瑞吉外卖——SpringBoot + MybatisPlus项目笔记(持续更新)
本文必看:
阅读提醒:最重要的内容都是我手打的字、截图上的红字备注部分,代码一定要看,有注释的代码更要看,因为可以加深理解,里面有思路复现,并且学习时请把项目代码放在旁边以便进行对照,带※的是自己感觉比较复杂的内容。
如果需要完成此次项目,则需要会前端知识,看得懂前端三剑客以及Vue的代码,后端默认都会,会使用浏览器f12的network来查看请求路径,请求参数,要发送的数据等等,同时也需要具备用idea调试代码的能力
目录
- 本文必看:
- 开发小技巧
- 业务开发:
-
- 登录、退出功能
- 员工管理的业务开发
-
- 新增员工
- 员工信息分页查询
- 2023.2.3
-
-
- 启用禁用员工账号
- 编辑员工信息:
- 菜品分类管理的业务开发
-
- 公共字段填充
- 新增分类
- 分类信息分页查询
-
- 训练中的不足
- 2023.2.4
-
-
- 删除分类业务
- ※小记:
- 修改分类业务:
- 菜品管理的业务开发
-
- 文件上传
- 文件下载
- ※新增菜品
-
- 2023.2.5
- 2023.2.6
-
-
- ※菜品信息分页查询
- 修改菜品
- 套餐管理的业务开发
-
- 新增套餐
- ※套餐信息分页查询
-
- 2023.2.7
-
-
- 删除套餐
- 手机验证码登录
-
- 短信发送
- 手机验证码登录
- 前端页面
-
- 导入用户地址簿相关代码
- 菜品展示
- 购物车
-
- 2023.2.8
-
-
- 用户下单
-
- Git
- Linux
-
- jdk
- Tomcat
- MySQL
- 项目部署
-
- 手动
- 自动
- Redis
- 补充知识(小细节)






nginx是一个服务器,主要部署一些静态的资源,包括后面做tomcat的集群, 可以接收前端的请求,然后分发给各个tomcat

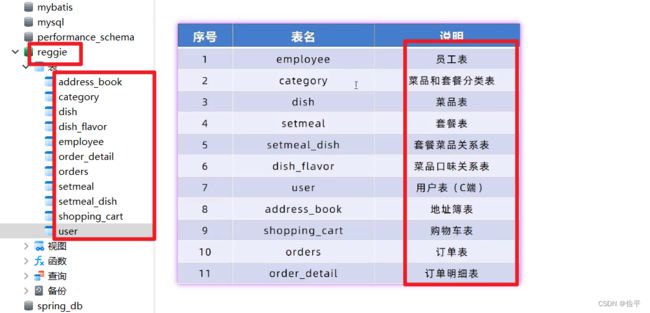
第一步搭建数据库:


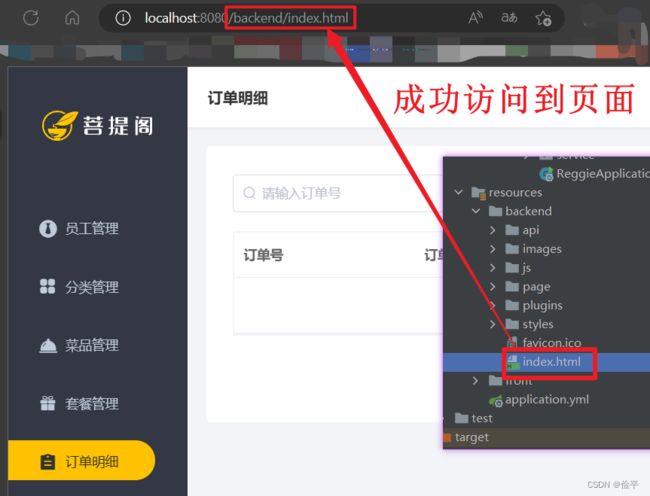
通过url访问页面,可以访问到静态资源页面,也可以访问到controller页面,但是静态资源页面是不能接受后端的数据的,所以会用到jsp页面,或者用Vue来返回数据。
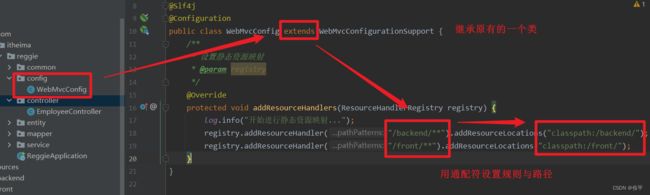
开发小技巧
写业务需求的时,先考虑前端传来的数据是什么,数据格式是什么,我要返回的值是什么,请求的url是什么?等等想清楚这些问题之后先不着急写业务代码,而是接受前端数据并进行log打印,打断点调试一下,看看能不能接收到前端数据,再开始辨析业务需求。
要想操作数据库则一定要调用xxxService
业务开发:
登录、退出功能
分三步走:

在登录界面上,输入用户名和密码,点击登录按钮就会发送请求,最终这个请求就会请求到服务端的一些组件,比如说先请求到我们的controller,然后通过controller调我们的service,然后通过service调mapper,最终和数据库交互,根据用户名和密码进行查询。
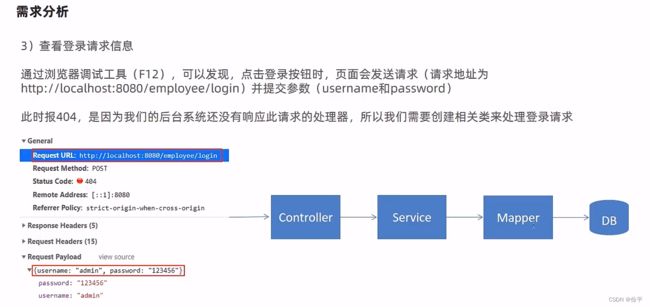
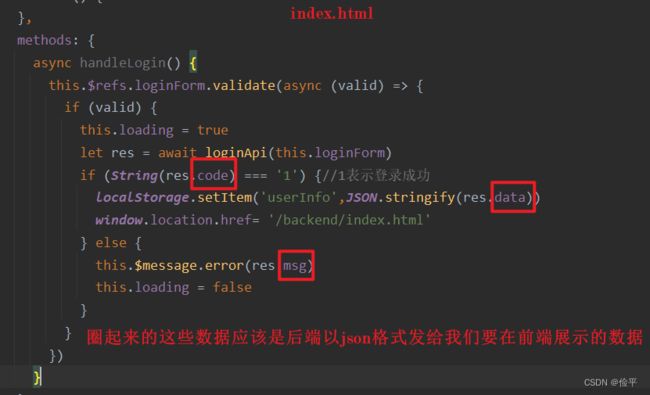


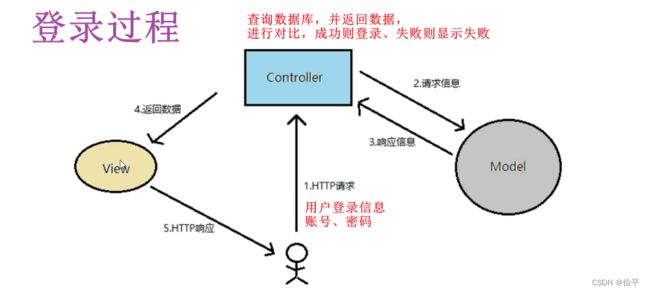
controller对请求进行处理会返回数据,这些数据需要用一个类来封装,相当一个通用结果类,服务端响应的所有结果最终都会包装为此类型返回给前端页面,我们将此类定义为R,并将其放在common包下。

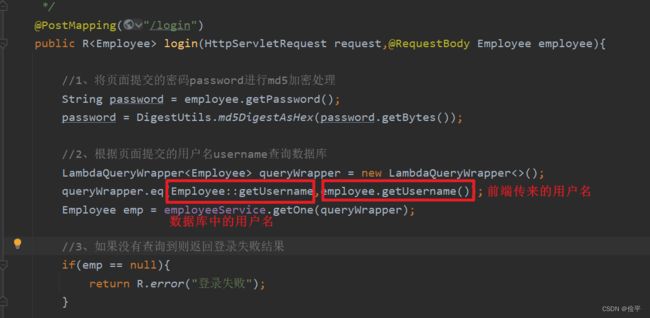
//2、根据页面提交的用户名username查询数据库
LambdaQueryWrapper<Employee> queryWrapper = new LambdaQueryWrapper<>(); //查询包装类
queryWrapper.eq(Employee::getUsername,employee.getUsername()); //比较是否一致
Employee emp = employeeService.getOne(queryWrapper); //username是唯一约束,是不能重复的,所以可以调用getOne方法
//将此用户名的对象赋值给emp
//4、密码比对,如果不一致则返回登录失败结果
if(!emp.getPassword().equals(password)){ //判断数据库中的密码和前端传来的密码password 是否一致
return R.error("登录失败");
}
调试要打断点再调试,然后一步一步往下走,看数据的变化。
如果改了后端的配置文件信息,前端没有生效,原因是浏览器中有缓存,所以需要清理一下历史记录(cookie),再刷新就ok
账号退出的需求:

/**
* 员工退出
* @param request
* @return
*/
@PostMapping("/logout")
public R logout(HttpServletRequest request){
//清理Session中保存的当前登录员工的id
request.getSession().removeAttribute("employee");
return R.success("退出成功");
}
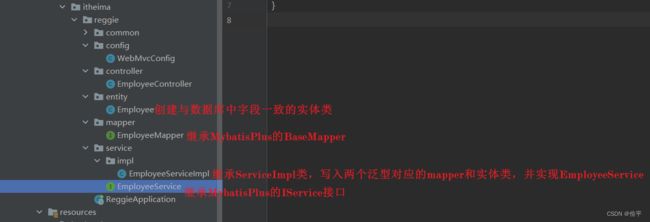
员工管理的业务开发



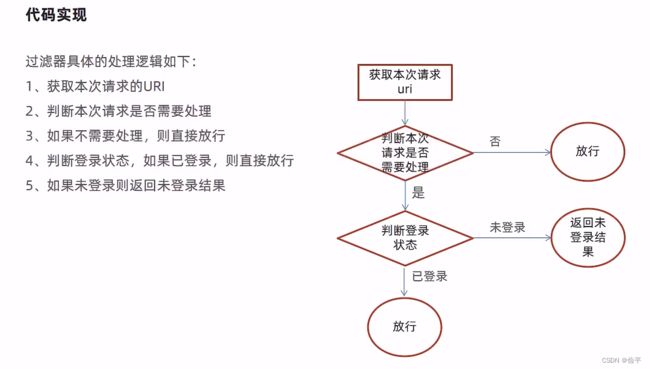
先完成整个架子,再去填充过滤器的细节。
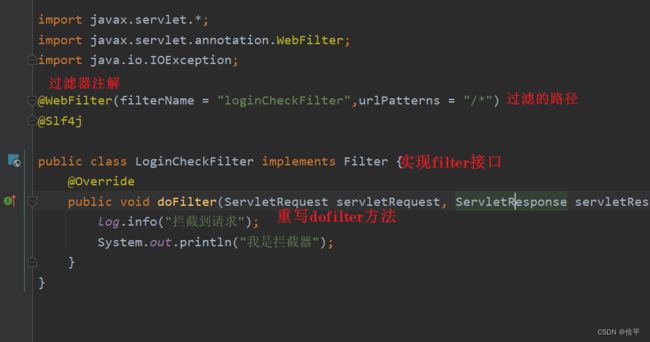
使用参数servletRequest,将其强转为HttpServletRequest,然后调用request.getRequestURL()方法
接下来放行,如何放行?用参数 filterChain调用doFilter( , )方法,将request和response放进去,如:
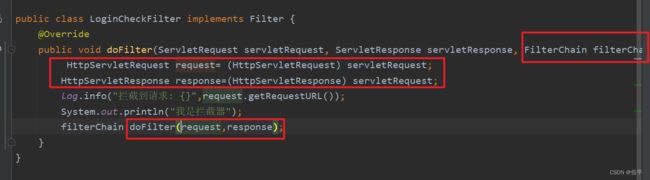
再进行访问页面,发现控制台和日志有输出,证明我们的过滤器架子搭好了:

