Pandas常用操作命令(六)——数据分组groupby
文章目录
- ️ 6. 数据分组
-
- 6.1 一列分组
- 6.2 多列分组
- 6.3 每组的统计数据(横向显示)
- 6.4 每组的统计数据(纵向显示)
- 6.5 查看指定列的统计信息
- 6.6 分组大小
- 6.7 分组成绩最大值
- 6.8 分组成绩最小值
- 6.9 分组成绩总和
- 6.10 分组平均成绩
- 6.11 按省份分组,计算英语成绩总分和平均分
- 6.12 按省份、城市分组计算平均成绩
- 6.13 不同列不同的计算方法
- 6.14 性别分别替换为1/0
- 6.15 增加一列按省份分组的语文平均分
- 6.16 输出语文成绩最高的男生和女生(groupby默认会去掉空值)
- 6.17 按列省份、城市进行分组,计算语文、数学、英语成绩最大值的透视表
- 推荐阅读
大家好,我是 【Python当打之年(点击跳转)】
本期为大家带来 《 Pandas常用操作命令》 的 第六篇 ,主要介绍在数据处理可视化过程中经常用到的一些指令,本系列在后期会不断进行补充更新,希望对你有所帮助,如有疑问或者需要改进的地方可以私信小编。
️ 6. 数据分组
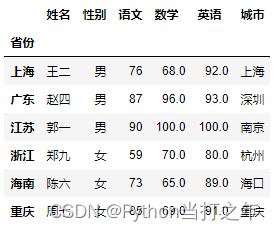
示例数据:

6.1 一列分组
df2.groupby('省份').groups
{‘上海’: [‘009’], ‘广东’: [‘003’, ‘010’], ‘江苏’: [‘001’, ‘013’], ‘浙江’: [‘011’], ‘海南’: [‘005’], ‘重庆’: [‘007’]}
6.2 多列分组
df2.groupby(['省份','城市']).groups
{(‘上海’, ‘上海’): [‘009’], (‘广东’, ‘广州’): [‘003’], (‘广东’, ‘深圳’): [‘010’], (‘江苏’, ‘南京’): [‘001’, ‘013’], (‘浙江’, ‘杭州’): [‘011’], (‘海南’, ‘海口’): [‘005’], (‘重庆’, ‘重庆’): [‘007’]}
6.3 每组的统计数据(横向显示)
df2.groupby('省份').describe()
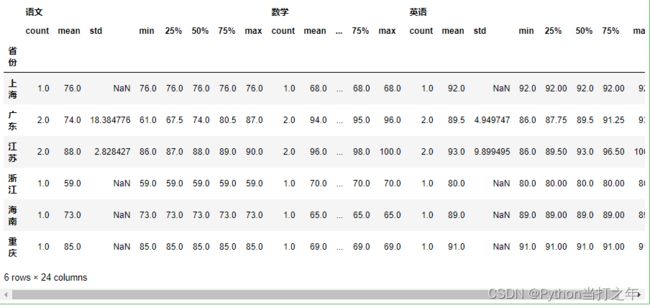
6.4 每组的统计数据(纵向显示)
df2.groupby('省份').describe().unstack()

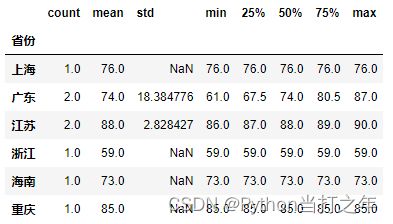
6.5 查看指定列的统计信息
df2.groupby('省份').describe()['语文']
6.6 分组大小
df2.groupby('省份').count()
df2.groupby('省份').agg(np.size)

6.7 分组成绩最大值
df2.groupby('省份').max()
df2.groupby('省份').agg(np.max)
6.8 分组成绩最小值
df2.groupby('省份').min()
df2.groupby('省份').agg(np.min)

6.9 分组成绩总和
df2.groupby('省份').sum()
df2.groupby('省份').agg(np.sum)

