lamp架构--mysql主从复制(慢查询,mysql路由器,MHA高可用)
文章目录
-
-
- 1. 慢查询
- 2. mysql路由器
-
- 2.1 原理图
- 2.2 下载路由安装包
- 2.3 安装、配置路由
- 2.4 测试
- 3. MHA高可用
-
- 3.1 介绍
- 3.2 一主俩从的搭建
- 3.3 MHA环境的搭建
- 4. MHA高可用的切换
-
- 4.1 手动切换
-
- 4.1.1 master活着
- 4.1.2 master down掉
- 4.2 自动切换
- 4.3 通过vip进行自动、手动的切换
-
- 4.3.1 通过vip 进行手动切换
- 4.3.2 通过vip 进行自动切换
-
1. 慢查询
[root@server11 ~]# /etc/init.d/mysqld start
[root@server12 ~]# /etc/init.d/mysqld start
[root@server13 ~]# /etc/init.d/mysqld start
Starting MySQL SUCCESS!
[root@server11 ~]# mysql -pwestos
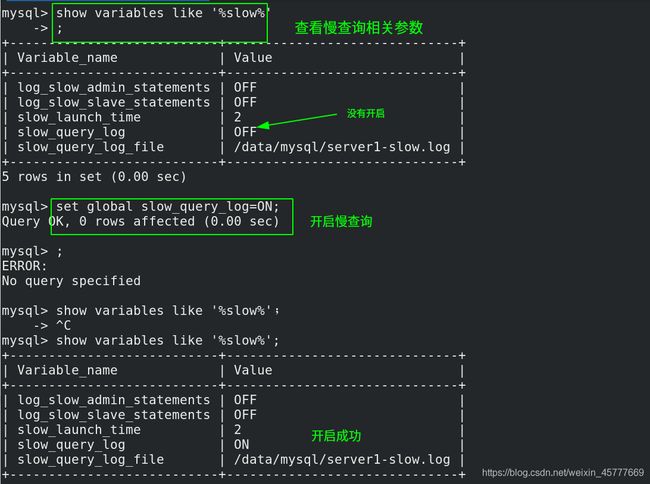
mysql> show variables like 'slow%'; ##查看慢查询相关参数
mysql> set global slow_query_log=ON; ##开启慢查询
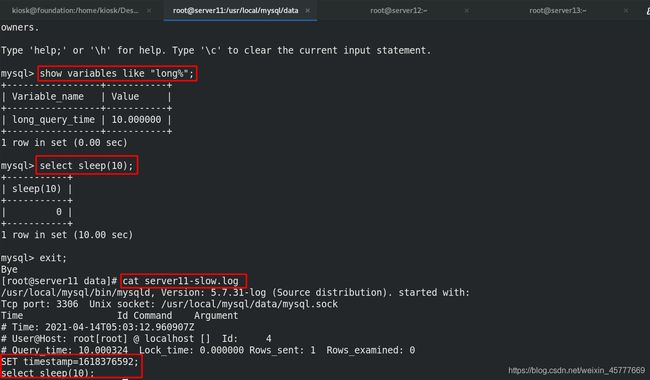
mysql> show variables like "long%"; ##查看慢查询的时间,默认为10s;
mysql> select sleep(10);
[root@server11 data]# pwd
/usr/local/mysql/data
[root@server11 data]# cat server11-slow.log ##查看慢查询的日志文件,有记录的日志信息
2. mysql路由器
2.1 原理图

