.*?'
r'(?P.*?).*?'
r'(?P.*?)'
,re
.S
)
result
=obj
.finditer
(content_page
)
f
=open("data.csv",mode
="w",encoding
='utf-8')
cswriter
=csv
.writer
(f
)
for item
in result
:
dic
=item
.groupdict
()
dic
['time']=dic
['time'].strip
()
cswriter
.writerow
(dic
.values
())
f
.close
()
print("over")
3.3 bs4数据解析
数据解析原理
1. 标签定位,
2. 提取标签,标签属性中存储的数据值
实例化一个beautifulSoup对象,并且将页面源码数据加载到该对象 中
3. 通过调用BeautifulSoup对象中相关属性或者方法进行标签定位和数据提取
环境安装:
pip install bs4
pip install lxml
如何实例化BeautifulSoup对象
- from bs4 import BeautifulSoup
-
对象实例化:
- 将本地的html文档中的数据加载到该对象中
fp=open('../01_初识爬虫/周杰伦.html','r',encoding='utf-8')
soup=BeautifulSoup(fp,'lxml')
print(soup)
- 将互联网上获取的页面源码加载到该对象中
page_text=response.text
soup=BeautifulSoup(page_text,'lxml')
print(soup)
* 提供的用于数据解析的方法和属性:
1. soup.tageName:返回的是文档中第一次出现的tageName对应的标签内容
2. soup.find():
* find('tageName'):等同于soup.div
* 属性定位:
- soup.find('div',class_='song')
3. soup.find_all('a')
soup.find_all(['a','span'])
soup.find_all('li',limit=2)
4. soup.select('.tang')
* soup.select('某种选择器') 选择器可以是id,class ,标签选择器
soup.select('.c1')
soup.select('#l1')
soup.select('li[id]')
soup.select('li[id="l2"]')
* 层级选择器使用:
* soup.select('.tang > ul > li >a')[0]
li > a
* soup.select('.tang > ul > li a')[0]
li a
* soup.select('li ~ a')
* soup.select('div + a')
* soup.select('a,li')
5. 获取标签中的文本数据
- soup.a.text /string/get_text()
> text 和 get_text():可以获取一个某标签中所有的文本内容
string只可以获取该标签下面直系的文本内容
6. 获取标签中的属性值
- soup.a['href']
- soup.a.get('href')
7. 获取标签的属性和属性值
- soup.a.attrs
8. 获取标签的名字
- ob=soup.select('#p1')[0].name
- print(ob)
案例一:爬取三国演义小说所有章节标题和章节内容
三国演义
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
if __name__ =='__main__':
headers={
"User-Agent":UserAgent().chrome
}
get_url='https://www.shicimingju.com/book/sanguoyanyi.html'
page_text=requests.get(url=get_url,headers=headers).text.encode('ISO-8859-1')
soup=BeautifulSoup(page_text,'lxml')
list_data=soup.select('.book-mulu > ul > li')
fp=open('./sanguo.text','w',encoding='utf-8')
for i in list_data:
title=i.a.text
detail_url='https://www.shicimingju.com/'+ i.a['href']
detail_text=requests.get(url=detail_url,headers=headers).text.encode('ISO-8859-1')
detail_soup=BeautifulSoup(detail_text,'lxml')
content=detail_soup.find('div',class_='chapter_content').text
fp.write(title+":"+content+"\n")
print(title,'下载完成')
**案例二:**星巴克菜单名
from bs4 import BeautifulSoup
import urllib.request
url = 'https://www.starbucks.com.cn/menu/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'
}
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
soup = BeautifulSoup(content, 'lxml')
name_list=soup.select('ul[class="grid padded-3 product"] strong')
for name in name_list:
print(name.get_text())
import requests
from bs4 import BeautifulSoup
import time
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'
}
def get(url):
response = requests.get(url, headers=headers)
if response.status_code == 200:
response.encoding = 'utf-8'
content = response.text
parse(content)
def parse(html):
soup = BeautifulSoup(html, 'lxml')
name_list = soup.select('ul[class="grid padded-3 product"] strong')
lists = []
for name in name_list:
lists.append(name.get_text())
itemipiline(lists)
import csv
def itemipiline(name):
for i in name:
with open('星巴克.csv', 'a', encoding='utf-8') as fp:
writer = csv.writer(fp)
writer.writerows([i])
if __name__ == '__main__':
url = 'https://www.starbucks.com.cn/menu/'
get(url)
3.4xpath数据解析
1. 安装lxml库
pip install lxml
2. 导入 lxml.etree
from lxml import etree
3. etree.parse() 解析本地文件
html_tree=etree.parse('xx.html')
4. etree.HTML() 解析服务器响应文件
html_tree=etree.HTML(response.read().decode("utf-8"))
5. html_tree.xpath(xpath路径)
- 实例化etree对象,且将被解析的源码加载到该对象中
- 调用etree对象中的xpath方法,结合着xpath表达式实现标签定位和内容的捕获
xpath基本语法:
1.路径查询
//:查找所有子孙节点,不考虑层级关系
/:找直接子节点
2.谓词查询
//div[@id]
//div[@id="maincontent"]
3.属性查询
//@class
4.模糊查询
//div[contains(@id,"he")]
//div[starts-with(@id,"he")]
5.内容查询
//div/h1/text()
6.逻辑运算
//div[@id="head"and @class="s_down"]
//title | //price
<body>
<ul>
<li id="l1" class="c1">北京li>
<li id="l2">上海li>
<li id="c3">山东li>
<li id="c4">四川li>
ul>
body>
from lxml import etree
tree = etree.parse('../../data/xpath的基本使用.html')
li_list = tree.xpath('//ul/li[@id="l1"]/text() | //ul/li[@id="l2"]/text()')
print(len(li_list))
print(li_list)
**案例零:**获取百度网站的百度一下
from lxml import etree
import urllib.request
url = 'https://www.baidu.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'
}
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
tree = etree.HTML(content)
res = tree.xpath('//input[@id="su"]/@value')[0]
print(res)
案例一:彼岸图网
import requests
from lxml import etree
import os
from fake_useragent import UserAgent
headers={
"User-Agent":UserAgent().chrome
}
url='https://pic.netbian.com/4kdongman/'
response=requests.get(url=url,headers=headers)
page_text=response.text
tree=etree.HTML(page_text)
list_data=tree.xpath('//div[@class="slist"]/ul/li')
if not os.path.exists('./PicLibs'):
os.mkdir('./PicLibs')
for li in list_data:
img_src='https://pic.netbian.com' + li.xpath('./a/img/@src')[0]
img_name=li.xpath('./a/img/@alt')[0]+'.jpg'
img_name=img_name.encode("iso-8859-1").decode('gbk')
img_data=requests.get(url=img_src,headers=headers).content
img_path='PicLibs/'+ img_name
with open(img_path,'wb') as fp:
fp.write(img_data)
print(img_name,'下载成功!!!!')
案例二:发表情
import requests,os
from lxml import etree
from fake_useragent import UserAgent
def crawl(url):
headers={
"User-Agent":UserAgent().chrome
}
page_text=requests.get(url,headers).text
tree=etree.HTML(page_text)
list_data=tree.xpath('//div[@class="ui segment imghover"]/div/a')
if not os.path.exists('表情包'):
os.mkdir('表情包')
for i in list_data:
detail_url='https://www.fabiaoqing.com'+i.xpath('./@href')[0]
detail_page_text=requests.get(detail_url,headers).text
tree=etree.HTML(detail_page_text)
detail_list_data=tree.xpath('//div[@class="swiper-wrapper"]/div/img/@src')[0]
fp=detail_list_data.split('/')[-1]
with open('表情包/'+fp, 'wb') as fp:
fp.write(requests.get(detail_list_data).content)
print(fp,'下载完了!!!')