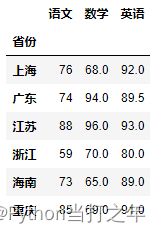
6.10 分组平均成绩
df2.groupby('省份').mean()
df2.groupby('省份').agg(np.mean)
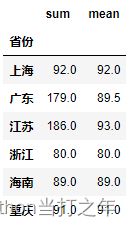
6.11 按省份分组,计算英语成绩总分和平均分
df2.groupby('省份')['英语'].agg([np.sum, np.mean])
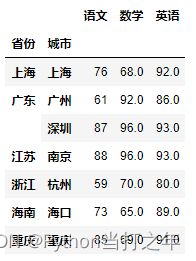
6.12 按省份、城市分组计算平均成绩
df2.groupby(['省份','城市']).agg(np.mean)
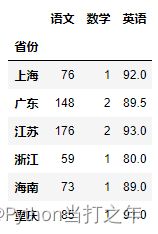
6.13 不同列不同的计算方法
df2.groupby('省份').agg({'语文': sum, '数学':'count', '英语':'mean'})
6.14 性别分别替换为1/0
df2 = df2.dropna()
df2['性别'] = df2['性别'].map({'男':1, '女':0})

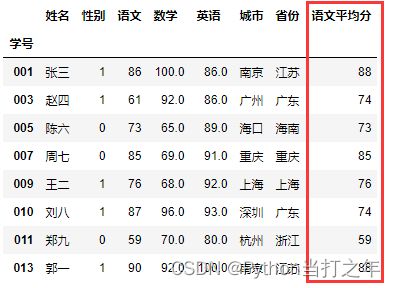
6.15 增加一列按省份分组的语文平均分
df2['语文平均分'] = df2.groupby('省份')['语文'].transform('mean')
6.16 输出语文成绩最高的男生和女生(groupby默认会去掉空值)
def get_max(g):
df = g.sort_values('语文',ascending=True)
print(df)
return df.iloc[-1,:]
df2.groupby('性别').apply(get_max)
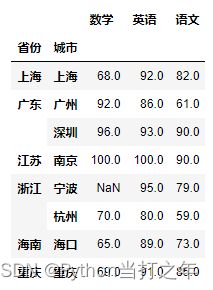
6.17 按列省份、城市进行分组,计算语文、数学、英语成绩最大值的透视表
df.pivot_table(index=['省份','城市'], values=['语文','数学','英语'], aggfunc=max)
未完待续。。。
文章首发:微信公众号 “Python当打之年” ,Python编程技巧推送,希望大家可以喜欢。
以上就是本期为大家整理的全部内容了,赶快练习起来吧,原创不易,喜欢的朋友可以点赞、收藏也可以分享(注明出处)让更多人知道。
推荐阅读
- 【Pandas+Pyecharts | 山东省高考考生数据分析可视化】
- 【Pandas+Pyecharts | 40000+汽车之家数据分析可视化】
- 【Pandas+Pyecharts | 20000+天猫订单数据可视化】
- 【Pandas+Pyecharts | 广州市已成交房源信息数据可视化】
- 【Pandas+Pyecharts | 考研信息数据可视化】
- 【Pandas+Pyecharts | 某平台招聘信息数据可视化】
- 【Pandas+Pyecharts | 医院药品销售数据可视化】
- ️ 【Pyecharts | 比特币每日价格动态可视化】
- 【可视化 | Python中秋月饼销量分析,这些口味才是yyds!】
- 【Pyecharts | 《白蛇2:青蛇劫起》20000+数据分析可视化】
- 【Pyecharts | 历年全国各地民政局登记数据分析+可视化】
- 【Pandas+Pyecharts | 全国热门旅游景点数据分析+可视化】
- 【Pandas+Pyecharts | 2020东京奥运会奖牌数据可视化】
- 【Pandas常用基础操作指令汇总 】
- 【pandas + pyecharts | ADX游戏广告投放渠道综合分析】
- 【Schedule + Pyecharts | 时间序列图(动态轮播图)】
- 【Pandas+Pyecharts | 北京某平台二手房数据分析+可视化】
- 【Pandas+Pyecharts | 2021中国大学综合排名分析+可视化】
- 【爬虫 | Python爬取豆瓣电影Top250 + 数据可视化】
- 【技巧 | Python创建自己的高匿代理IP池】