七、加载数据集
①准备数据集
还是拿那个糖尿病数据集(diabetes.csv)为例,数据集免费下载,仅供学习使用。
下载完解压,将解压后得到的压缩包放到指定的路径下,我这边放到了我的jupyter里面了

数据集是一个以逗号分割的数据集,有九个特征,八个输入,一个输出
八个维度的输入分别是不同的患者参数,输出表示一年后是否患糖尿病
②加载数据集
若数据集较小,可以直接全部读入内存中进行训练,但是像图片等数据集过于庞大,一次性全部读入内存中显然有点不太现实,就需要使用Dataset和DataLoader
ⅠDataset
from torch.utils.data import Dataset
Dataset是一个抽象类,不可实例化,只能继承,通过构造其内部的方法来使用
常用的有三个:__init__、__getitem__、__len__
第一个方法就是初始化,把数据集都放入到这里面
第二个方法为了对数据进行索引操作,也就是可以通过下标来选择指定数据
第三个方法可以得到数据集的大小
还是拿糖尿病数据集为例
filepath传入数据集所在路径
delimiter=","按逗号将数据集进行划分
np.loadtxt(filepath,delimiter=",",dtype=np.float32)划分完之后,data就变成了一个二维矩阵
举例:
import torch
import numpy as np
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import matplotlib.pylab as plt
data = np.loadtxt('diabetes.csv.gz',delimiter=",",dtype=np.float32)
data
"""
array([[-0.294118 , 0.487437 , 0.180328 , ..., -0.53117 , -0.0333333,
0. ],
[-0.882353 , -0.145729 , 0.0819672, ..., -0.766866 , -0.666667 ,
1. ],
[-0.0588235, 0.839196 , 0.0491803, ..., -0.492741 , -0.633333 ,
0. ],
...,
[-0.411765 , 0.21608 , 0.180328 , ..., -0.857387 , -0.7 ,
1. ],
[-0.882353 , 0.266332 , -0.0163934, ..., -0.768574 , -0.133333 ,
0. ],
[-0.882353 , -0.0653266, 0.147541 , ..., -0.797609 , -0.933333 ,
1. ]], dtype=float32)
"""
data.shape
"""
(759, 9)
"""
data.shape[0]
"""
759
"""
很显然,data变成了N行9列的矩阵,N就是数据的条数,故通过data.shape转换成元组,取第一个即可得到数据集的数量
data中的每个元素又包含x和y,[x1,x2…x8,y]一共9个元素,前八个是x,最后一个是y
torch.from_numpy(data[:,:-1])将数据集data中的[:,:-1]所有行,[0,-1)除了最后一列所有数据取出来,以矩阵的形式返回
torch.from_numpy(data[:,[-1]])数据集data中的所有行,[-1]表示仅最后一列,且以向量形式返回
Dataset示例
class yDataset(Dataset):
def __init__(self,filepath):
data = np.loadtxt(filepath,delimiter=",",dtype=np.float32)
self.len = data.shape[0]
self.x = torch.from_numpy(data[:,:-1])
self.y = torch.from_numpy(data[:,[-1]])
def __getitem__(self,index):
return self.x[index],self.y[index]
def __len__(self):
return self.len
ⅡDataLoader
from torch.utils.data import DataLoader,DataLoader是个可实例化的类,目的是分组,方便加载数据集
epoch:全部样本训练的次数
batch_size:每次训练多少个
iterations:有几个batch
shuffle:是否将数据集打乱顺序
num_works:使用几个进程同步训练
举个例子:1000条数据,每组训练25个,一共有1000/25=40组,训练50次
epoch=50、batch_size=25、iterations=40

train_loader = DataLoader(dataset=dataset,batch_size=32,shuffle=True)
Ⅲ完整代码
class yDataset(Dataset):
def __init__(self,filepath):
data = np.loadtxt(filepath,delimiter=",",dtype=np.float32)
self.len = data.shape[0]
self.x = torch.from_numpy(data[:,:-1])
self.y = torch.from_numpy(data[:,[-1]])
def __getitem__(self,index):
return self.x[index],self.y[index]
def __len__(self):
return self.len
dataset = yDataset('diabetes.csv.gz')
train_loader = DataLoader(dataset=dataset,batch_size=32,shuffle=True)
测试一下Dataset
x,y = dataset[0]
x
"""
tensor([-0.2941, 0.4874, 0.1803, -0.2929, 0.0000, 0.0015, -0.5312, -0.0333])
"""
y
"""
tensor([0.])
"""

测试一下DataLoader
为更好的对比数据,这次重新创建了一个DataLoader,不打乱顺序,且batch_size设置小一点
train_loader_y = DataLoader(dataset=dataset,batch_size=8,shuffle=False)
for data in train_loader_y:
x,y = data
print(x,y)

