Spring的IOC和AOP和事务源码流程详解
建议全文对比着这个图来看https://www.processon.com/view/link/5f15341b07912906d9ae8642
IOC
控制反转
配置
通过xml
基于注解+xml的配置: @Compont(@serivce @controller @repository) @Autowride
在之前的项目中,我们都是通过xml文件进行bean或者某些属性的赋 值,其实还有另外一种注解的方式,在企业开发中使用的很多,在bean上添加 注解,可以快速的将bean注册到ioc容器。
这种方式呢只是对于我们自己写的类不需要用标签来交给spring了,通过注解就可以了。但是对于第三方的,比如数据库连接池还是得在xml中配置。因为我们没有办法去第三方的源码里加入我们的注解和注入。
如果想要将自定义的bean对象添加到IOC容器中,需要在类上添加某些注解
Spring中包含4个主要的组件添加注解:
@Controller:控制器,推荐给controller层添加此注解
@Service:业务逻辑,推荐给业务逻辑层添加此注解
@Repository:仓库管理,推荐给数据访问层添加此注解
@Component:给不属于以上基层的组件添加此注解
注意:我们虽然人为的给不同的层添加不同的注解,但是在spring看来,可以在任意层添 加任意注解
spring底层是不会给具体的层次验证注解,这样写的目的只是为了提高可读性,最偷懒的 方式就是给所有想交由IOC容器管理的bean对象添加component注解
使用注解需要如下步骤:
1、添加上述四个注解中的任意一个
2、添加自动扫描注解的组件,此操作需要依赖context命名空间
3、添加自动扫描的标签context:component‐scan
注意:当使用注解注册组件和使用配置文件注册组件是一样的,但是要注意:
1、组件的id默认就是组件的类名首字符小写,如果非要改名字的话,直接在注解中添加 即可
2、组件默认情况下都是单例的,如果需要配置多例模式的话,可以在注解下添加@Scope注解
<!‐‐ 定义自动扫描的基础包: base‐package:指定扫描的基础包,spring在启动的时候会将基础包及子包下所 有加了注解的类都自动扫描进IOC容器 ‐‐> <context:component‐scan base‐package="cn.tulingxueyuan"> context:compo nent‐scan> beans>
基于Java的配置: 即JavaConfig。@Confiration @Bean @Import
@Configuration 就相当于创建了一个xml 文件
@ComponentScan(“cn.tulingxueyuan”) //等于
@Import({JDBCConfig.class, Abc.class})导入其他的配置类
XML中配置第三方开发的资源是很方便的,但使用注解驱动无法在第三方开发的资源中进行编辑,因此会增加一部分的代码量
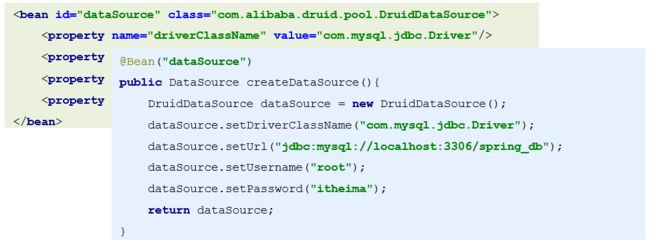
@Bean注入和factorybean注入区别
使用@Bean注入和factorybean注入,创建对象时,spring单独处理了factorybean,说明还是有区别的;
factorybean最大的亮点,还是在getObject这块,像mybatis,feign,我们在用的时候,注入的bean他都是一个接口,它注入到容器总不能也是个接口吧,这玩意能实例化嘛?以mybatis为例,实际上mapper接口注入的时候,类型是MapperFactoryBean,通过getObject,从sqlsession获取mapper,getObject后返回mapper的代理对象;
factorybean的强大就在这里,我注入容器的真实类型是FactoryBean,从容器获取的类型,不一定就是FactoryBean他本身;你用@Bean方式注入的对象,是啥就是啥,不可能说我注入的是DataSource,返回的UserService,但是使用factorybean,他注入的是factorybean,但是返回的是你getobject的对象了,他是啥,什么可能都有
DI
依赖注入:将成员属性注入到当前类,可以xml也可以@autowired。用类的反射机制为类的属性赋值。
常用注解
https://www.cnblogs.com/859630097com/p/14504509.html
类注解
@Configuration:设置当前类为 Spring 核心配置加载类,核心配合类用于替换 Spring 核心配置文件
@ComponentScan:设置 Spring 配置加载类扫描规则
@Controller、@Service 、@Repository 是 @Component 的衍生注解:设置该类为Spring 管理的 bean
@Scope:设置该类作为 bean 对应的 scope 属性
@Order:配置类注解。控制配置类的加载顺序,值越小越先加载
@Import:导入第三方bean作为spring控制的资源,这些类都会被Spring创建并放入ioc容器
@Import注解在同一个类上,仅允许添加一次,如果需要导入多个,使用数组的形式进行设定
@Configuration
@Import(OtherClassName.class)
public class ClassName {
}
@Import({JDBCConfig.class, Abc.class})@Bean所在的类可以使用导入的形式进入spring容器,无需使用@Component声明
方法/属性注解
@PostConstruct、@PreDestroy:设置该方法作为 bean 对应的生命周期方法
@Bean:设置该方法的返回值作为 Spring 管理的 bean。@Bean是一个方法级别的注解,它与XML中的 元素类似。注解支持 提供的一 些属性,例如 * init-method * destroy-method * autowiring * name
原本我们用@component,是把类交给spring去生产管理,让spring去new。用@bean注解是我们自己干预bean的生成,new一个bean,return这个bean交给spring。用在比如集成mybatis的时候。
因为第三方 bean 无法在其源码上进行修改,使用 @Bean 解决第三方 bean 的引入问题
该注解用于替代 XML 配置中的静态工厂与实例工厂创建 bean,不区分方法是否为静态或非静态
@Bean 所在的类必须被 Spring 扫描加载,否则该注解无法生效。所以需要在@Configuration类或@Component类中使用@Bean注解
怎么去自动依赖外部bean:直接在方法的形参里面写上需要依赖的bean就可以了,不需要@autowired
@Bean public A a(B b){ A aa=new A(); 对A做操作 使用b return aa; }如果与@component的bean名字重复,这个会覆盖@component的
@Value:设置对应属性的值或对方法进行传参
@Autowired、@Qualifier:@Autowired 默认按类型装配,指定 @Qualifier 后可以指定自动装配的 bean 的 id
在启动spring IoC时,容器自动装载了一个AutowiredAnnotationBeanPostProcessor后置处理器,当容器扫描到@Autowied、@Resource或@Inject时,就会在IoC容器自动查找需要的bean,并装配给该对象的属性。
在使用 @Autowired 时,首先在容器中查询对应类型的 bean,如果查询结果刚好为一个,就将该 bean 装配给 @Autowired 指定的数据,如果查询的结果不止一个,那么 @Autowired 会根据名称来查找。如果查询的结果为空,那么会抛出异常。解决方法:使用 required = false
@Resource:JDK提供的
@Autowired默认是按照类型装配注入的,默认情况下它要求依赖对象必须存在(可以设置它required属性为false)
@Resource默认按照名称来装配注入,只有当找不到与名称匹配的bean才会按照类型来装配注入
@Autowired是spring自带的, @Resource是JSR250规范实现的,需要导入不同的包
方法/类注解
@Lazy:类注解、方法注解。控制bean的加载时机,使其延迟加载,获取的时候加载。
重要类
BeanFactory:使用简单工厂模式,通过传入bean的名字,生产bean。
BeanDefinition:顶层接口,有个实现类,里面封装了生产bean的原料,就是一些成员变量。包括:bean的全类名、单例还是多例、

