Lamp架构——mysql高可用切换(MHA高可用)
mysql高可用切换(MHA高可用)
- MHA介绍
- 一、安装软件,搭建环境
-
- 1.节点1(server5)配置mysql的master端
- 2.节点2(server6)配置mysql的slave端
- 2.节点3(server7)配置mysql的slave端
- 4.节点4(server8)安装MHA软件(server8作为MHA的管理端)
- 5.管理端安装的Manager工具包和数据库节点端安装的Node工具包主要包含工具
- 二、管理端创建配置文件,实现管理,并进行脚本检测
-
- 1.管理端创建配置文件
- 2.脚本检测
- 3.重启所有主机后,状态检查
- 三、手动切换
-
- 1.master还活着进行切换
- 2.master端挂掉时进行切换
- 四、vip漂移脚本测试
-
- 1.后台进程监控自动切换测试
- 2.手动切换vip漂移脚本测试
- 3.自动切换vip漂移脚本测试
MHA介绍
MHA解决了mysql数据库主从架构下单点故障,提高了数据的安全性
MHA概念
MHA(MasterHigh Availability)是一套优秀的MySQL高可用环境下故障切换和主从复制的软件。
MHA 的出现就是解决MySQL 单点的问题。
MySQL故障切换过程中,MHA能做到0-30秒内自动完成故障切换操作。
MHA能在故障切换的过程中最大程度上保证数据的一致性,以达到真正意义上的高可用。
MHA 的组成
MHA Node(数据节点)
MHA Node 运行在每台 MySQL 服务器上。
MHA Manager(管理节点)
MHA Manager 可以单独部署在一台独立的机器上,管理多个 master-slave 集群;也可以部署在一台 slave 节点上。
MHA Manager 会定时探测集群中的 master 节点。当 master 出现故障时,它可以自动将最新数据的 slave 提升为新的 master, 然后将所有其他的 slave 重新指向新的 master。整个故障转移过程对应用程序完全透明。
MHA 的特点
- 自动故障切换过程中,MHA试图从宕机的主服务器上保存二进制日志,最大程度的保证数据不丢失
- 使用半同步复制,可以大大降低数据丢失的风险,只要有一个slave已经收到了最新的二进制日志,MHA就可以将最新的二进制日志应用于其他所有的slave服务器上,因此可以保证所有节点的数据一致性
- 目前MHA支持一主多从架构,最少三台服务,即一主两从
实验环境及安装包
| 节点 | 操作系统 | IP地址 | 安装包 / 软件 / 工具 |
|---|---|---|---|
| MHAmanager | rhel7.6 | 172.25.254.4 | MHAnode组件、MHAmanager组件 |
| master | rhel7.6 | 172.25.254.1 | mysql-boost-5.7.20.tar.gz、MHAnode组件 |
| slave1 | rhel7.6 | 172.25.254.2 | mysql-boost-5.7.20.tar.gz、MHAnode组件 |
| slave2 | rhel7.6 | 172.25.254.3 | mysql-boost-5.7.20.tar.gz、MHAnode组件 |
一、安装软件,搭建环境
一主两从的mysql集群架构设置
因为之前实验构建的组复制架构,所以需要重新设置成一主两从的架构。把所有节点上的mysql服务关闭,并把/data/mysql 中的数据删除干净,重新设置初始化.
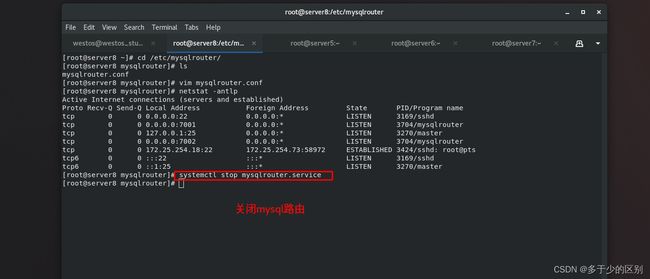
1.节点1(server5)配置mysql的master端
关闭节点1(server5)的mysql,修改配置文件