crawl('https://www.fabiaoqing.com/biaoqing/lists/page/1.html')
案例三:绝对领域
import requests
from fake_useragent import UserAgent
from lxml import etree
import os
def crawl():
url='https://www.jdlingyu.com/tuji'
headers={
"User-Agent":UserAgent().chrome
}
page_text=requests.get(url=url,headers=headers).text
tree=etree.HTML(page_text)
list_url=tree.xpath('//li[@class="post-list-item item-post-style-1"]/div/div/a')
for i in list_url:
detail_link=i.xpath('./@href')[0]
detail_data=requests.get(detail_link,headers).text
tree=etree.HTML(detail_data)
list_name=tree.xpath('//article[@class="single-article b2-radius box"]//h1/text()')[0]
if not os.path.exists('绝对领域\\'+list_name):
os.makedirs('绝对领域\\'+list_name)
list_link=tree.xpath('//div[@class="entry-content"]/p')
for i in list_link:
img_src=i.xpath('./img/@src')[0]
pic_name=img_src.split('/')[-1]
with open(f'绝对领域\\{list_name}\\{pic_name}','wb') as fp:
fp.write(requests.get(img_src).content)
print(list_name,'下载完成')
crawl()
案例四:爬取站长素材中免费简历模板
from lxml import etree
import requests,os
import time
if __name__ == '__main__':
url = 'https://sc.chinaz.com/jianli/free.html'
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36"
}
page_text = requests.get(url=url, headers=headers).text
tree=etree.HTML(page_text)
list_data= tree.xpath('//div[@id="main"]/div/div')
if not os.path.exists('./网络爬虫/sucai/站长素材'):
os.makedirs('./网络爬虫/sucai/站长素材')
for i in list_data:
detail_url ='https:'+i.xpath('./a/@href')[0]
detail_name =i.xpath('./p/a/text()')[0]
detail_name=detail_name.encode('iso-8859-1').decode('utf-8')
detail_data_text=requests.get(url=detail_url,headers=headers).text
tree=etree.HTML(detail_data_text)
down_link= tree.xpath('//div[@class="clearfix mt20 downlist"]/ul/li[1]/a/@href')[0]
final_data= requests.get(url=down_link,headers=headers).content
file_path='./网络爬虫/sucai/站长素材/'+detail_name
with open(file_path,'wb') as fp:
fp.write(final_data)
time.sleep(1)
print(detail_name+'下载成功!!!')
**案例五:**站长素材高清风景图片
import urllib.request
from lxml import etree
import os
def create_request(page):
if page == 1:
url = 'https://sc.chinaz.com/tupian/fengjingtupian.html'
else:
url = f'https://sc.chinaz.com/tupian/fengjingtupian_{str(page)}.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'
}
request = urllib.request.Request(url=url, headers=headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def download(content):
tree=etree.HTML(content)
src_list=tree.xpath('//body/div[3]/div[2]/div/img/@data-original')
name_list=tree.xpath('//body/div[3]/div[2]/div/img/@alt')
for i in range(len(name_list)):
name=name_list[i]
url='https:'+src_list[i]
print('正在下载 %s [%s]' % (name, url))
urllib.request.urlretrieve(url=url,filename=fr'D:\图片\风景\{name}.jpg')
if __name__ == '__main__':
if not os.path.exists('D:\图片\风景'):
os.mkdir('D:\图片\风景')
start_page = int(input('请输入起始页码:'))
end_page = int(input('请输入结束页码:'))
for page in range(start_page, end_page + 1):
request = create_request(page)
content = get_content(request)
download(content)
3.5jsonpaht数据解析
安装
pip install jsonpath
使用
obj=json.load(open('json文件','r',encoding="utf-8"))
ret=jsonpath.jsonpath(obj,'jsonpah语法')
博客教程

json格式数据
{ "store": {
"book": [
{ "category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{ "category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{ "category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{ "category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"author":"老王",
"color": "red",
"price": 19.95
}
}
}
提取数据
import jsonpath
import json
obj = json.load(open('../../../data/jsonpath.json', 'r', encoding='utf-8'))
book=jsonpath.jsonpath(obj,'$..book[?(@.price>10)]')
print(book)
(四)爬虫进阶
4.0验证码识别
4.1 cookie
用来让服务器端记录客户端的相关信息
- 手动处理:通过抓包工具获取cookie值,将该值封装到headers中 (不建议)
- 自动处理: 进行模拟登陆post请求后,由服务器创建,
- session会话对象
- 作用:1. 可以进行请求发送
2.如果请求过程中产生了cookie,则该cookie会被自动存储/携带在该session对象中
- 使用:
1. 创建session对象
2. 使用session对象进行模拟登陆post请求的发送,(cookie就会被存储在session中)
3. session对象对个人主页对应的get请求进行发送(携带了cookie)
import requests
session=requests.session()
data={
'loginName': '自己的账户名',
'passwod': '自己的密码',
}
url='https://passport.17k.com/ck/user/login'
rs=session.post(url=url,data=data)
response=session.get('https://user.17k.com/ck/author/shelf?page=1&appKey=2406394919')
print(response.json())
另一种携带cookie访问
直接把cookie放在headers中(不建议)
res=requests.get('https://user.17k.com/ck/author/shelf?page=1&appKey=2406394919',headers={
"Cookie":"GUID=868e19f9-5bb3-4a1e-b416-94e1d2713f04; BAIDU_SSP_lcr=https://www.baidu.com/link?url=r1vJtpZZQR2eRMiyq3NsP6WYUA45n6RSDk9IQMZ-lDT2fAmv28pizBTds9tE2dGm&wd=&eqid=f689d9020000de600000000462ce7cd7; Hm_lvt_9793f42b498361373512340937deb2a0=1657699549; sajssdk_2015_cross_new_user=1; c_channel=0; c_csc=web; accessToken=avatarUrl%3Dhttps%253A%252F%252Fcdn.static.17k.com%252Fuser%252Favatar%252F08%252F08%252F86%252F97328608.jpg-88x88%253Fv%253D1657699654000%26id%3D97328608%26nickname%3D%25E9%2585%25B8%25E8%25BE%25A3%25E9%25B8%25A1%25E5%259D%2597%26e%3D1673251686%26s%3Dba90dcad84b8da40; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2297328608%22%2C%22%24device_id%22%3A%22181f697be441a0-087c370fff0f44-521e311e-1764000-181f697be458c0%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%2C%22first_id%22%3A%22868e19f9-5bb3-4a1e-b416-94e1d2713f04%22%7D; Hm_lpvt_9793f42b498361373512340937deb2a0=1657700275"
})
print(res.json())
cookie登录古诗文网
import requests
from bs4 import BeautifulSoup
import urllib.request
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'
}
login_url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
response = requests.get(url=login_url, headers=headers)
content = response.text
soup = BeautifulSoup(content, 'lxml')
viewstate = soup.select('#__VIEWSTATE')[0].attrs.get('value')
viewstategenerator = soup.select('#__VIEWSTATEGENERATOR')[0].attrs.get('value')
img = soup.select('#imgCode')[0].attrs.get('src')
code_url = 'https://so.gushiwen.cn/' + img
session = requests.session()
response_code = session.get(code_url)
content_code = response_code.content
with open('../../../data/code.jpg', 'wb') as f:
f.write(content_code)
code_name = input('请输入验证码:')
url_post = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx'
data = {
'__VIEWSTATE': viewstate,
'__VIEWSTATEGENERATOR': viewstategenerator,
'from': 'http://so.gushiwen.cn/user/collect.aspx',
'email': 'xxxxxxxxx',
'pwd': '123123',
'code': code_name,
'denglu': '登录',
}
response_post = session.post(url=url_post, headers=headers, data=data)
content_post = response_post.text
with open('../../../data/古诗文.html', 'w', encoding='utf-8') as f:
f.write(content_post)
4.2代理
破解封IP的各种反扒机制
- 社么是代理:
1. 代理服务器
- 代理作用:
* 突破自身IP访问的限制
* 可以隐藏自身真实IP
- 代理相关网站:
- 代理IP类型:
* http:应用到http协议对应的URL中
* https:应用到https协议对应的URL中
- 代理IP的匿名度:
- 透明:服务器知道该次请求使用了代理, 也知道请求对应的真实IP
- 匿名:知道使用代理,不知道真实IP
- 高匿名:不知道使用代理,更不知道真实IP
案例:
requests
import requests
proxies={
"https":"222.110.147.50:3218"
}
res=requests.get("https://www.baidu.com/s?tn=87135040_1_oem_dg&ie=utf-8&wd=ip",proxies=proxies)
