请求重新排序。排序时会利用幂等性中的SeqNumber单调递增的特性,所以,kafka能保证数据单分区内部有序。
十、kafka broker工作原理
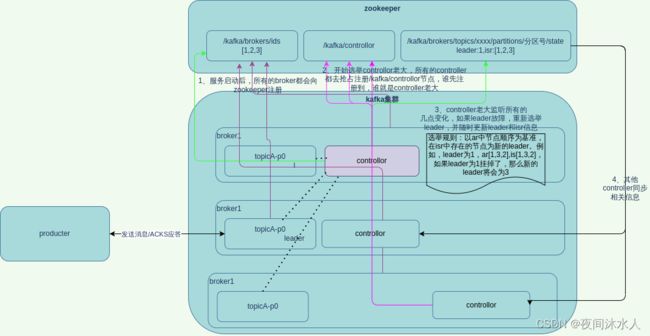
- broker启动之后,会去zookeeper注册信息,在zookeeper中生成一个/kafka/brokers/ids信息,里面存储的是所有的broker信息。
- 每一个主题的副本都对应一个controllor,所以必须选出一个controllor老大,最后由这个controllor老大监听各个broker节点的变化,在后续会辅助broker选举新的主题副本leader。选举controllor老大的方式就是去抢先注册zookeeper中的/kafka/controller节点,谁先注册到,谁就是controllor老大。
- controllor老大会将集群中的broker信息上传到zookeeper中,生成/kafka/brokers/topics/[对应的主题]/partitions/[对应的分区号]/state,里面存储的就是该主题该分区下副本的信息,包括leader以及存活的follower信息(isr)。
- 假如节点中的某一个主题的分区中的leader挂了,此时controllor老大会监听到这个变化,那么它会更新/kafka/brokers/topics/[对应的主题]/partitions/[对应的分区号]/state信息,并且开始重新选举leader。选举规则为,以ar中节点顺序为基准,在isr中存在的节点为新的leader。例如,leader为1,ar[1,3,2],is[1,3,2],如果leader为1挂掉了,那么新的leader将会为3。
十一、节点的服役/退役
-
服役一台新的节点:
- 创建一台新的kafka节点或者从之前的机器上克隆一个kafka节点(注意,如果是克隆的机器,那么需要删除kafka的data和log目录,并修改broker.id),并启动。
- 创建一个xxxx.json文件,对原来的主题进行负载均衡。
{ "topics" : [ {"topic" : "xxxx"} ], "version" : 1 }- 按照xxxx.json生成一个负载均衡的计划。
kafka-reassign-partitions.sh --bootstrap-server node-01:9092 --topics-to-move-json-file xxxx.json --broker-list "0,1,2,3" --generate- 将生成的负载均衡的计划保存成xx.json文件。
- 按照xx.json文件执行负载均衡的计划。
kafka-reassign-partitions.sh --bootstrap-server node-01:9092 --reassignment-json-file xx.json --execute- 验证负载均衡的计划是否执行完成。
kafka-reassign-partitions.sh --bootstrap-server node-01:9092 --reassignment-json-file xx.json --verify -
退役一台旧节点:
思想,将旧节点上的数据转移到其他的节点上后删除该节点即可,方法类似于服役新节点的方式,在生成负载均衡计划的时候,将–broker-list "0,1,2,3"中要退役的的broker.id取消掉,其他步骤按照顺序依次执行即可将数据到其他的节点上。
十二、kafka故障处理

Follower故障处理
- LEO(Log End Offset):每一个副本的最后一个offset,也就是最新的offset + 1。
- HW:所有副本中最小的LEO。
Follower故障处理步骤:
- 将故障的Follower节点从isr中剔除。
- 期间,leader和其他follower继续接收数据。
- 待该follower恢复后,开始恢复数据,首先从本地磁盘中加载数据,读取自己上次的HW,高于上次的HW的数据将会被删除,并且向leader请求同步数据,等到数据恢复达到新的HW时,就可以加入ISR中了。
Leader故障处理
