Python基础学习-简要记录
目录
-
- 快捷键
- 基础
-
- 1.字符串
- 2.变量
- 3.序列
- 4.列表
- 5.元组
- 6.字典
- 7.集合
- 8.time 模块
- 9.datetime 模块
-
- date
- time
- datetime 类
- 10.calendar 模块
-
- Calendar 类
- TextCalendar 类
- HTMLCalendar类
- 11.函数
- 12.模块与包
-
- 引用
- 13.对象
-
- 类
- 对象
- 继承
- 14.文件
-
- 创建
- 写入
- 读取
- 定位
- 15.os 模块
- 16.错误和异常
-
- 异常处理
- 17.枚举
- 18.迭代器与生成器
-
- 可迭代对象
- 迭代器
- 生成器
- 19.装饰器
-
- 闭包
- 装饰器
- 基于函数
- 基于类
- 20.命名空间 & 作用域
-
- 命名空间
- 作用域
- 21.数学相关模块
-
- math 模块
- decimal 模块
- random 模块
- 22.sys 模块
- 23.argparse 模块
- 24.正则表达式
-
- 正则对象
- 匹配对象
- 进阶
-
- 1. 多线程
-
- threading
- 2.多进程
-
- Process 类
- 进程间交换数据
- 进程间同步
- 进程间共享状态
- 3.网络编程
-
- API 介绍
- TCP 方式
- 爬虫
-
- Requests
-
- 参数传递
- 响应内容
- 自定义请求头
- 重定向与历史
- 错误与异常
- BeautifulSoup
-
- 搜索文档树
- CSS选择器
- Selenium
-
- 安装
- 操作浏览器
- 元素定位
- 等待事件
- 登录邮箱
- PyQuery
- Scrapy
-
- 快速上手
- 保存数据
- pyspider
-
- pyspider vs scrapy
原文链接:https://blog.csdn.net/ityard/article/details/102807071?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522167625103516782429768968%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=167625103516782429768968&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_positive~default-2-102807071-null-null.142v73insert_down1,201v4add_ask,239v1insert_chatgpt&utm_term=python%E5%85%A5%E9%97%A8&spm=1018.2226.3001.4187
快捷键
IDEL:
ALT+p:上一个命令
指定pip
c:\Python310\Scripts>pip.exe install requests
换源命令:
临时:pip命令+ -i +镜像地址。例如 pip install numpy -i https://mirrors.aliyun.com/pypi/simple/
永久:在更新到最新版本pip后,pip config set global.index-url+国内镜像地址,例如
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
原文链接:
基础
1.字符串
Python 使用了 ord() 函数返回单个字符的编码,chr() 函数把编码转成相应字符。
s = 'A'
print(ord(s))
print(chr(65))
65
A
s = 'Python'
# 访问第一个字符 P
print(s[0])
#访问范围内字符
s = 'Python'
# 访问 yt
print(s[1:3])
# 访问 Pyt
print(s[:3])
# 访问 hon
print(s[3:])
# 原始字符串
print("D:\\keys\\ware\\hello.py")
print(r"D:\keys\ware\hello.py")
#输出效果相同
D:\keys\ware\hello.py
D:\keys\ware\hello.py
# 长字符串 三引号内的字符串可以换行(不用在尾部加\)
print("""第一行
第二行""")
第一行
第二行
# 字符串 * 重复输出
print("第一行"*4)
第一行
第一行
第一行
第一行
#格式化字符串
print('Hello %s' % 'Python')
Hello Python
2.变量
x = 3
y = 4
x,y = y,x
#交换x y的值
x = input("输入一个数字");
#输入赋值 x的值是屏幕输入的内容
import random
inter = random.randint(1,10)
#获取范围内的随机整数
#浮点型变量有精度范围,所以会出现误差;可引入模块decimal
0.3 == 0.1 + 0.2
#False
import decimal
a = decimal.Decimal('0.1')
b = decimal.Decimal('0.2')
print(a+b)
print(0.1+0.2)
0.3
0.30000000000000004
3.序列
Python 中的序列是一块可存放多个值的连续内存空间,所有值按一定顺序排列,每个值所在位置都有一个编号,称其为索引,我们可以通过索引访问其对应值。
字符串就是序列结构,除此之外常见的序列结构还包括列表、元组等。
索引
str = 'Python'
print('str[0] str[-6] =', str[0], str[-6])
print('str[5] str[-1] =', str[5], str[-1])
#输出结果:
str[0] str[-6] = P P
str[5] str[-1] = n n
切片
str = 'Python'
print(str[:3])
print(str[3:])
print(str[:])
#输出结果:
Pyt
hon
Python
元素是否在序列中
str = 'Python'
print('on'in str)
#输出结果:
True
内置函数
str = 'dbcae'
print('len -->', len(str))
print('max -->', max(str))
print('sorted -->', sorted(str))
#输出结果:
len --> 5
max --> e
sorted --> ['a', 'b', 'c', 'd', 'e']
4.列表
Python 中没有数组,而是加入了功能更强大的列表(list),列表可以存储任何类型的数据,同一个列表中的数据类型还可以不同;列表是序列结构,可以进行序列结构的基本操作:索引、切片、加、乘、检查成员。
#访问
l = [1024, 0.5, 'Python']
print('l[0] -->', l[0])
print('l[1:] -->', l[1:])
输出结果:
l[0] --> 1024
l[1:] --> [0.5, 'Python']
#更新
l = [1024, 0.5, 'Python']
# 修改列表中第二个元素
l[1] = 5
# 向列表中添加新元素
l.append('Hello')
print('l[1] -->', l[1])
print('l -->', l)
输出结果:
l[1] --> 5
l --> [1024, 5, 'Python', 'Hello']
#删除
l = [1024, 0.5, 'Python']
# 删除列表中第二个元素
del l[1]
print('l -->', l)
输出结果:
l --> [1024, 'Python']
count() 统计列表中某个元素出现的次数,使用如下所示:
l = ['d', 'b', 'a', 'f', 'd']
print("l.count('d') -->", l.count('d'))
#输出结果:
l.count('d') --> 2
index() 查找某个元素在列表中首次出现的位置(即索引),使用如下所示:
l = ['d', 'b', 'a', 'f', 'd']
print("l.index('d') -->", l.index('d'))
#输出结果:
l.index('d') --> 0
remove() 移除列表中某个值的首次匹配项,使用如下所示:
l = ['d', 'b', 'a', 'f', 'd']
l.remove('d')
print("l -->", l)
#输出结果:
l --> ['b', 'a', 'f', 'd']
sort() 对列表中元素进行排序,使用如下所示:
l = ['d', 'b', 'a', 'f', 'd']
l.sort()
print('l -->', l)
#输出结果:
l --> ['a', 'b', 'd', 'd', 'f']
copy() 复制列表,使用如下所示:
l = ['d', 'b', 'a', 'f', 'd']
lc = l.copy()
print('lc -->', lc)
#输出结果:
lc --> ['d', 'b', 'a', 'f', 'd']
5.元组
元组(tuple)与列表类似,但元组是不可变的,可简单将其看作是不可变的列表,元组常用于保存不可修改的内容
#元组中所有元素都放在一个小括号 () 中,相邻元素之间用逗号 , 分隔
t = (1024, 0.5, 'Python')
print('t[0] -->', t[0])
print('t[1:] -->', t[1:])
输出结果:
t[0] --> 1024
t[1:] --> (0.5, 'Python')
#元组中元素不能被修改,我们要用重新赋值的方式操作,如下所示:
t = (1024, 0.5, 'Python')
t = (1024, 0.5, 'Python', 'Hello')
print('t -->', t)
输出结果:
t --> (1024, 0.5, 'Python', 'Hello')
#元组中的元素不能被删除,我们只能删除整个元组,如下所示:
t = (1024, 0.5, 'Python')
del t
print('t -->', t)
输出结果:
NameError: name 't' is not defined
#由于元组实例被删除,所以输出了异常信息。
#len()计算元组中元素个数,使用如下所示:
t = (1024, 0.5, 'Python')
print('len(t) -->', len(t))
输出结果:
len(t) --> 3
# max() 和 min()返回元组中元素最大、最小值,使用如下所示:
t = ('d', 'b', 'a', 'f', 'd')
print('max(t) -->', max(t))
print('min(t) -->', min(t))
输出结果:
max(t) --> f
min(t) --> a
# tuple()将列表转换为元组,使用如下所示:
l = ['d', 'b', 'a', 'f', 'd']
t = tuple(l)
print('t -->', t)
输出结果:
t --> ('d', 'b', 'a', 'f', 'd')
6.字典
它们的内容都是以键-值(key-value)的方式存在的。
dict 拥有良好的查询速度,dict 中的值可以是任意 Python 对象,多次对一个 key 赋 value,后面的 value 会把前面的 value 覆盖。
#创建
d = {'name':'小明', 'age':'18'}
# 使用 dict 函数
# 方式一
l = [('name', '小明'), ('age', 18)]
d = dict(l)
# 方式二
d = dict(name='小明', age='18')
# 空字典
d = dict()
d = {}
#访问
>>> d = dict(name='小明', age='18')
>>> d['name']
'小明'
# 使用 get 方法
>>> d.get('name')
'小明'
#修改
>>> d = dict(name='小明', age='18')
>>> d['age'] = '20'
>>> d['age']
'20'
#清空
>>> d = dict(name='小明', age='18')
>>> d.clear()
>>> d
{}
#获取字典的长度,如下所示:
>>> d = dict(name='小明', age='18')
>>> len(d)
2
7.集合
集合(set)与字典相同均存储 key,但也只存储 key,因 key 不可重复,所以 set 的中的值不可重复,也是无序的。
#集合使用花括号 {} 或者 set() 函数创建,如果创建空集合只能使用 set() 函数,以创建集合 s 为例,如下所示:
s = {'a', 'b', 'c'}
# 使用 set 函数
s = set(['a', 'b', 'c'])
# 空集合
s = set()
#集合中重复的元素会被自动过滤掉,如下所示:
>>> s = {'a', 'a', 'b', 'c', 'c'}
>>> s
{'a', 'c', 'b'}
#添加元素可以使用 add 或 update 方法,如果元素已经存在,则不进行操作,如下所示:
>>> s = {'a', 'b', 'c'}
>>> s.add('d')
>>> s
{'a', 'd', 'c', 'b'}
>>> s.update('e')
>>> s
{'a', 'b', 'e', 'd', 'c'}
# 添加已经存在的元素 a
>>> s.add('a')
>>> s
{'a', 'b', 'e', 'd', 'c'}
#删除元素使用 remove 方法,如下所示:
>>> s = {'a', 'b', 'c'}
>>> s.remove('c')
>>> s
{'a', 'b'}
#清空集合使用 clear 方法,如下所示:
>>> s = {'a', 'b', 'c'}
>>> s.clear()
>>> s
set()
#获取集合的长度,同样使用 len 方法,如下所示:
>>> s = {'a', 'b', 'c'}
>>> len(s)
3
8.time 模块
time 模块的 struct_time 类代表一个时间对象,可以通过索引和属性名访问值。对应关系如下所示:
| 索引 | 属性 | 值 |
|---|---|---|
| 0 | tm_year(年) | 如:1945 |
| 1 | tm_mon(月) | 1 ~ 12 |
| 2 | tm_mday(日) | 1 ~ 31 |
| 3 | tm_hour(时) | 0 ~ 23 |
| 4 | tm_min(分) | 0 ~ 59 |
| 5 | tm_sec(秒) | 0 ~ 61 |
| 6 | tm_wday(周) | 0 ~ 6 |
| 7 | tm_yday(一年内第几天) | 1 ~ 366 |
| 8 | tm_isdst(夏时令) | -1、0、1 |
tm_sec 范围为 0 ~ 61,值 60 表示在闰秒的时间戳中有效,并且由于历史原因支持值 61。
#localtime() 表示当前时间,返回类型为 struct_time 对象,示例如下所示:
import time
t = time.localtime()
print('t-->', t)
print('tm_year-->', t.tm_year)
print('tm_year-->', t[0])
输出结果:
t--> time.struct_time(tm_year=2019, tm_mon=12, tm_mday=1, tm_hour=19, tm_min=49, tm_sec=54, tm_wday=6, tm_yday=335, tm_isdst=0)
tm_year--> 2019
tm_year--> 2019
| 函数(常量) | 说明 |
|---|---|
| time() | 返回当前时间的时间戳 |
| gmtime([secs]) | 将时间戳转换为格林威治天文时间下的 struct_time,可选参数 secs 表示从 epoch 到现在的秒数,默认为当前时间 |
| localtime([secs]) | 与 gmtime() 相似,返回当地时间下的 struct_time |
| mktime(t) | localtime() 的反函数 |
| asctime([t]) | 接收一个 struct_time 表示的时间,返回形式为:Mon Dec 2 08:53:47 2019 的字符串 |
| ctime([secs]) | ctime(secs) 相当于 asctime(localtime(secs)) |
| strftime(format[, t]) | 格式化日期,接收一个 struct_time 表示的时间,并返回以可读字符串表示的当地时间 |
| sleep(secs) | 暂停执行调用线程指定的秒数 |
| altzone | 本地 DST 时区的偏移量,以 UTC 为单位的秒数 |
| timezone | 本地(非 DST)时区的偏移量,UTC 以西的秒数(西欧大部分地区为负,美国为正,英国为零) |
| tzname | 两个字符串的元组:第一个是本地非 DST 时区的名称,第二个是本地 DST 时区的名称 |
epoch:1970-01-01 00:00:00 UTC
9.datetime 模块
datatime 模块重新封装了 time 模块,提供了更多接口,变得更加直观和易于调用。
date
date 类表示一个由年、月、日组成的日期,格式为:datetime.date(year, month, day)。
year 范围为:[1, 9999]
month 范围为:[1, 12]
day 范围为 [1, 给定年月对应的天数]。
| 方法(属性) | 说明 |
|---|---|
| today() | 返回当地的当前日期 |
| fromtimestamp(timestamp) | 根据给定的时间戮,返回本地日期 |
| min | date 所能表示的最小日期 |
| max | date 所能表示的最大日期 |
import datetime
import time
print(datetime.date.today())
print(datetime.date.fromtimestamp(time.time()))
print(datetime.date.min)
print(datetime.date.max)
| 方法(属性) | 说明 |
|---|---|
| replace(year, month, day) | 生成一个新的日期对象,用参数指定的年,月,日代替原有对象中的属性 |
| timetuple() | 返回日期对应的 struct_time 对象 |
| weekday() | 返回一个整数代表星期几,星期一为 0,星期天为 6 |
| isoweekday() | 返回一个整数代表星期几,星期一为 1,星期天为 7 |
| isocalendar() | 返回格式为 (year,month,day) 的元组 |
| isoformat() | 返回格式如 YYYY-MM-DD 的字符串 |
| strftime(format) | 返回自定义格式的字符串 |
| year | 年 |
| month | 月 |
| day | 日 |
import datetime
td = datetime.date.today()
print(td.replace(year=1945, month=8, day=15))
print(td.timetuple())
print(td.weekday())
print(td.isoweekday())
print(td.isocalendar())
print(td.isoformat())
print(td.strftime('%Y %m %d %H:%M:%S %f'))
print(td.year)
print(td.month)
print(td.day)
time
time 类表示由时、分、秒、微秒组成的时间,格式为:time(hour=0, minute=0, second=0, microsecond=0, tzinfo=None, *, fold=0)。
hour 范围为:[0, 24)
minute 范围为:[0, 60)
second 范围为:[0, 60)
microsecond 范围为:[0, 1000000)
fold 范围为:[0, 1]
| 方法(属性) | 说明 |
|---|---|
| isoformat() | 返回 HH:MM:SS 格式的字符串 |
| replace(hour, minute, second, microsecond, tzinfo, * fold=0) | 创建一个新的时间对象,用参数指定的时、分、秒、微秒代替原有对象中的属性 |
| strftime(format) | 返回自定义格式的字符串 |
| hour | 时 |
| minute | 分 |
| second | 秒 |
| microsecond | 微秒 |
| tzinfo | 时区 |
import datetime
t = datetime.time(10, 10, 10)
print(t.isoformat())
print(t.replace(hour=9, minute=9))