并清空数据目录,初始化数据库,启动数据库并修改管理员密码

创建用户并授权

2.节点2(server6)配置mysql的slave端
关闭mysql,清空数据目录,修改配置文件
[root@server6 ~]# /etc/init.d/mysqld stop
Shutting down MySQL............ SUCCESS!
[root@server6 ~]# cd /data/mysql/
[root@server6 mysql]# rm -fr *
[root@server6 mysql]# ls
[root@server6 mysql]# vim /etc/my.cnf
[mysqld]
datadir=/data/mysql
socket=/data/mysql/mysql.sock
symbolic-links=0
server_id=2
gtid_mode=ON
enforce_gtid_consistency=ON
master_info_repository=TABLE
relay_log_info_repository=TABLE
log_slave_updates=ON
log_bin=binlog
binlog_format=ROW
 初始化数据库,启动mysql,修改管理员密码
初始化数据库,启动mysql,修改管理员密码
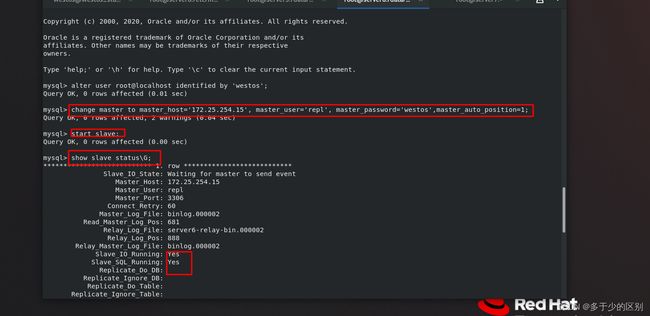
 修改master信息,启动slave,查看slave状态
修改master信息,启动slave,查看slave状态
2.节点3(server7)配置mysql的slave端
关闭mysql,清空数据目录,修改配置文件
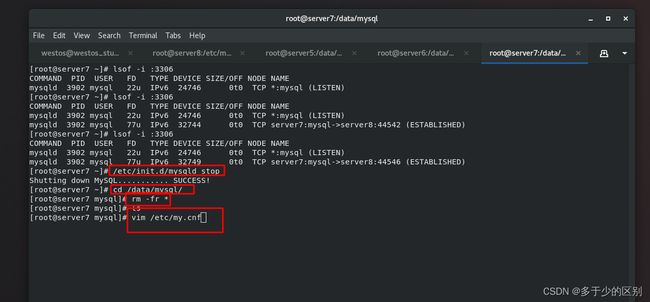 主从切换涉及到,节点1挂掉后1,需要节点2或者3自动接管,接管之后成为master,每个节点都可能成为master,都需要开二进制日志
主从切换涉及到,节点1挂掉后1,需要节点2或者3自动接管,接管之后成为master,每个节点都可能成为master,都需要开二进制日志

初始化mysql,开启mysql,修改管理员用户密码
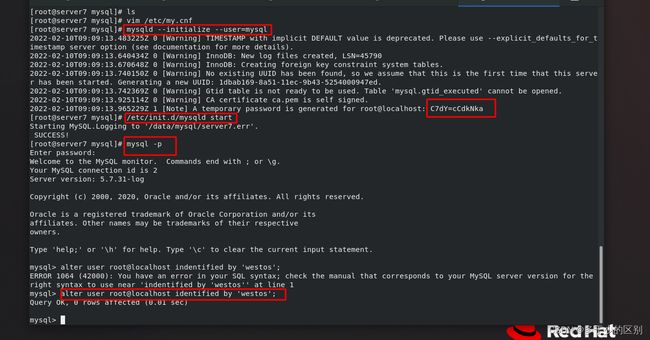
修改master信息,启动slave,查看slave状态

节点1创建repl用户的动作记录到二进制日志中了,所以节点2和3也都有repl用户

4.节点4(server8)安装MHA软件(server8作为MHA的管理端)
MHA-7是针对企业7版本,代码里边已经限制了架构必须是一主两从的架构,也可以一主一从,阿里就是修改了代码,数据池里边就是一主一从,每个实例都有一个备机,动态的,自动进行高可用。
 管理端(server8)安装rpm包
管理端(server8)安装rpm包
 设置免密
设置免密
免密是有需求的,后面mha软件在工作时要求管理节点可以免密连接所有的数据库节点。
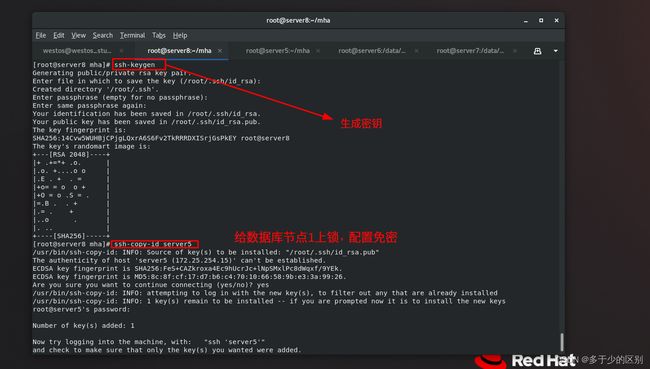

