【重识云原生】第六章容器6.1.7.2节——cgroups原理剖析

《重识云原生系列》专题索引:
- 第一章——不谋全局不足以谋一域
- 第二章计算第1节——计算虚拟化技术总述
- 第二章计算第2节——主流虚拟化技术之VMare ESXi
- 第二章计算第3节——主流虚拟化技术之Xen
- 第二章计算第4节——主流虚拟化技术之KVM
- 第二章计算第5节——商用云主机方案
- 第二章计算第6节——裸金属方案
- 第三章云存储第1节——分布式云存储总述
- 第三章云存储第2节——SPDK方案综述
- 第三章云存储第3节——Ceph统一存储方案
- 第三章云存储第4节——OpenStack Swift 对象存储方案
- 第三章云存储第5节——商用分布式云存储方案
- 第四章云网络第一节——云网络技术发展简述
- 第四章云网络4.2节——相关基础知识准备
- 第四章云网络4.3节——重要网络协议
- 第四章云网络4.3.1节——路由技术简述
- 第四章云网络4.3.2节——VLAN技术
- 第四章云网络4.3.3节——RIP协议
- 第四章云网络4.3.4节——OSPF协议
- 第四章云网络4.3.5节——EIGRP协议
- 第四章云网络4.3.6节——IS-IS协议
- 第四章云网络4.3.7节——BGP协议
- 第四章云网络4.3.7.2节——BGP协议概述
- 第四章云网络4.3.7.3节——BGP协议实现原理
- 第四章云网络4.3.7.4节——高级特性
- 第四章云网络4.3.7.5节——实操
- 第四章云网络4.3.7.6节——MP-BGP协议
- 第四章云网络4.3.8节——策略路由
- 第四章云网络4.3.9节——Graceful Restart(平滑重启)技术
- 第四章云网络4.3.10节——VXLAN技术
- 第四章云网络4.3.10.2节——VXLAN Overlay网络方案设计
- 第四章云网络4.3.10.3节——VXLAN隧道机制
- 第四章云网络4.3.10.4节——VXLAN报文转发过程
- 第四章云网络4.3.10.5节——VXlan组网架构
- 第四章云网络4.3.10.6节——VXLAN应用部署方案
- 第四章云网络4.4节——Spine-Leaf网络架构
- 第四章云网络4.5节——大二层网络
- 第四章云网络4.6节——Underlay 和 Overlay概念
- 第四章云网络4.7.1节——网络虚拟化与卸载加速技术的演进简述
- 第四章云网络4.7.2节——virtio网络半虚拟化简介
- 第四章云网络4.7.3节——Vhost-net方案
- 第四章云网络4.7.4节vhost-user方案——virtio的DPDK卸载方案
- 第四章云网络4.7.5节vDPA方案——virtio的半硬件虚拟化实现
- 第四章云网络4.7.6节——virtio-blk存储虚拟化方案
- 第四章云网络4.7.8节——SR-IOV方案
- 第四章云网络4.7.9节——NFV
- 第四章云网络4.8.1节——SDN总述
- 第四章云网络4.8.2.1节——OpenFlow概述
- 第四章云网络4.8.2.2节——OpenFlow协议详解
- 第四章云网络4.8.2.3节——OpenFlow运行机制
- 第四章云网络4.8.3.1节——Open vSwitch简介
- 第四章云网络4.8.3.2节——Open vSwitch工作原理详解
- 第四章云网络4.8.4节——OpenStack与SDN的集成
- 第四章云网络4.8.5节——OpenDayLight
- 第四章云网络4.8.6节——Dragonflow
-
第四章云网络4.9.1节——网络卸载加速技术综述
