数据模型 数据应用
用户评价模型:如何建立用户评价模型,量化用户体验 | 人人都是产品经理
关联推荐模型:https://zhuanlan.zhihu.com/p/84954294 https://zhuanlan.zhihu.com/p/84954294
https://zhuanlan.zhihu.com/p/84954294
RFM分析模型如何通俗易懂的理解和应用RFM分析方法(模型)? - 知乎https://www.zhihu.com/question/49439948
https://posts.careerengine.us/p/5d8c4ce08ccaab7136879a34https://posts.careerengine.us/p/5d8c4ce08ccaab7136879a34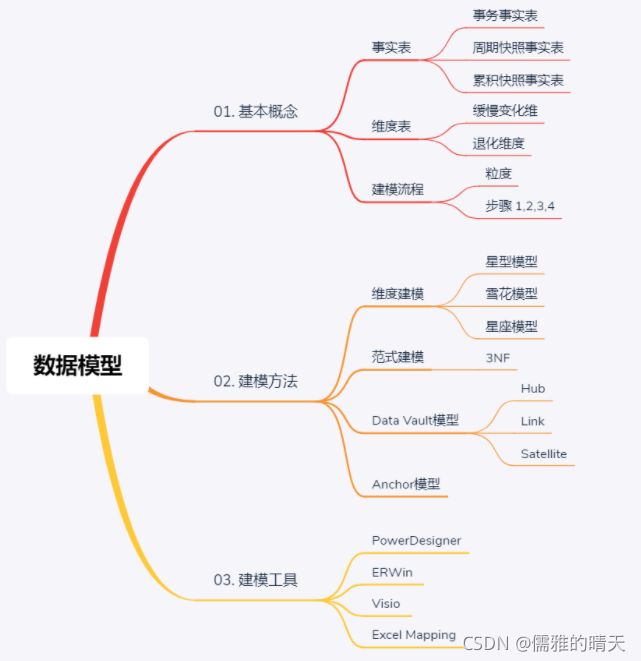
model对于数仓是最核心的东西,数据模型是数据组织和存储方法,模型的好坏,决定了数仓能支撑企业业务多久。
维度建模以分析决策的需求出发构建模型,构建的数据模型为分析需求服务,因此它重点解决用户如何更快速完成分析需求,同时还有较好的大规模复杂查询的响应性能。
它是面向分析的,为了提高查询性能可以增加数据冗余,反规范化的设计技术。
粒度: 用于确定某一事实表中的行表示什么,是业务最小活动单元或不同维度组合,即业务细节程度。
维度建模步骤:选择业务过程->声明粒度->确定维度->确定事实。旨在重点解决数据粒度、维度设计和事实表设计问题。

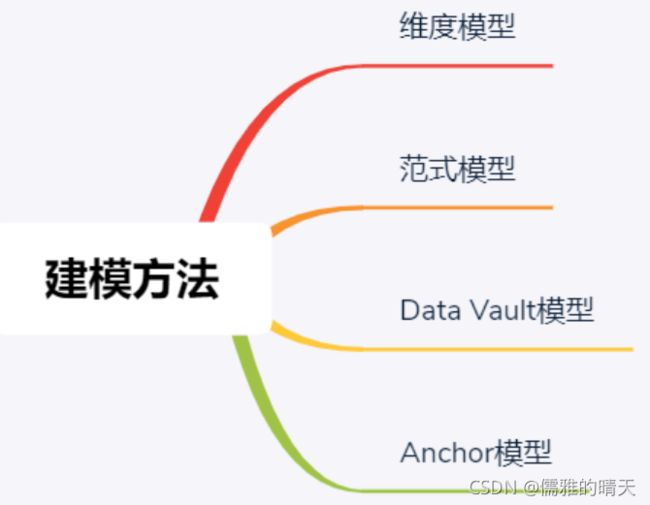
数据仓库建模方法论可分为:维度建模、范式建模、Data Vault模型、Anchor模型。
1. 维度模型
按数据组织类型划分可分为星型模型、雪花模型、星座模型。
星型模型 主要是维表和事实表,以事实表为中心,所有维度直接关联在事实表上,呈星型分布。
雪花模型 在星型模型的基础上,维度表上又关联了其他维度表。这种模型维护成本高,性能方面也较差,所以一般不建议使用。尤其是基于hadoop体系构建数仓,减少join就是减少shuffle,性能差距会很大。
星座模型 是对星型模型的扩展延伸,多张事实表共享维度表。数仓模型建设后期,大部分维度建模都是星座模型。
2. 范式模型
即 实体关系(ER)模型,数据仓库之父Immon提出的,从全企业的高度设计一个3NF模型,用实体加关系描述的数据模型描述企业业务架构,在范式理论上符合3NF。此建模方法,对建模人员的能力要求非常高。
3. Data Vault模型
DataVault由Hub(关键核心业务实体)、Link(关系)、Satellite(实体属性) 三部分组成 ,是Dan Linstedt发起创建的一种模型方法论,它是在ER关系模型上的衍生,同时设计的出发点也是为了实现数据的整合,并非为数据决策分析直接使用。
4. Anchor模型
高度可扩展的模型,所有的扩展只是添加而不是修改,因此它将模型规范到6NF,基本变成了K-V结构模型。企业很少使用,本文不多做介绍。
建模工具,一般企业以Erwin、powerdesigner、visio,甚至Excel等为主。也有些企业自行研发工具,或使用阿里等成熟套装组件产品。
—————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————
数据应用
https://posts.careerengine.us/p/5d9d33f16b4d4767678251c5https://posts.careerengine.us/p/5d9d33f16b4d4767678251c5
