redis的IO及高性能
影响Redis 性能的主要是如下几方面:
Redis内部的阻塞式操作。
CPU调度的开销,以及NUMA架构下不同cpu之间调度访问内存速度差异的一姑娘
Redis内存碎片整理
Redis 缓冲区及IO
best practice,比如一些关键系统属性的配置等。
下面就这些点,整理一些个人的理解和心得。
redis的阻塞操作
redis的交互操作及阻塞点
redis的交互,以及这些交互中潜在的阻塞当前线程的点:
和客户端交互:这部分的内容都是在Redis的主线程中完成的,即我们常说的Redis的单线程。
和客户端的网络IO,包括链接的创建、读/写kv键值对。
对于IO。Redis使用了epoll IO多路复用,所以说网络上的阻塞,不会导致redis的单线程的阻塞。所以这部分不会是导致redis这个单线程阻塞的原因。
对于value为集合类型的读取,redis提供了scan命令,来分批读取数据。不至于一次读取所有数据将主线程给阻塞。
服务端对kv键值对的增删改查操作。redis对外提供的操作kv的服务中,大部分都是O(1)的操作,再加上都是内存操作,所以这些操作会非常快就能完成。但是不是所有的操作都是O(1)的,如果使用不当,大量使用了有些O(n)的操作,就会导致主线程的阻塞
集合类的范围操作(甚至集合全量数据扫描)、聚合操作、以及String类型的范围操作、批量key操作。
删除的影响:大量删除数据后,需要对原本占用内存的释放,这个过程会阻塞当前释放内存的那个线程。比如主动删除一个集合类型、string类型的value使用不当存储了非常多的数据,总之就是大key的删除操作都很危险。
ps:对整个redis实例的内容清除,即flush操作,其实也是操作了大量数据,同理会阻塞主线程
但是删除操作是可以延迟删除的,几乎所有的面向存储组件都会这么做,客户端的删除操作其实只是标记了删除,而没有真正去释放内存。释放内存的操作是异步线程来做的。所以redis其实也不例外。
和磁盘交互:这里的磁盘交互主要就是为了快速恢复内存数据而实现的将数据持久化到磁盘的操作。即AOF和RDB两种方式的磁盘持久化
AOF和RDB磁盘操作,是在子线程中进行的。所以理论上是不会阻塞主线程的。但是如果是redis直接记录AOF日志,且回写磁盘的策略是同步方式,那么AOF的同步刷盘操作会阻塞主线程。
ps:redis的持久化的最大目的是为了快速恢复(当然集群功能也是依赖于这些日志的),不能因为它有持久化功能,一定程度上可以做数据库的持久性,但是不要把它当db来使用。
集群主从节点交互
主从同步是依赖于RDB文件的,从节点需要全量同步主节点数据的时候,就需要主及诶单生成RDB文件、传输给从节点、然后从节点将RDB文件加载到内存、flushDb命令情况当前子节点、使用主节点传过来的RDB文件中的数据。这个过程中
主节点中生成RDB文件和传输RDB文件都是在子线程完成的。所以不会阻塞主进程。
从节点收到RDB文件,flushDb清空数据、以及加载RDB文件中的数据,这个过程是阻塞主进程的。所以如果客户端请求KV读是落到这个从节点上,那么就会阻塞主线程。
集群分片之间的交互
在集群模式中,数据是通过一致性hash将数据分布在不同的分片上的。但是一致性hash的一个问题就是可能导致数据分布不均匀,所以会增加一些虚拟节点来让数据尽量均匀的分布在各个节点上去。所以redis会有一些调度操作,将数据在不同的分片中进行调度。
这个数据调度过程中,其实是会阻塞主线程的。只不过这个调度也是渐进式的,不会突然一大批数量的被调度到不同的节点。所以一个key的数据的调度其实就只是一个key查询和写入的耗时,这个耗时是非常端的,再加上调度算法的加持,不会去调度热key。所以因为这种调度导致主线程阻塞的概率并不大。
但是如果遇到大key数据,那么相对来说因为大key数据的操作耗时可能会阻塞主线程。所以无论如何,在使用redis缓存的时候,就应该去避免大key数据。
综上所述,其实redis的交互操作中,只有对key-value键值对的增删改查、以及副本节点上RDB文件同步是必须在主线中去做的。
对于AOF日志同步落盘、大key的删除(包括flush清空数据)这些都是可以挪到子线程去做的。
Redis 主线程启动后,会使用操作系统提供的 pthread_create() 函数创建 3 个子线程,分别负责
AOF 日志写操作