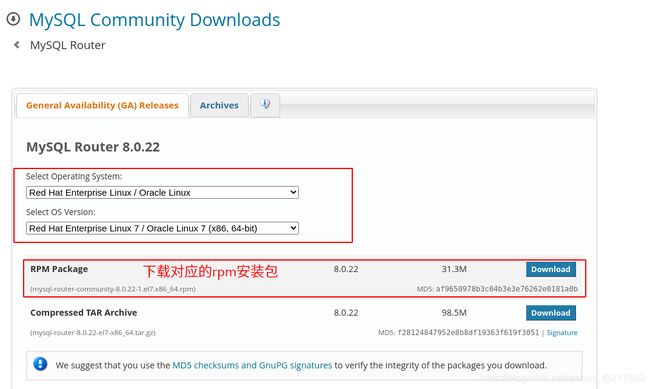
2.2 下载路由安装包
- 安装:
# rpm -ivh mysql-router-community-8.0.21-1.el7.x86_64.rpm
mysql原装的路由
- 配置:(读写分离)
# vim /etc/mysqlrouter/mysqlrouter.conf
[routing:ro] ##进行只读时候选择7001端口
bind_address = 0.0.0.0
bind_port = 7001
destinations = 172.25.0.1:3306,172.25.0.2:3306,172.25.0.3:3306
routing_strategy = round-robin ##采用的负载均衡的模式
[routing:rw] ##进行读写的时候采用7002端口
bind_address = 0.0.0.0
bind_port = 7002
destinations = 172.25.0.1:3306,172.25.0.2:3306,172.25.0.3:3306
routing_strategy = first-available ##第一可用模式,1不可用了才往2里面写
- 不止可以使用多主模式。也可以使用主从复制


2.3 安装、配置路由
[root@server11 data]# mysql -pwestos
mysql> SELECT * FROM performance_schema.replication_group_members;
mysql> STOP GROUP_REPLICATION;
mysql> SET GLOBAL group_replication_bootstrap_group=ON;
mysql> START GROUP_REPLICATION;
mysql> SET GLOBAL group_replication_bootstrap_group=OFF;
server12 :mysql> START GROUP_REPLICATION;
server13: mysql> START GROUP_REPLICATION;

