BIO/NIO/AIO/IO多路复用简介
bio、nio、aio、io多路复用、reactor模式io,在将IO的时候,是不是都遇到过这些概念,也有种傻傻分不清?甚至别人在大谈特谈的时候,一会nio,一会io多路复用,一会又搞到reactor模式上去了?这些概念到底是什么?什么关系?这些都是我曾经的疑问。
这里说明一下这些概念,帮助理解redis的单线程+io多路复用实现高性能,因为很多其他这种需要IO的也使用了多路复用,但并不是单线程,比如netty,也实现了高性能的io,啥区别呢?
下面就结合掌握的只是和理解,来尝试理清楚这些概念。有不准确的地方,不吝赐教。
bio vs nio
- bio:阻塞式IO。也就是说io没有就绪的时候,操作IO当前线程会被阻塞。
什么叫IO就绪了?从编程的角度看,其实就是对应的缓冲区有没有数据/有没有满。对于读,缓冲区是空的,就是没有就绪;对于写,缓冲区满了,就是没有就绪。所以其实当前线程都是被缓冲区阻塞的,只是这个缓冲区是内核管理的一块内存、阻塞当前线程也是操作系统内核里完成的(和用户使用操作的系统调用阻塞当前你线程的区别就在于:是否需要用户态和内核态的切换)。比如:
-
- socket.accept() 这个其实就是去读的操作系统实现tcp的时候,会有一个完全连接队列。即三次握手创建的链接fd都会放到这个队列里,socket.accept()其实就是去读这个队列,队列为空就被阻塞了。
- socket.read()/socket.write(),参考上面说的socket缓冲区
- 通过文件系统的磁盘IO,道理一样
- 当然也有不通过文件系统,直接使用磁盘IO接口,自己管理磁盘的。对于IO来说,道理是一样的。
- nio:非阻塞式的IO。说清楚了阻塞式的IO,那非阻塞式的IO就很简单了。当前线程去读写对应缓冲区的时候,缓冲空的/满了,不会阻塞当前线程,而是直接返回,并通过返回值告诉当前线程发生了什么
- 如果是读,则通过返回0,告诉当前线程缓冲区是空的;返回eof,告诉当前你线程,已经没数据可读了,等等。
- 如果是写:返回的是本次成功写入到缓冲区了多少字节,那就有可能是将当前线程本次请求的所有内存写入到了缓冲区、可能是写入了一部分、可能是一个字节都没有写入。对于阻塞式IO,那么只有当本次请求数据都写入缓冲区了,才会返回、或者最超时那就报错返回。
所以,对于nio,最大的区别就是:IO不ready,不阻塞当前线程而已。相比于阻塞式的IO,使用nio,程序员有更大的自由,可以来决定IO不ready时,当前线程该怎么办:
-
- 直接调用操作系统的系统调用,把当前线程给阻塞住。这其实就是阻塞式IO,只是阻塞在用户空间实现了。用户还要自己去处理唤醒之类的事情。
- 不断轮询重试。比如如果socket.read(),返回0,说明没有数据。那就不断的调用socket.read(),去探测是不是有数据ready了;写入也是一样的,如果socket缓冲区满了,那就不断的去调用socket.write(),将没有写入完的字节不断轮询写入。ps:这其实就是IO多路复用的基本原理了
- 将待io处理的数据,先放到内存中(即缓冲区),然后换个时间,再来去重试,这样重试成功的概率就会更大,而且不用怼这一个IO请求的数据狂重试。ps:其实这就是缓冲区的基本原理了。
总结一下:
- bio:就是io操作没有完成,那当前线程就会被内核阻塞,整个IO操作内核来完成。只有当IO完成了,内核会唤醒当前线程。所以当前线程在IO过程中,一直是挂起的,不能做任何事情。
- 好处:使用io很简单,io的处理过程都交给了内核。用户完全不用care
- 坏处:io过程当前线程被阻塞,io过程中当前线程除了挂起等待,啥也不能干。
- nio:io操作内核尽力去做,做不完我也不阻塞当前线程。通过返回值我告诉你我做了多少。没有做完的,就需要用户自己去来决策该怎么处理了。
- 好处:不阻塞当前线程。那用户(程序员)就有更大的灵活性了。自己来决策对于没有执行完的IO该怎么处理。这也是各种IO优化,满足c10k,c100k等等的前提,因为有了更大的灵活性了,那就有八仙过海各显神通的机会了。
- 坏处:相比于bio,使用起来要复杂的多。io过程不再是内核的一个黑盒了,用户需要了解io过程,并处理。这就要复杂的多了。
nio vs aio
