微服务异常问题--灵活熔断以及其他应对策略
服务雪崩

造成灾难性雪崩效应原因 简单来说有三种:
1 服务提供者不可用。如:硬件故障、程序BUG、缓存击穿、并发请求量过大等。
2 重试加大流量。如:用户重试、代码重试逻辑等。
3 服务调用者不可用。如:同步请求阻塞造成的资源耗尽等。
最终结果:
服务链条中的某一个服务不可用,导致一系列的服务不可用,最终造成服务逻辑崩溃
解决思路
熔断,降级、请求缓存、请求合,
外加技术实现手段隔离
降级:
降级是指,当请求超时、资源不足等情况发生时进行服务降级处理,不调用真实服务逻辑,而是使用快速失败(fallback)方式直接返回一个托底数据,保证服务链条的完整,避免服务雪崩。
解决服务雪崩效应,都是避免application client请求application service时,出现服务调用错误或网络问题。处理手法都是在application client中实现。我们需要在application client相关工程中导入hystrix依赖信息。
并在对应的启动类上增加新的注解@EnableCircuitBreaker,这个注解是用于开启hystrix熔断器的,简言之,就是让代码中的hystrix相关注解生效。
在调用application service相关代码中,增加新的方法注解@HystrixCommand,代表当前方法启用Hystrix处理服务雪崩效应。
@HystrixCommand注解中的属性:fallbackMethod - 代表当调用的application service出现问题时,调用哪个fallback快速失败处理方法返回托底数据。
具体实现逻辑,参考代码
缓存:
缓存是指请求缓存。通常意义上说,就是将同样的GET请求结果缓存起来,使用缓存机制(如redis、mongodb)提升请求响应效率。
使用请求缓存时,需要注意非幂等性操作对缓存数据的影响。
请求缓存是依托某一缓存服务来实现的。在案例中使用redis作为缓存服务器,那么可以使用spring-data-redis来实现redis的访问操作。需要在application client相关工程中导入下述依赖:
spring cloud会检查每个幂等性请求,如果请求完全相同(路径、参数等完全一致),则首先访问缓存redis,查看缓存数据,如果缓存中有数据,则不调用远程服务application service。如果缓存中没有数据,则调用远程服务,并将结果缓存到redis中,供后续请求使用。
如果请求是一个非幂等性操作,则会根据方法的注解来动态管理redis中的缓存数据,避免数据不一致。
注意:使用请求缓存会导致很多的隐患,如:缓存管理不当导致的数据不同步、问题排查困难等。在商业项目中,解决服务雪崩效应不推荐使用请求缓存。
具体实现逻辑,参考代码
请求合并:
请求合并是指,在一定时间内,收集一定量的同类型请求,合并请求需求后,一次性访问服务提供者,得到批量结果。这种方式可以减少服务消费者和服务提供者之间的通讯次数,提升应用执行效率。
什么情况下使用请求合并:
在微服务架构中,我们将一个项目拆分成很多个独立的模块,这些独立的模块通过远程调用来互相配合工作,但是,在高并发情况下,通信次数的增加会导致总的通信时间增加,同时,线程池的资源也是有限的,高并发环境会导致有大量的线程处于等待状态,进而导致响应延迟,为了解决这些问题,我们需要来了解Hystrix的请求合并
通常来说,服务链条超出4个,不推荐使用请求合并。因为请求合并有等待时间。
请求合并的缺点:
设置请求合并之后,本来一个请求可能5ms就搞定了,但是现在必须再等10ms看看还有没有其他的请求一起的,这样一个请求的耗时就从5ms增加到15ms了,不过,如果我们要发起的命令本身就是一个高延迟的命令,那么这个时候就可以使用请求合并了,因为这个时候时间窗的时间消耗就显得微不足道了,另外高并发也是请求合并的一个非常重要的场景。
使用注解@HystrixCollapser来描述需要合并请求的方法,并提供合并方法使用注解@HystrixCommand来描述。当合并条件(@HystrixCollapser)满足时,会触发合并方法(@HystrixCommand)来调用远程服务并得到结果。
@HystrixCollapser注解介绍:此注解描述的方法,返回值类型必须是java.util.concurrent.Future类型的。代表方法为异步方法。
@HystrixCollapser注解的属性:
batchMethod - 请求合并方法名。