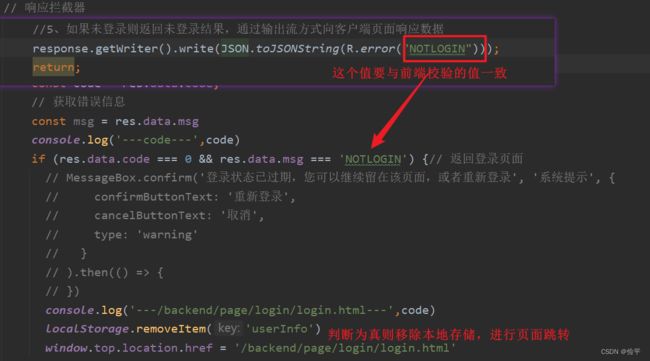
用Session判断登录状态,用AntPathMatcher类的match方法进行地址匹配,
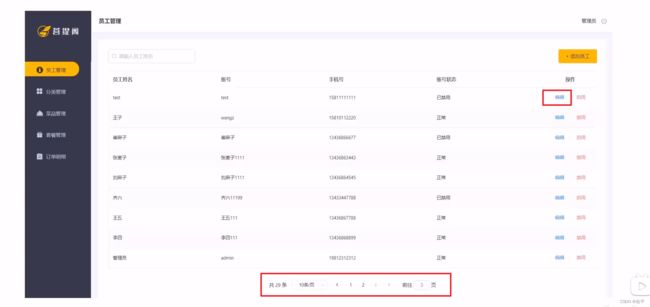
这一章是针对员工实体进行一系列的操作,是带分页的,所以会有分页查询的功能,而且点击编辑可以对员工的信息进行修改,还有账号的启用和禁用,点击添加员工可以跳转页面,并进行信息填写
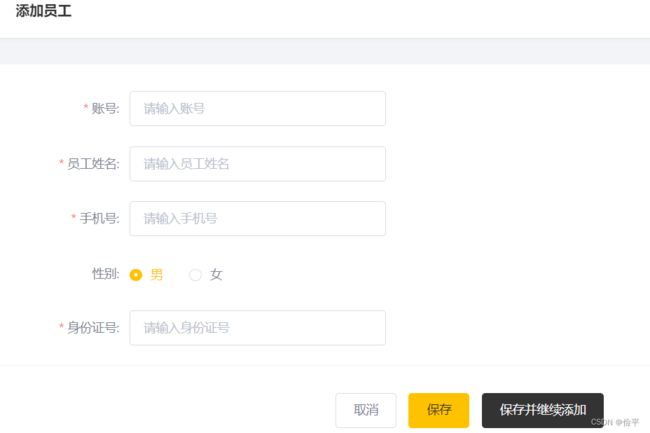
新增员工
业务开发中,需求分析和数据模型是最关键的一块,往后的代码开发和功能测试就是对需求分析一一翻译的过程。
点击新增员工,页面跳转到一个表单,输入信息,点击保存,前端页面发送ajax请求,将数据以json的方式传给controller,它再调用Service将数据进行保存,Service调用Mapper进行查询数据库,看username是否重复,因为username字段设置的唯一,不重复则将数据插入到数据库中,再跳转到员工管理。
/**
* 新增员工
* @param employee
* @return
*/
@PostMapping()
public R<String> save(HttpServletRequest request,@RequestBody Employee employee){ //这个返回值是返回给前端
log.info("员工信息:{}",employee.toString());
employee.setPassword(DigestUtils.md5DigestAsHex("123456".getBytes()));
//获取当前时间
employee.setCreateTime(LocalDateTime.now());
employee.setUpdateTime(LocalDateTime.now());
//获得当前用户的id(用session获得
long empId = (long) request.getSession().getAttribute("employee");
employee.setCreateUser(empId);
employee.setUpdateUser(empId);
employeeService.save(employee);
return R.success("新增员工成功");
}
因为数据库当中的username设置的是唯一,所以当我们输入重复的username时,会抛异常,两种处理方法
手动捕获和使用异常处理器进行全局异常捕获。
推荐使用异常处理器(Handler),如果做?
创建一个异常处理器类,在上面打上@ControllerAdvice注解,advice是通知的意思,然后在自定义的方法上打上@ExceptionHandler(SQLIntegrityConstraintViolationException.class),括号内填入捕捉异常的类型,代码如下:
@ControllerAdvice(annotations = {RestController.class, Controller.class})
@ResponseBody
@Slf4j
public class GlobalExceptionHandler {
/**
* 异常处理方法
* @return
*/
@ExceptionHandler(SQLIntegrityConstraintViolationException.class)
public R<String> exceptionHandler(SQLIntegrityConstraintViolationException ex){
log.error(ex.getMessage());
if(ex.getMessage().contains("Duplicate entry")){
String[] split = ex.getMessage().split(" ");
String msg = split[2] + "已存在";
return R.error(msg);
}
return R.error("未知错误");
}
}
下次再输入重复的username就可以捕获异常,并在前端输出“***已存在”
员工信息分页查询
展现员工信息的时候,全部展示出来会很乱,所以一般采用分页的方式来展示数据
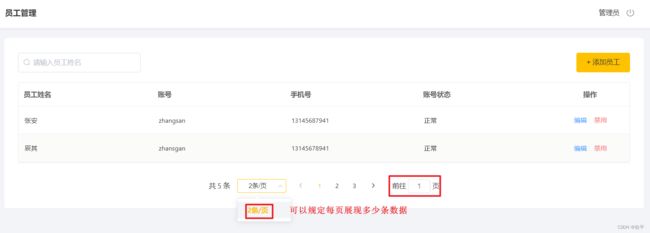
第一步配置MP的分页插件
/**
* 配置MP的分页插件
*/
@Configuration
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor(){
MybatisPlusInterceptor mybatisPlusInterceptor = new MybatisPlusInterceptor();
mybatisPlusInterceptor.addInnerInterceptor(new PaginationInnerInterceptor());
return mybatisPlusInterceptor;
}
}
controller方法返回值的核心的,前端页面需要什么数据我们就给他什么数据。
然后在页面上的按姓名查询会在url中拼接name,所以参数一共三个。
构造分页条件,我们只需要告诉MP我们的page和pageSize是多少就可以了,他会帮我们做分页查询
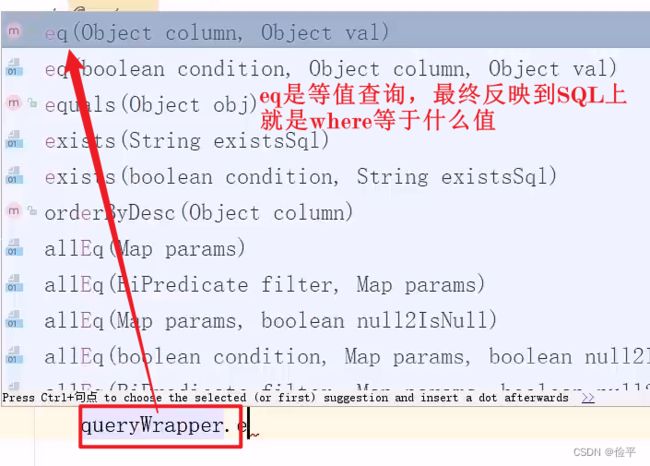
这里我们推荐使用like,对于姓名推荐使用like
2023.2.3
最终的代码:
@GetMapping("/page")
public R<Page> page(int page,int pageSize,String name){
log.info("第{}页,每页{}数据,姓名{}",page,pageSize,name);
//构造分页构造器
Page pageInfo = new Page();
//构造条件构造器
LambdaQueryWrapper<Employee> queryWrapper = new LambdaQueryWrapper<>();
//过滤条件
queryWrapper.like(StringUtils.isNotEmpty(name),Employee::getName,name);
//添加排序条件
queryWrapper.orderByDesc(Employee::getUpdateTime);
//执行查询
employeeService.page(pageInfo,queryWrapper);
return R.success(pageInfo) ;
}
启用禁用员工账号

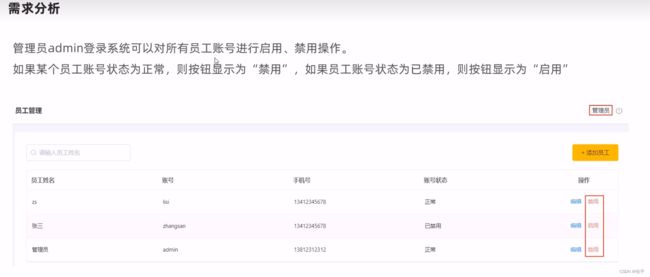
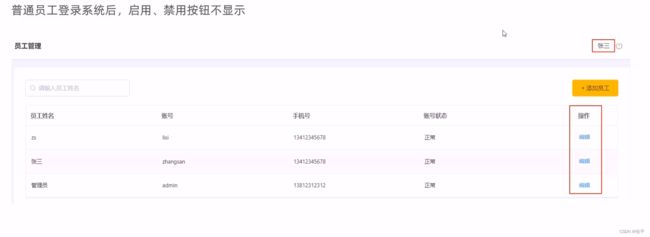
如何实现管理员可以看到禁用按钮,其实是前端做了处理:

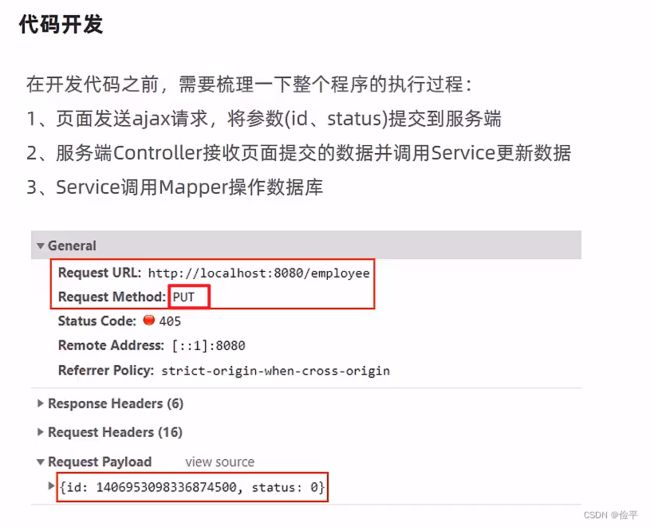
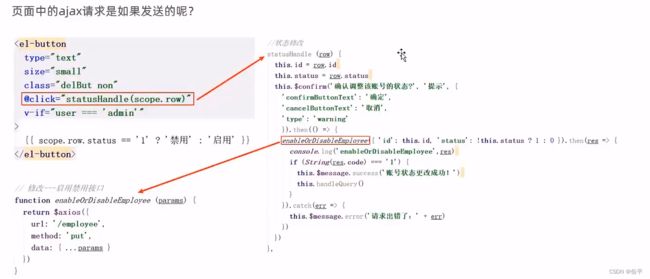
前面返回的数据是json,所以加上RequsetBody
代码:

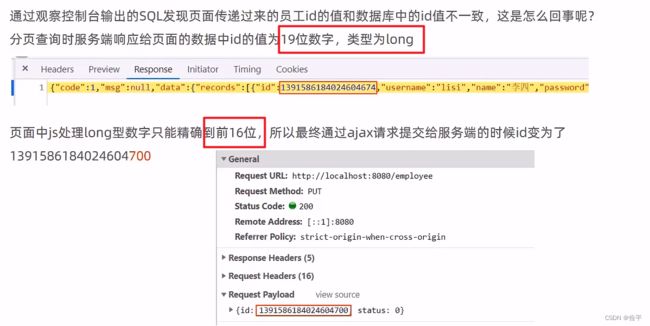
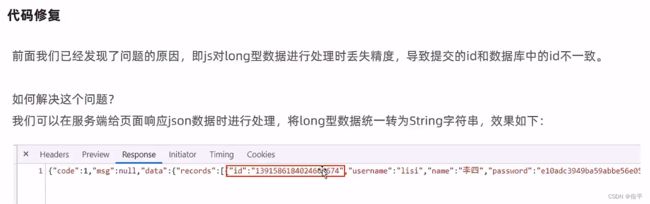
前端的数据是正常的,经过js一处理就不正常了,问题出在js,因为精度问题。所以将long类型给为String类型。
需要一个Java对象转json或者json对象转Java的类,这个类不需要我们写,到时候直接CV,知道作用就可以了。
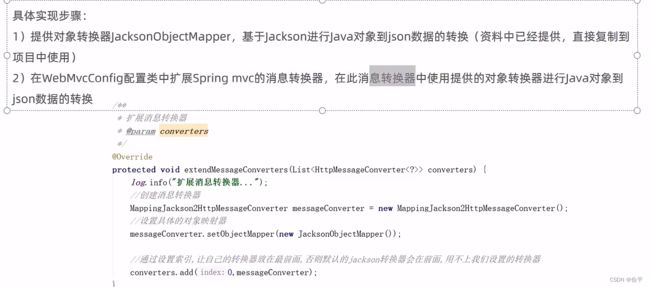
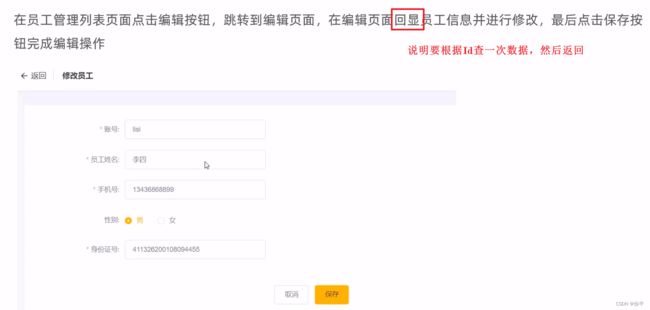
编辑员工信息:

/**
* 根据员工id查询员工信息
* @param id
* @return
*/
@GetMapping("/{id}")
public R<Employee> getById(@PathVariable Long id ){
Employee employee = employeeService.getById(id);
return R.success(employee);
}
@PutMapping
public R<String> update(HttpServletRequest request,@RequestBody Employee employee){
log.info(employee.toString());
Long empId = (Long) request.getSession().getAttribute("employee");
employee.setUpdateTime(LocalDateTime.now());
employee.setUpdateUser(empId);
employeeService.updateById(employee);
return R.success("修改员工信息成功");
}
菜品分类管理的业务开发

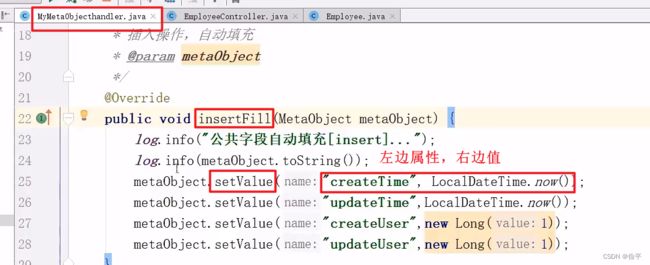
公共字段填充
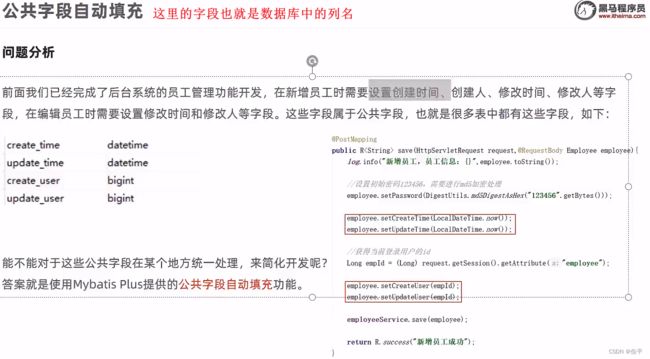
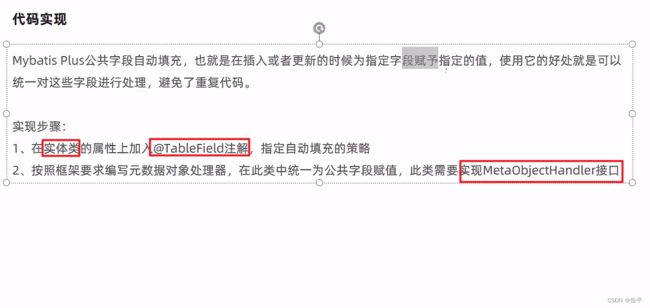
@TableField(fill = FieldFill.INSERT)
private LocalDateTime createTime;
@TableField(fill = FieldFill.INSERT)
private LocalDateTime updateTime;
@TableField(fill = FieldFill.INSERT)
private Long createUser;
@TableField(fill = FieldFill.INSERT_UPDATE)
private Long updateUser;

这里因为获取不到id,所以暂时写死了,后面再来解决这个问题
解决方案:




新增分类

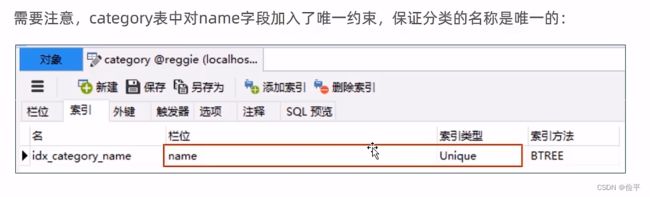

添加分类,直接使用save方法,将接受到的json数据放入。
@PostMapping
public R<String> save(@RequestBody Category category){
categoryService.save(category);
return R.success("新增分类成功");
}
分类信息分页查询
编写一个controller的前提是,明确它要返回什么类型,接受哪几个参数,什么类型的请求映射,路径要写什么合适,具体的业务实现是什么?
@GetMapping("/page")
public R<Page> page(int page ,int pageSize){
Page<Category> pageInfo = new Page(page,pageSize);
LambdaQueryWrapper<Category> queryWrapper = new LambdaQueryWrapper();
queryWrapper.orderByAsc(Category::getSort);
categoryService.page(pageInfo,queryWrapper);
return R.succes(pageInfo);
}
训练中的不足
关于MP的分页查询不熟很熟悉,以及对于LambdaQueryWrapper的使用比较生疏,以及对这条语句categoryService.page(pageInfo,queryWrapper);的使用
2023.2.4
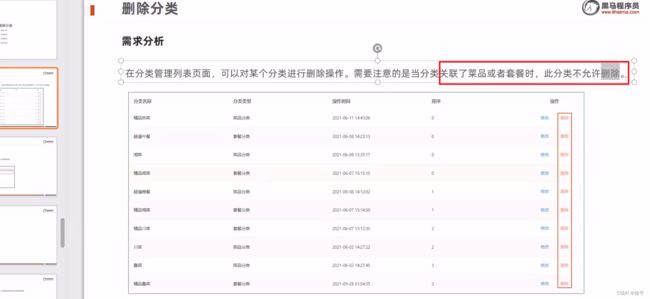
删除分类业务
简单实现:
/**
* 删除分类
* @param id
* @return
*/
@DeleteMapping()
public R<String> delect(Long id){
log.info("删除分类的id为{}",id);
categoryService.removeById(id);
return R.success("删除分类成功");
}

完善功能:当分类关联了菜品或者套餐时不能删除:
在CategoryService类中声明remove方法,然后在CateMapperServiceImpl中实现remove方法,并且把当分类关联了菜品或者套餐时不能删除,这一条件加进去,删除之前应该判断id对应的菜品个数是否大于零,若大于则表明有关联,则抛出自定义异常,并且要在定义的全局异常处理类中捕获异常。
remove方法中先进行查询LambdaQueryWrapper,并指定实体,然后调用eq方法(左要查的字段,右传来的值),然后调用
@Override
public void remove(Long id) {
LambdaQueryWrapper<Dish> dishQueryWrapper = new LambdaQueryWrapper();
dishQueryWrapper.eq(Dish::getCategoryId, id);
int count1 = dishService.count(dishQueryWrapper);
//查询对应的id在dish表中是否有数据,如果有则抛一个异常(未能删除,因为有关联)
if(count1 > 0){
//抛一个异常(未能删除,因为有关联)
throw new CustomException("当前分类下关联了菜品,不能删除");
}
//查询对应id在Setmeal表中是否有数据,如果有则抛异常
LambdaQueryWrapper<Setmeal> setmealLambdaQueryWrapper = new LambdaQueryWrapper();
setmealLambdaQueryWrapper.eq(Setmeal::getCategoryId, id);
int count2 = setmealService.count(setmealLambdaQueryWrapper);
if(count2 > 0){
//抛一个异常(未能删除,因为有关联)
throw new CustomException("当前分类下关联了套餐,不能删除");
}
//正常删除
super.removeById(id);
}
自定义异常:
/**
* 自定义业务异常类
*/
public class CustomException extends RuntimeException{
public CustomException(String message){
super(message);
}
}
全局捕获:
/**
*删除分类异常处理方法
* @return
*/
@ExceptionHandler(CustomException.class)
public R<String> exceptionHandler(CustomException ce){
log.error(ce.getMessage());
return R.error(ce.getMessage());
}
※小记:
修改分类业务:
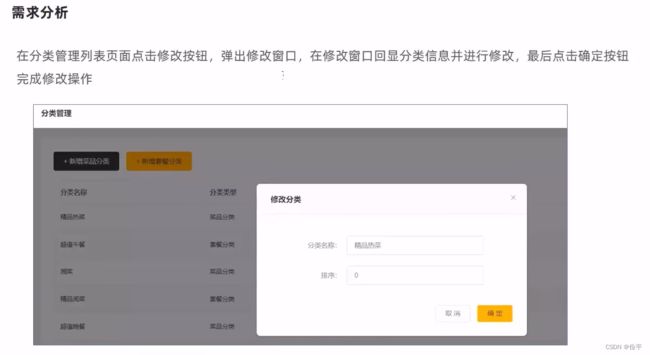
f12查看请求页面
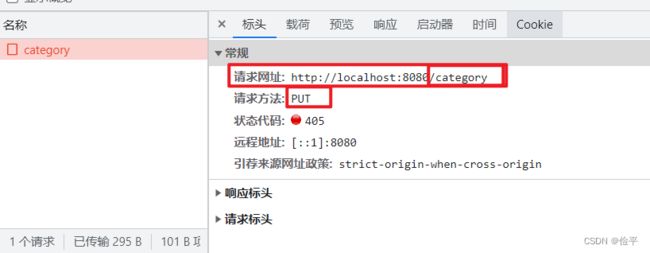
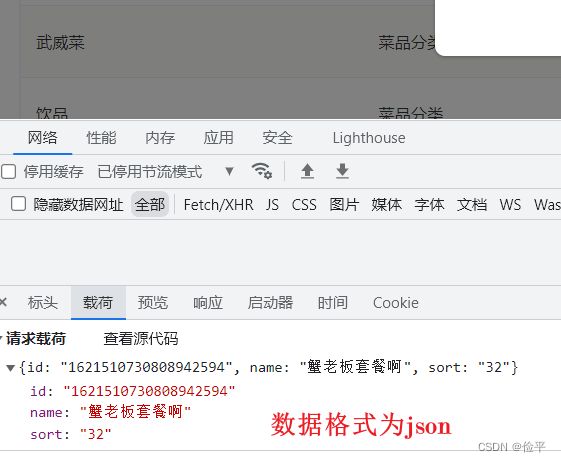
所以controller中的代码:
@PutMapping
public R<String> update(@RequestBody Category category){
categoryService.updateById(category);
return R.success("修改成功");
}
菜品管理的业务开发

