Elastic Search(二)Elastic Search基本操作
文章目录
- 二 Elastic Search 基础操作
-
- 2.1 索引操作
-
- 2.1.1 可视化工具
- 2.1.2 创建索引
- 2.1.3 删除索引
- 2.1.4 关闭索引
- 2.1.5 打开索引
- 2.1.6 索引别名
- 2.2 数据隐射
-
- 2.2.1 查看隐射
- 2.2.2 扩展隐射
- 2.3 基本数据类型
-
- 2.3.1 keyword类型
- 2.3.2 text数据类型
- 2.3.3 数值类型
- 2.3.4 布尔类型
- 2.3.5 日期类型
- 2.3.6 数组类型
- 2.3.7 对象类型
- 2.3.8 地理类型
- 2.3.9动态隐射
- 2.4 文档操作
-
- 2.4.1 文档写入
- 2.4.2 批量写入
- 2.4.3 更新文档
- 2.4.4 批量更新
- 2.4.5 条件更新
- 2.4.6 删除文档
- 2.4.7 批量删除
- 2.4.8 文档搜索
- 2.4.9 结果计数
- 2.4.10 结果分页
- 2.5 匹配功能
-
- 2.5.1 查询所有文档
- 2.5.2 term查询
- 2.5.3 terms查询
- 2.5.4 range查询
- 2.5.5 exits查询
- 2.6 布尔查询
-
- 2.6.1 must查询
- 2.6.2 should查询
- 2.6.3 must not 查询
- 2.6.4 filter查询
- 2.7 全文搜索
-
- 2.7.1 match搜索
- 2.7.2 multi_match查询
- 2.7.3 match_phrase查询
二 Elastic Search 基础操作
2.1 索引操作
索引的相关操作,涉及创建、删除、关闭和打开索引,以及索引别名的操作。其中,索引别名的操作在生产环境中使用比较广泛,可以和关闭或删除索引配合使用。在生产环境中使用索引时,一定要慎重操作,因为稍有不慎就会导致数据的丢失或异常。
2.1.1 可视化工具
2.1.2 创建索引
使用ES构建搜索引擎的第一步是创建索引。在创建索引时,可以按照实际需求对索引进行主分片和副分片设置。ES创建索引的请求类型为PUT,其请求形式如下:
PUT/$ {index_name]{
"settings": {},
"mappings": {}
}
其中:变量index_name就是创建的目标索引名称;可以在settings子句内部填写索引相关的设置项,如主分片个数和副分片个数等;可以在mappings子句内部填写数据组织结构,即数据映射。
{
"settings": {
"number_of_shards" : 10, // 主分区
"number_of_replicas" : 2 // 副分区
},