-
第四章云网络4.9.2节——传统网络卸载技术
-
第四章云网络4.9.3.1节——DPDK技术综述
-
第四章云网络4.9.3.2节——DPDK原理详解
-
第四章云网络4.9.4.1节——智能网卡SmartNIC方案综述
-
第四章云网络4.9.4.2节——智能网卡实现
-
第六章容器6.1.1节——容器综述
-
第六章容器6.1.2节——容器安装部署
-
第六章容器6.1.3节——Docker常用命令
-
第六章容器6.1.4节——Docker核心技术LXC
-
第六章容器6.1.5节——Docker核心技术Namespace
-
第六章容器6.1.6节—— Docker核心技术Chroot
-
第六章容器6.1.7.1节——Docker核心技术cgroups综述
-
第六章容器6.1.7.2节——cgroups原理剖析
-
第六章容器6.1.7.3节——cgroups数据结构剖析
-
第六章容器6.1.7.4节——cgroups使用
-
第六章容器6.1.8节——Docker核心技术UnionFS
-
第六章容器6.1.9节——Docker镜像技术剖析
-
第六章容器6.1.10节——DockerFile解析
-
第六章容器6.1.11节——docker-compose容器编排
-
第六章容器6.1.12节——Docker网络模型设计
-
第六章容器6.2.1节——Kubernetes概述
-
第六章容器6.2.2节——K8S架构剖析
-
第六章容器6.3.1节——K8S核心组件总述
-
第六章容器6.3.2节——API Server组件
-
第六章容器6.3.3节——Kube-Scheduler使用篇
-
第六章容器6.3.4节——etcd组件
-
第六章容器6.3.5节——Controller Manager概述
-
第六章容器6.3.6节——kubelet组件
-
第六章容器6.3.7节——命令行工具kubectl
-
第六章容器6.3.8节——kube-proxy
-
第六章容器6.4.1节——K8S资源对象总览
-
第六章容器6.4.2.1节——pod详解
-
第六章容器6.4.2.2节——Pod使用(上)
-
第六章容器6.4.2.3节——Pod使用(下)
-
第六章容器6.4.3节——ReplicationController
-
第六章容器6.4.4节——ReplicaSet组件
-
第六章容器基础6.4.5.1节——Deployment概述
-
第六章容器基础6.4.5.2节——Deployment配置详细说明
-
第六章容器基础6.4.5.3节——Deployment实现原理解析
-
第六章容器基础6.4.6节——Daemonset
-
第六章容器基础6.4.7节——Job
-
第六章容器基础6.4.8节——CronJob
2 cgroups原理解析
上面是说的cgroups 是内核提供的功能,但现在我们在用户空间想使用的是cgroup的功能。其原理是:linux 内核有一个很强大的模块叫做VFS(vritual File System),VFS 把具体的文件系统的细节隐藏起来,给用户态进程提供一个完备的文件系统API接口。linux 也是通过VFS 把cgroups 功能暴漏给用户态进程的,cgroups 与VFS 之间的衔接部分叫做cgroups 文件系统。
用户态进程对groups 文件系统的操作,通过VFS 转换成cgroups 层级结构的维护。
2.1 cgroups 层级树的四大规则