所有的数据库节点安装node节点rpm包
 数据库节点1安装node节点rpm包
数据库节点1安装node节点rpm包

数据库节点2安装node节点rpm包
 数据库节点3安装node节点rpm包
数据库节点3安装node节点rpm包

数据库节点上不需要启什么进程,这些包只是装了一些二进制命令。
5.管理端安装的Manager工具包和数据库节点端安装的Node工具包主要包含工具

二、管理端创建配置文件,实现管理,并进行脚本检测
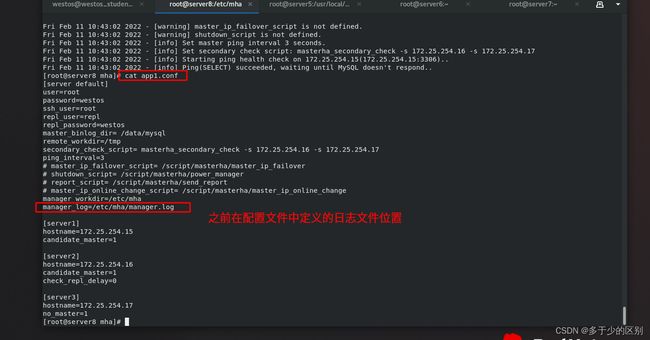
1.管理端创建配置文件
创建配置目录/etc/mha
[root@server8 mha]# pwd
/etc/mha
[root@server8 mha]# ls
app1.conf
[root@server8 mha]# vim app1.conf
[server default]
user=root
password=westos
ssh_user=root
repl_user=repl
repl_password=westos
master_binlog_dir= /data/mysql
remote_workdir=/tmp
secondary_check_script= masterha_secondary_check -s 172.25.254.16 -s 172.25.254.17
ping_interval=3
# master_ip_failover_script= /script/masterha/master_ip_failover
# shutdown_script= /script/masterha/power_manager
# report_script= /script/masterha/send_report
# master_ip_online_change_script= /script/masterha/master_ip_online_change
manager_workdir=/etc/mha
manager_log=/etc/mha/manager.log
[server1]
hostname=172.25.254.15
candidate_master=1
[server2]
hostname=172.25.254.16
candidate_master=1
check_repl_delay=0
[server3]
hostname=172.25.254.17
no_master=1





2.脚本检测
mha的环境有没有准备好,需要用两个脚本进行检测,查看执行结果
运行脚本检测免密访问环境
[root@server8 mha]# masterha_check_ssh --conf=/etc/mha/app1.conf
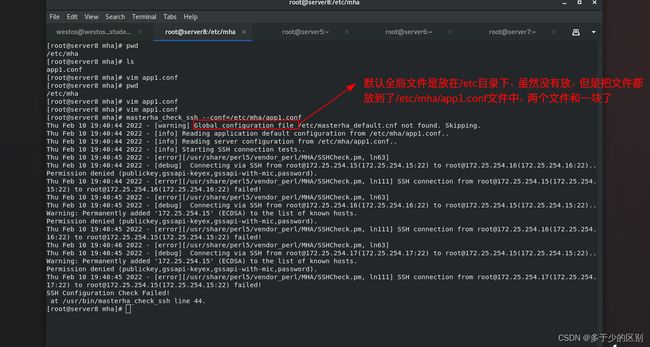
提示有错误,这个节点是用来检测节点间的免密的,刚才只是做了管理端server8免密访问数据库节点server5、server6、server7。
 数据库节点免密访问设置,所有节点的密钥用的是一对
数据库节点免密访问设置,所有节点的密钥用的是一对


