使用docker搭建Hadoop
Hadoop简介
1、Hadoop的整体框架
Hadoop由HDFS、MapReduce、HBase、Hive和ZooKeeper等成员组成,其中最基础最重要元素为底层用于存储集群中所有存储节点文件的文件系统HDFS(Hadoop Distributed File System)来执行MapReduce程序的MapReduce引擎。
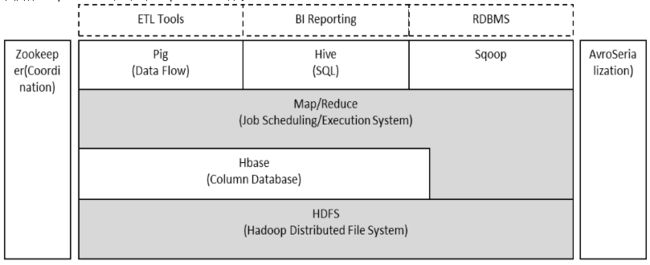
(1)Pig是一个基于Hadoop的大规模数据分析平台,Pig为复杂的海量数据并行计算提供了一个简单的操作和编程接口;
(2)Hive是基于Hadoop的一个工具,提供完整的SQL查询,可以将sql语句转换为MapReduce任务进行运行;
(3)ZooKeeper:高效的,可拓展的协调系统,存储和协调关键共享状态;
(4)HBase是一个开源的,基于列存储模型的分布式数据库;
(5)HDFS是一个分布式文件系统,有着高容错性的特点,适合那些超大数据集的应用程序;
(6)MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。
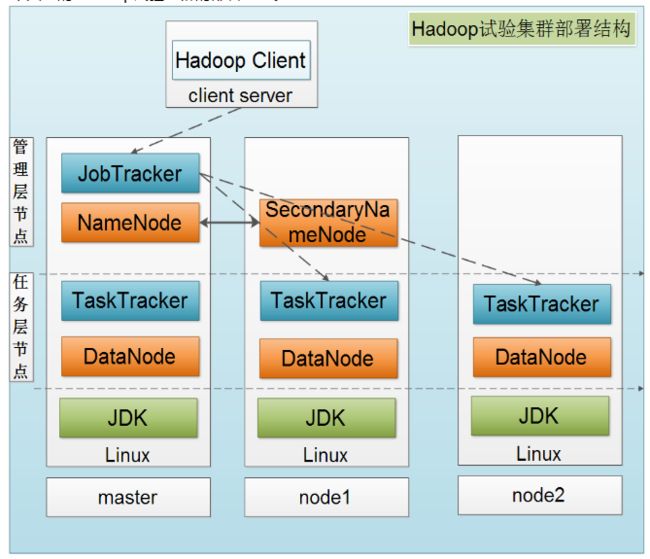
下图是一个典型的Hadoop集群的部署结构:
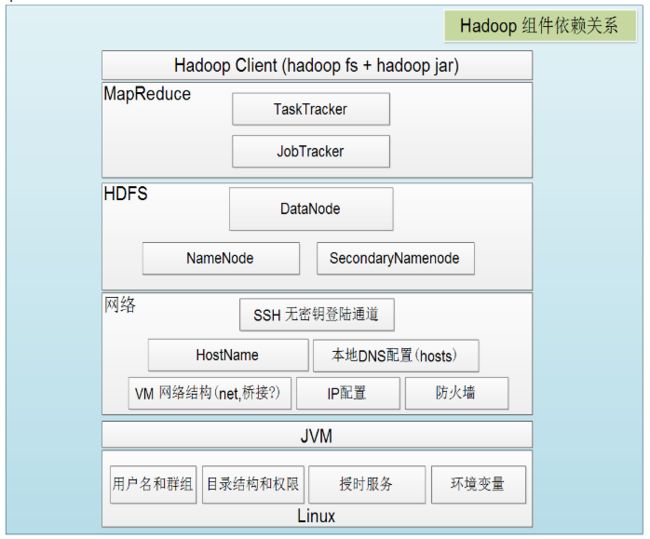
接着给出Hadoop各组件依赖共存关系:
2、Hadoop的核心设计
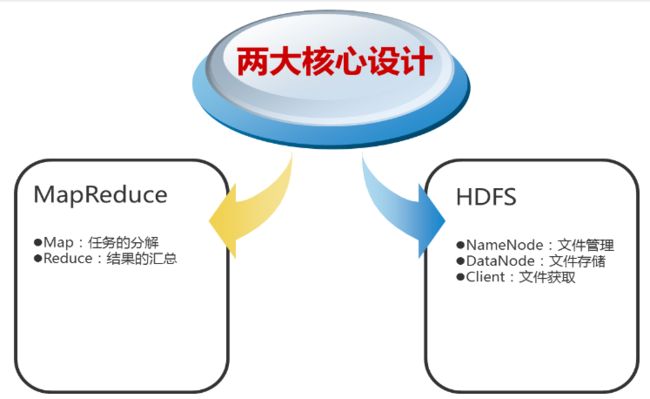
(1)HDFS
HDFS是一个高度容错性的分布式文件系统,可以被广泛的部署于廉价的PC上。它以流式访问模式访问应用程序的数据,这大大提高了整个系统的数据吞吐量,因而非常适合用于具有超大数据集的应用程序中。
HDFS的架构如图所示。HDFS架构采用主从架构(master/slave)。一个典型的HDFS集群包含一个NameNode节点和多个DataNode节点。NameNode节点负责整个HDFS文件系统中的文件的元数据的保管和管理,集群中通常只有一台机器上运行NameNode实例,DataNode节点保存文件中的数据,集群中的机器分别运行一个DataNode实例。在HDFS中,NameNode节点被称为名称节点,DataNode节点被称为数据节点。DataNode节点通过心跳机制与NameNode节点进行定时的通信。
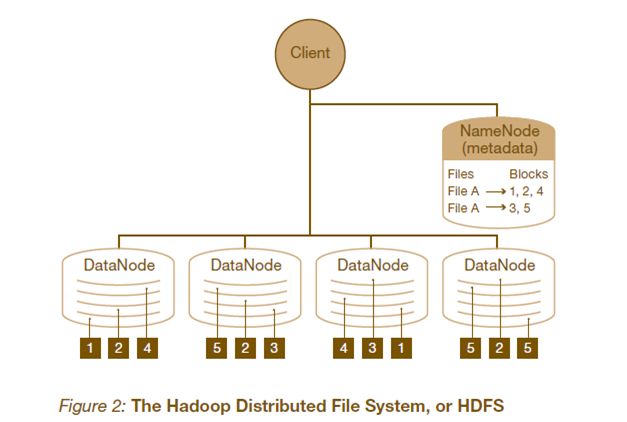
- NameNode
可以看作是分布式文件系统中的管理者,存储文件系统的meta-data,主要负责管理文件系统的命名空间,集群配置信息,存储块的复制。
- DataNode
是文件存储的基本单元。它存储文件块在本地文件系统中,保存了文件块的meta-data,同时周期性的发送所有存在的文件块的报告给NameNode。
- Client
就是需要获取分布式文件系统文件的应用程序。
以下来说明HDFS如何进行文件的读写操作:
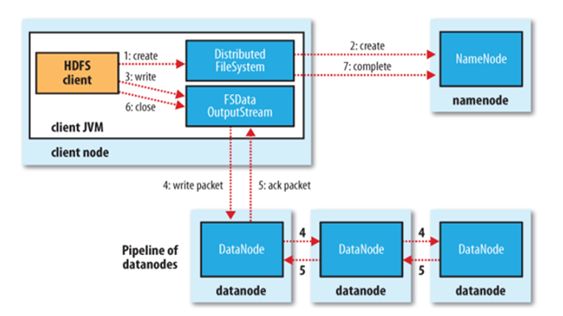
文件写入:
- Client向NameNode发起文件写入的请求
- NameNode根据文件大小和文件块配置情况,返回给Client它所管理部分DataNode的信息。
- Client将文件划分为多个文件块,根据DataNode的地址信息,按顺序写入到每一个DataNode块中。