"mappings": {} // 数据隐射
}
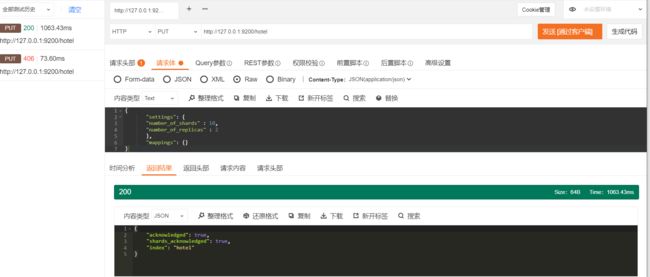
2.1.3 删除索引
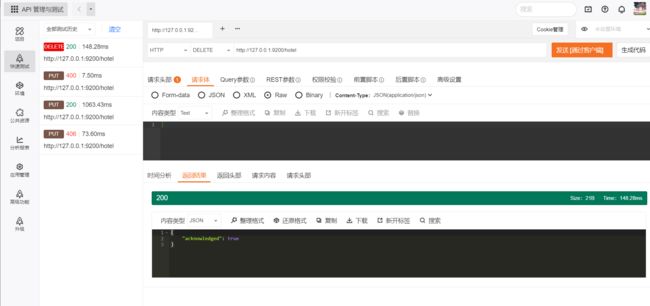
ES中删除索引的请求类型是DELETE,其请求形式如下:
DELETE /$ {index_name]
2.1.4 关闭索引
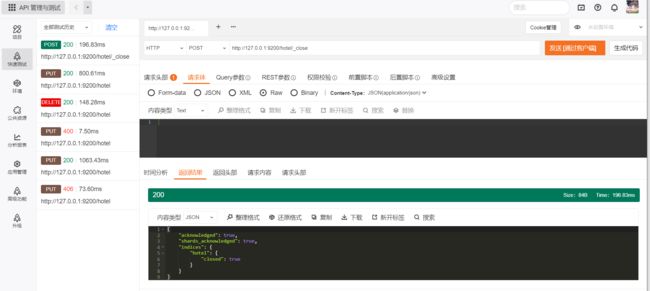
在有些场景下,某个索引暂时不使用,但是后期可能又会使用,这里的使用是指数据写入和数据搜索。这个索引在某一时间段内属于冷数据或者归档数据,这时可以使用索引的关闭功能。索引关闭时,只能通过ES的API或者监控工具看到索引的元数据信息,但是此时该索引不能写入和搜索数据,待该索引被打开后,才能写入和搜索数据。
POST /$ {index_name]/_close
2.1.5 打开索引
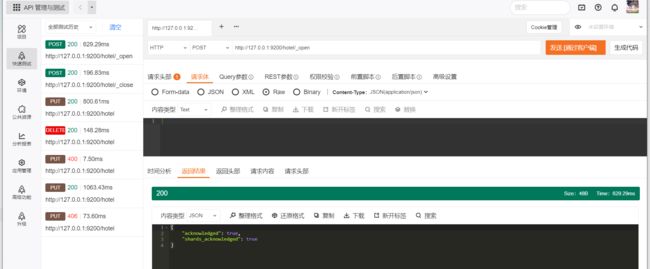
索引关闭后,需要开启读写服务时可以将其设置为打开状态。下面的示例是把处于关闭状态的hotel索引设置为打开状态。
POST/$ {index_name]/_open
2.1.6 索引别名
顾名思义,别名是指给一个或者多个索引定义另外一个名称,使索引别名和索引之间可以建立某种逻辑关系。
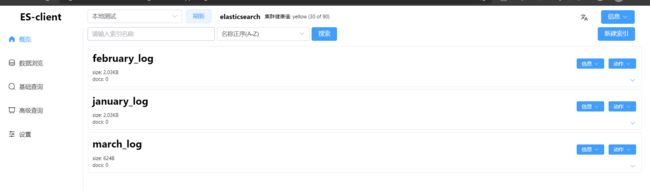
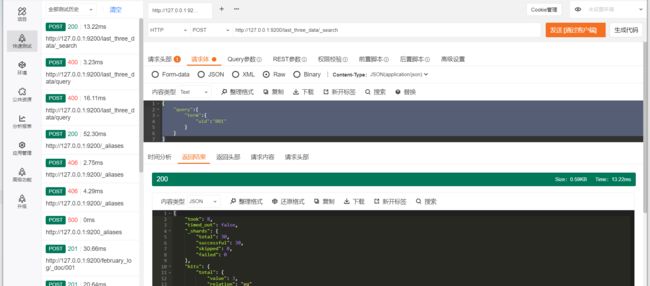
例如,我们建立了1月、2月、3月的用户入住酒店的日志索引,假设当前日期是4月1日,需要搜索过去的3个月的日志索引,如果分别去3个索引中进行搜索,这种编码方案比较低效。此时可以创建一个别名last_three_month,设置前面的3个索引的别名为last_three_month,然后在last_three_month中进行搜索即可。如图3.1所示,last_three_month包含january_log、february_log和march_log3个索引,用户请求在last_three_month中进行搜索时,ES会在上述3个索引中进行搜索。
{
"settings": {
"number_of_shards" : 10, // 主分区
"number_of_replicas" : 2 // 副分区
},
"mappings": {
"properties":{
"uid":{
"type":"keyword"
},
"hotel_id":{
"type":"keyword"
},
"time":{
"type":"keyword"
}
}
}
}
添加数据
{
"uid":"001",
"hotel_id":"1001",