res.encoding='utf-8'
with open('ip.html','w') as fp:
fp.write(res.text)
urllib.request
import urllib.request
url='https://www.baidu.com/s?ie=UTF-8&wd=ip'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'
}
request=urllib.request.Request(url=url,headers=headers)
proxies={
'http': '118.24.219.151:16817'
}
handler=urllib.request.ProxyHandler(proxies=proxies)
opener=urllib.request.build_opener(handler)
resposne=opener.open(request)
content=resposne.read().decode('utf-8')
with open('../data/代理.html','w',encoding='utf-8') as f:
f.write(content)
4.3防盗链
在访问一些链接的时,网站会进行溯源,
他所呈现的反扒核心:当网站中的一些地址被访问的时候,会溯源到你的上一个链接
需要具备的一些“环境因素”,例如访问的过程中需要请求的时候携带headers
案例:梨视频
#分析
#请求返回的地址 和 可直接观看的视频的地址有差异#
#请求返回的数据中拼接了返回的systemTime值
#真实可看的视频地址中有浏览器地址栏的ID值
#解决办法,将url_no中的systemTime值替换为cont-拼接的ID值
#url='https://www.pearvideo.com/video_1767372
import requests,os
if not os.path.exists('./网络爬虫/sucai/梨video'):
os.makedirs('./网络爬虫/sucai/梨video')
#梨视频爬取视频
url='https://www.pearvideo.com/video_1767372'
contId= url.split('_')[1]
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36",
"Referer":url,
}
videoStatusUrl=f'https://www.pearvideo.com/videoStatus.jsp?contId={contId}&mrd=0.6004271686556242'
res =requests.get(videoStatusUrl,headers=headers)
#print(res.json())
dic=res.json()
srcUrl=dic['videoInfo']['videos']['srcUrl']
systemTime=dic['systemTime']
srcUrl=srcUrl.replace(systemTime,f'cont-{contId}')
#下载视频,进行存储
video_data=requests.get(url=srcUrl,headers=headers).content
with open('./网络爬虫/sucai/梨video/video.mp4','wb')as fp:
fp.write(video_data)
(五)异步爬虫
目的:在爬虫中使用异步实现高性能的数据爬取操作
- 进程是资源单位,每一个进程至少要有一个线程
- 线程是执行单位
- 同一个进程中的线程可共享该进程的资源
- 启动每一个城西默认都会有一个主线程
异步爬虫方式:
-
多线程,多进程:(不建议)
- 好处:可以被相关阻塞的操作单独开启线程或者进程,阻塞操作就可以异步执行
- 弊端:无法无限开启多线程或者多进程。
-
进程池,线程池(适当使用)
- 好处:可以降低系统对进程或者线程创建和销毁一个频率,从而很好的降低系统的开销
- 弊端:池中线程或者进程的数量有上限
- 线程池
一次性开辟一些线程,我们用户直接给线程池提交任务,线程任务的调度交给线程池来完成
- 单线程+异步协程
- event_loop:事件循环,相当于一个无限循环,我们可以把一些函数注册到这个事件循环上
当满足某些条件的时候,函数就会被循环执行
- coroutine:协程对象,我们可以将协程对象注册到事件循环中,它会被事件循环调用。
我们可以使用 async关键字来定义一个方法,这个方法在调用时不会立即执行,而是返回一个协程对象
- task:任务,它是对协程对象的进一步封装,包含了任务的各个状态,
- future:代表将来执行或还没有执行的任务,实际上和task没有本质区别
- async:定义一个协程
- await用来挂起阻塞方法的执行
5.0单线程
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36"
}
urls=[
'https://www.51kim.com/'
'https://www.baidu.com/'
'https://www.baidu.com/'
]
5.1多线程
from threading import Thread
def fun():
for i in range(100):
print('func',i)
if __name__ =='__main__':
t=Thread(target=fun)
t.start()
for i in range(100):
print('main',i)
'''
def MyThread(Thread):
def run(self): #当线程被执行的时候,被执行的就是run
for i in range(1000):
print("子线程",i)
if __name__ =='__main__':
t=MyThread()
t.start()#开启线程
for i in range(1000):
print("主线程",i)
'''
def fun(name):
for i in range(1000):
print(name,i)
if __name__ =='__main__':
t1=Thread(target=fun,args=('周杰伦',))
t1.start()
t2=Thread(target=fun,args=('周星驰',))
t2.start()
5.2多进程
from multiprocessing import Process
def fun():
for i in range(10000):
print('子进程',i)
if __name__ =='__main__':
p=Process(target=fun)
p.start()
for i in range(10000):
print('主进程',i)
案例:基于进程+线程实现多任务爬虫
需求分析

import uuid
from multiprocessing import Queue, Process
from threading import Thread
import pymysql
from lxml import etree
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'
}
class DownloadThread(Thread):
def __init__(self, url):
super().__init__()
self.url = url
def run(self):
print('开始下载', self.url)
resp = requests.get(url=self.url, headers=headers)
if resp.status_code == 200:
resp.encoding = 'utf-8'
self.content = resp.text
print(self.url, '下载完成')
def get_content(self):
return self.content
class DownloadProcess(Process):
"""
下载进程
"""
def __init__(self, url_q, html_q):
self.url_q: Queue = url_q
self.html_q = html_q
super().__init__()
def run(self):
while True:
try:
url = self.url_q.get(timeout=30)
t = DownloadThread(url)
t.start()
t.join()
html = t.get_content()
self.html_q.put((url, html))
except:
break
print('---下载进程over---')
class ParseThread(Thread):
def __init__(self, html, url_q):
self.html = html
self.url_q = url_q
super().__init__()
def run(self):
tree = etree.HTML(self.html)
imgs = tree.xpath('//div[contains(@class,"com-img-txt-list")]//img')
for img in imgs:
item = {}
item['id'] = uuid.uuid4().hex
item['name'] = img.xpath('./@data-original')[0]
item['src'] = img.xpath('./@alt')[0]
conn = pymysql.connect(
user='root',
password='123.com',
host='127.0.0.1',
port=3306,
database='dog',
charset='utf8'
)
cursor = conn.cursor()
sql = 'insert into labuladuo(name,src) values("{}","{}")'.format(item['name'], item['src'])
cursor.execute(sql)
conn.commit()
cursor.close()
conn.close()
print(item)
next_page = tree.xpath('//a[@class="nextpage"]/@href')
if next_page:
next_url = 'https://sc.chinaz.com/tupian/' + next_page[0]
self.url_q.put(next_url)
class ParseProcess(Process):
"""
解析进程
"""
def __init__(self, url_q, html_q):
super().__init__()
self.url_q = url_q
self.html_q = html_q
def run(self):
while True:
try:
url, html = self.html_q.get(timeout=60)
print('开始解析', url)
t = ParseThread(html, self.url_q).start()
except:
break
print('---解析进程over---')
if __name__ == '__main__':
task1 = Queue()
task2 = Queue()
task1.put('https://sc.chinaz.com/tupian/labuladuo.html')
p1 = DownloadProcess(task1, task2)
p2 = ParseProcess(task1, task2)
p1.start()
p2.start()
p1.join()
p2.join()
print('Over !!!!')
5.3线程池和进程池
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
def fun(name):
for i in range(1000):
print(name,i)
if __name__ =='__main__':
with ThreadPoolExecutor(50) as t:
for i in range(100):
t.submit(fun,name=f'线程{i}')
print('123132')
'''
def fun(name):
for i in range(1000):
print(name,i)
if __name__ =='__main__':
#创建进程池
with ProcessPoolExecutor(50) as t:
for i in range(100):
t.submit(fun,name=f'进程{i}')
#等待线程池中的任务全部执行完毕,才继续执行
print('123132')
'''
案例:水果交易网
import requests,csv,os
from fake_useragent import UserAgent
from concurrent.futures import ThreadPoolExecutor
from lxml import etree
if not os.path.exists('./网络爬虫/sucai/中国水果交易'):
os.makedirs('./网络爬虫/sucai/中国水果交易')
f='./网络爬虫/sucai/中国水果交易/fruit.csv'
fp=open(f,'w',encoding='utf-8')
csvwrite=csv.writer(fp)
def download_one_page(url):
response=requests.get(url=url,headers={"user-agent":UserAgent().chrome}).text
tree=etree.HTML(response)
list_data=tree.xpath('//li[@class="fruit"]/a')
all_list_data=[]
for i in list_data:
list_price=i.xpath('./div[2]/span[1]/text()')[0]
list_sort=i.xpath('./p[1]/text()')[0]
list_address=i.xpath('./p[2]/text()')[0]
all_list_data.append([list_price,list_sort,list_address])
csvwrite.writerow(all_list_data)
print(url,'下载完毕')
if __name__ =='__main__':
with ThreadPoolExecutor(50) as Thread:
for i in range(1,60):
Thread.submit(download_one_page,f'https://www.guo68.com/sell?page={i} ')
print("全部下载完毕")
5.4协程
-
协程不是计算机真实存在的(计算机只有进程,线程),而是由程序员人为创造出来的。
-
协程也可以被成为微线程,是一种用户态内的上下文切换技术,简而言之,其实就是通过一个线程实现代码块相互切换执行
-
实现协程方法:
-
通过greenlet,早期模块
-
yield关键字
-
asyncio模块
-
async,await关键字 【推荐】
-
协程意义
-
在一个线程中如果遇到IO等待时间,线程不会傻傻等,利用空闲的时间再去干点别的事