传统的进程启动,是以init为根节点,也叫父进程,由它来创建子进程,作为子节点,而每个子节点还可以创建新的子节点,这样构成了树状结构。而cgroup的结构也是类似的,子节点继承父节点的属性。他们最大的不同在于,系统的cgroup构成的层级树允许有多个存在,如果进程模型是init为根节点形成一个树,那cgroup的模型由多个层级树来构成。
内核使用 cgroup 结构体来表示一个 control group 对某一个或者某几个 cgroups 子系统的资源限制。cgroup 结构体可以组织成一颗树的形式,每一棵cgroup 结构体组成的树称之为一个 cgroups 层级树。
1. 同一个cgroups层级树可以 attach 一个或者几个 cgroups 子系统(subsystem),当前层级树可以对其 attach 的 cgroups 子系统进行资源的限制。每一个 cgroups 子系统只能被 attach 到一个层级树中。
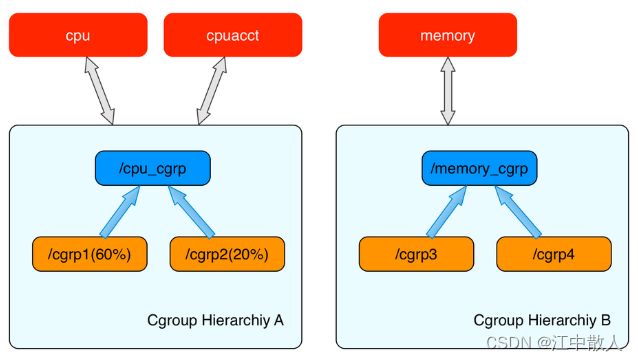
2. 创建了 cgroups 层级树中的节点(cgroup 结构体)之后,可以把进程加入到某一个节点的控制任务列表中,一个节点的控制列表中的所有进程都会受到当前节点的资源限制。同时某一个进程也可以被加入到不同的 cgroups 层级树的节点中,因为不同的 cgroups 层级树可以负责不同的系统资源。所以说进程和 cgroup 结构体是一个多对多的关系。
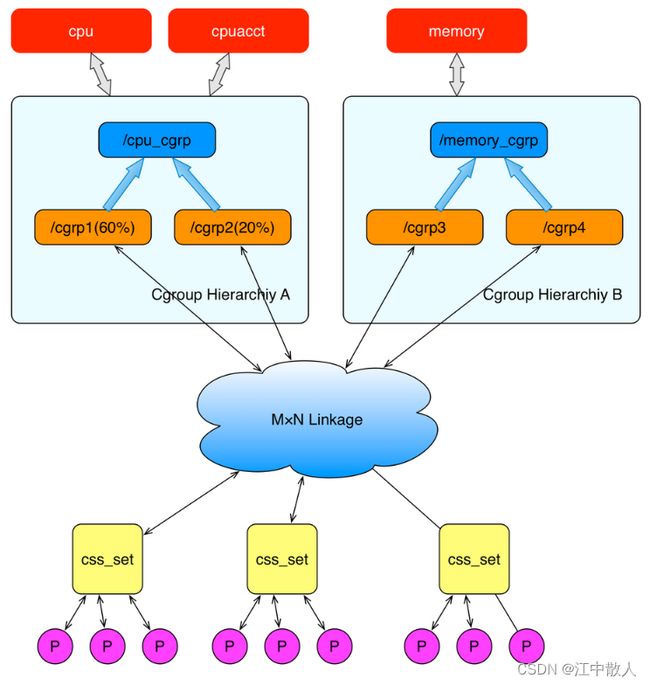
上面这个图从整体结构上描述了进程与 cgroups 之间的关系。最下面的P代表一个进程。每一个进程的描述符中有一个指针指向了一个辅助数据结构css_set(cgroups subsystem set)。 指向某一个css_set的进程会被加入到当前css_set的进程链表中。一个进程只能隶属于一个css_set,一个css_set可以包含多个进程,隶属于同一css_set的进程受到同一个css_set所关联的资源限制。
上图中的”M×N Linkage”说明的是css_set通过辅助数据结构可以与 cgroups 节点进行多对多的关联。但是 cgroups 的实现不允许css_set同时关联同一个cgroups层级树下多个节点。 这是因为 cgroups 对同一种资源不允许有多个限制配置。
一个css_set关联多个 cgroups 层级树的节点时,表明需要对当前css_set下的进程进行多种资源的控制。而一个 cgroups 节点关联多个css_set时,表明多个css_set下的进程列表受到同一份资源的相同限制。
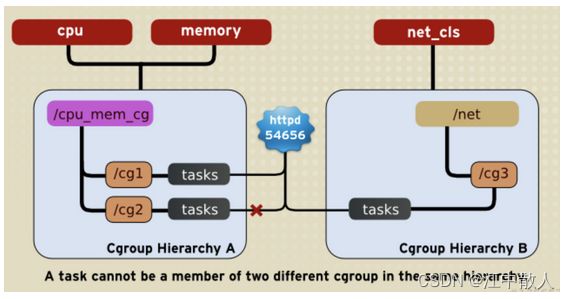
3. 一个task不能存在于同一个hierarchy的不同cgroup,但可以存在在不同hierarchy中的多个cgroup
系统每次新建一个hierarchy(即层级树)时,该系统上的所有task默认构成了这个新建的hierarchy的初始化cgroup,这个cgroup也称为root cgroup。
对于你创建的每个hierarchy,task只能存在于其中一个cgroup中,即一个task不能存在于同一个hierarchy的不同cgroup中,但是一个task可以存在在不同hierarchy中的多个cgroup中。
如果操作时把一个task添加到同一个hierarchy中的另一个cgroup中,则会从第一个cgroup中移除。
如下图,cpu和memory被附加到cpu_mem_cg的hierarchy。而net_cls被附加到net hierarchy。并且httpd进程被同时加到了cpu_mem_cg hierarchy的cg1 cgroup中和net hierarchy的cg3 cgroup中。并通过两个hierarchy的subsystem分别对httpd进程进行cpu,memory及网络带宽的限制。