print(t.strftime('%I:%M:%S %p'))
print(t.hour)
print(t.minute)
print(t.second)
print(t.microsecond)
print(t.tzinfo)
datetime 类
datetime 包括了 date 与 time 的所有信息,格式为:datetime(year, month, day, hour=0, minute=0, second=0, microsecond=0, tzinfo=None, *, fold=0),参数范围值参考 date 类与 time 类。
| 方法(属性) | 说明 |
|---|---|
| today() | 返回当地的当前时间 |
| now(tz=None) | 类似于 today(),可选参数 tz 可指定时区 |
| utcnow() | 返回当前 UTC 时间 |
| fromtimestamp(timestamp, tz=None) | 根据时间戳返回对应时间 |
| utcfromtimestamp(timestamp) | 根据时间戳返回对应 UTC 时间 |
| combine(date, time) | 根据 date 和 time 返回对应时间 |
| min | datetime 所能表示的最小日期 |
| max | datetime 所能表示的最大日期 |
import datetime
print(datetime.datetime.today())
print(datetime.datetime.now())
print(datetime.datetime.utcnow())
print(datetime.datetime.fromtimestamp(time.time()))
print(datetime.datetime.utcfromtimestamp(time.time()))
print(datetime.datetime.combine(datetime.date(2019, 12, 1), datetime.time(10, 10, 10)))
print(datetime.datetime.min)
print(datetime.datetime.max)
| 方法(属性) | 说明 |
|---|---|
| date() | 返回具有同样 year,month,day 值的 date 对象 |
| time() | 返回具有同样 hour, minute, second, microsecond 和 fold 值的 time 对象 |
| replace(year, month, day=self.day, hour, minute, second, microsecond, tzinfo, * fold=0) | 生成一个新的日期对象,用参数指定的年,月,日,时,分,秒…代替原有对象中的属性 |
| weekday() | 返回一个整数代表星期几,星期一为 0,星期天为 6 |
| isoweekday() | 返回一个整数代表星期几,星期一为 1,星期天为 7 |
| isocalendar() | 返回格式为 (year,month,day) 的元组 |
| isoformat() | 返回一个以 ISO 8601 格式表示日期和时间的字符串 YYYY-MM-DDTHH:MM:SS.ffffff |
| strftime(format) | 返回自定义格式的字符串 |
| year | 年 |
| month | 月 |
| day | 日 |
| hour | 时 |
| minute | 分 |
| second | 秒 |
| microsecond | 微秒 |
| tzinfo | 时区 |
import datetime
td = datetime.datetime.today()
print(td.date())
print(td.time())
print(td.replace(day=11, second=10))
print(td.weekday())
print(td.isoweekday())
print(td.isocalendar())
print(td.isoformat())
print(td.strftime('%Y-%m-%d %H:%M:%S .%f'))
print(td.year)
print(td.month)
print(td.month)
print(td.hour)
print(td.minute)
print(td.second)
print(td.microsecond)
print(td.tzinfo)
10.calendar 模块
calendar 模块提供了很多可以处理日历的函数
| 方法 | 说明 |
|---|---|
| setfirstweekday(weekday) | 设置每一周的开始(0 表示星期一,6 表示星期天) |
| firstweekday() | 返回当前设置的每星期的第一天的数值 |
| isleap(year) | 如果 year 是闰年则返回 True ,否则返回 False |
| leapdays(y1, y2) | 返回 y1 至 y2 (包含 y1 和 y2 )之间的闰年的数量 |
| weekday(year, month, day) | 返回指定日期的星期值 |
| monthrange(year, month) | 返回指定年份的指定月份第一天是星期几和这个月的天数 |
| month(theyear, themonth, w=0, l=0) | 返回月份日历 |
| prcal(year, w=0, l=0, c=6, m=3) | 返回年份日历 |
import calendar
calendar.setfirstweekday(1)
print(calendar.firstweekday())
print(calendar.isleap(2019))
print(calendar.leapdays(1945, 2019))
print(calendar.weekday(2019, 12, 1))
print(calendar.monthrange(2019, 12))
print(calendar.month(2019, 12))
print(calendar.prcal(2019))
Calendar 类
Calendar 对象提供了一些日历数据格式化的方法,实例方法如下所示
| 方法 | 说明 |
|---|---|
| iterweekdays() | 返回一个迭代器,迭代器的内容为一星期的数字 |
| itermonthdates(year, month) | 返回一个迭代器,迭代器的内容为年 、月的日期 |
from calendar import Calendar
c = Calendar()
print(list(c.iterweekdays()))
#[0, 1, 2, 3, 4, 5, 6]
for i in c.itermonthdates(2019, 12):
print(i)
TextCalendar 类
TextCalendar 为 Calendar子类,用来生成纯文本日历。实例方法如下所示
| 方法 | 说明 |
|---|---|
| formatmonth(theyear, themonth, w=0, l=0) | 返回一个多行字符串来表示指定年、月的日历 |
| formatyear(theyear, w=2, l=1, c=6, m=3) | 返回一个 m 列日历,可选参数 w, l, 和 c 分别表示日期列数, 周的行数, 和月之间的间隔 |
from calendar import TextCalendar
tc = TextCalendar()
print(tc.formatmonth(2019, 12))
print(tc.formatyear(2019))
输出:
December 2019
Mo Tu We Th Fr Sa Su
1
2 3 4 5 6 7 8
9 10 11 12 13 14 15
16 17 18 19 20 21 22
23 24 25 26 27 28 29
30 31
HTMLCalendar类
HTMLCalendar 类可以生成 HTML 日历。实例方法如下所示:
| 方法 | 说明 |
|---|---|
| formatmonth(theyear, themonth, withyear=True) | 返回一个 HTML 表格作为指定年、月的日历 |
| formatyear(theyear, width=3) | 返回一个 HTML 表格作为指定年份的日历 |
| formatyearpage(theyear, width=3, css=‘calendar.css’, encoding=None) | 返回一个完整的 HTML 页面作为指定年份的日历 |
from calendar import HTMLCalendar
hc = HTMLCalendar()
print(hc.formatmonth(2019, 12))
print(hc.formatyear(2019))
print(hc.formatyearpage(2019))
11.函数
Python 使用 def 关键字来声明函数,格式如下所示:
def 函数名(参数):
函数体
return 返回值
如果要定义一个无任何功能的空函数,函数体只写 pass 即可。格式如下所示:
def 函数名():
pass
当我们不确定参数的个数时,可以使用不定长参数,在参数名前加 * 进行声明,格式如下所示:
def 函数名(*参数名):
函数体
我们还可以使用 lambda 定义匿名函数,格式如下所示:
lambda 参数 : 表达式
# 空函数
def my_empty():
pass
# 无返回值
def my_print(name):
print('Hello', name)
# 有返回值
def my_sum(x, y):
s = x + y
print('s-->', s)
return s
# 不定长参数
def my_variable(*params):
for p in params:
print(p)
# 匿名函数
my_sub = lambda x, y: x - y
12.模块与包
模块
Python 中一个以 .py 结尾的文件就是一个模块,模块中定义了变量、函数等来实现一些类似的功能。Python 有很多自带的模块(标准库)和第三方模块,一个模块可以被其他模块引用,实现了代码的复用性。
包
包是存放模块的文件夹,包中包含 __init__.py 和其他模块,__init__.py 可为空也可定义属性和方法,在 Python3.3 之前的版本,一个文件夹中只有包含 __init__.py,其他程序才能从该文件夹引入相应的模块、函数等,之后的版本没有 __init__.py 也能正常导入,简单来说就是 Python3.3 之前的版本,__init__.py 是包的标识,是必须要有的,之后的版本可以没有。
如创建包和模块的最终目录结构为:
package
|- pg1
|- - __init__.py
|- - a.py
|- - b.py
|- pg2
|- - __init__.py
|- - c.py
|- - d.py
a.py
def a():
print('a')
b.py
def b():
print('b')
c.py
def c():
print('c')
d.py
def d():
print('d')
引用
从包中引入模块有如下两种方式:
import …
import 包名1.包名2...模块名
from … import …
from 包名1.包名2... import 模块名
from 包名1.包名2...模块名 import 变量名/函数名
# a 模块中引入 b 模块
import pg1.b
from pg1 import b
# a 模块中引入 c 模块
import pg2.c
from pg2 import c
# a 模块中引入 c 模块和 d 模块
import pg2.c,pg2.d
from pg2 import c,d
# a 模块中引入包 pg2 下的所有模块
from pg2 import *
# a 模块中引入 d 模块中函数 d()
from pg2.d import d
# 调用函数 d()
d()
13.对象
面向对象相关概念
类:描述具有相同属性和方法的集合,简单来说就是一个模板,通它来创建对象。
对象:类的实例。
方法:类中定义的函数。
类变量:定义在类中且在函数之外的变量,在所有实例化对象中公用。
局部变量:方法中定义的变量,只作用于当前实例。
面向对象三大特性
封装:隐藏对象的属性和实现细节,仅对外提供公共访问方式,提高复用性和安全性。
继承:一个类继承一个基类便可拥有基类的属性和方法,可提高代码的复用性。
多态:父类定义的引用变量可以指向子类的实例对象,提高了程序的拓展性。
类
class Cat:
# 属性
color = 'black'
# 构造方法
def __init__(self, name):
self.name = name
# 自定义方法
def eat(self, food):
self.food = food
print(self.name, '正在吃'+food)
构造方法 __init__() 会在类实例化时自动调用。无论构造方法还是其他方法都需要将 self 作为第一个参数,它代表类的实例。
类创建好后,我们可以直接通过类名访问属性,格式为:类名.属性名,比如我们访问 Cat 类的 color 属性,如下所示:
print('color-->', Cat.color)
Cat 类中定义的属性和方法都是公开的,除此之外我们还可以定义私有属性和方法,声明方式为:在属性名或方法名前加两条下划线,示例如下所示:
class Cat:
__cid = '1'
def __run(self):
pass
需要强调一点是:外部不能访问私有属性和调用私有方法,自然 Cat.__cid 是会报错的。
对象
创建对象也称类的实例化,比如我们通过 Cat 类创建对象,如下所示:
# 创建对象
c = Cat('Tom')
创建好对象后,我们就可以使用它访问属性和调用方法了,如下所示:
# 访问属性
print('name-->', c.name)
print('color-->', c.color)
# 调用方法
c.eat('鱼')
同样对象 c 不能访问私有属性 __cid 及调用私有方法 __run;在类内部私有属性和方法是可以被访问和调用的
继承
# 波斯猫类
class PersianCat(Cat):
def __init__(self, name):
self.name = name
def eat(self, food):
print(self.name, '正在吃'+food)
#加菲猫类
class GarfieldCat(Cat):
def __init__(self, name):
self.name = name
def run(self, speed):
print(self.name, '正在以'+speed+'的速度奔跑')
# 单继承
class SingleCat(PersianCat):
pass
# 多继承
class MultiCat(PersianCat, GarfieldCat):
pass
#调用
sc = SingleCat('波斯猫1号')
sc.eat('鱼')
mc = MultiCat('波斯加菲猫1号')
mc.eat('鱼')
mc.run('50迈')
如果继承的父类方法不能满足我们的需求,这时子类可以重写父类方法,如下所示:
class SingleCat(PersianCat):
def eat(self, food ):
print(self.name, '正在吃'+food, '十分钟后', self.name+'吃饱了')
sc = SingleCat('波斯猫1号')
sc.eat('鱼')
14.文件
创建
Python 使用 open() 函数创建或打开文件,语法格式如下所示
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
参数说明如下:
- file:表示将要打开的文件的路径,也可以是要被封装的整数类型文件描述符。
- mode:是一个可选字符串,用于指定打开文件的模式,默认值是 ‘r’(以文本模式打开并读取)。可选模式如下:
| 模式 | 描述 |
|---|---|
| r | 读取(默认) |
| w | 写入,并先截断文件 |
| x | 排它性创建,如果文件已存在则失败 |
| a | 写入,如果文件存在则在末尾追加 |
| b | 二进制模式 |
| t | 文本模式(默认) |
| + | 更新磁盘文件(读取并写入) |
- buffering:是一个可选的整数,用于设置缓冲策略。
- encoding:用于解码或编码文件的编码的名称。
- errors:是一个可选的字符串,用于指定如何处理编码和解码错误(不能在二进制模式下使用)。
- newline:区分换行符。
- closefd:如果 closefd 为 False 并且给出了文件描述符而不是文件名,那么当文件关闭时,底层文件描述符将保持打开状态;如果给出文件名,closefd 为 True (默认值),否则将引发错误。
- opener:可以通过传递可调用的 opener 来使用自定义开启器。
以 txt 格式文件为例,我们不手动创建文件,通过代码方式来创建,如下所示:
open('test.txt', mode='w',encoding='utf-8')
执行完上述代码,就为我们创建好了 test.txt 文件。
写入
上面我们创建的文件 test.txt 没有任何内容,我们向这个文件中写入一些信息,对于写操作,Python 文件对象提供了两个函数,如下所示:
| 函数 | 描述 |
|---|---|
| write(str) | 将字符串写入文件,返回写入字符长度 |
| writelines(s) | 向文件写入一个字符串列表 |
我们使用这两个函数向文件中写入一些信息,如下所示:
wf = open('test.txt', 'w', encoding='utf-8')
wf.write('Tom\n')
wf.writelines(['Hello\n', 'Python'])
# 关闭
wf.close()
上面我们使用了 close() 函数进行关闭操作,如果打开的文件忘记了关闭,可能会对程序造成一些隐患,为了避免这个问题的出现,可以使用 with as 语句,通过这种方式,程序执行完成后会自动关闭已经打开的文件。如下所示:
with open('test.txt', 'w', encoding='utf-8') as wf:
wf.write('Tom\n')
wf.writelines(['Hello\n', 'Python'])
读取
之前我们已经向文件中写入了一些内容,现在我们读取一下,对于文件的读操作,Python 文件对象提供了三个函数,如下所示:
| 函数 | 描述 |
|---|---|
| read(size) | 读取指定的字节数,参数可选,无参或参数为负时读取所有 |
| readline() | 读取一行 |
| readlines() | 读取所有行并返回列表 |
我们使用上面三个函数读取一下之前写入的内容,如下所示:
with open('test.txt', 'r', encoding='utf-8') as rf:
print('readline-->', rf.readline())
print('read-->', rf.read(6))
print('readlines-->', rf.readlines())
定位
Python 提供了两个与文件对象位置相关的函数,如下所示:
| 函数 | 描述 |
|---|---|
| tell() | 返回文件对象在文件中的当前位置 |
| file.seek(offset[, whence]) | 将文件对象移动到指定的位置;offset 表示移动的偏移量;whence 为可选参数,值为 0 表示从文件开头起算(默认值)、值为 1 表示使用当前文件位置、值为 2 表示使用文件末尾作为参考点 |
下面通过示例对上述函数作进一步了解,如下所示:
with open('test.txt', 'rb+') as f:
f.write(b'123456789')
# 文件对象位置
print(f.tell())
# 移动到文件的第四个字节
f.seek(3)
# 读取一个字节,文件对象向后移动一位
print(f.read(1))
print(f.tell())
# 移动到倒数第二个字节
f.seek(-2, 2)
print(f.tell())
print(f.read(1))
15.os 模块
os 模块提供了各种操作系统的接口,这些接口主要是用来操作文件和目录。
Python 中所有依赖于操作系统的内置模块统一设计方式为:对于不同操作系统可用的相同功能使用相同的接口,这样大大增加了代码的可移植性;当然,通过 os 模块操作某一系统的扩展功能也是可以的,但这样做会损害代码的可移植性。
os.getcwd()
查看当前路径。
import os
print(os.getcwd())
os.listdir(path)
返回指定目录下包含的文件和目录名列表。
import os
print(os.listdir('E:/'))
os.path.abspath(path)
返回路径 path 的绝对路径。
import os
# 当前路径(相对路径方式)
print(os.path.abspath('.'))