文件上传
从数据库拿数据叫下载,向数据库存数据叫上传。

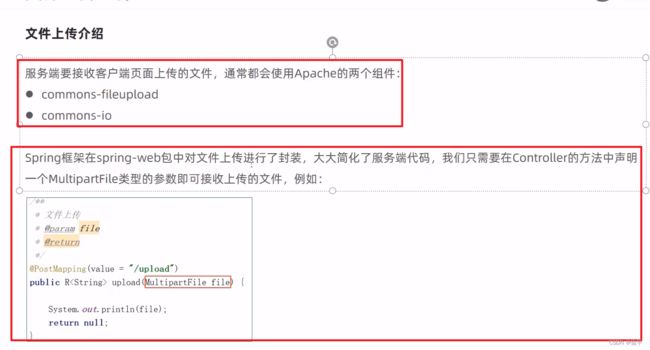

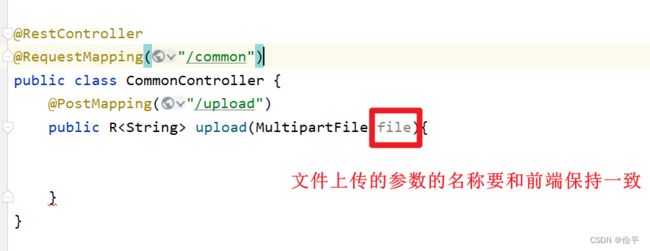
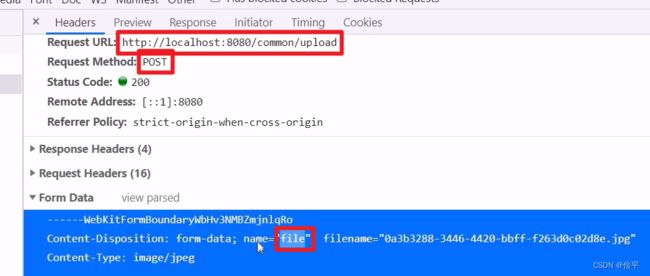
这个file是个临时文件,需要转存到指定位置,否则本次请求结束后临时文件会自动删除。
原始文件名上传:
@PostMapping("/upload")
public R<String> upload(MultipartFile file){
log.info("文件上传{}",file.toString());
//获取原始文件名
String originalFilename = file.getOriginalFilename();
try {
//将文件转存到指定路径+文件名
File file1 = new File(basePath + originalFilename); //此处的basePath不必写死,应写在配置文件中
//调用transferTo函数转存到指定路径
file.transferTo(file1);
} catch (IOException e) {
e.printStackTrace();
}
return R.success("上传成功") ;
}
一般采用UUID来随机生成名称(防止重名覆盖),并且动态获取文件后缀名:

上传文件差不多就完成了,有一个小细节就是在读取配置文件中的路径是,如果路径没有我们应该创建出该目录在进行存储,所以需要判断一下目录是否存在。

文件上传完整代码:
@PostMapping("/upload")
public R<String> upload(MultipartFile file){
log.info("文件上传{}",file.toString());
//获取原始文件名
String originalFilename = file.getOriginalFilename();
//动态获取文件的后缀名
String suffix = originalFilename.substring(originalFilename.lastIndexOf("."));
//使用UUID随机生成名称
String fileName = UUID.randomUUID().toString() + suffix;
//创建一个目录对象
File dir = new File(basePath);
//判断目录是否存在
if(!dir.exists()){
//不存在,进行创建
dir.mkdirs();
}
try {
//将文件转存到指定路径+文件名
File file1 = new File(basePath + fileName ); //此处的basePath不必写死,应写在配置文件中
//调用transferTo函数转存到指定路径
file.transferTo(file1);
} catch (IOException e) {
e.printStackTrace();
}
return R.success(fileName) ;
}
注意上述代码中,要返回一个fileName字符串,因为前端需要这个图片的名称,在添加菜品点击保存时,要把数据存入数据库当中的。
文件下载

文件下载时一开始需要我们的页面发送一个请求,然后在服务端我们将这个文件通过输出流的方式,写回浏览器页面。

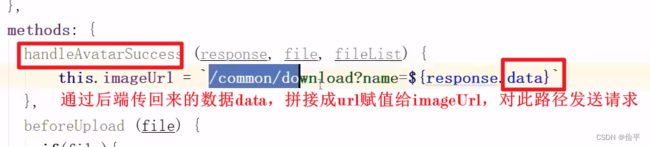
通过输入流来读取数据,通过输出流向浏览器页面写数据,通过HttpServletResponse来获得输出流,通过调用write方法来写入
不着急,先浅浅地补一下IO流的知识

然后定义一个byte数组,将读到的数据写到数组中,read()会从输入流中读取下一个字节。如果没有字节可读(也就是read()读到文件最后了)read()返回-1.
所以我们需要把读到的内容写在数组里,如何知道读完了?看read返回的值是否为-1,然后把读到的内容写到 outputStream输出流,然后用flush刷新一下,并关闭输入输出流以节约资源。
局部代码实现:
int len = 0;
//定义一个数组来存放读入的内容
byte[] bytes = new byte[1024];
while((len = fileInputStream.read(bytes))!= -1){
outputStream.flush();
}
fileInputStream.close();
outputStream.close();
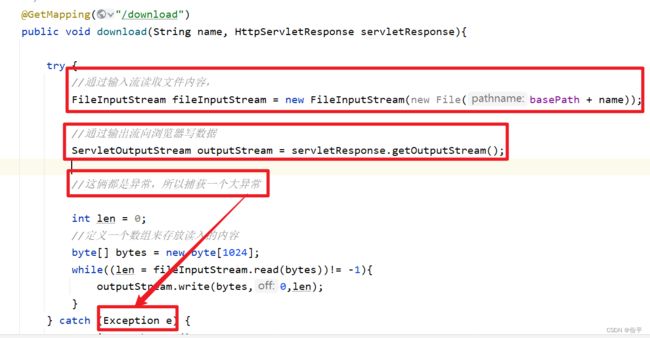
完整代码:
/**
* 文件下载
* @param name
* @param servletResponse
*/
@GetMapping("/download")
public void download(String name, HttpServletResponse servletResponse){
try {
//通过输入流读取文件内容,
FileInputStream fileInputStream = new FileInputStream(new File(basePath + name));
//通过输出流向浏览器写数据
ServletOutputStream outputStream = servletResponse.getOutputStream();
//这俩都是异常,所以捕获一个大异常
//因为上传下载的是图片,获取一下文件类型,然后设置为图片格式(固定格式)
servletResponse.setContentType("image/jpeg");
int len = 0;
//定义一个数组来存放读入的内容
byte[] bytes = new byte[1024];
while((len = fileInputStream.read(bytes))!= -1){
outputStream.write(bytes,0,len);
outputStream.flush();
}
fileInputStream.close();
outputStream.close();
} catch (Exception e) {
e.printStackTrace();
}
//输出流
}
※新增菜品


前端backend/page/food/add.html页面


编写 获取菜品分类的controller,我们看一眼他发的请求:
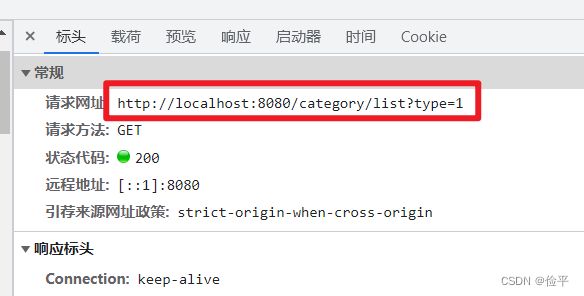
由上图我们就知道,需要传入参数type,并且路径在list下
代码:
@GetMapping("/list")
public R<List<Category>> queryCategoryId(Category category){ //将前端传来的type封装在cate对象中
// 用Category,因为可能要用其他的属性
//构造条件查询器
LambdaQueryWrapper<Category> lambdaQueryWrapper = new LambdaQueryWrapper();
//通过type字段进行查询
lambdaQueryWrapper.eq(category.getType()!= null,Category::getType,category.getType());
//将查询的结果排升序
lambdaQueryWrapper.orderByAsc(Category::getSort);
//存入list中
List<Category> list = categoryService.list(lambdaQueryWrapper);
return R.success(list);
}
关于口味的html页面,name和value字段后面会用到。

在点击保存的时候,会发送dish路径的请求
前端传来的数据中有flavor,而dish实体类中没有这个属性,所有我们要创建DishDto,在这个类中既要有Dish的属性还要有flavor属性

当增删改查的业务复杂时,我们应该自己实现方法来达到业务目的
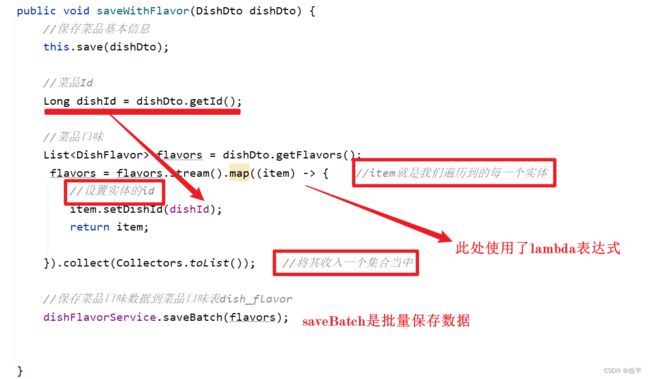
新增菜品,同时插入菜品对应的口味数据,需要操作两张表: dish、 dish_ flavor
在DishService中声明saveWithFlavor方法,并在实现类中实现。
大体思路就是:先保存菜品信息到Dish表,然后在dish_flavor表中根据dish_id保存name和value的值
复习一下lambda表达式,以前学过的又忘了:
什么是Lambda表达式?
可以将Lambda表达式理解为一个匿名函数; Lambda表达式允许将一个函数作为另外一个函数的参数; 我们可以把 Lambda 表达式理解为是一段可以传递的代码(将代码作为实参),也可以理解为函数式编程,将一个函数作为参数进行传递。
==================================================================================================================================================================
为什么要引入Lambda表达式?
这就好像小强看到小明的手里拿了一把玩具手枪,自己也想拥有一把一样。当java程序员看到其他语言的程序员(如JS,Python)在使用闭包或者Lambda表达式的时候,于是开始吐槽世界上使用最广的语言居然不支持函数式编程。千呼万唤,Java8推出了Lambda表达式。
Lambda表达式能够让程序员的编程更加高效
遍历集合我们可以使用for循环,也可以使用stream流处理,我们这里就采用stream流处理
2023.2.5
今天元宵节,全看花灯了…没怎么学习 = =
2023.2.6
涉及到多张表的操作,所以要在相应的方法上加上事务控制注解,并在启动类上开启事物支持@EnableTransactionManagement
最后编写DishController中编写方法,并调用saveWithFlavor:
/**
* 新增菜品(要涉及到两个表!!)
* @param
* @return
*/
@PostMapping
public R<String> save(@RequestBody DishDto dishDto){
log.info("新增菜品数据:{}",dishDto.toString());
dishService.saveWithFlavor(dishDto);
return R.success("新增菜品成功!");
}
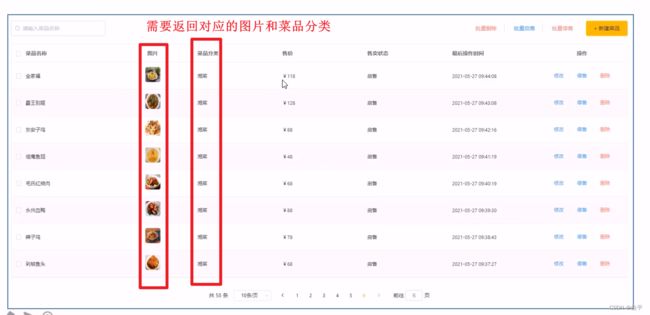
※菜品信息分页查询
字符串对比,比如菜品名称啊,用户名称啊这种建议使用like模糊查询,id一般用eq查询。
queryWrapper.like方法有两个,其一是两个参数,其二是三个参数,最后一个参数是前端传回的数据,倒数第二个是数据库中表的列名
要返回的数据有菜品基本信息、菜品图片、菜品分类名称
代码(只返回菜品基本信息、菜品图片):
/**
* 菜品信息分页查询
* @param page
* @param pageSize
* @param name
* @return
*/
@GetMapping("/page")
public R<Page> page(int page,int pageSize,String name){
log.info(" 菜品分页查询{},{}",page,pageSize);
Page<Dish> pageInfo = new Page<>(page,pageSize);
LambdaQueryWrapper<Dish> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.like(name!=null,Dish::getName,name);
queryWrapper.orderByDesc(Dish::getUpdateTime);
dishService.page(pageInfo,queryWrapper);
return R.success(pageInfo);
}
如何返回菜品分类?
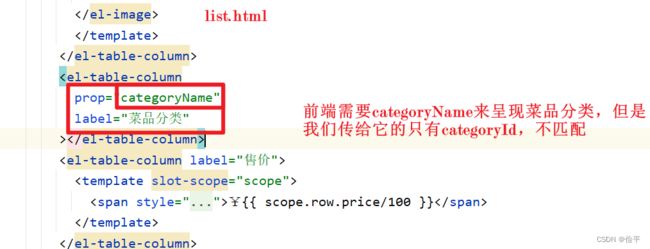
所以需要添加一个categoryName属性
完整流程就是:前端需要categoryName来显示商品分类名称, 但是后端没有这个属性,所以我们在DishDto中加入这个属性,然后再返回基本菜品信息和菜品图片之后,还有返回菜品分类的名称,这时候需要创建两个Page对象,pageInfo用来存基本信息(Dish),dishDtoPage用来存菜品分类名称(DishDto),将pageInfo拷贝给dishDtoPage,然后再设置dishDtoPage的categoryName属性,再返回dishDto.
要用哪个表就用哪个Service,拷贝用BeanUtils.copyProperties方法
完整带注释代码:
/**
* 菜品信息分页查询
* @param page
* @param pageSize
* @param name
* @return
*/
@GetMapping("/page")
public R<Page> page(int page,int pageSize,String name){
//查询菜品基本信息
log.info(" 菜品分页查询{},{}",page,pageSize);
Page<Dish> pageInfo = new Page<>(page,pageSize);
LambdaQueryWrapper<Dish> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.like(name!=null,Dish::getName,name);
queryWrapper.orderByDesc(Dish::getUpdateTime);
dishService.page(pageInfo,queryWrapper);
//菜品分类
//对象拷贝,忽略records是一条一条的菜品信息,这个需要我们处理
Page<DishDto> dishDtoPage = new Page<>();
BeanUtils.copyProperties(pageInfo,dishDtoPage,"records"); //将pageInfo复制给dishDtoPage,records属性忽略
//对pageInfo的records进行处理再赋值给dishDtoPage的records
List<Dish> records = pageInfo.getRecords();
//处理,依旧是基于stream流遍历每一条记录
List<DishDto> list = records.stream().map((item) -> { //item代表每一个菜品对象'
//此对象用来将复制item
DishDto dishDto = new DishDto();
//获得id
Long categoryId = item.getCategoryId();
//拿着id查category表,得到Category对象,需要注入一个CategoryService对象
Category category = categoryService.getById(categoryId);
//得到categoryName
String categoryName = category.getName();
//将item拷贝给DishDto对象
BeanUtils.copyProperties(item,dishDto);
//设置名称
dishDto.setCategoryName(categoryName);
return dishDto;
}).collect(Collectors.toList()); //收集成一个集合,集合内是一条一条的记录
//将此记录赋值给dishDtoPage的records属性
dishDtoPage.setRecords(list);
return R.success(dishDtoPage);
}
以上代码我自认为的难点还是stream流与lambda表达式
修改菜品
回忆知识点:(@PathVariable注解,了解的话直接跳过)
1、若方法参数名称和需要绑定的url中变量名称一致时,可以简写:
@RequestMapping("/getUser/{name}")
public User getUser(@PathVariable String name){
return userService.selectUser(name);
}
2、若方法参数名称和需要绑定的url中变量名称不一致时,写成:
@RequestMapping("/getUserById/{name}")
public User getUser(@PathVariable("name") String userName){
return userService.selectUser(userName);
}