添加server14作为路由器
[root@server14 ~]# rpm -ivh mysql-router-community-8.0.21-1.el7.x86_64.rpm ##安装路由
[root@server14 ~]# cd /etc/mysqlrouter/ ##进入配置目录,编写配置文件
[root@server14 mysqlrouter]# ls
mysqlrouter.conf
[root@server14 mysqlrouter]# vim mysqlrouter.conf
[keepalive]
interval = 60 ##高可用,60s切换主机
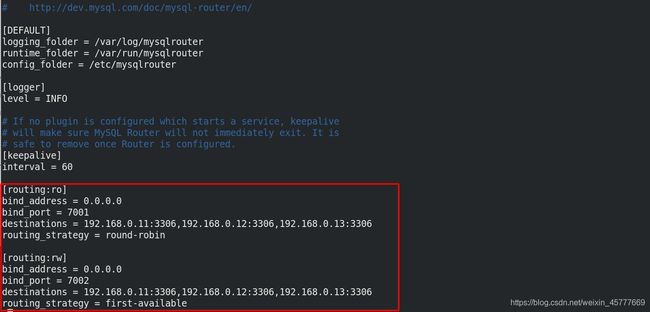
[routing:ro]
bind_address = 0.0.0.0
bind_port = 7001 ##通过端口访问
destinations = 192.168.0.11:3306,192.168.0.12:3306,192.168.0.13:3306 ##配合后端组复制
routing_strategy = round-robin ##round-robin负载均衡
[routing:rw]
bind_address = 0.0.0.0
bind_port = 7002
destinations = 192.168.0.11:3306,192.168.0.12:3306,192.168.0.13:3306
routing_strategy = first-available
[root@server14 mysqlrouter]# systemctl start mysqlrouter.service ##启动服务
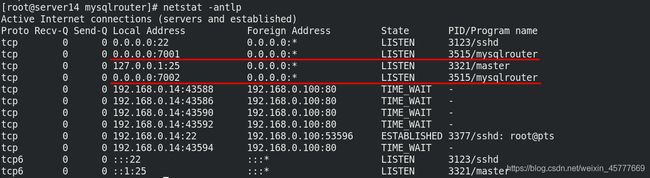
[root@server14 mysqlrouter]# netstat -antlp ##查看7001 7002端口
tcp 0 0 0.0.0.0:7001 0.0.0.0:* LISTEN 3515/mysqlrouter
tcp 0 0 0.0.0.0:7002 0.0.0.0:* LISTEN 3515/mysqlrouter
如果第一个主机server11挂掉,自动转换成server12。
建立一个用户,作为客户端访问后端数据库的授权用户,多主模式下server12,server13会自动同步建立用户。
server11
mysql> grant select on *.* to user11@'%' identified by 'westos';
mysql> grant all on test.* to user12@'%' identified by 'westos';##可写
mysql> flush privileges;
2.4 测试
真机远程登陆数据库
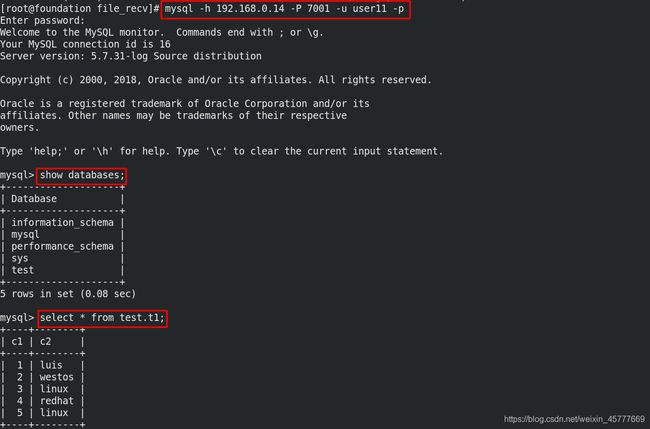
[root@foundation file_recv]# mysql -h 192.168.0.14 -P 7001 -u user11 -p
mysql> show databases;
mysql> select * from test.t1;
访问成功
[root@foundation file_recv]# mysql -h 192.168.0.14 -P 7002 -u user12 -p
mysql> show databases;
mysql> use test;
mysql> insert into t1 values (6,'redhat');
真机远程插入数据,server11 12 13 同步成功
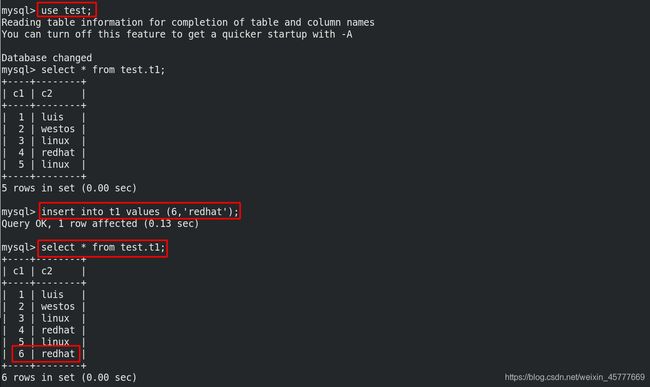
重复登陆退出,server11 server12 server13 轮询可读
[root@foundation file_recv]# mysql -h 192.168.0.14 -P 7001 -u user11 -p
[root@server11 data]# yum install -y lsof
[root@server11 data]# lsof -i :3306
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
mysqld 3938 mysql 30u IPv6 44930 0t0 TCP *:mysql (LISTEN)
mysqld 3938 mysql 80u IPv6 47390 0t0 TCP server11:mysql->server14:57662 (ESTABLISHED)
[root@server12 ~]# lsof -i :3306
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
mysqld 8947 mysql 29u IPv6 43398 0t0 TCP *:mysql (LISTEN)
mysqld 8947 mysql 55u IPv6 45132 0t0 TCP server12:mysql->server14:47216 (ESTABLISHED)
[root@server13 ~]# lsof -i :3306
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
mysqld 8939 mysql 14u IPv6 42861 0t0 TCP *:mysql (LISTEN)
mysqld 8939 mysql 56u IPv6 43644 0t0 TCP server13:mysql->server14:38874 (ESTABLISHED)



server11挂掉 选择一个节点接管主节点角色
[root@server11 data]# /etc/init.d/mysqld stop
Shutting down MySQL............ SUCCESS!
[root@foundation file_recv]# mysql -h 192.168.0.14 -P 7001 -u user11 -p 连接正常
[root@server12 ~]# lsof -i :3306 ##连接的为server12
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
mysqld 8947 mysql 29u IPv6 43398 0t0 TCP *:mysql (LISTEN)
mysqld 8947 mysql 55u IPv6 46261 0t0 TCP server12:mysql->server14:47222 (ESTABLISHED)



