练习总结sql面试50题(2021-12-27完结)
参考
【数据分析】- SQL面试50题 - 跟我一起打怪升级 一起成为数据科学家_哔哩哔哩_bilibili
图解SQL面试题:经典50题 - 知乎
sql面试题:topN问题
sql 分组查询 分组查询查询每组的前几条数据_qq87802343的博客-CSDN博客_sql每组前几条记录
sql面试题:行列如何互换?
免费教程《图解SQL面试题》 - 知乎
SQL面试必会50题(含答案和学习链接)_欢迎来到小丁的技术空间-CSDN博客_sql面试50题
前言
猴子老师的“sql面试50题”几年前就已经收藏吃灰了,最近是看到陆老师的视频才开始着手写文练习和记录的。流程是先看了陆老师视频第1,2题了解上下文,然后就去看猴子老师的知乎了,最后快刷陆老师视频查缺补漏,学习其他解法。
因为自己是有sql基础的,陆老师讲的很细很到位所以就慢一些,而猴子老师的有些答案具有局限性,所以再看陆老师如何解决。自己对新知识一般是视频入门,文章系统学习,视频查缺补漏,文章复习的学习策略。
学习还得是靠笔记,一是自己整理的材料即使若干年后再看也会很快回忆起来,毕竟是自己整理的;二是学完知识就可以清空大脑,不必背负记忆的包袱。
注意
# 本文只选取了“sql面试50题”中本人思维盲区、值得练习和记录的部分题目。
# "sql面试50题"只实现查询,不考虑查询性能
# 数据对部分题目来说缺少多样性和丰富度,所以仅作为数据导入模板使用。如 score表中没有不及格的成绩。
# 部分sql语句存在特殊空格或字符,导致复制粘贴无法直接执行,所以需要照抄后再尝试执行。
知识点
条件,分组,分组条件,排序,统计函数,子查询,窗口函数(分组排名,topN问题,组内比较),case when,注意left join和inner join区别
陆老师视频点赞亮点
# 带领小白熟悉sql编写的思考历程
# 第一题关联表获取更多详细字段的过程
# 第二题不建议select包含gourp by中不包含的字段
# 第三题说明了left join和inner join的区别,使用case when处理null值
# 第五题提供了两种解法思路
# 第七题拓展了select LENGTH(NULL)的结果仍然是NULL值
# 第十二题翻车视频,主要是自己也无脑被带沟里去了。但陆老师及时枚举翻车原因,顺利上岸。翻车及上岸历程真实深刻,推荐体验
# 第十九题拓展了窗口函数(row_number(),rank(),dense_rank())
row_number不重复排序,dense_rank连续排序,rank跳跃排序

# 第二十三题使用count()和sum()两种写法
# 第四十题拓展了limit m,n的用法
# 第四十六题拓展了round(x,d)四舍五入并保留d位小数位,ceiling(x)向上取整,floor(x)向下取整
# 第五十题where语句中的case when

创建数据库sql_test
字符集utf8--UTF-8 Unicode
排序规则utf8_unicode_ci
创建表、导入数据
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for course
-- ----------------------------
DROP TABLE IF EXISTS `course`;
CREATE TABLE `course` (
`课程号` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`课程名称` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`教师号` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
PRIMARY KEY (`课程号`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = DYNAMIC;
-- ----------------------------
-- Records of course
-- ----------------------------
INSERT INTO `course` VALUES ('0001', '语文', '0002');
INSERT INTO `course` VALUES ('0002', '数学', '0001');
INSERT INTO `course` VALUES ('0003', '英语', '0003');
INSERT INTO `course` VALUES ('0004', '计算机', '0001');
-- ----------------------------
-- Table structure for score
-- ----------------------------
DROP TABLE IF EXISTS `score`;
CREATE TABLE `score` (
`学号` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`课程号` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`成绩` float NOT NULL,