包括mysql、ES等各种需要写磁盘的存储型组件,几乎都提供了刷盘时机的可选项,一般来说的选项包括:周期刷盘、写到文件系统缓存就返回、必须落盘成功后才返回。
Redis其实也不例外,同样提供了这类选项。只要不配置成同步刷盘,那么刷盘行为就是异步进行的,不会影响主线程。
比如当配置成everySec(每秒周期刷盘),主线程会把 AOF 写日志操作封装成一个任务,也放到任务队列中。后台子线程读取任务后,开始自行写入 AOF 日志
键值对删除
主线程通过一个链表形式的任务队列和子线程进行交互,当收到键值对删除和清空数据库的操作时,主线程会把这个操作封装成一个任务,放入到任务队列中,然后给客户端返回一个完成信息,表明删除已经完成
这种删除,称之为惰性删除,从而避免删除/清空数据对主线程的阻塞。
注意:flushDb、del命令默认都不是异步删除的,都是同步在主线程中的删除。是需要特殊命令来支持这种异步删除的
unlink("key"):异步删除。主线程只是将这个请求放到任务队列中就返回,所以会非常快。然后子线程去执行任务,来删除数据、释放空间。
如果key指定的数据是个大key(比如value是集合类型,且里面存放了比较多的数据),一定不要直接用del,应该用unlink()
flussh("async"):异步情况数据。同样的如果不带async参数,默认是同步的
文件关闭的异步执行
key的过期清除带来的延迟
定期清除
Redis支持在key的维度设置过期时间,当对应的key过期后,就会自动清除这个key对应的数据,并回收内存。
redis删除回收过期key的一个策略就是周期删除,默认周期100ms,即redis会每100ms检查一次key的过期,但并不是全量扫描所有的key,而是采样检查:
采样ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP指定个数的key(默认值为20),然后将采样的这些key中过期的key进行删除。
如果超过25%的key 过期了,则重复删除的过程,直到过期 key 的比例降至 25% 以下
访问时清除(惰性清除)
如果文档某个key的时候,发现key已经过期,一方面返回null、另一方面删除key。这个方式势必会阻塞主线程的(但并不确定redis实现的时候是使用的del方式、还是unlink异步的方式)。
这种惰性删除过期key的方式到时挺常见的,比如jvm进程缓存框架guava cache、Caffine都使用了这种方式。
内存碎片整理带来的延迟
当数据删除后,Redis 释放的内存空间会由内存分配器管理,并不会立即返回给操作系统
redis-cli中有个命令:info memory,可以查看内存的使用情况
used_memory:redis实际占用的内存
used_memory_rss:操作系统分配给redis进程的物理内存
memory_fragmentation_radio=used_memory/used_memory_rss 碎片比
redis4.0以后,提供了自动合并整理内存碎片的机制。这个就跟jvm的标记整理gc算法一样,对于碎片内存的整理,是需要代价的,且会停顿redis主线程。所以在开启redis的自动碎片内存整理的时候,一定要注意,其控制内存整理的一些参数,不能一次整理所有,这样会阻塞主线程。
控制开启碎片内存整理的三个参数:
activedefrag =yes时,表示启动redis的自动碎片内存的整理。
使用config set activedefrag yes来设置这个参数,开启碎片内存整理
active-defrag-ignore-bytes=100mb:表示内存碎片的字节数达到 100MB 时,才开始清理;
active-defrag-threshold-lower=10:表示内存碎片空间占操作系统分配给Redis的总空间比例达到 10% 时,开始清理。
控制内存碎片占用资源的参数,这些参数是为了尽量降低对主线程的影响呢:
active-defrag-cycle-min=25:表示自动清理过程所用 CPU 时间的比例不低于 25%,保证清理能正常开展;
active-defrag-cycle-max=75:表示自动清理过程所用 CPU 时间的比例不高于 75%,一旦超过,就停止清理,从而避免在清理时,大量的内存拷贝阻塞 Redis,导致响应延迟升高。
Redis的IO复用模型
redis使用的epoll IO多路复用
