ssis高级转换任务—查找_SSIS中的模糊查找转换
ssis高级转换任务—查找
This article helps you to understand the usage of the Fuzzy Lookup Transformation in SQL Server Integration Services (SSIS).
本文可帮助您了解SQL Server Integration Services(SSIS)中模糊查找转换的用法。
SQL Server Integration Services (SSIS) is said to be a zero-code tool that can be used to integrate data from multiple sources. If you are working with multiple data sources, there can be cases where there are issues with data integration.
SQL Server集成服务(SSIS)被认为是一种零代码工具,可用于集成来自多个源的数据。 如果您使用多个数据源,则有时可能会出现数据集成问题。
Let us look at this by means of an example. There was a requirement to integrate two systems to generate reports. Those two systems are Production and Human Resource Management. Due to the fact that this was built by two different vendors, these two cannot be integrated technically. The production system has details of the 150 workers and the human resource management system has all the details of all the employees. Since Employee ID cannot be used to match employee, employee name was selected to match these employees. However, due to the fact that these were differently managed systems, out of the 150 workers, only 125 workers were able to match. Those employees’ names were matched with the exact name. The rest of the 25 employees cannot be matched because there are small spelling, space issues. However, for the successful analysis, it is important to match these employees.
让我们通过一个例子来看一下。 需要集成两个系统来生成报告。 这两个系统是生产和人力资源管理。 由于它是由两个不同的供应商构建的,因此这两个技术上无法集成。 生产系统包含150名工人的详细信息,而人力资源管理系统包含所有员工的所有详细信息。 由于不能使用员工ID来匹配员工,因此选择了员工姓名来匹配这些员工。 但是,由于这些系统是不同管理的系统,因此在150名工人中,只有125名工人能够匹配。 这些员工的姓名与确切姓名匹配。 由于拼写,空格问题小,其余25名员工无法配对。 但是,对于成功的分析,匹配这些员工很重要。
In SSIS, typically, we use Lookup transformation for exact matching. However, we need more than a standard lookup transformation to match these partial matching columns. To match these types of partial matching scenarios, there are two controls is SSIS toolset. There are Fuzzy Lookup and Fuzzy Grouping transformations in SSIS to support these types of scenarios. In this article, let us see how we can use Fuzzy Lookup in SSIS to solve the above problem.
通常,在SSIS中,我们使用Lookup转换进行精确匹配。 但是,我们不仅需要标准的查找转换来匹配这些部分匹配的列。 为了匹配这些类型的部分匹配方案,SSIS工具集有两个控件。 SSIS中存在模糊查找和模糊分组转换,以支持这些类型的方案。 在本文中,让我们看看如何在SSIS中使用模糊查找来解决上述问题。
I assume you are familiar with the basics of SSIS and also know how to create an SSIS package. In case you are not, you can check these tutorials here on Microsoft Documentation before proceeding with this article.
我假设您熟悉SSIS的基础知识,并且知道如何创建SSIS包。 如果不是这样,您可以在继续本文之前查看 Microsoft文档中的这些教程。
抬头 (Lookup)
First, let us see how we can use standard Lookup transformation. Let us see the following as the sample reference data set.
首先,让我们看看如何使用标准的Lookup转换。 让我们将以下内容作为示例参考数据集。

Let us see the following as the input data.
让我们将以下内容作为输入数据。

This data has to be matched with the reference data. Let us create an SSIS project from SQL Server Data Tools (SSDT). Lookup transformation was configured as the following screenshot.
该数据必须与参考数据匹配。 让我们从SQL Server数据工具(SSDT)创建一个SSIS项目。 查找转换已配置为以下屏幕截图。

In the above SSIS package, Data Flow control was configured in the SSIS control flow as above. The Flat file was configured to a Flat File source. Since Lookup needs the same data type, data from the Flat file is converted to nvarchar data type in the Data Conversion task.
在上面的SSIS包中,如上所述,在SSIS控制流中配置了数据流控制。 平面文件已配置为平面文件源。 由于查找需要相同的数据类型,因此在数据转换任务中,来自平面文件的数据将转换为nvarchar数据类型。
In the Lookup control, the configuration is done so no match records will be set to a different path. The following records will not be matched.
在Lookup控件中,配置已完成,因此不会将匹配记录设置为其他路径。 以下记录将不匹配。