PRIMARY KEY (`学号`, `课程号`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = DYNAMIC;
-- ----------------------------
-- Records of score
-- ----------------------------
INSERT INTO `score` VALUES ('0001', '0001', 80);
INSERT INTO `score` VALUES ('0001', '0002', 90);
INSERT INTO `score` VALUES ('0001', '0003', 99);
INSERT INTO `score` VALUES ('0002', '0002', 60);
INSERT INTO `score` VALUES ('0002', '0003', 80);
INSERT INTO `score` VALUES ('0003', '0001', 80);
INSERT INTO `score` VALUES ('0003', '0002', 60);
INSERT INTO `score` VALUES ('0003', '0003', 60);
INSERT INTO `score` VALUES ('0003', '0004', 70);
-- ----------------------------
-- Table structure for student
-- ----------------------------
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student` (
`学号` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`姓名` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`出生日期` date NOT NULL,
`性别` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
PRIMARY KEY (`学号`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = DYNAMIC;
-- ----------------------------
-- Records of student
-- ----------------------------
INSERT INTO `student` VALUES ('0001', '猴子', '1989-01-01', '男');
INSERT INTO `student` VALUES ('0002', '猴子', '1990-12-21', '女');
INSERT INTO `student` VALUES ('0003', '马云', '1991-12-21', '男');
INSERT INTO `student` VALUES ('0004', '王思聪', '1990-05-20', '男');
-- ----------------------------
-- Table structure for teacher
-- ----------------------------
DROP TABLE IF EXISTS `teacher`;
CREATE TABLE `teacher` (
`教师号` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`教师姓名` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
PRIMARY KEY (`教师号`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = DYNAMIC;
-- ----------------------------
-- Records of teacher
-- ----------------------------
INSERT INTO `teacher` VALUES ('0001', '孟扎扎');
INSERT INTO `teacher` VALUES ('0002', '马化腾');
INSERT INTO `teacher` VALUES ('0003', NULL);
INSERT INTO `teacher` VALUES ('0004', '');
SET FOREIGN_KEY_CHECKS = 1;
sql语法
select 查询结果字段
from 从哪张表中查找数据
where 查询条件
group by 分组
having 对分组结果指定条件
order by 对查询结果排序;查询选了课程的学生人数(逻辑思维漏洞,知识盲区:count(distinct 字段)的用法)
select count(distinct 学号) as 学生人数
from score;【分组查询】
查询各科成绩最高和最低的分, 以如下的形式显示:课程号,最高分,最低分
select 课程号,max(成绩) as 最高分,min(成绩) as 最低分
from score
group by 课程号;查询男生、女生人数
select 性别,count(*)