Redis 是单线程,主要是指Redis的网络 IO和键值对读写是由一个线程来完成的,
这也是Redis对外提供键值存储服务的主要流程。但Redis的其他功能,比如持久化、异步删除、集群数据同步等,其实是由额外的线程执行的。IO多路复用参考:C10k与IO多路复用。理解了这个其实就比较好理解redis的单线程是怎么回事了。
redis的单线程处理IO请求,对应到epoll多路复用模型上,如下:
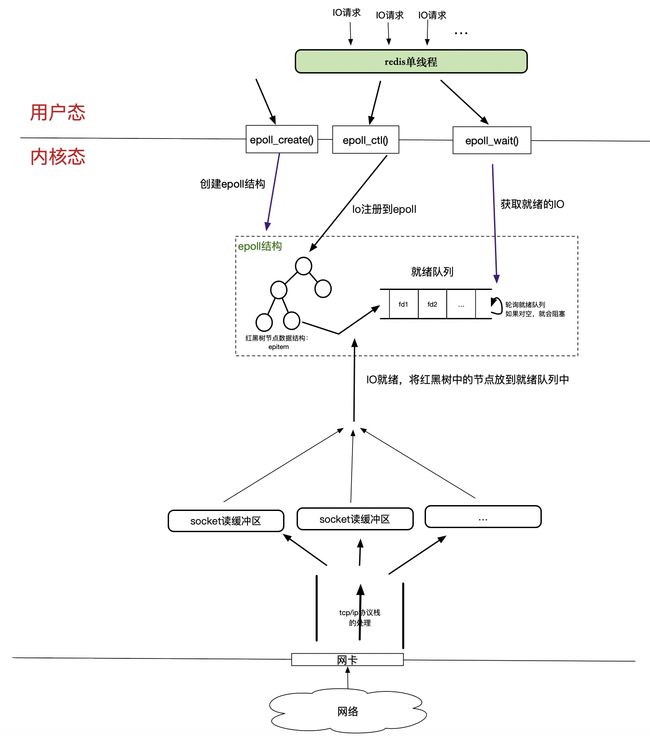
这样其实会发现,redis的单线程,其实可以处理很多io请求,阻塞的io 的fd都在epoll里的红黑树里,而就绪的io都在epoll的就绪队列中,而redis这个单线程其实就只是想epoll注册IO请求的fd(这个是非阻塞的,且红黑树操作是O(logn)的,很快),然后从就绪队列中获取就绪的IO。从整个处理过程看,redis的这个单线程其实几乎全是内存操作,哪怕是IO操作,也几乎不会夯筑阻塞,换句话说,redis的这个单线程是个计算密集型的场景。
这种情况,将redis的这个单线程绑定到一个cpu上,且这个cpu只跑这一个线程,连多核调度的时间都剩了,那几乎就是内存操作有多快,redis的效率就有多高(甚至高于内存的访问效率,因为绑定了CPU后,没有了redis线程在不同cpu上来回调度,高速缓存的利用率按道理也会更高)。
所以说,Redis的使用了epoll模型IO多路复用,是redis的单线程能够支持如此高的qps的最根本原因。
redis的缓冲区
系统中有IO操作的时候,为了缓和IO和内存处理效率的矛盾,已经常用的办法就是使用缓冲区,一方面将IO来不及处理的数据暂时缓冲一下,这样可以让IO全速工作,而又暂时不影响内存操作(比如mysql的change buffer,就是将IO操作延后)。另一方面,就是批量IO,多个数据通过一次IO来处理,而不是n次小的IO(比如mysql的组提交)。
对于redis来说,io场景分为三种:
和客户端的交互的网络IO。这个是最多且用户感知最多的。
集群模式下,主从节点之间,数据同步的网络IO
AOF、RDB持久化的磁盘IO
和客户端交互网络IO的缓冲区
redis缓冲区的工作原理概述
linux环境下,redis客户端和服务端的是通过linux提供的socket接口来实现网络通信的。这里简单介绍小socket的缓冲区,操作系统内核会为每个socket分配一个读缓冲区和写缓冲区,即socket的缓冲区是内核空间中内存区域:
对于接收网络数据,内核是将接收的数据先存放在缓冲区的,应用线程是去缓冲区读取数据。如果应用线程读取数据的时候,缓冲区是空的,那就会阻塞应用线程(当然也有非阻塞的方式)
对于向网络发送数据,应用线程其实也只是将数据放到了socket的写缓冲区,然后内核会去将数据发送到网卡上,说白了我们使用的socket.write()方法并不是真的就将数据发送出去了,只是将数据写入到了写缓冲区,内核决定什么时候将这个数据发送出去。如果应用线程调用socket.wirte()的时候,写缓冲区满了,就会阻塞应用线程(当然也有非阻塞的方式)
socket缓冲区参考:Socket缓冲区。socket缓冲区是操作系统内核控制的,而且每个socket的读/写缓冲区的大小也是由内核选项来控制的。
而这里所说的redis的缓冲区,是redis进程自己在用户空间管理的一块内存,跟socket的缓冲区是完全不同的内存块。
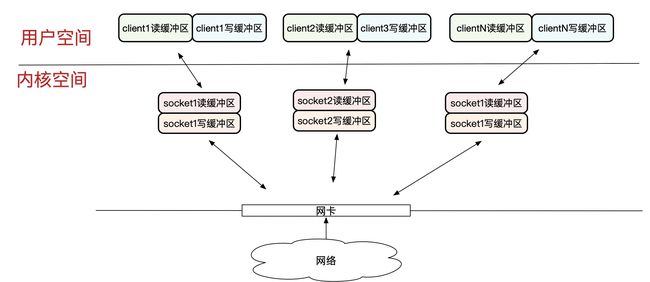
在网络编程中,调用socket.read()/socket.wirte()其实都只是对对应socket缓冲区操作,至于写缓冲区中的内容什么时候写入到网卡发送到网络、什么时候将网络数据填充到socket读缓冲区,其实都是内核控制的。
Redis在用户空间为每一个客户端都分配了一个输入缓冲区和输出缓冲区,
输入缓冲区用于缓冲从socket读缓冲区读取的客户端发送过来的命令
输出缓冲区用于缓冲redis处理后准备反馈给客户但的数据。redis进一步将返回给客户端的数据分成了两类,分开进行缓存
kv的增删改这种操作命令,只需要返回给客户端是否成功少量,且长度基本固定的内容
kv的读取操作、monitor监控类操作,这种需要将kv的内容本身返回给客户端,这种操作返回给客户端的数据内容和长度都是不固定的。
redis为什么要做缓冲区?