BeanDefinitionReader:读取所有的配置类或者.xml文件。相当于销售把所有人都拉进店里面。
BeanDefinitionScanner:扫描读取进来的配置类或者.xml文件,找到那些有@component或者的想要注册bean的。相当于接待,找到真正有购买意愿的。
BeanDefinitionRegistry:将这些bean的想法,即是否懒加载啊、单例多例啊,注册成BeanDefiniton,放到BeanDefinitonMap里面。
类辨析
BeanFactory需要获得图纸,即BeanDefinition才能生产bean。他没有读取,扫描,注册BeanDefinition的能力。(两者都支持 BeanPostProcessor、BeanFactoryPostProcessor 的使用,但两者之间的区别是:BeanFactory 需要手动注册,而 ApplicationContext 则是自动注册)BeanFactory是一个纯粹的工厂,只负责生产Bean,是没有装配(设计)BeanDefinition的功能的,专业的事还是交给专业的人做,设计的事情还是交由ApplicationContext完成的。
ApplicationContext是通过读取xml或者资源配置类,然后增加一些服务,最后生成BeanDefinition,再交给BeanFactory生产bean。

如果一个类实现了FactoryBean接口,那么就要实现返回对象的方法。也就是这个类的bean不再由Spring给你返回了,而是Spring在流程中看到你这个类实现了FactoryBean方法,那么就会直接调用你这个类的GetObject返回你个性化定制的Bean.

重点概念
**bean工厂后置处理器(BeanFactoryPostProcessor)**的用途,这是一个接口,是一个扩展点。然后多个实现类去实现这个接口,那么就可以按照实现类自己的想法去解析BeanDefinition,用于进行bean定义的加载 比如我们的包扫描,@import @Bean 等等。然后Spring在固定的地方会调用这个后置处理器,如果你有类实现了后置处理器,那么就会调用你这个实现类的方法。
spring只是提供这个接口,和扫描这个接口实现类的方法,并不关心你是怎么解析出来的。所以这相当于解耦了。将解析BeanDefinition和Spring主要逻辑进行解耦。
bean后置处理器(BeanPostProcessor):就是一个接口,AOP啊,事务啊都有实现类实现了这个接口。我们也可以自定义一些类实现这个接口(需要@component注册)。(用接口的原因是拓展性,接口规定内容,函数重写,这样每个重写的函数都规范化)Spring在很多环节处,会去读取Bean的后置处理器,判断这个处理器的类型,然后根据类型找到实现类,从而执行实现类的专属扩展方法。
这个实现类呢在很多时候被调用,有的实现类作用是为了返回一个bean,一个经过我们特殊处理(AOP和事务)的代理bean。具体的就是在生成bean的过程中会调用,由于我们refresh方法中已经注册了所有的后置处理器。调用的时候根据不同场景会判断,注册的所有后置处理器,有没有符合我这个场景的后置处理器,如果符合,那就按照这个后置处理器处理后的bean返回。
两者区别,
bean工厂后置处理器主要是针对BeanDefinition的,是对解析BeanDefinition做的扩展
bean后置处理器主要针对bean的,是对生成bean的过程中设置了很多扩展点(增增补补,甚至直接停止生成)。
有关bean后置处理器(BeanPostProcessor)的结构层次
对照这个图体会后置处理器的继承实现关系和作用

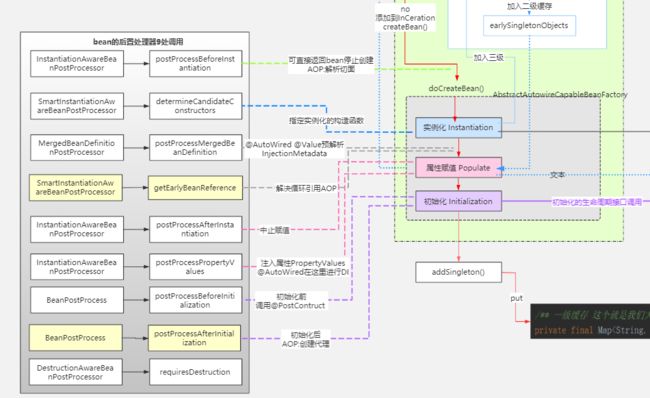
IOC流程与Bean生命周期
读取Bean图纸
注解式(使用@component、@Bean…)和xml式(
然后通过AnnotationConfigApplicationContext(注解式加载器)或者ClassPathXMLApplicationContext(xml加载器)加载Spring上下文,将配置类或者xml读取、扫描、注册成BeanDefinition图纸,然后交给BeanDefinitionMap。然后BeanFactory从Map里面取出图纸,去生产Bean。
形象画法
真正执行:
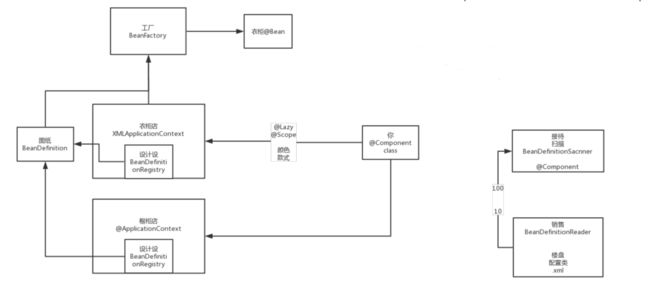

