使用Java快速开发一个新闻爬虫项目
一、项目简介
其实使用Java开发一个爬虫项目并没有想象中那么难,流行的SpringBoot快速构建项目,还有现成的WebMagic之类的爬虫框架,实现简单的新闻爬虫项目还是很容易的。
由于想要做一些热点分析的项目,写了个新闻爬虫项目。由于我需要的是历史的新闻数据,对实时性要求不高,所以每30分钟爬取一次新闻数据,并将数据保存在MongoDB中。
目前支持爬取的新闻网站:
- 腾讯新闻
- 凤凰资讯
项目代码:https://github.com/Laichj/box-spider (随手给星的都是长得帅的)
二、Web Magic爬虫框架
本项目引用了WebMagic框架,这里就不多唠叨,想要了解的可以看一下官方文档
WebMagic文档:http://webmagic.io/
三、项目使用
如果只想直接使用现成项目代码将项目跑起来,以达到爬取数据的目的,可以直接执行以下步骤:
1、项目导入
本项目使用maven管理项目,将项目代码下载下来之后,使用导入maven项目的方式导入到idea中,导入pom.xml中的依赖即可
2、MongoDB配置
启动项目之前,需要在 application.yml 配置文件中配置有效的MongoDB数据库
3、启动SpringBoot项目
执行 com.aposs.box.spider.BoxSpiderApplication 类中的main方法,即可启动项目
四、项目代码
使用springBoot开发项目的好处就是搭建框架的时候就像拼积木一样,将自己想要的东西都放在一起就好了。
关于项目代码及开发过程,简要梳理一下,具体的文件路径参考如下:

1、新增maven项目,并导入以下依赖
pom.xml
4.0.0
org.springframework.boot
spring-boot-starter-parent
2.1.3.RELEASE
com.aposs.box
box-spider
1.0-SNAPSHOT
1.8
0.7.3
2.1.3.RELEASE
3.12.7
us.codecraft
webmagic-core
${webmagic.version}
org.slf4j
slf4j-api
org.slf4j
slf4j-log4j12
us.codecraft
webmagic-extension
${webmagic.version}
org.springframework.boot
spring-boot-starter-test
test
org.springframework.boot
spring-boot-starter-data-mongodb
${spring.boot.version}
org.mongodb
mongo-java-driver
${mongodb.version}
aliyun-central
http://maven.aliyun.com/nexus/content/groups/public/
aliyun maven
maven-central
http://repo1.maven.org/maven2/
maven
aliyun-repos
aliyun Repository
http://maven.aliyun.com/nexus/content/groups/public
maven-central
http://repo1.maven.org/maven2/
maven
org.springframework.boot
spring-boot-maven-plugin
2、日志配置
日志模块使用springBoot自带的logback,配置每天自动生成一个日志文件
logback-spring.xml
%date{yyyy-MM-dd HH:mm:ss.SSS} %-5level [${modname} => %thread] %logger - %msg%n
${pathroot}/${filename}.log
${pathroot}/${filename}.%d{yyyy-MM-dd}.log
${log_format_general}
UTF-8
3、项目属性配置
必须修改的是MongoDB数据库配置,必须配置有效的数据库。定时任务执行间隔等参数,根据具体需求调整即可。
application.yml
spring:
application:
name: box-spider
profiles:
active: dev
# 配置存储数据的mongoDB数据库连接,需要配置有效的MongoDB数据库
data:
mongodb:
username: box
host: 127.0.0.1
port: 27017
password: 123456
database: box
# 每30分钟抓取腾讯新闻150条记录
box:
spider:
# 腾讯新闻 深圳新闻
tencentNews:
url: https://i.news.qq.com/trpc.qqnews_web.kv_srv.kv_srv_http_proxy/list?sub_srv_id=gd&srv_id=pc&offset=0&limit=
limit: 150
collectionName: tencentNewsJson
# 网易新闻 深圳
163News:
url: https://bendi.news.163.com/guangdong/special/04178NDR/news_sz.js
collectionName: 163NewsJson
# 凤凰新闻 资讯
ifengNews:
url: https://shankapi.ifeng.com/shanklist/_/getColumnInfo/_/dynamicFragment/6737905981943976661/
limit: 100
collectionName: ifengNewsJson
# 定时任务
cron: 0 */30 * * * ?
4、业务代码
程序入口:
虽然项目入口为com.aposs.box.spider.BoxSpiderApplication的main方法,但是业务逻辑的入口是com.aposs.box.spider.BoxSpiderRunner
BoxSpiderRunner实现了ApplicationRunner的run方法,在SpringBoot项目启动完成之后会立刻执行run()方法,然后根据Scheduled配置定时执行schedule()方法
爬虫逻辑:
com.aposs.box.spider.service:定义爬虫任务执行入口
com.aposs.box.spider.processor:定义爬虫程序页面解析逻辑
com.aposs.box.spider.pipeline:定义爬虫获取到的数据管道(数据存储逻辑)
数据库:
com.aposs.box.spider.dao:封装数据库操作
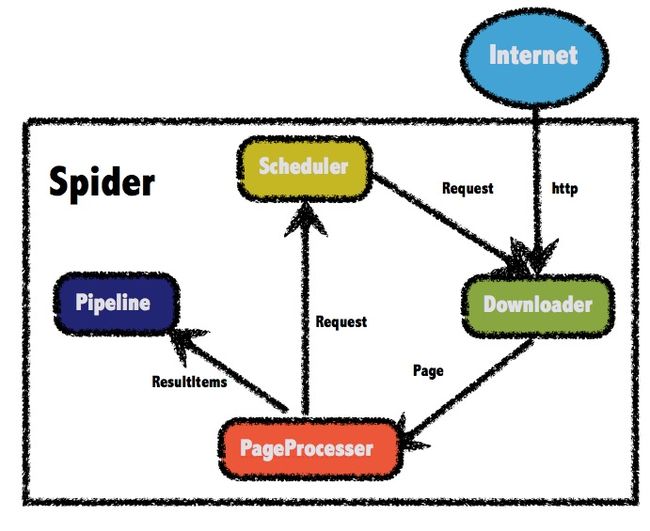
总结:
回顾了简单的爬虫项目开发,发现这张图是精髓。爬虫框架其实无非这几个模块,这个项目主要实现的逻辑包含Scheduler、PageProcesser、Pipeline这几个模块,不过在更复杂的爬虫项目中,Downloader模块也相当重要。这个项目只是作为Java程序员开发爬虫项目的一个入门尝试项目,爬虫开发还经常会涉及到很多反爬门槛,也是一项面向监狱编程。后续如有契机继续爬虫相关开发,再继续分享心得吧。