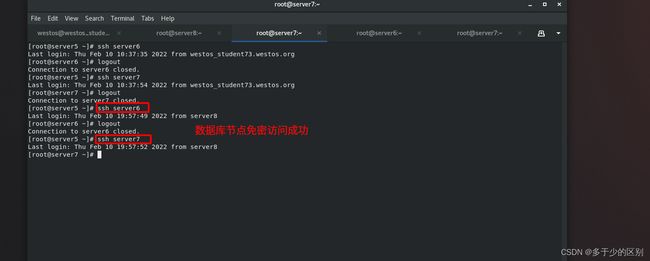
再次运行脚本,检测免密访问

运行脚本,检测数据库主从集群的配置
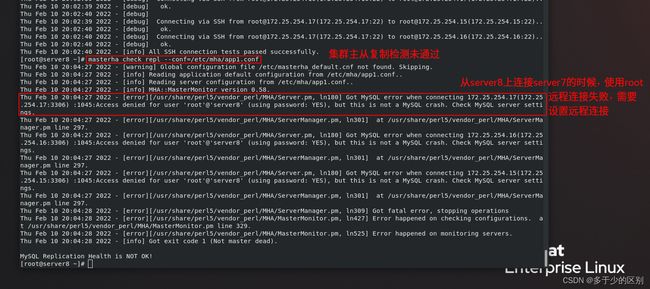
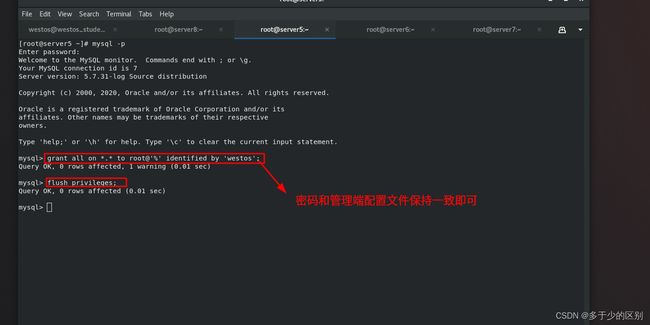
数据库节点对远程连接进行授权,在master端操作即可
mysql> grant all on *.* to root@'%' identified by 'westos';
mysql> flush privileges;
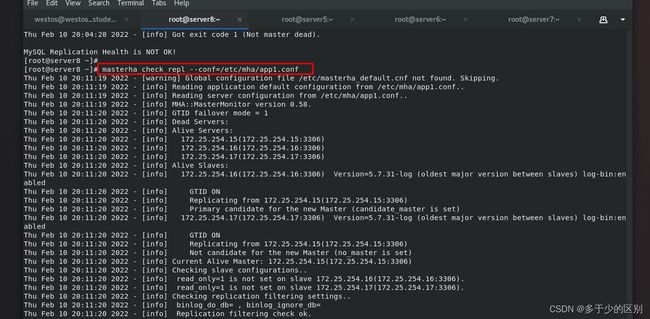
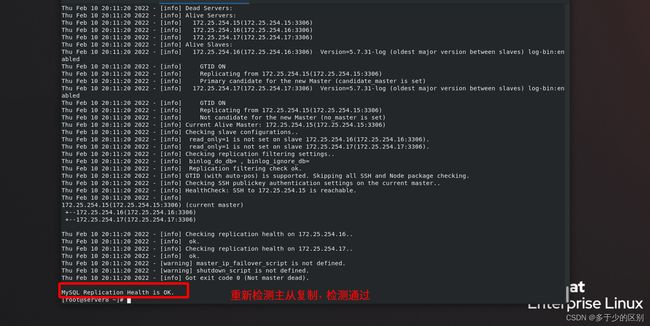

3.重启所有主机后,状态检查
在上述设定完毕后,如果重启了主机,需要重新启动各个数据库节点的mysql,并检查节点1的master状态以及节点2、3的slave状态。
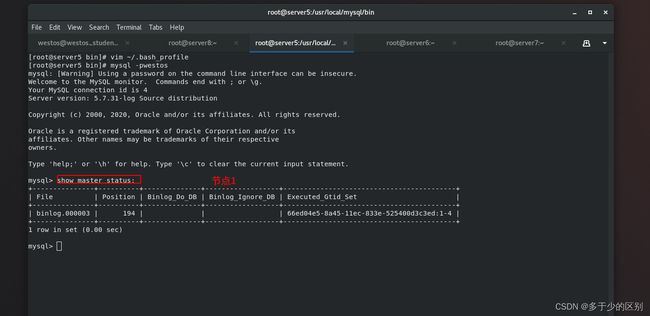

管理端脚本检测连通性(节点无密连接检测)
[root@server8 ~]# masterha_check_ssh --conf=/etc/mha/app1.conf

管理端脚本检测数据库主从复制状态
[root@server8 ~]# masterha_check_repl --conf=/etc/mha/app1.conf


三、手动切换
从严谨考虑选择手动切换比自动切换好,因为数据库可能会不一致,MHA的机制比较好,自动切换也是靠谱的,MHA不是新技术,但是技术成熟、稳定一致在用。
MHA手动切换有两种情况,一种是master还活着,一种是master已经挂了。
1.master还活着进行切换
[root@server8 ~]# masterha_master_switch --conf=/etc/mha/app1.conf --master_state=alive --new_master_host=172.25.254.16 --new_master_port=3306 --orig_master_is_new_slave --running_updates_limit=10000
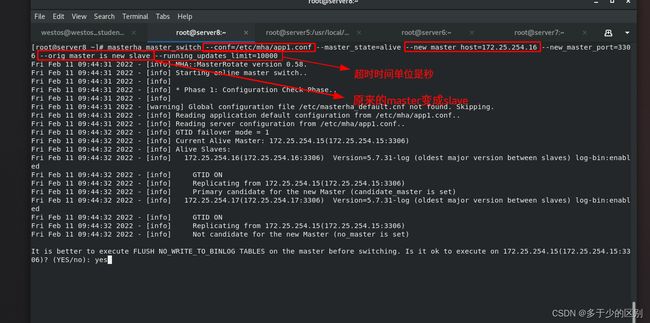
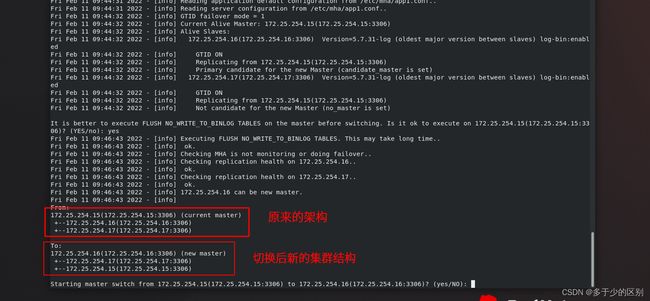