However, if you closely analyze mismatch records with the reference data set, you will see that they are not matching, purely because there are few typing mistakes rather than they are completely missing. Therefore, it is better if we can match them using any other techniques such as Fuzzy Lookup in SSIS.
但是,如果您仔细分析不匹配记录与参考数据集,您会发现它们不匹配,这纯粹是因为几乎没有键入错误而不是完全丢失了。 因此,最好使用其他任何技术(例如SSIS中的模糊查找)将它们匹配。
SSIS中的模糊查找 (Fuzzy Lookup in SSIS)
Let us see how fuzzy lookup can be configured.
让我们看看如何配置模糊查找。

First, it has to be a reference table. Though you can use a query in a lookup, in a fuzzy lookup in SSIS, it has to be either a table or a view.
首先,它必须是一个参考表。 尽管您可以在查询中使用查询,但是在SSIS中的模糊查询中,查询必须是表或视图。
An index is used to store the tokenization values. We will discuss the concept of tokenization later. If it is a large table, better to store an index in a table. If the reference table is a static table, which is not changing, you can use an existing index. However, since you are not sure about data changes, it is better to configure, as shown in the above screenshot.
索引用于存储标记化值。 稍后我们将讨论标记化的概念。 如果表很大,最好将索引存储在表中。 如果引用表是不变的静态表,则可以使用现有索引。 但是,由于不确定数据更改,因此最好进行配置,如上面的屏幕快照所示。
If you have selected Store new index option above, you would have to specify whether you also want SQL Server to maintain stored index. To do that, make sure to enable CLR using the following code.
如果您在上面选择了存储新索引选项,则必须指定是否还希望SQL Server 维护存储的索引 。 为此,请确保使用以下代码启用CLR。
EXEC sp_configure 'clr enabled', 1;
RECONFIGURE;
GO
The next step is to define the matching columns from the below screen.
下一步是在下面的屏幕中定义匹配的列。
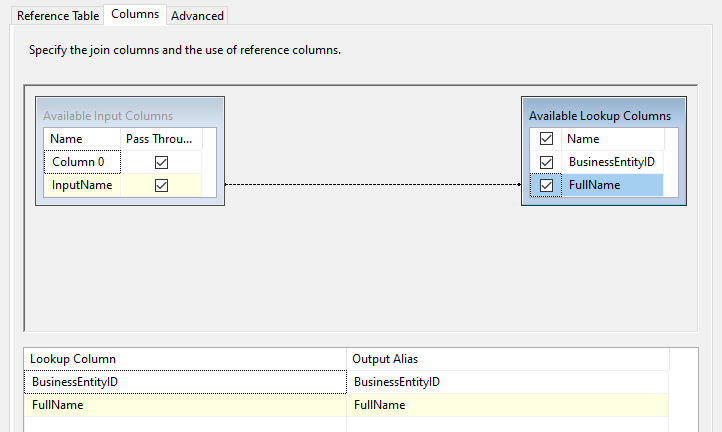
Since this is fuzzy matching, these columns have to be either varchar or nvarchar data types. However, both columns should be of the same data type. In this example, since FullName is nvarchar, the input column data type should be converted to nvarchar.
由于这是模糊匹配,因此这些列必须是varchar或nvarchar数据类型。 但是,两个列都应具有相同的数据类型。 在此示例中,由于FullName为nvarchar,因此应将输入列数据类型转换为nvarchar。
The advanced tab offers further configurations to the Fuzzy Lookup.
高级选项卡为“模糊查找”提供了更多配置。

Since these are not full match attributes, there can be multiple columns that are matching with the reference table. You can define the Maximum number of matches to output per lookup setting. By default, this is 1.
由于这些不是完全匹配属性,因此可以有多个与参考表匹配的列。 您可以定义每个查找设置要输出的最大匹配数 。 默认情况下,该值为1。
Similarity Threshold defined how well it is matching. Typically this threshold is set to a value between 0.75 to 0.80. If this value is close to 1, the attribute is closely matching. Token delimiters will define the tokenization process. Tokenization is a step that splits the text into smaller words or tokens. Larger strings can be tokenized into words, so that fuzzy lookup is done on the tokenized text words.
相似度阈值定义了匹配度。 通常,此阈值设置为0.75至0.80之间的值。 如果该值接近于1,则属性紧密匹配。 令牌定界符将定义令牌化过程。 标记化是将文本分成较小的单词或标记的步骤。 可以将较大的字符串标记为单词,以便对标记的文本单词进行模糊查找。
Now let us execute this SSIS package and verify the results as shown in the below screenshot.
现在,让我们执行此SSIS包并验证结果,如下面的屏幕快照所示。

If we enable the data viewer after the fuzzy lookup, you will see the following data viewer.
如果在模糊查找之后启用数据查看器,您将看到以下数据查看器。