4. 子task继承父task cgroup的关系
系统中的任何一个task(Linux中的进程)fork自己创建一个子task(子进程)时,子task会自动的继承父task cgroup的关系,在同一个cgroup中,但是子task可以根据需要移到其它不同的cgroup中。父子task之间是相互独立不依赖的。
如下图,httpd进程在cpu_and_mem hierarchy的/cg1 cgroup中并把PID 4537写到该cgroup的tasks中。
之后httpd(PID=4537)进程fork一个子进程httpd(PID=4840)与其父进程在同一个hierarchy的统一个cgroup中,但是由于父task和子task之间的关系独立不依赖的,所以子task可以移到其它的cgroup中。

2.2 cgroup 的组成
cgroup 代表“控制组”,并且不会使用大写。cgroup 是一种分层组织进程的机制, 沿层次结构以受控的方式分配系统资源。我们通常使用单数形式用于指定整个特征,也用作限定符如 “cgroup controller” 。
cgroup 主要有两个组成部分:
- core - 负责分层组织过程;
- controller - 通常负责沿层次结构分配特定类型的系统资源。每个 cgroup 都有一个 cgroup.controllers 文件,其中列出了所有可供 cgroup 启用的控制器。当在 cgroup.subtree_control 中指定多个控制器时,要么全部成功,要么全部失败。在同一个控制器上指定多项操作,那么只有最后一个生效。每个 cgroup 的控制器销毁是异步的,在引用时同样也有着延迟引用的问题;
所有 cgroup 核心接口文件都以 cgroup 为前缀。每个控制器的接口文件都以控制器名称和一个点为前缀。控制器的名称由小写字母和“”组成,但永远不会以“”开头。
2.2.1 cgroup 的核心文件
- cgroup.type - (单值)存在于非根 cgroup 上的可读写文件。通过将“threaded”写入该文件,可以将 cgroup 转换为线程 cgroup,可选择 4 种取值,如下:
-
- domain - 一个正常的有效域 cgroup
- domain threaded - 线程子树根的线程域 cgroup
- domain invalid - 无效的 cgroup
- threaded - 线程 cgroup,线程子树
- cgroup.procs - (换行分隔)所有 cgroup 都有的可读写文件。每行列出属于 cgroup 的进程的 PID。PID 不是有序的,如果进程移动到另一个 cgroup ,相同的 PID 可能会出现不止一次;
- cgroup.controllers - (空格分隔)所有 cgroup 都有的只读文件。显示 cgroup 可用的所有控制器;
- cgroup.subtree_control - (空格分隔)所有 cgroup 都有的可读写文件,初始为空。如果一个控制器在列表中出现不止一次,最后一个有效。当指定多个启用和禁用操作时,要么全部成功,要么全部失败。
-
- 以“+”为前缀的控制器名称表示启用控制器
- 以“-”为前缀的控制器名称表示禁用控制器
- cgroup.events - 存在于非根 cgroup 上的只读文件。
-
- populated - cgroup 及其子节点中包含活动进程,值为1;无活动进程,值为0.
- frozen - cgroup 是否被冻结,冻结值为1;未冻结值为0.