"time":"2022-2-20"
}
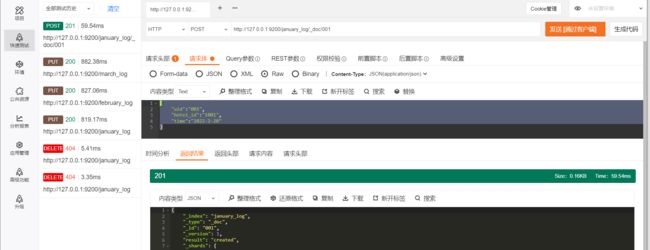
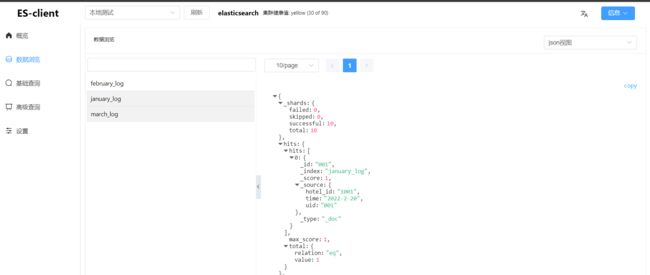
建立别名
{
"actions":[
{
"add":{
"index":"march_log",
"alias":"last_three_data"
}
},
{
"add":{
"index":"january_log",
"alias":"last_three_data"
}
},
{
"add":{
"index":"february_log",
"alias":"last_three_data"
}
}
]
}
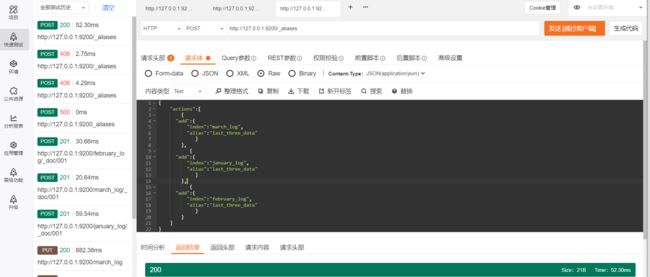
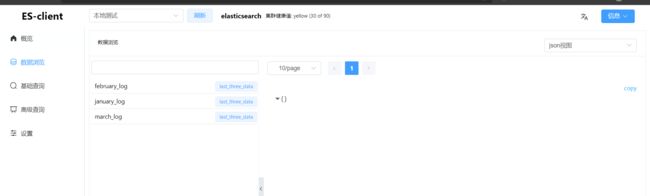
查询
{
"query":{
"term":{
"uid":"001"
}
}
}
2.2 数据隐射
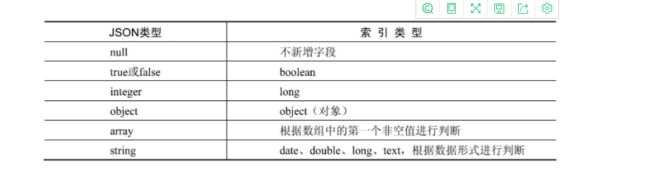
在使用数据之前,需要构建数据的组织结构。这种组织结构在关系型数据库中叫作表结构,在ES中叫作映射。作为无模式搜索引擎,ES可以在数据写入时猜测数据类型,从而自动创建映射。但有时ES创建的映射中的数据类型和目标类型可能不一致。当需要严格控制数据类型时,还是需要用户手动创建映射。
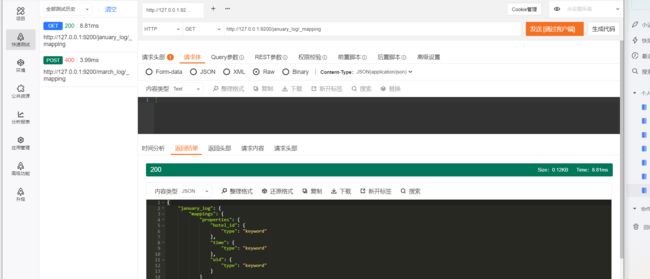
2.2.1 查看隐射
GET/$ {index_name]/ _mapping
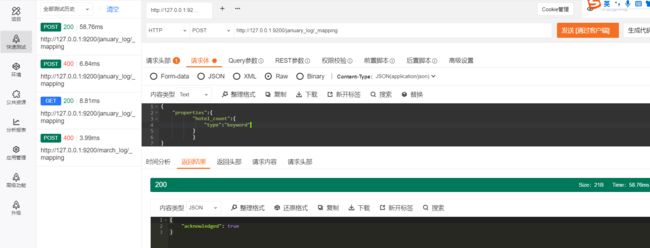
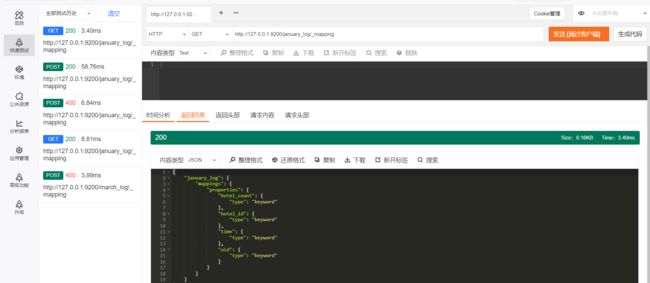
2.2.2 扩展隐射
可能有的读者看到标题时会有疑问:映射不能修改吗?为什么是扩展呢?答案是,映射中的字段类型是不可以修改的,但是字段可以扩展。最常见的扩展方式是增加字段和为object(对象)类型的数据新增属性。
{
"properties":{
"hotel_count":{
"type":"keyword"
}
}
}
2.3 基本数据类型
2.3.1 keyword类型
keyword类型是不进行切分的字符串类型。这里的“不进行切分”指的是:在索引时,对keyword类型的数据不进行切分,直接构建倒排索引;在搜索时,对该类型的查询字符串不进行切分后的部分匹配。keyword类型数据一般用于对文档的过滤、排序和聚合。
在现实场景中,keyword经常用于描述姓名、产品类型、用户ID、URL和状态码等。keyword类型数据一般用于比较字符串是否相等,不对数据进行部分匹配,因此一般查询这种类型的数据时使用term查询。