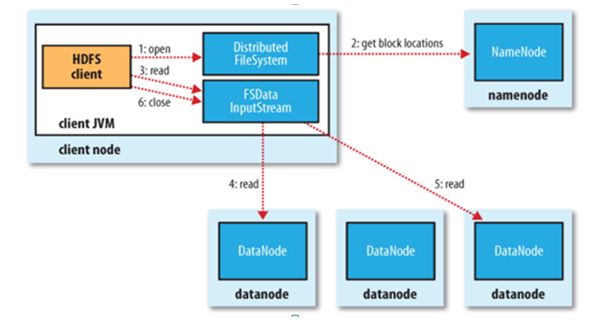
文件读取:
- Client向NameNode发起文件读取的请求
- NameNode返回文件存储的DataNode的信息。
- Client读取文件信息。
(2)MapReduce
MapReduce是一种编程模型,用于大规模数据集的并行运算。Map(映射)和Reduce(化简),采用分而治之思想,先把任务分发到集群多个节点上,并行计算,然后再把计算结果合并,从而得到最终计算结果。多节点计算,所涉及的任务调度、负载均衡、容错处理等,都由MapReduce框架完成,不需要编程人员关心这些内容。
下图是MapReduce的处理过程:
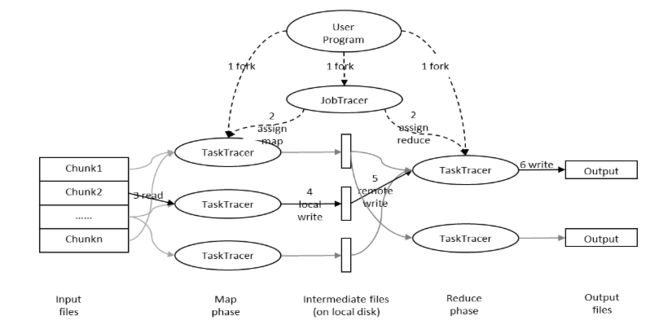
用户提交任务给JobTracer,JobTracer把对应的用户程序中的Map操作和Reduce操作映射至TaskTracer节点中;输入模块负责把输入数据分成小数据块,然后把它们传给Map节点;Map节点得到每一个key/value对,处理后产生一个或多个key/value对,然后写入文件;Reduce节点获取临时文件中的数据,对带有相同key的数据进行迭代计算,然后把终结果写入文件。
如果这样解释还是太抽象,可以通过下面一个具体的处理过程来理解:(WordCount实例)
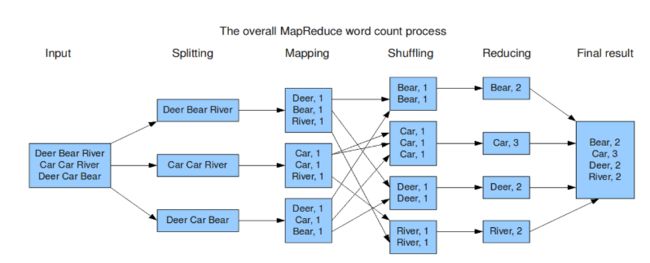
Hadoop的核心是MapReduce,而MapReduce的核心又在于map和reduce函数。它们是交给用户实现的,这两个函数定义了任务本身。
map函数:接受一个键值对(key-value pair)(例如上图中的Splitting结果),产生一组中间键值对(例如上图中Mapping后的结果)。Map/Reduce框架会将map函数产生的中间键值对里键相同的值传递给一个reduce函数。
reduce函数:接受一个键,以及相关的一组值(例如上图中Shuffling后的结果),将这组值进行合并产生一组规模更小的值(通常只有一个或零个值)(例如上图中Reduce后的结果)
但是,Map/Reduce并不是万能的,适用于Map/Reduce计算有先提条件:
(1)待处理的数据集可以分解成许多小的数据集;
(2)而且每一个小数据集都可以完全并行地进行处理;
若不满足以上两条中的任意一条,则不适合适用Map/Reduce模式。
使用docker搭建Hadoop
使用Docker搭建Hadoop集群的过程包括:
- 安装Docker
- 获取centos镜像
- 安装SSH
- 为容器配置IP
- 安装JAVA和Hadoop
- 配置Hadoop
安装docker
参考学习笔记-搭建Docker
获取centos镜像
[root@ali-test~]# docker search centos # 查找centos镜像
NAME DESCRIPTION STARS OFFICIAL AUTOMATED
centos The official build of CentOS. 6255 [OK]
[root@ali-test~]# docker pull centos # 拉取centos镜像
[root@ali-test~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
centos latest 0d120b6ccaa8 2 months ago 215MB
安装SSH