读取图纸源码
主要重点在refresh方法中
public AnnotationConfigApplicationContext(Class<?>... annotatedClasses) {
this();
// 解析配置类,封装成一个 BeanDefinitionHolder,并注册到容器
register(annotatedClasses);
// 加载刷新容器中的 Bean
refresh();
}
public AnnotationConfigApplicationContext() {
// 注册 Spring 的注解解析器到容器
this.reader = new AnnotatedBeanDefinitionReader(this);
// 实例化路径扫描器,用于对指定的包目录进行扫描查找 bean 对象
this.scanner = new ClassPathBeanDefinitionScanner(this);
}
this和register方法执行完,都只是注册了Reader、Scanner而已,并没有解析成BeanDefinition。只是准备好了一些创世纪的类,包括解析BeanDefinition的函数(这个函数实现了BeanFactoryPostProcessor这个类,所以BeanDefinition其实是在refresh方法中被真正解析和创建)。
这就是BeanFactoryPostProcessor的用途,这是一个接口,是一个扩展点。然后函数去实现这个接口,那么就可以按照实现类自己的想法去解析BeanDefinition,spring只是提供这个接口,和扫描这个接口实现类的方法,并不关心你是怎么解析出来的。所以这相当于解耦了。将解析BeanDefinition和Spring主要逻辑进行解耦。
refresh方法几个重要函数
实例化Bean工厂,
对Bean工厂进行一些预处理,
invokeBeanFactoryPostProcessors:
https://www.processon.com/view/link/5f18298a7d9c0835d38a57c0
这个方法还是挺重要的
会解析@Bean、解析@Import注解,将CLass变成Bean定义,放到工厂中,等待最终加工
bean工厂的后置处理器中invokeBeanDefinitionRegistryPostProcessors将真正的将Class变成BeanDefinition(这一步是通过扫描所有的实现了BeanFactoryPostProcessor的类得到的,其中有一个类就是用来BeanDefinition的,从而class变成了BeanDefinition)
注册Bean的后置处理器(留待GetBean的时候用),
初始化国际化资源处理器、事件多播器、注册事件监听器、
finishBeanFactoryInitialization():实例化非抽象、单实例,非懒加载的Bean,其中当前类如果实现了FactoryBean接口那么会用类中重写的getObject方法直接返回私人订制的bean,如果没有实现,那么就getBean()。从而将BeanDefinitionMap里面的所有的BeanDefinition变成真正的bean
容器刷新,启动
生产Bean
这个过程主要做一些,预处理工作,比如先尝试去缓存获取,子向父容器请求bean创建,dependon依赖的bean递归创建。
就是上文提到的getBean(),真实是调用doGetBean方法
处理别名,循环获取到真实的名字
尝试去一级缓存中获取对象(getSingleton)此处有解决循环依赖的逻辑方法。从一级缓存获取,从二级缓存找(为了应付C也循环依赖A的情况),从三级缓存找(应付B循环依赖A的情况,A在实例化的时候就放到了三级缓存。此时可以解决循环依赖,并提前AOP)三级缓存都没拿到返回Null。
从缓存中能获取到对象,直接返回
没有获取到,
父子容器,集成MVC的时候,由于Spring和MVC是父子容器的关系,所以MVC会去父容器中GetBean找到需要的bean。比如我们的Controller中注入Service的时候,发现我们依赖的是一个引用对象,那么他就会调用getBean去把service找出来。
处理dependsOn的依赖(这个不是我们所谓的循环依赖 而是bean创建前后的依赖),调用getBean将当前bean依赖的bean进行加载。其中也会判断循环依赖的问题(通过依赖map和被依赖map解决)
判断是不是单例:
是:getSingleton(),标记成正在创建,开始创建。createBean(),此处第一次调用bean后置处理器。如果这个后置处理器啥也没干,调用doCreateBean真正创建bean
是多例,多例创建。都不是,抛异常
真正生产bean
doCreateBean:
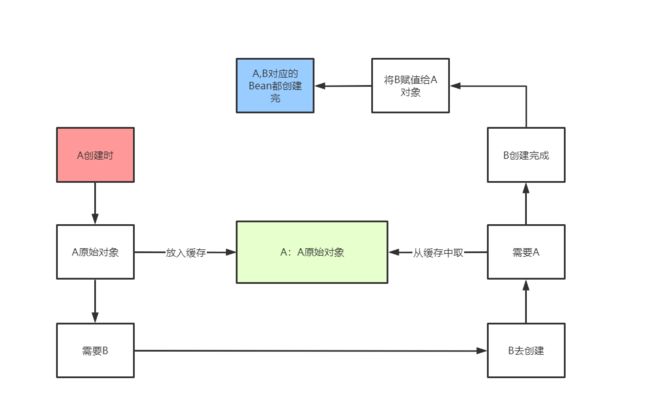
1.实例化。通过(如果配置了工厂,会先通过工厂)反射创建对象(通过有参和无参构造),createBeanInstance()使用合适的实例化策略来创建新的实例:工厂方法、构造函数自动注入、简单初始化 该方法很复杂也很重要。此时对象=null。即原始对象。然后将原材料BeanName,BeanDefinition,原始对象放在第三级缓存。(留待回头AOP用:循环依赖提前AOP或者没有循环依赖的正常AOP)
2.填充属性。 @Autowired、@Value、@Inject。populateBean()。属性填充,依赖注入,整体逻辑是先处理标签再处理注解,填充至 pvs 中,最后通过 apply 方法最后完成属性依赖注入到 BeanWrapper 。此时如果填充的属性B循环依赖了A,那么会在B的填充属性阶段去实例化A,然后又会进入A的doGetBean中的getSingleton,此时从二级缓存中找,没找到就从第三级缓存中根据有没有AOP返回 1.有AOP的对象,即A代理对象),并放入第二级缓存2.没有AOP的元素对象,即A原始对象。这两种对象我们统称为(即暴露的早期对象)赋值给B中的属性A
3.初始化。initializeBean()。使用bean后置处理器,进行AOP。返回AOP后的代理对象bean。(此处的代理对象中,属性值都是空的,不过代理对象中有个被代理对象,这里面就是我们未AOP之前,属性填充满的原始对象。因为对我们AOP之后的代理对象只使用方法,所以不需要属性值)(此处需要判断会不会循环依赖已经提前AOP了)
4.将这个bean放到一级缓存中
refresh()方法源码
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
//1:准备刷新上下文环境
prepareRefresh();
//2:获取告诉子类初始化Bean工厂 不同工厂不同实现
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
//3:对bean工厂进行填充属性
prepareBeanFactory(beanFactory);
try {
// 第四:留个子类去实现该接口
postProcessBeanFactory(beanFactory);
// 调用我们的bean工厂的后置处理器. 1. 会在此将class扫描成beanDefinition 2.bean工厂的后置处理器调用
invokeBeanFactoryPostProcessors(beanFactory);
// 注册我们bean的后置处理器
registerBeanPostProcessors(beanFactory);
// 初始化国际化资源处理器.
initMessageSource();
// 创建事件多播器
initApplicationEventMulticaster();
// 这个方法同样也是留个子类实现的springboot也是从这个方法进行启动tomcat的.
onRefresh();
//把我们的事件监听器注册到多播器上
registerListeners();
// 实例化我们剩余的单实例bean.
finishBeanFactoryInitialization(beanFactory);
// 最后容器刷新 发布刷新事件(Spring cloud也是从这里启动的)
finishRefresh();
}
循环依赖
https://www.yuque.com/renyong-jmovm/ds/dpzl6u
如果不考虑Spring,循环依赖并不是问题,因为对象之间相互依赖是很正常的事情。
因为,在Spring中,一个对象并不是简单new出来了,而是会经过一系列的Bean的生命周期,就是因为Bean的生命周期所以才会出现循环依赖问题。
bean的生命周期
Bean的生命周期指的就是:在Spring中,Bean是如何生成的?
被Spring管理的对象叫做Bean。Bean的生成步骤如下:
1Spring扫描class得到BeanDefinition
2根据得到的BeanDefinition去生成bean
3首先根据class推断构造方法
4根据推断出来的构造方法,反射,得到一个对象(暂时叫做原始对象)
5填充原始对象中的属性(依赖注入)
6如果原始对象中的某个方法被AOP了,那么则需要根据原始对象生成一个代理对象
7把最终生成的代理对象放入单例池(源码中叫做singletonObjects)中,下次getBean时就直接从单例池拿即可
Aservice是一个单例bean是不是表示整个Spring容器中Aservice这个类只有一个实例?单例bean和单例模式相同吗?
其实不是的,因为在Spring容器中,对于Bean的管理是通过一个单例池:ConcurrentHashMap,
这种k-v形式,那么当bean的name不同,那就可以有多个相同类的实例。 所以单例bean和单例模式不同。
那我们说的单例是什么意思?其实是通过ApplicationContext进行getbean的时候,传入同一个名字,获得的对象永远是同一个,说白了是跟名字有关系的。原理就是就是上边的Map,名字不同,key值就不同