数据应用,是真正体现数仓价值的部分,包括且又不局限于 数据可视化、BI、OLAP、即席查询,实时大屏,用户画像,推荐系统,数据分析,数据挖掘,人脸识别,风控反欺诈等等。

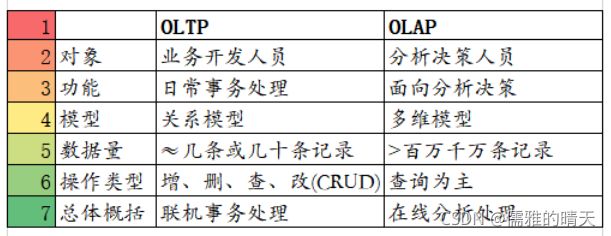
OLAP,On-Line Analytical Processing,在线分析处理,主要用于支持企业决策管理分析。区别于OLTP,On-Line Transaction Processing,联机事务处理。
OLAP的优势:丰富的数据展现方式、高效的数据查询以及多视角多层次的数据分析。
数据仓库与OLAP的关系是互补的,现代OLAP系统一般以数据仓库作为基础,即从数据仓库中抽取详细数据的一个子集并经过必要的聚集存储到OLAP存储器中供前端分析工具读取。
OLAP基本操作:
OLAP的多维分析操作包括:钻取(Drill-down)、上卷(Roll-up)、切片(Slice)、切块(Dice)以及旋转(Pivot)。
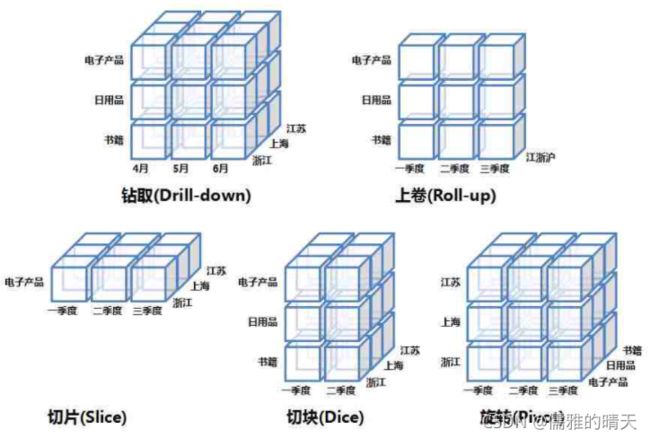
★钻取:维的层次变化,从粗粒度到细粒度,汇总数据下钻到明细数据。如通过季度销售数据钻取每个月的销售数据
★上卷:钻取的逆,向上钻取。从细粒度到粗粒度,细粒度数据到不同维层级的汇总。eg. 通过每个月的销售数据汇总季度、年销售数据
★切片:特定维数据(剩余维两个)。eg. 只选电子产品销售数据
★切块:维区间数据(剩余维三个)。eg. 第一季度到第二季度销售数据
★旋转:维位置互换(数据行列互换),通过旋转可以得到不同视角的数据。
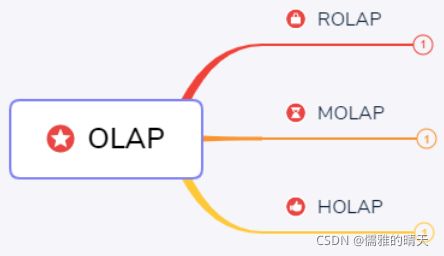
OLAP分类: OLAP按存储器的数据存储格式分为ROLAP(Relational OLAP)、MOLAP(Multi-dimensional OLAP)和 HOLAP(Hybrid OLAP)。
-
MOLAP,基于多维数组的存储模型,也是OLAP最初的形态,特点是对数据进行预计算,以空间换效率,明细和聚合数据都保存在cube中。但生成cube需要大量时间和空间。
-
ROLAP,完全基于关系模型进行存储数据,不需要预计算,按需即时查询。明细和汇总数据都保存在关系型数据库事实表中。
-
HOLAP,混合模型,细节数据以ROLAP存放,聚合数据以MOLAP存放。这种方式相对灵活,且更加高效。可按企业业务场景和数据粒度进行取舍,没有最好,只有最适合。
OLAP数据库选型:
在大数据数仓架构中,离线以Hive为主,实时计算一般是Spark+Flink配合,消息队列Kafka一家独大,后起之秀Pulsar想要做出超越难度很大,Hbase、Redis和MySQL都在特定场景下有一席之地。
唯独在OLAP领域,百家争鸣,各有所长。
OLAP引擎/工具/数据库,技术选型可有很多选择,传统公司大多以Congos、Oracle、MicroStrategy等OLAP产品,互联网公司则普遍强势拥抱开源,如
Presto,Druid ,Impala,SparkSQL,AnalyticDB,(Hbase)Phoenix,kudu, Kylin,Greenplum,Clickhouse, Hawq, Drill,ES等
在数据架构时,可以说目前没有一个引擎能在数据量,灵活程度和性能上(吞吐和并发)做到完美,用户需要根据自己的业务场景进行选型。
开源技术选型,MOLAP可选Kylin、Druid,ROLAP可选Presto、impala等