os.path.split(path)
将路径 path 拆分为目录和文件两部分,返回结果为元组类型。
import os
print(os.path.split('E:/tmp.txt'))
os.path.join(path, *paths)
将一个或多个 path(文件或目录) 进行拼接。
import os
print(os.path.join('E:/', 'tmp.txt'))
os.path.getctime(path)
返回 path(文件或目录) 在系统中的创建时间。
import os
import datetime
print(datetime.datetime.utcfromtimestamp(os.path.getctime('E:/tmp.txt')))
os.path.getmtime(path)
返回 path(文件或目录)的最后修改时间。
import os
import datetime
print(datetime.datetime.utcfromtimestamp(os.path.getmtime('E:/tmp.txt')))
os.path.getatime(path)
返回 path(文件或目录)的最后访问时间。
import os
import datetime
print(datetime.datetime.utcfromtimestamp(os.path.getatime('E:/tmp.txt')))
os.path.exists(path)
判断 path(文件或目录)是否存在,存在返回 True,否则返回 False。
import os
print(os.path.exists('E:/tmp.txt'))
os.path.isdir(path)
判断 path 是否为目录。
import os
print(os.path.isdir('E:/'))
os.path.isfile(path)
判断 path 是否为文件。
import os
print(os.path.isfile('E:/tmp.txt'))
os.path.getsize(path)
返回 path 的大小,以字节为单位,若 path 是目录则返回 0。
import os
print(os.path.getsize('E:/tmp.txt'))
print(os.path.getsize('E:/work'))
os.mkdir()
创建一个目录。
import os
os.mkdir('E:/test')
os.makedirs()
创建多级目录。
import os
os.makedirs('E:/test1/test2')
目录 test1、test2 均不存在,此时使用 os.mkdir() 创建会报错,也就是说 os.mkdir() 创建目录时要保证末级目录之前的目录是存在的。
os.chdir(path)
将当前工作目录更改为 path。
import os
print(os.getcwd())
os.chdir('/test')
print(os.getcwd())
os.system(command)
调用 shell 脚本。
import os
print(os.system('ping www.baidu.com'))
如果出现乱码,可以通过修改编码解决,比如:我在 Windows 下 PyCharm 中出现乱码问题,可以将 PyCharm 中编码修改为 GBK 解决。
16.错误和异常
Python 内置异常:
BaseException为所有异常的基类,其下面分为:SystemExit、KeyboardInterrupt、GeneratorExit、Exception 四类异常,Exception 为所有非系统退出类异常的基类,Python 提倡继承 Exception 或其子类派生新的异常;Exception 下包含我们常见的多种异常如:MemoryError(内存溢出)、BlockingIOError(IO异常)、SyntaxError(语法错误异常)
| 异常名称 | 描述 |
|---|---|
| BaseException | 所有异常的基类 |
| SystemExit | 解释器请求退出 |
| KeyboardInterrupt | 用户中断执行(通常是输入^C) |
| Exception | 常规错误的基类 |
| StopIteration | 迭代器没有更多的值 |
| GeneratorExit | 生成器(generator)发生异常来通知退出 |
| StandardError | 所有的内建标准异常的基类 |
| ArithmeticError | 所有数值计算错误的基类 |
| FloatingPointError | 浮点计算错误 |
| OverflowError | 数值运算超出最大限制 |
| ZeroDivisionError | 除(或取模)零 (所有数据类型) |
| AssertionError | 断言语句失败 |
| AttributeError | 对象没有这个属性 |
| EOFError | 没有内建输入,到达EOF 标记 |
| EnvironmentError | 操作系统错误的基类 |
| IOError | 输入/输出操作失败 |
| OSError | 操作系统错误 |
| WindowsError | 系统调用失败 |
| ImportError | 导入模块/对象失败 |
| LookupError | 无效数据查询的基类 |
| IndexError | 序列中没有此索引(index) |
| KeyError | 映射中没有这个键 |
| MemoryError | 内存溢出错误(对于Python 解释器不是致命的) |
| NameError | 未声明/初始化对象 (没有属性) |
| UnboundLocalError | 访问未初始化的本地变量 |
| ReferenceError | 弱引用(Weak reference)试图访问已经垃圾回收了的对象 |
| RuntimeError | 一般的运行时错误 |
| NotImplementedError | 尚未实现的方法 |
| SyntaxError Python | 语法错误 |
| IndentationError | 缩进错误 |
| TabError | Tab 和空格混用 |
| SystemError | 一般的解释器系统错误 |
| TypeError | 对类型无效的操作 |
| ValueError | 传入无效的参数 |
| UnicodeError | Unicode 相关的错误 |
| UnicodeDecodeError | Unicode 解码时的错误 |
| UnicodeEncodeError | Unicode 编码时错误 |
| UnicodeTranslateError | Unicode 转换时错误 |
| Warning | 警告的基类 |
| DeprecationWarning | 关于被弃用的特征的警告 |
| FutureWarning | 关于构造将来语义会有改变的警告 |
| OverflowWarning | 旧的关于自动提升为长整型(long)的警告 |
| PendingDeprecationWarning | 关于特性将会被废弃的警告 |
| RuntimeWarning | 可疑的运行时行为(runtime behavior)的警告 |
| SyntaxWarning | 可疑的语法的警告 |
| UserWarning | 用户代码生成的警告 |
异常处理
#1、被除数为 0,未捕获异常
def getNum(n):
return 10 / n
print(getNum(0))
#输出结果:ZeroDivisionError: division by zero
#2、捕获异常
def getNum(n):
try:
return 10 / n
except IOError:
print('Error: IOError argument.')
except ZeroDivisionError:
print('Error: ZeroDivisionError argument.')
print(getNum(0))
'''
输出结果:
Error: ZeroDivisionError argument.
None
'''
try 语句的工作方式为:
首先,执行 try 子句 (在 try 和 except 关键字之间的部分);
如果没有异常发生, except 子句 在 try 语句执行完毕后就被忽略了;
如果在 try 子句执行过程中发生了异常,那么该子句其余的部分就会被忽略;
如果异常匹配于 except 关键字后面指定的异常类型,就执行对应的except子句,然后继续执行 try 语句之后的代码;
如果发生了一个异常,在 except 子句中没有与之匹配的分支,它就会传递到上一级 try 语句中;
如果最终仍找不到对应的处理语句,它就成为一个 未处理异常,终止程序运行,显示提示信息。
try/except 语句还可以带有一个 else、finally子句,示例如下:
def getNum(n):
try:
print('try --> ',10 / n)
except ZeroDivisionError:
print('except --> Error: ZeroDivisionError argument.')
else:
print('else -->')
finally:
print('finally -->')
'''
1、调用:getNum(0)
输出结果:
except --> Error: ZeroDivisionError argument.
finally -->
2、调用:getNum(1)
输出结果:
try --> 10.0
else -->
finally -->
'''
其中,else 子句只能出现在所有 except 子句之后,只有在没有出现异常时执行;finally 子句放在最后,无论是否出现异常都会执行。
抛出异常
使用 raise 语句允许强制抛出一个指定的异常,要抛出的异常由 raise 的唯一参数标识,它必需是一个异常实例或异常类(继承自 Exception 的类),如:
raise NameError('HiThere')
17.枚举
#创建
from enum import Enum
class WeekDay(Enum):
Mon = 0
Tue = 1
Wed = 2
Thu = 3
Fri = 4
枚举成员及属性的访问如下所示:
# 枚举成员
print(WeekDay.Mon)
# 枚举成员名称
print(WeekDay.Mon.name)
# 枚举成员值
print(WeekDay.Mon.value)
枚举的迭代也很简单,如下所示:
# 方式 1
for day in WeekDay:
# 枚举成员
print(day)
# 枚举成员名称
print(day.name)
# 枚举成员值
print(day.value)
# 方式 2
print(list(WeekDay))
#打印结果
WeekDay.Mon
Mon
0
WeekDay.Mon
Mon
0
WeekDay.Tue
Tue
1
WeekDay.Wed
Wed
2
WeekDay.Thu
Thu
3
WeekDay.Fri
Fri
4
[<WeekDay.Mon: 0>, <WeekDay.Tue: 1>, <WeekDay.Wed: 2>, <WeekDay.Thu: 3>, <WeekDay.Fri: 4>]
比较
print(WeekDay.Mon is WeekDay.Thu)
print(WeekDay.Mon == WeekDay.Mon)
print(WeekDay.Mon.name == WeekDay.Mon.name)
print(WeekDay.Mon.value == WeekDay.Mon.value)
False
True
True
True
18.迭代器与生成器
Python 中有一些对象可以通过 for 来循环遍历,比如:列表、元组、字符等;这个遍历过程就是迭代。
for i in 'Hello':
print(i)
可迭代对象
可迭代对象需具有 __iter__() 方法,它们均可使用 for 循环遍历,我们可以使用 isinstance() 方法来判断一个对象是否为可迭代对象,看下示例:
from collections import Iterable
print(isinstance('abc', Iterable))
print(isinstance({1, 2, 3}, Iterable))
print(isinstance(1024, Iterable))
执行结果:
True
True
False
迭代器
迭代器需要具有__iter__()和__next__()两个方法,这两个方法共同组成了迭代器协议,通俗来讲迭代器就是一个可以记住遍历位置的对象,迭代器一定是可迭代的,反之不成立。
__iter__():返回迭代器对象本身
__next__():返回下一项数据
迭代器对象本质是一个数据流,它通过不断调用 __next__() 方法或被内置的 next() 方法调用返回下一项数据,当没有下一项数据时抛出 StopIteration异常迭代结束。上面我们说的 for 循环语句的实现便是利用了迭代器。
我们试着自己来实现一个迭代器,如下所示:
class MyIterator:
def __init__(self):
self.s = '程序之间'
self.i = 0
def __iter__(self):
return self
def __next__(self):
if self.i < 4:
n = self.s[self.i]
self.i += 1
return n
else:
raise StopIteration
mi = iter(MyIterator())
for i in mi:
print(i)
输出结果:
程
序
之
间
生成器
生成器是用来创建迭代器的工具,其写法与标准函数类似,不同之处在于返回时使用 yield 语句。
yield 是一个关键字,作用和 return 差不多,差别在于 yield 返回的是一个生成器(在 Python 中,一边循环一边计算的机制,称为生成器),它的作用是:有利于减小服务器资源,在列表中所有数据存入内存,而生成器相当于一种方法而不是具体的信息,用多少取多少,占用内存小。
生成器的创建方式有很多种,比如:使用 yield 语句、生成器表达式(可以简单的理解为是将列表的 [] 换成了 (),特点是更加简洁,但不够灵活)。
示例 1
def reverse(data):
for i in range(len(data)-1, -1, -1):
yield data[i]
for char in reverse('Hello'):
print(char)
执行结果:
o
l
l
e
H
示例 2
# 列表
lis = [x*x for x in range(5)]
print(lis)
# 生成器
gen = (x*x for x in range(5))
for g in gen:
print(g)
执行结果:
[0, 1, 4, 9, 16]
0
1
4
9
16
19.装饰器
闭包
闭包(英语:Closure),又称词法闭包(Lexical Closure)或函数闭包(function closures),是引用了自由变量的函数。这个被引用的自由变量将和这个函数一同存在,即使已经离开了创造它的环境也不例外。所以,有另一种说法认为闭包是由函数和与其相关的引用环境组合而成的实体。闭包在运行时可以有多个实例,不同的引用环境和相同的函数组合可以产生不同的实例。
比如我们调用一个带有返回值的函数 x,此时函数 x 为我们返回一个函数 y,这个函数 y 就被称作闭包。
def x(id):
def y(name):
print ('id:', id, 'name:', name)
return y
y = x('ityard')
y('程序之间')
结果:
id: ityard name: 程序之间
闭包与类有一些相似,比如:它们都能实现数据的封装、方法的复用等;此外,通过使用闭包可以避免使用全局变量,还能将函数与其所操作的数据关连起来。
装饰器
装饰器(decorator)也称装饰函数,是一种闭包的应用,其主要是用于某些函数需要拓展功能,但又不希望修改原函数,它就是语法糖,使用它可以简化代码、增强其可读性,当然装饰器不是必须要求被使用的,不使用也是可以的,Python 中装饰器通过 @ 符号来进行标识。
装饰器可以基于函数实现也可基于类实现,其使用方式基本是固定的,看一下基本步骤:
-
定义装饰函数(类)
-
定义业务函数
-
在业务函数上添加 @装饰函数(类)名
基于函数
# 装饰函数
def funA(fun):
def funB(*args, **kw):
print('函数 ' + fun.__name__ + ' 开始执行')
fun(*args, **kw)
print('函数 ' + fun.__name__ + ' 执行完成')
return funB
@funA
# 业务函数
def funC(name):
print('Hello', name)
funC('Jhon')
结果:
函数 funC 开始执行
Hello Jhon
函数 funC 执行完成
装饰函数也是可以接受参数的,如下所示:
# 装饰函数
def funA(flag):
def funB(fun):
def funC(*args, **kw):
if flag == True:
print('==========')
elif flag == False:
print('----------')
fun(*args, **kw)
return funC
return funB
@funA(False)
# 业务函数
def funD(name):
print('Hello', name)
funD('Jhon')
结果:
----------
Hello Jhon
基于类
装饰器除了基于函数实现,还可以基于类实现,看下示例:
class Test(object):
def __init__(self, func):
print('函数名是 %s ' % func.__name__)
self.__func = func
def __call__(self, *args, **kwargs):
self.__func()
@Test
def hello():
print('Hello ...')
hello()
函数名是 hello
Hello ...
Python 装饰器的 @… 相当于将被装饰的函数(业务函数)作为参数传入装饰函数(类)。
20.命名空间 & 作用域
命名空间
命名空间(namespace)是名称到对象的映射,当前大部分命名空间都是通过 Python 字典来实现的,它的主要作用是避免项目中的名字冲突,每一个命名空间都是相对独立的,在不同的命名空间中可以同名,在相同的命名空间中不可以同名。
命名空间主要有以下三种:
- 内置:主要用来存放内置函数、异常等,比如:abs 函数、BaseException 异常。
- 全局:指在模块中定义的名称,比如:类、函数等。
- 局部:指在函数中定义的名称,比如:函数的参数、在函数中定义的变量等。
生命周期
通常在不同时刻创建的命名空间拥有不同的生命周期,看一下三种命名空间的生命周期:
- 内置:在 Python 解释器启动时创建,退出时销毁。
- 全局:在模块定义被读入时创建,在 Python 解释器退出时销毁。
- 局部:对于类,在 Python 解释器读到类定义时创建,类定义结束后销毁;对于函数,在函数被调用时创建,函数执行完成或出现未捕获的异常时销毁。
作用域
作用域是 Python 程序可以直接访问命名空间的文本区域(代码区域),名称的非限定引用会尝试在命名空间中查找名称,作用域是静态的,命名空间是随着解释器的执行动态产生的,因此在作用域中访问命名空间中的名字具有了动态性,即作用域被静态确定,被动态使用。
Python 有如下四种作用域:
- 局部:最先被搜索的最内部作用域,包含局部名称。
- 嵌套:根据嵌套层次由内向外搜索,包含非全局、非局部名称。
- 全局:倒数第二个被搜索,包含当前模块的全局名称。
- 内建:最后被搜索,包含内置名称的命名空间。
# 全局作用域
g = 1
def outer():
# 嵌套作用域
e = 2
def inner():
# 局部作用域
i = 3
全局作用域与局部作用域
# 全局变量
d = 0
def sub(a, b):
# d 在这为局部变量
d = a - b
print('函数内 : ', d)
sub(9, 1)
print('函数外 : ', d)
执行结果:
函数内 : 8
函数外 : 0
当内部作用域想要修改外部作用域的变量时,就要用到 global 和 nonlocal 关键字了,下面通过具体示例来了解一下。
如果我们想将上面示例中 sub() 函数中的 d 变量修改为全局变量,则需使用 global 关键字,示例如下所示:
# 全局变量
d = 0
def sub(a, b):
# 使用 global 声明 d 为全局变量
global d
d = a - b
print('函数内 : ', d)
sub(9, 1)
print('函数外 : ', d)
执行结果:
函数内 : 8
函数外 : 8
如果需要修改嵌套作用域中的变量,则需用到 nonlocal 关键字。
def outer():
d = 1
def inner():
d = 2
print('inner:', d)
inner()
print('outer:', d)
outer()
执行结果:
inner:2
outer:1
再来看一下使用了 nonlocal 关键字的执行情况,如下所示:
def outer():
d = 1
def inner():
nonlocal d
d = 2
print('inner:', d)
inner()
print('outer:', d)
outer()
执行结果:
inner:2
outer:2
如下:
d = 0
def outer():
#global d
d = 1
def inner():
global d
d = 2
def iiner():
nonlocal d
d = 3
print('iiner:',d)
iiner()
print('inner:', d)
inner()
print('outer:', d)
outer()
print(d)

21.数学相关模块
| 模块 | 描述 |
|---|---|
| math | 提供了对 C 标准定义的数学函数的访问(不适用于复数) |
| cmath | 提供了一些关于复数的数学函数 |
| decimal | 为快速正确舍入的十进制浮点运算提供支持 |
| fractions | 为分数运算提供支持 |