3. MHA高可用
3.1 介绍

3.2 一主俩从的搭建
[root@server12 ~]# /etc/init.d/mysqld stop ##停止服务
[root@server13 ~]# /etc/init.d/mysqld stop
[root@server14 ~]# systemctl stop mysqlrouter.service ##server14配置
server11 12 13 作同样操作
[root@server11 data]# pwd
/usr/local/mysql/data
[root@server11 data]# rm -fr * ##删除数据库文件
[root@server11 data]# vim /etc/my.cnf ##修改配置文件
[mysqld]
datadir=/usr/local/mysql/data
socket=/usr/local/mysql/data/mysql.sock
symbolic-links=0
server_id=1 ##server_id=1 2 3 对应server11 12 13
gtid_mode=ON
enforce_gtid_consistency=ON
master_info_repository=TABLE
relay_log_info_repository=TABLE
log_slave_updates=ON
log_bin=binlog
binlog_format=ROW
[root@server11 data]# mysqld --initialize --user=mysql ##初始化
[root@server11 data]# /etc/init.d/mysqld start ##启动数据库
[root@server11 data]# mysql_secure_installation
[root@server11 data]# mysql -p ##登陆数据库
mysql> ALTER USER root@localhost identified by 'westos';##修改数据库登陆密码
mysql> show master status;
mysql> grant replication slave on *.* to repl@'%' identified by 'westos';##主master的设置
server12 13 作同样操作
[root@server12 data]# mysql -p
mysql> ALTER USER root@localhost identified by 'westos';
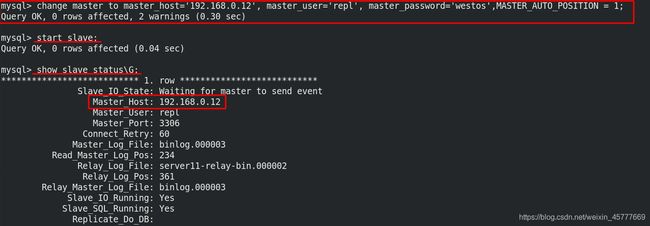
mysql> change master to master_host='192.168.0.11', master_user='repl', master_password='westos',MASTER_AUTO_POSITION = 1;
mysql> start slave; ##配置slave并启动
mysql> show slave status\G;
配置成功

3.3 MHA环境的搭建
- Manager工具包主要包括以下几个工具:
masterha_check_ssh //检查MHA的SSH配置状况
masterha_check_repl //检查MySQL复制状况
masterha_manger //启动MHA
masterha_check_status //检测当前MHA运行状态
masterha_master_monitor //检测master是否宕机
masterha_master_switch //控制故障转移(自动或者手动)
masterha_conf_host //添加或删除配置的server信息
- Node工具包(由MHA Manager的脚本触发,无需人为操作)主要包括以下几个工具:
save_binary_logs //保存和复制master的二进制日志
apply_diff_relay_logs //识别差异的中继日志事件并将其差异的事件应用于其他的slave
filter_mysqlbinlog //去除不必要的ROLLBACK事件(MHA已不再使用这个工具)
purge_relay_logs //清除中继日志(不会阻塞SQL线程)
server14作为MHA控制端的配置
[root@server14 ~]# tar zxvf mha.tgz
[root@server14 MHA-7]# ls
mha4mysql-manager-0.58-0.el7.centos.noarch.rpm perl-Mail-Sender-0.8.23-1.el7.noarch.rpm
mha4mysql-manager-0.58.tar.gz perl-Mail-Sendmail-0.79-21.el7.noarch.rpm
mha4mysql-node-0.58-0.el7.centos.noarch.rpm perl-MIME-Lite-3.030-1.el7.noarch.rpm
perl-Config-Tiny-2.14-7.el7.noarch.rpm perl-MIME-Types-1.38-2.el7.noarch.rpm
perl-Email-Date-Format-1.002-15.el7.noarch.rpm perl-Net-Telnet-3.03-19.el7.noarch.rpm
perl-Log-Dispatch-2.41-1.el7.1.noarch.rpm perl-Parallel-ForkManager-1.18-2.el7.noarch.rpm
[root@server14 MHA-7]# yum isntall -y *.rpm