循环依赖产生
ABean创建–>依赖了B属性(单例池如果没找到)–>触发BBean创建—>B依赖了A属性—>需要ABean(但ABean还在创建过程中)
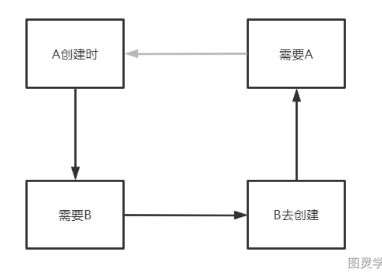
从而导致ABean创建不出来,BBean也创建不出来。
打破循环依赖
那么如何打破这个循环,加个中间人(缓存)
A的Bean在创建过程中,在进行依赖注入之前,先把A的原始Bean放入缓存(提早暴露,只要放到缓存了,其他Bean需要时就可以从缓存中拿了),放入缓存后,再进行依赖注入
从上面这个分析过程中可以得出,只需要一个缓存就能解决循环依赖了,那么为什么Spring中还需要singletonFactories呢?
循环依赖的AOP情况
这是难点,基于上面的场景想一个问题:如果A的原始对象注入给B的属性之后,A的原始对象进行了AOP产生了一个代理对象,此时就会出现,对于A而言,它的Bean对象其实应该是AOP之后的代理对象,而B的a属性对应的并不是AOP之后的代理对象,这就产生了冲突。B想要注入的A,是代理后的A,但是此时A只是原始对象,注入给B对象的A对象和经历过完整生命周期之后的A对象,不是一个对象。所以出现矛盾。
B依赖的A和最终的A不是同一个对象。
那么如何解决这个问题?这个问题可以说没有办法解决。
因为在一个Bean的生命周期最后,Spring提供了BeanPostProcessor可以去对Bean进行加工,这个加工不仅仅只是能修改Bean的属性值,也可以替换掉当前Bean。
所以在这种情况下的循环依赖,Spring是解决不了的,因为在属性注入时,Spring也不知道A对象后续会经过哪些BeanPostProcessor以及会对A对象做什么处理。
提前AOP?
那可不可以对A提前进行AOP呢?可以,应该在A出现了循环依赖的情况下,再提前进行AOP,否则没必要。
那在哪一点进行提前AOP,应该在B注入A的时候,判断A是不是正在创建中(A在创建的时候会放到一个正在创建的set中),如果正在创建中,那么就提前AOP,返回一个A的代理对象。
但是这又会产生问题,就是如果A中不仅仅@Autowired了b,还注入了C。然后C还注入了A,那么在C中,也会对A进行提前AOP,产生一个A的代理对象。那么此时的B中注入的A的代理对象,和C 中注入的A的代理对象不是同一个,这显然是矛盾的。
引出二级缓存
aService Bean的生命周期
0.creat ingSet
1.实例化— AService不完整对象(new AService()
2.填充bService属性 —>从单例池找bService—>找不到–>创建bService
- bService Bean的生命周期
2.1.实例化—BService对象(new BService())
2.2.填充aService属性 -->从单例池找aService—>找不到-- >aService正在创建中–>aService出现了循环—>第二级缓存–>提前AOP—>AService代理对象—>第=级缓存<’ aService’,AService代理对象>
2.3.填充其他属性
2.4.做其他事情
2.5.放入单例池
3.填充cService属性—>从单例池找cService—>找不到–>创建cService
- cService Bean的生 命周期
2.1.实例化—CService对象(new CService())
2.2.填充aService属性— >从单例池找aService— >找不到-- >aService正在创建中— >aService出现了循环—>第二级缓存— >AService代理对象
2.3.填充其他属性
2.4.做其他事情
2.5.放入单例池
4.做其他事情— -AOP— >AService代理对象
4.5从二级缓存取出Aservice代理对象
5.放入单例池
6.creatingSet . remove( ’ aservice’)

引出第三级缓存
再进行提前AOP的时候,对谁进行?从哪里获得被代理对象即原始对象?所以引出三级缓存
1.实例化— AService不完整对象(new AService()原始对象)—>第三级缓存
2.填充bService属性 —>从单例池找bService—>找不到–>创建bService
- bService Bean的生命周期
2.1.实例化—BService对象(new BService())
2.2.填充aService属性 -->从单例池找aService—>找不到-- >aService正在创建中–>aService出现了循环—>第二级缓存–>第三级缓存—>找到并执行lambda(拿到三个属性,执行AOP。如果没有AOP就返回原始对象放到二级缓存中)—>AService代理对象—>第=级缓存<’ aService’,AService代理对象>
2.3.填充其他属性
2.4.做其他事情
2.5.放入单例池