- cgroup.threads - (换行分隔)所有 cgroup 都有的可读写文件。每行列出属于 cgroup 的线程的 TID。TID 不是有序的,如果线程移动到另一个 cgroup ,相同的 TID 可能会出现不止一次。
- cgroup.max.descendants - (单值)可读写文件。最大允许的 cgroup 子节点数量。
- cgroup.max.depth - (单值)可读写文件。低于当前节点最大允许的树深度。
- cgroup.stat - 只读文件。
-
- nr_descendants - 可见后代的 cgroup 数量。
- nr_dying_descendants - 被用户删除即将被系统销毁的 cgroup 数量。
- cgroup.freeze - (单值)存在于非根 cgroup 上的可读写文件。默认值为0。当值为1时,会冻结 cgroup 及其所有子节点 cgroup,会将相关的进程关停并且不再运行。冻结 cgroup 需要一定的时间,当动作完成后, cgroup.events 控制文件中的 “frozen” 值会更新为“1”,并发出相应的通知。cgroup 的冻结状态不会影响任何 cgroup 树操作(删除、创建等);
- cgroup.kill - (单值)存在于非根 cgroup 上的可读写文件。唯一允许值为1,当值为1时,会将 cgroup 及其所有子节点中的 cgroup 杀死(进程会被 SIGKILL 杀掉)。一般用于将一个 cgroup 树杀掉,防止叶子节点迁移;
2.3子系统接口/参数
2.3.1 cpu子系统:用于限制进程的 CPU 利用率
CPU资源的控制有两种策略:
- 一种是完全公平调度 (CFS:Completely Fair Scheduler)策略,提供了限额和按比例分配两种方式进行资源控制;
- 另一种是实时调度(Real-Time Scheduler)策略,针对实时进程按周期分配固定的运行时间。配置时间都以微秒(µs)为单位,文件名中用us表示。
CFS调度策略下的配置:
- 设定CPU使用周期使用时间上限
- cpu.cfs_period_us:规定CPU的时间周期(单位是微秒)。最大值是1秒,最小值是1000微秒。如果在一个单CPU的系统内,要保证一个cgroup 内的任务在1秒的CPU周期内占用0.2秒的CPU时间,可以通过设置cpu.cfs_quota_us 为200000和cpu.cfs_period_us 为 1000000。必须与cfs_quota_us配合使用。
- cpu.cfs_quota_us :在单位时间内(即cpu.cfs_period_us设定值)可用的CPU最大时间(单位是微秒)。cpu.cfs_quota_us值可以大于cpu.cfs_period_us值,例如在一个双CPU的系统内,想要一个cgroup内的进程充分的利用2个CPU,可以设定cpu.cfs_quota_us为 200000 及cpu.cfs_period_us为 100000,当设定cpu.cfs_quota_us为-1时,表明不受限制,同时这也是默认值。
- cpu.stat:统计信息,包含nr_periods(表示经历了几个cfs_period_us周期)、nr_throttled(表示task被限制的次数)及throttled_time(表示task被限制的总时长)。
- 按权重比例设定CPU的分配
- cpu.shares:cpu比重分配。通过一个整数的数值来调节cgroup所占用的cpu时间。例如,有2个cgroup(假设为CPU1,CPU2),其中一个(CPU1)cpu.shares设定为100另外一个(CPU2)设为200,那么CPU2所使用的cpu时间将是CPU1所使用时间的2倍。cpu.shares 的值必须为2或者高于2。
RT调度策略下的配置 实时调度策略与公平调度策略中的按周期分配时间的方法类似,也是在周期内分配一个固定的运行时间。
- cpu.rt_period_us :设定周期时间。
- cpu.rt_runtime_us:设定周期中的运行时间。
2.3.2 cpuacct子系统:用于统计各个 Cgroup 的 CPU 使用情况
这个子系统的配置是cpu子系统的补充,提供CPU资源用量的统计,时间单位都是纳秒。
- cpuacct.stat:统计cgroup中所有任务的用户和内核分别使用CPU的时长
- cpuacct.usage:统计cgroup中所有任务的CPU使用时长(纳秒)
- cpuacct.usage_percpu:统计cgroup中所有任务使用的每个cpu的时间(纳秒)
