记一次线上Dubbo线程池爆满问题的排查过程
随手翻有道云笔记,发现2020年12月份的一篇问题排查日记,感觉有点意义,发出来分享给大家

一、 客户端现象
1)不定期无规律出现dubbo接口调用超时错误
Failed to invoke the method xxx in the service xxx
last error is:Invoke remote method timeout
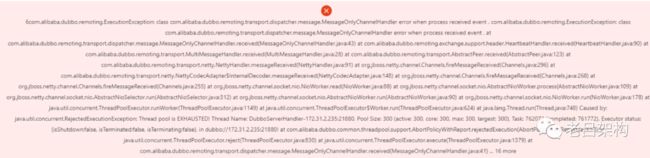
2)dubbo线程池超最大线程数错误
RejectedExecutionException:Thread pool is EXHAUSTED!
二、第1个问题的排查
1、根据错误栈发现是调用了edf_business 和 edf_system 两个基础服务的接口超时,但是在基础服务里的错误日志是dubbo线程池超限,这就有了疑问,为什么消费者收到的错误为调用超时呢?而明明应该是线程池超限错误。后经过对dubbo线程池配置的研究发现,在线程分发模型配置中 当dispatcher="all"时,一旦Provider线程池被打满,由于异常处理也需要用业务线程池,如果此时运气好,业务线程池有空闲线程,那么Consumer将收到Provider发送的线程池打满异常;但很可能此时业务线程池还是满的,于是悲剧,异常处理和应答步骤也没有线程可以跑,导致无法应答Consumer,这时候Consumer只能苦等到超时!
经过对几种分发模型的研究,最终选择了dispatcher=massage的分发模型,只有业务请求处理会用到业务线程池,其他的非业务操作直接在IO线程池执行。
2、经过以上改进,线程池满的异常虽然可以提示了,但是问题的占满的原因还是没有找到,过了几天线上又出现了这个问题,这次问题直接提示了 system和business基础服务的线程池被打满的异常,见上图。
三、第2个问题的排查
通过日志观察到出现问题时,有接口的调用出现sql死锁现象,最开始我一直怀疑是MySQL死锁引起的故障,但是又找不到理论支撑,因为那个接口的sql只涉及到一张表的先删后增操作,不至于堵塞整个MySQL,另外MySQL自身的死锁检测机制可以及时解开死锁的事务,从这个角度来说说不通。
没有别的案发现场资料只有阿里云的日志服务,这个日志服务相比log文件的方式,有优点也有缺点。没办法只能一点点鼓捣日志,慢慢仔细观察上下文。(在此期间解决了一个开发环境的死锁问题,和这个死锁有点类似,最终发现是主键冲突引起的,再通过分析业务代码发现是对同一张表在同一个线程中先后两个不同的方法里进行了插入相同数据的操作 ),受此启发,仔细分析日志, 发现死锁的前面往往伴随着插入操作主键冲突的异常。通过错误栈和sql语句定位到了业务操作接口,于是就开始梳理此接口的业务逻辑,很是麻烦,由于业务代码质量普遍不高,业务流程还很长。经过分析最终定位到一个业务功能,分配客户的功能,于是开始各种场景的分析,单用户操作怎么会引起并发呢???想不明白,还是想不明白,整个链路无法连通,由此陷入僵局。
四、dubbo线程池爆满的思考
上面说了死锁的排查陷入僵局了,因为怎么也想不通单户操作会引起并发问题,通过各种模拟用户点击场景,也不能复现问题。
终于线上又出现问题了,dubbo线程池再次爆满,这次为了弄清楚到底是突发事件引起的还是正常用户并发逐渐上升超过集群容量引起的事故,我们决定对dubbo线程池状态进行监控,每间隔5分钟打印一次dubbo线程池的状态信息。
如果是突发占满线程池,那么一定是有db异常或者程序异常导致的,需要排查解决;
如果是平稳逐步上升达到占满线程池,这属于业务量增大造成的,需要扩容集群;
虽然我们怀疑某些接口导致了此次事故,但是由于没有完整的证据链来推理现象的发生过程,我们也无法提供解决方案。
12月10日上午10点半左右问题再次发生,我们深入分析了打印的dubbo线程池状态日志,数据如下:
通过对某一个服务的某个容器的检测发现,存在突发占满现象
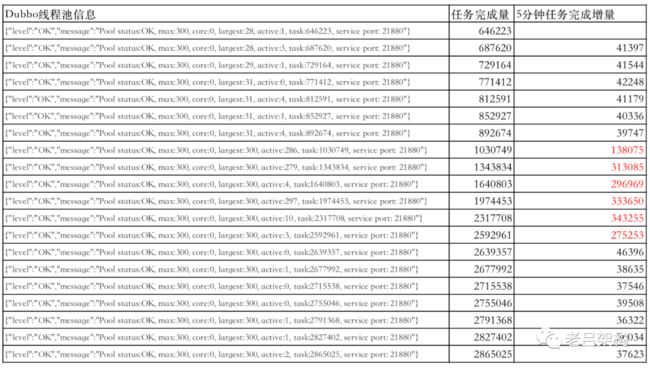
信息解读:max是最大线程数,core是核心线程数,largest 是曾经达到的最大并发线程数,active是活跃线程数,也就是正在处理业务接口调用,task是此线程池自JVM启动以来累计完成的任务量
core之所以是0,是因为dubbo线程池类型选择了 cached pool。
着重看 active 项,在出现问题的阶段active一直很高,而且是突发的急剧上升。这验证了一个问题,故障是突发流量引起的,正常情况下客户的并发量没有这么大,可以说很小。
进一步思考这些活跃的线程是在等待数据库吗?难道死锁引起了MySQL性能整体下降?导致接口性能下降,线程池不能及时空闲下来?
