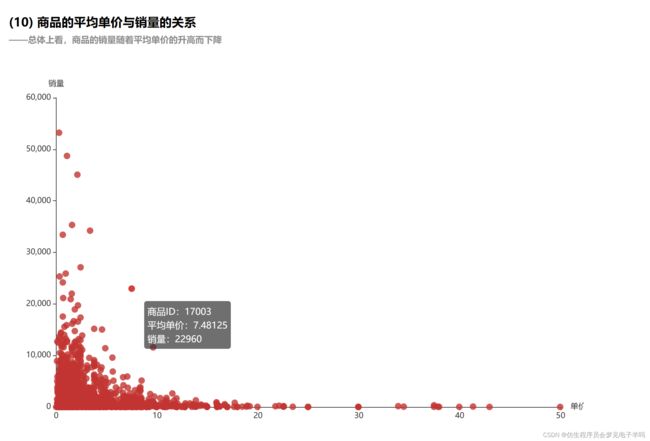
【大数据基础】基于零售交易数据的Spark数据处理与分析
环境搭建
sudo apt-get install python3-pip
pip3 install bottle

数据预处理
首先,将数据集E_Commerce_Data.csv上传至hdfs上,命令如下:
./bin/hdfs dfs -put /home/hadoop/E_Commerce_Data.csv /user/hadoop
![]()
接着,使用如下命令进入pyspark的交互式编程环境,对数据进行初步探索和清洗:
cd /usr/local/spark #进入Spark安装目录
./bin/pyspark
(1)读取在HDFS上的文件,以csv的格式读取,得到DataFrame对象。
>>> df=spark.read.format('com.databricks.spark.csv').options(header='true', inferschema='true').load('E_Commerce_Data.csv')
(2)查看数据集的大小,输出541909,不包含标题行
df.count()

(3)打印数据集的schema,查看字段及其类型信息。输出内容就是上文中的属性表。
df.printSchema()

(4)创建临时视图data。
df.createOrReplaceTempView("data")
(5)由于顾客编号CustomID和商品描述Description均存在部分缺失,所以进行数据清洗,过滤掉有缺失值的记录。特别地,由于CustomID为integer类型,所以该字段若为空,则在读取时被解析为0,故用df[“CustomerID”]!=0 条件过滤。
clean=df.filter(df["CustomerID"]!=0).filter(df["Description"]!="")
(6)查看清洗后的数据集的大小,输出406829。
clean.count()
![]()
(7)数据清洗结束。根据作业要求,预处理后需要将数据写入HDFS。将清洗后的文件以csv的格式,写入E_Commerce_Data_Clean.csv中(实际上这是目录名,真正的文件在该目录下,文件名类似于part-00000),需要确保HDFS中不存在这个目录,否则写入时会报“already exists”错误。
>>> clean.write.format("com.databricks.spark.csv").options(header='true',inferschema='true').save('E_Commerce_Data_Clean.csv')

数据分析
首先,导入需要用到的python模块。
# -*- coding: utf-8 -*-
from pyspark import SparkContext
from pyspark.sql import SparkSession
from pyspark.sql.types import StringType, DoubleType, IntegerType, StructField, StructType
import json
import os
接着,获取spark sql的上下文。
sc = SparkContext('local', 'spark_project')
sc.setLogLevel('WARN')
spark = SparkSession.builder.getOrCreate()
最后,从HDFS中以csv的格式读取清洗后的数据目录E_Commerce_Data_Clean.csv,程序会取出该目录下的所有数据文件,得到DataFrame对象,并创建临时视图data用于后续分析。
df = spark.read.format('com.databricks.spark.csv').options(header='true', inferschema='true').load('E_Commerce_Data_Clean.csv')
df.createOrReplaceTempView("data")
为方便统计结果的可视化,将结果导出为json文件供web页面渲染。使用save方法导出数据:
def save(path, data):
with open(path, 'w') as f:
f.write(data)
最后利用如下指令运行分析程序:
cd /usr/local/spark
./bin/spark-submit project.py
可视化方法
from bottle import route, run, static_file
import json
@route('/static/' )
def server_static(filename):
return static_file(filename, root="./static")
@route("/" )
def server_page(name):
return static_file(name, root=".")
@route("/")
def index():
return static_file("index.html", root=".")
run(host="0.0.0.0", port=9999)
代码完成后,在代码所在的根目录下执行以下指令启动web服务器:
python3 web.py

