作者: dba_360-顾大伟 原文来源: https://tidb.net/blog/b6784b61
1 背景
随着 Kubernetes(K8s) 的全面成熟,越来越多的组织开始大规模地基于 K8s 构建基础设施层。然而,考虑到数据库在架构中的核心地位与 K8s 在有状态应用编排上的短板,仍有不少组织认为在 K8s 上运行核心数据库会带来颇高的风险。事实上,在 K8s 上运行 TiDB 不仅能实现企业技术栈的统一,降低维护成本,还能带来更高的可用性与安全性,我愿做第一个吃螃蟹的人,接下来会逐步进行k8s tidb 部署、功能测试、性能测试等,今天第一篇-部署
2 Tidb架构

\
3 组件配置详解
kubernetes 部署可以参考 https://blog.csdn.net/omaidb/article/details/121549382,网上很多,在此不作重要概述
3.1 配置Storage Class
TiDB 集群中 PD、TiKV、监控等组件以及 TiDB Binlog 和备份等工具都需要使用将数据持久化的存储。Kubernetes 上的数据持久化需要使用 PersistentVolume (PV)。Kubernetes 提供多种存储类型,主要分为两大类,网络存储和本地存储,在此我用本地存储
本地PV配置:
Sharing a disk filesystem by multiple filesystem PVs
假设/mnt/disks 为provisioner发现目录
1. Format and mount
$ sudo mkfs.ext4 /dev/path/to/disk $ DISK_UUID=$(blkid -s UUID -o value /dev/path/to/disk) $ sudo mkdir /mnt/$DISK_UUID $ sudo mount -t ext4 /dev/path/to/disk /mnt/$DISK_UUID
2. Persistent mount entry into /etc/fstab
$ echo UUID=`sudo blkid -s UUID -o value /dev/path/to/disk` /mnt/$DISK_UUID ext4 defaults 0 2 | sudo tee -a /etc/fstab
3. Create multiple directories and bind mount them into discovery directory
for i in $(seq 1 10); do sudo mkdir -p /mnt/${DISK_UUID}/vol${i} /mnt/disks/${DISK_UUID}_vol${i} sudo mount --bind /mnt/${DISK_UUID}/vol${i} /mnt/disks/${DISK_UUID}_vol${i} done
4. Persistent bind mount entries into /etc/fstab
for i in $(seq 1 10); do echo /mnt/${DISK_UUID}/vol${i} /mnt/disks/${DISK_UUID}_vol${i} none bind 0 0 | sudo tee -a /etc/fstab done
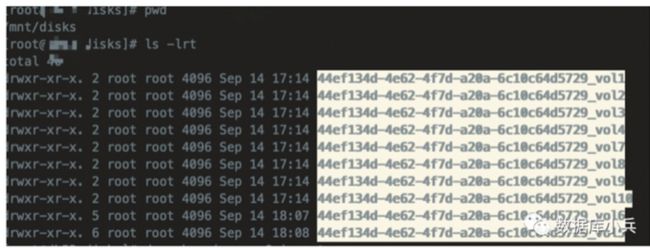
\
wget https://raw.githubusercontent.com/pingcap/tidb-operator/master/examples/local-pv/local-volume-provisioner.yaml
如果你使用与上一步中不同路径的发现目录,需要修改 ConfigMap 和 DaemonSet 定义
修改 DaemonSet 定义中的 volumes 与 volumeMounts 字段,以确保发现目录能够挂载到 Pod 中的对应目录:
部署 local-volume-provisioner 程序
kubectl apply -f local-volume-provisioner.yaml
kubectl get po -n kube-system -l app=local-volume-provisioner && \
kubectl get pv | grep -e shared-ssd-storage
下面可看到一共输出30个pv,每个节点10个
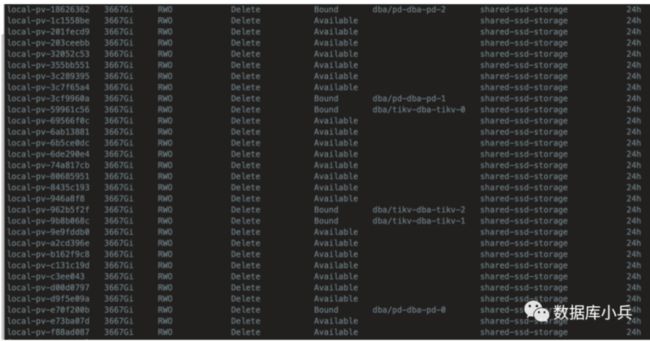
3.2 配置Tidb Operator
可通过官网介绍的helm 安装即可
4 配置Tidb 集群
在此列出tidb_cluster.yaml 配置文件,tidb/pd/tikv 各个组件可以在配置文件指定cpu/memory 等硬件资源隔离,类似cgroup,其它数据库参数也可在config 自定义配置
apiVersion: pingcap.com/v1alpha1
kind: TidbCluster
metadata:
name: dba
namespace: dba
spec:
# ** Basic Configuration **
# # TiDB cluster version
version: "v6.1.0"
# Time zone of TiDB cluster Pods
timezone: UTC
configUpdateStrategy: RollingUpdate
hostNetwork: false
imagePullPolicy: IfNotPresent