对于输出缓冲区:比如客户端提交过来的命令是keys,即获取所有的key。redis收到这个命令后,redis主线程就会去内存中查出所有的key,然后发送给客户端。加入所有key有100M,但是socket的缓冲区只有10M,所以每次调用socket.write()都只能写入10M,要等客户端端成功接收了10M后,才能继续发送下一个10M(tcp是有流控的,如果客户端接收数据慢(半天没有会送ack),那是不会继续往网络里写入数据的)。所以redis主线程就会阻塞住,直到这100M数据都发送完成。
可能有人说,使用费阻塞的socket呀,确实,使用非阻塞的socket,直接socket.write(100M数据),会立即返回,但是操作系统会给你返回本次只是成功写入了10M,那剩下的90M咋办呢?这需要应用层自己去决策的。那要么就是等,将这90M发送完成,那这个过程redis主线程 就只能hang在这里。为了避免这种情况,redis在应用层实现了一个发送缓冲区,来暂存回写给客户端的数据的。
对于输入缓冲区:说实话我没有get到输入缓冲区的必要性。
因为是IO多路复用,所以IO不会堵住redis主线程。所以主线程就干三件事:
从socket缓冲区读取命令
接收到客户端命令的时候,就直接去执行客户端命令操作kv了,
然后操作完其实直接写入到输出缓冲区,主线程的工作就结束了。这整个过程全是内存操作。
从这几步来看redis输入缓冲区的作用。
如果说考虑第一步,如果命令是比较大,socket读缓冲区都放不下,需要多次读取socket缓冲区才能获取到完整的命令。那其实是有必要的,将每次从socket中读取出来的都先放到输入缓冲区,然后就可以去其它事情了,然后等到客户端再发送过来一批,填充满了socket后再去读取。这样redis其实就不用等待客户端将一个命令完整的发送过来后,去执行。省下的其实就是这部分时间。
如果说考虑第二步,如果命令执行耗时比较严重。这个没有用呀。耗时严重,也一定会阻塞主线程,中选成只能将这个耗时的命令执行完了,才能去做其他的事情。所以没啥可缓冲的。
第三部就更没表要了,这已经是写出去的事了。
总结起来就是:
没有缓冲区,虽然使用了IO多路复用,看起来不会被IO阻塞。但实际情况是,虽然确实不会被阻塞。但是IO跟不上的时候,主线程不得不hang住,等待IO完成,否则接受到不完整的信息,也不能进行后续的处理
有了缓冲区后,只要缓冲工区没满,那么redis主线程其实就是真正的一直在做内存操作。所以效率很高。
缓冲区溢出
对于输入缓冲区,redis设置了每个客户端1GB的上限,且不支持配置参数修改。注意是因为;
输入缓冲区是针对每个客户端端的,即每个客户端都会有自己独立的输入缓冲区。这个值其实已经够大了,如果再允许调大,多个客户端链接redis的时候,输入缓冲区都要占用大量内存
如果一个连接的读入缓冲区内存占用都查过1G了,大概率是是出问题了。这个时候缓冲区设置再大,其实也没有用。反而可能因为缓冲区占用太多的内容,导致整个redis实例原地崩溃
输入缓冲区一旦满了,redis就会关闭对应的客户端连接。
常见的输入缓冲区溢出的原因:
写入大key数据,即客户端发送的redis命令里携带了太多数据
慢命令。客户端发送了执行很慢的命令。
对于输入缓冲区,可以用redis的redis-cli中,提供的client list命令来查看客户端连接情况,其中就包含了对连接的客户端输入/输出缓冲区的监控:
有多少个客户端连接到redis上,就有多少条记录:
addr:是连接上来的客户端的ip+port
cmd,连接上来的客户端最近一次执行的命令。如上图,表示连接上来的客户端最新执行的一条命令就是client
qbuf,当前这连接已经使用了多少输入缓冲区,如上例子中,id=13的这个连接已经使用了26 字节大小的输入缓冲区。
qbuf-free,当前连接还可以使用多少输入缓冲区。如上例子中,id=13这个连接还可以使用32742 字节的输入缓冲区。qbuf 和 qbuf-free 的总和就是Redis 服务器端当前为已连接的这个客户端分配的缓冲区总大小。这个例子中总共分配了 26 + 32742 = 32768 字节,也就是 32KB 的缓冲区。
输出缓冲区溢出
对于输出缓冲区,redis提供了参数可以修改器大小,即client-output-buffer-limit。所以如果确定是输出缓冲区太小导致了效率降低,那么可以通过该参数调整。
常见的输出缓冲区溢出原因:
大key的读取。
redis-cli中monitor命令的执行。该命令会持续向客户端输出监控信息