那么在最后A进行AOP的时候,如何判断B已经给A提前进行过了AOP并存在了二级缓存中了呢?
这个功能其实是AOP实现的,AOP这个”插件“会维护一个Map,在提前进行AOP的时候,会把原始bean放进earlyProxyReferences这个map中,代表这个bean已经被提前AOP了。那么在最后A进行AOP的时候,判断这个map中有没有这个bean就可以了。
三级缓存
三级缓存是通用的叫法。
一级缓存为:singletonObjects(ConcurrentHashMap 《beanName,bean对象》)
二级缓存为:earlySingletonObjects(HashMap 《beanName,bean对象》)
三级缓存为:singletonFactories(HashMap 《beanName,ObjectFactory(函数式接口)即一个lambda表达式》)
先稍微解释一下这三个缓存的作用,后面详细分析:
●singletonObjects中缓存的是已经经历了完整生命周期的bean对象。
●earlySingletonObjects比singletonObjects多了一个early,表示缓存的是早期的bean对象。早期是什么意思?表示Bean的生命周期还没走完就把这个Bean放入了earlySingletonObjects。即缓存提前通过原始对象进行了AOP之后得到的代理对象,原始对象还没有进行属性注入和后续的BeanPostProcessor等生命周期
●singletonFactories中缓存的是ObjectFactory(一个函数式接口),表示对象工厂,用来创建某个对象的。注意:只是存到这里,并不会执行这个lambda表达式。缓存的是一个ObjectFactory,也就是一个Lambda表达式。在创建一个Bean时,在每个Bean的生成过程中,都会提前暴露一个Lambda表达式,并保存到三级缓存中,这个Lambda表达式可能用到,也可能用不到,如果没有出现循环依赖依赖本bean,那么这个Lambda表达式无用,本bean按照自己的生命周期执行,执行完后直接把本bean放入singletonObjects中即可,如果出现了循环依赖依赖了本bean,则从三级缓存中获取Lambda表达式,并执行Lambda表达式得到一个AOP之后的代理对象(如果有AOP的话,如果无需AOP,则直接得到一个原始对象),并把得到的对象放入二级缓存
●其实还要一个缓存,就是earlyProxyReferences(HashMap),它用来记录某个原始对象是否进行过AOP了。里面存的是原始对象,循环依赖进行提前AOP的时候,会把原始对象放到这个map中。如果最后初始化后期进行AOP的时候,会判断这个map中有没有这个bean原始对象,有的话说明提前创建过,就返回提前创建的AOP代理对象
什么是单例池?什么是一级缓存?
通过map的key是唯一的,来解决单例的问题,保存的是bean的完整对象
什么是二级缓存,它的作用是什么?
二级缓存是用来解决,多个属性同时循环依赖从而导致创建了多个不同的AOP代理对象。将第一个循环依赖创建的AOP代理对象放到这个二级缓存的map中,第二、三、、等等的注入的循环依赖的属性就可以直接获取创建好的AOP代理对象了。
解决AOP代理对象的单例的问题。一个bean名字只会对应一个不完整的bean对象
什么是三级缓存,它的作用是什么?
因为刚开始实例化原始对象的时候,根本不知道会不会循环依赖,会不会AOP,但是先通过三级缓存将原材料beanName,BeanDefinition,原始对象缓存起来,如果出现了循环依赖,那第三级缓存就排上用场了。
A(存入三级缓存)–B(存入三级缓存)–A(此时A执行getSingleton,先从一级缓存找,没有,二级缓存找,没有,三级缓存找,肯定有,如果AOP了,那就执行lambda返回AOP的后的代理对象,如果没有AOP,那就返回原始对象)
就是为了提供原始对象的。
为什么第二级、第三级缓存用的是HashMap而不是ConcurrentHashMap?难道他俩不需要保证多线程并发正确性吗?
这是因为第二级和第三级缓存是一起用的,那么此时直接在这个方法上加上synchronized(this.singletonObjects(即第一级缓存对象)),那么此时2/3级缓存的dd和remove一定就是原子性的了。所以他俩用HashMap就行了,而且效率比ConcurrentHashMap更高。
3.add(beanName)/2.remove(beanName),
3.remove(beanName)/2.add(beanName),
有哪些情况下的循环依赖是Spring解决不了的
构造器注入。由于只有有参构造函数,构造器注入的时候,就没有办法像上边那样找到一个A的原始对象了。所以就无法解决循环依赖。要想解决,得在构造方法上边加上@Lazy注解,Spring直接注入BService代理对象。注入完成后,将AService搞定后。Bservice再开始实例化。相当于先给你一个代理对象,你这个bean先搞定。等用到B的时候,在去搞B这个bean
class AService{
private BService bService;
@Lazy //解决循环依赖
public AService(BService bService){
this.bService=bService;
}
}
class BService{
private AService aService;
public BService(AService aService){
this.aService=aService;
}
}
为什么@Lazy注解可以用来解决循环依赖
AOP
三要素
目标对象
代理逻辑
代理对象
重要概念
Advice:通知。建议。即利用advice,添加代理的逻辑。其实就是下面四个方法,方法里进行代理逻辑的书写。
在Spring中,Advice分为:
- 前置Advice:MethodBeforeAdvice
- 后置Advice:AfterReturningAdvice
- 环绕Advice:MethodInterceptor
- 异常Advice:ThrowsAdvice
(1)前置通知(Before advice):在某连接点(join point)之前执行的通知,但这个通知不能阻止连接点前的执行(除非它抛出一个异常)。
(2)返回后通知(After returning advice):在某连接点(join point)正常完成后执行的通知:例如,一个方法没有抛出任何异常,正常返回。
(3)抛出异常后通知(After throwing advice):在方法抛出异常退出时执行的通知。
(4)后通知(After (finally) advice):当某连接点退出的时候执行的通知(不论是正常返回还是异常退出)。
(5)环绕通知(Around Advice):包围一个连接点(join point)的通知,如方法调用。这是最强大的一种通知类型。 环绕通知可以在方法调用前后完成自定义的行为。它也会选择是否继续执行连接点或直接返回它们自己的返回值或抛出异常来结束执行。 环绕通知是最常用的一种通知类型。
PointCut:切点。表示我想让哪些地方加上我的代理逻辑。比如某个方法,比如某些方法,比如某些方法名前缀为“find” 的方法,比如某个类下的所有方法,等等。
Advisor:Advice+PointCut。如下图,每个框就代表一个Advisor
切点表达式:execution**: 用于匹配方法执行连接点。 这是使用Spring AOP时使用的主要切点标识符。 可以匹配到方法级别 ,细粒度

实际编码使用
比如实现日志的功能。
1.添加依赖。在ioc的基础上添加pom依赖
<dependency>
<groupId>org.aspectjgroupId>
<artifactId>aspectjweaverartifactId>
<version>1.9.5version>
dependency>
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring‐aspectsartifactId>
<version>5.2.3.RELEASEversion>
dependency>
2.xml中开启
<context:component-scan base‐package="cn.tulingxueyuan">
context:component-scan>
<aop:aspectj-autoproxy>aop:aspectj-autoproxy>beans>
3.设置切面类.
声明为切面: 在LogUtil.java中添加@Aspect注解
将切面交给spring去管:给LogUtil添加@Component注解

4.设置目标类
给MyCalculator添加@Service注解
5.测试
体会
此处直接跳跃到AOP中的实现。通过自定义new ProxyFactory();,来感知AOP是如何实现的,此处不去关系是如何进入方法的。只关心ProxyFactory是什么意思,有什么API,和属性都是什么。
Bean生命周期:实例化Bean原始对象,属性填充,初始化前,初始化,初始化后(进行AOP,在postProcessAfterInitialization()方法中)
AOP的时候就进行下面的步骤(为了清楚写的比较细,其实AOP真正的源代码,会考虑很多特殊情况,进行判断,不过**主体流程,就是new-->设置属性-->getProxy()**),先new一个ProxyFactory(),然后将原始对象setTarget(),然后addInterface(bean所实现的接口类)
ProxyFactory有一个成员变量是targetsource。等到后来invoke的时候获得target(即原始对象,目标对象)的,调用target方法

//必须设置target,因为spring是管理的bean,然后才AOP,如果都没有target这个bean,那么AOP的时候是空对象,报错。
ProxyFactory factory = new ProxyFactory();
factory.setTarget(new UserService()); //target:不为空 targetClass 不为空 即 UserService。class
//factory.setTargetClass(UserServiceInterface.class);//target 为空 targetClass不为空 即 UserServiceInterface.class
factory.addAdvisor(new MyAdvisor());
UserService userService = (UserService) factory.getProxy();userService.test();
AOP的入口
这三种方法其实都是实现了bean的后置处理器,然后通过实现类做了前期的find advisor的工作,最后还是会进入postProcessAfterInitialization这个方法
1.使用自动代理BeanNameAutoProxyCreator
"自动代理"表示,只需要在Spring中添加某个Bean,这个Bean是一个BeanPostProcessor,那么Spring在每创建一个Bean时,都会经过这个BeanPostProcessor的判断,去判断当前正在创建的这个Bean是不是需要进行AOP。
我们可以在项目中定义很多个Advisor,定义方式有两种:
- 通过实现PointcutAdvisor接口
- 通过@Aspect、@Pointcut、@Before等注解
在创建某个Bean时,会根据当前这个Bean的信息,比如对应的类,以及当前Bean中的方法信息,去和定义的所有Advisor进行匹配,如果匹配到了其中某些Advisor,那么就会把这些Advisor给找出来,并且添加到ProxyFactory中去,在利用ProxyFactory去生成代理对象
BeanNameAutoProxyCreator
@Beanpublic BeanNameAutoProxyCreator creator(){
BeanNameAutoProxyCreator beanNameAutoProxyCreator = new BeanNameAutoProxyCreator();
beanNameAutoProxyCreator.setBeanNames("userService");
beanNameAutoProxyCreator.setInterceptorNames("myAdvisor");
return beanNameAutoProxyCreator;}
定义的这个bean,相当于一个“自动代理”器,有了这个Bean之后,可以自动的对setBeanNames中所对应的bean进行代理,代理逻辑为所设置的interceptorNames
BeanNameAutoProxyCreator–》extends AbstractAutoProxyCreator -->implements SmartInstantiationAwareBeanPostProcessor其实是一个后置处理器,调用方法postProcessAfterInitialization
后继流程看下文流程postProcessAfterInitialization
但是这个入口还得自己写beanName,InterceptorNames。那能不能全自动切入呢?于是引出下面这个
2.使用DefaultAdvisorAutoProxyCreator

