Hadoop 启动 HDFS DataNode 时报错Error: JAVA_HOME is not set and could not be found.
目录
- 环境描述
- 问题现象
- 问题分析
-
- SSH 远程执行命令
- bash 的四种模式
-
- interactive + login shell
- non-interactive + login shell
- interactive + non-login shell
- non-interactive + non-login shell
- 解决方案
- 总结
我创建了一个 《Hadoop 成神之路》的星球,大家有Hadoop 相关的问题可以直接在星球里向我提问,有问必答:https://t.zsxq.com/05JImq37u
环境描述
- 操作系统:CentOS 6.5
- Hadoop:Apache Hadoop 2.7.7
问题现象
修改好配置文件,准备启动 HDFS DataNode 时,报错:
[hdfs@slave1 hadoop-2.7.7]$ $HADOOP_PREFIX/sbin/hadoop-daemons.sh --config $HADOOP_CONF_DIR --script hdfs start datanode
slave2: Error: JAVA_HOME is not set and could not be found.
slave1: Error: JAVA_HOME is not set and could not be found.
slave3: Error: JAVA_HOME is not set and could not be found.
问题分析
从报错信息上看,应该是JAVA_HOME 这个环境变量没有配置导致的,但其实我的环境变量是在/etc/profile中配置过的:
export JAVA_HOME=/data/software/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
而且hadoop-env.sh配置文件中也配置了 JAVA_HOME相应的值:
export JAVA_HOME=${JAVA_HOME}
正常情况下,hadoop-env.sh运行时会从系统环境变量中寻找JAVA_HOME并替换这里的值的,但显然这里是没找到,需要再继续分析它为何没从环境变量中找到。
(!)其实这里如果为了快速解决问题的话,可以直接把 hadoop-env.sh 中的 JAVA_HOME 配置成 java 目录的绝对路径,这样就不涉及到 hadoop-env.sh 从环境变量中找 JAVA_HOME 了。
SSH 远程执行命令
从头开始分析,我运行的是 $HADOOP_PREFIX/sbin/hadoop-daemons.sh 这个脚本,看看它是怎么跟JAVA_HOME挂上钩的:
[hdfs@slave1 hadoop-2.7.7]$ cat $HADOOP_PREFIX/sbin/hadoop-daemons.sh
#!/usr/bin/env bash
# Run a Hadoop command on all slave hosts.
usage="Usage: hadoop-daemons.sh [--config confdir] [--hosts hostlistfile] [start|stop] command args..."
# if no args specified, show usage
if [ $# -le 1 ]; then
echo $usage
exit 1
fi
bin=`dirname "${BASH_SOURCE-$0}"`
bin=`cd "$bin"; pwd`
DEFAULT_LIBEXEC_DIR="$bin"/../libexec
HADOOP_LIBEXEC_DIR=${HADOOP_LIBEXEC_DIR:-$DEFAULT_LIBEXEC_DIR}
. $HADOOP_LIBEXEC_DIR/hadoop-config.sh
exec "$bin/slaves.sh" --config $HADOOP_CONF_DIR cd "$HADOOP_PREFIX" \; "$bin/hadoop-daemon.sh" --config $HADOOP_CONF_DIR "$@"
注意到 hadoop-daemons.sh 最后一行是调用了 slaves.sh,继续看 slaves.sh 是如何实现的:
[hdfs@slave1 hadoop-2.7.7]$ cat $HADOOP_PREFIX/sbin/slaves.sh
#!/usr/bin/env bash
usage="Usage: slaves.sh [--config confdir] command..."