以centos7镜像为基础,构建一个带有SSH功能的centos
[root@ali-test~]# vim Dockerfile # 以 centos 镜像为基础,安装SSH的相关包,设置了root用户的密码
FROM centos # 基于centos镜像
MAINTAINER tian # 创建者信息
# 执行的命令
RUN yum -y install openssh-server sudo
RUN sed -i 's/UsePAM yes/UsePAM no/g' /etc/ssh/sshd_config
RUN yum -y install openssh-clients
RUN echo "root:1" | chpasswd
RUN echo "root ALL=(ALL) ALL" >> /etc/sudoers
RUN ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key
RUN ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key
RUN mkdir /var/run/sshd
EXPOSE 22 # 开放的端口
CMD ["/usr/sbin/sshd","-D"] # 执行的命令,这里为启动的命令,在/lib/systemd/system/sshd.service 可以查看到相应的启动命令
[root@ali-test ~]# docker build -t myos:ssh . # 构建基于centos的ssh镜像
Successfully tagged myos:ssh
[root@ali-test ~]# docker images # 查看镜像列表,可以看到构建的新镜像
REPOSITORY TAG IMAGE ID CREATED SIZE
myos ssh e82288279686 About a minute ago 277MB
centos latest 0d120b6ccaa8 2 months ago 215MB
设置固定IP
需要用到 pipework,他用于给容器设置IP
[root@ali-test ~]# git clone https://github.com/jpetazzo/pipework.git
[root@ali-test ~]# cd pipework/
[root@ali-test pipework]# cp pipework /usr/local/bin/ # 复制启动命令
# 下载bridge-utils网桥工具
[root@ali-test ~]# yum -y install bridge-utils
# 创建网络
[root@ali-test ~]# brctl addbr br1 # 添加bridge
[root@ali-test ~]# ip link set dev br1 up # 激活网桥设备br1
[root@ali-test ~]# ip addr add 192.168.1.1/24 dev br1 # 给br1添加ip
-----------------------------------------------------------------------------ps----------------------------------------------------------------------------------------------------------