在DishService中声明一个getByIdWithFlavor方法,在其实现类中实现,要返回口味所以返回对象一定是DishDto
回显页面的代码:
/**
* 通过查id菜品信息
* @param id
* @return
*/
@Override
public DishDto getByIdWithFlavor(Long id) {
Dish dish = this.getById(id);
DishDto dishDto = new DishDto();
//将菜品的基本信息复制给DishDto
BeanUtils.copyProperties(dish,dishDto);
LambdaQueryWrapper<DishFlavor> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(DishFlavor::getDishId,dish.getId()); //eq是对queryWrapper进行操作,操作完的结果还是在queryWrapper中,所以下面直接又用的queryWrapper
//获得口味信息
List<DishFlavor> flavors = dishFlavorService.list(queryWrapper);
dishDto.setFlavors(flavors);
return dishDto;
}
完善保存的功能:
先更新菜品表,再更新口味表。更新口味表时,可以先清除对应的口味,在重新录入新的数据。涉及到两张表进行事务注解
功能复杂,所以自己定义updateWithFlavor方法并进行实现

完整代码:
DishServiceImpl.java
/**
* 更新菜品信息,同时更新口味信息
* @param
* @return
*/
@Transactional //涉及多张表,添加
public void updateWithFlavor(DishDto dishDto) {
//更新dish表基本信息
this.updateById(dishDto);
//清理当前菜品对应口味数据---dish flavor表的delete操作
LambdaQueryWrapper<DishFlavor> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(DishFlavor::getDishId,dishDto.getId());
dishFlavorService.remove(queryWrapper);
//添加当前提交过来的口味数据---dish flavor表的insert操作
List<DishFlavor> flavors = dishDto.getFlavors();
flavors = flavors.stream().map((item) -> { //item指每一个菜品的口味数据
item.setDishId(dishDto.getId()); //为口味设置对应的菜品id
return item;
}).collect(Collectors.toList());
dishFlavorService.saveBatch(flavors);
}
DishController.java
/**
* 更新菜品(要涉及到两个表!!)
* @param
* @return
*/
@PutMapping
public R<String> update(@RequestBody DishDto dishDto){
dishService.updateWithFlavor(dishDto);
return R.success("更新菜品成功!");
}
套餐管理的业务开发

新增套餐


简单理解就是:如果有一个名为“儿童套餐A计划”的套餐,则在set_meal表中,属于儿童套餐A计划的所有菜品的setmeal_id都是商务套餐的id


需要把套餐名称、价格、图片、套餐分类、描述等数据添加至setmeal表中;
套餐菜品的数据添加至setmeal_dish表中,
所以涉及到了两张表,本项目中涉及到两张表以上的一般都要加事务注解(要么全成功,要么全失败),并且自己声明一个新方法,并进行实现
SetmealService中声明saveWithDish方法
SetmealServiceImpl中实现saveWithDish方法
SetmealController中调用saveWithDish方法
SetmealServiceImpl.java
@Autowired
private SetmealDishService setmealDishService;
/**
* 新增套餐,同时需要保存套餐和菜品的关联关系
* @param setmealDto
*/
@Transactional
public void saveWithDish(SetmealDto setmealDto) {
//保存套餐基本信息
this.save(setmealDto);
List<SetmealDish> setmealDishes = setmealDto.getSetmealDishes();
/*此时SetmealDish的mealId值是空的,从前端传来的数据也可以看到它是空的
* 所以要对每一条数据的mealDish进行赋值,这个值正好就是setmealDto.getId
* */
setmealDishes.stream().map((item) -> {
item.setSetmealId(setmealDto.getId());
return item;
}).collect(Collectors.toList()); //最后收到一个集合当中
//保存套餐和菜品的关联信息,操作setmeal_dish,执行insert操作
setmealDishService.saveBatch(setmealDishes); //批量保存
}
※套餐信息分页查询


这个其实跟菜品信息的分页查询大同小异,都用到了Dto,用到了拷贝,用到了Stream流遍历然后收入一个集合
/**
* 套餐信息分页查询
* @param page
* @param pageSize
* @param name
* @return
*/
@GetMapping("/page")
public R<Page> page(int page,int pageSize,String name){
// SetmealDto setmealDto = new SetmealDto();
//构造分页构造器
Page<Setmeal> pageInfo = new Page<>(page,pageSize);
//为返回categoryName,使用SetmealDto
Page<SetmealDto> setmealDtoPage = new Page<>();
//构造条件查询
LambdaQueryWrapper<Setmeal> queryWrapper = new LambdaQueryWrapper<>();
//匹配传来的name,并先判断是否为空(如果是用户输入的则要判断,如果是已经存在的则不必判断)
queryWrapper.like(name != null,Setmeal::getName,name);
//排序
queryWrapper.orderByDesc(Setmeal::getUpdateTime);
setmealService.page(pageInfo, queryWrapper);
//拷贝
BeanUtils.copyProperties(pageInfo,setmealDtoPage,"records");
//怎么获取categoryId啊???用records,records里面封装的是对象
List<SetmealDto> collect = pageInfo.getRecords().stream().map((item) -> {
/**
* 先新建对象,然后拷贝
* 我要通过category_id找到categoryName
* 在哪找?在category表中找,要用哪个service?CategoryService
*/
SetmealDto setmealDto = new SetmealDto();
BeanUtils.copyProperties(item,setmealDto);
Long categoryId = item.getCategoryId();
Category category = categoryService.getById(categoryId);
if(category != null){
String categoryName = category.getName();
setmealDto.setCategoryName(categoryName);
}
return setmealDto;
}).collect(Collectors.toList());
setmealDtoPage.setRecords(collect);
return R.success(setmealDtoPage);
}
2023.2.7
删除套餐


用一个List集合来接收传来的参数,泛型指定为Long,需要在参数前加@RequestParam,才能正确接收到,在删除之前先要判断套餐的状态,是正在售卖,还是停售了,如果正在售卖则不能被删除,需要调整为停售再删除,删除套餐时,不仅要删除套餐,还要删除套餐菜品关系表中的数据,我们需要自定义方法deleteWithDish来实现这一功能
自己的大致理解:不知是否正确。
对于一条SQL语句,在MybatisPlus中,将其拆分为大致两块
他将SQL中的SELECT、INSERT、UPDATE、DELETE,映射为IService中的 get、save、update、remove等方法
将SQL中的where子句映射为LambdaQueryWrapper的eq、between、or、and、in等方法
在语雀小结了一下SQL语句
SetmealServiceImpl.java
/**
* 删除套餐,同时删除套餐和菜品的关联信息
* @param ids
*/
@Transactional
public void deleteWithDish(List<Long> ids) {
//查询套餐,看是否可以删除。
// select count(*) from setmeal where id in (1,2,3) and status = 1
LambdaQueryWrapper<Setmeal> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.in(Setmeal::getId,ids);
queryWrapper.eq(Setmeal::getStatus,1);
int count = this.count(queryWrapper);
if(count>0){
//如果不能删除,抛一个业务异常
throw new CustomException("套餐正在售卖中,请先停售再删除");
}
//可以删除则先删除套餐表中的数据,
this.removeByIds(ids);
//delete from setmeal_dish where setmeal_id in (list)
LambdaQueryWrapper<SetmealDish> queryWrapper1 = new LambdaQueryWrapper<>();
queryWrapper1.in(SetmealDish::getSetmealId,list());
//再删除关联信息,delete table setmeal_dish,find
setmealDishService.remove(queryWrapper1);
}
然后在controller中调用此方法就ok
手机验证码登录

短信发送
使用阿里云提供的短信服务来发送短信,


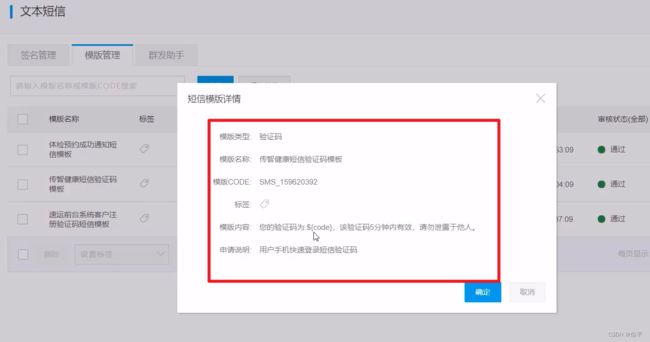
要自己添加一个模板,里面要写占位符${code}
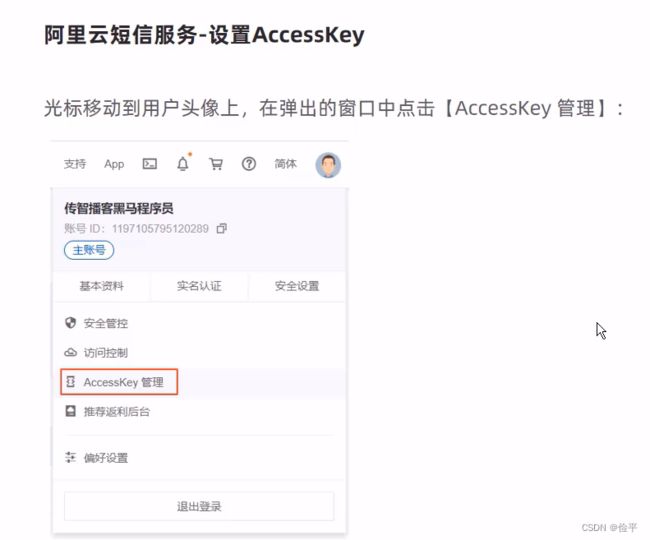
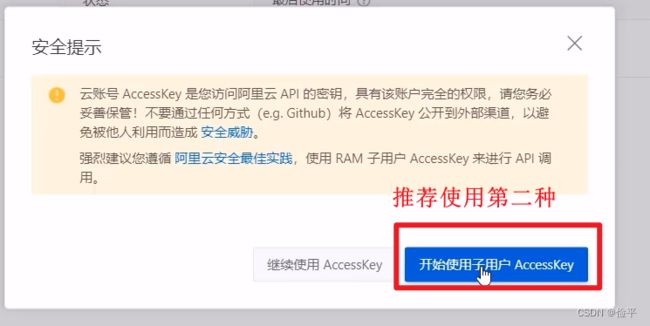

