作者: dba_360-顾大伟 原文来源: https://tidb.net/blog/6df22b36
继上篇-k8s实践部署之后,在此基础上对跑在k8s机器上的tidb服务进行基础运维测试
01 Tidb 组件扩缩容
缩容pd为2 副本:
kubectl patch -n dba tc dba --type merge --patch '{"spec":{"pd":{"replicas":2}}}'

扩容pd为3副本:
kubectl patch -n dba tc dba --type merge --patch '{"spec":{"pd":{"replicas":3}}}'
kubectl get po -n dba -o wide
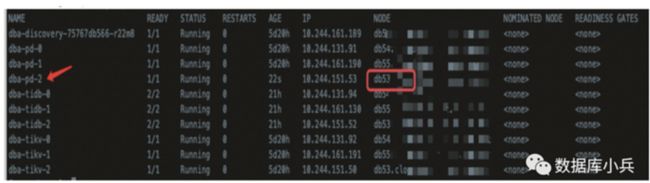
02 维护k8s node
维护db53 node
kubectl cordon db53
扩容一个pd,发现不会在db53分配新的pod了,db55 分配了2个,当然这是模拟,同一node 不建议存在两个相同集群角色

假设存在tikv 节点,首先迁移tikv region leader
为 TiKV Pod 添加一个 key 为 tidb.pingcap.com/evict-leader 的 annotation:
kubectl -n dba annotate pod dba-tikv-2 tidb.pingcap.com/evict-leader="none"
执行以下命令,检查 Region Leader 是否已经全部被迁移走:
kubectl -n dba get tc dba -ojson | jq ".status.tikv.stores | .[] | select ( .podName == \"dba-tikv-2\" ) | .leaderCount"
0 重建TIKV POD
查看TIKV Pod store-id:
kubectl get -n dba tc dba -ojson | jq ".status.tikv.stores | .[] | select ( .podName == \"dba-tikv-2\" ) | .id"
“1”
在任意一个 PD Pod 中,使用 pd-ctl 命令下线该 TiKV Pod:
kubectl exec -n dba dba-pd-0 -- /pd-ctl store delete 1

注意
下线 TiKV Pod 前,需要保证集群中剩余的 TiKV Pod 数不少于 PD 配置中的 TiKV 数据副本数(配置项:max-replicas,默认值 3)。假如不符合该条件,需要先操作扩容 TiKV。
遇到上面报错首先扩容一个tikv节点:
kubectl patch -n dba tc dba --type merge --patch '{"spec":{"tikv":{"replicas":4}}}'
![]()
新扩容的节点一直处于pending 状态
查看报错:
kubectl describe pod dba-tikv-3 -n dba

提示有1个节点在维护状态,剩下的节点cpu 不足,此时我们可以调整下tikv 节点需要的资源来满足k8s模拟场景
解除维护node:
kubectl uncordon db53.clouddb.bjzdt.qihoo.net
修改配置文件:
\
kubectl replace -f david/tidb-cluster.yaml
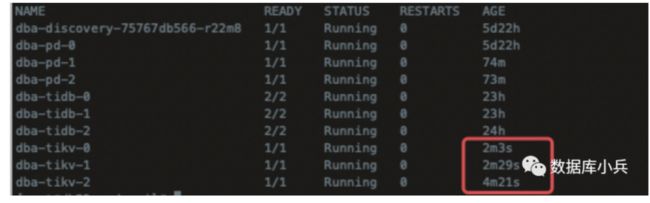
可以看到tikv jpod 已重启
然后按照上面的步骤重新维护节点,扩容tikv 副本为4,发现现在没问题了,扩容成功

再次执行下线Tikv Pod:
kubectl exec -n dba dba-pd-0 -- /pd-ctl store delete 1
Success!
解除 TiKV Pod 与当前使用的存储的绑定。
查询 Pod 使用的 PersistentVolumeClaim:
kubectl get pvc -n dba

删除该 PersistentVolumeClaim:
上图的NAME 就是PVC 的名字
kubectl delete -n dba pvc tikv-dba-tikv-2 --wait=false
删除 TiKV Pod,并等待新创建的 TiKV Pod 加入集群。
kubectl delete -n dba pod dba-tikv-2
pod “dba-tikv-2” deleted等待新创建的 TiKV Po 状态变为 Up。

从输出中可以看到,新的 TiKV Pod 有着新的 store-id,并且 Region Leader 会自动调度到该 TiKV Pod 上。
移除不再需要的 evict-leader-schedul
kubectl exec -n dba dba-pd-0 -- /pd-ctl scheduler remove evict-leader-scheduler-1
Success!
查看当前tikv 所在node 已经没db53了,db53节点维护成功