import time
def fun():
print('*'*50)
time.sleep(3)
print('*****'*10)
if __name__ =='__main__':
fun()
import asyncio
import time
'''
async def fun1():
print("你好,我叫周星驰")
time.sleep(3) #当程序出现同步操作的时候,异步就中断了,requests.get
await asyncio.sleep(3) #异步操作代码
print('我叫周星驰')
async def fun2():
print("你好,我叫周杰伦")
time.sleep(2)
await asyncio.sleep(2)
print('我叫周杰伦')
async def fun3():
print("你好,我叫周星驰")
time.sleep(4)
await asyncio.sleep(4)
print('我叫小潘')
if __name__ =="__main__":
f1 =fun1()#此时的函数是异步协程函数,此时函数执行得到的是一个协程对象
#print(g)
#asyncio.run(g) #协程需要asyncio模块的支持
f2=fun2()
f3=fun3()
task=[
f1,f2,f3
]
t1=time.time()
#一次性启动多个任务(协程)
asyncio.run(asyncio.wait(task))
t2=time.time()
print(t2-t1)
'''
async def fun1():
print("你好,我叫周星驰")
await asyncio.sleep(3)
print('我叫周星驰')
async def fun2():
print("你好,我叫周杰伦")
await asyncio.sleep(2)
print('我叫周杰伦')
async def fun3():
print("你好,我叫周星驰")
await asyncio.sleep(4)
print('我叫小潘')
async def main():
task=[
asyncio.create_task(fun1()),
asyncio.create_task(fun2()),
asyncio.create_task(fun3())
]
await asyncio.wait(task)
if __name__ =="__main__":
t1=time.time()
asyncio.run(main())
t2=time.time()
print(t2-t1)
5.4.1async & await关键字
python3.4之后版本能用
import asyncio
async def fun1():
print(1)
await asyncio.sleep(2)
print(2)
async def fun2():
print(3)
await asyncio.sleep(3)
print(4)
task=[
asyncio.ensure_future(fun1())
asyncio.ensure_future(fun2())
]
loop= asyncio.get_event_loop()
loop.run_untile_complete(asyncio.wait(task))
5.4.2事件循环
理解为一个死循环,检测并执行某些代码
import asyncio
loop=asyncio.get_event_loop()
loop.run_untile_complete(任务)
5.4.3快速上手
协程函数:定义函数时,async def 函数名
协程对象:执行 协程函数(),得到的就是协程对象
async def func():
pass
result=func()
执行协程函数创建协程对象,函数内部代码不会执行
如果想要执行协程函数内部代码,必须要将协程对象交给事件循环来处理
import asyncio
async def func():
pritn("你好,中国)
result=func()
asyncio.run(result)
5.4.4await关键字
await +可等待对象(协程对象,task对象,Future对象=====》IO等待)
示例1:
import asyncio
async def fun():
print("12374")
await asyncio.sleep(2)
print("结束")
asyncio.run(fun())
示例2:
import asyncio
async def others():
print('start')
await asyncio.sleep(2)
print('end")
return '返回值'
async def fun():
print("执行协程函数内部代码")
response =await others()
print('IO请求结束,结果为:',response)
asyncio.run(fun())
示例3:
import asyncio
async def others():
print('start')
await asyncio.sleep(2)
print('end")
return '返回值'
async def fun():
print("执行协程函数内部代码")
response1 =await others()
print('IO请求结束,结果为:',response1)
response2 =await others()
print('IO请求结束,结果为:',response2)
asyncio.run(fun())
await 等待对象的值得到结果之后才继续往下走
5.4.5Task对象
白话:在事件循环中添加多个任务
Task用于并发调度协程,通asyncio.create_task(协程对象)的方式创建Task对象,这样可以让协程加入事件循环中等待被调度执行,除了使用asyncio.create_task()函数以外,还可以用低级的loop.create_task()或者ensure_future()函数。不建议手动实例化Task对象
示例1:
import asyncio
async def func():
print(1)
await asyncio.sleep(2)
print(2)
return '返回值'
async def main():
print("main开始")
task1=asyncio.create_task(func())
task2=asyncio.creat_task(func())
print("main结束")
res1=await task1
res2=await task2
print(res1,res2)
asyncio.run(main())
示例2:
import asyncio
async def func():
print(1)
await asyncio.sleep(2)
print(2)
return '返回值'
async def main():
print("main开始")
task_list=[
asyncio.create_task(func(),name="n1")
asyncio.create_task(func(),name="n2")
]
print("main结束")
done,pending=await asyncio.wait(task_list,timeout=None)
print(done)
asyncio.run(main())
示例3:
import asyncio
async def func():
print(1)
await asyncio.sleep(2)
print(2)
return '返回值'
task_list=[
func(),
func(),
]
done,pending=asyncio.run( asyncio.wait(task_list))
print(done)
5.4.6async.Future对象
Task继承Tuture对象,Task对象内部await结果的处理基于Future对象来的
示例1:
async def main():
loop=asyancio.get_running_loop()
fut=loop.create_future()
await fut
asyncio.run(main())
示例2:
async def set_after():
await asyncio.sleep(2)
fut.set_result("666")
async def main():
loop=asyancio.get_running_loop()
fut=loop.create_future()
await loop.create_task(set_after(fut))
data=await fut
print(data)
asyncio.run(main())
5.4.7concurrent.futures.Future对象
使用线程池,进程池来实现异步操作时用到的对象
import time
from concurrent.futures.thread import ThreadPoolExecutor
from concurrent.futures.process import ProcessPoolExecutor
from concurrent.futures import Future
def fun(value):
time.sleep(1)
print(value)
pool=ThreadPoolExecutor(max_workers=5)
for i in range(10):
fut =pool.submit(fun,i)
print(fut)
5.4.8异步和非异步
案例:asyncio + 不支持异步的模块
import requests
import asyncio
async def down_load(url):
print('开始下载',url)
loop=asyncio.get_event_loop()
future=loop.run_in_executor(None,requets.get,url)
response=await future
print("下载完成")
file_name=url.rsplit('/')[-1]
with open(file_name,'wwb') as fp:
fp.write(response.content)
if __name__=="__main__":
urls=[
""
""
""
]
tasks=[ down_load(url) for url in urls]+
loop=asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
5.4.9异步上下文管理器
5.5 多任务异步协程
import asyncio,time
async def request(url):
print("正在下载:",url)
await asyncio.sleep(2)
print('下载完毕!!!',url)
strat_time=time.time()
urls=[
"www.baidui.com",
"www.sougou.com",
"www.goubanjai.com"
]
tasks=[]
for url in urls:
c =request(url)
task=asyncio.ensure_future(c)
tasks.append(task)
loop=asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
print(time.time()-strat_time)
5.6aiohttp模块
import asyncio
import aiohttp
import aiofiles
urls=[
"http://kr.shanghai-jiuxin.com/file/2020/0605/819629acd1dcba1bb333e5182af64449.jpg",
"http://kr.shanghai-jiuxin.com/file/2022/0515/small287e660a199d012bd44cd041e8483361.jpg",
"http://kr.shanghai-jiuxin.com/file/2022/0711/small72107f2f2a97bd4affd9c52af09d5012.jpg"
]
async def aiodownload(url):
img_name=url.split('/')[-1]
async with aiohttp.ClientSession() as session:
data=await session.get(url)
async with aiofiles.open(img_name,'wb') as fp:
fp.write(data)
print(img_name,'搞定')
async def main():
tasks=[]
for url in urls:
tasks.append(aiodownload(url))
await asyncio.wait(tasks)
'''
tasks=[]
for url in urls
task_obj=asyncio.ensure_future(download(url))
tasks.append(task_obj)
await asyncio.wait(tasks)
'''
if __name__=="__main__":
asyncio.run(main())
(六)动态加载数据处理
什么是selenium?
* (1) Selenium是一个用于web应用程序测试的工具。
* (2) Selenium测试直接运行在浏览器中,就像滇正的用户在操作一样。1
* (3) 支持通过各种driver(FirfoxDriver,IternetExplorerDriver,OperaDriver,ChromeDriver)驱动
真实浏览器完成测试
* (4) seleniumt也是支持无界面浏览器操作的。
为什么使用selenium?
模拟浏览器功能,自动执行网页中的js代码,实现动态加载
selenium
6.0selenium模块使用
selenium是基于浏览器自动化的一个模块
使用流程
- 先打开chrome 输入
chrome://version/来查看chrome版本
chromedriver驱动,,驱动下载好放在当前目录下就可以了
查看驱动和浏览器版本的映射关系
chromedriver官方文档
浏览迷:各种浏览器版本
安装selenium
pip install selenium
实例化一个浏览器对象:
from selenium import webdriver
bro = webdriver.Chrome(executable_path = './chromedriver')
方法:
获取文本和标签属性的方法
使用:获取红楼梦章节标题
from selenium import webdriver
from lxml import etree
from time import sleep
drive = webdriver.Chrome()
drive.get("https://www.shicimingju.com/book/hongloumeng.html")
page_text=drive.page_source
tree=etree.HTML(page_text)
list_data=tree.xpath('//div[@class="book-mulu"]/ul/li')
for i in list_data:
article_title=i.xpath('./a/text()')[0]
print(article_title)
sleep(5)
drive.quit()
6.1其他自动化操作
selenium的元素定位?
