Python 实现 JSON 解析器
Json 解析
文章目录
- Json 解析
-
- Json 的组成
-
- 对象结构
- 数组结构
- 词法分析
- 逻辑性解析
-
- 解析对象类型
- 解析数组类型
- 完整代码
- 小结
Json 的组成
JSON结构共有2种
- 对象结构
- 数组结构
一个合法的JSON字符串可以包含这几种元素:
- 特殊符号,如"{" “}“表示一个JSON Object,”[” "]“表示一个JSON Array,”:“用于分隔key-value,”,"用于分隔两个元素
- 字符串,用引号引起来
- 数字,包含0-9,浮点数带有".“,表示符号可带有”+" “-”
- 常量有true, false, null
对象结构
对象结构是使用大括号“{”括起来的,大括号是由0个或多个用英文逗号分隔的“关键字:值”对(key:value)构成。
语法:
{
"健名1": "值1",
"健名2": "值2"
}
说明:
jsonObj指的是json对象。对象结构是以"{“开始,到”}"结束。其中"键值"和"值"之间英文冒号构成对,两个"键名:值"之间用英文逗号分隔。
注意,这里的键名是字符串,但是值可以是数值、字符串、对象、数组或逻辑true和false。
数组结构
JSON数组结构是用中括号"[]“括起来,中括号内部由0个或多个英文逗号”,"分隔的值列表组成。
语法:
[
{"name": "ywh"},
{"age": 18}
]
说明:
数组结构是以"{“开始,到”]“结束,这一点跟JSON对象不同。在JSON数组中,每一对”{}"相当于一个JSON对象,大家看看像不像?而且语法都非常类似。
注意,这里的键名是字符串,但是值可以是数值、字符串、对象、数组或逻辑true和false。
词法分析
词法分析的主要目的是将字符串解析成一小组一小组的合法元素,要将那些是结构所需的符号,数据表达的符号识别出来。比如要将字符串+12.0解析为一个数字12.0等等。
可以分析json的组成发现,特殊的元素都只包含一个字符,常量,数字的表示中间则不会出现空格或其他不相关字符,因此可以轻易地用表达的特征区分,如:
-
数字 可以匹配一段连续的且所有字符都在
0-9或者是("." "+" "-")的范围内。 -
字符串 对于字符串我们则只需要考虑在双引号
"之间的任何字符。特殊的话我们需要考虑到字符串中的特殊的转义字符比如字符\"转义之后的意思其实就是"。 -
常量 对于
(true, false, null)这些常量与字符串的不同之处就是它们不会被"所包裹。所以我们只需要读取结构分隔符(例如:(":", ",", "]","}"))之间的字符串,并在匹配字符后查看是否有对应的常量。 -
空格字符 空格字符一般,让我们的json数据看起来结构更加清晰。但是在解析到相应语言的数据结构的时候则不需要考虑,所以遇到有效字符片段后的空格都跳过。
-
结构标志性字符 一般单独出现,并且位置比较特殊。比如
{作为对象的开始,在对象中:的下一个有效字符片段作为相应value
后面将这些特殊的元素组合称为 合法字符组
所以json解析器要做的就是,如何识别出字符串中一小组一小组的合法元素,同时要根据 结构标志性字符 将得到的合法元素组逻辑拼接起来并检查其中是否有非法格式。
因此编写了下面这个Tokener类:
class Tokener():
"""
## TODO: 字符串中的各种 Token 解析
"""
def __init__(self, json_str):
self.__str = json_str # json 字符串
self.__i = 0 # 当前读到的字符位置
self.__cur_token = None # 当前的字符
def __cur_char(self):
"""
## 读取当前的字符的位置
"""
if self.__i < len(self.__str):
return self.__str[self.__i]
return ''
def __move_i(self, step=1):
"""
## 读取下一个字符
"""
if self.__i < len(self.__str): self.__i += step
def __next_string(self):
"""
## str 字符片段读取
"""
outstr = ''
trans_flag = False
self.__move_i()
while self.__cur_char() != '':
ch = self.__cur_char()
if ch == "\\": trans_flag = True # 处理转义
else:
if not trans_flag:
if ch == '"':
break
else:
trans_flag = False
outstr += ch
self.__move_i()
return outstr
def __next_number(self):
"""
## number 字符片段读取
"""
expr = ''
while self.__cur_char().isdigit() or self.__cur_char() in ('.', '+', '-'):
expr += self.__cur_char()
self.__move_i()
self.__move_i(-1)
if "." in expr: return float(expr)
else: return int(expr)
def __next_const(self):
"""
## bool 字符片段读取
"""
outstr = ''
while self.__cur_char().isalpha() and len(outstr) < 5:
outstr += self.__cur_char()
self.__move_i()
self.__move_i(-1)
if outstr in ("true", "false", "null"):
return {
"true": True,
"false": False,
"null": None,
}[outstr]
raise Exception(f"Invalid symbol {outstr}")
def next(self):
"""
## 解析这段 json 字符串
## TODO: 获得下一个字符片段(合法字符组)
"""
is_white_space = lambda a_char: a_char in ("\x20", "\n", "\r", "\t")
while is_white_space(self.__cur_char()):
self.__move_i()
ch = self.__cur_char()
if ch == '':
cur_token = None
elif ch in ('{', '}', '[', ']', ',', ':'):
# 这些特殊的包裹性、分隔性字符作为单独的token
cur_token = ch
elif ch == '"':
# 以 “ 开头代表是一个字符串
cur_token = self.__next_string()
elif ch.isalpha():
# 直接以字母开头的话检查是不是 bool 类型的
cur_token = self.__next_const()
elif ch.isdigit() or ch in ( '-', '+'):
# 以数字开头或者是+-符号开头
cur_token = self.__next_number()
self.__move_i()
self.__cur_token = cur_token
return cur_token is not None
def cur_token(self):
# 当前的合法元素组
return self.__cur_token
代码注释中的 Token 就可以理解为合法字符组。
调用这个类中的next函数就可以获得下一个合法的字符组。也是将其中的字符串、数字、常量、特殊性分隔符识别出来。
逻辑性解析
首先我们需要去区分两种json类型
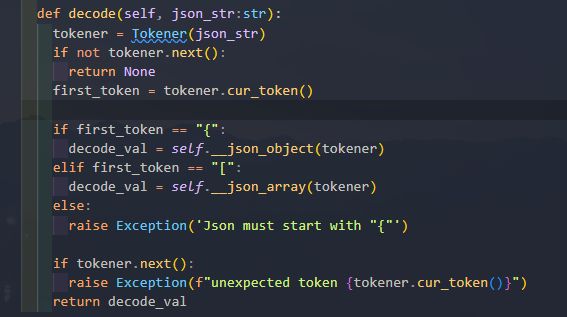
上图做的就是确定,这个json最外层属于哪种json类型的,然后根据两种类型的特征去解析。
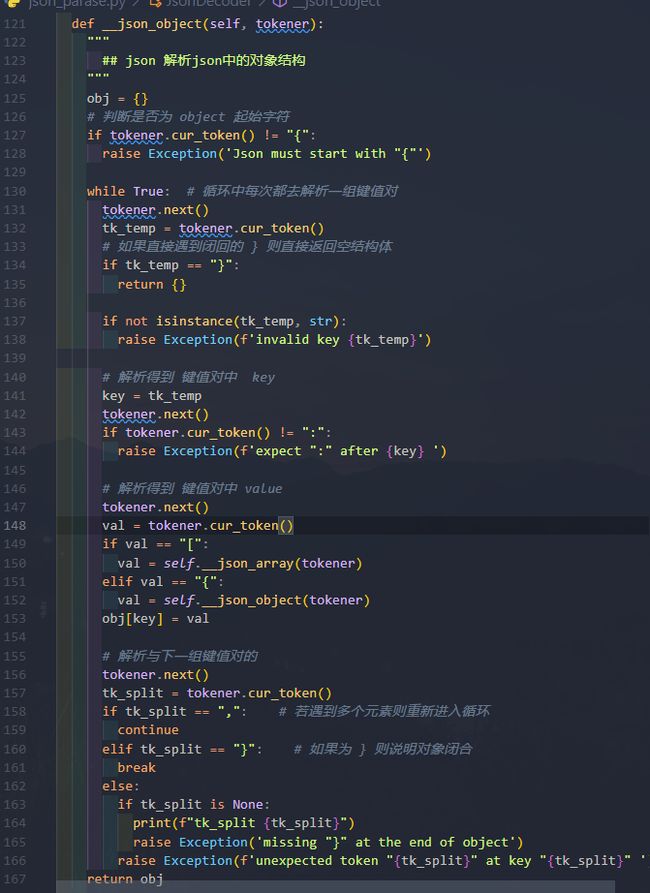
解析对象类型
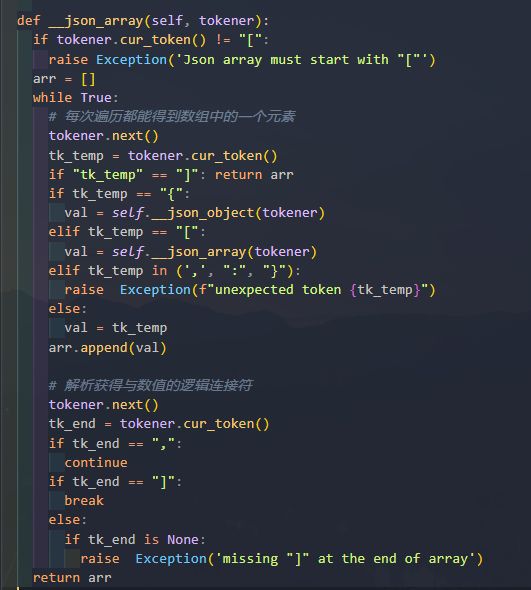
解析数组类型
完整代码
class Tokener():
"""
## TODO: 字符串中的各种 Token 解析
"""
def __init__(self, json_str):
self.__str = json_str # json 字符串
self.__i = 0 # 当前读到的字符位置
self.__cur_token = None # 当前的字符
def __cur_char(self):
"""
## 读取当前的字符的位置
"""
if self.__i < len(self.__str):
return self.__str[self.__i]
return ''
def __move_i(self, step=1):
"""
## 读取下一个字符
"""