- LEO(Log End Offset):每一个副本的最后一个offset,也就是最新的offset + 1。
- HW:所有副本中最小的LEO。
Leader故障处理步骤:
- 将故障的Leader节点从isr中剔除。
- 从其他follower中选举新的leader。
- 其他的follower必须和新的leader保持数据一致性,高于该leader的数据部分必须删除。所以,这样会存在数据丢失的问题,因为kafka保证的时数据一致性,并不能保证数据不丢失或者不重复。
十三、kafka文件存储机制
kafka的数据存储
kafka的数据存储是按照分区进行存储的,每个分区目录的命名格式为topic+分区号,每个分区目录下有三个类型的文件,.log,.index,.timeindex。因为kafka生产端为数据是不断的追加到.log文件中,所以.index用来记录数据的索引,.timeindex文件主要用来删除过期数据。kafka默认数据过期时间为7天。
.index为稀疏索引,文件中存储的是相对offset,.log文件中每写入大约4kb(log.index.interval.bytes)的数据,就会往.index文件中写入一条索引,这样能确保文件占用空间不会太大。
# 查看kafka的.log文件
[root@node-02 topic-orkasgb-test-1]# kafka-run-class.sh kafka.tools.DumpLogSegments --files ./00000000000000000000.log
Dumping ./00000000000000000000.log
Starting offset: 0
baseOffset: 0 lastOffset: 0 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 0 CreateTime: 1649067089350 size: 79 magic: 2 compresscodec: none crc: 384684249 isvalid: true
[root@node-02 topic-orkasgb-test-1]#
手动调整分区副本存储策略
- 创建分区副本存储策略计划xxxx.json。
{
"partitions" : [
{"topic" : "xxx","partition": 0,"replicas": [1,3]},
{"topic" : "xxx","partition": 1,"replicas": [2,3]},
{"topic" : "xxx","partition": 2,"replicas": [1,2]}
],
"version" : 1
}
- 按照xx.json文件执行负载均衡的计划。
kafka-reassign-partitions.sh --bootstrap-server node-01:9092 --reassignment-json-file xxxx.json --execute
- 验证负载均衡的计划是否执行完成。
kafka-reassign-partitions.sh --bootstrap-server node-01:9092 --reassignment-json-file xxxx.json --verify
日志清除策略
kafka中的文件清除,由以下参数控制:
- log.retention.hours:默认7天,优先级最低
- log.retention.minutes:分钟,默认为null,优先级2
- log.retention.ms:毫秒,默认为null,优先级1
- log.retention.check.interval.ms:检测数据文件过期时间的周期,默认每5分钟检测一次。
- log.cleanup.policy:日志清楚策略设置,默认delete
日志清楚策略:
-
delete删除日志:删除过期的数据,log.cleanup.policy = delete。
- 基于时间:默认打开,以segment中所有记录中最大时间戳作为该文件的时间戳。
- 基于大小:默认关闭,超过设置的所有的日志总大小,删除最早的segment。log.retention.bytes,默认为-1,表示无穷大。