| random | 实现各种分布的伪随机数生成器 |
| statistics | 提供了用于计算数字数据的数理统计量的函数 |
math 模块
ceil(x)
返回 x 的上限,即大于或者等于 x 的最小整数。看下示例:
import math
x = -1.5
print(math.ceil(x))
floor(x)
返回 x 的向下取整,小于或等于 x 的最大整数。看下示例:
import math
x = -1.5
print(math.floor(x))
fabs(x)
返回 x 的绝对值。看下示例:
import math
x = -1.5
print(math.fabs(x))
fmod(x, y)
返回 x/y 的余数,值为浮点数。看下示例:
import math
x = 3
y = 2
print(math.fmod(x, y))
factorial(x)
返回 x 的阶乘,如果 x 不是整数或为负数时则将引发 ValueError。看下示例:
import math
x = 3
print(math.factorial(3))
pow(x, y)
返回 x 的 y 次幂。看下示例:
import math
x = 3
y = 2
print(math.pow(x, y))
fsum(iterable)
返回迭代器中所有元素的和。看下示例:
import math
print(math.fsum((1, 2, 3, 4, 5)))
gcd(x, y)
返回整数 x 和 y 的最大公约数。看下示例:
import math
x = 9
y = 6
print(math.gcd(x, y))
sqrt(x)
返回 x 的平方根。看下示例:
import math
x = 9
print(math.sqrt(x))
trunc(x)
返回 x 的整数部分。看下示例:
import math
x = 1.1415926
print(math.trunc(x))
exp(x)
返回 e 的 x 次幂。看下示例:
import math
x = 2
print(math.exp(2))
log(x[, base])
返回 x 的对数,底数默认为 e。看下示例:
import math
x = 10
y = 10
# 不指定底数
**print(math.log(x))**
# 指定底数
**print(math.log(x, y))**
常量
import math
# 常量 e
print(math.e)
# 常量 π
print(math.pi)
tan(x)
返回 x 弧度的正切值。看下示例:
import math
print(math.tan(math.pi / 3))
atan(x)
返回 x 的反正切值。看下示例:
import math
print(math.atan(1))
sin(x)
返回 x 弧度的正弦值。看下示例:
import math
print(math.sin(math.pi / 3))
asin(x)
返回 x 的反正弦值。看下示例:
import math
print(math.asin(1))
cos(x)
返回 x 弧度的余弦值。看下示例:
import math
print(math.cos(math.pi / 3))
acos(x)
返回 x 的反余弦值。看下示例:
import math
print(math.acos(1))
decimal 模块
decimal 模块为正确舍入十进制浮点运算提供了支持,相比内置的浮点类型 float,它能更加精确的控制精度,能够为精度要求较高的金融等领域提供支持。
prec=28,这就是默认的精度,我们可以使用 getcontext().prec = xxx 来重新设置精度。
基本运算
import decimal
d1 = decimal.Decimal(1.1)
d2 = decimal.Decimal(9.9)
print(d1 + d2)
print(d1 - d2)
print(d1 * d2)
print(d1 / d2)
执行结果:
11.00000000000000044408920985
-8.800000000000000266453525910
10.89000000000000127009514017
0.1111111111111111160952773272
上面结果是用了默认精度,我们重新设置下精度再来看一下:
import decimal
decimal.getcontext().prec = 2
d1 = decimal.Decimal(1.1)
d2 = decimal.Decimal(9.9)
print(d1 + d2)
print(d1 - d2)
print(d1 * d2)
print(d1 / d2)
执行结果:
11
-8.8
11
0.11
random 模块
random 模块可以生成随机数
random()
返回 [0.0, 1.0) 范围内的一个随机浮点数。看下示例:
import random
print(random.random())
uniform(a, b)
返回 [a, b) 范围内的一个随机浮点数。看下示例:
import random
print(random.uniform(1.1, 9.9))
randint(a, b)
返回 [a, b] 范围内的一个随机整数。看下示例:
import random
print(random.randint(1, 10))
randrange(start, stop[, step])
返回 [start, stop) 范围内步长为 step 的一个随机整数。看下示例:
import random
print(random.randrange(1, 10))
print(random.randrange(1, 10, 2))
choice(seq)
从非空序列 seq 返回一个随机元素。看下示例:
import random
print(random.choice('123456'))
print(random.choice('abcdef'))
shuffle(x[, random])
将序列 x 随机打乱位置。看下示例:
import random
l = [1, 2, 3, 4, 5, 6]
random.shuffle(l)
print(l)
sample(population, k)
返回从总体序列或集合中选择的唯一元素的 k 长度列表,用于无重复的随机抽样。看下示例:
import random
l = [1, 2, 3, 4, 5, 6]
print(random.sample(l, 3))
#从l中随机抽取3个数
22.sys 模块
sys 模块主要负责与 Python 解释器进行交互,该模块提供了一系列用于控制 Python 运行环境的函数和变量。
之前我们说过 os 模块,该模块与 sys 模块从名称上看着好像有点类似,实际上它们之间是没有什么关系的,os 模块主要负责与操作系统进行交互。
argv
返回传递给 Python 脚本的命令行参数列表。看下示例:
import sys
if __name__ == '__main__':
args = sys.argv
print(args)
print(args[1])
上面文件名为:test.py,我们在控制台使用命令:python test.py 123 abc 执行一下,执行结果如下:
['test.py', '123', 'abc']
123
version
返回 Python 解释器的版本信息。
winver
返回 Python 解释器主版号。
platform
返回操作系统平台名称。
path
返回模块的搜索路径列表。
maxsize
返回支持的最大整数值。
maxunicode
返回支持的最大 Unicode 值。
copyright
返回 Python 版权信息。
modules
以字典类型返回系统导入的模块。
byteorder
返回本地字节规则的指示器。
executable
返回 Python 解释器所在路径。
import sys
print(sys.version)
print(sys.winver)
print(sys.platform)
print(sys.path)
print(sys.maxsize)
print(sys.maxunicode)
print(sys.copyright)
print(sys.modules)
print(sys.byteorder)
print(sys.executable)
stdout
标准输出。看下示例:
import sys
# 下面两行代码等价
sys.stdout.write('Hi' + '\n')
print('Hi')
stdin
标准输入。看下示例:
import sys
s1 = input()
s2 = sys.stdin.readline()
print(s1)
print(s2)
stderr
错误输出。看下示例:
import sys
sys.stderr.write('this is a error message')
exit()
退出当前程序。看下示例:
import sys
print('Hi')
sys.exit()
print('Jhon')
getdefaultencoding()
返回当前默认字符串编码的名称。
getrefcount(obj)
返回对象的引用计数。
getrecursionlimit()
返回支持的递归深度。
getsizeof(object[, default])
以字节为单位返回对象的大小。
setswitchinterval(interval)
设置线程切换的时间间隔。
getswitchinterval()
返回线程切换时间间隔。
import sys
print(sys.getdefaultencoding())
print(sys.getrefcount('123456'))
print(sys.getrecursionlimit())
print(sys.getsizeof('abcde'))
sys.setswitchinterval(1)
print(sys.getswitchinterval())
23.argparse 模块
argparse 模块主要用于处理 Python 命令行参数和选项,程序定义好所需参数后,该模块会通过sys.argv 解析出那些参数;除此之外,argparse 模块还会自动生成帮助和使用手册,并在用户给程序传入无效参数时报出错误信息。使用 argparse 模块,我们可以轻松的编写出用户友好的命令行接口。
示例:
import argparse
# 创建解析对象
parser = argparse.ArgumentParser()
# 解析
parser.parse_args()
文件名为 test.py,在控制输入命令:python test.py --help,执行结果:
usage: test.py [-h]
optional arguments:
-h, --help show this help message and exit
通过具体示例看一下:
import argparse
parser = argparse.ArgumentParser()
# 增加-n参数,对应值写入rname变量
parser.add_argument(
'-n', '--name', dest='rname', required=True,
help='increase output name'
)
args = parser.parse_args()
name = args.rname
print('Hello', name)
先在控制台执行命令 python test.py -h,执行结果:
usage: test.py [-h] -n RNAME
optional arguments:
-h, --help show this help message and exit
-n RNAME, --name RNAME
increase output name
我们可以看到参数已经添加进来了,接着执行命令 python test.py -n Jhon 或 python test.py --name Jhon,执行结果:
Hello Jhon
24.正则表达式
正则表达式是一个强大的字符串处理工具,几乎所有的字符串操作都可以通过正则表达式来完成,其本质是一个特殊的字符序列,可以方便的检查一个字符串是否与我们定义的字符序列的某种模式相匹配。
正则表达式并不是 Python 所特有的,几乎所有编程语言都支持正则表达式,Python 提供了内置模块 re 和第三方模块 regex 来支持正则表达式,regex 模块提供了与 re 模块兼容的 API 接口,同时还提供了额外的功能和更全面的 Unicode 支持,本文只介绍 re 模块
基本语法:
| 字符 | 说明 |
|---|---|
| . | 默认情况,匹配除了换行的任意字符;如果指定了标签 DOTALL,则匹配包括换行符的任意字符 |
| ^ | 匹配字符串的开头,在 MULTILINE 模式也匹配换行后的首个符号 |
| $ | 匹配字符串尾或者换行符的前一个字符,在 MULTILINE 模式匹配换行符的前一个字符 |
* |
匹配前一个字符 0 到无限次 |
+ |
匹配前一个字符 1 到无限次 |
| ? | 匹配前一个字符 0 次或 1 次 |
| {m} | 匹配前一个字符 m 次 |
| {m, n} | 匹配前一个字符 m 到 n 次 |
| *? +? ?? {m,n}? | 使 *、+、?、{m,n} 变成非贪婪模式,也就是使这些匹配次数不定的表达式尽可能少的匹配 |
| \ | 转义特殊字符 |
| […] | 用于表示一个字符集合 |
| |
匹配 | 两边任意表达式 |
| (…) | 将括起来的表达式分组, |
| (?aiLmsux) | aiLmsux 每一个字符代表一个匹配模式,可选多个 |
| (?:…) | (…) 的不分组版本 |
| (?P…) | 分组,除了原有的编号外再指定一个额外的别名 |
| (?P=name) | 引用别名为 name 的分组匹配到的字符串 |
| (?#…) | # 后面的将作为注释被忽略 |
| (?=…) | 匹配 … 的内容,但是并不消费样式的内容 |
| (?!…) | 匹配 … 不符合的情况 |
| (?<=…) | 匹配字符串的当前位置,它的前面匹配 … 的内容到当前位置 |
| (? | 匹配当前位置之前不是 … 的样式 |
| (?(id/name)yes-pattern | no-pattern) |
| \number | 匹配数字代表的组合 |
| \A | 只匹配字符串开始 |
| \b | 匹配空字符串,但只在单词开始或结尾的位置 |
| \B | 匹配空字符串,但不能在词的开头或者结尾 |
| \d | 主要匹配数字 [0-9] |
| \D | 匹配任何非十进制数字的字符 |
| \s | 匹配空白字符,主要包括:空格 \t \n \r \f \v |
| \S | 匹配任何非空白字符 |
| \w | 匹配 [a-zA-Z0-9_] |
| \W | 匹配非单词字符 |
| \Z | 只匹配字符串尾 |
re.compile(pattern, flags=0)
用于编译正则表达式,生成一个正则表达式(Pattern)对象,供 match() 和 search() 这两个函数使用。参数说明如下:
- pattern : 一个字符串形式的正则表达式
- flags : 匹配模式,包括如下:
| 参数 | 说明 |
|---|---|
| re.A | 让 \w, \W, \b, \B, \d, \D, \s, \S 只匹配 ASCII |
| re.I | 忽略大小写 |
| re.M | 多行模式 |
| re.L | 由当前语言区域决定 \w, \W, \b, \B 和大小写敏感匹配 |
| re.S | . 匹配包括换行符在内的任意字符 |
| re.U | 在 Python3 中是冗余的,因为 Python3 中字符串已经默认为 Unicode |
| re.X | 忽略空格和 # 后面的注释 |
re.search(pattern, string, flags=0)
扫描整个字符串找到匹配样式的第一个位置,并返回一个相应的匹配对象;如果没有匹配,就返回一个 None。参数说明如下:
- pattern:匹配的正则表达式
- string:要匹配的字符串
- flags:匹配模式
import re
print(re.search(r'abc', 'abcef'))
print(re.search(r'abc', 'aBcef'))
print(re.search(r'abc', 'aBcef',re.I))
None
re.match(pattern, string, flags=0)
如果 string 开始的 0 或者多个字符匹配到了正则表达式样式,就返回一个相应的匹配对象;如果没有匹配,就返回 None。看下示例:
import re
print(re.match(r'abc', 'abcef'))
re.fullmatch(pattern, string, flags=0)
如果整个 string 匹配到正则表达式样式,就返回一个相应的匹配对象;否则就返回一个 None。看一下示例:
import re
print(re.fullmatch(r'abc', 'abcef'))
print(re.fullmatch(r'abc', 'abc'))
None
re.split(pattern, string, maxsplit=0, flags=0)
用 pattern 分开 string,如果在 pattern 中捕获到括号,那么所有的组里的文字也会包含在列表里,如果 maxsplit 非零,最多进行 maxsplit 次分隔,剩下的字符全部返回到列表的最后一个元素。看一下示例:
import re
print(re.split(r'\W+', 'ityard, ityard, ityard.'))
print(re.split(r'(\W+)', 'ityard, ityard, ityard.'))
print(re.split(r'\W+', 'ityard, ityard, ityard.', 1))
print(re.split('[a-f]+', '1A2b3', flags=re.IGNORECASE))
['ityard', 'ityard', 'ityard', '']
['ityard', ', ', 'ityard', ', ', 'ityard', '.', '']
['ityard', 'ityard, ityard.']
['1', '2', '3']
re.findall(pattern, string, flags=0)
对 string 返回一个不重复的 pattern 的匹配列表,string 从左到右进行扫描,匹配按找到的顺序返回,如果样式里存在一到多个组,就返回一个组合列表,空匹配也会包含在结果里。看一下示例:
import re
print(re.findall(r'ab', 'abefabdeab'))
['ab', 'ab', 'ab']
re.finditer(pattern, string, flags=0)
pattern 在 string 里所有的非重复匹配,返回为一个迭代器 iterator 保存了匹配对象,string 从左到右扫描,匹配按顺序排列。看一下示例:
import re
it = re.finditer(r'\d+', '12ab34cd56')
for match in it:
print(match)
re.sub(pattern, repl, string, count=0, flags=0)
返回通过使用 repl 替换在 string 最左边非重叠出现的 pattern 而获得的字符串,count 表示匹配后替换的最大次数,默认 0 表示替换所有的匹配。看一下示例:
import re
str = 'ityard # 是我的名字'
print(re.sub(r'#.*$', '', str))
#ityard
re.subn(pattern, repl, string, count=0, flags=0)
行为与 re.sub() 相同,但返回的是一个元组。看一下示例:
import re
str = 'ityard # 是我的名字'
print(re.subn(r'#.*$', '', str))
#('ityard ', 1)
re.escape(pattern)
转义 pattern 中的特殊字符。看一下示例:
import re
print(re.escape('https://blog.csdn.net/ityard'))
#https://blog\.csdn\.net/ityard
re.purge()
清除正则表达式缓存。
正则对象
来看一下正则表达式对象的相应方法。
Pattern.search(string[, pos[, endpos]])
扫描整个 string 寻找第一个匹配的位置,并返回一个相应的匹配对象,如果没有匹配,就返回 None;可选参数 pos 给出了字符串中开始搜索的位置索引,默认为 0;可选参数 endpos 限定了字符串搜索的结束。看一下示例:
import re
pattern = re.compile(r'bc', re.I)
print(pattern.search('aBcdef'))
print(pattern.search('aBcdef', 1, 3))
Pattern.match(string[, pos[, endpos]])
如果 string 的开始位置能够找到这个正则样式的任意个匹配,就返回一个相应的匹配对象,如果不匹配,就返回 None。看一下示例:
import re
pattern = re.compile(r'bc', re.I)
print(pattern.match('aBcdef'))
print(pattern.match('aBcdef', 1, 3))
None
Pattern.fullmatch(string[, pos[, endpos]])
如果整个 string 匹配这个正则表达式,就返回一个相应的匹配对象,否则就返回 None。看一下示例:
import re
pattern = re.compile(r'bc', re.I)
print(pattern.fullmatch('Bc'))
print(pattern.fullmatch('aBcdef', 1, 3))
Pattern.split(string, maxsplit=0)
等价于 re.split() 函数,使用了编译后的样式。看一下示例:
import re
pattern = re.compile(r'bc', re.I)
print(pattern.split('abc, aBcd, abcde.'))
['a', ', a', 'd, a', 'de.']