2.3.2 text数据类型
text类型是可进行切分的字符串类型。这里的“可切分”指的是:在索引时,可按照相应的切词算法对文本内容进行切分,然后构建倒排索引;在搜索时,对该类型的查询字符串按照用户的切词算法进行切分,然后对切分后的部分匹配打分。

2.3.3 数值类型
ES支持的数值类型有long、integer、short、byte、double、float、half_float、scaled_float和unsigned_long等。
为节约存储空间并提升搜索和索引的效率,在实际应用中,在满足需求的情况下应尽可能选择范围小的数据类型。

2.3.4 布尔类型
布尔类型使用boolean定义,用于业务中的二值表示,如商品是否售罄,房屋是否已租,酒店房间是否满房等。写入或者查询该类型的数据时,其值可以使用true和false,或者使用字符串形式的"true"和"false"。

2.3.5 日期类型
在ES中,日期类型的名称为date。ES中存储的日期是标准的UTC格式。
日期类型的默认格式为strict_date_optional_time||epoch_millis。其中,strict_date_optional_time的含义是严格的时间类型,支持yyyy-MM-dd、yyyyMMdd、yyyyMMddHHmmss、yyyy-MM-ddTHH:mm:ss、yyyy-MM-ddTHH:mm:ss.SSS和yyyy-MM-ddTHH:mm:ss.SSSZ等格式,epoch_millis的含义是从1970年1月1日0点到现在的毫秒数。
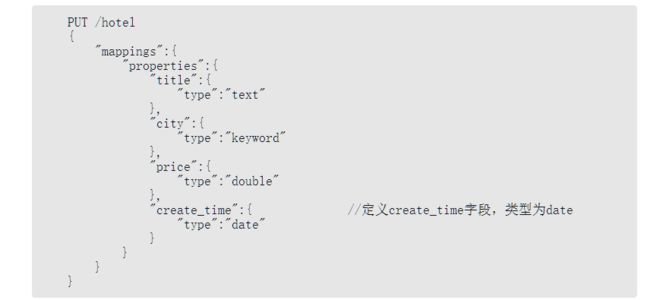
2.3.6 数组类型
ES数组没有定义方式,其使用方式是开箱即用的,即无须事先声明,在写入时把数据用中括号[]括起来,由ES对该字段完成定义。