server14配置MHA
server11 12 13
[root@server14 MHA-7]# scp mha4mysql-node-0.58-0.el7.centos.noarch.rpm 192.168.0.11:
[root@server11 ~]# yum install -y mha4mysql-node-0.58-0.el7.centos.noarch.rpm
[root@server14 MHA-7]# rpm -ql mha4mysql-manager
[root@server14 MHA-7]# mkdir /etc/masterha
[root@server14 masterha]# cd -
/root/MHA-7
[root@server14 MHA-7]# tar zxf mha4mysql-manager-0.58.tar.gz
[root@server14 MHA-7]# cd mha4mysql-manager-0.58/samples/conf
[root@server14 conf]# ls
app1.cnf masterha_default.cnf
[root@server14 conf]# cat masterha_default.cnf app1.cnf > /etc/masterha/app.cnf
[root@server14 conf]# cd /etc/masterha/
[root@server14 masterha]# vim app.cnf
[server default]
user=root #mysql主从节点的管理员用户密码,确保可以从远程登陆
password=westos ##访问数据库的管理员用户密码
ssh_user=root ##免密 ssh用户名
repl_user=repl ###主从复制用户密码
repl_password=westos
master_binlog_dir= /usr/local/mysql/data #mysql主服务器的binlog目录
remote_workdir=/tmp #远端mysql在发生切换时binlog的保存位置
secondary_check_script= masterha_secondary_check -s 192.168.0.11 -s 192.168.0.12
ping_interval=3 #发送ping包的时间间隔,默认是3秒,
# master_ip_failover_script= /script/masterha/master_ip_failover #failover自动切换脚本
# shutdown_script= /script/masterha/power_manager #故障发生后关闭故障主机脚本,防止脑裂
# report_script= /script/masterha/send_report #发生切换后发送报警的脚本
# master_ip_online_change_script= /script/masterha /master_ip_online_change #手动切换脚本
manager_workdir=/etc/masterha/app1 #manager工作目录
manager_log=/etc/masterha/app1/manager.log #manager日志文件
[server11]
hostname=192.168.0.11
[server12]
hostname=192.168.0.12
candidate_master=1 #指定failover时此slave会接管master,即使数据不是最新的。
#check_repl_delay=0 #默认情况下如果一个slave落后master 100M的relay logs的话,MHA将不会选择该slave作为一个新的master,因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的master
[server13]
hostname=192.168.0.13
no_master=1 #始终是slave
[root@server14 masterha]# mkdir app1

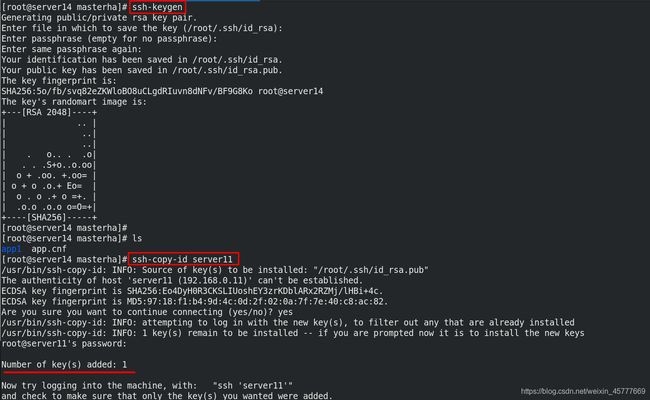
[root@server14 masterha]# ssh-keygen ##设置免密认证
[root@server14 masterha]# ssh-copy-id server11
[root@server14 masterha]# ssh-copy-id server12
[root@server14 masterha]# ssh-copy-id server13
[root@server14 ~]# scp -r .ssh/ server11: ##使用同一个密钥
[root@server14 ~]# scp -r .ssh/ server12:
[root@server14 ~]# scp -r .ssh/ server13:
[root@server14 masterha]# masterha_check_ssh --conf=/etc/masterha/app.cnf ##所有节点之间都必须免密
[root@server11 ~]# mysql -pwestos
mysql> grant all on *.* to root@'%' identified by 'westos';
mysql> flush privileges;
[root@server14 ~]# masterha_check_repl --conf=/etc/masterha/app.cnf
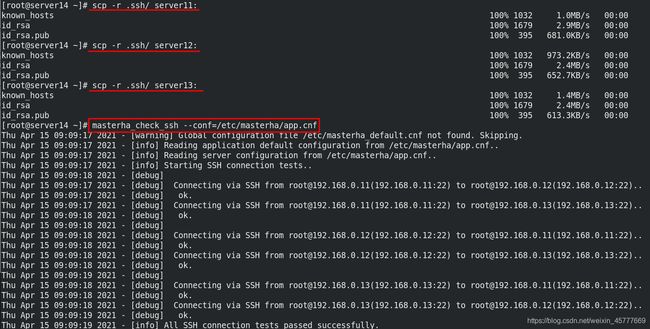