# if no args specified, show usage
if [ $# -le 0 ]; then
echo $usage
exit 1
fi
bin=`dirname "${BASH_SOURCE-$0}"`
bin=`cd "$bin"; pwd`
DEFAULT_LIBEXEC_DIR="$bin"/../libexec
HADOOP_LIBEXEC_DIR=${HADOOP_LIBEXEC_DIR:-$DEFAULT_LIBEXEC_DIR}
. $HADOOP_LIBEXEC_DIR/hadoop-config.sh
if [ -f "${HADOOP_CONF_DIR}/hadoop-env.sh" ]; then
. "${HADOOP_CONF_DIR}/hadoop-env.sh"
fi
# Where to start the script, see hadoop-config.sh
# (it set up the variables based on command line options)
if [ "$HADOOP_SLAVE_NAMES" != '' ] ; then
SLAVE_NAMES=$HADOOP_SLAVE_NAMES
else
SLAVE_FILE=${HADOOP_SLAVES:-${HADOOP_CONF_DIR}/slaves}
SLAVE_NAMES=$(cat "$SLAVE_FILE" | sed 's/#.*$//;/^$/d')
fi
# start the daemons
for slave in $SLAVE_NAMES ; do
ssh $HADOOP_SSH_OPTS $slave $"${@// /\\ }" \
2>&1 | sed "s/^/$slave: /" &
if [ "$HADOOP_SLAVE_SLEEP" != "" ]; then
sleep $HADOOP_SLAVE_SLEEP
fi
done
wait
看到最后一个 for 循环里,对于每个 slave 节点,都会通过 SSH 去连接并执行一串命令来启动程序。怀疑是通过 SSH 执行远程命令时加载环境变量有问题,进一步排除下:
在这个 for 循环代码前面,加一行日志:
echo "slaves.sh get JAVA_HOME values is: "$JAVA_HOME
# start the daemons
for slave in $SLAVE_NAMES ; do
ssh $HADOOP_SSH_OPTS $slave $"${@// /\\ }" \
2>&1 | sed "s/^/$slave: /" &
if [ "$HADOOP_SLAVE_SLEEP" != "" ]; then
sleep $HADOOP_SLAVE_SLEEP
fi
done
再运行一次,来确认脚本在运行到 SSH 命令之前,是否能获取到 JAVA_HOME。再次运行后日志里打印出:
slaves.sh get JAVA_HOME values is: /data/software/jdk1.8.0_144
显然,整个流程从 hadoop-daemons.sh 开始,hadoop-daemons.sh 调 slaves.sh,slaves.sh 本身是能获取到 JAVA_HOME的,但是通过 SSH 去远程服务器执行命令时,这个JAVA_HOME值就丢了。
bash 的四种模式
通过以下方式可以确认一下通过 SSH 执行远程命令时,环境变量是否有问题:
[hdfs@slave1 hadoop-2.7.7]$ ssh slave2 "env"
XDG_SESSION_ID=34
SHELL=/bin/bash
SSH_CLIENT=192.168.90.36 42818 22
USER=hdfs
MAIL=/var/mail/hdfs
PATH=/usr/local/bin:/usr/bin
PWD=/home/hdfs
LANG=zh_CN.UTF-8
SHLVL=1
HOME=/home/hdfs
LOGNAME=hdfs
SSH_CONNECTION=192.168.90.36 42818 192.168.90.37 22
LESSOPEN=||/usr/bin/lesspipe.sh %s
XDG_RUNTIME_DIR=/run/user/1001
_=/usr/bin/env
[hdfs@slave1 hadoop-2.7.7]$ ssh slave2 "echo $JAVA_HOME"
[空]
打印结果env里没有JAVA_HOME。说明 slave1 通过 SSH 让 slave2 执行命令时,slave2 并没有先执行 /etc/profile ,这跟我平时的理解是有出入的,/etc/profile作为优先级最高的配置文件,为何不先加载呢?
同时,如果 slave1 先通过 SSH 登录到 slave2 上,然后再执行 echo $JAVA_HOME,这样就能正常加载出来:
[deploy@slave2 ~]$ echo $JAVA_HOME
/data/software/jdk1.8.0_144
这说明,通过 SSH 执行执行命令,和 先 SSH 登录再执行命令,这两种方式,是有区别的。
通过这篇文章:http://feihu.me/blog/2014/env-problem-when-ssh-executing-command-on-remote/ 才搞明白,原来 bash 是分四种模式的:
interactive + login shell
第一种模式是交互式的登陆shell,这里面有两个概念需要解释:interactive和login:
login故名思义,即登陆,login
shell是指用户以非图形化界面或者以ssh登陆到机器上时获得的第一个shell,简单些说就是需要输入用户名和密码的shell。因此通常不管以何种方式登陆机器后用户获得的第一个shell就是login
shell。interactive意为交互式,这也很好理解,interactive
shell会有一个输入提示符,并且它的标准输入、输出和错误输出都会显示在控制台上。所以一般来说只要是需要用户交互的,即一个命令一个命令的输入的shell都是interactive