文档地址在这
maven:
<dependency>
<groupId>com.aliyungroupId>
<artifactId>aliyun-java-sdk-coreartifactId>
<version>4.5.16version>
dependency>
调用API:
import com.aliyuncs.DefaultAcsClient;
import com.aliyuncs.IAcsClient;
import com.aliyuncs.exceptions.ClientException;
import com.aliyuncs.exceptions.ServerException;
import com.aliyuncs.profile.DefaultProfile;
import com.google.gson.Gson;
import java.util.*;
import com.aliyuncs.dysmsapi.model.v20170525.*;
public class SendSms {
public static void main(String[] args) {
DefaultProfile profile = DefaultProfile.getProfile("cn-beijing", "" , "" );
/** use STS Token
DefaultProfile profile = DefaultProfile.getProfile(
"", // The region ID
"", // The AccessKey ID of the RAM account
"", // The AccessKey Secret of the RAM account
""); // STS Token
**/
IAcsClient client = new DefaultAcsClient(profile);
SendSmsRequest request = new SendSmsRequest();
request.setPhoneNumbers("1368846****");//接收短信的手机号码
request.setSignName("阿里云");//短信签名名称
request.setTemplateCode("SMS_20933****");//短信模板CODE
request.setTemplateParam("张三");//短信模板变量对应的实际值
try {
SendSmsResponse response = client.getAcsResponse(request);
System.out.println(new Gson().toJson(response));
} catch (ServerException e) {
e.printStackTrace();
} catch (ClientException e) {
System.out.println("ErrCode:" + e.getErrCode());
System.out.println("ErrMsg:" + e.getErrMsg());
System.out.println("RequestId:" + e.getRequestId());
}
}
}
修改自己的access-key-id和access-key-secret
手机验证码登录

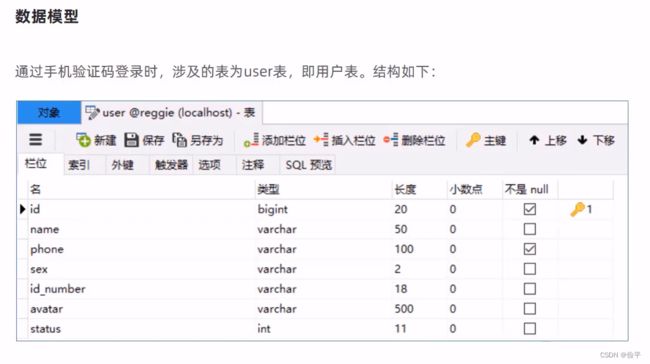


因为发送短信和登录页面不需要跳转,所以加入到不需要处理的路劲中


完整代码:
/**
* 发送短信验证码
* @param user
* @param httpSession
* @return
*/
@PostMapping("/sendMsg")
public R<String> sendMsg(@RequestBody User user, HttpSession httpSession){
//获取手机号
String phone = user.getPhone();
if(StringUtils.isNotEmpty(phone)){
//生成随机的4位验证码
String code = ValidateCodeUtils.generateValidateCode(6).toString();
log.info("验证码{}",code);
//调用阿里云提供的短信服务API完成发送短信
// SMSUtils.sendMessage("瑞吉外卖","",phone,code);
//需要将生成的验证码保存到Session
httpSession.setAttribute(phone,code);
return R.success("手机验证码发送成功");
}
return R.error("短信发送失败");
}
我在输入手机号想获取验证码,结果前端直接给我返回了,因为老师给的资料前段直接给你用random生成并返回到form上了 自己修改下代码,如下图

然后再将sendMsg方法添加在login.js
如果输入手机号,获取验证码还没有反应,那就maven要clean一下,然后清除浏览器的缓存就ok了
请求中只有电话号码,没有验证码???
原因是资料里面写死了,只写了电话号码
解决方案:改为表单
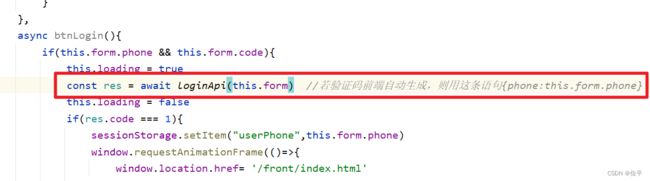
controller怎么写呢?
首先我们要接受json数据,里面有phone和code,如果用User对象接受的话,它里面并没有一个code的属性,所以我们用Map来接收,phone和code为键,传来的值为值。
然后它的返回数据是什么呢?登录之后我们要返回用户的个人信息到浏览器或者APP,所以返回值是User对象,
user表的id在存数据库之前就已经有了
完整代码:
/**
* 移动端用户登录
* @param map
* @param httpSession
* @return
*/
@PostMapping("/login")
public R<User> login(@RequestBody Map map, HttpSession httpSession){
log.info(map.toString());
//获取手机号
String phone = map.get("phone").toString();
//获取验证码
String code = map.get("code").toString();
//从Session中获取保存的验证码
Object codeInSession = httpSession.getAttribute(phone);
//进行验证码的比对页面提交的验证码和Session中保存的验证码比对
if(codeInSession != null && codeInSession.equals(code)){
//如果能够比对成功,说明登录成功
LambdaQueryWrapper<User> queryWrapper = new LambdaQueryWrapper<>();
//根据手机号查user表
queryWrapper.eq(User::getPhone,phone);
//因为手机号是唯一表示,所以调用getOne方法,并把queryWrapper传入
User user = userService.getOne(queryWrapper);
//判断当前手机号对应的用户是否为新用户,如果是新用户就自动完成注册
if(user ==null ){
//该用户为新用户
user = new User();
//设置手机号和状态
user.setPhone(phone);
user.setStatus(1);
userService.save(user);
}
//登录成功之后,需要把用户的id放到session一份 ,因为它经过过滤器的时候回校验,有session就通过,没有session就会被过滤,跳转的登录页面
httpSession.setAttribute("user",user.getId());
return R.success(user);
}
return R.error("登录失败");
}
前端页面
导入用户地址簿相关代码

菜品展示
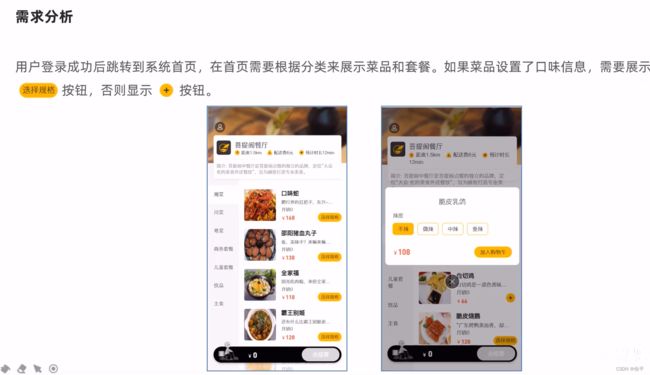
在改了静态页面cartData.json后,页面竟然还是不显示,用maven的clean了一下解决了,如果还是不行就清除历史记录(ctrl+f5)
需要完善dish/list的controller方法,以便能在点餐页面显示口味信息,也就是既返回菜品信息,又返回口味信息。
所以返回值将原来的Dish集合改为DishDto集合,然后获取到口味信息然后再返回。
完整代码:
/**
* 通过id查询菜品信息
* @param dish
* @return
*/
@GetMapping("/list")
public R<List<DishDto>> list(Dish dish){ //前端传来的数据是id,我们为了更加通用,所以用Dish实体
//条件查询
LambdaQueryWrapper<Dish> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(dish.getCategoryId() != null,Dish::getCategoryId,dish.getCategoryId());
//添加条件,查询状态为1(正在售卖中的),防止菜品挺卖了还可以出现在套餐中
queryWrapper.eq(Dish::getStatus,1);
//添加排序条件
queryWrapper.orderByAsc(Dish::getSort).orderByDesc(Dish::getUpdateTime);
List<Dish> list = dishService.list(queryWrapper);
//
List<DishDto> dtoList = list.stream().map((item) -> { //item代表每一个菜品对象'
//此对象用来将复制item
DishDto dishDto = new DishDto();
//将item拷贝给DishDto对象
BeanUtils.copyProperties(item,dishDto);
//获得id
Long categoryId = item.getCategoryId();
//拿着id查category表,得到Category对象,需要注入一个CategoryService对象
Category category = categoryService.getById(categoryId);
if (category != null) {
//得到categoryName
String categoryName = category.getName();
//设置名称
dishDto.setCategoryName(categoryName);
}
//获取菜品id
Long dishId = item.getId();
//通过菜品id查到口味信息
LambdaQueryWrapper<DishFlavor> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.eq(DishFlavor::getDishId,dishId);
//将查询结果放入一个集合
List<DishFlavor> dishFlavors = dishFlavorService.list(lambdaQueryWrapper);
dishDto.setFlavors(dishFlavors);
return dishDto;
}).collect(Collectors.toList());
//
return R.success(dtoList);
}
写完之后在页面点击套餐发现还是404,因为套餐查询我们还行没有写,:
/**
* 根据条件查询套餐
* @param setmeal
* @return
*/
@GetMapping("/list")
public R<List<Setmeal>> list( Setmeal setmeal){
//构造查询器
LambdaQueryWrapper<Setmeal> queryWrapper = new LambdaQueryWrapper<>();
//比较id和状态,并进行排序
queryWrapper.eq(setmeal.getCategoryId() != null,Setmeal::getCategoryId,setmeal.getCategoryId());
queryWrapper.eq(setmeal.getStatus() != null,Setmeal::getStatus,setmeal.getStatus());
queryWrapper.orderByDesc(Setmeal::getUpdateTime);
//收集至一个集合当中
List<Setmeal> setmealList = setmealService.list(queryWrapper);
return R.success(setmealList);
}
购物车
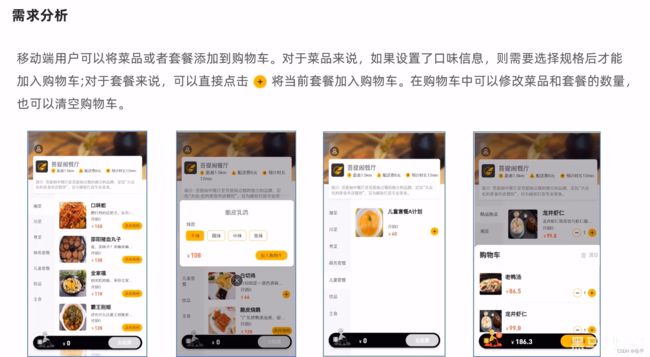
实测,点击加号和选择规格就会发送网络请求,我以前一直以为这个增加删除只是前端页面的效果,等最后提交的时候再一并传给后端.