| 参数 | 说明 | 示例 |
|---|---|---|
addbr |
创建网桥 | brctl addbr br10 |
delbr |
删除网桥 | brctl delbr br10 |
addif |
将网卡接口接入网桥 | brctl addif br10 eth0 |
delif |
删除网桥接入的网卡接口 | brctl delif br10 eth0 |
show |
查询网桥信息 | brctl show br10 |
stp |
启用禁用 STP | brctl stp br10 off/on |
showstp |
查看网桥 STP 信息 | brctl showstp br10 |
setfd |
设置网桥延迟 | brctl setfd br10 10 |
showmacs |
查看 mac 信息 | brctl showmacs br10 |
-----------------------------------------------------------------------------ps----------------------------------------------------------------------------------------------------------
基于myos:ssh这个镜像启动一个容器,名为 myos.ssh
[root@ali-test ~]# docker run -d --name=myos.ssh myos:ssh # 后台启动
6dd5df3310da5fafdfb5e8d5833ae0ccfa9dd7120dbb2b8fba71ac85f8daa7f9
[root@ali-test ~]# pipework br1 myos.ssh 192.168.1.2/24 # 设置该容器的ip
[root@ali-test ~]# ping 192.168.1.2 # 在宿主机测试ping和ssh
PING 192.168.1.2 (192.168.1.2) 56(84) bytes of data.
64 bytes from 192.168.1.2: icmp_seq=1 ttl=64 time=0.076 ms
64 bytes from 192.168.1.2: icmp_seq=2 ttl=64 time=0.048 ms
^C
--- 192.168.1.2 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.048/0.062/0.076/0.014 ms
[root@ali-test ~]# ssh 192.168.1.2
The authenticity of host '192.168.1.2 (192.168.1.2)' can't be established.
RSA key fingerprint is SHA256:m4A8kQLWvbA/a+1wdwwrrbSmEDiyCWHQZT9xNg29UBg.
RSA key fingerprint is MD5:59:60:02:77:8b:2e:8c:fe:d8:e8:5b:1b:5e:5e:d2:ec.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '192.168.1.2' (RSA) to the list of known hosts.
