OSI七层网络协议及TCP/UDP、C/S架构详解
OSI七层网络协议及TCP/UDP、C/S架构详解
- 一、OSI七层网络、Linux四层网络模型
-
- 1、为什么需要网络通信
- 2、通讯设备有哪些
- 3、什么是通信协议?作用是什么?
- 二、OSI七层协议
-
- 1、物理层
- 2、数据链路层
- 3、网络层
- 4、传输层
-
- A)TCP协议
- 1)三次握手
- 2)四次挥手
- 3)粘包与拆包:
- B)UDP
- c)TCP VS UDP
- 5、会话层
- 6、表示层
- 7、应用层
- 二、C/S架构
一、OSI七层网络、Linux四层网络模型
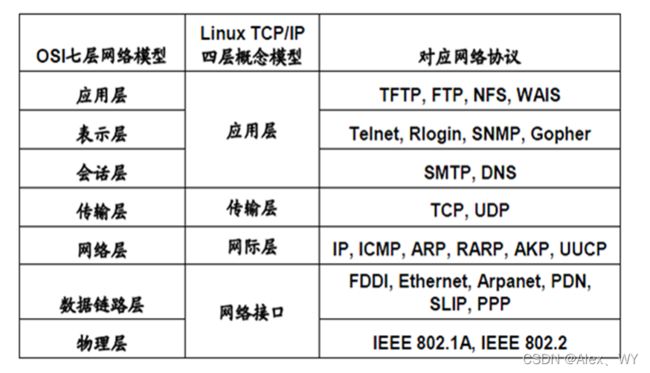
1、为什么需要网络通信
进程间通讯解决的是本机内的通讯,而网络通信解决的是任意不同机器间的通讯
2、通讯设备有哪些
网卡:PC机自带
路由器,交换机
光纤、电缆、基站
3、什么是通信协议?作用是什么?
通信协议是指双方实体完成通信或者服务所必须遵循的规则和约定。协议定义了 数据单元使用的格式,信息单元该包含的信息和含义,连接方式,信息发送和接收的时序,从而确保网络中数据顺利地传输到正确的地方。
作用是什么:在计算机通信中,通讯协议用于实现计算机与网络连接之间的标准,网络如果没有统一的通讯协议,电脑之间的信息传递就无法识别。
二、OSI七层协议
1、物理层
字面意思就是:物理传输、硬件、物理特性。在不同地方的人使用qq聊天,电脑必须得联网吧。那么在物理上就是要接根网线,再插个路由器。也就是说计算机与计算机之间的通讯,必须要有底层物理层方面的连接,类似于打电话,中间要插电话线一样。
物理层需要将通信介质的信号转换到数字信号(二进制0101)。然而如何使这些二进制位有具体意思呢?这就需要人为的分组,8位一组,发送及接收都按照8位一组来划分。如果没有分组的话,对方接收的计算机根本就不知道传过来的数据从哪位开始计算,那就解析不了这些数据了。因此要想让底层的数字信号有意义,那就必须将其分组。那么分组的活,哪层干呢?这时候就用到了数据链路层!
2、数据链路层
很早之前,数据链路层就是用来对数字信号进行分组的。以前每个公司都有自己的分组方式,非常的乱。后来就形成了统一的标准(标准就是协议),也就是以太网协议Ethernet。
以太网协议规定:
一组数字信号称之为一个数据包,或者叫做一“帧”。
每一个数据包包含两部分:head报头、data数据两部分。
其中head包含:发送者(源地址,6个字节)、接收者(目标地址,6个字节)、数据类型(6个字节)。所以head报头固定是18个字节。
data包含:数据包的具体内容(最短46字节,最长1500字节)
head长度+data长度=最短64字节,最长1518字节,超过最大长度就分片发送。
在计算机通信中源地址和目标地址都是指的是mac地址。
Mac地址的由来:
以太网协议规定接入互联网的设备都必须具备网卡,发送端和接收端的地址便是指网卡地址,即Mac地址。
每块网卡出厂时都被烧录上一个实际上唯一的Mac地址,长度是48位2进制,通常由12位16进制数表示。有了mac地址以后,计算机就可以通信了。
交换机:
交换机是一种用于电(光)信号转发的网络设备。它可以为接入交换机的任意两个网络节点提供独享的电信号通路
交换机工作原理:
交换机根据收到数据帧中的源MAC地址建立该地址同交换机端口的映射,并将其写入MAC地址表中
交换机将数据帧中的目的MAC地址同已建立的MAC地址表进行比较,以决定由哪个端口进行转发
如数据帧中的目的MAC地址不在MAC地址表中,则向所有端口转发。这一过程称为泛洪(flood)
数据链路层将我的mac地址和接收者mac地址以及我发送的内容包装成一个数据包之后就往外发,到物理层以后就全部转换成二进制,那么怎么往外发呢?广播!计算机底层,只要在一个局域网中,都是靠广播。
什么是互联网,互联网就是由一个个局域网组成。局域网内计算机不管是对内还是对外都是靠广播,这就是数据链路层的工作方式——广播!