4. MHA高可用的切换
4.1 手动切换
- MHA的故障切换过程,共包括以下的步骤:
1.配置文件检查阶段,这个阶段会检查整个集群配置文件配置
2.宕机的master处理,这个阶段包括虚拟ip摘除操作,主机关机操作
3.复制dead maste和最新slave相差的relay log,并保存到MHA Manger具体的目录下
4.识别含有最新更新的slave
5.应用从master保存的二进制日志事件(binlog events)
6.提升一个slave为新的master进行复制
7.使其他的slave连接新的master进行复制
4.1.1 master活着
[root@server14 masterha]# masterha_master_switch --conf=/etc/masterha/app.cnf --master_state=alive --new_master_host=192.168.0.12 --new_master_port=3306 --orig_master_is_new_slave --running_updates_limit=10000 ##切换为另一个master
It is better to execute FLUSH NO_WRITE_TO_BINLOG TABLES on the master before switching. Is it ok to execute on 192.168.0.11(192.168.0.11:3306)? (YES/no): YES
Starting master switch from 192.168.0.11(192.168.0.11:3306) to 192.168.0.12(192.168.0.12:3306)? (yes/NO): yes
master_ip_online_change_script is not defined. If you do not disable writes on the current master manually, applications keep writing on the current master. Is it ok to proceed? (yes/NO): yes

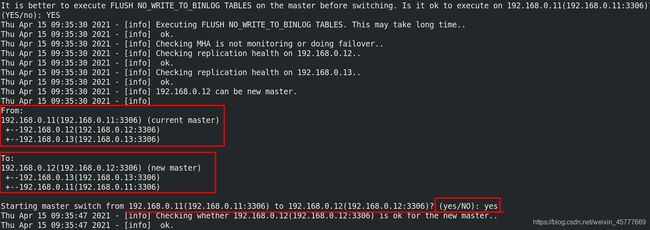


server11 13 master变为server12
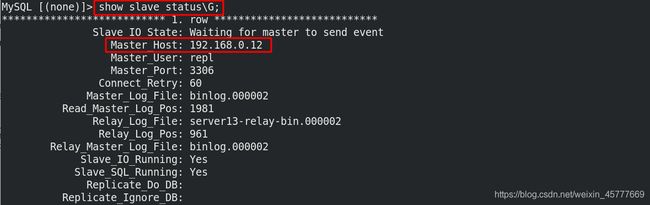
4.1.2 master down掉
[root@server12 ~]# /etc/init.d/mysqld stop ##停止server12服务
Shutting down MySQL............ SUCCESS!
[root@server14 masterha]# masterha_master_switch --master_state=dead --conf=/etc/masterha/app.cnf --dead_master_host=192.168.0.12 --dead_master_port=3306 --new_master_host=192.168.0.11 --new_master_port=3306 --ignore_last_failover
Master 192.168.0.12(192.168.0.12:3306) is dead. Proceed? (yes/NO): yes
Starting master switch from 192.168.0.12(192.168.0.12:3306) to 192.168.0.11(192.168.0.11:3306)? (yes/NO): yes
[root@server14 masterha]# cd app1/
[root@server14 app1]# ll
total 0
-rw-r--r-- 1 root root 0 Apr 15 09:57 app.failover.complete
[root@server14 app1]# ls
app.failover.complete ##故障切换生成的文件,类似于锁定文件,有这个文件,下次切换master的时候不加--ignore_last_failover这个选项会失败,避免服务抖动,不允许来回切,有时间判断,在规定的时间内不能切换,属于抖动期,需检测。