为方便运行程序,编写run.sh脚本,内容如下。首先向spark提交project.py程序对数据进行统计分析,生成的json文件会存入当前路径的static目录下;接着运行web.py程序,即启动web服务器对分析程序生成的json文件进行解析渲染,方便用户通过浏览器查看统计结果的可视化界面。
#!/bin/bash
cd /usr/local/spark
./bin/spark-submit project.py
python3 web.py

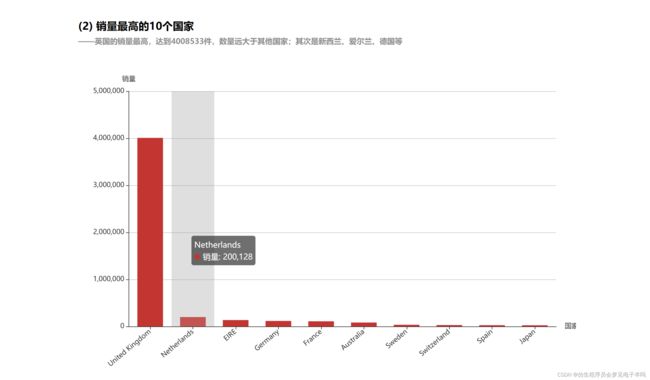
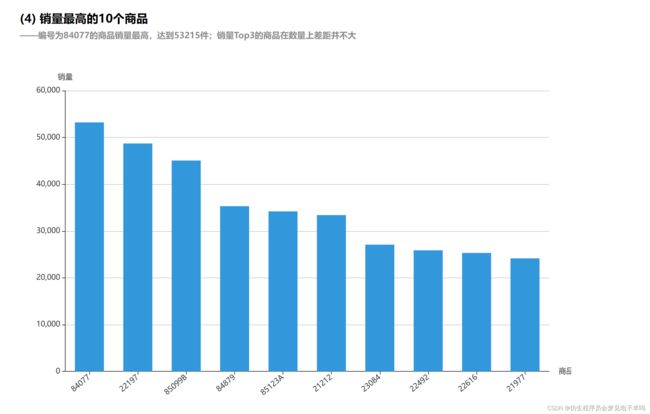
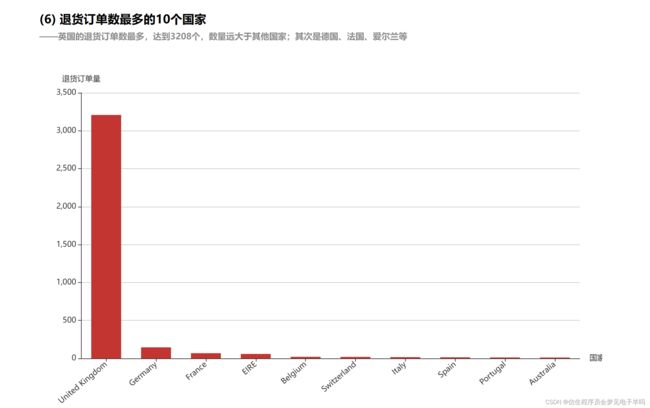
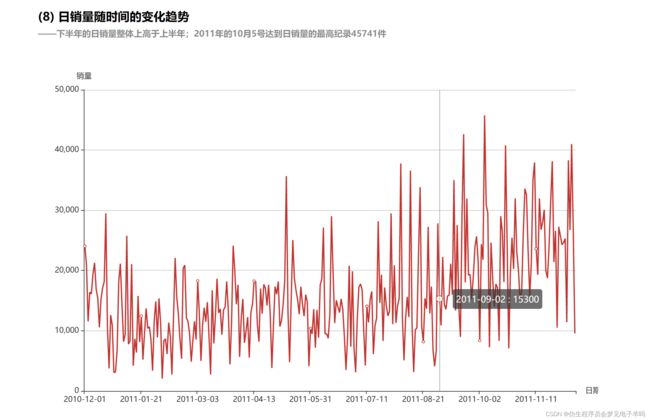
结果可视化