C++ 多线程(一)入门
C++ 多线程(一)
Multi-Threaded
多线程编程术语
线程
更确切地说,是执行线程,它是最小的处理单元。
- 由操作系统调度。
- 通常它包含在进程中。
- 因此,同一个进程中可以存在多个线程。它与进程共享资源:内存、代码(指令)和全局变量(上下文——它的变量在任何给定时刻引用的值)。
- 在单个处理器上,每个线程根据时间进行多路复用;在多处理器上,每个线程同时运行,每个处理器/核心运行一个特定的线程。
为什么用多线程
在应用程序本身中有多个执行线程的应用程序称为多线程应用程序。
例如,如果我们想创建一个服务器,它可以提供与服务器能够处理的并发连接数量一样多的连接,我们可以相对容易地完成这样的任务,如果我们为每个连接提供一个新线程。在某些情况下,多线程服务器不是创建单独的套接字来处理传入的连接,而是为每个传入的连接创建一个新线程,并为每个新线程创建一个新套接字。
我们需要多线程的另一个典型例子是 GUI 应用程序。GUI 应用程序有一个执行线程(主线程),每次执行一个操作。此线程要么在等待事件,要么在处理事件。因此,如果用户从用户界面触发一个耗时的操作,则在操作进行期间界面会冻结。在这种情况下,我们需要实现多线程。
主线程可以通过创建 thread 子类的对象来启动新线程。如果是多线程的,GUI 在它自己的线程中运行,在其他线程中进行额外的处理,即使在密集处理期间,应用程序也将具有响应性的 GUI。换句话说,我们将繁重的处理传递给分离的辅助线程,并让主 GUI 线程自由地响应用户。
这些新线程需要完成他们之间的沟通,以便应用程序可以让用户了解进展(保持用户界面更新关于进展),允许用户进行干预(为用户提供一些控制辅助线程),然后让主线程知道何时处理完成。通常,它们通过使用诸如互斥、信号量或等待条件等资源保护机制来一起使用共享变量。
线程 vs 进程
进程和线程彼此相关,但本质上是不同的。
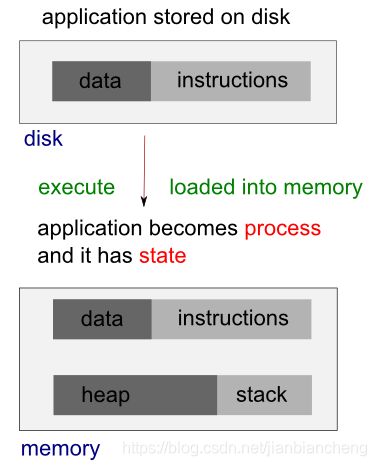
一个进程可以被看作是一个正在运行的程序的实例。每个进程都是一个独立的实体,系统资源(如 CPU 时间、内存等)都被分配给它,并且每个进程都在一个独立的地址空间中执行。如果我们想访问另一个进程的资源,必须使用进程间通信,如管道、文件、套接字等。关于 Linux 进程的更多信息。
进程为每个程序提供了两个关键的抽象:
- 逻辑控制流
每个进程似乎都独占 CPU- 专用虚拟地址空间
每个进程似乎独占使用主存
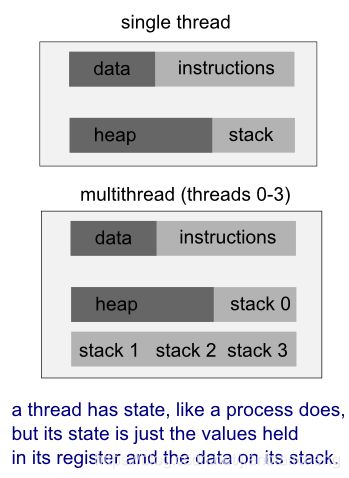
线程使用进程的相同地址空间。一个进程可以有多个线程。进程和线程之间的一个关键区别是,多个线程共享它们的部分状态。通常,多个线程可以对同一个内存进行读写(没有一个进程可以直接访问另一个进程的内存)。但是,每个线程仍然有自己的激活记录堆栈和自己的 CPU 寄存器副本,包括堆栈指针和程序计数器,它们一起描述了线程的执行状态。
线程是进程的特定执行路径。当一个线程修改一个进程资源时,该更改立即对同级线程可见。
- 当线程在进程中时,进程是独立的。
- 进程有独立的地址空间,而线程共享它们的地址空间。
- 进程之间通过进程间通信进行通信。
- 进程携带大量状态信息(例如,就绪、运行、等待或停止),而进程中的多个线程共享状态以及内存和其他资源。
- 同一进程中线程之间的上下文切换通常比进程之间的上下文切换要快。
- 多线程比多进程有一些优势。线程比进程需要更少的管理开销,而且进程内线程通信比进程间通信的开销更小。
- 多进程并发程序有一个优点:每个进程可以在不同的机器上执行(分发程序)。分布式程序的例子有文件服务器(NFS)、文件传输客户端和服务器(FTP)、远程登录客户端和服务器(Telnet)、群件程序、Web 浏览器和服务器。
消息传递 vs 共享内存
- 消息传递
- 消息通过进程间通信(IPC)机制交换数据。
- 优点: 适用于本地和远程通信。
- 缺点: 在“环回”配置中,对于大消息可能会导致额外的开销。
- 共享内存
- 共享内存允许应用程序访问和交换数据,就像他们是本地地址空间的每个进程。
- 优点: 在环回配置中可以更有效地处理大消息。
- 缺点: 不能有效地推广到远程系统 & 可能更容易出错 & 对于OO应用程序是不可移植的。
多进程 vs 多线程
- 多进程
- 进程是资源配置和保护的单位。
- 进程管理某些资源,如虚拟内存、I/O处理程序和信号处理程序。
- 优点: 通过 MMU 保护进程不受其他进程的影响。
- 缺点: 进程间的 IPC 可能是复杂和低效的。
- 多线程
- 线程管理特定的资源,例如堆栈、寄存器、信号掩码、优先级和特定于线程的数据
- 优点: 线程间的 IPC 比进程间的 IPC 更有效率。
- 缺点: 线程可能相互干扰。
进程和内核
在 Linux 系统中,内核知道并控制运行中的系统的一切,但进程不知道。进程是一个正在执行的程序的实例。当一个程序执行时,内核将程序的代码加载到虚拟内存中,为程序变量分配空间,并设置内核记录数据结构来记录关于该进程的各种信息(如进程ID、终止状态、用户ID和组ID)。
进程
- 一个正在运行的系统通常有许多进程。
- 对于一个进程,许多事情都是异步发生的。
- 一个正在执行的进程不知道它下一次何时会超时,其他哪些进程将被调度到 CPU (以及以什么顺序),或者下一次何时调度。信号的传递和进程间通信事件的发生是由内核调解的,并且可以在进程的任何时候发生。
- 对于一个过程来说,许多事情都是透明的。进程不知道它位于 RAM 中的什么位置,通常也不知道它的内存空间的特定部分当前是驻留在内存中还是保存在交换区(用于补充计算机 RAM 的预留磁盘空间)中。
- 类似地,进程不知道它访问的文件在磁盘驱动器的何处;它只是通过名称引用文件。
- 进程是独立运行的;它不能直接与另一个进程通信。
- 进程本身不能创建新进程,甚至不能结束自身的存在。实际上,一个进程可以使用 fork() 系统调用创建一个新进程。调用 fork() 的进程称为父进程,新的进程称为子进程。内核通过复制父进程来创建子进程。
- 最后,进程不能直接与计算机上的输入和输出设备通信。
内核
- 内核促进了系统上所有进程的运行。
- 内核决定接下来哪个进程将获得对 CPU 的访问权、何时访问以及访问时间。
- 内核维护包含所有正在运行的进程信息的数据结构,并在创建、更改状态和终止进程时更新这些结构。
- 内核维护所有低级数据结构,这些结构使程序使用的文件名能够被转换到磁盘上的物理位置。
- 内核还维护数据结构,将每个进程的虚拟内存映射到计算机的物理内存和磁盘上的交换区域。