元素定位:自动化要做的就是模拟鼠标和键盘来操作来操作这些元素,点击、输入等等。操作这些元素前首先要找到它们,WebDriver提供很多定位元素的方法

访问元素信息
获取元素属性
.get_attribute('class')
获取元素文本
text
获取id
.id
获取标签名
.tag_name
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome('chromedriver.exe')
browser.get('https://www.baidu.com')
input = browser.find_element(by=By.ID, value='su')
print(input.get_attribute('class'))
print(input.tag_name)
a=browser.find_element(by=By.LINK_TEXT,value='新闻')
print(a.text)
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
drive=webdriver.Chrome()
drive.get('https://www.taobao.com/')
search_input =drive.find_element(By.ID,'q')
search_input.send_keys('Iphone ')
drive.execute_script("window.scrollTo(0,document.body.scrollHeight)")
sleep(3)
bottom = drive.find_element(By.CSS_SELECTOR,'.btn-search')
bottom.click()
drive.get('http://www.baidu.com')
sleep(2)
drive.back()
sleep(2)
drive.forward()
sleep(2)
sleep(4)
drive.quit()
6.2拉钩网自动化操作
from selenium.webdriver import Chrome
import time
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
drive = Chrome()
drive.get('https://www.lagou.com/')
quanguo=drive.find_element(by=By.XPATH,value='//*[@id="changeCityBox"]/p[1]/a')
quanguo.click()
drive.find_element(by=By.XPATH,value='//*[@id="search_input"]').send_keys('Python',Keys.ENTER)
div_list=drive.find_elements(by=By.XPATH,value='//*[@id="jobList"]/div[1]/div')
for i in div_list:
Job_name=i.find_element(by=By.XPATH,value='./div[1]//a').text
Job_price=i.find_element(by=By.XPATH,value='./div[1]//span').text
company_name=i.find_element(by=By.XPATH,value='./div[1]/div[2]//a').text
print(Job_name,Job_price,company_name)
time.sleep(2)
drive.quit()
6.3窗口切换
from selenium.webdriver import Chrome
import time
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
drive = Chrome()
drive.get('https://www.lagou.com/')
drive.find_element(by=By.XPATH, value='//*[@id="changeCityBox"]/p[1]/a').click()
time.sleep(1)
drive.find_element(by=By.XPATH, value='//*[@id="search_input"]').send_keys('Python', Keys.ENTER)
time.sleep(1)
drive.find_element(by=By.XPATH, value='//*[@id="jobList"]/div[1]/div[1]/div[1]/div[1]/div[1]/a').click()
drive.switch_to.window(drive.window_handles[-1])
job_detail = drive.find_element(by=By.XPATH,value='//*[@id="job_detail"]/dd[2]').text
print(job_detail)
drive.close()
drive.switch_to.window(drive.window_handles[0])
print(drive.find_element(by=By.XPATH, value='//*[@id="jobList"]/div[1]/div[1]/div[1]/div[1]/div[1]/a').text)
time.sleep(2)
drive.quit()
6.4动作链和iframe的处理
from selenium.webdriver import Chrome
from selenium.webdriver.common.by import By
from selenium.webdriver import ActionChains
from time import sleep
bro = Chrome()
bro.get('')
bro.switch_to.frame(id)
div = bro.find_element(By.ID, 'draggable')
action =ActionChains(bro)
action.click_and_hold(div)
for i in range(5):
action.move_by_offset(17,0).perform()
sleep(0.3)
action.release()
bro.quit()
6.5模拟登录qq空间
from selenium.webdriver import Chrome
from selenium.webdriver.common.by import By
from time import sleep
from selenium.webdriver import ActionChains
bro =Chrome()
bro.get('https://qzone.qq.com/')
bro.switch_to.frame('login_frame')
a_tag=bro.find_element(By.ID,'switcher_plogin')
a_tag.click()
username = bro.find_element(By.ID,'u')
password = bro.find_element(By.ID,'p')
username.send_keys('318129549')
sleep(1)
password.send_keys('song027..')
sleep(1)
login= bro.find_element(By.ID,'login_button')
login.click()
sleep(3)
bro.quit()
Phantomjs
1.什么是Phantomjs?
(1)是一个无界面的浏览器
(2)支持页面元素查找,js的执行等
(3)由于不进行css和gui渲染,运行效率要比真实的浏览器要快很多
2.如何使用Phantomjs?
(1)获取Phantoms.exe文件路径path
(2)browser=webdriver.PhantomJs(path)
(3)browser.get(url)
selenium新版本已经不能导入Phantomjs了
知道有这个东西就OK
Chrome handless
固定配置
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--dissable-gpu')
path=r'C:\Users\456\AppData\Local\Google\Chrome\Application\chrome.exe'
chrome_options.binary_location=path
browser = Chrome(chrome_options=chrome_options)
代码封装
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
def share_browser():
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--dissable-gpu')
path=r'C:\Users\31812\AppData\Local\Google\Chrome\Application\chrome.exe'
chrome_options.binary_location=path
browser= Chrome(chrome_options=chrome_options)
return browser
browser=share_browser()
url='https://www.baidu.com'
browser.get(url)
browser.save_screenshot('baidu.png')
谷歌无头浏览器+反检测
from selenium.webdriver import Chrome
from time import sleep
from selenium.webdriver.chrome.options import Options
from selenium.webdriver import ChromeOptions
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--dissable-gpu')
options=ChromeOptions()
options.add_experimental_option('excludeSwitches',['enable-outomation'])
bro = Chrome(chrome_options=chrome_options,options=options)
bro.get('https://www.baidu.com')
print(bro.page_source)
sleep(2)
bro.quit()
(七)scrapy框架
什么是scrapy?
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
scrapy创建以及运行
1.创建scrapyl项目:
终端输入 scrapy startproject 项目名称
2.项目组成
spiders
init_·py
自定义的爬虫文件.py --》由我们自己创建,是实现爬虫核心功能的文件
__init_.py
items.py --》定义数据结构的地方,是一个继承自scrapy.Item的类
middlewares.py --》中间件代理
pipelines.py --》管道文件,里面只有一个类,用于处理下载数据的后续处理
默认是300优先级,值越小优先级越高(1-1000)
settings.py --》配置文件比如:是否遵守robotsi协议,User-Agent定义等
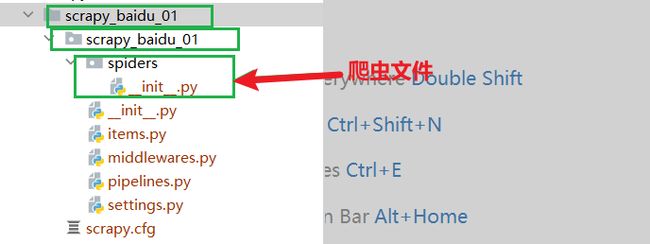
3. 创建爬虫文件:
(1)跳转到spiders文件夹 cd 项目名字/项目名字/spiders
(2)scrapy genspider 爬虫名字 网页的域名
爬虫文件的基本组成:
继承scrapy.Spider类
name ='baidu' ---》运行爬虫文件时使用的名字
allowed domains ---》爬虫允许的域名,在爬取的时候,如果不是此域名之下的url,会被过滤掉
start_urls --》声明了爬虫的起始地址,可以写多个u1,一般是一个
parse(self,response)--》解析数据的回调函数
response.text --》响应的是字符串
response.body --》响应的是二进制文件
response.xpath()--》xpath方法的返回值类型是selector列表
extract() --》提取的是selector对象的data属性值
extract_first() --》提取的是selector列表中的第一个数据
4.运行爬虫代码
scrapy crawl 爬虫名字 (--nolog)
scrapy架构组成
(1)引擎 --》自动运行,无需关注,会自动组织所有的请求对象,分发给下载器
(2)下载器 --》从引擎处获取到请求对象后,请求数据
(3)spiders --》Spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例
如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。换句话说,Spideri就是您定义爬取的动作及分析某个网页(或者是有些网页)的地方。
(4)调度器 --》有自己的调度规则,无需关注
(5)管道(Item pipeline) --》最终处理数据的管道,会预留接口供我们处理数据
当Item在Spider中被收集之后,它将会被传递到虹tem Pipeline,一些组件会按照一定的顺序执行对缸tem的处理。
每个item pipeline组件(有时称之为“Item Pipeline”)是实现了简单方法的Python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被丢弃而不再进行处理,
以下是item pipelinef的一些典型应用:
1.清理HTML数据
2.验证爬取的数据(检查item包含某些字段)
3.查重(并丢弃)
4.将爬取结果保存到数据库中
五大核心组件
- 引擎 Scrapy
用来处理整个系统的数据流处理,触发事物(框架核心)
- 调度器 Scheduler
用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回,可以想象成一个URL(抓取网页的地址或者说是链接)的优先队列,由它来决定下一个要抓取的网址是什么,同时去除重复的网址
- 下载器 Downloader
用于下载网页内容,并将网页内容返回给的链接(Scrapy下载器是建立在twisted这个高效的异步模型上的)
- 爬虫 Spider
爬虫是主要干活的,用于从特定的网页中提取自己需要的信息,即所有的实体(item)用户也可以从中提取链接,让Scrapy继续抓取下一个页面
- 项目管道 Pipeline
负责处理爬虫从网页中抽取的实体,主要功能是持久化存储,验证实体的有效性,清楚不许需要的信息,当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据
scrapy工作原理


scrapy shell
1.什么是scrapy she11?