DefaultAdvisorAutoProxyCreator这个更加强大,只要添加了这个Bean,它就会自动识别所有的Advisor中的PointCut进行代理。就是如果我的自定义advisor切了test方法,只要你这个bean中有test方法,那么都会被我切到,就不需要你自己指定了具体的bean和advisor了,不管是bean还是advisor我都能自己找到。
具体源代码是还是后置处理器实现类里面的postProcessAfterInitialization方法中
不同点就是在wrapIfNecessary方法里面找specificInterceptors即当前bean的advisor。那我没有指定advisor,他是怎么找到的呢?在wrapIfNecessary方法中有个函数找到所有的Advisor,遍历每一个advisor。对于每一个advisor,然后遍历当前targetClass和父类和接口的所有方法,如果存在advisor里面要求的方法,那就说明找到了对应的advisor,然后返回这 个advisor,说明这个advisor符合要求,那么我就筛选了出来。
这个是可以自动切入,但是这个是针对全局,所有都切入,那我想要更细粒度切入具体哪个方法或者哪个类,而且我还不想写@bean的代码,那怎么做?就可以使用下面的这个注解。
3.使用注解@EnableAspectJAutoProxy
这个注解主要是添加了一个AnnotationAwareAspectJAutoProxyCreator类型的BeanDefinition。然后在IOC的过程中,就会通过图纸BeanDefinition注册这个bean。由于这个类其实最终继承了AbstractAutoProxyCreator,那么最终还是会走入postProcessAfterInitialization()方法。
他不仅会扫描所有的通过实现接口的Advisor还会扫描通过实现了@aspect注解的advisor(解析@before ,@after这些注解)
注解和源码对应关系
主要是proceed方法,他代表这会去执行下一个拦截器
-
@Before对应的是AspectJMethodBeforeAdvice,直接实现MethodBeforeAdvice,在进行动态代理时会把AspectJMethodBeforeAdvice转成MethodBeforeAdviceInterceptor,也就转变成了MethodBeforeAdviceInterceptor- 先执行advice对应的方法
- 再执行MethodInvocation的proceed(),会执行下一个Interceptor,如果没有下一个Interceptor了,会执行target对应的方法
-
@After对应的是AspectJAfterAdvice,直接实现了MethodInterceptor- 先执行MethodInvocation的proceed(),会执行下一个Interceptor,如果没有下一个Interceptor了,会执行target对应的方法
- 再执行advice对应的方法
-
@Around对应的是AspectJAroundAdvice,直接实现了MethodInterceptor。around里面需要自己写执行前,proceed,和执行后,所以源码里面直接执行这个around的advisor- 直接执行advice对应的方法
-
@AfterThrowing对应的是AspectJAfterThrowingAdvice,直接实现了MethodInterceptor
1.先执行MethodInvocation的proceed(),会执行下一个Interceptor,如果没有下一个Interceptor了,会执行target对应的方法
2. 如果上面抛了Throwable,那么则会执行advice对应的方法 -
@AfterReturning对应的是AspectJAfterReturningAdvice,实现了AfterReturningAdvice,在进行动态代理时会把AspectJAfterReturningAdvice转成AfterReturningAdviceInterceptor,也就转变成了MethodInterceptor
1. 先执行MethodInvocation的proceed(),会执行下一个Interceptor,如果没有下一个Interceptor了,会执行target对应的方法
2. 执行上面的方法后得到最终的方法的返回值
3. 再执行Advice对应的方法
流程postProcessAfterInitialization
其实AOP就是通过两个后置处理器,一个是用来解决循环依赖时候的提前AOP,一个是正常的初始化后的AOP。
通过上文我们知道了bean的后置处理器有多种接口,那么对于我们的初始化后的AOP来说,主要是用到的implements SmartInstantiationAwareBeanPostProcessor的AbstractAutoProxyCreator中的postProcessAfterInitialization()方法,也就是在初始化后,Spring自动调用后置处理器Smartxxx,于是找到了实现类的这个post方法,在里面进行AOP
1.postProcessAfterInitialization()
/**
* 生成aop代理
* 在该后置方法中 我们的事务和aop的代理对象都是在这生成的
* @param bean bean实例
* @param beanName bean的名称
* @return
* @throws BeansException
*/
@Override
public Object postProcessAfterInitialization(@Nullable Object bean, String beanName) throws BeansException {
if (bean != null) {
//获取缓存key
Object cacheKey = getCacheKey(bean.getClass(), beanName);
// 之前循环依赖创建的动态代理 如果是现在的bean 就不再创建,,并且移除
// earlyProxyReferences中存的是哪些提前进行了AOP的bean, beanName :A0P之前的对象
//注意earlyProxyReferences中并没有存AOP之后的代理对象 BeanPostProcessor
if (this.earlyProxyReferences.remove(cacheKey) != bean) {
// 没有提前进行AOP,则进行AOP,该方法将会返回动态代理实例
return wrapIfNecessary(bean, beanName, cacheKey);
}
}
//为什么不返回代理对象呢?
return bean;
}
2.wrapIfNecessary() :判断这个bean需不需要代理(对应一些特殊情况)。根据当前bean找到独有的Advisor:specificInterceptors(就是我们直接切到具体类的具体方法的那些Advice),标记当前bean已经处理了,然后基于bean的原始对象和所匹配的Advice和Advisor创建代理对象createProxy()
3.createProxy():创建代理对象,先new一个ProxyFactory(),将所有的ProxyFactory有的属性设置好,(就是下文提到的那些参数,以及是否指定了JDK还是cglib代理的属性)。将commonInterceptors(就是那种只要bean里面包含xx方法,都能切到,不是针对于某个类的某个方法)与specificInterceptors两个Advisor通知整合,加到工厂中。最后proxyFactory.getProxy()真正的创建代理对象
4.getProxy():
factory.getProxy();这个方法会进入createAopProxy().getProxy()
public Object getProxy(@Nullable ClassLoader classLoader) {
//createAopProxy() 用来获取我们的代理工厂
return createAopProxy().getProxy(classLoader);
}
其中createAopProxy()选择是用哪个动态代理,返回AopProxy接口类型的一个对象,只有三个实现类

5.调用不同动态代理的getProxy()方法。最后通过反射生成一个代理对象,当我们执行代理对象的方法的时候,就会在JDK动态代理这个类里面找到invoke方法,执行。
这是JDK动态代理的getProxy()方法。最后newProxyInstance里面的this,代表的是当前类,当前类实现了invokeHandler方法。这就和我们之前自己使用反射的时候,参数里面有个InvokeHandler一样
自己使用反射的时候
UserService userServiceProxy = (UserService) Proxy.newProxyInstance(contextClassLoader, classes, new InvocationHandler() { public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { return null; } });