from student
group by 性别;
-- 陆老师的另一种写法
select
sum(case when 性别='男' then 1 else 0 end) as '男生人数',
sum(case when 性别='女' then 1 else 0 end) as '女生人数'
from student;
【分组结果的条件】
查询至少选修两门课程的学生学号
select 学号, count(课程号) as 选修课程数目
from score
group by 学号
having count(课程号)>=2;查询同名同姓学生名单并统计同名人数(逻辑思维漏洞,知识盲区:同名同性可以使用分组且数量大于2进行约束。该题与上一题在实现上相同,但同名同性逻辑表述较抽象。自己第一想法是left join,但这样实现上是比较混淆和困难的,没进一步深究)
select 姓名,count(*) as 人数
from student
group by 姓名
having count(*)>=2;我的第一想法(实现上是比较混淆和困难的,没进一步深究)

【结果排序】
查询不及格的课程并按课程号从大到小排列
select distinct 课程号
from score
where 成绩<60
order by 课程号 desc;查询每门课程的平均成绩,结果按平均成绩升序排序,平均成绩相同时,按课程号降序排列(逻辑思维漏洞,知识盲区:select查询结果字段存在别名时,sql语句中其他关键词后可以直接使用别名。如该题的“平均成绩”)
select 课程号, avg(成绩) as 平均成绩
from score
group by 课程号
order by 平均成绩 asc,课程号 desc;统计每门课程的学生选修人数(超过2人的课程才统计)
要求输出课程号和选修人数,查询结果按人数降序排序,若人数相同,按课程号升序排序
select 课程号, count(学号) as 选修人数
from score
group by 课程号
having 选修人数>2
order by 选修人数 desc,课程号 asc;查询两门以上不及格课程的同学的学号及其平均成绩(不及格课程的平均成绩)
-- 不及格课程的平均成绩
select 学号, avg(成绩) as 平均成绩
from score
where 成绩 <60
group by 学号
having count(课程号)>2;
-- 所有课程的平均成绩
SELECT 学号,avg(成绩)
FROM score
WHERE 学号 IN (
SELECT 学号
FROM score
WHERE 成绩 < 60
GROUP BY 学号
HAVING count(*)> 2 )
GROUP BY 学号【复杂查询】
查询所有课程成绩小于60分学生的学号、姓名
-- 猴子老师的答案(强调子查询知识点)
select 学号,姓名
from student
where 学号 in (
select 学号
from score
where 成绩 < 60
);
-- 我的第一想法(错误想法:120和0的平均值为60)
select b.学号,b.姓名
from score a, student b
where a.学号=b.学号
group by b.学号
having avg(成绩)<60
-- 陆老师:比较不及格课程数与选课数是否相等
select a.学号,c.姓名
from (select 学号,count(学号) as n from score where 成绩<60 group by 学号) as a,
(select 学号,count(学号) as m from score group by 学号) as b,
student as c
where a.学号=b.学号 and a.学号=c.学号 and a.n=b.m查找1990年出生的学生名单

查询下周过生日的学生(陆老师有讲解,但太麻烦了,略过)
查询本月过生日的学生
select * from student where month(出生日期)=month(now())查询下个月过生日的学生
select *
from student
where case when month(now())=12
then month(出生日期)=1
else month(出生日期)=month(now())+1 end【top N问题】
注意:top关键词仅sql server和access支持,mysql不支持。
按课程号分组取成绩最大值所在行的数据
select 学号,max(成绩)
from score
group by 学号查询各科成绩前两名的记录(难,逻辑思维漏洞,知识盲区:通过后续的窗口函数可以轻松实现)
(select * from score where 课程号 = '0001' order by 成绩 desc limit 2)
union all
(select * from score where 课程号 = '0002' order by 成绩 desc limit 2)
union all
(select * from score where 课程号 = '0003' order by 成绩 desc limit 2);
-- 我认为这样参数写死了,算是提供了一种思路,但不是最终的答案查询各学生的年龄(精确到月份)
--【知识点】时间格式转化
-- 猴子老师的答案