2.3.3 cpuset子系统:为一组进程分配指定的CPU和内存节点
为task分配独立CPU资源的子系统,参数较多,这里只选讲两个必须配置的参数,同时Docker中目前也只用到这两个。
- cpuset.cpus:允许cgroup中的进程使用的CPU列表。如0-2,16代表 0,1,2,16这4个CPU
- cpuset.mems:允许cgroup中的进程使用的内存节点列表。如0-2,16代表 0,1,2,16这4个可用节点
- cpuset.memory_migrate:当cpuset.mems变化时内存页上的数据是否迁移(默认值0,不迁移;1,迁移)
- cpuset.cpu_exclusive:cgroup是否独占cpuset.cpus 中分配的cpu 。(默认值0,共享;1,独占),如果设置为1,其他cgroup内的cpuset.cpus值不能包含有该cpuset.cpus内的值
- cpuset.mem_exclusive:是否独占memory,(默认值0,共享;1,独占)
- cpuset.mem_hardwall:cgroup中任务的内存是否隔离,(默认值0,不隔离;1,隔离,每个用户的任务将拥有独立的空间)
- cpuset.sched_load_balance:cgroup的cpu压力是否会被平均到cpuset中的多个cpu上。(默认值1,启用负载均衡;0,禁用。)
2.3.4 memory子系统:限制cgroup所能使用的内存上限
- memory.limit_in_bytes:设定最大的内存使用量,可以加单位(k/K,m/M,g/G)不加单位默认为bytes
- memory.soft_limit_in_bytes:和 memory.limit_in_bytes 的差异是,这个限制并不会阻止进程使用超过限额的内存,只是在系统内存不足时,会优先回收超过限额的进程占用的内存,使之向限定值靠拢。该值应小于memory.limit_in_bytes设定值
- memory.memsw.limit_in_bytes:设定最大的内存+swap的使用量
- memory.oom_control:当进程出现Out of Memory时,是否进行kill操作。默认值0,kill;设置为1时,进程将进入睡眠状态,等待内存充足时被唤醒
- memory.force_empty:当设置为0时,清空该group的所有内存页;该选项只有在当前group没有tasks才可以使用
- memory.stat:统计内存使用情况。各项单位为字节
统计相关特性:
- memory.usage_bytes:报告该 cgroup中进程使用的当前总内存用量(以字节为单位)。
- memory.max_usage_bytes:报告该 cgroup 中进程使用的最大内存用量。
- memory.failcnt:报告内存达到在 memory.limit_in_bytes设定的限制值的次数。
- memory.stat:包含大量的内存统计数据。各项单位为字节。
- cache:页缓存,包括 tmpfs(shmem),单位为字节。
- rss:匿名和 swap 缓存,不包括 tmpfs(shmem),单位为字节。
- mapped_file:memory-mapped 映射的文件大小,包括 tmpfs(shmem),单位为字节。
- pgpgin:存入内存中的页数。
- pgpgout:从内存中读出的页数。
- swap:swap 用量,单位为字节。
- active_anon:在活跃的最近最少使用(least-recently-used,LRU)列表中的匿名和 swap 缓存,包括 tmpfs(shmem),单位为字节。
- inactive_anon:不活跃的 LRU 列表中的匿名和 swap 缓存,包括 tmpfs(shmem),单位为字节。
- active_file:活跃 LRU 列表中的 file-backed 内存,以字节为单位。
- inactive_file:不活跃 LRU 列表中的 file-backed 内存,以字节为单位。
- unevictable:无法再生的内存,以字节为单位。
- hierarchical_memory_limit:包含 memory cgroup 的层级的内存限制,单位为字节。
- hierarchical_memsw_limit:包含 memory cgroup 的层级的内存加 swap 限制,单位为字节。
2.3.5 blkio子系统:限制cgroup对IO的使用
- blkio.weight:设置权值,范围在[100, 1000],属于比重分配,不是绝对带宽。因此只有当不同 Cgroup 争用同一个 阻塞设备时才起作用