假如一个segment中的日志有一部分数据过期了,一部分没有过期(记录中最大时间戳的那部分),那么这个segment是不会被删除掉的。
-
compact:日志压缩,log.cleanup.policy = compact。
对于相同的key,只保留最后一个版本。压缩后会存在offset不是连续的,如果要找的某个offset不存在,那么就会返回一个最近的比它大的offset,然从这个offset开始消费。
十四、kafka消费者
消费者组的分区分配流程:
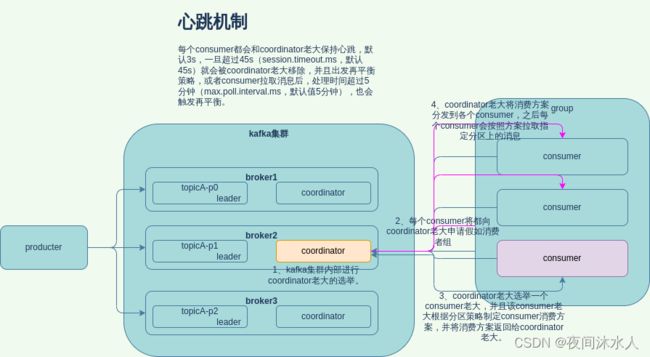
- kafka集群内部进行coordinator老大的选举,用于辅助consumer组的初始化和分区的分配。选举方式为group.id的hash值%50,计算出来的值对应的broker上的coordinator为coordinator老大。
- consumer组中的所有的consumer都向coordinator老大发送加入当前group组的请求,coordinator老大收到请求后将这些consumer编为一组,并从这些consumer中选举出来一个leader consumer,然leader consumer制定消费方案。
- leader consumer制定好消费方案后发送给coordinator老大,coordinator老大将任务分配给对应的consumer,然后各个consumer到分配给自己的分区上拉取数据。
- 每个消费者都会和coordinator老大保持心跳(默认3秒),一旦出现超时(session.timeout.ms=45s),那么coordinator老大就会将这个consumer移除,之后触发负载均衡,将其他分区的任务均衡到剩余的consumer。在拉取数据之后,如果消费者处理时间过长(max.poll.interval.ms=5分钟),也会触发负载均衡,将其他分区的任务均衡到剩余的consumer。
消费者组的数据拉取流程:
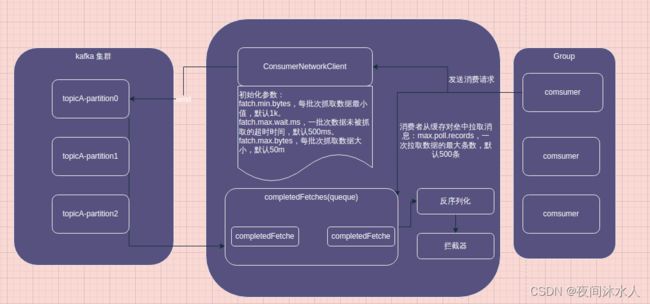
- 消费者组创建一个ConsumerNetworkClient网络链接,用于和kafka集群进行交互,consumer发送消费请求,并初始化一些参数:fatch.min.bytes,每批次抓取数据最小值,默认1k。fatch.max.wait.ms,一批次数据未被抓取的超时时间,默认500ms。fatch.max.bytes,每批次抓取数据大小,默认50m。max.poll.records,一次拉取数据的最大条数,默认500条。
- ConsumerNetworkClient将数据拉取过来之后,缓存到对应的队列中。
- consumer开始从缓存队列中拉取数据,默认一次拉取500条数据。
- 拉取数据之后开始进行反序列化,因为在生产者端,数据被序列化了。
- 数据还需要进过拦截器,之后才是真正的处理处理。
消费者分配分区策略:
kafka提供了四种消费者分配分区策略(partition.assignment.strategy),分别是:
- org.apache.kafka.clients.consumer.RangeAssignor:按主题分配分区,所以RangeAssignor是针对每一个topic而言的,首先对分区按照序号进行排序,如下,consumer1将会消费topicA-p1,topicA-p2,consumer2将会消费topicA-p3。通过partition数/consumer数来决定每一个consumer应该消费多少个分区,除不尽的,排在前边的消费者将会多消费几个分区。这种方式很明显,如果有多个topic的情况下,所有topic多余出来的分区都会交给前边几个consumer,而导致前边几个consumer会很忙,后边的consumer会很悠闲,这就是数据倾斜问题。
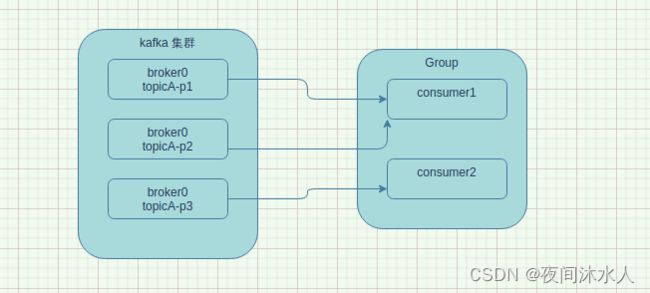
- org.apache.kafka.clients.consumer.RoundRobinAssignor:以循环方式将分区分配给消费者。即以轮询的方式将分区分配给各个消费者。如下,consumer1将会消费topicA-p1和topicA-p3两个分区,consumer2将会消费topicA-p2。