将redis服务端执行的命令的监控信息,持续返回给客户端端,如下:

redis对客户单进行了分类管理,可以分为三类,可以通过client-output-buffer-limit分别为不同的客户端设置输出缓冲区大小。
通过redis-clie这种连接上去的这种常规客户端
client-output-buffer-limit normal 0 0 0
通过消息订阅Redis频道的客户端
client-output-buffer-limit pubsub 0 0 0
主从同步结构中,从节点也是以一个客户端的身份和主节点连的。这种就是从节点客户端。
client-output-buffer-limit replica 0 0 0
设置的三个值依次是:分配的客户端输出缓冲区大小、持续写入的最大内存、持续写入的最大时间。为0代表没有限制。
主从同步,日志复制缓冲去
对于集群模式,从节点需要去不断同步主节点的数据。从节点启动会执行一次全量同步,而正常情况下执行的都是增量同步。主从同步正常情况下不阻塞主线程,不深入。随便百度了一篇,参考下就好:https://blog.csdn.net/weixin_48380416/article/details/124548390
ps:redis的缓冲区的介绍的文章很多。我这里其实主要就是补充了下为什么需要缓冲区,这样其实更容易理解一些。
reactor模式和IO多路复用
为了帮助理解redis的单线程+io多路复用实现高性能,这里贴一个BIO、NIO、AIO、IO多路复用、reactor IO到底是啥东西,啥联系和区别。参考:BIO/NIO/AIO/IO多路复用简介
cpu调度对单线程的影响
cpu架构简介之NUMA架构
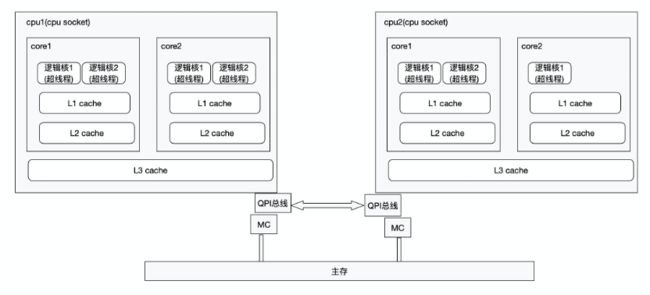
如上就是现在最流程的多cpu结构。简单理解就是一个cpu插槽就是一个cpu socket(注意这里的socket就是本身的含义:插槽的意思,不要和网络通信方式socket混淆)。而现在的cpu基本都是多核了,所谓的cpu核心就是一个cpu上集成了多套计算单元(ALU)、控制单元、存储单元。
而所谓的逻辑核就是,一个物理核中的ALU、控制单元、存储单元不会同时被占用,所以利用超线程技术,在一套ALU、控制单元、存储单元之上模拟出多个cpu核心,这样最大限度的去利用ALU、控制单元、存储单元。
这种多cpu架构中,所有的cpu都可以通过总线访问内存,但是这些内存有点离某个cpu近(近端内存)、有的离某个cpu远(远端内存),访问离自己近的内存就会更快,访问离自己远的内存就相对慢一些,所以对于同一个CPU来说,访问不同的内存块的访问延迟是不一样的。所以在这种架构下,cpu访问近端内存和远端内存延迟不一样,将这种架构成为非统一内存访问架构(Non-UniformMemory Access,NUMA架构)
NUMA架构下cpu编号
在 CPU 的 NUMA 架构下,对 CPU 核的编号规则,并不是先把一个 CPU Socket 中的所有逻辑核编完,再对下一个 CPU Socket 中的逻辑核编码,而是先给每个 CPU Socket 中每个物理核的第一个逻辑核依次编号,再给每个 CPU Socket 中的物理核的第二个逻辑核依次编
2 个 CPU Socket,每个 Socket 上有 6 个物理核,每个物理核又有 2 个逻辑核,总共 24 个逻辑核
lscpu:

NUMA node0的 CPU 核编号是 0 到 5、12 到 17。其中,0 到 5 是 node0 上的 6 个物理核中的第一个逻辑核的编号,12 到 17 是相应物理核中的第二个逻辑核编号。NUMA node1 的 CPU 核编号规则和 node0 一样。
CPU调度对redis的影响
在计算机单cpu单核时代,一个系统中的多个线程是通过时分复用的方式来共享这个cpu的,操作系统将cpu资源按照时间划分成时间片段,然后通过调度程序来让各个线程使用cpu执行指令。这个时代的操作系统的调度程序是让多个线程依次使用同一个cpu。
但是到多多cpu、多物理核、甚至后面的超线程技术虚拟出的逻辑核。这个时候操作系统的调度程序就更复杂了。他的调度就需要确定:使用哪个cpu的哪个物理核的哪个逻辑核来执行线程里的指令。也就是这个时候,才有了真正的并行计算。一个系统中有多少个cpu核心,那就能够真正支持多少个线程同时运行。
对于这种多cpu的架构来说,对于某一个线程,可能上一次操作系统的cpu调度算法将cpu1分配给自己执行指令,但下一次就有可能被调度到cpu2上运行了。