[email protected]'s password:
[root@6dd5df3310da ~]# 退出
以上证明一个容器启动成功,接下来可以再运行2个容器、设置好IP,那么就相当于有了3台服务器
[root@ali-test ~]# docker run -d --name=myos.ssh2 myos:ssh
87d0790f54072bc3289ae487733c0aecdebfb130a60cb939ce32a66d1440ba52
[root@ali-test ~]# docker run -d --name=myos.ssh3 myos:ssh
62eac2ea57f798066d6b21bd95d5a262cdf3a0eafe651913cd513207dc831521
[root@ali-test ~]# pipework br1 myos.ssh2 192.168.1.3/24
[root@ali-test ~]# pipework br1 myos.ssh3 192.168.1.4/24
# 测试验证
[root@ali-test ~]# ping -c 2 192.168.1.3
PING 192.168.1.3 (192.168.1.3) 56(84) bytes of data.
64 bytes from 192.168.1.3: icmp_seq=1 ttl=64 time=0.074 ms
64 bytes from 192.168.1.3: icmp_seq=2 ttl=64 time=0.050 ms
--- 192.168.1.3 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.050/0.062/0.074/0.012 ms
[root@ali-test ~]# ping -c 2 192.168.1.4
PING 192.168.1.4 (192.168.1.4) 56(84) bytes of data.
64 bytes from 192.168.1.4: icmp_seq=1 ttl=64 time=0.081 ms
64 bytes from 192.168.1.4: icmp_seq=2 ttl=64 time=0.051 ms
--- 192.168.1.4 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.051/0.066/0.081/0.015 ms
[root@ali-test ~]# ssh 192.168.1.3
The authenticity of host '192.168.1.3 (192.168.1.3)' can't be established.
RSA key fingerprint is SHA256:m4A8kQLWvbA/a+1wdwwrrbSmEDiyCWHQZT9xNg29UBg.
RSA key fingerprint is MD5:59:60:02:77:8b:2e:8c:fe:d8:e8:5b:1b:5e:5e:d2:ec.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '192.168.1.3' (RSA) to the list of known hosts.
[email protected]'s password:
[root@87d0790f5407 ~]# logout
Connection to 192.168.1.3 closed.
[root@ali-test ~]# ssh 192.168.1.4
The authenticity of host '192.168.1.4 (192.168.1.4)' can't be established.
RSA key fingerprint is SHA256:m4A8kQLWvbA/a+1wdwwrrbSmEDiyCWHQZT9xNg29UBg.
RSA key fingerprint is MD5:59:60:02:77:8b:2e:8c:fe:d8:e8:5b:1b:5e:5e:d2:ec.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '192.168.1.4' (RSA) to the list of known hosts.
[email protected]'s password:
[root@62eac2ea57f7 ~]# logout
Connection to 192.168.1.4 closed.
[root@ali-test ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
62eac2ea57f7 myos:ssh "/usr/sbin/sshd -D" 2 minutes ago Up 2 minutes 22/tcp myos.ssh3
87d0790f5407 myos:ssh "/usr/sbin/sshd -D" 2 minutes ago Up 2 minutes 22/tcp myos.ssh2
6dd5df3310da myos:ssh "/usr/sbin/sshd -D" 9 minutes ago Up 9 minutes 22/tcp myos.ssh
这样就有了3个可以SSH连接的容器,可以在上面安装和配置集群环境了
构建Hadoop镜像
上面是运行了3个centos容器,需要在每个容器中单独安装Hadoop环境,我们可以像构建SSH镜像一样,构建一个Hadoop镜像,然后运行3个Hadoop容器,这样就更简单了
# 前提环境准备:在官网下载jdk包:https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html和Hadoop包
[root@ali-test ~]# mkdir Hadoop ;cd Hadoop
[root@ali-test Hadoop]# wget wget https://mirrors.bfsu.edu.cn/apache/hadoop/common/hadoop-2.9.2/hadoop-2.9.2.tar.gz
[root@ali-test Hadoop]# ll
total 111176
-rw-r--r-- 1 root root 39119388 Nov 20 2018 hadoop-2.9.2-src.tar.gz