- 进程之间的所有通信都是通过内核提供的机制完成的。为了响应来自进程的请求,内核创建新进程并终止现有进程。
- 最后,内核(特别是设备驱动程序)执行所有与输入和输出设备的直接通信,根据需要向用户进程传递信息。
从“Linux 编程接口”中的“系统的进程与内核视图”编辑
实时操作系统中的调度方法
优先级
- 每个任务相对于所有其他任务有一个优先级
- 最关键的任务被赋予最高的优先级
- 准备运行的最高优先级的 Task 获得处理器的控制权
- Task 会一直运行,直到产生、终止或阻塞
- 每个 Task 都有自己的内存堆栈
- 在一个 Task 运行之前,它必须从它的内存堆栈中加载它的上下文(这可能需要许多个周期)
- 如果 Task 被抢占,它必须保存当前状态/上下文;当 Task 获得处理器的控制权时,将恢复此上下文
在这种抢占式调度中,线程(或进程)必须处于以下四种状态之一:
- 运行:任务在 CPU 的控制下
- 就绪:当调度策略显示该任务为系统中优先级最高的未被阻塞任务时,该任务不被阻塞,并准备接受 CPU 的控制。
- 不活动:任务被阻塞,需要初始化才能准备好。
- 阻塞:任务正在等待某事发生或等待资源可用。
轮循
在这种方法中,时间片以相等的部分和循环的顺序分配给每个进程,处理没有优先级的所有进程(也称为循环执行)。循环调度非常简单,易于实现,而且不受限制。
有关实时操作系统的更多信息,请访问嵌入式系统编程:RTOS (实时操作系统)
优先级反转
这个问题的存在早已为人所知,然而,并没有万无一失的方法来预测情况。
为了确保快速响应时间,嵌入式 RTOS 可以使用抢占(高优先级任务可以中断正在运行的低优先级任务)。高优先级任务结束运行后,低优先级任务从中断点开始继续执行。
不幸的是,在抢占式多任务环境中操作的任务之间共享资源的需求可能会造成冲突。与死锁一起,优先级反转是两个最常见的导致应用程序失败的问题之一。(火星探路者计划)
典型的例子是中优先级任务(M)抢占高优先级任务,导致优先级反转。一个低优先级进程(L)获取了一个高优先级进程(H)想要访问的资源,但是被一个中优先级进程(M)抢占,因此高优先级进程(H)阻塞在该资源上,而中优先级进程(M)完成。当第三个中等优先级(M)的任务在低优先级进程使用资源时变为可运行时,就会发生这种情况。一旦高优先级的任务变得不可运行,第三个中等优先级的任务(M)是最高优先级的可运行任务,因此它运行,而当它运行时,L不能释放资源。因此,在这个场景中,中优先级任务(M)抢占高优先级任务(H),导致优先级反转。

图片来自如何使用优先级继承
为了避免优先级反转,优先级被设置(提升)为预定义的优先级,高于或等于可能锁定特定互斥锁的所有线程的最高优先级。这就是所谓的优先级上限。
当一个任务获取一个共享资源时,该任务会被提升(其优先级暂时提升)到该资源的优先级上限(这种无条件提升与优先级继承不同)。优先级上限必须高于所有可以访问该资源的任务的最高优先级,以确保拥有共享资源的任务不会被试图访问同一资源的其他任务抢占。当被提升的任务释放资源时,任务将恢复到原有的优先级。
优先级上限的替代方法是优先级继承,这是一种使用动态优先级调整的变体。当低优先级任务获取共享资源时,该任务将继续以其原始优先级运行。如果高优先级的线程请求共享资源的所有权,那么低优先级的任务将被提升到请求线程的优先级级别(高优先级的线程正在等待互斥锁),方法是继承该优先级。然后,低优先级任务可以继续执行其关键部分,直到释放资源。一旦资源被释放,任务就被放回到它原来的低优先级级别,允许高优先级任务使用它刚刚获得的资源。
由于实时应用程序中的大多数锁没有竞争,所以优先级继承协议具有良好的平均情况性能。当一个锁没有争用时,优先级不会改变;没有额外的开销。
不变量
不变量是广泛使用的概念之一,可以帮助程序员对代码进行推理。不变量——对于特定的数据结构(如链表)总是成立的语句。这些不变量经常在更新期间被破坏,特别是在以下情况下
- 数据结构的复杂性是任意的
- 更新需要修改多个值。
让我们考虑一个双向链表,其中每个节点都持有一个指向链表中下一个节点和上一个节点的指针。不变量之一是,如果我们遵循下一个指针(1)从一个节点到另一个(2),从该节点前面的指针(2)点回到第一个节点(1)。为了从列表中删除一个节点,节点两侧必须被更新为指向对方。一旦更新了一个节点,不变式就会被打破,直到另一边的节点也被更新为止。只有在所有必要的更新都完成之后,不变式才会重新保存。从这样的列表中删除条目的步骤如下:
- 确定需要删除的节点,n。
- 更新从 n 之前的节点到 n 之后的节点的链接。
- 更新从 n 之后的节点指向 n 之前的节点的链接。
- 删除节点 n。
然而,当一个方向的链接可能与相反方向的链接不一致时,不变式就被打破了。
破坏不变式是修改线程间共享数据时最简单的潜在问题。如果我们不做任何特别的保证否则,如果一个线程是读双向链表,而另一个是删除一个节点,读线程很可能看到列表中删除一个节点只能部分改变了(因为只有一个链接),不变的是坏了。
这个被打破的不变量的结果可能会有所不同。如果另一个线程只是从左到右读取列表项,那么它将跳过正在删除的节点。另一方面,如果第二个线程试图删除列表中最右边的节点,可能会永久地破坏数据结构并最终导致程序崩溃。无论结果如何,这都是并发代码中最常见的 bug 原因之一的一个例子:竞争条件。
本节主要来自 Anthony Williams 的 《C++ Concurrency in Action Practical Multithreading》 一书。
fork() 系统调用 vs 创建线程
我们需要清楚 fork() 系统调用和新线程创建之间的区别。
当一个进程执行 fork() 调用时,会创建一个带有它自己的变量和它自己的进程 id (PID) 的新副本,并且这个新进程是独立调度的,并且几乎独立于父进程执行。
另一方面,当我们在进程中创建一个新线程时,新线程会获得自己的堆栈(局部变量),但会与创建它的进程共享全局变量、文件描述符、信号处理程序和当前目录状态。
线程池 vs 按需线程
- 多重处理
1.预先创建线程,通过快速的生成策略分摊创建成本。
- 按需线程生成
- 用于实现每个请求的线程和每个连接的线程模型。
- 优点:减少未使用的预选线程的浪费资源消耗。
- 缺点:由于产生线程和启动服务的开销,可能会降低负载繁重的服务器和确定性的性能。
多线程的优势
- 在多 CPU 系统上更快。
- 即使在单 CPU 系统中,应用程序也可以通过使用与主线程并行运行的工作线程来保持响应。
识别何时使用多线程
所以,多线程是一件好事。如何识别代码中的是否要使用多线程?