select 学, 出生日期, timestampdiff(month, 出生日期, now())/12 from student;
-- 陆老师的答案
select 学号, 出生日期, round(DATEDIFF(NOW(), 出生日期)/365) as 年龄 from student;
-- round(x,d)四舍五入并保留d位小数位,ceiling(x)向上取整,floor(x)向下取整【多表查询】
查询所有学生的学号、姓名、选课数、总成绩(逻辑思维漏洞,知识盲区:我第一想法是inner join写法,但题目中提及“所有学生”,所以应以student为左表,使用left join进行查询)
select a.学号,a.姓名,count(b.课程号) as 选课数,sum(b.成绩) as 总成绩
from student as a left join score as b
on a.学号 = b.学号
group by a.学号;
-- 我的第一想法(不周全的想法,存在没有选课的学生)
select a.学号,a.姓名,count(课程号),sum(成绩)
from student a, score b
where a.学号=b.学号
group by a.学号
-- 陆老师优化
select a.学号,a.姓名,count(b.课程号) as 选课数,
sum(case when b.成绩 is null then 0 else b.成绩 end) as 总成绩
from student as a left join score as b
on a.学号 = b.学号
group by a.学号;查询学生的选课情况:学号,姓名,课程号,课程名称
-- 学生的选课情况
select a.学号, a.姓名, c.课程号,c.课程名称
from student a inner join score b on a.学号=b.学号
inner join course c on b.课程号=c.课程号;
-- 所有学生的选课情况
select a.学号, a.姓名, c.课程号,c.课程名称
from student a left join score b on a.学号=b.学号
left join course c on b.课程号=c.课程号;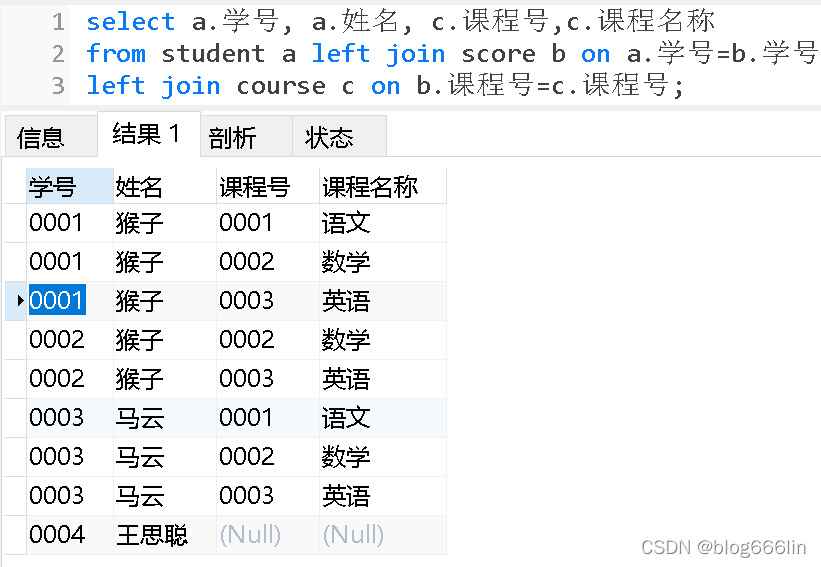
查询出每门课程的及格人数和不及格人数(逻辑思维漏洞,知识盲区:case when表达式)
-- 考察case when表达式
select 课程号,
sum(case when 成绩>=60 then 1 else 0 end) as 及格人数,
sum(case when 成绩<60 then 1 else 0 end) as 不及格人数
from score
group by 课程号;
-- 尝试子查询实现
select p.课程号,n as 不及格数,m as 及格数
from
(select a.课程号,b.n
from
(select 课程号 from score group by 课程号) as a
left join
(select 课程号,count(*) as n from score where 课程号 in (select 课程号 from score group by 课程号) and 成绩<60 GROUP BY 课程号) as b
on a.课程号=b.课程号) as p,
(select a.课程号,b.m from
(select 课程号 from score group by 课程号) as a
left join
(select 课程号,count(*) as m from score where 课程号 in (select 课程号 from score group by 课程号) and 成绩>=60 GROUP BY 课程号) as b
on a.课程号=b.课程号) as q
where p.课程号=q.课程号使用分段[100-85],[85-70],[70-60],[<60]来统计各科成绩,分别统计:各分数段人数,课程号和课程名称(逻辑思维漏洞,知识盲区:case when表达式的between...and和and)
-- 考察case表达式
select a.课程号,b.课程名称,
sum(case when 成绩 between 85 and 100 then 1 else 0 end) as '[100-85]',
sum(case when 成绩 >=70 and 成绩<85 then 1 else 0 end) as '[85-70]',
sum(case when 成绩>=60 and 成绩<70 then 1 else 0 end) as '[70-60]',
sum(case when 成绩<60 then 1 else 0 end) as '[<60]'
from score as a right join course as b
on a.课程号=b.课程号
group by a.课程号,b.课程名称;
-- 陆老师另一种写法:使用count()时,需要对应NULL值
-- 知识点:count()不会统计值为NULL的记录
count(case when 成绩 between 85 and 100 then 1 else NULL end) as '[100-85]')【行列互换】
下面是学生的成绩表(表名score,列名:学号、课程号、成绩)