Pattern.findall(string[, pos[, endpos]])
使用了编译后样式,可以接收可选参数 pos 和 endpos,限制搜索范围。看一下示例:
import re
pattern = re.compile(r'bc', re.I)
print(pattern.findall('abcefabCdeABC'))
print(pattern.findall('abcefabCdeABC', 0, 6))
['bc', 'bC', 'BC']
['bc']
Pattern.finditer(string[, pos[, endpos]])
使用了编译后样式,可以接收可选参数 pos 和 endpos ,限制搜索范围。看一下示例:
import re
pattern = re.compile(r'bc', re.I)
it = pattern.finditer('12bc34BC56', 0, 6)
for match in it:
print(match)
Pattern.sub(repl, string, count=0)
使用了编译后的样式。看一下示例:
import re
pattern = re.compile(r'#.*$')
str = 'ityard # 是我的名字'
print(pattern.sub('', str))
ityard
Pattern.subn(repl, string, count=0)
使用了编译后的样式。看一下示例:
import re
pattern = re.compile(r'#.*$')
str = 'ityard # 是我的名字'
print(pattern.subn('', str))
('ityard ', 1)
匹配对象
最后看一匹配对象的相应方法。
Match.expand(template)
对 template 进行反斜杠转义替换并且返回。看一下示例:
import re
match = re.match(r'(?P\w+) (?P\w+)' ,'2020 01')
print(match.expand(r'现在是 \1 年 \2 月'))
现在是 2020 年 01 月
Match.group([group1, …])
返回一个或者多个匹配的子组。看一下示例:
import re
match = re.match(r'(?P\w+) (?P\w+)' ,'2020 01')
print(match.group(0))
print(match.group(1))
print(match.group(2))
2020 01
2020
01
Match.groups(default=None)
返回一个元组,包含所有匹配的子组,在样式中出现的从 1 到任意多的组合,default 参数用于不参与匹配的情况,默认为 None。看一下示例:
import re
match = re.match(r'(?P\w+) (?P\w+)' ,'2020 01')
print(match.groups())
('2020', '01')
Match.groupdict(default=None)
返回一个字典,包含了所有的命名子组,default 参数用于不参与匹配的组合,默认为 None。看一下示例:
import re
match = re.match(r'(?P\w+) (?P\w+)' ,'2020 01')
print(match.groupdict())
{'year': '2020', 'month': '01'}
Match.start([group]) 和 Match.end([group])
返回 group 匹配到的字串的开始和结束标号。看一下示例:
import re
match = re.match(r'(?P\w+) (?P\w+)' ,'2020 01')
print(match.start())
print(match.end())
0
7
Match.span([group])
对于一个匹配 m,返回一个二元组 (m.start(group), m.end(group))。看一下示例:
import re
match = re.match(r'(?P\w+) (?P\w+)' ,'2020 01')
print(match.span())
(0, 7)
进阶
1. 多线程
解释器
Python 解释器的主要作用是将我们在 .py 文件中写好的代码交给机器去执行。
GIL
GIL 全称 global interpreter lock,中文译为全局解释器锁,CPython 解释器就是通过 GIL 机制来确保同一时刻只有一个线程执行 Python 代码的,这样做十分方便的帮助 CPython 解决了并发访问的线程安全问题,但却牺牲了在多处理器上的并行性,所以 CPython 解释器下的多线程并不是真正意义上的多线程。
我们可能会有一个疑问:既然 CPython 解释器使用 GIL 机制牺牲了多线程的并行性,那么把 GIL 去掉换用其他方式实现不行吗?在说这个问题之前,我们先简单了解一下基本情况:最初因 GIL 可以简单、快捷的解决多线程并发访问的安全问题选择了这种机制,随后又有大量的代码库开发者开始依赖这种特性,随之时间的推移,人们开始意识到了并行性的问题,但这时已经到了尾大不掉的程度了,所以现实情况是:尽管可以去掉 GIL,但工程量太大了。
threading
Python(CPython) 提供了 _thread 和 threading 两个线程模块,_thread 是低级模块,threading 对 _thread 进行了封装,提高了 _thread 原有功能的易用性以及扩展了新功能,通常我们只需要使用 threading 模块就可以了,这里我们也只对 threading 模块进行详细介绍。
方法属性:
首先,我们来看一下 threading 模块的直接方法和属性。
threading.enumerate()
以列表形式返回当前所有存活的 threading.Thread 对象。
threading.active_count()
返回当前存活的 threading.Thread 对象,等于 len(threading.enumerate())。
threading.current_thread()
返回当前对应调用者控制的 threading.Thread 对象,如果调用者的控制线程不是利用 threading 创建,则会返回一个功能受限的虚拟线程对象。
threading.get_ident()
返回当前线程的线程标识符,它是一个非零的整数,其值没有直接含义,它可能会在线程退出,新线程创建时被复用。
threading.main_thread()
返回主线程对象,一般情况下,主线程是 Python 解释器开始时创建的线程。
threading.stack_size([size])
返回创建线程时用的堆栈大小,可选参数 size 指定之后新建线程的堆栈大小,size 值需要为 0 或者最小是 32768(32KiB)的一个正整数,如不指定 size,则默认为 0。
threading.get_native_id()
返回内核分配给当前线程的原生集成线程 ID,其值是一个非负整数。
threading.TIMEOUT_MAX
指定阻塞函数(如:Lock.acquire(), Condition.wait() …)中形参 timeout 允许的最大值,传入超过这个值的 timeout 会抛出 OverflowError 异常。
线程对象:
先了解一下 Python 守护线程基本概念。
守护线程:当一个线程被标记为守护线程时,Python 程序会在剩下的线程都是守护线程时退出,即等待所有非守护线程运行完毕;守护线程在程序关闭时会突然关闭,可能会导致资源不能被正确释放的的问题,如:已经打开的文档等。
非守护线程:通常我们创建的线程默认就是非守护线程,Python 程序退出时,如果还有非守护线程在运行,程序会等待所有非守护线程运行完毕才会退出。
threading.Thread(group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None)
创建线程对象,参数说明如下所示。
- group:通常默认即可,作为日后扩展 ThreadGroup 类实现而保留。
- target:用于 run() 方法调用的可调用对象,默认为 None。
- name:线程名称,默认是 Thread-N 格式构成的唯一名称,其中 N 是十进制数。
- args:用于调用目标函数的参数元组,默认为 ()。
- kwargs:用于调用目标函数的关键字参数字典,默认为 {}。
- daemon:设置线程是否为守护模式,默认为 None。
看一下线程对象 threading.Thread 的方法和属性。
start():启动线程。
run():线程执行具体功能的方法。
join(timeout=None):当 timeout 为 None 时,会等待至线程结束;当 timeout 不为 None 时,会等待至 timeout 时间结束,单位为秒。
is_alive():判断线程是否存活。
getName():返回线程名。
setName():设置线程名。
isDaemon():判断线程是否为守护线程。
setDaemon():设置线程是否为守护线程。
name:线程名。
ident:线程标识符。
daemon:线程是否为守护线程。
我们可以通过实例化 threading.Thread 来创建线程,也可以使用继承 threading.Thread 的子类来创建。
实例化 threading.Thread
import threading
import time
def target(sleep):
time.sleep(sleep)
print('当前线程为:', threading.current_thread().name,' ', 'sleep:', sleep)
if __name__ == '__main__':
t1 = threading.Thread(name='t1', target=target, args=(1,))
t2 = threading.Thread(name='t2', target=target, args=(2,))
t1.start()
t2.start()
print('主线程结束')
主线程结束
当前线程为: t1 sleep: 1
当前线程为: t2 sleep: 2
继承 threading.Thread
import threading
import time
class MyThread(threading.Thread):
def __init__(self, sleep, name):
super().__init__()
self.sleep = sleep
self.name = name
def run(self):
time.sleep(self.sleep)
print('name:' + self.name)
if __name__ == '__main__':
t1 = MyThread(1, 't1')
t2 = MyThread(1, 't2')
t1.start()
t2.start()
name:t2name:t1
锁对象
同一变量在多线之间是共享的,任何一个变量都可以被所有线程修改,当多个线程一起修改同一变量时,很可能互相冲突得不到正确的结果,造成线程安全问题,如:
import threading
a = 5
def oper(b):
global a
a = a - b
a = a + b
def target(b):
for i in range(100000):
oper(b)
if __name__ == '__main__':
m = 10
while m > 0:
t1 = threading.Thread(target=target, args=(1,))
t2 = threading.Thread(target=target, args=(2,))
t1.start()
t2.start()
t1.join()
t2.join()
print(a)
m = m - 1
执行结果:
5
5
5
6
6
正常情况下,oper(b) 操作会使 a 的值保持不变,但从多线程的执行结果来看,我们发现出现了错误的结果,并且每次执行的结果可能不同,通常这种问题我们可以使用加锁的方式解决。
threading.Lock
实现原始锁对象的类,一旦一个线程获得一个锁,会阻塞随后尝试获得锁的线程,直到它被释放,通常称其为互斥锁,它是由 _thread 模块直接扩展实现的。它具有如下方法:
-
acquire(blocking=True, timeout=-1):可以阻塞或非阻塞地获得锁,参数 blocking 用来设置是否阻塞,timeout 用来设置阻塞时间,当 blocking 为 False 时 timeout 将被忽略。
-
release():释放锁。
-
locked():判断是否获得了锁,如果获得了锁则返回 True。
threading.RLock
可重入锁(也称递归锁)类,一旦线程获得了重入锁,同一个线程再次获取它将不阻塞,重入锁必须由获取它的线程释放。它具有如下方法:
-
acquire(blocking=True, timeout=-1):解释同上。
-
release():解释同上。
import threading
# 创建锁
lock = threading.Lock()
a = 5
def oper(b):
# 获取锁
lock.acquire()
global a
a = a - b
a = a + b
# 释放锁
lock.release()
def target(b):
for i in range(100000):
oper(b)
if __name__ == '__main__':
m = 5
while m > 0:
t1 = threading.Thread(target=target, args=(1,))
t2 = threading.Thread(target=target, args=(2,))
t1.start()
t2.start()
t1.join()
t2.join()
print(a)
m = m - 1
5
5
5
5
5
条件对象
条件对象总是与某种类型的锁对象相关联,锁对象可以通过传入获得,或者在缺省的情况下自动创建。
threading.Condition(lock=None)
实现条件对象的类。它具有如下方法:
-
acquire(*args):请求底层锁。
-
release():释放底层锁。
-
wait(timeout=None):等待直到被通知或发生超时。
-
wait_for(predicate, timeout=None):等待直到条件计算为 True,predicate 是一个可调用对象且它的返回值可被解释为一个布尔值。
-
notify(n=1):默认唤醒一个等待该条件的线程。
-
notify_all():唤醒所有正在等待该条件的线程。
使用条件对象的典型场景是将锁用于同步某些共享状态的权限,那些关注某些特定状态改变的线程重复调用 wait() 方法,直到所期望的改变发生;对于修改状态的线程,它们将当前状态改变为可能是等待者所期待的新状态后,调用 notify() 方法或者 notify_all() 方法
import time
import threading
# 创建条件对象
c = threading.Condition()
privilege = 0
def getPri():
global privilege
c.acquire()
c.wait()
print(privilege)
c.release()
def updPri():
time.sleep(5)
c.acquire()
global privilege
privilege = 1
c.notify()
c.release()
if __name__ == '__main__':
t1 = threading.Thread(target=getPri)
t2 = threading.Thread(target=updPri)
t1.start()
t2.start()
如果 acquire 获取锁的线程一直 wait 其他线程 notify,此锁会一直卡住,别的线程无法 acquire 到锁?
信号量对象
和锁机制一样,信号量机制也是一种实现线程同步的机制,不过它比锁多了一个计数器,这个计数器主要用来计算当前剩余的锁的数量。
threading.Semaphore(value=1)
信号量实现类,可选参数 value 赋予内部计数器初始值,默认值为 1 。它具有如下方法:
-
acquire(blocking=True, timeout=None):获取一个信号量,参数 blocking 用来设置是否阻塞,timeout 用来设置阻塞时间。
-
release():释放一个信号量,将内部计数器的值增加1。
import threading
# 创建信号量对象
s = threading.Semaphore(10)
a = 5
def oper(b):
# 获取信号量
s.acquire()
global a
a = a - b
a = a + b
# 释放信号量
s.release()
def target(b):
for i in range(100000):
oper(b)
if __name__ == '__main__':
m = 5
while m > 0:
t1 = threading.Thread(target=target, args=(1,))
t2 = threading.Thread(target=target, args=(2,))
t1.start()
t2.start()
t1.join()
t2.join()
print(a)
m = m - 1
是不是没什么用这个锁,一共两个线程?应该是一起进入
事件对象
一个线程发出事件信号,其他线程等待该信号,这是最简单的线程之间通信机制之一。
threading.Event
实现事件对象的类。它有如下方法:
-
is_set():当内部标志为 True 时返回 True。
-
set():将内部标志设置为 True。
-
clear():将内部标志设置为 False。
-
wait(timeout=None):阻塞线程直到内部变量为 True。
import time
import threading
# 创建事件对象
event = threading.Event()
def dis_class():
#time.sleep(5)#下课铃响,同学们立马下课;时间看来初始默认为false
event.wait()
print('同学们下课了')
def bell():
time.sleep(3)
print('下课铃声响了')
event.set()
if __name__ == '__main__':
t1 = threading.Thread(target=bell)
t2 = threading.Thread(target=dis_class)
t1.start()
t2.start()
t1.join()
t2.join()
2.多进程
进程:通常一个运行着的应用程序就是一个进程,比如:我启动了一个音乐播放器,现在它就是一个进程。线程:线程是进程的最小执行单元,比如:我在刚启动的音乐播放器上选了一首歌曲进行播放,这就是一个线程。
因为 GIL 的原因,CPython 解释器下的多线程牺牲了并行性,为此 Python 提供了多进程模块 multiprocessing,该模块同时提供了本地和远程并发,使用子进程代替线程,可以有效的避免 GIL 带来的影响,能够充分发挥机器上的多核优势,可以实现真正的并行效果,并且它与 threading 模块的 API 基本类似,使用起来也比较方便。
Process 类
multiprocessing 模块通过创建一个Process对象然后调用它的 start() 方法来生成进程,Process 与 threading.Thread API 相同。
multiprocessing.Process(group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None)
进程对象,表示在单独进程中运行的活动。参数说明如下:
- group:仅用于兼容 threading.Thread,应该始终是 None。
- target:由 run() 方法调用的可调用对象。
- name:进程名。
- args:目标调用的参数元组。
- kwargs:目标调用的关键字参数字典。
- daemon:设置进程是否为守护进程,如果是默认值 None,则该标志将从创建的进程继承。
multiprocessing.Process 对象具有如下方法和属性。
- run():进程具体执行的方法。
- start():启动进程。
- join([timeout]):如果可选参数 timeout 是默认值 None,则将阻塞至调用 join() 方法的进程终止;如果 timeout 是一个正数,则最多会阻塞 timeout 秒。
- name:进程的名称。
- is_alive():返回进程是否还活着。
- daemon:进程的守护标志,是一个布尔值。
- pid:返回进程 ID。
- exitcode:子进程的退出代码。
- authkey:进程的身份验证密钥。
- sentinel:系统对象的数字句柄,当进程结束时将变为 ready。
- terminate():终止进程。
- kill():与 terminate() 相同,但在 Unix 上使用 SIGKILL 信号。
- close():关闭 Process 对象,释放与之关联的所有资源。
多进程的示例。
from multiprocessing import Process
import time, os
def target():
time.sleep(2)
print ('子进程ID:', os.getpid())
if __name__=='__main__':
print ('主进程ID:', os.getpid())
ps = []
for i in range(10):
p = Process(target=target)
p.start()
ps.append(p)
for p in ps:
p.join()
注意,此文件的名称不能为 multiprocessing.py
主进程ID: 10252
貌似子进程的打印信息不会出现控制台界面。
当进程数量比较多时,我们可以利用进程池方便、高效的对进程进行使用和管理。
multiprocessing.pool.Pool([processes[, initializer[, initargs[, maxtasksperchild[, context]]]]])
进程池对象。参数说明如下:
- processes:工作进程数目,如果 processes 为 None,则使用 os.cpu_count() 返回的值。
- initializer:如果 initializer 不为 None,则每个工作进程将会在启动时调用 initializer(*initargs)。
- maxtasksperchild:一个工作进程在它退出或被一个新的工作进程代替之前能完成的任务数量,为了释放未使用的资源。
- context:用于指定启动的工作进程的上下文。
有如下两种方式向进程池提交任务:
- apply(func[, args[, kwds]]):阻塞方式。
- apply_async(func[, args[, kwds[, callback[, error_callback]]]]):非阻塞方式。
import multiprocessing, time
def target(p):
print('t')
time.sleep(2)
print(p)
if __name__ == "__main__":
pool = multiprocessing.Pool(processes = 5)
for i in range(3):
p = 'p%d'%(i)
# 阻塞式
pool.apply(target, (p, ))
# 非阻塞式
# pool.apply_async(target, (p, ))
pool.close()
pool.join()
print("over")
进程间交换数据
管道
multiprocessing.Pipe([duplex])
返回一对 Connection 对象 (conn1, conn2) , 分别表示管道的两端;如果 duplex 被置为 True (默认值),那么该管道是双向的,否则管道是单向的。
from multiprocessing import Pipe, Process
import time
def setData(conn, data):
conn.send(data)
def printData(conn):
print(conn.recv())
if __name__ == "__main__":
data = '程序之间'
# 创建管道返回管道的两端
conn1, conn2 = Pipe()
p1 = Process(target=setData, args=(conn1, data,))
p2 = Process(target=printData, args=(conn2,))
p1.start()
p2.start()
#conn1.send("wqer")
#print(conn2.recv())
#time.sleep(1)
#print(conn2.recv())
p1.join()
p2.join()
print("over")
队列
multiprocessing.Queue([maxsize])
返回一个共享队列实例。具有如下方法:
- qsize():返回队列的大致长度。
- empty():如果队列是空的,返回 True,反之返回 False。
- full():如果队列是满的,返回 True,反之返回 False。
- put(obj[, block[, timeout]]):将 obj 放入队列。
- put_nowait(obj):相当于 put(obj, False)。
- get([block[, timeout]]):从队列中取出并返回对象。
- get_nowait():相当于 get(False)。
- close():指示当前进程将不会再往队列中放入对象。
- join_thread():等待后台线程。
- cancel_join_thread():防止进程退出时自动等待后台线程退出。
from multiprocessing import Queue, Process
def setData(q, data):
q.put(data)
def printData(q):
print(q.get())
if __name__ == "__main__":
data = '程序之间'
q = Queue()
p1 = Process(target=setData, args=(q, data,))
p2 = Process(target=printData, args=(q,))
p1.start()
p2.start()
p1.join()
p2.join()
进程间同步
多进程之间不共享数据,但共享同一套文件系统,像访问同一个文件、同一终端打印,如果不进行同步操作,就会出现错乱的现象。
所有在 threading 存在的同步方式,multiprocessing 中都有类似的等价物,如:锁、信号量等。以锁的方式为例,我们来看一个终端打印例子。
不加锁
from multiprocessing import Process
import os,time
def target():
print('p%s is start' %os.getpid())
time.sleep(2)
print('p%s is end' %os.getpid())
if __name__ == '__main__':
for i in range(3):
p=Process(target=target)
p.start()
执行结果:
p7996 is start
p10404 is start
p10744 is start
p7996 is end
p10404 is end
p10744 is end
加锁
from multiprocessing import Process, Lock
import os,time
def target(lock):
lock.acquire()
print('p%s is start' %os.getpid())
time.sleep(2)
print('p%s is end' %os.getpid())
lock.release()
if __name__ == '__main__':
lock = Lock()
for i in range(3):
p=Process(target=target, args=(lock,))
p.start()
执行结果:
p11064 is start
p11064 is end
p1532 is start
p1532 is end
p11620 is start
p11620 is end
进程间共享状态
并发编程时,通常尽量避免使用共享状态,但如果有一些数据确实需要在进程之间共享怎么办呢?对于这种情况,multiprocessing 模块提供了两种方式。
共享内存:
multiprocessing.Value(typecode_or_type, *args, lock=True)
返回一个从共享内存上创建的对象。参数说明如下:
- typecode_or_type:返回的对象类型。