对于redis追求极高性能的场景,这种调度会有几个问题:
对于redis线程来说,如果在cpu1上运行,访问的内存正好是cpu1的近端内存,但是如果调度cpu2上,那么访问redis线程所在的进程内存空间就成了远端内存了。那么cpu2执行redis线程的指令就会比cpu2要慢。
高速缓存的利用率的问题。这种redis线程调度到了不同的cpu上执行,那么三级缓存都是利用不上的,都必须要重新从内存中加载数据和指令。
线程调度本身就是需要占用资源的,比如现场的保存、内核态/用户态的切换等
所以对redis这种纯内存操作,且追求高性能的场景来说,操作系统的cpu调度带来的是负面影响。所以解决这个问题的方式就是:禁用操作系统的调用。
绑定进程到指定cpu核心上
操作系统提供了一条命令,可以将进程绑定在指定编号的几个cpu上,那么这个进程下的所有线程的调度都会在指定cpu核心上进行。
taskset -c cpu编号 进程启动命令。
比如taskset -c 0 ./redis-servie 就是将redis进程绑定到0号cpu上。
但有个问题,redis进程可不止用于响应客户端请求的主线程。还有用于处理RDB、异步删除等的子线程。如果将redis进程绑定一个cpu核心上,那么主线程和子线程就会去竞争这个cpu核心,这种竞争其实也是会影响主线程的。
taskset这个指令是可以将进程绑定在多个cpu核心上的,所以我们可以将redis进程绑定在一个cpu上的多个核心上,这样来减少redis主线程和子线程的竞争。比如:

将redis进程绑定在0和12编号的核心上。这里就需要注意一下NUMA架构下的cpu核心编号规则,注意一定是绑定统一cpu的多个核心上,不要跨cpu。
网络中断线程的cpu调度
redis主线程主要就是用来响应客户端的请求,其实这个过程中,还有重要的一趴很重要的就是网络通信。
redis是通过socket来实现客户端和服务端的网络通信的。linux操作系统,有多少cpu核心就初始化了多少用于处理软中断的内核线程,线程名=ksoftirqd/cpu核心编号。当操作系统收到网络信号的时候,会触发一个硬中断,硬中断只是将网络数据放到内核缓冲区,然后触发一个软中断。然后软中断线程就会去缓冲区读取数据,进行网络的解码,然后通知应用层网络数据ready。
所以为了避免处理网络中断处理的线程和redis主线程调度到不同的cpu上,出现了远近端内存访问差异影响效率。所以可以将中断处理进程和reids进程绑定到相同的cpu上。即用同一个cpu的多个核心来处理redis主线程、子线程、网络中断。
这样相当于给redis专门配备了一个cpu来使用。
绑定线程到cpu上
上卖弄的taskset只能将进程绑定到某个/某几个cpu核心上(可能后面操作系统有支持线程维度的绑定,我不知道罢了)。如上述,这样其实也只是缓解了主线程和其他子线程的竞争,减少因竞争带来的主线程变慢。不能彻底解决。
要彻底解决就是指定线程去绑定。当前没有发现更好的方式,但是操作系统提供了一些方法可以在创建了线程后,就指定该线程绑定的cpu核心,这样这个线程就不会调度到别的线程上执行了。但是这对于redis来说,就需要修改源码了来完成这个事情了。利用操作系统提供的
1 个数据结好三个函数来完成这个事情:
数据结 cpu_set_t :是一个位图,每一位用来表示服务器上的一个 CPU 逻辑核
CPU_ZERO():入参:cpu_set_t位图结构。将cpu_set_t结构中所有位都置0
CPU_SET():入参是:cpu逻辑核编号和 cpu_set_t 。会将指定cpu逻辑编号在对应cpu_set_t中国的位置置1
sched_setaffinity():入参:进程(或者线程)ID号和 cpu_set_t 为参数。这个方法会检查cpu_set_t,找出所有为1的位置,然后将指定的进程(或者线程)绑定到cpu_set_t中为1的对应的cpu逻辑核心上。
ps:Redis 6.0及以后,已经将这个过程封装成能力了,不用修改源码,可以直接通过配置来完成这种指定线程绑定cpu核心。
线程上线文切换的观察
不管是使用taskset、还是该redis源码来绑定进程/线程到指定cpu核心上去运行,其本质都是在减少操作系统调度cpu带来的开销。而操作系统调度一次cpu使用权的切换,都会发生一次上下文的切换,而linux中,会对cpu的上线文切换进行统计。
进程维度的上下文切换的观察
pidstat -w -p 进程号