-rw-r--r-- 1 root root 143142634 Oct 30 15:48 jdk-8u271-linux-x64.tar.gz
[root@ali-test Hadoop]# vim Dockerfile # 编写Dockerfile
FROM myos:ssh
ADD jdk-8u271-linux-aarch64.tar.gz /usr/local
RUN mv /usr/local/jdk1.8.0_271 /usr/local/jdk1.8
ENV JAVA_HOME /usr/local/jdk1.8
ENV PATH $JAVA_HOME/bin:$PATH
ADD hadoop-2.9.2.tar.gz /usr/local
RUN mv /usr/local/hadoop /usr/local/hadoop
ENV HADOOP_HOME /usr/local/hadoop
ENV PATH $HADOOP_HOME/bin:$PATH
RUN yum -y install which sudo vim bash-completion
[root@ali-test Hadoop]# docker build -t hadoop . # 构建基于ssh的Hadoop镜像
Successfully tagged hadoop:latest
# 运行三个容器,分别给每个容器命名
[root@ali-test ~]# docker run --name hadoop0 --hostname hadoop0 -d -p 50070:50070 -p 8088:8088 hadoop # -p映射端口
298a5fdb46e3d5928f676b003345727ed98ba8e55f9f6be9d653bd8965bb53e2
[root@ali-test ~]# docker run --name hadoop1 --hostname hadoop1 -d -P hadoop # -P随机端口映射,容器内部端口随机映射到主机的端口
fa064c46a171ea6c32f318e6021d2402879c04b97d16ff0f387c02e177b0f8b1
[root@ali-test ~]# docker run --name hadoop2 --hostname hadoop2 -d -P hadoop
2c724351eb71b10297553815d8537513aab303388d47a9b5f60c518648368e8f
# 容器hadoop0启动时,映射了端口号,50070和8088,是用来在浏览器中访问hadoop WEB界面的
配置Hadoop集群
新开3个终端窗口,分别连接到 hadoop0,hadoop1,hadoop2,便于操作
[root@ali-test ~]# docker exec -it hadoop0 /bin/bash
[root@hadoop0 /]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
72: eth0@if73: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:05 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.5/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
[root@ali-test ~]# docker exec -it hadoop1 /bin/bash
[root@hadoop1 /]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
74: eth0@if75: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:06 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.6/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
[root@ali-test ~]# docker exec -it hadoop2 /bin/bash
[root@hadoop2 /]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
76: eth0@if77: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:07 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.7/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
[root@hadoop0 /]# vi /etc/hosts # 在每个容器修改/etc/hosts配置文件
172.17.0.5 hadoop0
172.17.0.6 hadoop1
172.17.0.7 hadoop2
# 配置三台主机互相免密登录
[root@hadoop0 /]# ssh-keygen # 在每台主机都执行该操作
[root@hadoop0 /]# for i in hadoop{0..2}; do ssh-copy-id root@$i; done # 将公钥传给包括自己的每台主机,三个容器都要做!!!确保最终每台主机都能免密访问其他主机包括自己
安装配置Hadoop
以上,准备环节结束,接下来开始正片内容,不要走开,马上回来!
# 进入容器,修改配置文件
[root@hadoop0 /]# cd /usr/local/hadoop/
[root@hadoop0 hadoop]# ls
LICENSE.txt NOTICE.txt README.txt bin etc include lib libexec sbin share
[root@hadoop0 hadoop]# mkdir tmp hdfs
[root@hadoop0 hadoop]# mkdir hdfs/data hdfs/name
# 修改配置文件
[root@hadoop0 hadoop]# vim etc/hadoop/core-site.xml
在 <configuration> 块儿中添加:
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop0:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