- 我们需要应用程序的运行时配置文件数据。然后,我们可以识别代码的瓶颈。
- 检查该区域,并检查依赖关系。然后,确定依赖项是否可以分解为其中任何一个
- 多个并行任务
- 在多个并行迭代上循环
- 在这个阶段,我们可以考虑一个不同的算法。
- 我们需要估计开销和性能收益。它会给我们线性缩放线程的数量吗?
- 如果这个比例看起来没有希望,我们可能不得不扩大我们的分析范围。
上下文切换
将 CPU 从一个进程或线程切换到另一个进程或线程称为上下文切换。它需要保存旧进程或线程的状态,并加载新进程或线程的状态。由于每秒可能有几百个上下文切换,所以上下文切换可能会给执行增加大量开销。
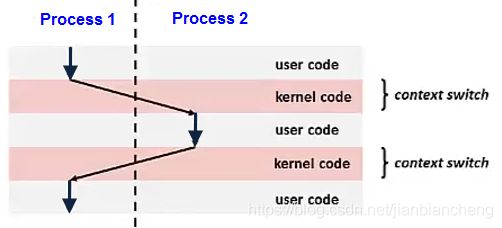
上下文切换通过异常控制流实现。
竞态条件
本节主要来自 Anthony Williams的《C++ Concurrency in Action Practical Multithreading》 一书。
在并发性中,竞争条件是任何结果依赖于两个或多个线程上操作的相对执行顺序的情况,其中线程竞争执行各自的操作。大多数时候,这是相当良性的,因为所有可能的结果都是可接受的,即使它们可能随着不同的相对顺序而改变。例如,如果两个线程向队列中添加项目以进行处理,那么首先添加哪个项目并不重要,前提是维护系统的不变量。
当竞争条件导致破坏不变量时,就会出现问题,比如本章不变量一节中提到的双链表例子。
当谈到并发时,术语竞态条件通常指有问题的竞态条件;良性的竞争条件不是那么有趣,也不应该成为 Bug 的原因。C++ 标准还定义了数据竞争这个术语,它指的是由于对单个对象进行并发修改而导致的特定类型的竞争条件,数据竞争导致了未定义的行为。
当临界区不是原子执行时,就会发生这种情况。
线程的执行依赖于共享状态。例如,两个线程共享变量i并试图将其增加1。这在很大程度上取决于他们什么时候得到它,什么时候保存它。
通常,当完成一个操作需要修改两个或多个不同的数据段(如不变量部分示例中的两个链接指针)时,会出现有问题的竞争条件。由于操作必须访问两个独立的数据段,因此必须在单独的指令中修改这些数据段,并且另一个线程可能在仅完成其中一个数据段时访问该数据结构。
竞争条件通常很难发现,也很难复制,因为机会之窗很小。如果修改是作为连续的CPU指令完成的,那么在任何一次运行中出现问题的概率都非常小,即使数据结构正在被另一个线程并发访问。随着系统负载的增加,以及操作执行次数的增加,出现问题执行序列的几率也会增加。在人们最不方便的时候出现这些问题几乎是不可避免的。
由于竞争条件通常是对时间敏感的,所以当应用程序在调试器下运行时,它们通常会完全消失,因为调试器会影响程序的时间,即使只有轻微的影响。
如果我们正在编写多线程程序,竞争条件很容易成为我们生活中的祸根。编写使用并发性的软件时的大量复杂性来自于避免有问题的竞争条件。
有几种方法可以解决有问题的比赛条件。最简单的选择是用保护机制包装数据结构,以确保只有实际执行修改的线程才能看到不变量被破坏的中间状态。从访问该数据结构的其他线程的角度来看,这些修改要么尚未开始,要么已经完成。
另一种选择是修改数据结构及其不变量的设计,以便将修改作为一系列不可分割的更改进行,每个更改都保留不变量。这通常称为无锁编程,很难正确实现。如果我们在这个层次上工作,那么内存模型的细微差别和识别哪些线程可以潜在地看到哪些值集可能会变得复杂。
如果我们正在编写多线程程序,竞争条件很容易成为我们生活中的祸根。编写使用并发性的软件时的大量复杂性来自于避免有问题的竞争条件。
有几种方法可以解决有问题的比赛条件。最简单的选择是用保护机制包装数据结构,以确保只有实际执行修改的线程才能看到不变量被破坏的中间状态。从访问该数据结构的其他线程的角度来看,这些修改要么尚未开始,要么已经完成。
另一种选择是修改数据结构及其不变量的设计,以便将修改作为一系列不可分割的更改进行,每个更改都保留不变量。这通常称为无锁编程,很难正确实现。如果我们在这个层次上工作,那么内存模型的细微差别和识别哪些线程可以潜在地看到哪些值集可能会变得复杂。
所需的一系列数据修改和读取存储在事务日志中,然后在单个步骤中提交。如果由于数据结构已被另一个线程修改而导致提交无法继续,则重新启动事务。这被称为软件事务性记忆(STM),目前是一个活跃的研究领域。
保护共享数据的最基本机制可能是互斥锁。
在下面的例子中,他们存入了100万美元。我们预计余额是200万美元。然而,正如我们从输出中看到的那样,事实并非如此:
// global1.c
#include
#include
static volatile int balance = 0;
void *deposit(void *param)
{
char *who = param;
int i;
printf("%s: begin\n", who);
for (i = 0; i < 1000000; i++)
{
balance = balance + 1;
}
printf("%s: done\n", who);
return NULL;
}
int main()
{
pthread_t p1, p2;
printf("main() starts depositing, balance = %d\n", balance);
pthread_create(&p1;, NULL, deposit, "A");
pthread_create(&p2;, NULL, deposit, "B");
// Join 等待线程完成
pthread_join(p1, NULL);
pthread_join(p2, NULL);
printf("main() A and B finished, balance = %d\n", balance);
return 0;
}
输出:
$ ./global
main() starts depositing, balance = 0
B: begin
A: begin
B: done
A: done