使用sql实现将该表行转列为下面的表结构(难)

-- 我认为这样参数写死了,算是提供了一种思路,但不是最终的答案
-- 陆老师优化else 0为else NULL,0表示考试0分,NULL表示未选课
select 学号,
max(case 课程号 when '0001' then 成绩 else NULL end) as '课程号0001',
max(case 课程号 when '0002' then 成绩 else NULL end) as '课程号0002',
max(case 课程号 when '0003' then 成绩 else NULL end) as '课程号0003'
from score
group by 学号;
select a.学号,a.成绩 as '课程号0001',b.成绩 as '课程号0002',c.成绩 as '课程号0003'
from
(select p.学号,成绩 from (select distinct 学号 from score) as p left join (select 学号,成绩 from score where 课程号='0001') as q on p.学号=q.学号) as a,
(select p.学号,成绩 from (select distinct 学号 from score) as p left join (select 学号,成绩 from score where 课程号='0002') as q on p.学号=q.学号) as b,
(select p.学号,成绩 from (select distinct 学号 from score) as p left join (select 学号,成绩 from score where 课程号='0003') as q on p.学号=q.学号) as c
where a.学号=b.学号 and a.学号=c.学号;查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩
select b.姓名,avg(a.成绩),a.学号
from score as a
inner join student as b
on a.学号 =b.学号
where a.成绩 <60
group by a.学号
having count(a.学号 ) >=2;查询不同课程,成绩相同的学生的学生编号、课程编号、学生成绩(这题出的别扭,猴子老师的答案是只要同一学生选修课程的成绩相同就符合,陆老师的答案是查询同一学生选修课程的成绩全部相同的信息)
-- 猴子老师的答案
SELECT DISTINCT
a.学号,
a.成绩,
a.课程号
FROM
score AS a
INNER JOIN score AS b ON a.学号 = b.学号
WHERE
a.课程号 != b.课程号
AND a.成绩 = b.成绩;
-- 陆老师的答案,前提:只选修一门课程的学生也算
select 学号
from (select 学号,成绩 from score group by 学号,成绩) as a
group by 学号
having count(学号)=1查询课程编号为“0001”的课程比“0002”的课程成绩高的所有学生的学号
-- 猴子老师答案
select a.学号
from
(select 学号,成绩 from score where 课程号='0001') as a
inner join
(select 学号,成绩 from score where 课程号='0002') as b
on a.学号=b.学号
where a.成绩>b.成绩;
-- 我使用","替换inner join
select a.学号
from
(select 学号,成绩 from score where 课程号='0001') as a,
(select 学号,成绩 from score where 课程号='0002') as b
where a.学号=b.学号 and a.成绩>b.成绩;
-- 我的第一想法:使用行列互换的方式实现
select 学号
from (select 学号,
max(case when 课程号='0001' then 成绩 else 0 end) as a,
max(case when 课程号='0002' then 成绩 else 0 end) as b
from score
group by 学号) as p
where a>b查询学过编号为“0001”的课程并且也学过编号为“0002”的课程的学生的学号、姓名
select a.学号
from
(select 学号,成绩 from score where 课程号='0001') as a,
(select 学号,成绩 from score where 课程号='0002') as b
where a.学号=b.学号;
查询学过“孟扎扎”老师教的所有课的学生学号
-- 前提:学号与课程号1对1关系
select 学号,count(*)
from score a,course b,teacher c
where a.`课程号`=b.`课程号` and b.`教师号`=c.`教师号` and c.`教师姓名`='孟扎扎'
group by a.学号
having count(*)=(select count(*) from course b,teacher c where b.`教师号`=c.`教师号` and c.`教师姓名`='孟扎扎')查询学过“孟扎扎”老师任意一门课程的学生学号