[root@hadoop0 hadoop]# vim etc/hadoop/hdfs-site.xml
在 <configuration> 块儿中添加:
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop0:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
[root@hadoop0 hadoop]# cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
[root@hadoop0 hadoop]# vim etc/hadoop/mapred-site.xml
在 <configuration> 块儿中添加:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop0:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop0:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop0:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop0:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop0:8088</value>
</property>
[root@hadoop0 hadoop]# vim etc/hadoop/slaves
删除已有内容,添加:
hadoop1
hadoop2
[root@hadoop0 hadoop]# vim etc/hadoop/hadoop-env.sh
找到 export JAVA_HOME=${JAVA_HOME},改为自己JAVA_HOME的绝对路径
export JAVA_HOME=/usr/local/jdk1.8
# 复制 hadoop目录 到hadoop1,hadoop2
[root@hadoop0 ~]# scp -r /usr/local/hadoop root@hadoop1:/usr/local/hadoop
[root@hadoop0 ~]# scp -r /usr/local/hadoop root@hadoop2:/usr/local/hadoop
启动 hadoop
在master启动hadoop,从节点会自动启动
初始化
[root@hadoop0 ~]# hdfs namenode -format
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop0/172.17.0.5
************************************************************/
启动
[root@hadoop0 ~]# cd /usr/local/hadoop/sbin/
[root@hadoop0 sbin]# ./hadoop-daemon.sh start namenode
[root@hadoop0 sbin]# ./hadoop-daemon.sh start datanode
[root@hadoop0 sbin]# ./start-dfs.sh
[root@hadoop0 sbin]# ./start-yarn.sh
[root@hadoop0 sbin]# ./mr-jobhistory-daemon.sh start historyserver
测试
# 在三台主机分别查看状态
[root@hadoop0 ~]# jps
418 DataNode
324 NameNode
1685 JobHistoryServer
1397 ResourceManager
1150 SecondaryNameNode
1758 Jps
[root@hadoop1 ~]# jps
550 Jps
312 DataNode
427 NodeManager
[root@hadoop2 ~]# jps
548 Jps
310 DataNode
425 NodeManager
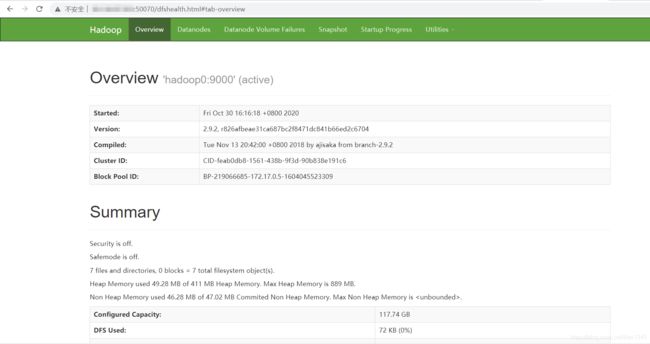
浏览器中访问:
http://ip:50070/
ps:在启动docker容器的时候已经设置了本机和容器的映射,所以此时只需要在云主机当中设置安全组放开并进行访问即可
http://ip:8088/
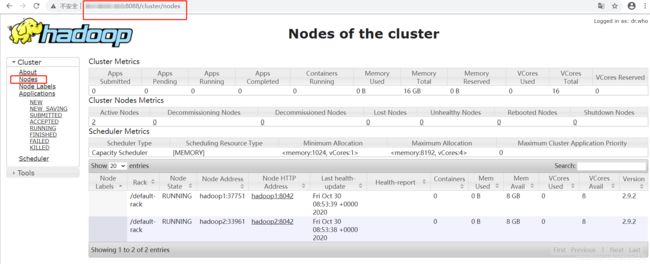
可以正常访问的话,可以说明集群启动成功了,但不一定可以正常运行,还需要下面的实际验证
验证
- (1)hdfs 操作
创建目录
[root@hadoop0 ~]# hdfs dfs -mkdir -p /hadoop/input
上传文件,把现有的一些配置文件上传到刚刚创建的目录中
[root@hadoop0 ~]# vim test.txt
hi,wo shi xiaotian
[root@hadoop0 ~]# hdfs dfs -put /usr/local/hadoop/etc/hadoop/kms*.xml /hadoop/input
[root@hadoop0 ~]# hdfs dfs -put test.txt /hadoop/input
如果没有返回错误信息,说明操作成功
访问 http://master ip:50070/,在文件浏览页面查看
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I0DqT8Kh-1604558200656)(C:\Users\tian\AppData\Roaming\Typora\typora-user-images\image-20201030163830933.png)]
- (2)mapreduce 操作
hadoop 安装包中提供了一个示例程序,我们可以使用它对刚刚上传的文件进行测试
[root@hadoop0 ~]# hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar grep /hadoop/input /hadoop/output 'dfs[a-z.]+'
![]()
在浏览器中进行验证


注:在执行过程中,如果长时间处于 running 状态不动,虽然没有报错,但实际上是出错了,后台在不断重试,需要到 logs 目录下查看日志文件中的错误信息