main() A and B finished, balance = 1270850
----
$ ./global
main() starts depositing, balance = 0
B: begin
A: begin
B: done
A: done
main() A and B finished, balance = 1423705
请注意,两个线程访问相同的函数并共享全局变量平衡。
简单地说,可能发生的情况是:增量余额的代码已经由 A 和 B 运行了两次,但是在这两种情况下,余额可能从 0 开始,而没有注意到另一个人正在将钱存入同一个帐户。
从技术上讲,存放过程可能不仅仅是一条指令,它可能有以下三个指令序列:
(1)
// 可变余额位于地址 0x8049a1c
// Mov 指令首先用于获取地址处的内存值
// 把它放到 eax 寄存器里
mov 0x8049a1c, %eax
(2)
// 执行添加,将1 (0x1) 添加到 eax 寄存器的内容中
add $0x1, %eax
(3)
// eax 的内容被存储在同一地址的内存中。
mov %eax, 0x8049a1c
我们需要使余额更新代码(临界部分)为原子:
// global2.c
#include
#include
static volatile int balance = 0;
pthread_mutex_t myMutex;
void *deposit(void *param)
{
char *who = param;
int i;
printf("%s: begin\n", who);
for (i = 0; i < 1000000; i++)
{
// 临界区
pthread_mutex_lock(&myMutex;);
balance = balance + 1;
pthread_mutex_unlock(&myMutex;);
}
printf("%s: done\n", who);
return NULL;
}
int main()
{
pthread_t p1, p2;
printf("main() starts depositing, balance = %d\n", balance);
pthread_mutex_init(&myMutex;,0);
pthread_create(&p1;, NULL, deposit, "A");
pthread_create(&p2;, NULL, deposit, "B");
// Join 等待线程完成
pthread_join(p1, NULL);
pthread_join(p2, NULL);
pthread_mutex_destroy(&myMutex;);
printf("main() A and B finished, balance = %d\n", balance);
return 0;
}
Makefile:
global2: global2.o
gcc -D_REENTRANT -o global2 global2.o -Wall -lpthread
global2.o: global2.c
gcc -c global2.c
clean:
rm -f *.o global2
现在,我们的输出看起来是理想的:
$ make
gcc -c global2.c
gcc -D_REENTRANT -o global2 global2.o -Wall -lpthread
$ ./global2
main() starts depositing, balance = 0
B: begin
A: begin
B: done
A: done
main() A and B finished, balance = 2000000
我们可以使用 valgrind --tool=helgrind 程序名来检测潜在的竞争条件。访问多线程调试。
死锁
两个或更多的竞争动作正在等待其他动作完成。没有线程改变它们的状态。
换句话说,当一些线程被阻塞以获取其他阻塞线程所持有的资源时,就会发生死锁。由于请求资源的两个或多个线程与持有这些资源的两个或多个线程之间的依赖关系,可能会导致死锁。
例1:阿方斯和加斯顿是朋友,是礼貌的忠实信徒。一个严格的礼貌规则是,当你向朋友鞠躬时,你必须一直鞠躬,直到你的朋友有机会回鞠躬。不幸的是,这条规则没有考虑到两个朋友可能同时向对方鞠躬的可能性。
例2:两个线程希望获得互斥锁A和B来完成它们的任务。假设线程1已经获得了锁A,线程2已经获得了锁B。那么,线程1因为等待锁B而不能取得进展,线程2因为等待锁A而不能取得进展,因此,两个线程都处于死锁状态。

如何避免死锁
- 在持有一个资源时,不要请求另一个资源。
- 如果你需要同时获得两个锁,那么你需要按照固定的顺序获得锁。
- 不要等待另一个线程,如果它有可能在等待你。
- 尽量避免锁的时间过长。
如何避免死锁C++ 11
如何避免死锁-生产者/消费者问题
从一个非常简单的例子开始,它提供了一个使用互斥(二进制信号量)的生产者/消费者(又名有界缓冲区)问题的解决方案。它还具有死锁的情况,并通过减小锁的范围来解决死锁的问题。
活锁
进程没有进展的情况。例子:当两个人在一条狭窄的小路上相遇,两个人都反复地试图向另一个人屈服。两者都在改变自己的状态,但没有任何进展。
一个线程经常对另一个线程的动作作出响应。如果另一个线程的动作也是对另一个线程的动作的响应,那么可能会产生活锁。与死锁一样,活动锁线程无法取得进一步的进展。然而,线程并没有被阻塞——它们只是忙于相互响应而无法继续工作。
在下例中,代码的编写是为了避免死锁,但是,如果两个线程同时执行,它们将被困在不断获取和释放互斥锁的活锁中。两者都不太可能取得进展。每个线程获得一个锁,然后尝试获取另一个锁。如果它无法获得另一个锁,它将在另一个尝试再次获得两个锁之前释放它持有的锁。当线程成功获得两个锁时,它就退出了循环,这种情况可能会发生,但在此之前,应用程序不会有任何进展:

饥饿
当进程被拒绝提供必要的资源时。没有资源,程序不能完成。