Scrapy终端,是个交互终端,供您在未启动spider的情况下尝试及调试您的爬取代码。其本意是用来测试提取数据的代码,不过您可以将其作为正常的Python终端,在上面测试任何的Python代码。
该终端是用来测试XPath或Css表达式,查看他们的工作方式及从爬取的网页中提取的数据。在编写您的spider时,该终端提供了交互性测试您的表达式代码的功能,免去了每次修改后运行spider的麻烦。
一旦熟悉了Scrapy终端后,您会发现其在开发和调试spider时发挥的巨大作用。
2.安装ipython
安装:pip install ipython
简介:如果您安装了IPython,Scrapy终端将使用IPython(替代标准Python终端)。IPython终端与其他相比更为强大,提供智能的自动补全,高亮输出,及其他特性。
3.应用:
直接打开cmd输入scrapy shell 域名 即可
(1)scrapy shell www.baidu.com
(2)scrapy shell http://www.baidu.com
(3)scrapy shell "http://www.baidu.com"
(4)scrapy shell "www.baidu.com"
语法:
(1)response对象:
response.body
response.text
response.url
response.status
(2)response的解析:
response.xpath()(常用)
使用xpath路径查询特定元素,返回一个selector列表对象
yield
1.带有yield的函数不再是一个普通函数,而是一个生成器generator,可用于迭代
2.yield是一个类似return的关键字,迭代一次遇到yield时就返回yield,后面(右边)的值。重点是:下一次迭代时,从上一次迭代遇到的yield后面的代码(下一行)开始执行
3.简要理解:yield就是return返回一个值,并且记住这个返回的位置,下次迭代就从这个位置后(下一行)开始
案例:
1.当当网 (1)yield (2).管道封装 (3).多条管道下载 (4)多页数据下载
2.电影天堂 (1) 一个item包含多级页面的数据
解析相关
应用
1.1scrapy持久化存储:
- 基于终端指令:
- 要求:只可以将parse方法的返回值存储到本地的文本文件中
- 要求:持久化存储对应的文本文件类型只可以是:json,jsonlines,jl,csv,xml,
- 指令:``scrapy crawl SpiderName -o filepath`
- 缺点:局限性强,(数据只可以存储到指定后缀的文本文件中)
- 基于管道指令:
- 编码流程:
-
- 数据解析
-
- 在item类中定义相关的属性
-
- 将解析的数据封装到item 类型的对象
-
- 将item类型对象提交给管道进行持久化存储的操作
-
- 在管道类的process_item中要将其接收到的item对象中存储的数据进行持久化存储操作
-
- 在配置文件中开启管道
- 优点:通用性强。
基于本地存储
基于终端指令存储只可以将parse方法的返回值存储到本地
scrapy crawl douban -o qidian.csv
import scrapy
class DoubanSpider(scrapy.Spider):
name = 'douban.'
start_urls = ['https://www.qidian.com/all/']
def parse(self, response):
list_data=response.xpath('//div[@class="book-img-text"]/ul/li')
alldata=[]
for i in list_data:
title =i.xpath('./div[2]/h2/a/text()').extract_first()
author=i.xpath('./div[2]/p/a/text()')[0].extract()
dic={
'title':title,
'author':author
}
alldata.append(dic)
return alldata
基于管道存储
使用管道要在``settings.py`中开启管道
ITEM_PIPELINES = {
'scrapt_dangdang_03.pipelines.ScraptDangdang03Pipeline': 300,
}
1.1爬虫文件的编写
import scrapy
from scrapt_dangdang_03.items import ScraptDangdang03Item
class DangSpider(scrapy.Spider):
name = 'dang'
allowed_domains = ['category.dangdang.com']
start_urls = ['http://category.dangdang.com/cp01.01.02.00.00.00.html']
def parse(self, response):
li_list = response.xpath('//ul[@id="component_59"]/li')
for li in li_list:
src = li.xpath('.//img/@data-original').extract_first()
if not src:
src = li.xpath('.//img/@src').extract_first()
name = li.xpath('.//img/@alt').extract_first()
price = li.xpath('.//p[3]/span[1]/text()').extract_first()
print(src, name, price)
item = ScraptDangdang03Item(src=src, name=name, price=price)
yield item
1.2 item文件的编写
import scrapy
class ScraptDangdang03Item(scrapy.Item):
src = scrapy.Field()
name = scrapy.Field()
price = scrapy.Field()
1.3管道文件的编写
from itemadapter import ItemAdapter
class ScraptDangdang03Pipeline:
fp = None
def open_spider(self, spider):
print('开始爬虫'.center(20,'-'))
self.fp = open('book.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
self.fp.write(str(item))
return item
def close_spider(self, spier):
print('结束爬虫'.center(20, '-'))
self.fp.close()
开启多条管道
(1)定义管道类
(2)在settings.py中开启管道
ITEM_PIPELINES = {
}
案例1
1.1爬虫文件的编写
import scrapy
from scrapt_dangdang_03.items import ScraptDangdang03Item
class DangSpider(scrapy.Spider):
name = 'dang'
allowed_domains = ['category.dangdang.com']
start_urls = ['http://category.dangdang.com/cp01.01.02.00.00.00.html']
def parse(self, response):
li_list = response.xpath('//ul[@id="component_59"]/li')
for li in li_list:
src = li.xpath('.//img/@data-original').extract_first()
if not src:
src = li.xpath('.//img/@src').extract_first()
name = li.xpath('.//img/@alt').extract_first()
price = li.xpath('.//p[3]/span[1]/text()').extract_first()
print(src, name, price)
item = ScraptDangdang03Item(src=src, name=name, price=price)
yield item
1.2item文件的编写
import scrapy
class ScraptDangdang03Item(scrapy.Item):
src = scrapy.Field()
name = scrapy.Field()
price = scrapy.Field()
1.3管道类的编写
from itemadapter import ItemAdapter
class ScraptDangdang03Pipeline:
fp = None
def open_spider(self, spider):
print('开始爬虫'.center(20, '-'))
self.fp = open('book.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
self.fp.write(str(item))
return item
def close_spider(self, spier):
print('结束爬虫'.center(20, '-'))
self.fp.close()
import urllib.request
class DangDangDownloadPipeline:
def process_item(self, item, spier):
url = 'http:' + item.get('src')
filename = './books' + item.get('name') + '.jpg'
print('正在下载{}'.format(item.get("name")).center(20,'-'))
urllib.request.urlretrieve(url=url, filename=filename)
return item
案例2
2.1 爬虫文件的编写
import scrapy
from douban.items import DoubanItem
class DoubanSpider(scrapy.Spider):
name = 'douban.'