2.3.7 对象类型
在实际业务中,一个文档需要包含其他内部对象。例如,在酒店搜索需求中,用户希望酒店信息中包含评论数据。评论数据分为好评数量和差评数量。为了支持这种业务,在ES中可以使用对象类型。和数组类型一样,对象类型也不用事先定义,在写入文档的时候ES会自动识别并转换为对象类型。

2.3.8 地理类型
在移动互联网时代,用户借助移动设备产生的消费也越来越多。例如,用户需要根据某个地理位置来搜索酒店,此时可以把酒店的经纬度数据设置为地理数据类型。该类型的定义需要在mapping中指定目标字段的数据类型为geo_point类型。

2.3.9动态隐射
当字段没有定义时,ES可以根据写入的数据自动定义该字段的类型,这种机制叫作动态映射。
2.4 文档操作
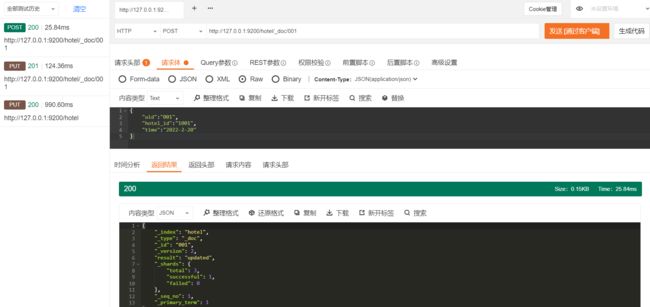
2.4.1 文档写入
在ES中写入文档请求的类型是POST,其请求形式如下:
POST /$ {index_name}l_doc/$ i_id}{
//写入的文档数据
}
{
"uid":"001",
"hotel_id":"1001",
"time":"2022-2-20"
}
Java高级REST客户端
/**
* 单条写入文档
* @param dataMap 需要写入的数据
* @param indexName 索引名
* @param indexId 索引id
*/
public void singleIndexDoc(Map<String,Object> dataMap,String indexName,String indexId){
IndexRequest request = new IndexRequest(indexName).id(indexId).source(dataMap);
try{
// 响应的结果
IndexResponse response = restHighLevelClient.index(request, RequestOptions.DEFAULT);
// 索引名称
String index = response.getIndex();
// 文档id
String responseId = response.getId();
// 文档版本
long version = response.getVersion();
System.out.println("xxx"+index+"yyy"+responseId+"zzz"+version);
}catch (Exception e){
e.printStackTrace();
}
2.4.2 批量写入
在ES中批量写入文档请求的类型是POST,其请求形式如下:
一般使用Linux系统中的curl命令进行数据的批量写入。curl命令支持上传文件,用户可以将批量写入的JSON数据保存到文件中,然后使用curl命令进行提交。