- org.apache.kafka.clients.consumer.StickyAssignor:保证分配是最大平衡的,同时保留尽可能多的现有分区分配。有点类似于RangeAssignor,但是不同的是,分配是随机,consumer1将可能会消费topicA-p1,topicA-p3/或者topicA-p2,topicA-p3,consumer2将会消费topicA-p2或者topicA-p1。
- org.apache.kafka.clients.consumer.CooperativeStickyAssignor:遵循相同的 StickyAssignor 逻辑,但允许合作再平衡。
默认分配器是 [RangeAssignor, CooperativeStickyAssignor],默认情况下将使用 RangeAssignor,但允许升级到 CooperativeStickyAssignor,实现 org.apache.kafka.clients.consumer.ConsumerPartitionAssignor 接口允许您插入自定义分配策略。
消费者offset位置维护:
kafka0.9版本之前的offset存放在zookeeper中,kafka0.9版本之后的offset存放在kafka系统主题(__consumer_offset)中,在consumer.properties中设置参数exclude.internal.topic=false才可以查看系统主题,默认为true。__consumer_offset中是以key-value的形式存放数据,key就是group.id+topic+分区号,value就是当前主题所在分区号的消费到的offset。每日过一段时间,kafka会对主题中的内容进行compact,所以consumer_offset中保留的就是最新的offset。
# 查看系统主题__consumer_offset中的主题信息
kafka-console-consumer.sh --bootstrap-server node-01:9092,node-02:9092 --topic __consumer_offset --consumer.config /orkasgb/software/kafka-3.1.0/config/consumer.properties --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --from-beginning
指定offset位置/时间消费:
kafka中提供了auto.offset.reset=earliest | latest | none三种offset消费方式,默认latest。
- earliest:自动将偏移量重置为最早的偏移量,–from-beginning。
- latest:自动将偏移量重置为最新的偏移量。
- none:如果没有找到消费者组的先前的偏移量,则抛出异常。
将时间转化为对应的offset,即可做到按照时间消费。
漏消费和重复消费:
- 重复消费:因自动提交offset引起,如果上一个offset自动提交成功,此时consumer继续往下消费,且消费成功,但是未等到本次offset自动提交就挂了,当再次启动消费者时,消费者会读取上次提交成功的offset,那么此时就会造成重复消费的问题。
- 漏消费:因手动提交offset引起,如果刚好手动提交offset成功,但是此时消费者刚好被kill掉,那么再次启动会读取上次提交成功的offset,而这个offset是手动提交成功,但是却未真正消费的offset,那么就会造成漏消费。
要避免漏消费和重复消费,那么就需要使用事务的方式,并且要做到整个消费到下游的所有链路上都支持事务。比如消费到存储数据到mysql,都必须支持事务才可以做到精确一次性消费。
消费者提高吞吐量:
- 如果kafka的消费能力不足,则可以考虑增加topic的分区数,并且同时提升消费组的消费者的数量,消费者数=topic分区数(两者缺一不可)。
- 如果是下游处理数据不及时:提高每批次数据拉取的数量,由默认的500条,提高到1000条。