start_urls = ['https://www.qidian.com/all/']
def parse(self, response):
list_data=response.xpath('//div[@class="book-img-text"]/ul/li')
for i in list_data:
title =i.xpath('./div[2]/h2/a/text()').extract_first()
author=i.xpath('./div[2]/p/a/text()')[0].extract()
item = DoubanItem()
item['title'] = title
item['author']=author
yield item
2.2 items文件的编写
import scrapy
class DoubanItem(scrapy.Item):
title = scrapy.Field()
author=scrapy.Field()
2.3管道类的重写
from itemadapter import ItemAdapter
import pymysql
class DoubanPipeline:
fp = None
def open_spider(self, spider):
print('开始爬虫')
self.fp = open('./qidian.txt', 'w', encoding='utf-8')
def process_item(self, item, spider):
author = item['author']
title = item['title']
self.fp.write(title + ':' + author + '\n')
return item
def close_spider(self, spider):
print('结束爬虫')
self.fp.close()
class mysqlPipeline:
conn = None
cursor = None
def open_spider(self, spider):
self.conn = pymysql.Connect(host='服务器IP地址', port=端口号, user='root', password=自己的密码', db='qidian',
charset='utf8')
def process_item(self, item, spider):
self.cursor = self.conn.cursor()
try:
self.cursor.execute('insert into qidian values(0,"%s","%s")'%(item["title"],item["author"]))
self.conn.commit()
except Exception as e:
print(e)
self.conn.rollback()
return item
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
1.2基于Spider的全站数据解析爬取
- 就是将网站中某板块下的全部页码对应的页面数据进行爬取
- 自行手动进行请求发送数据(推荐)
- 手动发送请求
yield scrapy.Resquest(url,callback) callback专门用作数据解析
案例1.:
import scrapy
class QidianSpider(scrapy.Spider):
name = 'qidian'
start_urls = ['https://www.qidian.com/all/']
url='https://www.qidian.com/all/page%d/'
page_num=2
def parse(self, response):
list_data=response.xpath('//div[@id="book-img-text"]/ul/li')
for i in list_data:
title =i.xpath('./div[2]/h2/a/text()').extract_first()
author=i.xpath('./div[2]/p/a[1]/text()')[0].extract()
styple=i.xpath('./div[2]/p/a[2]/text()').extract_first()
styple1=i.xpath('./div[2]/p/a[3]/text()').extract_first()
type=styple+'.'+styple1
if self.page_num<=3:
new_url=format(self.url%self.page_num)
self.page_num+=1
yield scrapy.Request(url=new_url,callback=self.parse)
案例2:当当网青春文学书籍图片下载
import scrapy
from scrapt_dangdang_03.items import ScraptDangdang03Item
class DangSpider(scrapy.Spider):
name = 'dang'
allowed_domains = ['category.dangdang.com']
start_urls = ['http://category.dangdang.com/cp01.01.02.00.00.00.html']
base_url = 'http://category.dangdang.com/pg'
page = 1
def parse(self, response):
li_list = response.xpath('//ul[@id="component_59"]/li')
for li in li_list:
src = li.xpath('.//img/@data-original').extract_first()
if not src:
src = li.xpath('.//img/@src').extract_first()
name = li.xpath('.//img/@alt').extract_first()
price = li.xpath('.//p[3]/span[1]/text()').extract_first()
print(src, name, price)
item = ScraptDangdang03Item(src=src, name=name, price=price)
yield item
if self.page < 100:
self.page += 1
url = self.base_url + str(self.page) + '-cp01.01.02.00.00.00.html'
yield scrapy.Request(url=url, callback=self.parse)
1.3请求传参
- 使用场景:如果爬取解析的数据不在同一张页面中(深度爬取),
将item 传递给请求所对应的回调函数
需要将不同解析方法中获取的解析数据封装存储到同一个Item中,并且提交到管道
案例:起点小说网
- 爬虫文件的编写
import scrapy
from qidian2.items import Qidian2Item
class QidianSpider(scrapy.Spider):
name = 'qidian'
start_urls = ['https://www.qidian.com/all/']
def detail_parse(self,response):
item=response.meta['item']
detail_data=response.xpath('//div[@class="book-intro"]/p//text()').extract()
detail_data=''.join(detail_data)
item['detail_data']=detail_data
yield item
def parse(self, response):
list_data=response.xpath('//div[@class="book-img-text"]/ul/li')
for i in list_data:
item = Qidian2Item()
title=i.xpath('./div[2]/h2/a/text()').extract_first()
item['title']=title
detail_url='https:'+i.xpath('./div[2]/h2/a/@href').extract_first()
yield scrapy.Request(url=detail_url,callback=self.detail_parse,meta={'item':item})
- items文件
import scrapy
class Qidian2Item(scrapy.Item):
title= scrapy.Field()
detail_data=scrapy.Field()
pass
- pipelines文件中管道类的重写
from itemadapter import ItemAdapter
class Qidian2Pipeline:
fp=None
def open_spider(self,spider):
print('开始爬虫!!!!!!!!!!!!!')
self.fp=open('./qidian.txt','w',encoding='utf-8')
def process_item(self, item, spider):
title=item['title']
detail_data=item['detail_data']
self.fp.write(title+":"+detail_data+"\n")
return item
def close_spider(self,spider):
print('结束爬虫!!!!!!!!!!!!')
self.fp.close()
图片管道
图片数据爬取之自定义ImagePipeline
三个核心的方法:
get_media_requests(elf,item,info)根据item中图片连接的属性,返回图片下载的requestfile_path(self,request,response,info)根据请求和响应返回图片保存的位置(相对于IMAGES STORE)item_completed(self,results,.item,info)图片下载完成后,从results的结果获取图片的保存路径,并设置到item中,最后返回这个item
案例一
* 基于scrapy爬取字符串类型数据和爬取图片类型数据区别:
- 字符串: 只需要基于xpath 进行解析,且提交管道进行持久化存储
- 图片: 只可以通过xpath解析出图片的src属性,单独的对图片地址发请求获取图片二进制类型的数据。
* 基于ImagePipeline:
- 只需要将img的src属性值进行解析,提交到管道,管道就会对图片src进行发送请求获取图片二进制类型的数据,且还会帮我么进行持久化存储。
* 需求:爬取站长素材中高清图片
- 使用流程:
1. 数据解析(图片地址)
2. 将存储图片地址的item提交到指定的管道类中
3. 在管道文件中自定义一个基于ImagesPipeline的一个管道类
- get_media_requests()
- file_path()
- item_completed()
4. 在配置文件中:
- 指定存储图片的目录:IMAGES_STORE='./imgs_站长素材'
- 开启自定义的管道:
1. 爬虫文件编写解析数据
import scrapy
from imgPro.items import ImgproItem
class ImgSpider(scrapy.Spider):
name = 'img'
start_urls = ['https://sc.chinaz.com/tupian/']
def parse(self, response):
div_list= response.xpath('//div[@id="container"]/div')
for i in div_list:
img_address='https:'+i.xpath('./div/a/img/@src').extract_first()
item=ImgproItem()
item['src']=img_address
yield item
2.把图片地址提交到管道
scr=scrapy.Field()
3.将解析到的数据封装到item中
from imgPro.items import ImgproItem
item=ImgproItem()
item['img_address']=img_address
yield item
4.管道类的重写 pipelines
import scrapy
from scrapy.pipelines.images import ImagesPipeline
class ImagsPipeline(ImagesPipeline):
def get_media_requests(self,item ,info ):
yield scrapy.Request(item['src'])
def file_path(self,request,response=None,info=None):
img_name=request.url.split('/')[-1]
return img_name
def item_completed(self,results,item ,info):
return item
5.settings中图片管道相关参数
IMAGES_STORE='./imgs_站长素材'
IMAGES_THUMBS={
'small':(60,32),
'big':(120,80)
}
6.settings配置
ITEM_PIPELINES = {
'imgPro.pipelines.ImagsPipeline': 300,
}
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
ROBOTSTXT_OBEY = False
LOG_LEVEL="ERROR"
```xxxxxxxxxx11 1
案例二
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class BookSpider(CrawlSpider):
name = 'book'
allowed_domains = ['dushu.com']
start_urls = ['https://dushu.com/book/']
rules = (
Rule(LinkExtractor(restrict_css='.sub-catalog'), follow=True),
Rule(LinkExtractor(allow='/book/\d+?_\d+?\.html'), follow=True),
Rule(LinkExtractor(allow='/book/\d+/'), callback='parse_item', follow=False),
)
def parse_item(self, response):
item = {}
item['name']=response.css('h1::text').get()
item['cover']=response.css('.pic img::attr("src")').get()
item['price']=response.css('.css::text').get()
table =response.css('#ctl00_c1_bookleft table')
item['author']=table.xpath('.//tr[1]/td[2]/text()').get()
item['publish']=table.xpath('.//tr[2]/td[2]/a/text()').get()
table=response.css('.book-details>table')
item['isbn']=table.xpath('.//tr[1]/td[2]/text()').get()
item['publish_date']=table.xpath('.//tr[1]/td[4]/text()').get()
item['pages']=table.xpath('.//tr[2]/td[4]/text()').get()
yield item
from itemadapter import ItemAdapter
from scrapy.pipelines.images import ImagesPipeline
from scrapy import Request
class DushuPipeline:
def process_item(self, item, spider):
return item
class BookImagePipiline(ImagesPipeline):
DEFAULT_IMAGES_URLS_FIELD = 'cover'
DEFAULT_IMAGES_RESULT_FIELD = 'path'
def get_media_requests(self, item, info):
return Request(item.get('cover'),meta={'book_name':item['name']})
def file_path(self, request, response=None, info=None, *, item=None):
name=request.meta['book_name']
return f'{name}.jpg'