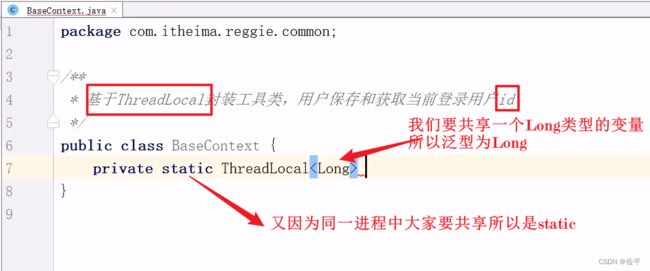
设置用户,指定此购物车是哪位用户的(使用localThread)
判断前端发来的是菜品还是套餐,如果是菜品就处理菜品,如果是套餐就处理套餐
判断用户之前是否点过某一个菜品或套餐,如果点过就number+1,没有点过,那数据库中的数据就为空,便插入至购物车表中
/**
* 购物车添加菜品或套餐,并写入购物车,回显数据
* @param shoppingCart
* @return
*/
@PostMapping("/add")
public R<ShoppingCart> add(@RequestBody ShoppingCart shoppingCart){
//设置用户
Long currentId = BaseContext.getCurrentId();
shoppingCart.setUserId(currentId);
//查询当前菜品或者菜品是否在购物车表中
Long dishId = shoppingCart.getDishId();
LambdaQueryWrapper<ShoppingCart> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(ShoppingCart::getUserId,currentId);
if(dishId != null){
//查菜品呗
queryWrapper.eq(ShoppingCart::getDishId,dishId);
} else{
//查套餐
queryWrapper.eq(ShoppingCart::getSetmealId,shoppingCart.getSetmealId());
}
//SQL:select * from shopping_cart where user id = ? and dish id/setmeal id = ?
ShoppingCart cart = shoppingCartService.getOne(queryWrapper);
if(cart != null){
//有套餐或菜品,加一
cart.setNumber(cart.getNumber()+1);
shoppingCartService.updateById(cart);
}else{
//没有,直接插入
shoppingCart.setNumber(1);
shoppingCartService.save(shoppingCart);
cart = shoppingCart;
}
return R.success(cart);
}
查看购物车:
/**
* 查看购物车
* @return
*/
@GetMapping("/list")
public R<List<ShoppingCart>> list(){
log.info("查看购物车...");
//SQL:select * from shopping_cart where user_id = currentId and order by create_Time
LambdaQueryWrapper<ShoppingCart> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(ShoppingCart::getUserId,BaseContext.getCurrentId());
queryWrapper.orderByAsc(ShoppingCart::getCreateTime);
//最后返回一个集合
List<ShoppingCart> list = shoppingCartService.list(queryWrapper);
return R.success(list);
}
2023.2.8
清空购物车:
/**
* 清空购物车
* @return
*/
@DeleteMapping("/clean")
public R<String> clean(){
//获得用户id
Long currentId = BaseContext.getCurrentId();
//根据id查询购物车表
//SQL:delete * from shopping_cart where user_id = currentId
LambdaQueryWrapper<ShoppingCart> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(ShoppingCart::getUserId,currentId); //这里应该是多条数据
shoppingCartService.remove(queryWrapper);
return R.success("已清空");
}
用户下单


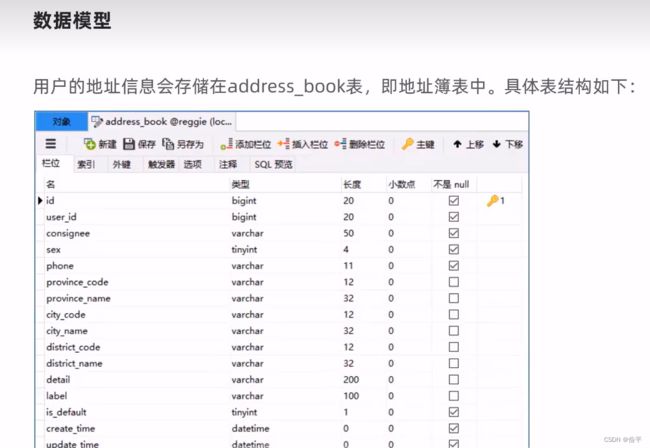
订单表中只有这个订单是哪个用户的,用户的地址,下单时间,金额,收货人,并没有菜品,套餐信息,所以追加了一个订单明细表


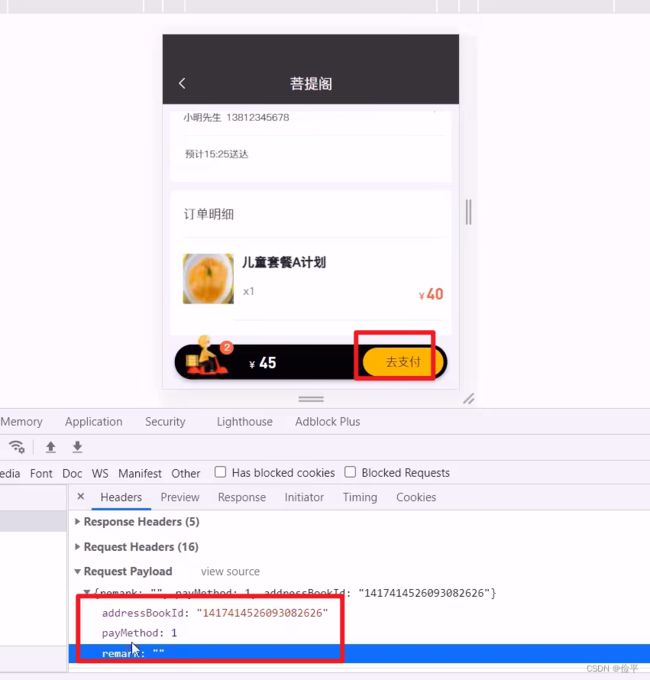
上图中,提交参数的时候只提交了三个,那菜品信息什么的都没有提交吗,原因是我们的session中已经存了用户的id 了,也就是我们只当前的用户是谁,那我们就可以那这id去查数据库了,其他信息都可以查到的
由于业务比较复杂,并且涉及到了多个表的操作,所以我们主要自己实现方法:
/**
* 用户下单
* @param orders
*/
@Transactional
public void submit(Orders orders) {
//获得当前用户id
Long userId = BaseContext.getCurrentId();
//查询当前用户的购物车数据
LambdaQueryWrapper<ShoppingCart> wrapper = new LambdaQueryWrapper<>();
wrapper.eq(ShoppingCart::getUserId,userId);
List<ShoppingCart> shoppingCarts = shoppingCartService.list(wrapper);
if(shoppingCarts == null || shoppingCarts.size() == 0){
throw new CustomException("购物车为空,不能下单");
}
//查询用户数据
User user = userService.getById(userId);
//查询地址数据
Long addressBookId = orders.getAddressBookId();
AddressBook addressBook = addressBookService.getById(addressBookId);
if(addressBook == null){
throw new CustomException("用户地址信息有误,不能下单");
}
long orderId = IdWorker.getId();//订单号
AtomicInteger amount = new AtomicInteger(0);
List<OrderDetail> orderDetails = shoppingCarts.stream().map((item) -> {
OrderDetail orderDetail = new OrderDetail();
orderDetail.setOrderId(orderId);
orderDetail.setNumber(item.getNumber());
orderDetail.setDishFlavor(item.getDishFlavor());
orderDetail.setDishId(item.getDishId());
orderDetail.setSetmealId(item.getSetmealId());
orderDetail.setName(item.getName());
orderDetail.setImage(item.getImage());
orderDetail.setAmount(item.getAmount());
amount.addAndGet(item.getAmount().multiply(new BigDecimal(item.getNumber())).intValue());
return orderDetail;
}).collect(Collectors.toList());
orders.setId(orderId);
orders.setOrderTime(LocalDateTime.now());
orders.setCheckoutTime(LocalDateTime.now());
orders.setStatus(2);
orders.setAmount(new BigDecimal(amount.get()));//总金额
orders.setUserId(userId);
orders.setNumber(String.valueOf(orderId));
orders.setUserName(user.getName());
orders.setConsignee(addressBook.getConsignee());
orders.setPhone(addressBook.getPhone());
orders.setAddress((addressBook.getProvinceName() == null ? "" : addressBook.getProvinceName())
+ (addressBook.getCityName() == null ? "" : addressBook.getCityName())
+ (addressBook.getDistrictName() == null ? "" : addressBook.getDistrictName())
+ (addressBook.getDetail() == null ? "" : addressBook.getDetail()));
//向订单表插入数据,一条数据
this.save(orders);
//向订单明细表插入数据,多条数据
orderDetailService.saveBatch(orderDetails);
//清空购物车数据
shoppingCartService.remove(wrapper);
}
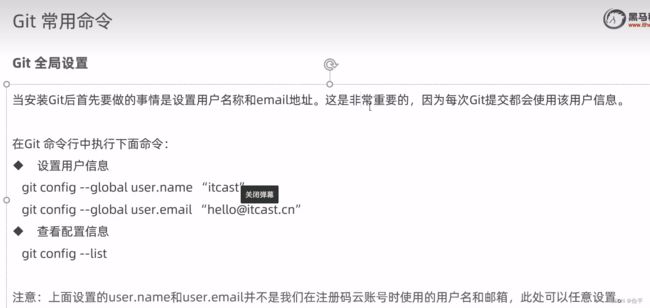
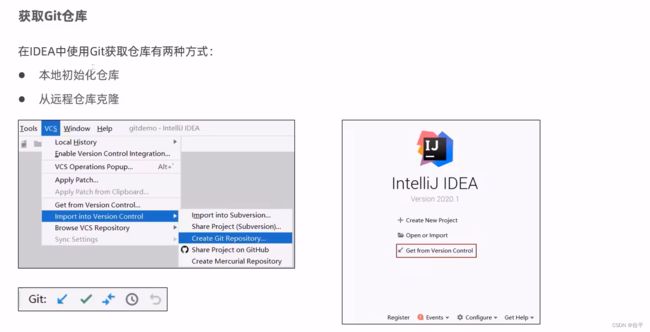
Git

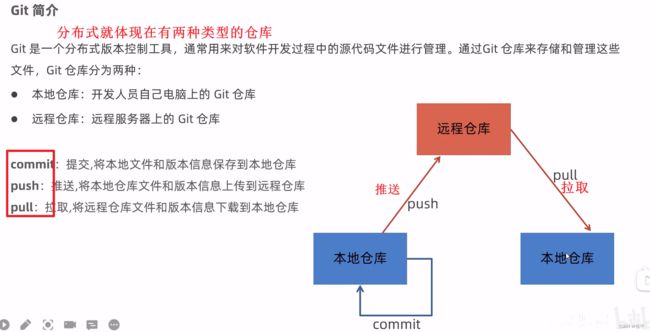
一些公司会架设自己局域网内的代码托管平台,以便公司内部员工协同工作。





git commit -m “init” *
(其中*表示所有内容)
本地仓库就是个文件夹,不过这个文件夹是git管理的,如果你使用git命令那就是对这些文件夹进行仓库管理
如何切换到指定版本?使用git reset --hard后面跟每次提交的唯一标识:
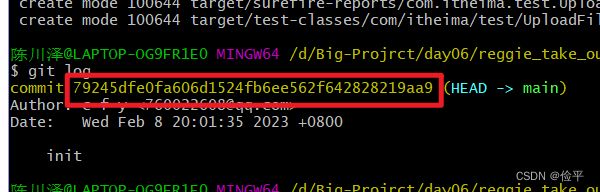
例如git reset --hard 79245dfe0fa606d1524fb6ee562f642828219aa9

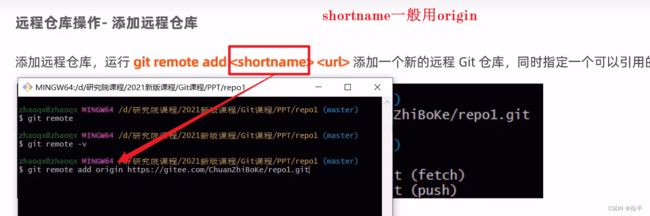
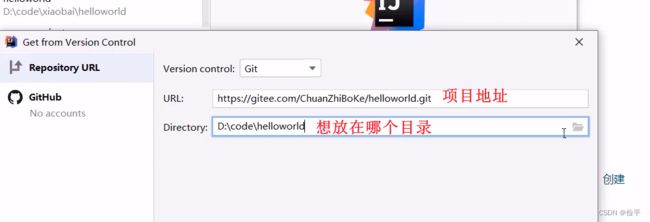
本地仓库如何关联远程仓库?