③模型构建
还是用上次的模型得了,可参考博文:六、多维特征的输入
通过线性层,先将输入数据从8维度降到6维度,再通过一个非线性激活函数sigmoid;
以此类推,6降4;4降2;2降1;最终得到一个1维的结果;
class y_model (torch.nn.Module):
def __init__(self):
super(y_model,self).__init__()
self.linear_1 = torch.nn.Linear(8,6)
self.linear_2 = torch.nn.Linear(6,4)
self.linear_3 = torch.nn.Linear(4,2)
self.linear_4 = torch.nn.Linear(2,1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self,x):
x = self.sigmoid(self.linear_1(x))
x = self.sigmoid(self.linear_2(x))
x = self.sigmoid(self.linear_3(x))
x = self.sigmoid(self.linear_4(x))
return x
ymodel = y_model()
④损失函数和优化器
损失函数选择MSELoss
优化器选择SGD
官网很多,不局限于这两个啊
size_average要不要bais,也就那个b,负责微调的
lossf = torch.nn.MSELoss(size_average=True) #损失函数
optimzer = torch.optim.SGD(ymodel.parameters(),lr=0.001) #优化器
#不同优化器的选择,只需要把SGD改成其他的优化器即可
loss_all = [] #存储损失值,便于绘图
epoch_all = []#存储每次epoch次数,便于绘图
⑤训练
for i data in enumerate(train_loader,0):
从train_loader这个DataLoader中进行枚举,0表示从DataLoader下标为0处开始,train_loader返回两个值,索引和数据,其中数据包括两类,x和y,x八个,y一个
i接收索引、data接收数据
x,y = data,x和y分别接收data中的八个x和一个y
这里对所有的数据样本训练100次,epoch设为100
一共759个数据样本,train_loader中设置batch_size=32,故iterations=759/32=23.71875,23组
23个batch,每个batch包含32个样本,训练100次
for epoch in range(100):
for i,data in enumerate(train_loader,0):
x,y = data
y_hat = ymodel(x)
loss = lossf(y_hat,y)
optimzer.zero_grad()
loss.backward()
optimzer.step()
print(epoch,loss.item())#每一次epoch之后存一下loss就行,不必每个数据都存一下
loss_all.append(loss)
epoch_all.append(epoch)
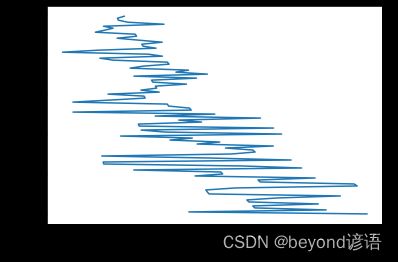
⑥绘图
# 绘图
plt.plot(loss_all,epoch_all)
plt.ylabel('loss Value')
plt.xlabel('Epoch')
plt.show()

效果不太好,但是趋势是对的,损失函数值是下降的
⑦完整代码
import torch
import numpy as np
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import matplotlib.pylab as plt
class yDataset(Dataset):
def __init__(self,filepath):
data = np.loadtxt(filepath,delimiter=",",dtype=np.float32)
self.len = data.shape[0]
self.x = torch.from_numpy(data[:,:-1])
self.y = torch.from_numpy(data[:,[-1]])
def __getitem__(self,index):
return self.x[index],self.y[index]
def __len__(self):
return self.len
dataset = yDataset('diabetes.csv.gz')
train_loader = DataLoader(dataset=dataset,batch_size=32,shuffle=True)
class y_model (torch.nn.Module):
def __init__(self):
super(y_model,self).__init__()
self.linear_1 = torch.nn.Linear(8,6)
self.linear_2 = torch.nn.Linear(6,4)
self.linear_3 = torch.nn.Linear(4,2)
self.linear_4 = torch.nn.Linear(2,1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self,x):
x = self.sigmoid(self.linear_1(x))
x = self.sigmoid(self.linear_2(x))
x = self.sigmoid(self.linear_3(x))
x = self.sigmoid(self.linear_4(x))
return x
ymodel = y_model()
lossf = torch.nn.MSELoss(size_average=True) #损失函数
optimzer = torch.optim.SGD(ymodel.parameters(),lr=0.001) #优化器
#不同优化器的选择,只需要把SGD改成其他的优化器即可
loss_all = [] #存储损失值,便于绘图
epoch_all = []#存储每次epoch次数,便于绘图
for epoch in range(100):
for i,data in enumerate(train_loader,0):
x,y = data
y_hat = ymodel(x)
loss = lossf(y_hat,y)
optimzer.zero_grad()
loss.backward()
optimzer.step()
print(epoch,loss.item())
loss_all.append(loss)
epoch_all.append(epoch)
# 绘图
plt.plot(loss_all,epoch_all)
plt.ylabel('loss Value')
plt.xlabel('Epoch')
plt.show()
⑧测试
这我哪知道如何测试啊,随便从数据集中巴拉一个吧
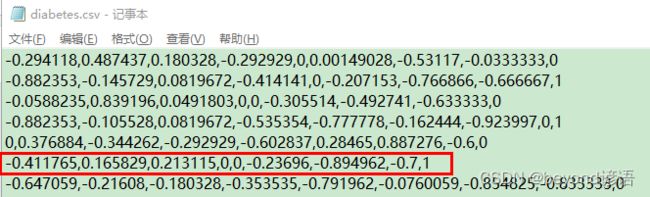
-0.411765,0.165829,0.213115,0,0,-0.23696,-0.894962,-0.7,1
test = torch.Tensor([[-0.411765,0.165829,0.213115,0,0,-0.23696,-0.894962,-0.7]])
print("predect:",ymodel(test).item())
"""
predect: 0.42398056387901306
"""
效果不咋地,预测概率连0.5都没到,还得多训练