广播出去以后,所有计算机都能接收到,所有计算机都会拆开这个包,读发送者是谁,只要接收者mac地址不是自己就丢弃掉,而目标计算机接收到,就会将我需要的信息发送回来,同样采用的是广播方式。
然而当不在同一个局域网中时,如何通信呢?这就是跨网络进行通信,数据链路层就解决不了这个问题了。这时候就需要网络层出手了!
3、网络层
网络层定义了一个IP协议
IP地址,路由器(通过公网ip来访问全世界)
IP地址:实际上是32位二进制数(01100100.00000100.00000101.00000110)100.4.5.6
公网IP(广域网通信):
a类:1.0.0.1~126.255.255.254
** b类:128.0.0.1~191.255.255.254**
** c类:192.0.0.1~223.255.255.254**
d类:224.0.0.1~239.255.255.254
** e类:240.0.0.1~255.255.255.254**
A:10.0.0.0~10.255.255.255
** B:172.16.0.0~172.31.255.255**
** C:192.168.0.0~192.168.255.255**
4、传输层
传输层的由来:网络层的ip帮我们区分子网,以太网层的mac帮我们找到主机,然后大家使用的都是应用程序,你的电脑上可能同时开启qq,微信,等多个应用程序
那么我们通过ip和mac找到了一台特定的主机,如何标识这台主机上的应用程序,答案就是端口,端口即应用程序与网卡关联的编号。
传输层功能:建立端口到端口的通信
补充:端口范围0-65535,0-1023为系统占用端口
A)TCP协议
TCP协议(传输控制协议):
特点:面向链接、可靠的字节流传输
字节流传输:优点:无需一次存储过大的数据占用太多内存。缺点:坏处就是无法知道这些字节代表的意义,导致粘包及拆包的问题
TCP的可靠传输:
停止等待协议:A给B发包,B回复收到,A继续发下一个包。每次发送都可能丢包,如果丢失,B永远无法回复A,A一直等待。
超时重传:
A发出包开始计时,若时间到未收到回复,则认为包丢失,再次发送、重传。若包没有丢失,等待时间较长。B会收到两个包,无法识别。
序号和确认号:
表示发送方数据第一个字节的编号,和接收方期待的下一份数据的第一个字节的编号
连续ARQ协议:
为什么要有连续ARQ协议:
停止等待满足可靠传输,但效率太低,等待过程中浪费资源
解决方法:
连续发送数据包,A源源不断的发送,B源源不断的接收,并逐一回复,累计确认:累积收到一定数量,回去之前的包全部收到。如果有包A未收到回复,那么重传
缺点:发送太快导致接收方无法接受,便频繁进行重传,浪费网络资源
如何处理丢包问题
选择确认SACK:在TCP报文的选项字段,可以设置已收到的报文段,每个报文段需要两个边界来进行确定
滑动窗口:
发送方需要根据接收方的缓冲区大小,设置自己的可发送的窗口大小,处于窗口内的数据表示可发送,之外的数据不可发送。
当窗口内的数据接收到确认回复时,整个窗口会往前移动,直到发送完成所有的数据当窗口内的数据接收到确认回复时,整个窗口会往前移动,直到发送完成所有的数据
可靠传输小结:
通过连续ARQ协议与发送-确认回复模式来保证每一个数据包都能到达接收方
通过给字节编号的方法来标记每个数据是属于重传还是新的数据
通过超时重传的方式来解决数据包在网络中丢失的问题
通过滑动窗口来实现流量控制
通过累计确认 + 选择确认的方法来提高确认回复与重传的效率
拥塞控制:
作用:避免网络过分拥挤导致丢包严重,网络效率降低
拥塞控制 VS 流量控制