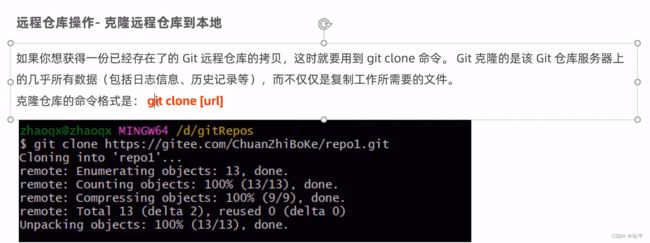




git通过仓库的形式管理项目
跳转到下图二
Linux


jdk

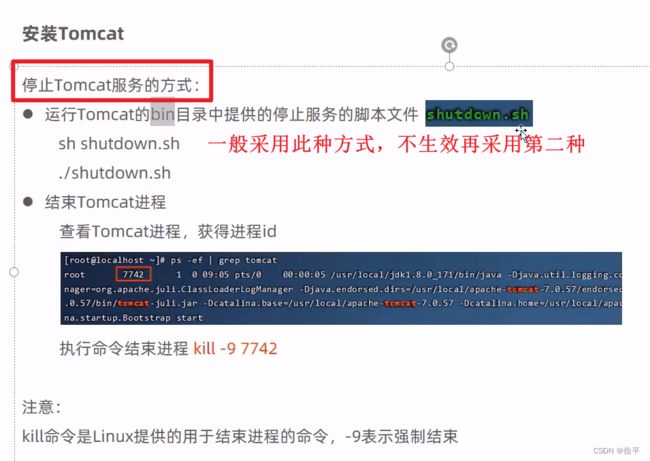
Tomcat



一般防火墙是关闭的,凡事可以开放指定端口号,然后输入立即生效的命令就ok

MySQL
CentOS自带mariadb数据库,要先卸载再安装MySQL,否则会失败
查询是否有mariadb的命令:rpm -qa | grep mariadb
卸载命令:rpm -e --nodeps mariadb-libs-5.5.60-1.el7_5.x86_64
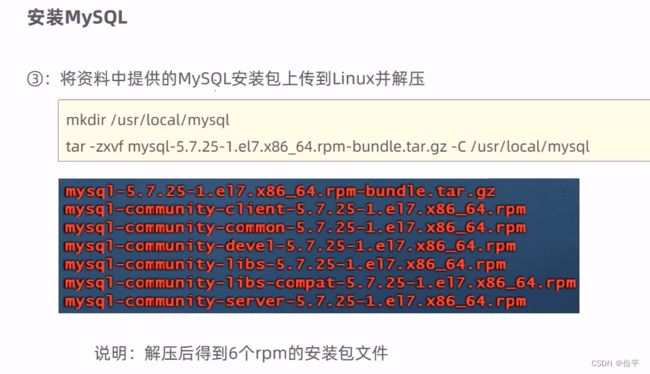

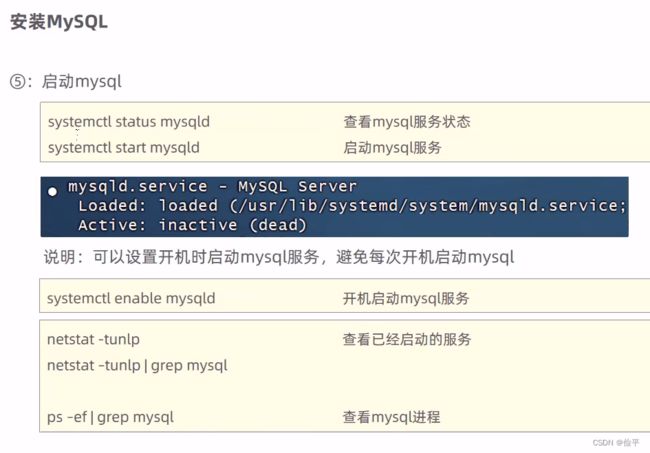
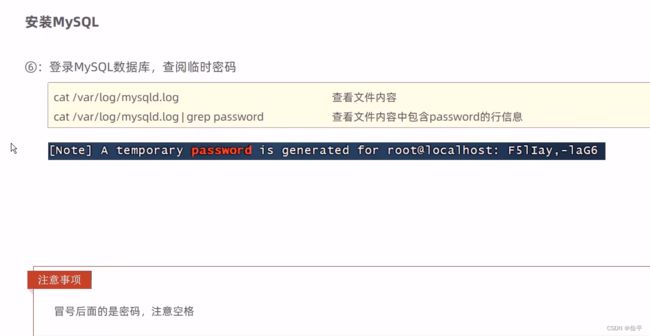


项目部署

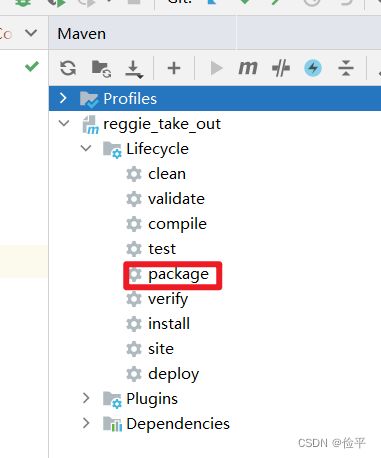
手动

如何打包?双击package
通过命令将windows下的jar包传到linux上,现在linux上准备一个app的目录,然后上传到app下
因为之前已经安装了lrzsz,所以直接用rz命令选择我们的jar包进行上传

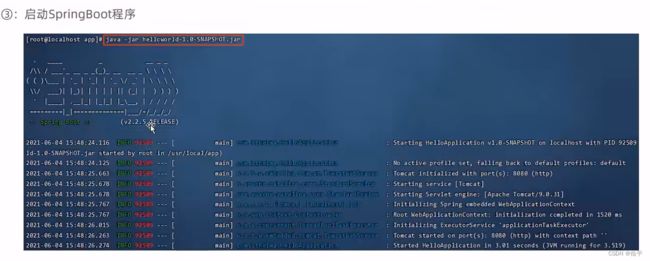
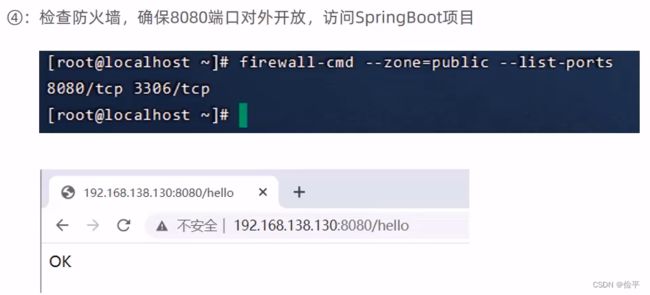

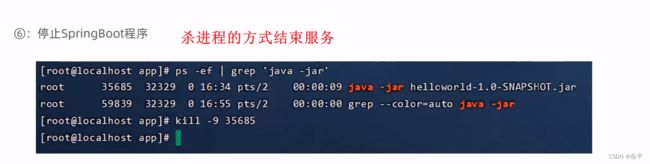
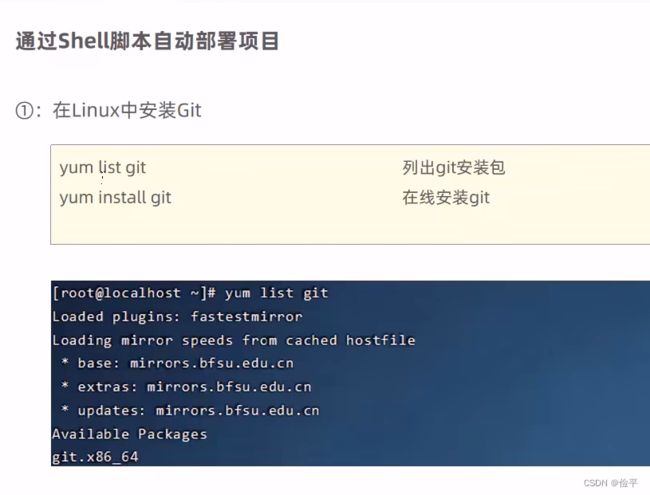
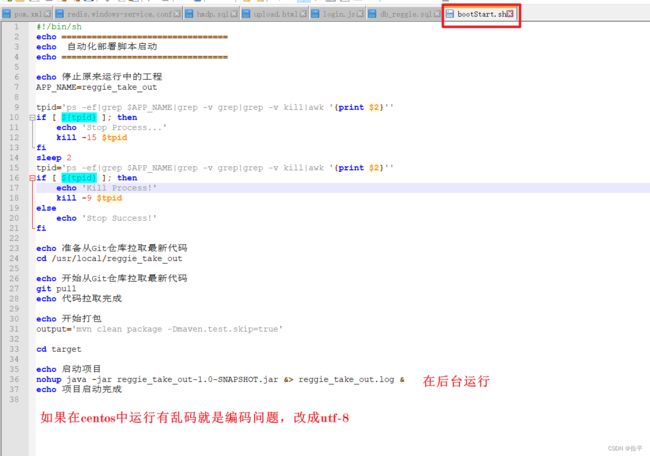
自动



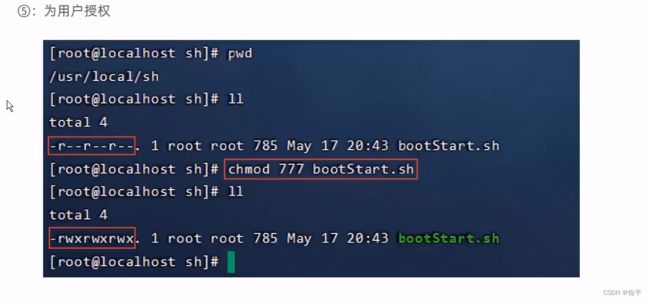
使用命令rz上传文件,使用chmod 777 bootStart.sh对文件进行授权,使用./bootStart.sh执行bootStart.sh文件,
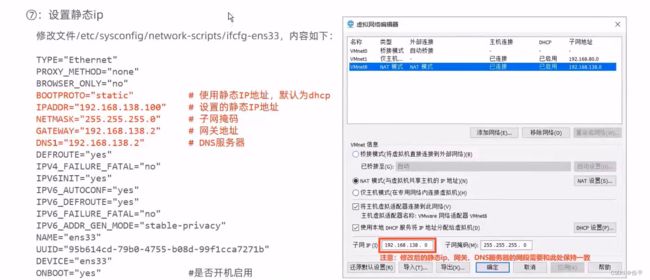
Redis






redis远程连接,
补充知识(小细节)
在实体类上注Data注解,可以Autowired注入Service对象,但是在实体类上注Component注解,不可以用Autowired注入Service对象。
Data注解的作用
PathVariable注解的作用
lombok
session
session.setAttribute()和session.getAttribute()的使用?
B/S架构中,客户端与服务器连接,在服务端就会自动创建一个session对象. session.setAttribute(“username”,username); 是将username保存在session中!session的key值为“username”value值就是username真实的值,或者引用值. 这样以后你可以通过session.getAttribute(“username”)的方法获得这个对象. 比如说,当用户已登录系统后你就在session中存储了一个用户信息对象,此后你可以随时从session中将这个对象取出来进行一些操作,比如进行身 份验证等等.
1、request.getSession()可以帮你得到HttpSession类型的对象,通常称之为session对象,session对 象的作用域为一次会话,通常浏览器不关闭,保存的值就不会消失,当然也会出现session超时。服务器里面可以设置session的超时时 间,web.xml中有一个session time out的地方,tomcat默认为30分钟
2、session.setAttribute(“key”,value);是session设置值的方法,原理同java中的HashMap的键值对, 意思也就是key现在为“user”;存放的值为userName,userName应该为一个String类型的变量吧?看你自己的定义。 3、可以使用session.getAttribute(“key”);来取值,意味着你能得到userName的值。
4、注意:getAttribute的返回值类型是Object,需要向下转型,转成你的userName类型的,简单说就是存什么,取出来还是什么。
5、setAttribute和getAttribute就是基于HashMap的put方法和get方法实现的,一般叫键值对或者key-value, 即通过键找到值。例如你的名字和你的人的关系,只要一叫你的名字,你就会喊到,通过你的名字来找你的人,简单说这就是键值对的概念。
注意:
session.getAttribute(“”)
取到的类型是是object
所以赋值前要强转一下
如:
String session1= (String)session.getAttribute(“student”) ;