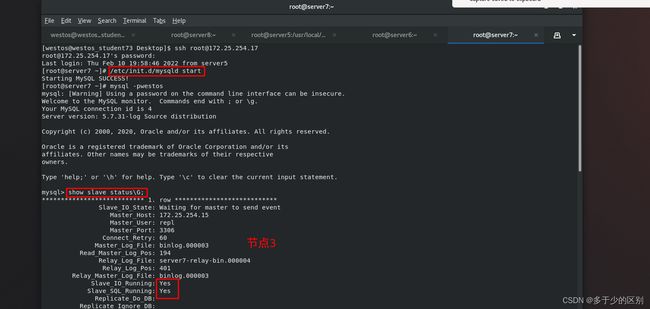
查看各节点状态
节点2(server6)已经成为新的master
 节点3(server7)查看
节点3(server7)查看
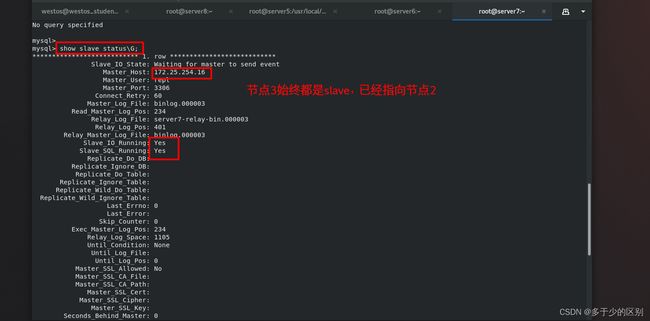 节点1(server5)查看
节点1(server5)查看

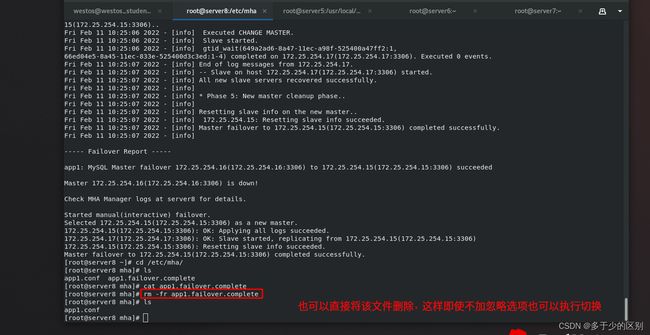
2.master端挂掉时进行切换
制造问题,当master端节点2挂掉时
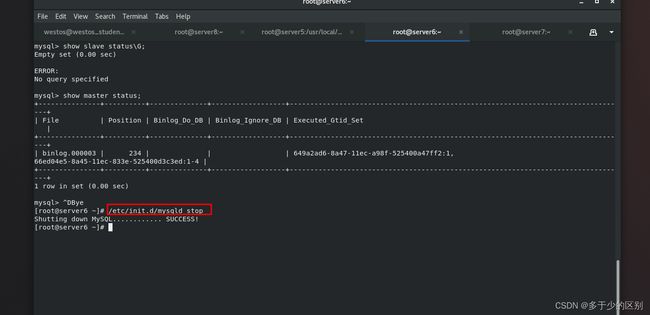
 管理端手动切换
管理端手动切换
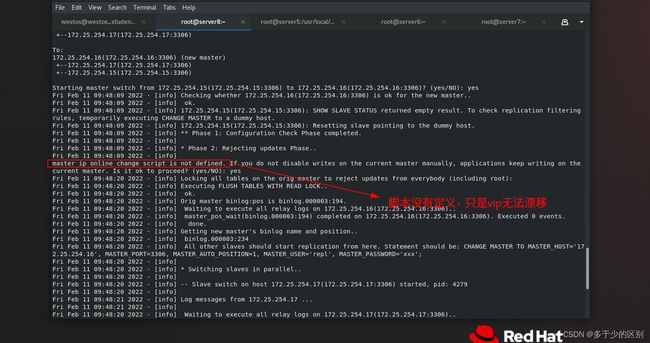
[root@server8 ~]# masterha_master_switch --master_state=dead --conf=/etc/mha/app1.conf --dead_master_host=172.25.254.16 --dead_master_port=3306 --new_master_host=172.25.254.15 --new_master_port=3306 --ignore_last_failover
master挂掉后,如果通过重配置进行切换,一方面是慢,肯定没有脚本快,而且down掉后,其他节点的数据不一致现象,主从是有延迟的,做数据压力测试就会发现延迟很高。MHA会自动应用不一样的日志,自动解决数据同步问题,MHA的逻辑是先把数据一致性搞定,然后再发起切换,数据不一致时,不能进行切换。大厂的数据库的高可用切换逻辑,一定会把高可用切换的操作打成原子操作,也就是不可被截断,先保证数据一致性后,再发起切换,中间不可被打断。