- *args:传给类的构造函数。
- lock:如果 lock 值是 True(默认值),将会新建一个递归锁用于同步此值的访问操作;如果 lock 值是 Lock、RLock 对象,那么这个传入的锁将会用于同步这个值的访问操作;如果 lock 是 False,那么对这个对象的访问将没有锁保护,也就是说这个变量不是进程安全的。
multiprocessing.Array(typecode_or_type, size_or_initializer, *, lock=True)
从共享内存中申请并返回一个数组对象。
- typecode_or_type:返回的数组中的元素类型。
- size_or_initializer:如果参数值是一个整数,则会当做数组的长度;否则参数会被当成一个序列用于初始化数组中的每一个元素,并且会根据元素个数自动判断数组的长度。
- lock:说明同上。
使用 Value 或 Array 将数据存储在共享内存映射中。
from multiprocessing import Process, Value, Array
def setData(n, a):
n.value = 1024
for i in range(len(a)):
a[i] = -a[i]
#没用到
def printData(n, a):
print(num.value)
print(arr[:])
if __name__ == '__main__':
num = Value('d', 0.0)
arr = Array('i', range(5))
print(num.value)
print(arr[:])
print('-----------------------')
p = Process(target=setData, args=(num, arr))
p.start()
p.join()
print(num.value)
print(arr[:])
0.0
[0, 1, 2, 3, 4]
-----------------------
1024.0
[0, -1, -2, -3, -4]
服务进程:
由 Manager() 返回的管理器对象控制一个服务进程,该进程保存 Python 对象并允许其他进程使用代理操作它们。
Manager() 返回的管理器支持类型包括:list、dict、Namespace、Lock、RLock、Semaphore、BoundedSemaphore、Condition、Event、Barrier、Queue、Value 和 Array。
from multiprocessing import Process, Manager
def setData(d, l):
d[1] = '1'
d[0.5] = None
l.reverse()
if __name__ == '__main__':
with Manager() as manager:
d = manager.dict()
l = manager.list(range(5))
print(d)
print(l)
print('-----------------------')
p = Process(target=setData, args=(d, l))
p.start()
p.join()
print(d)
print(l)
{}
[0, 1, 2, 3, 4]
-----------------------
{1: '1', 0.5: None}
[4, 3, 2, 1, 0]
3.网络编程
网络编程主要的工作就是在发送端将信息通过指定的协议进行组装包,在接收端按照规定好的协议对包进行解析并提取出对应的信息,最终达到通信的目的。传输协议主要有 TCP 和 UDP,TCP 需要建立连接,是可靠的、基于字节流的协议,通常与 IP 协议共同使用;UDP 不需要建立连接,可靠性差,但速度更快。
网络编程有一个重要的概念 socket(套接字),应用程序可以通过它发送或接收数据,套接字允许应用程序将 I/O 插入到网络中,并与网络中的其他应用程序进行通信。
Python 提供了如下两个 socket 模块:
Socket:提供了标准的 BSD Sockets API,可以访问底层操作系统 Socket 接口的全部方法。
SocketServer:提供了服务器中心类,可以简化网络服务器的开发。
API 介绍
Python 中通过 socket() 函数来创建套接字对象,具体格式如下:
socket.socket(family=AF_INET, type=SOCK_STREAM, proto=0, fileno=None)
- family:套接字协议族,可以使用 AF_UNIX(只能用于单一的 Unix 系统进程间通信)、AF_INET(服务器之间网络通信)
- type:套接字类型,可以使用 SOCK_STREAM(面向连接的)、SOCK_DGRAM(非连接的)
套接字对象服务端方法:
| 方法 | 描述 |
|---|---|
| bind(address) | 将套接字绑定到地址,在 AF_INET 下以元组 (host,port) 的形式表示地址 |
| listen([backlog]) | 开始监听 TCP 传入连接,backlog 指定在拒绝连接之前,操作系统可以挂起的最大连接数量,至少为1,大部分应用程序设为 5 就可以了 |
| accept() | 接受 TCP 连接并返回 (conn,address),conn 是新的套接字对象,可以用来接收、发送数据,address 是连接客户端的地址 |
套接字对象客户端方法:
| 方法 | 描述 |
|---|---|
| connect(address) | 连接到 address 处的套接字,格式一般为元组 (hostname,port),如果连接出错,返回 socket.error 错误 |
| connect_ex(address) | 功能与 connect(address) 相同,但是成功返回 0,失败返回 errno 的值 |
套接字对象公用方法:
| 方法 | 描述 |
|---|---|
| recv(bufsize[, flags]) | 接受 TCP 套接字的数据,数据以字符串形式返回,bufsize 指定要接收的最大数据量,flag 提供有关消息的其他信息,通常可以忽略 |
| send(bytes[, flags]) | 发送 TCP 数据,将 string 中的数据发送到连接的套接字,返回值是要发送的字节数量,该数量可能小于 string 的字节大小 |
| sendall(bytes[, flags]) | 完整发送 TCP 数据,将 string 中的数据发送到连接的套接字,但在返回之前会尝试发送所有数据,成功返回 None,失败则抛出异常 |
| recvfrom(bufsize[, flags]) | 接受 UDP 套接字的数据,与 recv() 类似,但返回值是 (data,address),其中 data 是包含接收数据的字符串,address 是发送数据的套接字地址 |
| sendto(bytes, flags, address) | 发送 UDP 数据,将数据发送到套接字,address 是形式为 (ipaddr,port) 的元组,指定远程地址,返回值是发送的字节数 |
| close() | 关闭套接字 |
| getpeername() | 返回连接套接字的远程地址,类型通常是元组 (ipaddr,port) |
| getsockname() | 返回套接字自己的地址,通常是一个元组 (ipaddr,port) |
| setsockopt(level,optname,value) | 设置给定套接字选项的值 |
| getsockopt(level, optname[, buflen]) | 返回套接字选项的值 |
| settimeout(value) | 设置套接字操作的超时时间,单位是秒 |
| gettimeout() | 返回当前超时时间 |
| fileno() | 返回套接字的文件描述符 |
| setblocking(flag) | 如果 flag 为 0,则将套接字设为非阻塞模式,否则将套接字设为阻塞模式(默认值);非阻塞模式下,如果调用 recv() 没有发现任何数据或 send() 调用无法立即发送数据,那么将引起 socket.error 异常 |
| makefile() | 创建一个与该套接字相关连的文件 |
TCP 方式
我们来看一下如何通过 socket 以 TCP 方式进行通信。
服务端基本思路:
- 创建套接字,绑定套接字到 IP 与端口
- 监听连接
- 不断接受客户端的连接请求
- 接收请求的数据,并向对方发送响应数据
- 传输完毕后,关闭套接字
具体代码实现如下:
import socket
# 创建套接字
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 绑定地址
s.bind(('127.0.0.1', 6666))
# 监听连接
s.listen(5)
while True:
print('等待客户端发送信息...')
# 接收连接
sock, addr = s.accept()
# 接收请求数据
data = sock.recv(1024).decode('utf-8')
print('服务端接收请求数据:' + data)
# 发送响应数据
sock.sendall(data.upper().encode('utf-8'))
# 关闭
sock.close()
等待客户端发送信息...
服务端接收请求数据:hello
等待客户端发送信息...
客户端基本思路:
- 创建套接字,连接服务端
- 连接后发送、接收数据
- 传输完毕后,关闭套接字
具体代码实现如下:
import socket
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 连接服务端
s.connect(('127.0.0.1', 6666))
# 向服务端发送数据
s.sendall(b'hello')
# 接受服务端响应数据
data = s.recv(1024)
print('客户端接收响应数据:' + data.decode('utf-8'))
# 关闭
s.close()
客户端接收响应数据:HELLO
我们只需先运行服务端代码,再运行客户端代码即可。
UDP 方式:
我们再来看一下如何通过 socket 以 UDP 方式进行通信。
服务端基本思路:
- 创建套接字,绑定套接字到 IP 与端口
- 接收客户端请求的数据
- 向客户端发送响应数据
具体代码实现如下:
import socket
# 创建套接字
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# 绑定地址
s.bind(('127.0.0.1', 6666))
while True:
# 接收数据
data, addr = s.recvfrom(1024)
print('服务端接收请求数据:' + data.decode('utf-8'))
# 响应数据
s.sendto(data.decode('utf-8').upper().encode('utf-8'), addr)
客户端基本思路:
- 创建套接字
- 向服务端发送数据
- 接受服务端响应数据
具体代码实现如下:
import socket
# 创建套接字
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# 向服务端发送数据
s.sendto(b'hello', ('127.0.0.1', 6666))
# 接受服务端响应数据
data = s.recv(1024).decode('utf-8')
print('客户端接收响应数据:' + data)
# 关闭
s.close()
同样的,我们还是先运行服务端代码,再运行客户端代码即可
爬虫
Request Headers 中包含 Referer 和 User-Agent 两个属性信息,Referer 的作用是告诉服务器该网页是从哪个页面链接过来的,User-Agent 中文是用户代理,它是一个特殊字符串头,作用是让服务器能够识别用户使用的操作系统、CPU 类型、浏览器等信息。通常的处理策略是:1)对于要检查 Referer 的网站就加上;2)对于每个 request 都添加 User-Agent。
1)不规则信息:网址上会有一些没有规则的一长串信息,这种情况通常采用 selenium(模拟浏览器,效率会低一些) 解决;
2)动态校验码:比如根据时间及一些其他自定义规则生成,这种情况我们就需要找到其规则进行破解了;
3)动态交互:需要与页面进行交互才能通过验证,可以采用 selenium 解决;
4)分批次异步加载:这种情况获取的信息可能不完整,可以采用 selenium 解决。
Requests
Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用。警告:非专业使用其他 HTTP 库会导致危险的副作用,包括:安全缺陷症、冗余代码症、重新发明轮子症、啃文档症、抑郁、头疼、甚至死亡。
安装:pip install requests
导入:import requests
获取网页:r = requests.get('http://xxx.xxx')
此时,我们获取了 Response 对象 r,我们可以通过 r 获取所需信息。Requests 简便的 API 意味着所有 HTTP 请求类型都是显而易见的,我们来看一下使用常见 HTTP 请求类型 get、post、put、delete 的示例:
r = requests.head('http://xxx.xxx/get')
r = requests.post('http://xxx.xxx/post', data = {'key':'value'})
r = requests.put('http://xxx.xxx/put', data = {'key':'value'})
r = requests.delete('http://xxx.xxx/delete')
通常我们会设置请求的超时时间,Requests 使用 timeout 参数来设置,单位是秒,示例如下:
r = requests.head('http://xxx.xxx/get', timeout=1)
参数传递
在使用 get 方式发送请求时,我们会将键值对形式参数放在 URL 中问号的后面,如:http://xxx.xxx/get?key=val ,Requests 通过 params 关键字,以一个字符串字典来提供这些参数。比如要传 key1=val1 和 key2=val2 到 http://xxx.xxx/get,示例如下:
pms= {'key1': 'val1', 'key2': 'val2'}
r = requests.get("http://xxx.xxx/get", params=pms)
Requests 还允许将一个列表作为值传入:
pms= {'key1': 'val1', 'key2': ['val2', 'val3']}
注:字典里值为 None 的键都不会被添加到 URL 的查询字符串里。
响应内容
我们来获取一下服务器的响应内容,这里地址 https://api.github.com 为例:
import requests
r = requests.get('https://api.github.com')
print(r.text)
# 输出结果
# {"current_user_url":"https://api.github.com/user","current_user...
当访问 r.text 之时,Requests 会使用其推测的文本编码,我们可以使用 r.encoding 查看其编码,也可以修改编码,如:r.encoding = ‘GBK’,当改变了编码,再次访问 r.text 时,Request 都将会使用 r.encoding 的新值。
1)二进制响应内容 比如当我们要获取一张图片的数据,会以二进制的方式获取响应数据,示例如下:
from PIL import Image
from io import BytesIO
i = Image.open(BytesIO(r.content))
2)JSON响应内容 Requests 中已经内置了 JSON 解码器,因此我们可以很容易的对 JSON 数据进行解析,示例如下:
import requests
r = requests.get('https://api.github.com')
r.json()
注:成功调用 r.json() 并不一定响应成功,有的服务器会在失败的响应中包含一个 JSON 对象(比如 HTTP 500 的错误细节),这时我们就需要查看响应的状态码了 r.status_code 或 r.raise_for_status(),成功调用时 r.status_code 为 200,r.raise_for_status() 为 None。
自定义请求头
当我们要给请求添加 headers 时,只需给 headers 参数传递一个字典即可,示例如下:
url = 'http://xxx.xxx'
hds= {'user-agent': 'xxx'}
r = requests.get(url, headers=hds)
注:自定义 headers 优先级是低于一些特定的信息的,如:在 .netrc 中设置了用户认证信息,使用 headers 设置的授权就不会生效,而当设置了 auth 参数,.netrc 的设置会无效。所有的 headers 值必须是 string、bytestring 或者 unicode,通常不建议使用 unicode。
重定向与历史
默认情况下,Requests 会自动处理除了 HEAD 以外的所有重定向,可以使用响应对象的 history 属性来追踪重定向,其返回为响应对象列表,这个列表是按照请求由晚到早进行排序的,看一下示例:
import requests
r = requests.get('http://github.com')
print(r.history)
# 输出结果
# []
如果使用的是get、post、put、delete、options、patch 可以使用 allow_redirects 参数禁用重定向。示例如下:
r = requests.get('http://xxx.xxx', allow_redirects=False)
错误与异常
当遇到网络问题(如:DNS 查询失败、拒绝连接等)时,Requests 会抛出 ConnectionError 异常;在 HTTP 请求返回了不成功的状态码时, Response.raise_for_status() 会抛出 HTTPError 异常;请求超时,会抛出 Timeout 异常;请求超过了设定的最大重定向次数,会抛出 TooManyRedirects 异常。所有 Requests 显式抛出的异常都继承自 requests.exceptions.RequestException。
BeautifulSoup
BeautifulSoup 是一个可以从 HTML 或 XML 文件中提取数据的 Python 库,它能够将 HTML 或 XML 转化为可定位的树形结构,并提供了导航、查找、修改功能,它会自动将输入文档转换为 Unicode 编码,输出文档转换为 UTF-8 编码。
BeautifulSoup 支持 Python 标准库中的 HTML 解析器和一些第三方的解析器,默认使用 Python 标准库中的 HTML 解析器,默认解析器效率相对比较低,如果需要解析的数据量比较大或比较频繁,推荐使用更强、更快的 lxml 解析器。
-
BeautifulSoup 安装
如果使用 Debain 或 ubuntu 系统,可以通过系统的软件包管理来安装:apt-get install Python-bs4,如果无法使用系统包管理安装,可以使用pip install beautifulsoup4来安装。 -
第三方解析器安装
如果需要使用第三方解释器 lxml 或 html5lib,可是使用如下命令进行安装:apt-get install Python-lxml(html5lib) 和pip install lxml(html5lib)。
看一下主要解析器和它们的优缺点:
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup,“html.parser”) | Python的内置标准库;执行速度适中;文档容错能力强。 | Python 2.7.3 or 3.2.2)前的版本中文档容错能力差。 |
| lxml HTML 解析器 | BeautifulSoup(markup,“lxml”) | 速度快;文档容错能力强。 | 需要安装C语言库。 |
| lxml XML 解析器 | BeautifulSoup(markup,[“lxml-xml”]);BeautifulSoup(markup,“xml”) | 速度快;唯一支持XML的解析器。 | 需要安装C语言库 |
| html5lib | BeautifulSoup(markup,“html5lib”) | 最好的容错性;以浏览器的方式解析文档;生成HTML5格式的文档。 | 速度慢;不依赖外部扩展。 |
将一段文档传入 BeautifulSoup 的构造方法,就能得到一个文档的对象,可以传入一段字符串或一个文件句柄
- 传入字符串
html = '''
BeautifulSoup学习
Hello BeautifulSoup
'''
from bs4 import BeautifulSoup
#使用默认解析器
soup = BeautifulSoup(html,'html.parser')
#使用 lxml 解析器
soup = BeautifulSoup(html,'lxml')
- 本地文件
还以上面那段 HTML 为例,将上面 HTML 字符串放在 index.html 文件中,使用示例如下:
#使用默认解析器
soup = BeautifulSoup(open('index.html'),'html.parser')
#使用 lxml 解析器
soup = BeautifulSoup(open('index.html'),'lxml')
对象的种类
BeautifulSoup 将 HTML 文档转换成一个树形结构,每个节点都是 Python 对象,所有对象可以归纳为4种:Tag,NavigableString,BeautifulSoup,Comment。
- Tag 对象
Tag 对象与 HTML 或 XML 原生文档中的 tag 相同,示例如下:
soup = BeautifulSoup('BeautifulSoup学习 ','lxml')
tag = soup.title
tp =type(tag)
print(tag)
print(tp)
#输出结果
BeautifulSoup学习
Tag 有很多方法和属性,这里先看一下它的的两种常用属性:name 和 attributes。
我们可以通过 .name 来获取 tag 的名字,示例如下:
soup = BeautifulSoup('BeautifulSoup学习 ','lxml')
tag = soup.title
print(tag.name)
#输出结果
#title
我们还可以修改 tag 的 name,示例如下:
tag.name = 'title1'
print(tag)
#输出结果
#BeautifulSoup学习
一个 tag 可能有很多个属性,先看一它的 class 属性,其属性的操作方法与字典相同,示例如下:
soup = BeautifulSoup('BeautifulSoup学习 ','lxml')
tag = soup.title
cls = tag['class']
print(cls)
#输出结果
#['tl']
我们还可以使用 .attrs 来获取,示例如下:
ats = tag.attrs
print(ats)
#输出结果
#{'class': ['tl']}
tag 的属性可以被添加、修改和删除,示例如下:
#添加 id 属性
tag['id'] = 1
#修改 class 属性
tag['class'] = 'tl1'
#删除 class 属性
del tag['class']
-
NavigableString 对象
NavigableString 类是用来包装 tag 中的字符串内容的,使用 .string 来获取字符串内容,示例如下:
str = tag.string
可以使用replace_with()方法将原有字符串内容替换成其它内容 ,示例如下:
tag.string.replace_with('BeautifulSoup') -
BeautifulSoup 对象
BeautifulSoup 对象表示的是一个文档的全部内容,它并不是真正的 HTML 或 XML 的 tag,因此它没有 name 和 attribute 属性,为方便查看它的 name 属性,BeautifulSoup 对象包含了一个值为 [document] 的特殊属性 .name,示例如下:
soup = BeautifulSoup('BeautifulSoup学习 ','lxml')
print(soup.name)
#输出结果
#[document]
- Comment 对象
Comment 对象是一个特殊类型的 NavigableString 对象,它会使用特殊的格式输出,看一下例子:
soup = BeautifulSoup('Hello BeautifulSoup ','html.parser')
comment = soup.title.prettify()
print(comment)
#输出结果
'''
Hello BeautifulSoup
'''
我们前面看的例子中 tag 中的字符串内容都不是注释内容,现在将字符串内容换成注释内容,我们来看一下效果:
soup = BeautifulSoup('<!--Hello BeautifulSoup--> ','html.parser')
str = soup.title.string
print(str)
#输出结果
#Hello BeautifulSoup
通过结果我们发现注释符号被自动去除了,这一点我们要注意一下。
搜索文档树
BeautifulSoup 定义了很多搜索方法,我们来具体看一下。
find_all():
find_all()方法搜索当前 tag 的所有 tag 子节点,方法详细如下:find_all(name=None, attrs={}, recursive=True, text=None,limit=None, **kwargs),来具体看一下各个参数。
- name 参数可以查找所有名字为 name 的 tag,字符串对象会被自动忽略掉,示例如下:
soup = BeautifulSoup('Hello BeautifulSoup ','html.parser')
print(soup.find_all('title'))
#输出结果
#[Hello BeautifulSoup ]
- attrs 参数定义一个字典参数来搜索包含特殊属性的 tag,示例如下:
soup = BeautifulSoup('Hello BeautifulSoup ','html.parser')
soup.find_all(attrs={"class": "tl"})
调用 find_all() 方法时,默认会检索当前 tag 的所有子孙节点,通过设置参数 recursive=False,可以只搜索 tag 的直接子节点,示例如下:
soup = BeautifulSoup('Hello BeautifulSoup ','html.parser')
print(soup.find_all('title',recursive=False))
#输出结果
#[]
- 通过 text 参数可以搜搜文档中的字符串内容,它接受字符串、正则表达式、列表、True,示例如下:
from bs4 import BeautifulSoup
import re
soup = BeautifulSoup('myHeadBeautifulSoup ','html.parser')
#字符串
soup.find_all(text='BeautifulSoup')
#正则表达式
soup.find_all(soup.find_all(text=re.compile('title')))
#列表
soup.find_all(soup.find_all(text=['head','title']))
#True
soup.find_all(text=True)
- limit 参数与 SQL 中的 limit 关键字类似,用来限制搜索的数据,示例如下:
soup = BeautifulSoup('ElsieElsie','html.parser')
soup.find_all('a', limit=1)
我们经常见到 Python 中 *arg 和 **kwargs 这两种可变参数,*arg 表示非键值对的可变数量的参数,将参数打包为 tuple 传递给函数;**kwargs 表示关键字参数,参数是键值对形式的,将参数打包为 dict 传递给函数。
使用多个指定名字的参数可以同时过滤 tag 的多个属性,如:
soup = BeautifulSoup('ElsieElsie','html.parser')
soup.find_all(href=re.compile("elsie"),id='link1')
有些 tag 属性在搜索不能使用,如 HTML5 中的 data-* 属性,示例如下:
soup = BeautifulSoup('foo!')