流量控制是拥塞控制的手段:为了避免阻塞,必须对流量进程控制
拥塞控制的目的是:限制每个主机的发送的数据量,避免网络拥塞效率下降
解决方法:
拥塞控制的解决方法是流量控制,流量控制的实现是滑动窗口
拥塞控制最终于是通过限制发送方的滑动窗口大小来限制流量
拥塞控制的4个重点:慢开始、快恢复、快重传、拥塞避免
解决原理:
最开始的时候,会把窗口设置一个较小的值,然后每轮变为原来的两倍。这是慢开始
当窗口值到达ssthresh值,这个值是需要通过实时网络情况设置的一个窗口限制值,开始进入拥塞避免,每轮把窗口值提升1,慢慢试探网络的底线
如果发生了数据超时,表示极可能发生了拥塞,然后回到慢开始,重复上面的步骤
如果收到三个相同的确认回复,表示现在网络的情况不太好,把ssthresh的值设置为原来的一半,继续拥塞避免。这部分称为快恢复
如果收到丢包信息,应该尽快把丢失的包重传一次,这是快重传
面向链接:
链接:
链接不是实实在在的链接,而是通信双发彼此之间的一个记录
TCP是一个全双工通信,也就是可以互相发送数据,所以双发都需要记录对方的信息(源IP、源端口号、目标端口号)
1)三次握手
建立链接:
目的:交换彼此的信息,然后记住对方的信息
三次握手:
机器A发送syn包,向机器B请求建立TCP链接,并附加上自身的接收缓冲区信息等,机器A进入SYN_SEND状态,表示请求已经发送正在等待回复
机械B收到请求之后,根据机器A的信息记录下来,并创建自身的接收缓存区,向机械A发送syn + ack的合成包,同时自身进入SYN_RECV状态,表示已经准备好了
机器A收到回复之后记录机器B的信息,发送ack信息,自身进入ESTABLISHED状态,,表示已经完全准备好了,可以进行发送和接收
机器B收到ACK数据后,进入ESTABLISHED状态
三次消息的发送,称之为三次握手
拒绝服务攻击(DOS):
通过各种技术手段导致目标系统进入拒绝服务状态的攻击。
分布式拒绝服务攻击:
利用合理的请求曹成资源过载,导致服务不可用,从而曹正服务器拒绝正常流量服务。
SYN_Flood攻击:
就是让客户端不返回最后的ACK包,这就形成了半开连接,TCP半开连接是指发送或者接受了TCP连接请求,等待对方应答的状态,半开连接状态需要占用系统资源以等待对方应答,半开连接数达到上限,无法建立新的连接,从而造成拒绝服务攻击。
2)四次挥手
断开链接:
四次挥手:
机器A发送完数据之后,向机械B请求断开链接,自身进入FIN_WAIT_1状态,表示数据发送完成且已经发送FIN包(FIN标志位为1)
机械B收到FIN包之后,回复ack包,表示已经收到,但此时,机械B可能还有数据没发送完成,自身进入CLOSE_WAIT状态,表示对方已发送完成且请求关闭链接,自身发送完成之后可以关闭链接
机械B发送完数据后,发送FIN包给机器A,自身进入LAST_ACK状态,表示等待一个ACK包即可关闭链接
机器A收到FIN包之后,知道机器B也发送完成了,回复一个ACK包。并进入TIME_WAIT状态
机器A等待两个报文存货最大时长之后,机器B接收到ACK报文之后,均关闭链接,进入CLASED状态
TIME_WAIT状态:
当机器A收到机器B的FIN包时,理想状态下,确实是可以直接关闭链接了
问题1:当网络不稳定时,可能机器B放了一些数据还没到(比FIN包慢)
问题2:同时回复的ACK包可能丢失,机械B会重传FIN包
问题3:此时机械A马上关闭链接,导致数据不完整、机械B无法释放链接等问题|机器A收到FIN包之后,知道机器B也发送完成了,回复一个ACK包。并进入TIME_WAIT状态