例如:一个对象提供了一个同步的方法,它通常需要很长时间才能返回。如果一个线程频繁地调用这个方法,那么其他需要频繁同步访问同一对象的线程通常会被阻塞。
锁的缺点
来自 MSDN:线程安全组件
虽然使用锁可以保证多个线程不会同时访问一个对象,但它们会导致显著的性能下降。想象一个运行着许多不同线程的程序。如果每个线程都需要使用一个特定的对象,并且必须在执行之前获得该对象的排他锁,那么这些线程将全部停止执行,并相互备份,从而导致性能较差。出于这些原因,我们应该只在代码必须作为一个单元执行时才使用锁。例如,我们可能更新多个相互依赖的资源。这样的代码被称为原子代码。将我们的锁限制在必须以原子方式执行的代码上,这将允许我们编写多线程组件,以确保我们的数据安全,同时仍然保持良好的性能。
我们还必须小心避免发生死锁的情况。在这种情况下,多个线程相互等待释放共享资源。例如,线程1可能持有资源a的锁,正在等待资源B。另一方面,线程2可能持有资源B的锁,正在等待资源a。在这种情况下,两个线程都不会被允许继续。避免死锁的唯一方法是仔细编程。
哲学家就餐问题
用餐哲学家的问题概括为五位哲学家坐在桌子前做两件事中的一件:吃饭或思考。当他们吃的时候,他们没有思考,当思考的时候,他们没有吃。五位哲学家坐在一张圆桌旁,中间放着一大碗意大利面。叉子被放在每一对相邻的哲学家之间,这样,每个哲学家都有一个叉子在他的左边,一个叉子在他的右边。由于意大利面很难用一个叉子端上桌,所以人们认为哲学家必须用两把叉子吃饭。每个哲学家只能使用他最左边和最右边的叉子。

源程序
哲学家们从不互相交谈,这就产生了一种危险的僵局,即每个哲学家都持有一个左叉,然后永远等待一个右叉(反之亦然)。
这个系统最初是用来说明死锁问题的,当出现“不合理的请求循环”时,系统就会出现死锁。在这种情况下,哲学家P1等待着哲学家P2抓住的叉子,P2也在等待哲学家P3的叉子,以此类推,形成了一个循环链。
如果一个哲学家因为时间问题而不能同时获得两个分叉,饥饿(这个双关语在最初的问题描述中是有意的)也可能独立于死锁发生。例如,可能有这样一条规则,哲学家在等待另一个叉子出现5分钟后放下一个叉子,然后再等待5分钟再进行下一次尝试。此方案消除了死锁的可能性(系统总是可以前进到不同的状态),但仍然存在活锁问题。如果所有五个哲学家出现在餐厅在完全相同的时间和每一个拿起叉车同时哲学家将等待5分钟,直到他们都放下刀叉,然后再等待五分钟前他们都把它们捡起来了。
总的来说,餐饮哲学家问题是一个用来解释以互斥为核心思想的问题中出现的各种问题的一般抽象问题。这些哲学家可能经历的各种失败类似于在真实的计算机编程中,当多个程序需要独占访问共享资源时出现的困难。这些问题是并发编程这一分支所研究的。Dijkstra最初的问题与磁带驱动器等外部设备有关。然而,当多个进程访问正在更新的数据集时,在餐饮哲学家问题中研究的困难更经常出现。必须处理大量并行进程的系统,如操作系统内核,使用数以千计的锁和同步,如果要避免死锁、饥饿或数据损坏等问题,这些锁和同步需要严格遵守方法和协议。
互斥(互斥)
我们希望保护数据不受竞态条件和可能出现的破坏不变量的影响。如果我们能将访问数据结构的所有代码片段标记为互斥的,那么如果任何线程正在运行其中的一个,任何试图访问该数据结构的其他线程必须等待第一个线程完成。这将使线程不可能看到被破坏的不变量,除非是线程在做修改。
有两种类型的同步:
1. 互斥
互斥确保了一组原子操作(临界区不能同时被多个线程执行)。
在访问共享数据结构之前,我们锁定与该数据相关联的互斥锁,当我们访问完数据结构后,我们解锁互斥锁。然后确保一旦一个线程锁定了一个特定的互斥锁,所有试图锁定同一互斥锁的其他线程必须等待,直到成功锁定互斥锁的线程解锁它。
这确保所有线程看到共享数据的自一致视图,没有任何损坏的不变量。
尽管互斥锁是最通用的数据保护机制,但重要的是要结构化代码以保护正确的数据,并避免接口中固有的竞争条件。
互斥锁也有其自身的问题,其形式是死锁和保护太多或太少的数据。
2. 状态同步
条件变量提供的同步类型与互斥锁、读/写锁或信号量锁不同。当持有锁的线程在临界区执行代码时,后三种机制使其他线程等待,条件变量允许协调和调度自己的处理(注意:信号量可以通过向其他线程发送条件信号来使用条件同步)。
这可以确保在某个操作发生之前,程序的状态满足特定的条件。例如,在银行账户问题中,需要条件同步和互斥。在执行方法 withdraw() 之前,余额必须不为空,并且需要互斥以确保取回不会执行多次。
它用于避免临界区同时使用全局变量等资源。临界区是进程或线程访问公共资源的一段代码。
互斥锁确保一次只有一个线程可以访问一个资源。如果锁被另一个线程持有,试图获取锁的线程将休眠,直到锁被释放。还可以指定一个超时,以便如果锁在指定的时间间隔内不可用,则锁定获取将失败。这种方法的一个问题是它可以序列化程序。这将导致多线程程序只有一个执行线程,这将阻止该程序利用多个核。
如果多个线程都在等待锁,则无法保证等待的线程获取互斥锁的顺序。互斥锁可以在进程之间共享。相比之下,临界区不能在进程之间共享;因此,关键部分的性能开销更低。
自旋锁
旋转锁本质上是互斥锁。
旋转锁反复轮询它的锁条件,直到该条件变为真。自旋锁通常用于锁的预期等待时间较小的多处理器系统。在这些情况下,轮询通常比阻塞线程更有效,后者涉及上下文切换和线程数据结构的更新。
互斥锁和自旋锁的区别在于,等待获取自旋锁的线程会在不休眠和消耗处理器资源的情况下不断尝试获取锁,直到最终获得锁。相反,互斥锁在无法获得锁的情况下可能会休眠。但在普通的互斥锁实现下,当一个线程无法获得互斥锁时,它会立即进入睡眠状态。
使用旋转锁的好处是,它们会在锁被释放后立即获得锁,而互斥锁在获得锁之前需要被操作系统唤醒。其缺点是,旋转锁将在独占该资源的虚拟CPU上旋转,但互斥锁将休眠并释放CPU供其他线程使用。因此,在实践中,互斥锁通常是旋转锁和更传统的互斥锁的混合体。这种互斥锁称为自适应互斥锁。
例如代码,请访问 PThread: Spin Locks。
互斥锁是如何实现的?