In this data viewer, you will see that the input Name and reference table column, in this case, it is Full Name.
在此数据查看器中,您将看到输入的名称和引用表列,在本例中为全名。
When the _Similarity is 1, it is exactly a match. Confidence defines the quality of the match.
_Similarity为1时,它就是一个匹配项。 置信度定义了比赛的质量。
Next is to work with these confidence levels. We can use a Conditional Split Transformation to define a few rules, as shown in the below screenshot.
接下来是使用这些置信度。 我们可以使用条件拆分转换来定义一些规则,如下面的屏幕快照所示。

Here we have defined, it is fuzzy matched when the confidence is more than 0.5 and if the confidence is between 0.25 to 0.5, it is not sure, but it is likely a match. Similarly, we have defined that if the Confidence is less than 0.25, it is not a match. These values may change depending on the data set that you will be using. It is better to set these values as package configurations so that it can be changed when necessary.
在这里我们定义了,当置信度大于0.5时模糊匹配,如果置信度在0.25到0.5之间,则不确定,但是可能是匹配。 同样,我们已经定义,如果置信度小于0.25,则它不是匹配项。 这些值可能会更改,具体取决于您将使用的数据集。 最好将这些值设置为程序包配置,以便可以在必要时进行更改。
Following is the total implementation of the Fuzzy Lookup and Conditional Split transformation in SSIS, as shown in the below screenshot.
以下是SSIS中模糊查找和条件拆分转换的全部实现,如下面的屏幕快照所示。

Depending on the condition, you may choose different operations. For example, if it is a fuzzy match, you can consider it as a correct match. If it is a no match, it will be an error. Likely, Match means that manual intervention is needed.
根据条件,您可以选择不同的操作。 例如,如果它是模糊匹配,则可以将其视为正确匹配。 如果不匹配,则将是错误。 匹配可能意味着需要人工干预。
Since the fuzzy lookup is a performance incentive task, it is better to use the transformation for only the required data. Therefore, it is better if we can use this fuzzy lookup transformation only for the data, which is not possible with the standard lookup transformation, as shown in the following screenshot.
由于模糊查找是一种性能激励任务,因此最好仅对所需数据使用转换。 因此,最好只对数据使用这种模糊查找转换,这对于标准查找转换是不可能的,如下面的屏幕快照所示。

As you can see in the above screenshot, a standard lookup is done on the data set initially. Only the no matched data is processed through the Fuzzy Lookup is SSIS. Then both streams of data were combined using the Union ALL task.
如您在上面的屏幕快照中所见,最初对数据集进行了标准查找。 通过“ SSIS模糊查找”仅处理不匹配的数据。 然后,使用Union ALL任务合并两个数据流。
模糊分组变换 (Fuzzy Grouping Transformation)
Fuzzy Grouping transformation is used to group the data within the same data set rather than as a matching technique. For example, if you get a list of employees in text files, within the text files, there can be the same name duplicated but with different spellings. Fuzzy Grouping technique can be used to find the same name in the same list.
模糊分组转换用于将同一数据集中的数据分组,而不是作为一种匹配技术。 例如,如果您在文本文件中获得一个雇员列表,则在文本文件中,可能有相同的名称重复,但拼写不同。 模糊分组技术可用于在同一列表中查找相同的名称。
最佳实践 (Best Practices)
- We have used the only attribute for comparison. Since this is partial matching, it is better to use as much as attributes possible. You will get the similarities for each column 我们使用了only属性进行比较。 由于这是部分匹配,因此最好使用尽可能多的属性。 您将获得每一列的相似之处
- When deciding what columns to match, make sure to choose columns that have a number of distinct values rather than more common values 在决定要匹配的列时,请确保选择具有多个不同值而不是更常见值的列
- Though in standard queries, NULL is not equal to another NULL, in case of fuzzy matching, it is equal. Therefore, it is important to avoid NULL values in both the input and output 尽管在标准查询中,NULL不等于另一个NULL,但在模糊匹配的情况下,它是相等的。 因此,重要的是在输入和输出中都避免使用NULL值
结论 (Conclusion)
Data Cleansing is an important technique in data analysis as non-cleaned data may result in wrong decisions. The Fuzzy Lookup in SSIS is a sophisticated method that can be used to clean data. However, there are performance issues with Fuzzy Lookup that has to be used accordingly.
数据清理是数据分析中的一项重要技术,因为未清理的数据可能会导致错误的决策。 SSIS中的模糊查找是一种可用于清除数据的复杂方法。 但是,必须使用模糊查找的性能问题。
翻译自: https://www.sqlshack.com/fuzzy-lookup-transformations-in-ssis/
ssis高级转换任务—查找