[root@server12 ~]# /etc/init.d/mysqld start ##手工恢复
Starting MySQL. SUCCESS!
[root@server12 ~]# mysql -pwestos
mysql> change master to master_host='192.168.0.11', master_user='repl', master_password='westos',MASTER_AUTO_POSITION = 1;
mysql> start slave;
mysql> show slave status\G;

4.2 自动切换
- MHA在线切换的大概过程:
1.检测复制设置和确定当前主服务器
2.确定新的主服务器
3.阻塞写入到当前主服务器
4.等待所有从服务器赶上复制
5.授予写入到新的主服务器
6.重新设置从服务器
- 为了保证数据完全一致性,在最快的时间内完成切换,MHA的在线切换必须满足以下条件才会切换成功,否则会切换失败。
1.所有slave的IO线程都在运行
2.所有slave的SQL线程都在运行
3.所有的show slave status的输出中Seconds_Behind_Master参数小于或者等于running_updates_limit秒,如果在切换过程中不指定running_updates_limit,那么默认情况下running_updates_limit为1秒。
4.在master端,通过show processlist输出,没有一个更新花费的时间大于running_updates_limit秒。
[root@server14 app1]# masterha_check_repl --conf=/etc/masterha/app.cnf
[root@server14 app1]# masterha_check_ssh --conf=/etc/masterha/app.cnf
[root@server14 app1]# masterha_manager --conf=/etc/masterha/app.cnf & ##打入后台自动执行切换
[root@server14 app1]# rm -fr app.failover.complete
[root@server14 app1]# ls
app.master_status.health manager.log
[root@server11 ~]# /etc/init.d/mysqld stop #停止现在的master server11,观察是否自动切换
Shutting down MySQL............ SUCCESS!
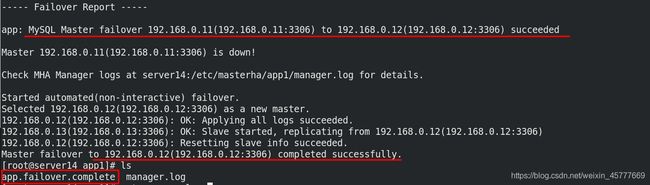
[root@server14 app1]# cat manager.log
Master failover to 192.168.0.12(192.168.0.12:3306) completed successfully.
[root@server14 app1]# ls
app.failover.complete manager.log
[root@server14 app1]# rm -fr app.failover.complete
可以在server4管理端看到正在切换,切换完成回车,自动结束此次转换。自动结束是为了防止数据抖动。

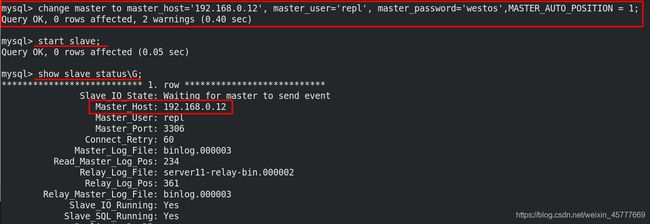
[root@server11 ~]# /etc/init.d/mysqld start ##手动恢复
Starting MySQL. SUCCESS!
[root@server11 ~]# mysql -pwestos
mysql> change master to master_host='192.168.0.11', master_user='repl', master_password='westos',MASTER_AUTO_POSITION = 1;
mysql> start slave;
mysql> show slave status\G;
4.3 通过vip进行自动、手动的切换
4.3.1 通过vip 进行手动切换
[root@foundation file_recv]# scp master_ip_failover master_ip_online_change 192.168.0.14:/usr/local/bin
[root@server14 scripts]# cd /usr/local/bin
[root@server14 bin]# ls
master_ip_failover master_ip_online_change
[root@server14 bin]# chmod +x *
[root@server14 bin]# ll
total 8
-rwx--x--x 1 root root 2156 Apr 15 10:45 master_ip_failover
-rwx--x--x 1 root root 3810 Apr 15 10:45 master_ip_online_change
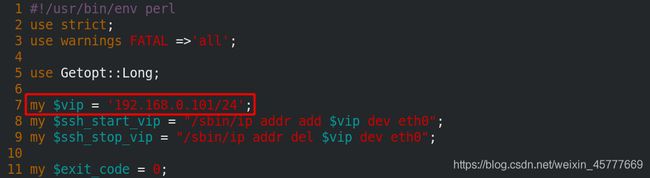
[root@server14 bin]# vim master_ip_failover
11 my $vip = '192.168.0.101/24';
[root@server14 bin]# vim master_ip_online_change
7 my $vip = '192.168.0.101/24';
[root@server14 bin]# cd /etc/masterha/
[root@server14 masterha]# vim app.cnf
master_ip_online_change_script= /usr/local/bin/master_ip_online_change
master_ip_failover_script= /usr/local/bin/master_ip_failover