cswch/s表示的是每秒自愿上下文切换次数。所谓自愿上下文切换是指进程无法获取所需资源,导致的上下文切换。比如说,I/O、内存等系统资源不足时,就会发生自愿上下文切换。
nvcswch/s表示的是每秒非自愿上下文切换次数。非自愿上下文切换是指进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换。比如说,大量进程都在争抢CPU时,就容易发生非自愿上下文切换。
对于redis来说,可以直接观察redis进程的nvcswch/s这个指标,上述的情况,其实都是因为cpu调度产生的上下文切换。
所以如果说redis所在服务器nvcswch/s比较高了,其实我们就可以考虑使用上述的绑定cpu的方式来进一步提高性能
操作系统维度的上下文切换次数的观察
vmstat

system栏的cs就是上线文切换的次数
单线程的保证不加锁的单一操作是原子的
redis的key-value的操作是单线程执行的,所以一个命令的执行是不存在并发问题的。那其实单线程本身就绝对了任何一个单个客户端命令的执行是原子的。
但是如果想要原子的执行多个命令呢?
首先看下在客户端命令中,有个multi、exec成对的命令。redis会将当前客户端multi后的命令进行暂存在一个队列中,当执行exec的时候,然后再去执行队列中的命令。
表面上看,因为redis是单线程执行的,那么是不是这个单线程要执行完缓存的所有命令,才会执行其他的命令呢?
首先,这里虽然redis的介绍中,包括官方提供的客户端,比如Jedis,都管这叫Transaction,但其实multi、exec根本不支持任何事务能力,ACID一个都不满足,只是蹭ip的,它就是个批量提交命令的操作:redis会客户端multi之后的命令都给放到缓存队列中、当执行exec的时候逐个从队列中获取命令,并执行。
如果在提交命令过程中出错,即redis在将命令放到队列过程中出错,那队列里的所有命令就失效了,相当于执行了discard。比如发送的命令本身有错误,比如命令不存在、格式不对等
如果客户端提交了exec命令,redis在执行某个命令出错,那就会跳过。更不会回滚之前已经执行的命令
redis也不是一次性执行完队列里所有命令,redis主线程才接收其他命令的。所以也具备单线程带来的原子性。
和事务行管的命令其实是4个:multi、exec、discard,这三个好理解,还有一个watch。watch的作用就是让redis监控在multi之后到exec之前指定key的变化,如果指定key的数据有变化,则就放弃批量提交的这些指令。
那如果真的要原子的执行多个命令该咋办呢?答案就是lua脚本。因为redis是单线程去执行完lua脚本后才会去干其他事情的。eval()命令就是用来执行一个lua脚本的。
在利用redis实现分布式锁、集群限流的时候,都会用到原子性的,其实lua脚本就必不可少了。
jedis执行multi示例
private void transactionTest() {
//表示一系列原子性操作的开始。收到这个命令后,Redis 就知道,接下来再收到的命令需要放到一个内部队列中,后续一起执行。
// 即接下来发送的命令,redis服务端收到过后不是立即执行,而是放到一个队列里,然后等待exec()命令,收到exec()命令后,取出队列中所有命令进行执行
Transaction transaction = jedis.multi();
// multi之后的命令,就不是直接执行了,而是批量提交给redis服务端,服务端先缓存这些命令。然后收到exec命令的时候再从缓存中获取命令执行。
// multi之后提交命令不能用jedis的接口,而是要用transaction下的接口了,否则会报错。
// redis服务端在执行缓存在队列里的命令,遇到出错的时候,是跳过该出错的命令,没有回滚能力。所以multi、exec不具备原子性
// 其内部执行的是redis的exec()命令。
// 表示一系列原子性操作的结束。一旦 Redis 收到了这个命令,就表示命令批量提交结束
// 此时,Redis 开始执行刚才放到内部队列中的所有命令操作。
transaction.exec();
}ps:其实在分布式框架(nosql)大发展时期,很多分布式框架其实在各自领域都取了很多的应用,比如redis在分布式缓存领域、kafka在分布式mq领域等等。而且曾经一度有人喊出了口号,nosql要干掉sql。但实际上,sql数据库的独门必杀技ACID事务,没有一个nosql是真的支持的,但是很好玩的是,几乎所有的nosql,都在介绍的时候宣城自己支持事务的,但实际上都只是实现了个批量操作而已。