enableDynamicConfiguration: true
pd:
baseImage: pingcap/pd
replicas: 3
requests:
cpu: "50m"
memory: 50Mi
storage: 50Mi
limits:
cpu: "6000m"
memory: 20Gi
config: |
lease = 3
enable-prevote = true
storageClassName: "shared-ssd-storage"
mountClusterClientSecret: true
tidb:
baseImage: pingcap/tidb
config: |
split-table = true
oom-action = "log"
replicas: 3
requests:
cpu: "50m"
memory: 50Mi
storage: 10Gi
limits:
cpu: "8000m"
memory: 40Gi
storageClassName: "shared-ssd-storage"
service:
type: NodePort
mysqlNodePort: 30002
statusNodePort: 30080
tikv:
baseImage: pingcap/tikv
config: |
[storage]
[storage.block-cache]
capacity = "32GB"
replicas: 3
requests:
cpu: "50m"
memory: 50Mi
storage: 100Gi
limits:
cpu: "12000m"
memory: 40Gi
storageClassName: "shared-ssd-storage"
mountClusterClientSecret: true
enablePVReclaim: false
pvReclaimPolicy: Delete
tlsCluster: {}
重点参数讲解:
apiVersion: 指定api 版本,此值必须在kubectl apiversion中
kind:指定创建资源的角色/类型,比如Pod/Deployment/Job/Sevice等
metadata:资源的元数据/属性,比如名称,namespace,标签等信息
spec:指定该资源的内容,比如container,storage,volume以及其它kubernetes需要的参数等
replicas: 指定副本的数量
requests: 代表容器启动请求的最小资源限制,分配的资源呢必须要达到此要求,比如cpu,memory,注意CPU的计量单位叫毫核(m)。一个节点的CPU核心数量乘以1000,得到的就是节点总的CPU总数量。如,一个节点有两个核,那么该节点的CPU总量为2000m。
limits:组件限制的最大资源可用值
storageClassName:存储类,需和提前创建的类对应
tidb:
service
type:NodePort
Service 可以根据场景配置不同的类型,比如 ClusterIP、NodePort、LoadBalancer 等,对于不同的类型可以有不同的访问方式
ClusterIP:是通过集群的内部 IP 暴露服务,选择该类型的服务时,只能在集群内部访问
NodePort:NodePort 是通过节点的 IP 和静态端口暴露服务。通过请求 NodeIP + NodePort,可以从集群的外部访问一个 NodePort 服务
若运行在有 LoadBalancer 的环境,比如 GCP/AWS 平台,建议使用云平台的 LoadBalancer 特性
5 部署Tidb集群
创建 Namespace :
kubectl create namespace dba
部署 TiDB 集群:
kubectl apply -f tidb_cluster.yaml
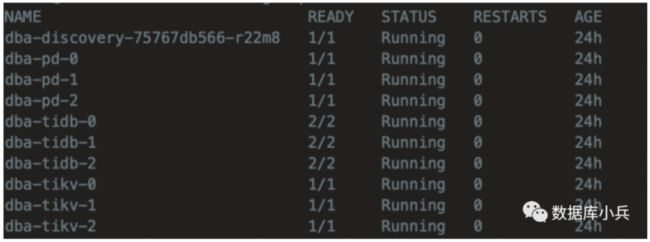
6 初始化Tidb 集群
主要用于初始化账号和密码设置,以及批量自动执行sql语句对数据库进行初始化
tidb-initializer.yaml
---
apiVersion: pingcap.com/v1alpha1
kind: TidbInitializer
metadata:
name: demo-init
namespace: demo
spec:
image: tnir/mysqlclient
# imagePullPolicy: IfNotPresent
cluster:
namespace: demo
name: demo
initSql: |-
create database app;
# initSqlConfigMap: tidb-initsql
passwordSecret: tidb-secret
# permitHost: 172.6.5.8
# resources:
# limits:
# cpu: 1000m
# memory: 500Mi
# requests:
# cpu: 100m
# memory: 50Mi
# timezone: "Asia/Shanghai"
执行初始化:
kubectl apply -f ${cluster_name}/tidb-initializer.yaml --namespace=${namespace}
7 访问Tidb 集群
kubectl get svc -n dba
\
mysql -uroot -P4000 -h 10.111.86.242 -pxxx
集群外部访问如下:
mysql -uroot -P30002 -h 机器真实ip -pxxx