aio:就是所谓的异步io。这其实就是基于事件来实现的io。用户提交io操作(发布一个事件)、然后注册一个监听器,然后内核来完成整个io过程,当io完成后,通过注册的监听器,主动去通知用户,并且将io结果通过回调就直接给到用户线程了,都不需要用户线程再来获取。
这个其实就非常棒了,既不会阻塞提交io请求的当前线程,也不需要用户关心io过程,io过程还是被内核全程cover,对用户又是个黑盒了。
总结:aio和nio
- 这两种io方式,在发起io请求的时候,都不会阻塞当前线程。
- nio:是尽力去做,做不完拉到,通过返回值告诉用户就好。用户来决策该怎么做。所以说使用nio其实就会有轮询,不断去尝试。
- aio:io的过程被内核cover了。不需要用户轮询:事都交给我,我搞完了我来通知你。这是一个典型的事件驱动来实现的。
从这个角度看,aio很明显各个高级,不管是使用还是性能都明显好于nio,为啥aio使用的人少呢?其本质原因就是很长一段时间linux内核不支持AIO,后面提供了AIO能力,又不太稳定。而nio非常成熟了,基于nio的各种复用技术也很成熟了,哪怕是现在linux具备了AIO的能力,基于NIO实现的多路复用技术,已经能满足c1000k的诉求了,而且netty框架基于nio的多路复用,性能很客观,将那些复杂的东西都已经封装处理了。使用的时候直接使用netty,而不是直接使用nio,使用起来也没那么困难。没有动力去当小白鼠使用AIO了而已。
nio vs io多路复用
我们说nio本身,对于操作系统内核来说,其实是比较小的改动,但是怎么通过nio来提高系统的io吞吐量才是最关键的。
一个朴素、简单、且有效的想法就是:轮询。
- 可以是发起io请求的那个线程,发起io请求后,定时/不定时的去调用io读写:当读到eof、或者写完自己需要写入的数据为止。
- 专门搞一个线程来处理io。在用户层搞一个io统一处理的结构,需要发起io请求的时候都是将io请求提交给这个结构,然后注册一个io完成的回调钩子。然后站门搞一个线程来轮询:只要io完成了,就回调。ps:其实这个方式对于发起IO请求的线程来说,就是AIO。只是说背后的实现是在用户层,本质上是nio,通过轮询来完成,不能算是真正的aio。
上面不管是哪种方式,其本质上都是用户空间,通过系统调用来轮询。这个轮询代价其实是比较大的,会涉及到cpu在用户态、内核态的来回切换,以及出入参在用户空间和内核空间的来回copy、因为io是否就绪用户态是感知不到的,所以不得不全量的fd轮询。所以轮询小效率并不搞。
这个时候,官方出手了:既然这个这么通用,我来提供一个轮询版的io多路复用器。这就是大名鼎鼎的select io多路复用。
只不过select的实现比较简单,性能不高。它虽然是操作系统的一部分,但是是在用户空间实现的。所以仅仅个大家提供了一个统一的拿来即用东西而已。用户自己实现这种多路复用有的问题他都有。比如:用户和内核态的频繁切换、数据在用户空间和内核空间频繁的来回copy、大量无效轮询等,所以最终的效果就是,比起bio,系统的io吞吐量是提升了。不过io复用的性能并不高。以及select用的数据结构是数组来保存注册过来的fd,所以io多路复用,能够同时处理的io数量就是有限的。
所以搞了一个小优化,那就是poll,做了一些优化,但本质上没有太大的改变。
这个时候内核出手了,linux提供了epoll这个IO多路复用器,这个和select/poll有个本质的改变,这个是在内核中实现的。彻底避免了轮询的时候频繁的用户态/内核态的频繁切换、用户空间/内核空间数据来回copy。因为内核是可以直接去操作io设备的,所以内核是可以通过io中断来感知到io状态的,所以避免了大量的无用轮询。
除此之外,epoll保存注册过来的fd,采用了更高效的红黑树结构,对注册fd的操作效率也提高了。
io多路复用参考:c10k问题与io多路复用
其实会发现,epoll这个结构里面,其实已经有事件驱动的方式在了,只是是这个事件驱动只是在内核中,内核不会真的去无脑的轮询注册过来的fd,看看有没有就绪了,当io就绪了,内核是可以直接通过中断感知到的,所以当fd就绪了(这个其实我有点不太确定,到底是不是内核线程来轮询的,还是通过中断来感知到的,有yy的成分在),内核就会将这个fd从红黑树中摘下来,放到一个就绪队列中。
然后坐等用户线程来查询就绪队列,只要用户主动来查询,内核才会返回就绪的fd,不会去轮询全量注册的fd,所以基本上是没有无效的轮询的(所谓的无效轮询,就是io本身还没有ready,但是用户线程又不知道,所以只能去轮询看一下,得到的结果自然也是未就绪)。