POST /_bulk
{
{"index" : {"_index" :"$ {index_name]"l}
{"index" :{"_index" :"$ {index_name}"]}
}
Java高级REST客户端
/**
* 批量写入文档
* @param indexName
* @param docIdKey
* @param recordMapList
*/
public void bulkIndexDoc(String indexName, String docIdKey, List<Map<String ,Object>> recordMapList){
BulkRequest request = new BulkRequest(indexName);
for (Map<String, Object> map : recordMapList) {
String s = map.get(docIdKey).toString();
IndexRequest indexRequest = new IndexRequest().id(s).source(map);
request.add(indexRequest);
}
request.timeout(TimeValue.timeValueSeconds(5));
try {
BulkResponse responses = restHighLevelClient.bulk(request, RequestOptions.DEFAULT);
if(responses.hasFailures()){
System.out.println("错误的消息"+responses.buildFailureMessage());
}
}catch (Exception e){
e.printStackTrace();
}
}
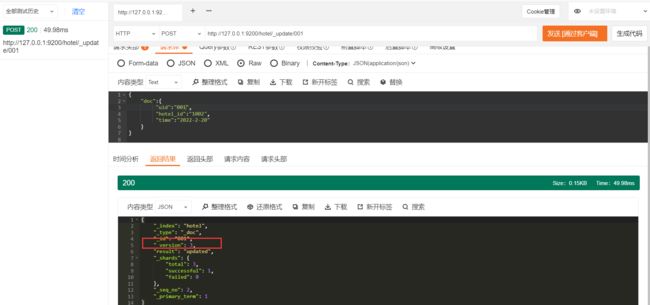
2.4.3 更新文档
在ES中更新索引的请求类型是POST,其请求形式如下:
POST/$ {index_name}/_update/$ {_id}
{
// 更新内容
}
{
"doc":{
"uid":"001",
"hotel_id":"1002",
"time":"2022-2-20"
}
}
Java高级REST客户端
/**
* 更新文档
* @param indexName
* @param docIdKey
* @param dataMap
*/
public void singleUpdate(String indexName,String docIdKey,Map<String,Object> dataMap){
UpdateRequest request = new UpdateRequest(indexName, docIdKey);
request.doc(dataMap);
// 不存在,就插入
request.upsert(dataMap);
try {
UpdateResponse response = restHighLevelClient.update(request, RequestOptions.DEFAULT);
// 索引名称
String index = response.getIndex();
// 文档id
String responseId = response.getId();
// 文档版本
long version = response.getVersion();
System.out.println("xxx"+index+"yyy"+responseId+"zzz"+version);
}catch (Exception e){
e.printStackTrace();
}
}
2.4.4 批量更新
与批量写入文档相似,批量更新文档的请求形式如下:

Java高级REST客户端
/**
* 批量更新
* @param indexName
* @param docIdKey
* @param recordMapList
*/
public void bulkUpdate(String indexName, String docIdKey, List<Map<String ,Object>> recordMapList){
BulkRequest request = new BulkRequest(indexName);
for (Map<String, Object> map : recordMapList) {
String s = map.get(docIdKey).toString();
map.remove(s);
request.add(new UpdateRequest(indexName,docIdKey).doc(map));
}
request.timeout(TimeValue.timeValueSeconds(5));
try {
BulkResponse responses = restHighLevelClient.bulk(request, RequestOptions.DEFAULT);
if(responses.hasFailures()){
System.out.println("错误的消息"+responses.buildFailureMessage());
}
}catch (Exception e){
e.printStackTrace();
}
}
2.4.5 条件更新
在索引数据的更新操作中,有些场景需要根据某些条件同时更新多条数据,类似于在RDBMS中使用update table table_name set…where…更新一批数据。为了满足这样的需求,ES为用户提供了_update_by_query功能。