大多数语言级互斥锁实现依赖于机器级支持,比如 http://en.wikipedia.org/wiki/Test-and-set。
临界区
访问共享变量(或其他共享资源)并且必须作为原子操作执行的代码段称为临界段。根据操作系统的不同,通常操作系统提供了比较和交换、测试和设置以及测试和清除操作的几个原子版本。
while (true)
{
entry-section
critical section // 访问共享变量
exit-section
noncritical section
}
临界区段周围的入口区段和出口区段必须满足以下正确性要求:
1. 互斥
当一个线程在其关键部分执行时,其他线程不能在其关键部分执行。
2. 进展
如果没有线程在其关键部分执行,并且有线程希望进入其关键部分,则只有在其入口或出口部分执行的线程才能参与决定下一个哪个线程将进入其关键部分,并且此决定不能无限期推迟。
3. 有界等待
在一个线程请求进入其关键部分之后,在该线程的请求被允许之前,允许其他线程进入其关键部分的次数有一个界限。
临界区类似于互斥锁。不同之处在于关键部分不能在进程之间共享。因此,它们的性能开销更低。临界区也有一个不同于互斥锁提供的接口。临界区不接受超时值,但是有一个接口允许调用线程尝试进入临界区。如果失败,调用立即返回,使线程能够继续执行。在线程无法进入临界段的情况下,它们还具有在线程进入睡眠之前旋转多次迭代的功能。
精简的读/写锁
精简的读/写锁为有多个线程读取共享数据的情况提供了支持,但在极少数情况下需要写入共享数据。多个线程可以同时访问正在读取的数据,而不必担心正在共享的数据的损坏问题。但是,在任何时间只有一个线程可以访问更新数据,其他线程不能在写操作期间访问该数据。这是为了防止线程读取正在写入的不完整或损坏的数据。精简的读/写锁不能跨进程共享。
信号量
信号量是可以增加或减少的计数器。它们可以用于对资源有有限限制的情况,而需要一种机制来施加这种限制。一个例子是具有固定大小的缓冲区。每当将一个元素添加到缓冲区中,可用位置的数量就会减少。每次删除一个元素,可用的数量就会增加。
当一个线程试图减少一个值为0的信号量时,它会阻塞。阻塞的线程只有在另一个线程发送信号量后才会被释放,导致其计数大于0。信号量保持状态以跟踪计数和阻塞线程的数量。它们通常使用睡眠锁来实现,睡眠锁会触发允许其他线程执行的上下文切换。与互斥锁不同,它们不需要由最初获得它们的同一个线程释放。此功能允许在更广泛的执行上下文中使用信号量,如信号/中断处理程序。
信号量也可以用来模拟互斥锁。如果信号量中只有一个元素,那么它可以被获取或可用,就像互斥锁可以被锁定或解锁一样。
信号量还将向等待它们使用可用资源的线程发出信号或唤醒它们。因此,它们可以用于线程之间的信令。
信号量用于提供互斥和条件同步。
它是一个二进制信号量(真或假)或计数器(计数)信号量的变量。信号量是用来防止竞争的。信号量提供了一种限制对一组有限资源的访问的方法,或者用来发出资源可用的信号。与互斥锁的情况一样,信号量可以跨进程共享。
1、计数信号量
计数信号量是一个用整数值初始化的同步对象,然后通过两个操作(分别表示向下、向上或递减、递增、等待、信号)进行访问(Dijkstra)。
class countingSemaphore
{
public:
countingSemaphore(int initialPermits)
{
permits = initialPermits;
}
void P() {}
void V() {}
private:
int permits;
};
void countingSemaphore::P()
{
if(permits > 0)
--permits; // take a permit from the pool
else // the pool is empty so wait for a permit
wait until permits becomes positive and the decrement permits by one.
}
void CountingSemaphore::V()
{
++permits; // return a permit to the pool
}
将计数信号量解释为拥有一个许可池是很有帮助的。一个线程调用方法P()来请求一个许可。如果池是空的,线程将等待一个许可变为可用。线程调用方法V()向池返回一个许可。计数信号量被声明和初始化
countingSemaphore s(1);
初始值(在本例中为1)表示池中许可的初始数量。对于计数信号量,在任何时候,以下关系都成立:
(the initial number of permits) + (the number of completed s.V() operations)
>= (the number of completed s.P() operations
这种关系被称为信号量的不变量。计数信号量依赖于信号量不变量来定义其行为。
2、二进制信号量
一个名为 mutex 的信号量被初始化为 1。对 mutex.P() 和 mutex.V() 的调用创建了一个临界区:
Thread1 Thread2
----------------------------------
mutex.P(); mutex.P();
/*critial section*/ /*critical section*/
mutex.V(); mutex.V();
由于互斥的初始值为1,并且 mutex.p() 和 mutex.v() 被放置在临界区附近,mutex.p() 操作会先完成,然后是 mutex.v(),依此类推。对于这个模式,我们可以让互斥量成为一个计数信号量,或者我们可以使用一种更严格的信号量类型,称为二进制信号量。
信号量和互斥锁
信号量是互斥量的另一种泛化,信号量可以用来保护一定数量的相同资源。互斥锁(二进制信号量)只允许锁定它的线程访问受保护的资源。任何线程都可以通过 pThread 的 sem_post() 来发送信号量,但是互斥锁只能由拥有它的线程来解锁。
| 信号量 | 锁 |
|---|---|
| Semaphore semaphore(1); | Mutext mutex; |
| semaphore.acquire(); | mutex.lock(); |
| semaphore.release(); | mutex.unlock(); |
我们将1传递给信号量构造函数,并告诉信号量它控制单个资源。显然,这是使用信号量的优点,因为我们可以将1以外的数字传递给构造函数,然后多次调用 acquire() 来获取许多资源。
互斥量本质上与二进制信号量是相同的,有时使用相同的基本实现。它们之间的区别是(wiki):
- 互斥锁有一个所有者的概念,即锁定互斥锁的进程。只有锁定互斥锁的进程才能解锁它。相反,信号量没有所有者的概念。任何进程都可以解锁一个信号量。
- 与信号量不同,互斥提供优先级反转安全性。因为互斥锁知道它的当前所有者,所以当一个高优先级的任务开始等待互斥锁时,就可以提升所有者的优先级。
- 互斥锁还提供了删除安全性,持有互斥锁的进程不会被意外删除。信号量不提供这种功能。
监控
信号量是在引入数据封装和信息隐藏等编程概念之前定义的。在基于信号量的程序中,共享变量和保护它们的信号量都是全局变量。这将导致共享变量和信号量操作分布到整个程序中。
因为P和V操作用于互斥和条件同步,所以在不检查所有代码的情况下很难确定信号量是如何被使用的。
监视器就是为了克服这些问题而发明的。
监视器封装共享数据、对数据的所有操作以及访问数据所需的任何同步。一个监视器有独立的构造用于互斥和条件同步。事实上,互斥是由监视器的实现自动提供的,将程序员从实现关键部分的负担中解放出来。
同步——信号量 vs 监视器
为了避免数据损坏和其他问题,应用程序必须控制线程如何访问共享资源。它被称为线程同步。基本的线程同步构造是监视器和信号量。我们应该用哪一个?这取决于系统或语言支持什么。