shell。而如果无需用户交互,它便是non-interactive shell。通常来说如bash
script.sh此类执行脚本的命令就会启动一个non-interactive
shell,它不需要与用户进行交互,执行完后它便会退出创建的shell。那么此模式最简单的两个例子为:
用户直接登陆到机器获得的第一个shell 用户使用ssh user@remote获得的shell
non-interactive + login shell
第二种模式的shell为non-interactive login
shell,即非交互式的登陆shell,这种是不太常见的情况。一种创建此shell的方法为:bash -l
script.sh,前面提到过-l参数是将shell作为一个login shell启动,而执行脚本又使它为non-interactive
shell。
interactive + non-login shell
第三种模式为交互式的非登陆shell,这种模式最常见的情况为在一个已有shell中运行bash,此时会打开一个交互式的shell,而因为不再需要登陆,因此不是login shell。
non-interactive + non-login shell
最后一种模式为非交互非登陆的shell,创建这种shell典型有两种方式:
bash script.sh ssh user@remote command
这两种都是创建一个shell,执行完脚本之后便退出,不再需要与用户交互。
bash 会依据这四种模式而选择加载不同的配置文件,而且加载的顺序也有所不同,更直观的配置文件加载顺序可以看这个图:
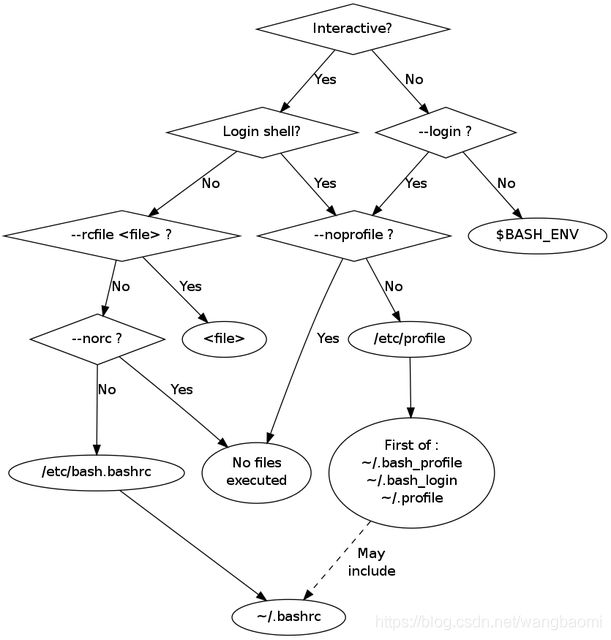
解决方案
回头再看下slaves.sh里的那个for循环:
# start the daemons
for slave in $SLAVE_NAMES ; do
ssh $HADOOP_SSH_OPTS $slave $"${@// /\\ }" \
2>&1 | sed "s/^/$slave: /" &
if [ "$HADOOP_SLAVE_SLEEP" != "" ]; then
sleep $HADOOP_SLAVE_SLEEP
fi
done
for 循环里的 SSH 执行命令的方式,其实属于 bash 的 non-interactive + non-login shell 模式,这种模式只会读取 $BASH_ENV里的配置文件,不会读取 /etc/profile 文件。
看看 $BASH_ENV 是哪个配置文件:
[hdfs@slave2 ~]$ echo $BASH_ENV
[空]
既然 $BASH_ENV 是空的,那这种方式就不会加载任何文件,也就拿不到JAVA_HOME的值了。
但是,等等,回过头来再看下之前这个命令:
[hdfs@slave1 hadoop-2.7.7]$ ssh slave2 "env"
XDG_SESSION_ID=34
SHELL=/bin/bash
SSH_CLIENT=192.168.90.36 42818 22
USER=hdfs
MAIL=/var/mail/hdfs
PATH=/usr/local/bin:/usr/bin
PWD=/home/hdfs
LANG=zh_CN.UTF-8
SHLVL=1
HOME=/home/hdfs
LOGNAME=hdfs
SSH_CONNECTION=192.168.90.36 42818 192.168.90.37 22
LESSOPEN=||/usr/bin/lesspipe.sh %s
XDG_RUNTIME_DIR=/run/user/1001
_=/usr/bin/env
[hdfs@slave1 hadoop-2.7.7]$ ssh slave2 "echo $JAVA_HOME"
[空]
虽然 slave1 通过 SSH 的 non-interactive + non-login shell 模式去 slave2 执行命令时,由于没有加载到任何配置文件,也就理所当然地没有加载到JAVA_HOME,但是为什么 env命令会打印出那么多信息呢?不是任何配置文件都不加载么?
答案还是在 bash 的 man page 里:
Bash attempts to determine when it is being run with its standard input connected to a network connection, as when executed by the remote shell daemon, usually rshd, or the secure shell daemon sshd. If bash determines it is being run in this fashion, it reads and executes commands from ~/.bashrc, if that file exists and is readable. It will not do this if invoked as sh. The --norc option may be used to inhibit this behavior, and the --rcfile option may be used to force another file to be read, but rshd does not generally invoke the shell with those options or allow them to be specified.
大意是,bash 会尝试确认它是不是在 ssh 这种方式下运行的,如果是,那 bash 会加载 ~/.bashrc 配置文件。
所以,通过 SSH 执行 non-interactive + non-login shell 模式下的 bash 时,bash 会加载~/.bashrc文件,我们只需要在~/.bashrc中设置JAVA_HOME即可,或者在~/.bashrc中将BASH_ENV设置为/etc/profile:
export BASH_ENV=/etc/profile
总结
man page 很重要,bash 这种自以为很熟悉的东西,可能自己知道的只有它自身功能的1/1000都不到…