if self.__i < len(self.__str): self.__i += step
def __next_string(self):
"""
## str 字符片段读取
"""
outstr = ''
trans_flag = False
self.__move_i()
while self.__cur_char() != '':
ch = self.__cur_char()
if ch == "\\": trans_flag = True # 处理转义
else:
if not trans_flag:
if ch == '"':
break
else:
trans_flag = False
outstr += ch
self.__move_i()
return outstr
def __next_number(self):
"""
## number 字符片段读取
"""
expr = ''
while self.__cur_char().isdigit() or self.__cur_char() in ('.', '+', '-'):
expr += self.__cur_char()
self.__move_i()
self.__move_i(-1)
if "." in expr: return float(expr)
else: return int(expr)
def __next_const(self):
"""
## bool 字符片段读取
"""
outstr = ''
while self.__cur_char().isalpha() and len(outstr) < 5:
outstr += self.__cur_char()
self.__move_i()
self.__move_i(-1)
if outstr in ("true", "false", "null"):
return {
"true": True,
"false": False,
"null": None,
}[outstr]
raise Exception(f"Invalid symbol {outstr}")
def next(self):
"""
## 解析这段 json 字符串
## TODO: 获得下一个字符片段
"""
is_white_space = lambda a_char: a_char in ("\x20", "\n", "\r", "\t")
while is_white_space(self.__cur_char()):
self.__move_i()
ch = self.__cur_char()
if ch == '':
cur_token = None
elif ch in ('{', '}', '[', ']', ',', ':'):
# 这些特殊的包裹性、分隔性字符作为单独的token
cur_token = ch
elif ch == '"':
# 以 “ 开头代表是一个字符串
cur_token = self.__next_string()
elif ch.isalpha():
# 直接以字母开头的话检查是不是 bool 类型的
cur_token = self.__next_const()
elif ch.isdigit() or ch in ( '-', '+'):
# 以数字开头或者是+-符号开头
cur_token = self.__next_number()
self.__move_i()
self.__cur_token = cur_token
return cur_token is not None
def cur_token(self):
return self.__cur_token
class JsonDecoder():
"""
TODO: json 字符串解析
"""
def __init__(self):
pass
def __json_object(self, tokener):
"""
## json 解析json中的对象结构
"""
obj = {}
# 判断是否为 object 起始字符
if tokener.cur_token() != "{":
raise Exception('Json must start with "{"')
while True: # 循环中每次都去解析一组键值对
tokener.next()
tk_temp = tokener.cur_token()
# 如果直接遇到闭回的 } 则直接返回空结构体
if tk_temp == "}":
return {}
if not isinstance(tk_temp, str):
raise Exception(f'invalid key {tk_temp}')