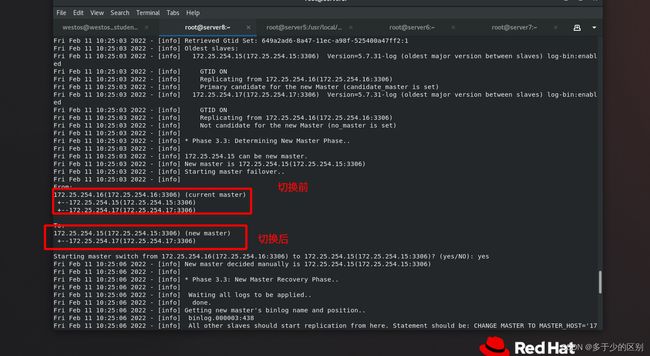
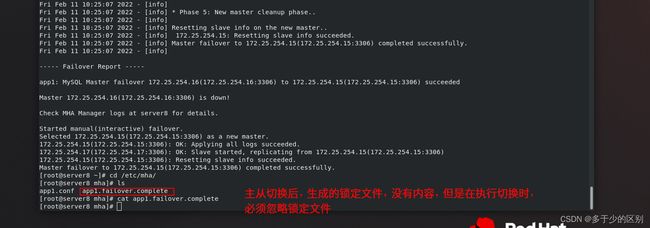
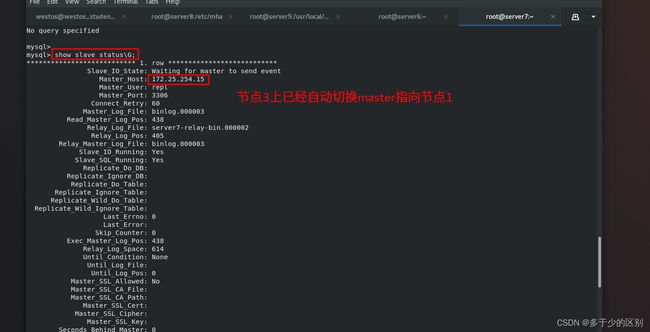
节点3已经指向节点1

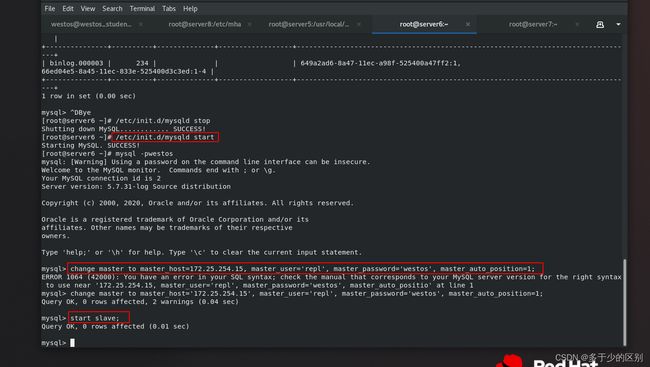
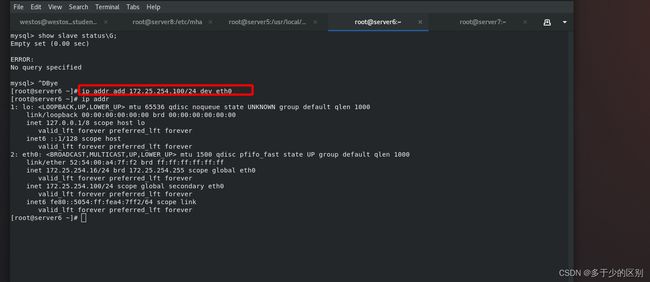
节点2(server6)down掉后,不能像之前活着时自动执行change master to语句,需要手动执行
[root@server6 ~]# /etc/init.d/mysqld start
Starting MySQL. SUCCESS!
[root@server6 ~]# mysql -pwesto
mysql> change master to master_host='172.25.254.15', master_user='repl', master_password='westos', master_auto_position=1;
mysql> start slave;
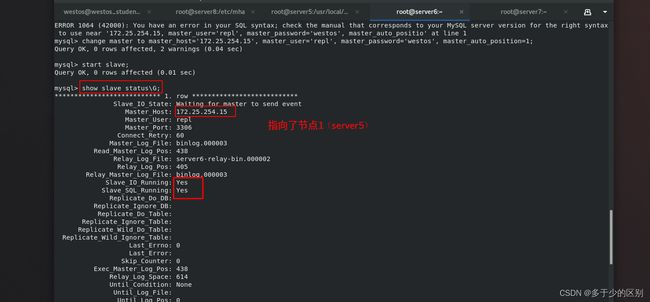
四、vip漂移脚本测试
1.后台进程监控自动切换测试
在后台进程自动故障切换过程中,会生成日志信息。
启动后端程序,监控集群,当master端故障时,完成自动切换
[root@server8 mha]# masterha_manager --conf=/etc/mha/app1.conf &