- blkio.weight_device:对具体设备设置权值。它会覆盖上面的选项值
- blkio.throttle.read_bps_device:对具体的设备,设置每秒读磁盘的带宽上限
- blkio.throttle.write_bps_device:对具体的设备,设置每秒写磁盘的带宽上限
- blkio.throttle.read_iops_device:对具体的设备,设置每秒读磁盘的IOPS带宽上限
- blkio.throttle.write_iops_device:对具体的设备,设置每秒写磁盘的IOPS带宽上限
2.3.6 devices子系统:限定cgroup内的进程可以访问的设备
- devices.allow:允许访问的设备。文件包括4个字段:type(设备类型), major(主设备号), minor(次设备号), and access(访问方式);
- type
- a — 适用所有设备,包括字符设备和块设备
- b — 块设备
- c — 字符设备
- major, minor
- 9:*
- *:*
- 8:1
- access
- r — 读
- w — 写
- m — 创建不存在的设备
- devices.deny:禁止访问的设备,格式同devices.allow;
- devices.list:显示目前允许被访问的设备列表;
2.3.7 freezer子系统:暂停或恢复任务
- freezer.state:当前cgroup中进程的状态
- FROZEN:挂起进程
- FREEZING:进程正在挂起中
- THAWED:激活进程
1. 挂起进程时,会连同子进程一同挂起。
2. 不能将进程移动到处于FROZEN状态的cgroup中。
3. 只有FROZEN和THAWED可以被写进freezer.state中, FREEZING则不能。
2.4 cgroup 文件系统实现
VFS虚拟文件系统转换,处理与Unix标准文件系统的所有系统调用。VFS对用户提供统一的读写接口,用户调用读写等函数时,内核则调用特定的文件系统实现。文件在内核内存中是一个file数据结构来表示的。这个数据结构包含一个f_op的字段,该字段中包含了一组指向特定文件系统实现的函数指针。当用户执行read()操作时,内核调用sys_read(),然后sys_read()查找到指向该文件属于的文件系统的读函数指针,并调用它,即file->f_op->read()。
基于VFS实现的文件系统,都必须实现定义这些对象,并实现这些对象中定义的函数指针。
cgroup文件系统的定义:
static struct file_system_type cgroup_fs_type = {
.name = "cgroup",
.get_sb = cgroup_get_sb,
.kill_sb = cgroup_kill_sb,
};
这里有定义了两个函数指针,定义了一个文件系统必须实现了的两个操作get_sb、kill_sb,即获得超级块和释放超级块。这两个操作会在使用mount系统调用挂载cgroup文件系统时使用。
参考链接
彻底搞懂容器技术的基石: cgroup
linux 容器(LXC) 第4章 cgroups_caoshuming_500的博客-CSDN博客
Cgroup原理及使用 - zhrx - 博客园
Linux 基础:cgroup 原理与实现_CGroup_层级_控制
【docker 底层知识】cgroup 原理分析_张忠琳的博客-CSDN博客_cgroup
CGroup的原理和使用_书笑生的博客-CSDN博客_cgroup原理
Docker核心原理之 Cgroup详解
Linux Cgroups详解(二) - lisperl - 博客园
Linux Cgroup系列(04):限制cgroup的内存使用(subsystem之memory)
Linux Cgroup系列(04):限制cgroup的内存使用(subsystem之memory) - SegmentFault 思否
Linux Cgroup系列(01):Cgroup概述
Linux Cgroup系列(01):Cgroup概述 - SegmentFault 思否
深入理解 Linux Cgroup 系列(一):基本概念
深入理解 Linux Cgroup 系列(一):基本概念 - SegmentFault 思否
深入理解 Linux Cgroup 系列(二):玩转 CPU
深入理解 Linux Cgroup 系列(二):玩转 CPU - SegmentFault 思否
深入理解 Linux Cgroup 系列(三):内存 - SegmentFault 思否