{
"query":{
"term":{
"hotel_id":{
"value":"1002"
}
}
},
"script":{
"source":"ctx._source['hotel_id']='1003'",
"lang":"painless"
}
}
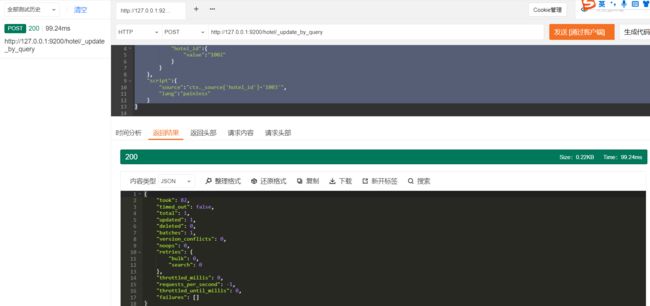
Java高级REST客户端
/**
* 查询更新
* @param index
* @param oldHotelId
* @param newHotelId
*/
public void updateBySearch(String index,String oldHotelId,String newHotelId){
UpdateByQueryRequest request = new UpdateByQueryRequest(index);
request.setQuery(new TermQueryBuilder("hotel_id",oldHotelId));
request.setScript(new Script("ctx._source['hotel_id']=’"+newHotelId+";"));
try {
restHighLevelClient.updateByQuery(request,RequestOptions.DEFAULT);
}catch (Exception e){
e.printStackTrace();
}
}
2.4.6 删除文档
在ES中删除文档的请求的类型是DELETE,其请求形式如下:
DELETE/$ {index_name] / _doc/$ {_id}
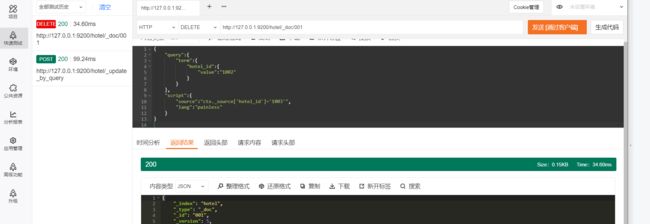
Java高级REST客户端
/**
* 删除文档
* @param index
* @param docId
*/
public void singleDelete(String index,String docId){
DeleteRequest request = new DeleteRequest(index, docId);
try{
restHighLevelClient.delete(request,RequestOptions.DEFAULT);
}catch (Exception e){
e.printStackTrace();
}
}
2.4.7 批量删除
与批量写入和更新文档不同的是,批量删除文档不需要提供JSON数据,其请求形式如下:

Java高级REST客户端
/**
* 批量删除
* @param index
* @param dicIdKey
* @param docIdList
*/
public void bulkDelete(String index,String dicIdKey,List<String> docIdList){
BulkRequest request = new BulkRequest();
for (String s : docIdList) {
DeleteRequest deleteRequest = new DeleteRequest(index, s);
request.add(deleteRequest);
}
try {
BulkResponse responses = restHighLevelClient.bulk(request, RequestOptions.DEFAULT);
if(responses.hasFailures()){
System.out.println("错误的消息"+responses.buildFailureMessage());
}
}catch (Exception e){
e.printStackTrace();
}
}
2.4.8 文档搜索

详细使用后面介绍
2.4.9 结果计数
为提升搜索体验,需要给前端传递搜索匹配结果的文档条数,即需要对搜索结果进行计数。针对这个要求,ES提供了_count API功能,在该API中,用户提供query子句用于结果匹配,ES会返回匹配的文档条数。

2.4.10 结果分页
- 在实际的搜索应用中,分页是必不可少的功能。在默认情况下,ES返回前10个搜索匹配的文档。用户可以通过设置from和size来定义搜索位置和每页显示的文档数量,from表示查询结果的起始下标,默认值为0,size表示从起始下标开始返回的文档个数,默认值为10。
- 对于普通的搜索应用来说,size设为10 000已经足够用了。如果确实需要返回多于10 000条的数据,可以适当修改max_result_window的值。
- 作为一个分布式搜索引擎,一个ES索引的数据分布在多个分片中,而这些分片又分配在不同的节点上。一个带有分页的搜索请求往往会跨越多个分片,每个分片必须在内存中构建一个长度为from+size的、按照得分排序的有序队列,用以存储命中的文档。然后这些分片对应的队列数据都会传递给协调节点,协调节点将各个队列的数据进行汇总,需要提供一个长度为number_of_shards*(from+size)的队列用以进行全局排序,然后再按照用户的请求从from位置开始查找,找到size个文档后进行返回。
- 作为搜索引擎,ES更适合的场景是对数据进行搜索,而不是进行大规模的数据遍历。一般情况下,只需要返回前1000条数据即可,没有必要取到10 000条数据。

2.5 匹配功能
2.5.1 查询所有文档
- 在关系型数据库中,当需要查询所有文档的数据时,对应的SQL语句为select*form table_name。
- 在ES中是否有类似的功能呢?答案是“有”,使用ES的match_all查询可以完成类似的功能。使用match_all查询文档时,ES不对文档进行打分计算,默认情况下给每个文档赋予1.0的得分。

2.5.2 term查询
term查询是结构化精准查询的主要查询方式,用于查询待查字段和查询值是否完全匹配.