03 部署Tidb monitor
编辑配置文件:
apiVersion: pingcap.com/v1alpha1
kind: TidbMonitor
metadata:
name: dba
namespace: dba
spec:
clusters:
- name: dba
prometheus:
baseImage: prom/prometheus
version: v2.18.1
#limits:
# cpu: 8000m
# memory: 8Gi
#requests:
# cpu: 4000m
# memory: 4Gi
imagePullPolicy: IfNotPresent
logLevel: info
reserveDays: 12
service:
type: NodePort
portName: http-prometheus
grafana:
baseImage: grafana/grafana
version: 6.0.1
imagePullPolicy: IfNotPresent
logLevel: info
#limits:
# cpu: 8000m
# memory: 8Gi
#requests:
# cpu: 4000m
# memory: 4Gi
username: admin
password: admin
envs:
# Configure Grafana using environment variables except GF_PATHS_DATA, GF_SECURITY_ADMIN_USER and GF_SECURITY_ADMIN_PASSWORD
# Ref https://grafana.com/docs/installation/configuration/#using-environment-variables
GF_AUTH_ANONYMOUS_ENABLED: "true"
GF_AUTH_ANONYMOUS_ORG_NAME: "Main Org."
GF_AUTH_ANONYMOUS_ORG_ROLE: "Viewer"
# if grafana is running behind a reverse proxy with subpath http://foo.bar/grafana
# GF_SERVER_DOMAIN: foo.bar
# GF_SERVER_ROOT_URL: "%(protocol)s://%(domain)s/grafana/"
service:
type: NodePort
portName: http-grafana
initializer:
baseImage: pingcap/tidb-monitor-initializer
version: v6.1.0
imagePullPolicy: Always
#limits:
# cpu: 50m
# memory: 64Mi
#requests:
# cpu: 50m
# memory: 64Mi
reloader:
baseImage: pingcap/tidb-monitor-reloader
version: v1.0.1
imagePullPolicy: IfNotPresent
service:
type: NodePort
portName: tcp-reloader
#limits:
# cpu: 50m
# memory: 64Mi
#requests:
# cpu: 50m
# memory: 64Mi
imagePullPolicy: IfNotPresent
persistent: true
storageClassName: shared-ssd-storage
storage: 10Gi
nodeSelector: {}
annotations: {}
tolerations: []
kubePrometheusURL: http://prometheus-k8s.monitoring.svc:9090
alertmanagerURL: ""
你可以通过以下命令来确认 PVC 情况:
kubectl get pvc -l app.kubernetes.io/instance=dba,app.kubernetes.io/component=monitor -n dba
应用配置文件:
kubectl apply -f tidb_monitor.yaml
访问 Grafana 监控面板
对于需要直接访问监控数据的情况,可以通过 kubectl port-forward 来访问 Prometheus:
kubectl port-forward --address 10.228.66.152 -n dba svc/dba-grafana 3000:3000 &>/tmp/portforward-grafana.log &
grafana监控
kubectl port-forward --address 10.228.66.152 -n dba svc/dba-prometheus 9090:9090 &>/tmp/portforward-prometheus.log &
访问 Prometheus 监控数
04 Alertmanager 告警配置
如果现有的基础设施已经有可用的alertmanager你服务,可以按照下面步骤配置告警
修改tidb _monitor.yaml 配置文件

重新应用下
Kubectl replace -f tidb_monitor.yaml
如果想单独部署一套独立的服务,参考官方 https://github.com/prometheus/alertmanager 来部署alertmanager 组件
docker run --name alertmanager -d -p 10.228.66.152:9093:9093 quay.io/prometheus/alertmanager
![]()
一般需要定制化告警,比如发送到邮件或者其他公司内部沟通软件,下面需要登陆到docker容器修改配置文件
docker ps |grep alert 找到alert docker 进程id
docker exec -it 25ed6524c91a sh 登陆进容器
![]()
按照自己需要可定制发送到邮件或者web hook等
cat >> /etc/alertmanager/alertmanager.yml << EOF
global:
smtp_smarthost: 'localhost:25'
smtp_from: '[email protected]'
smtp_auth_username: 'alertmanager'
smtp_auth_password: 'password'
route:
receiver: "webhook-sms"
group_by: ['env','instance','alertname','type','group','job']
group_wait: 30s
group_interval: 3m
repeat_interval: 3h
receivers:
- name: 'webhook-sms'
webhook_configs:
- url: 'http://api.xxxxx/public/alertmanagerSendXSM'
EOF
停止pod:
docker stop cdfe1e7beef4
启动pod:
docker start cdfe1e7beef4
查看服务:

查看某个pod的容器服务:
kubectl get pods dba-tidb-1 -o jsonpath={.spec.containers[*].name}
kubectl exec -it dba-tidb-0 -c tidb -n dba – /bin/sh
-c 指定某种服务

05 单独修改节点配置
Tikv 举例:
进入诊断模式后修改配置
让 TiKV Pod 进入诊断模式后,可以手动修改 TiKV 的配置文件,并指定使用修改后的配置文件启动 TiKV 进程。
具体操作步骤如下:
从 TiKV 的日志中获取 TiKV 的启动命令,后续步骤中将会使用。
kubectl logs pod dba-tikv-0 -n dba -c tikv | head -2 | tail -1
输出类似如下,该行就是 TiKV 的启动命令。
/tikv-server --pd=http://dba-pd:2379 --advertise-addr=dba-tikv-0.dba-tikv-peer.dba.svc:20160 --addr=0.0.0.0:20160 --status-addr=0.0.0.0:20180 --advertise-status-addr=dba-tikv-0.dba-tikv-peer.dba.svc:20180 --data-dir=/var/lib/tikv --capacity=0 --config=/etc/tikv/tikv.toml
注意:
如果 TiKV Pod 持续处于 CrashLoopBackoff 状态,无法从日志中获取启动命令,可以按照上述的命令格式来拼接出启动命令。
对 Pod 开启诊断模式,并重启 Pod。
执行以下命令为 Pod 添加 Annotation,等待下一次 Pod 重启。
kubectl annotate pod dba-tikv-0 -n dba runmode=debug
如果 Pod 一直处于运行中,你可以执行以下命令强制让 TiKV 容器重启。
kubectl exec dba-tikv-0 -n dba -c tikv -- kill -SIGTERM 1
可以通过检查 TiKV 的日志,确认是否进入了诊断模式。
kubectl logs dba-tikv-0 -n dba -c tikv
期望的日志内容如下:
entering debug mode.
执行下面命令进入 TiKV 容器。
kubectl exec -it dba-tikv-0 -n dba -c tikv -- sh
在 TiKV 容器中,复制 TiKV 的配置文件,然后在新的文件上修改 TiKV 的配置。
cp /etc/tikv/tikv.toml /tmp/tikv.toml && vi /tmp/tikv.tmol
在 TiKV 容器中,根据第 1 步中获取的 TiKV 的启动命令,修改启动参数 --config 为刚刚新创建的配置文件路径后,启动 TiKV 进程。
/tikv-server --pd=http://dba-pd:2379 --advertise-addr=dba-tikv-0.dba-tikv-peer.dba.svc:20160 --addr=0.0.0.0:20160 --status-addr=0.0.0.0:20180 --advertise-status-addr=dba-tikv-0.dba-tikv-peer.dba.svc:20180 --data-dir=/var/lib/tikv --capacity=0 --config=/tmp/tikv.toml
测试完成后,如果要恢复 TiKV Pod,可以直接删除当前的 TiKV Pod,并等待 TiKV Pod 自动被拉起。
kubectl delete dba-tikv-0 -n dba
06 压力测试
工具:sysbench
底层存储:nvme 盘,open-local 存储卷模式,网络直通
主要测试只读/只写/读写对应的性能指标,5个table,每个100w条数据,进行不同并发线程压测,同时观察组件是否实现资源限制(cpu/memory)
sysbench oltp_read_write --mysql-host=xxx --mysql-port=30002 --table-size=1000000 --db-driver=mysql --mysql-db=test --mysql-user=root --mysql-password='' --time=300 --threads=%s --tables=5 run
Tidb cpu 限制最大使用8c,tikv 限制cpu 最大10c,并发线程128进行压测,top 查看确实限制住了

只读测试 :

结论:
随着压测线程增加,只读qps 基本维持在35000-40000/s,延时在32线程之后明显提升,最大耗时在170ms
只写测试 :


结论:
随着压测线程增加,只读qps 基本维持在35000-40000/s,延迟在64线程之后有明显提升最大到112ms
读写测试 :


结论:
随着压测线程增加,只读qps 基本维持在35000-40000/s,延时在64线程之后明显提升,最大耗时在193ms,8-64线程压测延时也在30多ms
07 总结
在k8s 上跑有db 这种有状态服务目前还待成熟,学习成本比较高,对应运维难度增加,目前个人感觉网上可搜索的实战文章较少,如果对k8s 不熟悉,纠错成本比较高,毕竟官网也不可能全部概括,希望未来小伙伴使用越来越多,大家一起交流学习