十五、生产调优
1、提高生产者的吞吐量:
- batch.size:批次大小,默认16K。
- linger.ms:等待时间,建议修改为5~10ms。
- commpression-type:考虑使用snappy进行数据压缩后在发送。
- RecordAccumulator:缓冲区大小,可以适当的调整成64M,默认32M。
2、ACKS应答级别调优:
- 0:生产者将数据发送过来之后,不需要等待leader应答成功即可响应客户端。

**问题分析:**当数据发送之后,因为不用等待leader应答就立即返回,假如数据发送到leader之后,leader还未处理数据就发生故障,那么此时数据已经全部丢失。
**数据可靠性分析:**数据丢失,但是效率最高。
- 1:生产者将数据发送过来之后,需要等待leader应答成功后才能响应客户端。
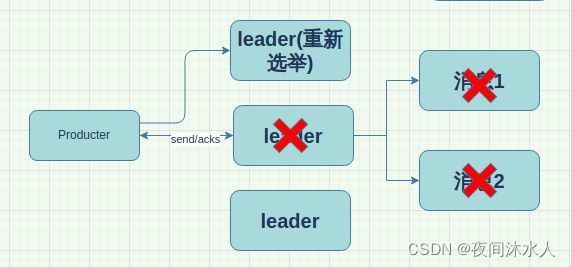
**问题分析:**当数据发送之后,leader应答成功后立即返回,假如数据发送到leader之后,leader还未处理数据就发生故障,此时根据内部的leader选择策略,某一个follower称为新的leader,生产者会立即和新的leader交互,但是因为之前的leader应答成功,producter会认为之前的数据已经发送完成,不会再次发送,那么此时数据已经全部丢失。
当数据发送之后,leade和ISR队列中的所有follower都已经处理完数据,正准备acks应答时,leader发生故障,此时根据内部的leader选择策略,某一个follower称为新的leader,生产者会立即和新的leader交互,但是因为之前的leader没有应答成功,producter会认为之前的数据没有发送完成,继续再次发送,那么此时数据已经重复处理。
**数据可靠性分析:**数据丢失,数据重复。
- -1(all):生产者将数据发送过来之后,需要等待leader和所有在ISR中存在的follower应答成功后才能响应客户端。
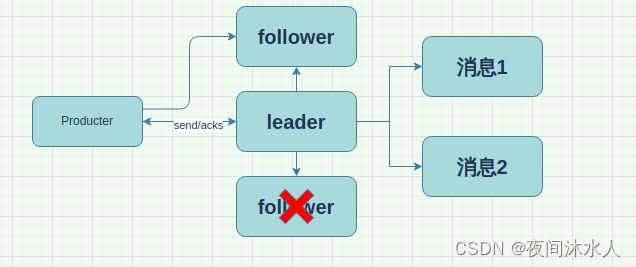
**问题分析:**当数据发送之后,producter再等待leader和其他follower应答,但是其中一个follower发生故障,导致无法acks应答,此时就会发生producter发送完数据却无法返回的情况。kafka为解决这种问题,让leader维护了一个动态的leader和follower的同步信息集合,形式为:(leader:1,isr:[1,2,3])。如果某一个follower超过30s(replica.lag.time.max.ms,默认30s)没有和leader进行通信,那么leader就认为该follower已经发生故障,此时就会将该follower从ISR队列中移除。
**数据可靠性分析:**如果副本数为1,任然存在数据丢失。
数据可靠性保障:
至少一次 = (ACKS级别=-1) + (分区副本数>=2)+ (ISR队列中至少要保障存在两个节点信息)。
精确一次 = 幂等性 + 至少一次。
3、手动调整分区副本存储策略
- 创建分区副本存储策略计划xxxx.json。
{
"partitions" : [
{"topic" : "xxx","partition": 0,"replicas": [1,3]},
{"topic" : "xxx","partition": 1,"replicas": [2,3]},
{"topic" : "xxx","partition": 2,"replicas": [1,2]}
],
"version" : 1
}
- 按照xx.json文件执行负载均衡的计划。
kafka-reassign-partitions.sh --bootstrap-server node-01:9092 --reassignment-json-file xxxx.json --execute
- 验证负载均衡的计划是否执行完成。
kafka-reassign-partitions.sh --bootstrap-server node-01:9092 --reassignment-json-file xxxx.json --verify