# 解析得到 键值对中 key
key = tk_temp
tokener.next()
if tokener.cur_token() != ":":
raise Exception(f'expect ":" after {key} ')
# 解析得到 键值对中 value
tokener.next()
val = tokener.cur_token()
if val == "[":
val = self.__json_array(tokener)
elif val == "{":
val = self.__json_object(tokener)
obj[key] = val
# 解析与下一组键值对的
tokener.next()
tk_split = tokener.cur_token()
if tk_split == ",": # 若遇到多个元素则重新进入循环
continue
elif tk_split == "}": # 如果为 } 则说明对象闭合
break
else:
if tk_split is None:
print(f"tk_split {tk_split}")
raise Exception('missing "}" at the end of object')
raise Exception(f'unexpected token "{tk_split}" at key "{tk_split}" ')
return obj
def __json_array(self, tokener):
if tokener.cur_token() != "[":
raise Exception('Json array must start with "["')
arr = []
while True:
# 每次遍历都能得到数组中的一个元素
tokener.next()
tk_temp = tokener.cur_token()
if "tk_temp" == "]": return arr
if tk_temp == "{":
val = self.__json_object(tokener)
elif tk_temp == "[":
val = self.__json_array(tokener)
elif tk_temp in (',', ":", "}"):
raise Exception(f"unexpected token {tk_temp}")
else:
val = tk_temp
arr.append(val)
# 解析获得与数值的逻辑连接符
tokener.next()
tk_end = tokener.cur_token()
if tk_end == ",":
continue
if tk_end == "]":
break
else:
if tk_end is None:
raise Exception('missing "]" at the end of array')
return arr
def decode(self, json_str:str):
tokener = Tokener(json_str)
if not tokener.next():
return None
first_token = tokener.cur_token()
if first_token == "{":
decode_val = self.__json_object(tokener)
elif first_token == "[":
decode_val = self.__json_array(tokener)
else:
raise Exception('Json must start with "{"')
if tokener.next():
raise Exception(f"unexpected token {tokener.cur_token()}")
return decode_val
def get_testData():
"""
## 获得测试数据
"""
with open("./data.json", "r", encoding="utf-8") as file:
return file.read()
def test():
data = get_testData()
decoder = JsonDecoder()
print(decoder.decode(data))
if __name__ == '__main__':
test()
小结
总结一下解析中的要点:
-
分析元始格式化数据的格式特点
-
解析字符串中的合法字符组
-
通过逻辑符将解析得到的合法字符组逻辑串联起来