select DISTINCT a.`学号`
from score a, course b, teacher c
where a.`课程号`=b.`课程号` and b.`教师号`=c.`教师号` and c.`教师姓名`='孟扎扎';查询没学过“孟扎扎”老师课程的学生学号(与以上两题不同之处:必须涉及student表,因为存在学生没选课的情况)
select *
from student
where 学号 not in (select DISTINCT a.`学号`
from score a, course b, teacher c
where a.`课程号`=b.`课程号` and b.`教师号`=c.`教师号` and c.`教师姓名`='孟扎扎')查询学过“孟扎扎”老师课程中成绩最高的学生号和成绩(逻辑思维漏洞,知识盲区:我的第一想法是使用group by,但没有分组的依据。第二想法是单独使用max(),但只能获取最高分是多少,无法获取对应的学生信息。)
select s.学号,s.成绩
from score s,course c,teacher t
where s.课程号=c.课程号 and c.教师号=t.教师号 and t.教师姓名='孟扎扎'
order by 成绩 desc
limit 0,1
limit m,n -- m表示查询起始位置,n表示返回多少记录数查询至少有一门课与学号为“0001”的学生所学课程相同的学生学号(逻辑思维漏洞,知识盲区:我的第一想法是查询出0001学生所学课程号集合c1,依次获取每个学生的课程号集合c2,如果c2中存在一个课程号在c2中,则认为该学生符合条件。但是这样使用sql实现起来较为复杂,所以不再进一步深究)
select distinct(学号)
from score
where 学号 !='0001'
and 课程号 in (select 课程号
from score
where 学号='0001');查询所学课程与学号为“0001”的学生所学课程完全相同的学生学号(逻辑思维漏洞,知识盲区:存在考虑不周的情况。此题自己无脑跟着陆老师的思维翻车了。。。)

select *
from student
where 学号 in (select 学号
from score
where 学号!='0001'
group by 学号
having count(课程号)=(select count(课程号)
from score
where 学号='0001'))
and 学号 not in (select 学号
from score
where 课程号 not in (select 课程号
from score
where 学号='0001'))按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩(我认为这样参数写死了,算是提供了一种思路,但不是最终的答案)

【窗口函数(sql高级功能)】
窗口函数解决3类问题:
1)分组排名
2)topN问题
3)组内比较
查询学生平均成绩及其名次(逻辑思维漏洞,知识盲区:row_number() over()。窗口函数的order by是根据值排序,而select的order by是根据值返回结果顺序。窗口函数的order by必须使用,但partition by根据情况使用)
select 学号, avg(成绩), row_number() over(order by avg(成绩) desc)
from score
group by 学号;按各科成绩进行排序,并显示排名
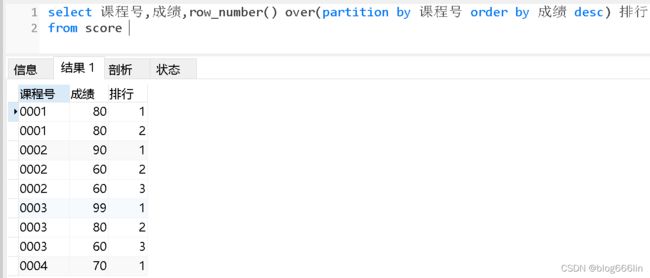
查询课程的总成绩并排名
select 课程号,sum(成绩),row_number() over(order by sum(成绩) desc) 排行
from score
group by 课程号如下是使不使用partition by比较的案例1:
 如下是使不使用partition by比较的案例2:
如下是使不使用partition by比较的案例2:
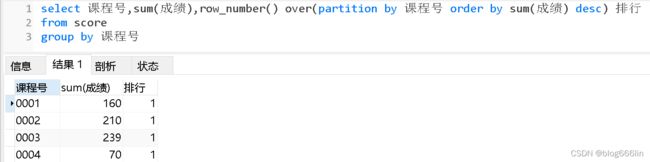

查询各科成绩前两名的记录
-- 前提:不考虑成绩并列情况
select *
from (select 课程号 ,学号 ,成绩 ,row_number () over(partition by 课程号 order by 成绩 desc) as ranking from score) as a
where a.ranking<3;查询各科成绩第2-3名的记录
-- 前提:不考虑成绩并列情况
select *
from (select 课程号 ,学号 ,成绩 ,row_number () over(partition by 课程号 order by 成绩 desc) as ranking from score) as a
where a.ranking BETWEEN 2 and 3;
select *
from (select 课程号 ,学号 ,成绩 ,row_number () over(partition by 课程号 order by 成绩 desc) as ranking from score) as a
where a.ranking in (2,3);