2.5.3 terms查询
terms查询是term查询的扩展形式,用于查询一个或多个值与待查字段是否完全匹配。
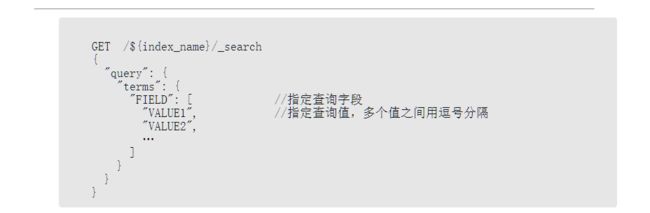
2.5.4 range查询
range查询用于范围查询,一般是对数值型和日期型数据的查询。使用range进行范围查询时,用户可以按照需求中是否包含边界数值进行选项设置,可供组合的选项如下:·gt:大于;·lt:小于;·gte:大于或等于;·lte:小于或等于。
2.5.5 exits查询
在某些场景下,我们希望找到某个字段不为空的文档,则可以用exists搜索。
2.6 布尔查询
复合搜索,顾名思义是一种在一个搜索语句中包含一种或多种搜索子句的搜索。布尔查询是常用的复合查询,它把多个子查询组合成一个布尔表达式,这些子查询之间的逻辑关系是“与”,即所有子查询的结果都为true时布尔查询的结果才为真。

2.6.1 must查询
当查询中包含must查询时,相当于逻辑查询中的“与”查询。命中的文档必须匹配该子查询的结果,并且ES会将该子查询与文档的匹配程度值加入总得分里。must搜索包含一个数组,可以把其他的term级别的查询及布尔查询放入其中。
2.6.2 should查询
当查询中包含should查询时,表示当前查询为“或”查询。命中的文档可以匹配该查询中的一个或多个子查询的结果,并且ES会将该查询与文档的匹配程度加入总得分里。should查询包含一个数组,可以把其他的term级别的查询及布尔查询放入其中。
2.6.3 must not 查询
当查询中包含must not查询时,表示当前查询为“非”查询。命中的文档不能匹配该查询中的一个或多个子查询的结果,ES会将该查询与文档的匹配程度加入总得分里。must not查询包含一个数组,可以把其他term级别的查询及布尔查询放入其中。
2.6.4 filter查询
filter查询即过滤查询,该查询是布尔查询里非常独特的一种查询。其他布尔查询关注的是查询条件和文档的匹配程度,并按照匹配程度进行打分;而filter查询关注的是查询条件和文档是否匹配,不进行相关的打分计算,但是会对部分匹配结果进行缓存。
2.7 全文搜索
不同于结构化查询,全文搜索首先对查询词进行分析,然后根据查询词的分词结果构建查询。这里所说的全文指的是文本类型数据(text类型),默认的数据形式是人类的自然语言,如对话内容、图书名称、商品介绍和酒店名称等。
结构化搜索关注的是数据是否匹配,全文搜索关注的是匹配的程度;结构化搜索一般用于精确匹配,而全文搜索用于部分匹配。本节将详细介绍使用最多的全文搜索
2.7.1 match搜索
match查询是全文搜索的主要代表。对于最基本的math搜索来说,只要分词中的一个或者多个在文档中存在即可。
2.7.2 multi_match查询
有时用户需要在多个字段中查询关键词,除了使用布尔查询封装多个match查询之外,可替代的方案是使用multi_match。
2.7.3 match_phrase查询
match_phrase用于匹配短语,与match查询不同的是,match_phrase用于搜索确切的短语或邻近的词语。