解决方法:此时机器A需要等待两个报文生存最大时长,确保网络中没有任何遗留报文了,再关闭链接
3)粘包与拆包:
应用层需要向母校进程发送两份数据,一份音频,一份文本
TCP只知道接受到一个流,并把流拆分成4段进行发送
中间第二个报文的数据就出现两个文件的数据混在一起,称为粘包
目标进用层在接收到数据之后,需要把这些数据拆分成正确的两个文件,就是拆包
粘包与拆包都是应用层需要解决的问题,可以再每个文件的最后附加上一些特殊字符,如换行符
B)UDP
UDP协议(用户数据报协议):
无连接无可靠传输:
UDP传送数据前并不与对方建立链接,对接受的数据也不发送确认信号,发送端不知道数据是否会正确接受,不需要重发
UDP中的每个数据包都是一个独立的信息,包括完成的源或目的地址,他在网络上以任何可能的路径传目的地,对于能否达到目的地,达到目的地的时间以及内容的正确性都是不能被保证的
因为UDP不必进行收发数据的确认,而且资源消耗小,处理速度快,所以他的实时性更好,传送速率更高。
UDP的报文格式:
源端口、目标端口号:区分主机的不同进程
校验码:校验数据包在传输的过程中没有出现错误,例如某个1变成0
长度:报文的长度
UDP的功能:校验数据报是否发生错误,区分不同的进程通信
优点:
效率更快,无需建立链接以及拥塞状态
链接更多的用户,没有链接状态,不用为每个客户创建缓存等
分组首部字节少,开销小,TCP首部固定首部是20字节,而UDP只有8字节,更小的首部意味着更大比例的数据部分
在一些需要高效率允许的可限度误差的场景下可以使用,如直播场景
可以进行广播,UDP不是面向链接的,所以可以同时对多个进程进行发送报文。
缺点:
无法保证消息完整、正确到达,UDP是不可靠的传输协议
缺少拥塞控制,容易互相竞争资源,导致网络系统瘫痪
UDP适用场景:
视频直播、DNS、RIP路由选择协议
c)TCP VS UDP
链接方式:TCP是面向链接,而UDP是无连接
可靠性:
TCP是可靠传输,适用流量控制和拥塞控制
UDP是不可靠传输,不适用流量控制和拥塞控制
链接对象的数量:
TCP只能是一对一通信
UDP支持一对一,一对多,多对一和多对多交互通信
传输方式:TCP是面向字节流,UDP是面向报文
首部开销:TCP首部最小20字节,最大60字节,UDP首部开销小,仅8字节
适用场景:
TCP适用于要求可靠传输的应用,例如文件传输
UDP适用于实时应用(IP电话、视频会议、直播等)
5、会话层
控制发包的数据
6、表示层
文件格式
7、应用层
会话层、表示层、应用层在Linux中合为应用层
应用层
DNS(Domain Name System:域名系统):
作用:解决IP地址复杂难以记忆的问题,存储并完成自己所管辖范围内主机的域名到IP地址的映射
域名解析的顺序:浏览器缓存,找本机的hosts文件,路由缓存,找DNS服务器(本地域名、顶级域名、根域名)->迭代解析、递归查询
域名由点、字母和数字组成:
顶级域(com,cn,net,gov,org)
二级域(baidu,taobao,qq,alibaba)
三级域(www)
二、C/S架构
优点:
用于客户端实现与服务器的直接相连,没有中间环节,因此影响速度快
操作界面漂亮、形式多样,可以充分满足客户自身的个性化要求
C/S结构的管理系统具有较强的事务处理能力,能实现复杂的业务流程
缺点:
需要专门的客户端安装程序,分布功能弱,针对点多面广且不具备网络条件的用户群体,不能够实现快速部署安装和配置。
兼容性差,对于不同的开发工具,具有较大的局限性。若采用不同工具,需要重新改写程序
开发成本较高,需要具有一定专业水准的技术人员才能完成