比如redis的multi/exec也说自己是事务、kafka也有个事务消息。redis的事务是完全单纯的批量提交命令、kafka的事务消息至少背后的幂等机制还能保证producer批量发布的消息的原子性(参考kafka简介之事务消息
实际应用中,在线交易业务占了很大部分,又非常依赖ACID事务特性,所以nosql是干不掉sql的。十几年过去了,nosql依然还只在是作为sql的补充来使用的,只是说单体数据库确实越来越难以支撑现在体量越来越大的业务场景了。所以当前最火的是newsql(又是google掀起的浪潮呀,很多走分布式的路线的newsql几乎都参考了google的spanner)
ps:newsql发展的两条路;
在基于proxy代理的分库分表中间件上叠加分布式能力,特点就是底层的存储是单体sql数据库
直接走分布式路线,即提供acid事务能力的分布式数据库。特点就是底层存储也是新开发的。
redis高性能总结
数据结构上
采用hashf表来构建key-value索引,本身就是一个O(1)的操作,效率非常高。
hash冲突、rehash采用了渐进式copy处理,不会出现rehash的时候性能抖动过于明显
value虽然支持的类型很多,但是其底层实现都是高效的数据结构,比如hash表、跳跃表、压缩表等,这些都是针对redis的内存操作进行了一些优化的,比如使用压缩表而不是数组。但是也不得不注意,并不是所有的操作都是那么高效的,这个在生产中是需要去避免的
value的类型是列表的时候,因为底层采用了压缩表,那么在头尾的操作都是O(1)的,但是要避免非头尾处的扫描类曹锁,比如范围操作等,这些操作都是O(n)的
IO复用模型
高效的epoll多路复用,使得一个线程可以同时处理n路IO,而不用以为IO操作的阻塞导致线程的阻塞。这其实是redis单线程能够行的通的一个大前提。
缓冲区的使用
IO多路复用技术的使用,使得redis主线程不会被IO阻塞,但是并不表示就能保证redis不用等io完成,所以仅仅是IO多路复用,还不能保证redis主线程不会被IO所累。缓冲区的使用,真正保证了redis主线程的操作全是内存操作了。效率就非常快了。
单线程
特别是value是集合类型的时候,其实是比较容易出现多个线程去操作同一个key对应的集合中不同元素的,那这个时候就必须要做线程同步,那么就势必会有线程同步的开销:线程调度和切换的开销。但是redis的数据都是在内存里,这些操作其实都是内存操作,操作本身就是比较快,极端点说就是线程同步的开销甚至无限逼近操作本身的开销,甚至超过操作本身的开销,那其实就是得不偿失的。所以采用单线程来处理,可以直接将这个单线程绑定在指定cpu上,那么这个cpu就专心的干一件事情,不会有线程调度、线程切换的开销。反而更省了。
使用best practice:
对于扫描类操作,不要直接全部读取,大量的数据操作会阻塞主线程。redis提供了scan命令来分批获取,这样减少对主线程的阻塞。
对于大key的删除,不要使用del()、rem()等这种命令,而是使用unlink()异步删除命令。
对于flush()请款数据的命令,需要带上async参数。
如果需要aof落盘,注意刷盘时机。尽量避免同步刷盘。因为同步刷盘会阻塞主线程,可能会导致其他kv操作服务就不可用了。
对于使用RDB主从全量同步数据,RDB文件不宜过大。而且在RDB同步期间,最好能够关闭副本上的读取流量,否则RDB文件加载阻塞主线程后,会导致打到副本节点上读取的阻塞,造成业务耗时较大抖动。
key的过期机制,清理过期key对应的数据带来的影响
内存碎片整理带来的影响
严禁使用大key。
ps:当我们在谈性能的时候,我们到底在谈什么?思路和方向是啥?,简单概括总结:

其实我们常见的那些组件的优化方式,其实高性能的手段在都在这张图里了,包括redis。
处理性能问题,个人认为最终要的是找到性能瓶颈到底在哪里,然后针对性的去处理。举个栗子:Disruptor是个高性能内存队列,感觉很牛逼的样子,所以我们照猫画虎,我系统里有性能不好,上来就去搞伪共享,感觉任何场景都会有伪共享问题,殊不知盲目的去填充避免共享,搞不好会带来负面效果的。高速缓存是用来平衡cpu和内存的速度差异,是提搞效率的。只是在某些特定场景下肯呢个出现伪共享,发挥不出来高速缓存的作用,所以才需要去解决。大胆乱说一下:巨大部分互联网场景,更多的是IO密集型,性能瓶颈一定不在伪共享上。