接下来的一个指标解决了上面的疑惑,通过 对 task 5分钟的增量统计发现,问题期间,任务处理完成量猛增好几倍, 这说明了接口性能并没有下降,纯粹是因为接口调用量激增导致的超限。
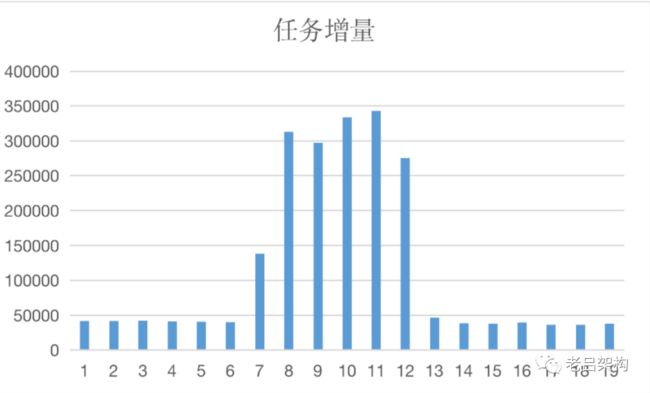
由此我们断定了一个问题,线程池爆满和MySQL无关,和MySQL的那个主键冲突和死锁也没有直接的关系,纯粹就是因为调用量激增造成的。我们断定一定是某个接口有大量的循环调用引起的短时间内调用量激增导致的。
下一步排查的方向就是找循环调用或者存在死循环的地方,去哪找呢,业务代码太多了,我们技术架构组又不太熟悉业务代码流程,还是只能靠日志缩小范围。
通过日志我们再次聚焦到了那个主键冲突和死锁sql对应的业务接口,我们断定是此接口并发调用引起的问题,但是我们从前端业务功能使用场景上又无法推理出大量并发的可能性。
五、柳暗花明又一村
后来在此接口基础上又向上查找了一层调用方,发现了一个批量数据导入接口也异步调用了此接口(除了前端的一个直接调用外,还发现一个间接调用的接口,就是批量导入数据接口),通过简单阅读代码,豁然开朗,批量导入excel数据时按行导入的,每导入成功一行就会异步调用一次A接口,异步调用A决定了此A接口存在大量并发,而A接口又是一个比较特殊的接口,它会进行一个表中全量数据的先删后增刷新操作,并发调用存在并发问题。而发生导入的这家客户的数据量又是比较突出的,数据量比较大。如果excel里有几千条数据就可以短时间内占满dubbo线程池。
六、证据链推导
简化的调用逻辑如下
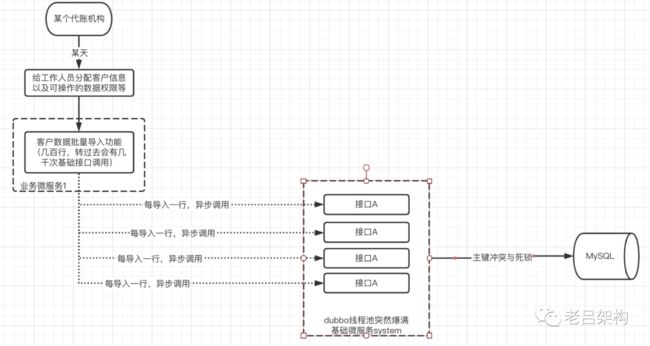
这样整个证据链打通,日志中的各种信息也得到了合理解释。
为什么一个接口的疯狂调用就可以使整个平台不可用呢?如何避免单个接口出现问题导致整个平台不可用呢?这是一个架构师需要思考的问题。这次事故中已经很明确了,所有接口共享线程池,没有做任何限制,没有做任何接口资源占用隔离,导致一个接口的疯狂调用占用了所有的线程池的线程,影响了其它接口的正常使用。
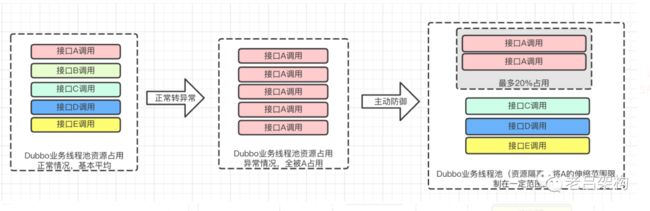
七、总结教训
1、尽量多的审计业务接口的实现思路,尤其是批量操作接口、异步并发的。
2、平台一定要有全面的限流措施,防患于未然,从网关的限流到业务接口资源的隔离到第三方接口的熔断,避免类似悲剧的发生。
3、完善应用监控机制,比如接口调用次数、接口性能统计等
4、合理的利用dubbo的重试机制,一定程度上可以缓解此问题(注意 慢接口的重试可能会加剧故障的蔓延,所以慢接口应该排除在外)