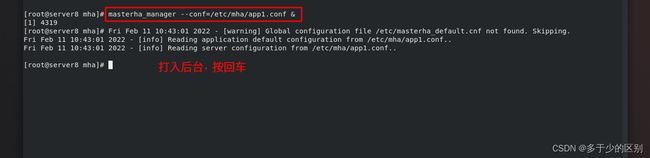
该进程正在监控集群


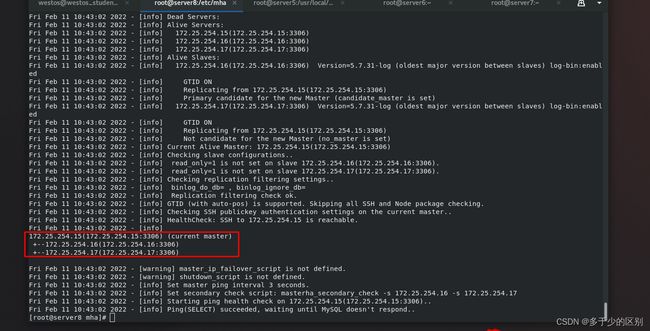
down掉master节点(节点1:server5)进行测试
 后台进程之所以会退出,是因为如果进程一直在,会在故障时自动进行切换,所以切换1完成后自动退出,只作一次自动切换,防止进行频繁切换
后台进程之所以会退出,是因为如果进程一直在,会在故障时自动进行切换,所以切换1完成后自动退出,只作一次自动切换,防止进行频繁切换
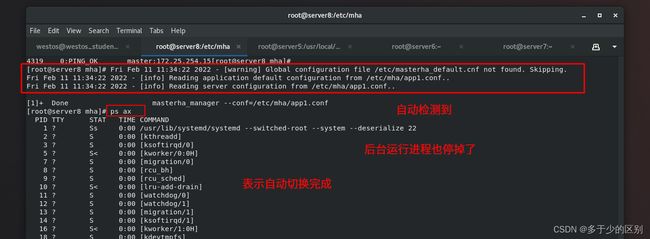
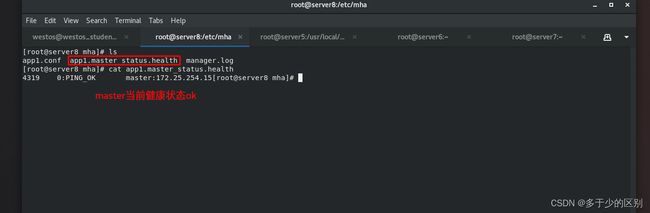
只有在故障切换后,才会生成app1.failover.complete锁定文件


查看节点信息

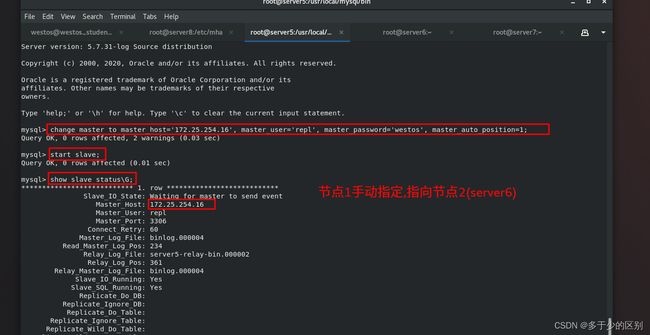
 节点1(server5)需要手动打开并添加至集群,指向节点2
节点1(server5)需要手动打开并添加至集群,指向节点2
 MHA必须要一主两从的架构,保证可用性,如果想用一主一从,需要改源代码
MHA必须要一主两从的架构,保证可用性,如果想用一主一从,需要改源代码