[root@server12 ~]# ip addr add 192.168.0.101/24 dev eth0 ##主master需要添加方才配置文件里的vip
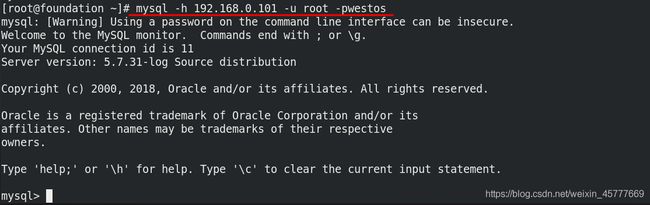
[root@foundation ~]# mysql -h 192.168.0.101 -u root -pwestos ##真机通过vip连接数据库
mysql> show databases;
[root@server14 masterha]# cd app1/
[root@server14 app1]# ls
manager.log
[root@server14 app1]# masterha_master_switch --conf=/etc/masterha/app.cnf --master_state=alive --new_master_host=192.168.0.11 --new_master_port=3306 --orig_master_is_new_slave --running_updates_limit=10000 ##手动切换
[root@server11 ~]# ip addr ##成功切换vip
[root@foundation ~]# mysql -h 192.168.0.101 -u root -pwestos
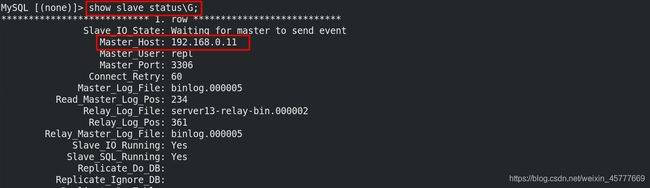
server13 MySQL [(none)]> show slave status\G;

成功切换vip
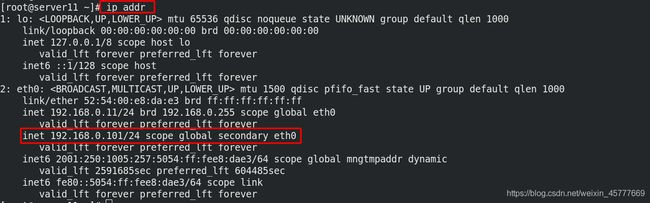
成功登陆
主master切换为server11
4.3.2 通过vip 进行自动切换
[root@server14 masterha]# masterha_manager --conf=/etc/masterha/app.cnf &
[root@server11 ~]# /etc/init.d/mysqld stop
Shutting down MySQL............ SUCCESS!
[root@server12 ~]# ip addr
[root@server11 ~]# /etc/init.d/mysqld start
Starting MySQL. SUCCESS!
[root@server11 ~]# /etc/init.d/mysqld start ##手动恢复
Starting MySQL. SUCCESS!
[root@server11 ~]# mysql -pwestos
mysql> change master to master_host='192.168.0.12', master_user='repl', master_password='westos',MASTER_AUTO_POSITION = 1;
mysql> start slave;
mysql> show slave status\G;
[root@server14 app1]# rm -fr app.failover.complete
vip自动切换到server12上

主master自动切换为server12