用户空间查询就绪队列的方式就是epoll_wait(),因为就绪队列可能是空的,所以epoll_wait()默认是阻塞的,即当就绪队列为空,会阻塞调用epoll_wait()方法的。
ps:所以epoll到底是阻塞io、还是bio呢? 个人认为,虽然epoll_wait()默认是阻塞的,但是是因为epoll的就绪队列阻塞的,不是io操作本身。而且如上述,我不是特别确定epoll底层有没有内核线程去轮询红黑树上的fd,还是像我yy的那样,完全没有轮询了。所以我们还是认为epoll是基于nio实现的一个多路复用
epoll的原理图:
reactor模式的io
我第一次接触到这个,其实就是netty的io模型上。虽然底层也是使用了io多路复用技术,netty在实现自己的IO操作的时候,又实现了实现了一个reactor模式的IO操作方式。
这里我们不将什么是reactor,有哪些reactor的模式,以及netty的reactor模式又是怎么样的,这个网上的资料到处都是。而且大部分的资料都是将reactor和io多路复用混为一谈,让人有些摸不着头脑(我也是其中一个)。
所以这里我们重点说下reactor模式、io多路复用到底什么关系?什么区别。
先给结论:io多路复用技术和reactor模式没有任何关系。
抛开reactor模式本身不谈,在io这一块,使用reactor模式,其本质就是线程池线程隔离:让一些线程只是做指定的事情,所以我认为其本质就是线程池隔离,跟任何一个其他需要线程池隔离的地方没有本质区别。
reactor模式io的实现,可以是基于BIO、NIO、或者io多路复用技术。所以我说reactor和io多路复用技术没有任何关系。
直接用bio/nio实现的reactor io示例:
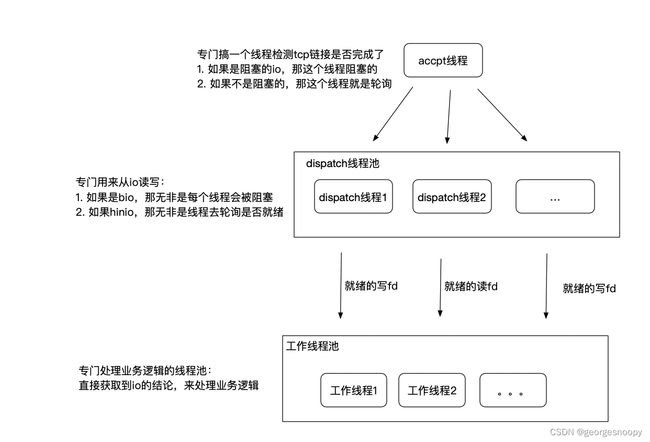
换成基于io多路复用器实现的reactor io:
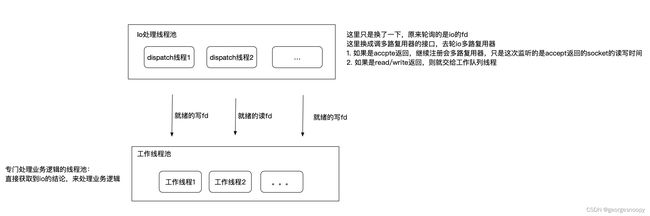 我这里画的比较简单一点罢了,只是其他地方的介绍,根据非工作线程池分了几个线程池、是单线程还是多线程去检测io状态, 然后搞了n多中reactor罢了。
我这里画的比较简单一点罢了,只是其他地方的介绍,根据非工作线程池分了几个线程池、是单线程还是多线程去检测io状态, 然后搞了n多中reactor罢了。
所以到这里,就把reactor io和IO多路复用说清楚了。
那么我们回过头来看,在epoll 高效的多路复用技术下,还要有reactor么。这里最典型的就是两个都是业界用的极其广泛的组件,且都是在各自的领域以性能著称的组件:redis和reactor,他们底层都使用了epoll io多路复用。但是redis是单线程的,而netty是使用了线程池的。
redis的点在于:redis的主线程都是内存操作,会非常快。所以多线程的cpu切换带来的开销、加上多线程的话就会有多线程同步问题,而线程同步又是开销。
ps:那其实需要线程同步的只是key-value的处理,可以是io处理的线程和key-value处理的线程分开,只不过key-value的处理是单线程的,如上图,工作线程池是个单线程而已。不久解决了么?
这个其实我也想的不是很明白了,可能是因为redis觉得在io多路复用+缓冲区的加持下,redis的操作都是内存操作了。那么对于计算密集型场景来说,线程始终独占一个cpu,其实效率是最高的。
那么问题又来了:可以将用于key-value处理的线程绑定在cpu的一个核心上、io处理的线程绑定在相同cpu的另一个核心上,那理论上是不是更快呢?
这个我就只能猜测了,redis的单线程模型已经足够快了,哪怕是再这么实现,有所提高也有限了,反而还带来了复杂性,没有必要了。
而对于netty,他是一个IO框架,后面的业务到底会怎么处理,其实netty已经控制不了,而且大概率不是redis key-value处理那么高效的。所以netty的高效重在io部分,线程切换带来的开销已经不是卡点了。所以这个时候采用多线程来处理也是合理的。
所以,还是回到性能这个话题,抛开场景单聊性能是没有意义的,而且性能优化那一定是要找到影响性能的点在哪儿,对症下药,否则意义不大的。比如reids和netty这里的处理,如果我们只是简单的去看,实际上是有些矛盾的,但是各自确实也都是用看似矛盾的两个方式实现了各自场景的搞性能。