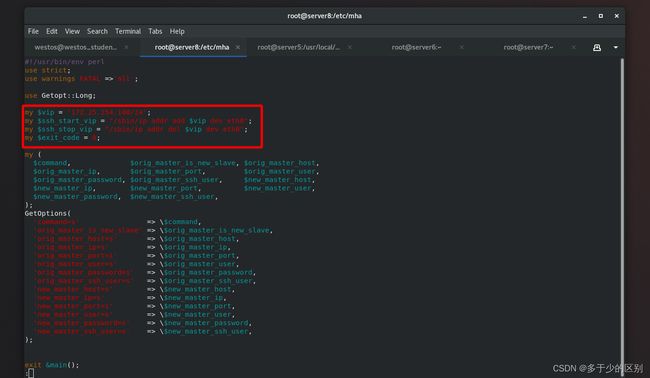
 管理端修改配置文件,指定脚本位置
管理端修改配置文件,指定脚本位置
 自动切换和手动切换脚本中都有vip漂移语句
自动切换和手动切换脚本中都有vip漂移语句
 在指定目录下放置脚本并赋予执行权限
在指定目录下放置脚本并赋予执行权限


查看自动切换脚本master_ip_failover
[root@server8 mha]# vim master_ip_failover

查看手动切换脚本master_ip_online_change
[root@server8 mha]# vim master_ip_online_change
2.手动切换vip漂移脚本测试
现在节点2是master,节点1和3是slave,现在把master切回节点1,根据设置节点3不能成为master
手动切换脚本测试
给master端(节点2:server6)加vip
 外部访问测试
外部访问测试

手动切换测试
[root@server8 mha]# masterha_master_switch --conf=/etc/mha/app1.conf --master_state=alive --new_master_host=172.25.254.15 --new_master_port=3306 --orig_master_is_new_slave --running_updates_limit=10000

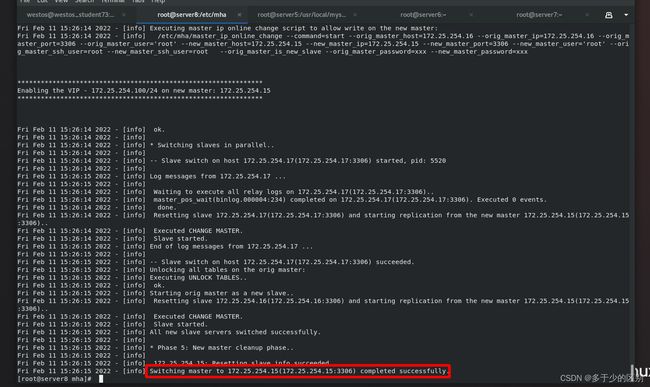
客户端进行重新查询测试

查看数据库节点信息
节点1
 节点2
节点2


3.自动切换vip漂移脚本测试
启动后台程序
[root@server8 mha]# masterha_manager --conf=/etc/mha/app1.conf &


关闭master进行测试

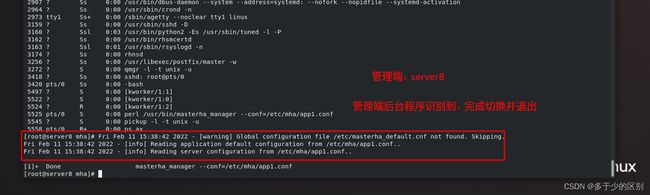

 查看节点信息
查看节点信息
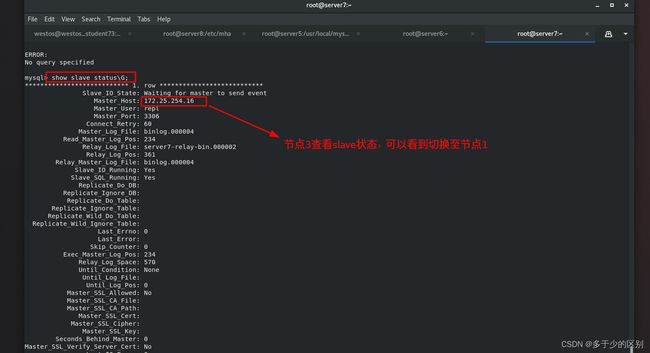
切换时,切记要么删除锁定文件app1.failover.complete,要么加选项–ignore_last_failover
节点2(server6)可以看到vip自动漂移至节点2(server6)上
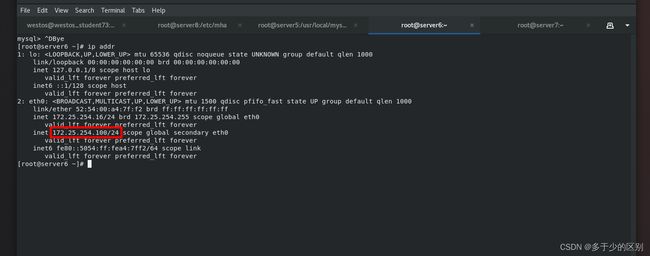 节点1vip被收回
节点1vip被收回