监视器是一组由互斥锁保护的例程。在获得锁之前,线程不能执行监视器中的任何例程,这意味着每次只能在监视器中执行一个线程。所有其他线程必须等待当前正在执行的线程释放锁。线程可以在监视器中挂起自己,等待事件发生,在这种情况下,另一个线程就有机会进入监视器。在某个时刻,被挂起的线程会被通知事件已经发生,从而允许它尽快唤醒并重新获得锁。
-
信号量是一个更简单的结构,它只是一个保护共享资源的锁。在使用共享资源之前,应用程序必须获得锁。任何试图使用该资源的其他线程都会被阻塞,直到拥有该资源的线程释放锁,此时等待的线程中的一个获得了锁并被解除阻塞。这是最基本的信号量,互斥信号量或互斥信号量。还有其他的信号量类型,比如计数信号量(允许n个线程在任何给定时间访问一个资源)和事件信号量(通知一个或所有等待的线程发生事件),但它们的工作方式基本相同。
-
监视器和信号量是等价的,但是监视器使用起来更简单,因为它们处理锁定获取和释放的所有细节。在使用信号量时,应用程序必须非常小心地释放线程终止时获得的任何锁。否则,其他需要共享资源的线程就不能继续。此外,访问共享资源的每个例程在使用资源之前必须显式地获取一个锁,这在编写代码时很容易忘记。监视器总是自动获取必要的锁。
记忆障碍
内存屏障是一种非阻塞同步工具,用于确保内存操作以正确的顺序发生。内存屏障就像一个栅栏,强制处理器完成位于屏障前面的任何加载和存储操作,然后才允许它执行位于屏障之后的加载和存储操作。
内存屏障通常用于确保一个线程的内存操作总是按照预期的顺序发生。在这种情况下,缺少内存屏障可能会让其他线程看到看似不可能的结果。要使用内存屏障,只需在代码中适当的位置调用内存屏障函数(acquire_memory_barrier()/release_memory_barrier()等)。
易失性变量
Volatile变量对单个变量应用另一种类型的内存约束。编译器通常通过将变量的值加载到寄存器来优化代码。对于局部变量,这通常不是问题。但是,如果变量在其他线程中可见,这样的优化可能会阻止其他线程注意到对它的任何更改。
对变量应用 volatile 关键字将强制编译器在每次使用该变量时从内存中加载该变量。如果一个变量的值可以在任何时候被编译器无法检测到的外部源更改,则可以将其声明为 volatile。
然而,就像内存屏障一样,由于volatile变量限制了优化的编译器性能,因此应该少量使用它,并且只在需要确保正确性的地方使用。
如果我们已经在使用互斥锁来保护一段代码,不要自动假设我们需要使用 volatile 关键字来保护该段中的重要变量。互斥锁包括一个内存屏障,以确保加载和存储操作的正确顺序。将 volatile 关键字添加到临界区中的变量中,将强制每次访问该变量时从内存中加载该值。在特定情况下,可能需要结合使用这两种同步技术,但这也会导致显著的性能损失。如果互斥量本身就足以保护变量,则省略 volatile 关键字。
同样重要的是,为了避免使用互斥对象,我们不要使用 volatile 变量。一般来说,互斥锁和其他同步机制比 volatile 变量更能保护数据结构的完整性。volatile 关键字只确保变量从内存中加载,而不是存储在寄存器中。volatile 关键字不能确保我们的代码正确访问该变量。
要了解更多信息,请访问 volatile关键字。
线程安全的
如果代码在多个线程并发执行时能够正确运行,那么它就是线程安全的。
当一个函数可以安全地从不同的线程同时调用时,我们可以说它是线程安全的。如果同时调用两个线程安全函数,则始终定义结果。当一个类的所有函数都可以从不同的线程同时调用时,即使在同一个对象上操作,也不需要相互推断,那么这个类就是线程安全的。
检查一段代码是否安全:
- 当它访问全局变量时。
- 分配/重新分配/释放全局范围的资源。
- 通过句柄或指针间接访问。
实现线程安全。
- 原子操作——可用的运行时库(机器语言指令)。
- 互斥锁
- 使用 Re-entrancy。
可重入的
如果可以安全地再次调用代码,则该代码是可重入的。换句话说,可重入代码可以被多次调用,即使被不同的线程调用,它仍然可以正确地工作。因此,代码的可重入部分通常只以这样一种方式使用局部变量,即每次对代码的调用都获得其自己的唯一数据副本。
可重入方法比线程安全方法更受限制。这是因为只有在每次调用只导致唯一的数据被访问(比如局部变量)时,才能从多个线程同时调用可重入方法。
1、不可重入代码
int g_var = 1;
int f()
{
g_var = g_var + 2;
return g_var;
}
int g()
{
return f() + 2;
}
如果两个并发线程访问 g_var,结果取决于每个线程的执行时间。
2、可重入代码
int f(int i)
{
return i + 2;
}
int g(int i)
{
return f(i) + 2;
}
线程安全和信号
本节借用 Threading Programming Guide。
对于线程化应用程序,没有什么比处理信号问题更令人担忧或困惑的了。信号是一种低级 BSD 机制,可用于向流程传递信息或以某种方式对其进行操作。有些程序使用信号来检测某些事件,如子进程的终止。该系统使用信号来终止失控进程并传递其他类型的信息。
信号的问题不在于它们做什么,而在于当我们的应用程序有多个线程时它们的行为。在单线程应用程序中,所有信号处理程序都在主线程上运行。在多线程应用程序中,没有绑定到特定硬件错误(如非法指令)的信号会被传递给当时正在运行的任何线程。如果多个线程同时运行,则将信号传递给系统碰巧选中的任何一个线程。换句话说,信号可以传递到应用程序的任何线程。
在应用程序中实现信号处理程序的第一个规则是避免假设是哪个线程在处理信号。如果一个特定的线程想要处理一个给定的信号,我们需要找到一种方法,在信号到达时通知该线程。我们不能假定安装来自该线程的信号处理程序将导致将信号传递给同一个线程。
无锁的代码
原子操作是成功完成或失败的操作。操作既不可能导致一个坏值,也不可能允许系统上的其他线程拥有一个瞬态值。这方面的一个例子是原子增量,这意味着调用线程将 n 与 n + 1 交换。这看起来很简单,但操作可能涉及以下几个步骤:
Load initial value to register
Increment the value
Store the new value back to memory
因此,在这三个步骤中,另一个线程可能会进来并干扰,并使用一个新的值替换该值,从而创建一个数据竞争。
通常,硬件提供对一系列原子操作的支持。原子操作通常用于启用无锁代码的编写。无锁实现不会依赖互斥锁来保护访问。相反,它将使用一系列操作来执行操作,而不需要获取显式锁。这可能比用锁控制访问具有更高的性能。
加入
一个线程可以执行一个线程联接,直到另一个线程终止。
让我们考虑下面的场景。你正在和你的同事准备明天的报告。作为团队的主要成员,你需要继续工作,而团队的其他成员出去为你带午餐。在本例中,您是主线程,而您的同事是子线程,并且您和您的同事都同时在做他们的工作(即,工作并携带午餐袋)。现在,我们有两种情况要考虑。首先,你的同事给你带来午餐,然后在你工作的时候下班。在这种情况下,你可以停止工作,享受午餐。第二,你很早就完成了你的工作,在午饭前小睡一会儿。当然,你不可能进入深度睡眠;否则,你就没机会吃午饭了。你要做的就是等你的同事把午饭带回来。
线程连接就是为了解决这个问题而设计的。一个线程可以执行一个线程联接,直到另一个线程终止。在我们的例子中,你(主线程)应该执行一个线程联接,等待你的同事(子线程)终止。一般来说,线程联接是让父线程§与它的一个子线程©联接。线程联接有以下活动,假设父线程P想要与其一个子线程C联接:
- 当P执行一个线程联接以便与C联接时(C仍在运行),P被挂起,直到C终止。一旦C终止,P继续。
- 当P执行一个线程连接而C已经终止时,P继续执行,就好像没有这样的线程连接执行过(也就是说,连接没有效果)。
一个父线程可以与父线程创建的许多子线程连接。或者,一个父线程只与它的一些子线程连接,而忽略其他的子线程。在这种情况下,那些被父线程忽略的子线程将在父线程终止时被终止。
如何在我的机器上使用线程?