scope - 请求合并方式。可选值有REQUEST和GLOBAL。REQUEST代表在一个request请求生命周期内的多次远程服务调用请求需要合并处理,此为默认值。GLOBAL代表所有request线程内的多次远程服务调用请求需要合并处理。
timerDelayInMilliseconds - 多少时间间隔内的请求进行合并处理,默认值为10ms。建议设置时间间隔短一些,如果单位时间并发量不大,并没有请求合并的必要。
maxRequestsInBatch - 设置合并请求的最大极值,也就是timerDelayInMilliseconds时间内,最多合并多少个请求。默认值是Integer.MAX_VALUE。
具体实现逻辑,参考代码
熔断:
熔断的本质:
1 失败率触发
2 失败总次数触发
熔断的恢复:
1 全恢复
2 半恢复(常用,半转全 后恢复,可控制节奏,可控制比例)
当一定时间内,异常请求比例(请求超时、网络故障、服务异常等)达到阀值时,启动熔断器,熔断器一旦启动,则会停止调用具体服务逻辑,通过fallback快速返回托底数据,保证服务链的完整。
熔断有自动恢复机制,如:当熔断器启动后,每隔5秒,尝试将新的请求发送给服务提供者,如果服务可正常执行并返回结果,则关闭熔断器,服务恢复。如果仍旧调用失败,则继续返回托底数据,熔断器持续开启状态。
熔断的实现是在调用远程服务的方法上增加@HystrixCommand注解。当注解配置满足则开启或关闭熔断器。
具体实现逻辑,参考代码
隔离:
所谓隔离,就是当服务发生问题时,使用技术手段隔离请求,保证服务调用链的完整。隔离分为线程池隔离和信号量隔离两种实现方式。
1 线程池隔离
所谓线程池隔离,就是将并发请求量大的部分服务使用独立的线程池处理,避免因个别服务并发过高导致整体应用宕机。
线程池隔离优点:
使用线程池隔离可以完全隔离依赖的服务,请求线程可以快速放回。
当线程池出现问题时,线程池是完全隔离状态的,是独立的,不会影响到其他服务的正常执行。
当崩溃的服务恢复时,线程池可以快速清理并恢复,不需要相对漫长的恢复等待。
独立的线程池也提供了并发处理能力。
线程池隔离缺点:
线程池隔离机制,会导致服务硬件计算开销加大(CPU计算、调度等),每个命令的执行都涉及到排队、调度、上下文切换等,这些命令都是在一个单独的线程上运行的
线程池隔离的实现方式同样是使用@HystrixCommand注解。相关注解配置属性参考代码
关于线程池:
对于所有请求,都交由tomcat容器的线程池处理,是一个以http-nio开头的的线程池;
开启了线程池隔离后,tomcat容器默认的线程池会将请求转交给threadPoolKey定义名称的线程池,处理结束后,由定义的线程池进行返回,无需还回tomcat容器默认的线程池。线程池默认为当前方法名;
所有的fallback都单独由Hystrix创建的一个线程池处理。
2 信号量隔离:
所谓信号量隔离,就是设置一个并发处理的最大极值。当并发请求数超过极值时,通过fallback返回托底数据,保证服务完整性。
信号量隔离同样通过@HystrixCommand注解配置,常用注解属性有:
commandProperty - 配置信号量隔离具体数据。属性类型为HystrixProperty数组,常用配置内容如下:
execution.isolation.strategy - 设置隔离方式,默认为线程池隔离。可选值只有THREAD和SEMAPHORE。
execution.isolation.semaphore.maxConcurrentRequests - 最大信号量并发数,默认为10。
两者对比:
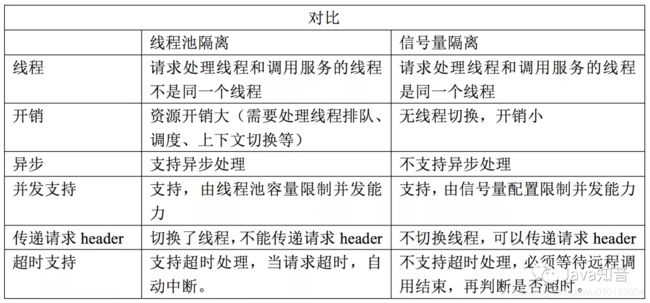
线程池隔离和信号量隔离的选择
线程池隔离:请求并发大,耗时较长(一般都是计算大,服务链长或访问数据库)时使用线程池隔离。可以尽可能保证外部容器(如Tomcat)线程池可用,不会因为服务调用的原因导致请求阻塞等待。
信号量隔离:请求并发大,耗时短(计算小,服务链段或访问缓存)时使用信号量隔离。因为这类服务的响应快,不会占用外部容器(如Tomcat)线程池太长时间,减少线程的切换,可以避免不必要的开销,提高服务处理效率。
具体应用
在声明式远程服务调用Feign中,实现服务灾难性雪崩效应处理也是通过Hystrix实现的。而feign启动器spring-cloud-starter-feign中是包含Hystrix相关依赖的。
在Feign技术中,一般不使用请求合并,请求缓存等容错机制。常用的机制是隔离,降级和熔断。
具体实现逻辑,参考代码