6.代理对象执行的时候,会调用动态代理类里面的invoke方法,这里面做了一些事情
如果通过ProxyFactory.setExposeProxy()把exposeProxy设置为了true,那么则把代理对象设置到一个ThreadLocal(currentProxy)中去。这个配置很重要很实用【暴露我们的代理对象到线程变量中,解释如下:】需要搭配@EnableAspectJAutoProxy(exposeProxy = true)一起使用。
比如我们的aop中 add和 mod方法都是被切入的方法,
但是在切入的方法中通过this来调用另外一个方法的时候,那么该方法就不会被代理执行,而是通过方法内部执行,所以需要用exposeProxy暴露出来,这样调用另一个方法的时候就能得到暴露出来的经过AOP代理后的代理方法了。
其实是因为使用的this的原因,用了this,代理就不生效了,因为this指的是原始对象,用原始对象调用add方法,那么就不会走代理逻辑了。
public int mod(int numA,int numB){ System.out.println("执行目标方法:mod"); //如果直接这样this.add那么就直接调用了add方法,就不会执行add方法的AOP代理 //int retVal = this.add(numA,numB); //这样写,使用的就是AOP代理后的add方法。 int retVal = ((Calculate) AopContext.currentProxy()).add(numA,numB); return retVal%numA; }这个尤其用在,事务方法调用事务方法的时候 。比如mod是一个事务方法,加了@Transactional。然后add也是一个事务方法,加了@Transactional。如果在mod中直接通过this.add调用,那么add就不会经过Transactional的AOP代理,那么就相当于add逃出了事务。所以此时应该通过AopContext.currentProxy()获得经过Transactional的AOP代理的add方法,再去执行。这样mod也用了事务,add也用了事务,没有逃出。
或者直接注入本类的对象,然后用这个对象去调用这两个方法。由于spring能够解决循环依赖的问题,所以这么做没啥问题
@Transactional public void mod(){ this.add();//这种情况下,add是不经过Transactional的 } @Transactional public void add(){ }
获取ProxyFactory的targetsource,从而获取到原始对象target。根据当前所调用的方法对象寻找ProxyFactory中所添加的并匹配的Advisor,并且把Advisor封装为MethodInterceptor返回,得到MethodInterceptor链叫做chain
比如@After、@Before这种AOP常规的Advisor会封装成拦截器,那么对于事务@Transactionnal,也有拦截器,那么这个chain会把所有的拦截器都涵盖了。然后执行完chain后,生成一个被所有拦截器改造过的代理对象。
-
如果chain为空,则直接执行target对应的当前方法,如果target为null会报错
-
如果chain不为空,则会依次执行chain中的MethodInterceptor
2.1如果当前MethodInterceptor是MethodBeforeAdviceInterceptor,那么则先执行Advisor中所advice的before()方法,然后执行下一个MethodInterceptor
2.2如果当前MethodInterceptor是AfterReturningAdviceInterceptor,那么则先执行下一个MethodInterceptor,拿到返回值之后,再执行Advisor中所advice的afterReturning()方法
此处与上文注解和源码对应关系结合着看
cglib创建代理对象并执行的流程,其实和上边使用JDK创建和执行的流程差不多:

JDK与Cglib动态代理
JDK动态代理:接口。
cglib动态代理:父子类。必须要有类
Spring何时使用cglib,何时使用JDK动态代理?
根据现象分析:
如果一个类没有实现接口,或者@EnableAspectJAutoProxy(proxyTargetClass = true,那么一定就是cglib动态代理
类实现了接口,并且没有@EnableAspectJAutoProxy(proxyTargetClass = true,那么就会JDK动态代理
根据源码分析:
config就是new 的ProxyFactory对象,
1.使用cglib的情况
生成的代理类其实是目标类的子类。(这是原理,实际使用的时候我们通过设置@EnableAspectJAutoProxy(proxyTargetClass = true)就可以了
//根据两个属性的设置,就会进入if里面。然后大概率会cglib动态代理 factory.setOptimize(true);//会使用cglib factory.setProxyTargetClass(true);//使用cglib2.使用JDK的情况。
2.使用JDK的情况。
//不需要类,只设置接口:但是target为空,调用不了方法,spring报错。因为
2.1生成的代理类是实现了接口的一个类,用到了目标类的方法。所以和目标类其实是兄弟的关系。(这个情况其实是AOP自动判断bean有没有实现接口,有接口的时候,会自动addInterface)我们现在是相当于自己写一写AOP,体会一下原理
//这个可以设置多个,那么最后生成的代理对象就是一个实现了多接口的代理对象 factory.addInterfaces(UserServiceInterface.class);//设置接口,会使用JDK //并且最后因为是JDK动态代理,所以需要使用接口去接收 UserServiceInterface userServiceInterface = (UserServiceInterface) factory.getProxy();这个情况使得if中三个判断都是false,那么就会走else,JDK动态代理
2.2 由于hasNoUserSuppliedProxyInterfaces返回true,所以会进入if,但是由于设置了targetClass,所以还是会用JDK动态代理。这就是为什么1里面说,大概率cglib,而不是肯定cglib
factory.setTargetClass(UserServiceInterface.class);

Spring AOP使用的动态代理,所谓的动态代理就是说AOP框架不会去修改字节码,而是在内存中临时为方法生成一个AOP对象,这个AOP对象包含了目标对象的全部方法,并且在特定的切点做了增强处理,并回调原对象的方法。
Spring AOP中的动态代理主要有两种方式,JDK动态代理和CGLIB动态代理。JDK动态代理通过反射来接收被代理的类,并且要求被代理的类必须实现一个接口。JDK动态代理的核心是InvocationHandler接口和Proxy类。
如果目标类没有实现接口,那么Spring AOP会选择使用CGLIB来动态代理目标类。CGLIB(Code Generation Library),是一个代码生成的类库,可以在运行时动态的生成某个类的子类,注意,CGLIB是通过继承的方式做的动态代理,因此如果某个类被标记为final,那么它是无法使用CGLIB做动态代理的。
事务
数据库交互
DateSource---->建立数据库连接Connection autocomit=true;
执行SQL

分类:
都需要提前xml中,先配置好DataSource
**编程式事务:**在代码中直接加入处理事务的逻辑,new DataSourceTransactionManager()。可能需要在代码中显式调用beginTransaction()、commit()、rollback()等事务管理相关的方法
声明式事务:
**1.最原始xml:**配置DataSourceTransactionManager这个bean,配置transaction-manager这个tx:advice,配置AOP。这样对应的方法上就会被AOP加上事务了。
**2.注解@Transactional+xml:**在使用配置文件的方式中,通常会在Spring的配置文件中配置事务管理器,并注入数据源:接下来可以直接在业务层Service的方法上或者类上添加 @Transactional。
<bean id="dataSource" class="..."> <property name="" value=""/> bean> <bean id="txManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"> <property name="dataSource" ref="dataSource" /> bean> <tx:annotation-driven transaction-manager="txManager" />
**3.注解@Transactional+配置类:**搞一个配置类,里面@bean配置数据源和@bean 配置platformTransactionManager,最重要的是要加上@EnableTransactionManagement表示开启注解驱动,等同 XML 格式中的注解驱动。这样接下来可以直接在业务层Service的方法上或者类上添加 @Transactional
**
@EnableTransactionManagement//重要 @Configuration public class TxConfig { @Bean public DataSource dataSource() { ComboPooledDataSource dataSource = new ComboPooledDataSource(); dataSource.setUser("..."); dataSource.setPassword("..."); dataSource.setDriverClass("..."); dataSource.setJdbcUrl("..."); return dataSource; } //重要 @Bean public PlatformTransactionManager platformTransactionManager() { return new DataSourceTransactionManager(dataSource());//放入数据源 } }
**Springboot配置事务:**在大多数SpringBoot项目中,简单地只要在配置类或者主类上添加 @EnableTransactionManagement,并在业务层Service上添加 @Transactional即可实现事务的提交和回滚。
为什么Springboot不用配置这些东西呢?因为Springboot在在依赖jdbc或者jpa之后,会自动配置TransactionManager。
spring.factories文件,如下:
TransactionAutoConfiguration类就是事务的自动装配了,在Spring容器启动时会自动进行装载。
跟进TransactionAutoConfiguration类,就会发现@EnableTransactionManagement注解了,如下:


伪代码
把事务理解成连接,一个新的事务对应一个新的连接
情况1
@Component
public class UserService {
@Autowired
private UserService userService;
@Transactional
public void test() {
// test方法中的sql
userService.a();
}
@Transactional
public void a() {
// a方法中的sql
}
}
默认情况下传播机制为REQUIRED
所以上面这种情况的执行流程如下:
新建一个数据库连接conn
设置conn的autocommit为false
执行test方法中的sql
执行a方法中的sql
执行conn的commit()方法进行提交
情况2
假如是这种情况
@Component
public class UserService {
@Autowired
private UserService userService;
@Transactional
public void test() {
// test方法中的sql
userService.a();
int result = 100/0;
}
@Transactional
public void a() {
// a方法中的sql
}
}
所以上面这种情况的执行流程如下:
新建一个数据库连接conn
设置conn的autocommit为false
执行test方法中的sql
执行a方法中的sql
抛出异常
执行conn的rollback()方法进行回滚
情况3
假如是这种情况:
@Component
public class UserService {
@Autowired
private UserService userService;
@Transactional
public void test() {
// test方法中的sql
userService.a();
}
@Transactional
public void a() {
// a方法中的sql
int result = 100/0;
}
}
所以上面这种情况的执行流程如下:
新建一个数据库连接conn
设置conn的autocommit为false
执行test方法中的sql
执行a方法中的sql
抛出异常
执行conn的rollback()方法进行回滚
情况4
如果是这种情况:
@Component
public class UserService {
@Autowired
private UserService userService;
@Transactional
public void test() {
// test方法中的sql
userService.a();
}
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void a() {
// a方法中的sql
int result = 100/0;
}
}
所以上面这种情况的执行流程如下:
新建一个数据库连接conn
设置conn的autocommit为false
执行test方法中的sql
又新建一个数据库连接conn2
执行a方法中的sql
抛出异常
执行conn2的rollback()方法进行回滚
继续抛异常
执行conn的rollback()方法进行回滚
流程
事务的底层原理就是通过 AOP 动态织入,进行事务开启和提交。对需要增强的方法进行一个拦截包装。
简化流程
@EnableTransactionManagement注解注入了两个bean:
- AutoProxyRegistrar
- ProxyTransactionManagementConfiguration
流程1,对于1,就是开启AOP
流程2,对于2,注册事务注解解析器,找到所有的@transactionnal注解,解析事务注解的相关信息(如隔离级别,传播属性)。就是注册事务增强器,用到解析器解析出来的原材料构造出advisor,留着AOP的时候用。注册拦截器(实现了AOP拦截器),从而使得AOP的时候能够找到这个拦截器,返回一个经过了事务AOP的代理对象。
执行事务的时候,就是调用拦截器的invoke方法,这个方法中通过 PlatformTransactionManager 控制着事务的提交和回滚,有开启事务,关闭事务,事务回滚,根据事务的传播机制(suspend,)等逻辑。

详细流程
在config中打开注解@EnableTransactionManagement,这个注解通过spring添加了两个bean
AutoProxyRegistrar:给容器中注册 InfrastructureAdvisorAutoProxyCreator,该类实现了 InstantiationAwareBeanPostProcessor 接口,可以拦截 Spring 的 bean 初始化和实例化前后。利用后置处理器机制拦截 bean 以后包装该 bean 并返回一个代理对象,代理对象中保存所有的拦截器,代理对象执行目标方法,利用拦截器的链式机制依次进入每一个拦截器中进行执行(AOP 原理)。就是和上文@EnableAspectJAutoProxy开启AOP一样,这里其实就是相当于开启了AOP
ProxyTransactionManagementConfiguration:是一个 Spring 的配置类,注册 BeanFactoryTransactionAttributeSourceAdvisor 事务增强器,利用注解 @Bean 把该类注入到容器中,该增强器有两个字段:
-
TransactionAttributeSource:用于解析事务注解的相关信息(如隔离级别,传播属性),比如 @Transactional 注解,该类的真实类型是 AnnotationTransactionAttributeSource,初始化方法中注册了三个注解解析器,解析三种类型的事务注解 Spring、JTA、Ejb3
-
TransactionInterceptor:事务拦截器,实现了MethodInterceptor,就是AOP里面的那个拦截器。那么在进行AOP拦截的时候,也会进入这个拦截器,从而执行这个拦截器的功能。就跟@after@before一样,执行自己的解析和执行。代理对象执行拦截器方法时,会调用 TransactionInterceptor 的 invoke 方法,底层调用TransactionAspectSupport.invokeWithinTransaction(),通过 PlatformTransactionManager 控制着事务的提交和回滚,所以事务的底层原理就是通过 AOP 动态织入,进行事务开启和提交
//invokeWithinTransaction()方法主要源码: // 创建平台事务管理器对象 final PlatformTransactionManager tm = determineTransactionManager(txAttr); // 开启事务 TransactionInfo txInfo = createTransactionIfNecessary(tm, txAttr, joinpointIdentification); // 执行目标方法 retVal = invocation.proceedWithInvocation(); // 调用 java.sql.Connection 提交或者回滚事务 commitTransactionAfterReturning(txInfo);createTransactionIfNecessary(tm, txAttr, joinpointIdentification):-
status = tm.getTransaction(txAttr):获取事务状态,方法内通过 doBegin 调用 Connection 的 setAutoCommit 开启事务,就是 JDBC 原生的方式。这是真正的创建了一个事务 -
prepareTransactionInfo(tm, txAttr, joinpointIdentification, status):方法内调用 bindToThread() 方法,利用 ThreadLocal 把当前事务绑定到当前线程补充策略模式(Strategy Pattern):使用不同策略的对象实现不同的行为方式,策略对象的变化导致行为的变化,事务也是这种模式,每个事务对应一个新的 connection 对象
-
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RWqDDhuZ-1629644773615)(https://gitee.com/zooozz/mark-down_images/raw/master/images_repo1/1605079039527-d90d7d18-bbdf-4b0d-a23f-b5d8c1432128.png)]
本地事务失效
本地事务失效问题
同一个对象内事务方法互调默认失效,原因绕过了代理对象,事务使用代理对象来控制的
解决:使用代理对象来调用事务方法
1)、引入aop-starter; spring-boot-starter-aop;引入了aspectj(这个比原始AOP更强大,因为原始AOP只能JDK代理)
2)、@EnableAspectJAutoProxy(exposeProxy = true); 开启aspectj动态代理功能。以后所有的动态代理都是aspect创建的(即使没有接口也能创建)
exposeProxy = true 对外暴露代理对象。这样就可以使用AopContext. currentProxy()得到我们的代理对象
3)、本类互调用调用对象
OrderServiceImpl orderService = (OrderServiceImpl) AopContext. currentProxy();
orderService.b();
prderService.c();