def item_completed(self, results, item, info):
item['path']=[ v['path'] for k,v in results if k]
return item
import os.path
BOT_NAME = 'dushu'
SPIDER_MODULES = ['dushu.spiders']
NEWSPIDER_MODULE = 'dushu.spiders'
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'
ROBOTSTXT_OBEY = False
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'Referer':'https://www.dushu.com/book/1114_13.html'
}
ITEM_PIPELINES = {
'dushu.pipelines.DushuPipeline': 300,
'dushu.pipelines.BookImagePipiline':302
}
BASE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
IMAGES_STORE=os.path.join(BASE_DIR,'images')
IMAGES_THUMBS={
'small':(60,32),
'big':(120,80)
}
CrawlSpider
1.继承自scrapy.Spider
2.独门秘笈
CrawlSpider可以定义规则,再解析html内容的时候,可以根据链接规则提取出指定的链接,然后再向这些链接发送请求
所以,如果有需要跟进链接的需求,意思就是爬取了网页之后,需要提取链接再次爬取,使用CrawlSpider是非常合适的
3.提取链接
链接提取器,在这里就可以写规则提取指定链接
scrapy.linkextractors.LinkExtractor(
a11ow=(),
deny =()
allow_domains =()
deny_domains =()
restrict xpaths=(),
restrict_css =()
4.模拟使用
正则用法:1inks1 = LinkExtractor(allow=r'1ist23_\d+\.html')
xpath: links2 = LinkExtractor(restrict_xpaths=r'//div[@class="x"]')
css用法:links3 = LinkExtractor(restrict_css='.X')
5.提取连接
link.extract_links(response)
6.注意事项
【注1】callback只能写函数名字符串,cal1back='parse_item'
【注2】在基本的spider中,如果重新发送清求,那里的cal1back写的是 cal1back=self.parse_item
【注3】follow=true是否跟进就是按照提取连接规则进行提取
CrawlSpider案例
案例一:读书网数据入库
l.创建项目:scrapy startproject dushuproject
2.跳转到spiders路径 cd\dushuproject\dushuproject\spiders
3.创建爬虫类:scrapy genspider -t crawl read www.dushu.com
4.items
5.spiders
6.settings
7.pipelines
数据保存到本地
数据保存到mysq1数据库
数据入库:
(1)settings配置参数:
DBH0T='127.0.0.1'
DB_PORT =3306
DB USER 'root'
DB PASSWORD '1234'
DB_NAME ='readbood'
DB_CHARSET = 'utf8'
(2)管道配置
from scrapy.utils.project import get_project_settings
import pymysql
class MysqlPipeline(object):
代码实现:
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy_readbook_05.items import ScrapyReadbook05Item
class ReadSpider(CrawlSpider):
name = 'read'
allowed_domains = ['www.dushu.com']
start_urls = ['https://www.dushu.com/book/1188_1.html']
rules = (
Rule(LinkExtractor(allow=r'/book/1188_\d+\.html'), callback='parse_item', follow=True),
)
def parse_item(self, response):
img_list=response.xpath('//div[@class="bookslist"]/ul/li//img')
for img in img_list:
src=img.xpath('./@data-original').extract_first()
name=img.xpath('./@alt').extract_first()
book=ScrapyReadbook05Item(name=name,src=src)
yield book
import scrapy
class ScrapyReadbook05Item(scrapy.Item):
name=scrapy.Field()
src=scrapy.Field()
DB_HOST = '127.0.0.1'
DB_PORT = 3306
DB_USER = 'root'
DB_PASSWORD = '123.com'
DB_NAME = 'readbook'
DB_CHARSET = 'utf8'
ITEM_PIPELINES = {
'scrapy_readbook_05.pipelines.ScrapyReadbook05Pipeline': 300,
'scrapy_readbook_05.pipelines.MysqlPipiline': 301,
}
from itemadapter import ItemAdapter
class ScrapyReadbook05Pipeline:
def open_spider(self, spider):
self.fp = open('./book.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
print('正在写入数据 : ' + item.get('name'))
self.fp.write(str(item))
return item
def close_spider(self, spider):
self.fp.close()
from scrapy.utils.project import get_project_settings
import pymysql
class MysqlPipiline:
def open_spider(self, spider):
settings = get_project_settings()
self.host = settings['DB_HOST']
self.port = settings['DB_PORT']
self.user = settings['DB_USER']
self.password = settings['DB_PASSWORD']
self.name = settings['DB_NAME']
self.charset = settings['DB_CHARSET']
self.connect()
def connect(self):
self.conn = pymysql.connect(
user=self.user,
host=self.host,
port=self.port,
password=self.password,
database=self.name,
charset=self.charset
)
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
sql = 'insert into book(name,src) values("{}","{}")'.format(item['name'], item['src'])
self.cursor.execute(sql)
self.conn.commit()
print(f'数据 : {item["name"]}提交成功......')
return item
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
案例二: 使用默认的ImagesPipeline下载图片
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class BookSpider(CrawlSpider):
name = 'book'
allowed_domains = ['dushu.com']
start_urls = ['https://dushu.com/book/']
rules = (
Rule(LinkExtractor(restrict_css='.sub-catalog'), follow=True),
Rule(LinkExtractor(allow='/book/\d+?_\d+?\.html'), follow=True),
Rule(LinkExtractor(allow='/book/\d+/'), callback='parse_item', follow=False),
)
def parse_item(self, response):
item = {}
item['name']=response.css('h1::text').get()
item['image_urls']=response.css('.pic img::attr("src")').extract()
item['images']=[]
item['price']=response.css('.css::text').get()
table =response.css('#ctl00_c1_bookleft table')
item['author']=table.xpath('.//tr[1]/td[2]/text()').get()
item['publish']=table.xpath('.//tr[2]/td[2]/a/text()').get()
table=response.css('.book-details>table')
item['isbn']=table.xpath('.//tr[1]/td[2]/text()').get()
item['publish_date']=table.xpath('.//tr[1]/td[4]/text()').get()
item['pages']=table.xpath('.//tr[2]/td[4]/text()').get()
yield item
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'dushu.pipelines.DushuPipeline': 300,
'scrapy.pipelines.images.ImagesPipeline':301
}
BASE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
IMAGES_STORE=os.path.join(BASE_DIR,'images')
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'Referer':'https://www.dushu.com/book/1114_13.html'
}
日志信息和等级
(1)日志级别:
CRITICAL: 严重错误
ERROR: 一股错误
WARNING: 警告
INFO: 一般信息
DEBUG: 调试信息
默认的日志等级是DEBUG
只要出现了DEBUG或者DEBUG以上等级的日志
那么这些日志将会打印
(2)settings.py文件设置:
默认的级别为DEUG,会显示上面所有的信息
在配置文件中settings.py
L0G_FILE:将屏幕显示的信息全部记录到文件中,屏幕不再显示,注意文件后缀一定是.10g
L0G_LEVEL:设置日志显示的等级,就是显示哪些,不显示哪些
L0G_FILE='logdemo.log'
L0G_LEVEL='INFO'
scrapy的post请求
(1)重写start_requests方法:
def start_requests(self)
(2)start_requests的返回值:
scrapy.FormRequest(url=url,headers=headers,callback=self.parse_item,formdata=data)
url:要发送的post地址
headers:可以定制头信息
ca11back:回调函数
formdata:post所携带的数据,这是一个字典
import scrapy
import json
class TestpostSpider(scrapy.Spider):
name = 'testpost'
allowed_domains = ['fanyi.baidu.com']
def start_requests(self):
url = 'https://fanyi.baidu.com/sug'
data = {
'kw': 'python'
}
yield scrapy.FormRequest(url=url, formdata=data, callback=self.parse_second)
def parse_second(self, response):
content = response.text
obj = json.loads(content)
print(obj)
分布式爬虫
pip install scrapy-redis
安装服务器并执行
docker pull redis
docker run -dit --name redis-server -p 6378:6379 redis

创建爬虫项目
scrapy startproject dushu_redis
cd dushu_redis\dushu_redsi\spiders
scrapy genspider guoxu dushu.com
编写爬虫程序
from scrapy_redis.spiders import RedisSpider
from scrapy import Request
class GuoxueSpider(RedisSpider):
name = 'guoxue'
allowed_domains = ['dushu.com']
redis_key = 'gx_start_urls'
def parse(self, response):
for url in response.css('.sub-catalog a::attr("href")').extract():
yield Request(url='https://www.dushu.com' + url, callback=self.parse_item)
def parse_item(self, response):
div_list = response.css('.book-info')
for i in div_list:
item = {}
item['name'] = i.xpath('./div//img/@alt').get()
item['cover'] = i.xpath('./div//img/@src').get()
item['detail_url'] = i.xpath('./div/a/@href').get()
yield item
next_url=response.css('.pages ').xpath('./a[last()]/@href').get()
yield Request(url='https://www.dushu.com' + next_url, callback=self.parse_item)
settings配置
SCHEDULER = 'scrapy_redis.scheduler.Scheduler'
SCHEDULER_PERSIST = True
DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter'
REDIS_URL='redis://192.168.163.128:6378/0'
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36'
ROBOTSTXT_OBEY = False
配置好后,然后执行爬虫文件
scrapy crawl guoxue
进入到redis数据库
docker exec -it redis-server bash
root@1472cc4b0e69:/data
127.0.0.1:6379> select 0
OK
127.0.0.1:6379> keys *
(empty array)
127.0.0.1:6379> lpush gx_start_urls https://www.dushu.com/guoxue/
(integer) 1
127.0.0.1:6379>