在本节中,我将只编写 linux 系统。
从理论上讲,我们可以使用堆栈大小和虚拟空间(交换)的大小来计算机器上可用线程的可能数量:
swap/stack
因此,如果一台机器的交换大小为20GB,默认堆栈大小(我们可以使用“ulimit -s”来检查它)为10MB,那么我们可以拥有2,000个线程。然而,在此之前我们的性能就会受到影响。
尽管对于线程性能的可伸缩性存在一些争论,但经验法则可能是线程的数量应该与处理器的数量相匹配。
如果我们在linux系统上使用cat /proc/cpuinfo,我们将得到处理器的数量。这应该是我们应该使用的最佳线程数。
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 26
model name : Intel(R) Xeon(R) CPU E5520 @ 2.27GHz
stepping : 5
cpu MHz : 1596.000
cache size : 8192 KB
physical id : 1
siblings : 8
core id : 0
cpu cores : 4
.....
.....
.....
processor : 15
vendor_id : GenuineIntel
cpu family : 6
model : 26
model name : Intel(R) Xeon(R) CPU E5520 @ 2.27GHz
stepping : 5
cpu MHz : 1596.000
cache size : 8192 KB
physical id : 0
siblings : 8
core id : 3
cpu cores : 4
apicid : 7
fpu : yes
fpu_exception : yes
cpuid level : 11
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush d
ts acpi mmx fxsr sse sse2 ss ht tm syscall nx rdtscp lm constant_tsc ida pni monitor ds_cpl vmx est
tm2 cx16 xtpr popcnt lahf_lm
bogomips : 4522.03
clflush size : 64
cache_alignment : 64
address sizes : 40 bits physical, 48 bits virtual
power management:
重要参数为:
处理器:0-15
物理 id: 0-1
兄弟姐妹:8
CPU核数:4
机器正在使用超线。我们知道这一点是因为兄弟姐妹(8)是cpu核数(4)的两倍。如果不是超线程,兄弟姐妹应该等于cpu核数。因此,对于每个cpu包(物理id = 0,1),我们有8个处理器(4核x hyperthread(2) = 8),这就给了我们8 x 2 = 16个处理器。
在Qt中,QtCore.QThread.idealThreadCount() 可以是合适的查询函数,我们可以使用它来决定可以使用的线程数。
内核级线程和用户级线程
- 操作系统调度确保应用程序适当地使用主机 CPU/核心资源。
- 现代操作系统平台为调度线程提供了各种模型。
- 模型之间的一个关键区别是线程争用系统资源(如 CPU 时间)的争用范围。
- 系统争用作用域(内核线程)
- 线程直接与其他系统作用域线程竞争,而不管它们处于哪个进程中。
- 用户线程和内核线程之间的1:1映射。
- 优点:可以有效地利用硬件并行性。。
- 缺点:更高的线程创建和上下文切换开销。。
- 进程争用作用域(用户线程)
- 同一个进程中的线程会相互竞争,但不会直接与其他进程中的线程竞争。
- N:1用户和内核线程之间的映射。
- 优点:较低的线程创建和上下文切换开销。
- 缺点:不能有效地利用硬件并行性,并且有奇怪的阻塞语义。。
- 系统争用作用域(内核线程)
操作系统多线程机制
操作系统提供多线程机制来处理生命周期管理、同步、属性和特定于线程的存储。线程生存期操作包括:
-
创建线程
- pthread_create() (PThreads)
- CreateThread() (WindowsOS)
-
终止线程
- 自愿——通过到达线程入口函数的终点或调用pthread_exit()(PThreads)或ExitThread()(Windows)。
- 非自愿的——通过信号或异步线程取消操作被终止pthread_cancel()(PThreads)或TerminateThread()(Windows)。
-
线程同步操作使创建的线程成为
- 分离-操作系统回收用于线程状态和退出状态的存储在它退出之后。
- 可接合的,操作系统保留终止线程的标识和退出状态,以便其他线程可以与它同步。
-
线程属性操作包括
设置和获取线程属性的操作,如优先级和调度类。 -
表的存储
这与全局数据类似,只是数据仅在执行线程的范围内是全局的。 -
(注意)使用本机OS并发机制开发并发应用可能会导致可移植性和可靠性问题。
套接字
要连接到另一台计算机,我们需要一个套接字连接。顺便问一下,这其中有什么联系?两个机器之间的关系,两个软件知道彼此。这两个软件知道如何相互沟通。换句话说,它们知道如何互相发送比特。
套接字连接意味着两台机器拥有彼此的信息,包括网络位置(IP地址)和TCP端口。
套接字是分配给服务器进程的资源。
有几种不同类型的套接字决定传输层的结构。最常见的类型是流套接字和数据报套接字。
流套接字
流套接字提供可靠的双向通信,类似于我们打电话给某人。一方向另一方发起连接,连接建立后,任何一方都可以与另一方进行通信。
此外,我们立即证实,我们所说的确实到达了目的地。
流套接字使用传输控制协议(TCP),它存在于开放系统互连(OSI)模型的传输层。数据通常以包的形式传输。TCP 的设计目的是使数据包的数据将到达没有错误和顺序。
web 服务器、邮件服务器以及它们各自的客户端应用程序都使用 TCP 和流套接字进行通信。
数据报套接字
与数据报套接字通信更像是写信,而不是打电话。连接是单向的,不可靠的。
如果我们寄几封信,我们就不能确定它们是否按照相同的顺序到达,甚至根本不能确定它们是否到达目的地。数据报套接字使用用户数据报协议(UDP)。实际上,它并不是真正的连接,只是将数据从一点发送到另一点的基本方法。
数据报套接字和 UDP 通常用于网络游戏和流媒体。
访问套接字编程