soup.find_all(data-foo='value')
首先当我在 Pycharm 中输入 data-foo=‘value’ 便提示语法错误了,然后我不管提示直接执行提示 SyntaxError: keyword can’t be an expression 这个结果也验证了 data-* 属性在搜索中不能使用。我们可以通过 find_all() 方法的 attrs 参数定义一个字典参数来搜索包含特殊属性的 tag,示例如下:
print(soup.find_all(attrs={'data-foo': 'value'}))
find():
方法详细如下:find(name=None, attrs={}, recursive=True, text=None,**kwargs),我们可以看出除了少了 limit 参数,其它参数与方法 find_all 一样,不同之处在于:find_all() 方法的返回结果是一个列表,find() 方法返回的是第一个节点,find_all() 方法没有找到目标是返回空列表,find() 方法找不到目标时,返回 None。来看个例子:
soup = BeautifulSoup('ElsieElsie','html.parser')
print(soup.find_all('a', limit=1))
print(soup.find('a'))
#输出结果
'''
[Elsie]
Elsie
'''
从示例中我们也可以看出,find() 方法返回的是找到的第一个节点。
find_parents() 和 find_parent():
find_all() 和 find() 用来搜索当前节点的所有子节点,find_parents() 和 find_parent() 则用来搜索当前节点的父辈节点。
find_next_siblings() 和 find_next_sibling():
这两个方法通过 .next_siblings 属性对当前 tag 所有后面解析的兄弟 tag 节点进行迭代,find_next_siblings() 方法返回所有符合条件的后面的兄弟节点,find_next_sibling() 只返回符合条件的后面的第一个tag节点。
find_previous_siblings() 和 find_previous_sibling():
这两个方法通过 .previous_siblings 属性对当前 tag 前面解析的兄弟 tag 节点进行迭代,find_previous_siblings() 方法返回所有符合条件的前面的兄弟节点,find_previous_sibling() 方法返回第一个符合条件的前面的兄弟节点。
find_all_next() 和 find_next():
这两个方法通过 .next_elements 属性对当前 tag 之后的 tag 和字符串进行迭代,find_all_next() 方法返回所有符合条件的节点,find_next() 方法返回第一个符合条件的节点。
find_all_previous() 和 find_previous():
这两个方法通过 .previous_elements 属性对当前节点前面的 tag 和字符串进行迭代,find_all_previous() 方法返回所有符合条件的节点,find_previous() 方法返回第一个符合条件的节点。
CSS选择器
BeautifulSoup 支持大部分的 CSS 选择器,在 Tag 或 BeautifulSoup 对象的 .select() 方法中传入字符串参数,即可使用 CSS 选择器的语法找到 tag,返回类型为列表。示例如下:
soup = BeautifulSoup('ElsieElsie','html.parser')
print(soup.select('a'))
#输出结果
#[Elsie, Elsie
通过标签逐层查找
soup.select('body a')
找到某个 tag 标签下的直接子标签
soup.select('body > a')
通过类名查找
soup.select('.elsie')
soup.select('[class~=elsie]')
通过 id 查找
soup.select('#link1')
使用多个选择器
soup.select('#link1,#link2')
通过属性查找
soup.select('a[class]')
通过属性的值来查找
soup.select('a[class="elsie"]')
查找元素的第一个
soup.select_one('.elsie')
查找兄弟节点标签
#查找所有
soup.select('#link1 ~ .elsie')
#查找第一个
soup.select('#link1 + .elsie')
Selenium
Selenium 是一个用于测试 Web 应用程序的框架,该框架测试直接在浏览器中运行,就像真实用户操作一样。它支持多种平台:Windows、Linux、Mac,支持多种语言:Python、Perl、PHP、C# 等,支持多种浏览器:Chrome、IE、Firefox、Safari 等。
安装
安装 Selenium
pip install selenium
安装 WebDriver
主要浏览器 WebDriver 地址如下:
Chrome:http://chromedriver.storage.googleapis.com/index.html
Firefox:https://github.com/mozilla/geckodriver/releases/
IE:http://selenium-release.storage.googleapis.com/index.html
本文以 Chrome 为例,本机为 Windows 系统,WebDriver 使用版本 78.0.3904.11,Chrome 浏览器版本为 78.0.3880.4 驱动程序下载好后解压,将 chromedriver.exe 放到 Python 安装目录下即可。
操作浏览器
打开浏览器
1)普通方式
以打开去 163 邮箱为例,使用 Chrome 浏览器
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://mail.163.com/')
使用 Firefox 浏览器
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('https://mail.163.com/')
使用 IE 浏览器
from selenium import webdriver
browser = webdriver.Ie()
browser.get('https://mail.163.com/')
2)加载配置方式
以 Chrome 为例,在 Chrome 浏览器地址栏输入 chrome://version/ 打开,如图所示:
我们可以看到个人资料路径这一项,取到路径:C:\Users\admin\AppData\Local\Google\Chrome\User Data,取到 User Data 使用自己设置的配置,取到 Default 使用默认配置。看下示例:
from selenium import webdriver
option = webdriver.ChromeOptions()
# 自己的数据目录(需要将复制的路径中的 \ 替换成 / 或进行转义 \\)
# option.add_argument('--user-data-dir=C:/Users/admin/AppData/Local/Google/Chrome/User Data')
option.add_argument('--user-data-dir=C:\\Users\\admin\\AppData\\Local\\Google\\Chrome\\User Data')
browser = webdriver.Chrome(chrome_options=option)
browser.get('https://mail.163.com/')
# 关闭
browser.quit()
如果执行时报错没有打开指定页面,可先将浏览器关闭再执行。
3)Headless 方式
前两种方式都是有浏览器界面的方式,Headless 模式是 Chrome 浏览器的无界面形态,可以在不打开浏览器的前提下,使用所有 Chrome 支持的特性运行我们的程序。这种方式更加方便测试 Web 应用、获得网站的截图、做爬虫抓取信息等。看下示例:
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
# 使用 headless 无界面浏览器模式
chrome_options.add_argument('--headless')
# 禁用 gpu 加速
chrome_options.add_argument('--disable-gpu')
# 启动浏览器,获取网页源代码
browser = webdriver.Chrome(chrome_options=chrome_options)
url = 'https://mail.163.com/'
browser.get(url)
print('browser text = ',browser.page_source)
browser.quit()
设置浏览器窗口
最大化显示
browser.maximize_window()
最小化显示
browser.minimize_window()
自定义大小
# 宽 500,高 800
browser.set_window_size(500,800)
前进后退
前进
browser.forward()
后退
browser.back()
元素定位
当我们想要操作一个元素时,首先需要找到它,Selenium 提供了多种元素定位方式,我们以 Chrome 浏览器 Headless 方式为例。看下示例:
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
browser = webdriver.Chrome(chrome_options=chrome_options)
url = 'https://xxx.xxx.com/'
browser.get(url)
data = browser.page_source
假设访问地址 https://xxx.xxx.com/,返回 data 为如下内容。
<html>
<body>
<form>
<input id="fid" name="fid" type="text" />
<input id="firstName" name="fname" class="fname" type="text" />
<input id="lastName" name="fname" class="fname" type="text" />
<a href="index.html">indexa>
form>
body>
<html>
1)根据 id 定位
browser.find_element_by_id('fid')
2)根据 name 定位
# 返回第一个元素
browser.find_element_by_name('fname')
# 返回所有元素
browser.find_elements_by_name('fname')
3)根据 class 定位
# 返回第一个元素
browser.find_element_by_class_name('fname')
# 返回所有元素
browser.find_elements_by_class_name('fname')
4)根据标签名定位
# 返回第一个元素
browser.find_element_by_tag_name('input')
# 返回所有元素
browser.find_elements_by_tag_name('input')
5)使用 CSS 定位
# 返回第一个元素
browser.find_element_by_css_selector('.fname')
# 返回所有元素
browser.find_elements_by_css_selector('.fname')
6)使用链接文本定位超链接
# 返回第一个元素
browser.find_element_by_link_text('index')
# 返回所有元素
browser.find_elements_by_link_text('index')
# 返回第一个元素
browser.find_element_by_partial_link_text('index')
# 返回所有元素
browser.find_elements_by_partial_link_text('index')
7)使用 xpath 定位
# 返回第一个元素
browser.find_elements_by_xpath("//input[@id='fid']")
# 返回所有元素
browser.find_elements_by_xpath("//input[@name='fname']")
等待事件
Web 应用大多都使用 AJAX 技术进行加载,浏览器载入一个页面时,页面内的元素可能会在不同的时间载入,这会加大定位元素的困难程度,因为元素不在 DOM 里,会抛出 ElementNotVisibleException 异常,使用 Waits,我们就可以解决这个问题。
Selenium WebDriver 提供了显式和隐式两种 Waits 方式,显式的 Waits 会让 WebDriver 在更深一步的执行前等待一个确定的条件触发,隐式的 Waits 则会让 WebDriver 试图定位元素的时候对 DOM 进行指定次数的轮询。
显示等待
WebDriverWait 配合该类的 until() 和 until_not() 方法,就能够根据判断条件而进行灵活地等待了。它主要流程是:程序每隔 x 秒检查一下,如果条件成立了,则执行下一步操作,否则继续等待,直到超过设置的最长时间,然后抛出 TimeoutException 异常。先看一下方法:
__init__(driver, timeout, poll_frequency=POLL_FREQUENCY, ignored_exceptions=None)
-
driver: 传入 WebDriver 实例;
-
timeout: 超时时间,单位为秒;
-
poll_frequency: 调用 until 或 until_not 中方法的间隔时间,默认是 0.5 秒;
-
ignored_exceptions: 忽略的异常,如果在调用 until 或 until_not 的过程中抛出这个元组中的异常,则不中断代码,继续等待,如果抛出的是这个元组外的异常,则中断代码,抛出异常。默认只有 NoSuchElementException。
until(method, message='')
-
method: 在等待期间,每隔一段时间(init 中的 poll_frequency)调用这个方法,直到返回值不是 False;
-
message: 如果超时,抛出 TimeoutException,将 message 传入异常。
until_not(method, message='')
until 方法是当某条件成立则继续执行,until_not 方法与之相反,它是当某条件不成立则继续执行,参数与 until 方法相同。
以去 163 邮箱为例,看一下示例:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome()
browser.get('https://mail.163.com/')
try:
# 超时时间为 5 秒
data = WebDriverWait(browser,5).until(
EC.presence_of_element_located((By.ID,'lbNormal'))
)
print(data)
finally:
browser.quit()
示例中代码会等待 5 秒,如果 5 秒内找到元素则立即返回,否则会抛出 TimeoutException 异常,WebDriverWait 默认每 0.5 秒调用一下 ExpectedCondition 直到它返回成功为止。
隐式等待
当我们要找一个或者一些不能立即可用的元素的时候,隐式 Waits 会告诉 WebDriver 轮询 DOM 指定的次数,默认设置是 0 次,一旦设定,WebDriver 对象实例的整个生命周期的隐式调用也就设定好了。看一下方法:
implicitly_wait(time_to_wait)
隐式等待是设置了一个最长等待时间 time_to_wait,如果在规定时间内网页加载完成,则执行下一步,否则一直等到时间截止,然后执行下一步。看到了这里,我们会感觉有点像 time.sleep(),它们的区别是:time.sleep() 必须等待指定时间后才能继续执行, time_to_wait 是在指定的时间范围加载完成即执行,time_to_wait 比time.sleep() 更灵活一些。
看下示例:
from selenium import webdriver
browser = webdriver.Chrome()
browser.implicitly_wait(5)
browser.get('https://mail.163.com/')
data = browser.find_element_by_id('lbNormal')
print(data)
browser.quit()
登录邮箱
通过地址 https://email2.163.com/ 登录,
我们发现直接进了邮箱用户名、密码登录页,我们直接输入用户名、密码,点击登录按钮即可。
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://email2.163.com/')
browser.switch_to.frame(browser.find_element_by_xpath('//iframe[starts-with(@id,"x-URS")]'))
browser.implicitly_wait(2)
# 自己的用户名
browser.find_element_by_xpath('//input[@name="email"]').send_keys('xxx')
# 自己的密码
browser.find_element_by_xpath('//input[@name="password"]').send_keys('xxx')
browser.find_element_by_xpath('//*[@id="dologin"]').click()
browser.implicitly_wait(2)
print(browser.page_source)
browser.implicitly_wait(2)
# 关闭
browser.quit()
第二种方式我们使用地址 https://mail.163.com/,先手动打开看一下
从图中我们会发现,登录页面首先展示的是二维码登录方式,因此我们需要先点击上图红框圈住的位置切换到用户名、密码的登录方式
此时,我们先输入用户名、密码,然后点击登录按钮即可。
PyQuery
PyQuery 是仿照 jQuery 实现的,语法与 jQuery 几乎完全相同,如果你熟悉 jQuery,又不想再记一套 BeautifulSoup (Python 爬虫(三):BeautifulSoup 库) 的调用方法,那么 PyQuery 是一个很好的选择。
使用如下终端命令安装pip install pyquery
安装完成后导包from pyquery import PyQuery as pq
传入字符串
from pyquery import PyQuery as pq
html = '''
Hello PyQuery
- l1
- l2
- l3
'''
doc = pq(html)
print(type(doc))
print(doc)
传入文件
from pyquery import PyQuery as pq
doc= pq(filename='p.html')
print(type(doc))
print(doc)
传入 lxml.etree
from pyquery import PyQuery as pq
from lxml import etree
doc = pq(etree.fromstring('Hello PyQuery '))
print(type(doc))
print(doc)
传入 URL
from pyquery import PyQuery as pq
doc = pq('http://www.baidu.com')
print(type(doc))
print(doc)
获取元素
首先,我们使用 PyQuery 的 CSS 选择器获取指定元素。示例如下:
from pyquery import PyQuery as pq
html = '''
Hello PyQuery
- l1
- l2
- l3
'''
doc = pq(html)
# 获取 ul
ul = doc('#container')
# 获取 li
li = doc('ul li')
print(ul)
print(li)
遍历元素
from pyquery import PyQuery as pq
html = '''
Hello PyQuery
- l1
- l2
- l3
'''
doc = pq(html)
# 遍历 li
lis =doc('li').items()
for li in lis:
print(li)
存在多个相同元素时,获取指定元素
from pyquery import PyQuery as pq
html = '''
Hello PyQuery
- l1
- l2
- l3
'''
doc = pq(html)
lis =doc('li').items()
# 获取第二个 li
l2 = list(lis)[1]
print(l2)
获取父、子、兄弟元素
PyQuery 可以通过方法直接获取指定元素的父、子、兄弟元素。示例如下:
from pyquery import PyQuery as pq
html = '''
Hello PyQuery
- l1
- l2
- l3
'''
doc = pq(html)
ul = doc('#container')
l2 = doc('#container .l2')
# 获取 ul 父元素
ul_parent = ul.parent()
# 获取 ul 子元素
ul_child = ul.children()
# 获取第二个 li 兄弟元素
l2_sib = l2.siblings()
print(ul_parent)
print(ul_child)
print(l2_sib)
获取属性、文本信息
from pyquery import PyQuery as pq
html = '''
Hello PyQuery
'''
doc = pq(html)
title =doc('title')
# 获取 name 属性
print(title.attr('name'))
# 获取 title 标签文本信息
print(title.text())
获取 html
from pyquery import PyQuery as pq
html = '''
Hello PyQuery
- l1
- l2
- l3
'''
doc = pq(html)
# 获取 ul 中 html
ul =doc('ul')
print(ul.html())
伪类选择器
伪类可以根据一个元素的特征进行分类,下面通过示例了解下伪类选择器的使用。
from pyquery import PyQuery as pq
html = '''
Hello PyQuery
- l1
- l2
- l3last
'''
doc = pq(html)
# 设置起始位置
lis = doc('li:gt(-1)')
# 获取第一个 li
fli = doc('li:first-child')
# 获取最后一个 li
lli = doc('li:last-child')
# 获取指定 li
l2 = doc('li:nth-child(2)')
# 获取包含 last 的 li
cli = doc('li:contains("last")')
print(lis)
print(fli)
print(lli)
print(l2)
print(cli)
Scrapy
Scrapy 是一个使用 Python 语言开发,为了爬取网站数据,提取结构性数据而编写的应用框架,它用途广泛,比如:数据挖掘、监测和自动化测试。安装使用终端命令 pip install Scrapy 即可。
Scrapy 比较吸引人的地方是:我们可以根据需求对其进行修改,它提供了多种类型的爬虫基类,如:BaseSpider、sitemap 爬虫等,新版本提供了对 web2.0 爬虫的支持。
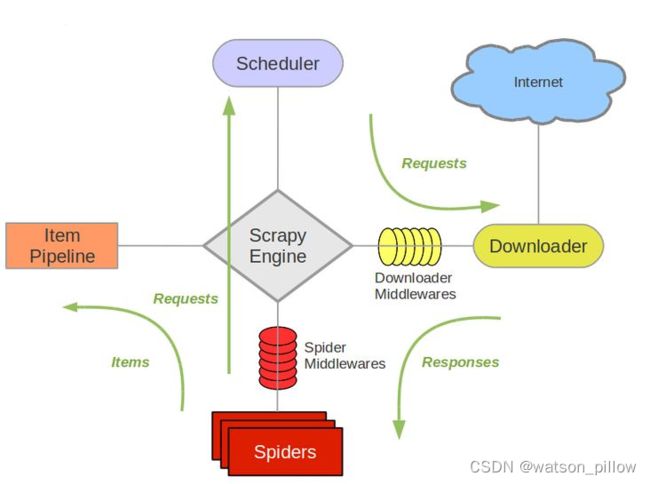
组成
-
Scrapy Engine(引擎):负责 Spider、ItemPipeline、Downloader、Scheduler 中间的通讯,信号、数据传递等。
-
Scheduler(调度器):负责接受引擎发送过来的 Request 请求,并按照一定的方式进行整理排列、入队,当引擎需要时,交还给引擎。
-
Downloader(下载器):负责下载 Scrapy Engine(引擎) 发送的所有 Requests 请求,并将其获取到的 Responses 交还给 Scrapy Engine(引擎),由引擎交给 Spider 来处理。
-
Spider(爬虫):负责处理所有 Responses,从中解析提取数据,获取 Item 字段需要的数据,并将需要跟进的 URL 提交给引擎,再次进入 Scheduler(调度器)。
-
Item Pipeline(管道):负责处理 Spider 中获取到的 Item,并进行后期处理,如:详细解析、过滤、存储等。
-
Downloader Middlewares(下载中间件):一个可以自定义扩展下载功能的组件,如:设置代理、设置请求头等。
-
Spider Middlewares(Spider 中间件):一个可以自定扩展和操作引擎和 Spider 中间通信的功能组件,如:自定义 request 请求、过滤 response 等。
总的来说就是:Spider 和 Item Pipeline 需要我们自己实现,Downloader Middlewares 和 Spider Middlewares 我们可以根据需求自定义。
流程梳理
1)Spider 将需要发送请求的 URL 交给 Scrapy Engine 交给调度器;
2)Scrapy Engine 将请求 URL 转给 Scheduler;
3)Scheduler 对请求进行排序整理等处理后返回给 Scrapy Engine;
4)Scrapy Engine 拿到请求后通过 Middlewares 发送给 Downloader;
5)Downloader 向互联网发送请求,在获取到响应后,又经过 Middlewares 发送给 Scrapy Engine。
6)Scrapy Engine 获取到响应后,返回给 Spider,Spider 处理响应,并从中解析提取数据;
7)Spider 将解析的数据经 Scrapy Engine 交给 Item Pipeline, Item Pipeline 对数据进行后期处理;
8)提取 URL 重新经 Scrapy Engine 交给Scheduler 进行下一个循环,直到无 URL 请求结束。
Scrapy 去重机制
Scrapy 提供了对 request 的去重处理,去重类 RFPDupeFilter 在 dupefilters.py 文件中,路径为:Python安装目录\Lib\site-packages\scrapy ,该类里面有个方法 request_seen 方法,源码如下:
def request_seen(self, request):
# 计算 request 的指纹
fp = self.request_fingerprint(request)
# 判断指纹是否已经存在
if fp in self.fingerprints:
# 存在
return True
# 不存在,加入到指纹集合中
self.fingerprints.add(fp)
if self.file:
self.file.write(fp + os.linesep)
它在 Scheduler 接受请求的时候被调用,进而调用 request_fingerprint 方法(为 request 生成一个指纹),源码如下:
def request_fingerprint(request, include_headers=None):
if include_headers:
include_headers = tuple(to_bytes(h.lower())
for h in sorted(include_headers))
cache = _fingerprint_cache.setdefault(request, {})
if include_headers not in cache:
fp = hashlib.sha1()
fp.update(to_bytes(request.method))
fp.update(to_bytes(canonicalize_url(request.url)))
fp.update(request.body or b'')
if include_headers:
for hdr in include_headers:
if hdr in request.headers:
fp.update(hdr)
for v in request.headers.getlist(hdr):
fp.update(v)
cache[include_headers] = fp.hexdigest()
return cache[include_headers]
在上面代码中我们可以看到
fp = hashlib.sha1()
...
cache[include_headers] = fp.hexdigest()
它为每一个传递过来的 URL 生成一个固定长度的唯一的哈希值。再看一下 init 方法,源码如下:
def __init__(self, path=None, debug=False):
self.file = None
self.fingerprints = set()
self.logdupes = True
self.debug = debug
self.logger = logging.getLogger(__name__)
if path:
self.file = open(os.path.join(path, 'requests.seen'), 'a+')
self.file.seek(0)
self.fingerprints.update(x.rstrip() for x in self.file)
我们可以看到里面有 self.fingerprints = set() 这段代码,就是通过 set 集合的特点(set 不允许有重复值)进行去重。
去重通过dont_filter参数设置,如图所示

dont_filter 为 False 开启去重,为 True 不去重。
快速上手
制作 Scrapy 爬虫需如下四步:
- 创建项目 :创建一个爬虫项目
- 明确目标 :明确你想要抓取的目标(编写 items.py)
- 制作爬虫 :制作爬虫开始爬取网页(编写 xxspider.py)
- 存储内容 :设计管道存储爬取内容(编写pipelines.py)
我们以爬取景区信息为例
创建项目
在我们需要新建项目的目录,使用终端命令scrapy startproject项目名 创建项目,我创建的目录结构如图所示:
spiders 存放爬虫的文件
items.py 定义数据类型
middleware.py 存放中间件
piplines.py 存放数据的有关操作
settings.py 配置文件
scrapy.cfg 总的控制文件
定义 Item
Item 是保存爬取数据的容器,使用的方法和字典差不多。我们计划提取的信息包括:area(区域)、sight(景点)、level(等级)、price(价格),在 items.py 定义信息,源码如下:
import scrapy
class TicketspiderItem(scrapy.Item):
area = scrapy.Field()
sight = scrapy.Field()
level = scrapy.Field()
price = scrapy.Field()
pass
爬虫实现
在 spiders 目录下使用终端命令 scrapy genspider 文件名 要爬取的网址 创建爬虫文件,然后对其修改及编写爬取的具体实现,源码如下:
import scrapy
from ticketSpider.items import TicketspiderItem
class QunarSpider(scrapy.Spider):
name = 'qunar'
allowed_domains = ['piao.qunar.com']
start_urls = ['https://piao.qunar.com/ticket/list.htm?keyword=%E5%8C%97%E4%BA%AC®ion=&from=mpl_search_suggest']
def parse(self, response):
sight_items = response.css('#search-list .sight_item')
for sight_item in sight_items:
item = TicketspiderItem()
item['area'] = sight_item.css('::attr(data-districts)').extract_first()
item['sight'] = sight_item.css('::attr(data-sight-name)').extract_first()
item['level'] = sight_item.css('.level::text').extract_first()
item['price'] = sight_item.css('.sight_item_price em::text').extract_first()
yield item
# 翻页
next_url = response.css('.next::attr(href)').extract_first()
if next_url:
next_url = "https://piao.qunar.com" + next_url
yield scrapy.Request(
next_url,
callback=self.parse
)
简单介绍一下:
- name:爬虫名
- allowed_domains:允许爬取的域名
- atart_urls:爬取网站初始请求的 url(可定义多个)
- parse 方法:解析网页的方法
- response 参数:请求网页后返回的内容
yield
在上面的代码中我们看到有个 yield,简单说一下,yield 是一个关键字,作用和 return 差不多,差别在于 yield 返回的是一个生成器(在 Python 中,一边循环一边计算的机制,称为生成器),它的作用是:有利于减小服务器资源,在列表中所有数据存入内存,而生成器相当于一种方法而不是具体的信息,占用内存小。
爬虫伪装
通常需要对爬虫进行一些伪装,我们也简单处理一下,介绍一个最简单的方法:
使用终端命令 pip install scrapy-fake-useragent 安装
在 settings.py 文件中添加如下代码:
DOWNLOADER_MIDDLEWARES = {
# 关闭默认方法
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
# 开启
'scrapy_fake_useragent.middleware.RandomUserAgentMiddleware': 400,
}
保存数据
我们将数据保存到本地的 csv 文件中,csv 具体操作可以参考:https://docs.python.org/zh-cn/3/library/csv.html,下面看一下具体实现。
首先,在 pipelines.py 中编写实现,源码如下:
import csv
class TicketspiderPipeline(object):
def __init__(self):
self.f = open('ticker.csv', 'w', encoding='utf-8', newline='')
self.fieldnames = ['area', 'sight', 'level', 'price']
self.writer = csv.DictWriter(self.f, fieldnames=self.fieldnames)
self.writer.writeheader()
def process_item(self, item, spider):
self.writer.writerow(item)
return item
def close(self, spider):
self.f.close()
然后,将 settings.py 文件中如下代码:
ITEM_PIPELINES = {
'ticketSpider.pipelines.TicketspiderPipeline': 300,
}
放开即可。
运行
我们在 settings.py 的同级目录下创建运行文件,名字自定义,放入如下代码:
from scrapy.cmdline import execute
execute('scrapy crawl 爬虫名'.split())
这个爬虫名就是我们之前在爬虫文件中的 name 属性值,最后在 Pycharm 运行该文件即可。
参考:
http://www.scrapyd.cn/doc/
https://www.liaoxuefeng.com/wiki/897692888725344/923029685138624
pyspider
pyspider 是一个支持任务监控、项目管理、多种数据库,具有 WebUI 的爬虫框架,它采用 Python 语言编写,分布式架构。详细特性如下:
-
拥有 Web 脚本编辑界面,任务监控器,项目管理器和结构查看器;
-
数据库支持 MySQL、MongoDB、Redis、SQLite、Elasticsearch、PostgreSQL、SQLAlchemy;
-
队列服务支持 RabbitMQ、Beanstalk、Redis、Kombu;
-
支持抓取 JavaScript 的页面;
-
组件可替换,支持单机、分布式部署,支持 Docker 部署;
-
强大的调度控制,支持超时重爬及优先级设置;
-
支持 Python2&3。
pyspider 主要分为 Scheduler(调度器)、 Fetcher(抓取器)、 Processer(处理器)三个部分,整个爬取过程受到 Monitor(监控器)的监控,抓取的结果被 Result Worker(结果处理器)处理。基本流程为:Scheduler 发起任务调度,Fetcher 抓取网页内容,Processer 解析网页内容,再将新生成的 Request 发给 Scheduler 进行调度,将生成的提取结果输出保存。
pyspider vs scrapy
-
pyspider 拥有 WebUI,爬虫的编写、调试可在 WebUI 中进行;Scrapy 采用采用代码、命令行操作,实现可视化需对接 Portia。
-
pyspider 支持使用 PhantomJS 对 JavaScript 渲染页面的采集 ;Scrapy 需对接 Scrapy-Splash 组件。
-
pyspider 内置了 PyQuery(Python 爬虫(五):PyQuery 框架) 作为选择器;Scrapy 对接了 XPath、CSS 选择器、正则匹配。
-
pyspider 扩展性弱;Scrapy 模块之间耦合度低,扩展性强,如:对接 Middleware、 Pipeline 等组件实现更强功能。
总的来说,pyspider 更加便捷,Scrapy 扩展性更强,如果要快速实现爬取优选 pyspider,如果爬取规模较大、反爬机制较强,优选 scrapy。
安装
方式一
pip install pyspider
这种方式比较简单,不过在 Windows 系统上可能会出现错误:Command “python setup.py egg_info” failed with error …,我在自己的 Windows 系统上安装时就遇到了该问题,因此,选择了下面第二种方式进行了安装。
方式二
使用 wheel 方式安装。步骤如下:
pip install wheel安装 wheel;- 打开网址
https://www.lfd.uci.edu/~gohlke/pythonlibs/,使用 Ctrl + F 搜索 pycurl,根据自己安装的 Python 版本,选择合适的版本下载,比如:我用的 Python3.6,就选择带有 cp36 标识的版本。如下图红框所示:
使用 pip 安装下载文件,如:pip install E:\pycurl-7.43.0.3-cp36-cp36m-win_amd64.whl;
最后还是使用pip install pyspider安装
哎,一直失败,决定放弃此章节