SQL 窗口函数应用
SQL 窗口函数应用
这里主要是记录窗口函数的相关应用,把有用的知识形成笔记,以方便自个儿复习
简介
窗口函数是 SQL 中一类特别的函数。与聚合函数相似,窗口函数的输入也是多行记录。不 同的是,聚合函数的作用于由 GROUP BY 子句聚合的组,而窗口函数则作用于一个窗口, 这里,窗口是由一个 OVER 子句 定义的多行记录。聚合函数对其所作用的每一组记录输 出一条结果,而窗口函数对其所作用的窗口中的每一行记录输出一条结果。一些聚合函 数,如 sum, max, min, avg,count 等也可以当作窗口函数使用。
一、窗口函数
(一)窗口函数分类
常用窗口函数分类:

1、排序窗口函数
- rank() over() 1 2 2 4 4 6 (计数排名,跳过相同的几个,eg.没有3没有5)
- row_number() over() 1 2 3 4 5 6 (赋予唯一排名)
- dense_rank() over() 1 2 2 3 3 4 (不跳过排名,可理解为对类别进行计数)
2、分布窗口函数
- percent_rank() over() 按照数字所在的位置进行百分位分段
- cume_dist() over()
cume_dist() over() 详解:
如果按升序排列,则统计:小于等于当前值的行数/总行数(number of rows ≤ current row)/(total number of rows)。如果是降序排列,则统计:大于等于当前值的行数/总行数。
公式:
- 当升序排列,计算小于等于当前值的行数/总行数(number of rows ≤ current row)/(total number of rows)
- 当降序排列,计算大于等于当前值的行数/总行数。
3、前后窗口函数
- lead(字段名,n)over()把字段数据向前移n个单元格
- lag(字段名,n)over()把字段数据向后移n个单元格
4、头尾窗口函数
- first_value(字段名)over() 取分组内排序后,截止到当前行,第一个值
- last_value(字段名)over() 函数返回有序行集中的最后一行
5、聚类窗口函数
- 主要考察聚类窗口函数,和聚类窗口函数的用法和group by 函数类似;
- 我的理解窗口函数的关键词是“不改变表格结构”,查出的数据,单独放一列。
- min()over() :不改变表结构的前提下,计算出最小值
- max()over():不改变表结构的前提下,计算出最大值
- count()over():不改变表结构的前提下,计数
- sum()over():不改变表结构的前提下,求和
- avg()over():不改变表结构的前提下,求平均值
6、其他窗口函数
- ntile(n)over() 将数字按照大小平均分成n段
- nth_value(字段名,n) over() 取指定排名行的数据
nth_value()详解:
nth_value(字段名 ,1) from first over (order by ID) 是根据查询出的排序结果取第一行数据的值作为该列的值,如果没取到该值为空
(二)窗口函数详解
(1)排序函数详解
①详解
- rank() over() 1 2 2 4 4 6 (计数排名,跳过相同的几个,eg.没有3没有5)
- row_number() over() 1 2 3 4 5 6 (赋予唯一排名)
- dense_rank() over() 1 2 2 3 3 4 (不跳过排名,可理解为对类别进行计数)
②示例
sql
select uid ,
row_number()over(order by uid) row_number1, /*按照uid的大小不重不漏1 2 3 4 5 6 7 */
rank()over(order by uid) rank1, /*按照uid的大小并列第一无第二,1 1 1 4 5 5 7*/
dense_rank()over(order by uid) dense_rank1,/*按照uid的大小并列第一有第二,1 1 1 2 3 3 4*/
percent_rank()over(order by uid) percent_rank1,/*按照uid的大小进行百分法排序*/
ntile(2)over(order by uid) ntile1,/*按照uid的大小,把uid评价分成2组*/
lead(uid)over(order by uid) lead1,/*把uid向上推1个位置*/
lag(uid)over(order by uid) lag1 /*把uid向下推1个位置*/
from user_info;
结果

(2)percent_rank() 详解
描述
以第二行的0.111111…为例,它是通过(rank - 1) / (rows - 1)计算得到的,其中rows为表的行数,即10;rank为排名,即2;结果为:(2-1)/(10-1)=1/9
sql
select *,
percent_rank() over(order by order_price) as percent_ranking,
rank() over(order by order_price)as ranking
from order_content;
截图

(3)first_value() 详解
select s.sid,s1.sname,s1.gender,c.cname,s.num,
first_value(num) over(partition by c.cname order by num desc) as first_value1
from score s join student s1 on s.student_id = s1.sid
left join course c on s.course_id = c.cid

(4)nth_value() 详解
sql
select id, name ,dept,
nth_value(name,3) over (order by id) as a
nth_value(name ,4) over (order by id) as b
nth_value(name ,1) from first over (order by id) as c
nth_value(name ,2) from first over (partition by dept order by id) as d,
nth_value(name ,2) from first over (order by id) as e,
nth_value(name ,4) from last over (order by id) as f
from salary
结果

解析
- 从上面的查询结果我们可以看出nth_value(product_name,3)是根据后面的分组的原则(分组或者不分组)找到已product_name排序的第三个值作为该列的值,如果没取到该值为空;
- nth_value(NAME ,1) from first over (order by ID) 是根据查询出的排序结果取第一行数据的值作为该列的值,如果没取到该值为空;
- nth_value(NAME ,4) from last over (order by ID) 这个的用法是从排序的是4名开始往后取依次错开作为该行的值。
(5)cume_dist() 详解
- 当升序排列,计算小于等于当前值的行数/总行数(number of rows ≤ current row)/(total number of rows)
- 当降序排列,计算大于等于当前值的行数/总行数。
(6)lead、lag() 详解
①详解
- lead(字段名,n) over () :取值向后偏移n行(空间的理解就是直接将一列数据往前推n个位置,后面的位置就空出来了,具体配合图片理解);
- lag(字段名,n) over () :取值向前偏移n行(空间的理解就是直接将一列数据往前后n个位置,前面的位置就空出来了,具体配合图片理解);
- lag(字段名,n,x) over () :取值向前偏移n行,并将空值填充为数字x(空间的理解就是直接将一列数据往前后n个位置,前面的空出来的位置用X填充上,具体配合图片理解)。
②示例
sql
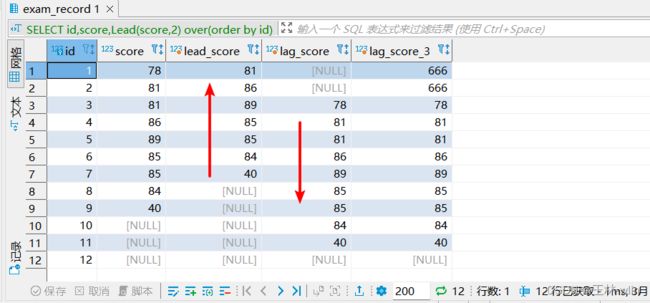
SELECT id,score,Lead(score,2) over(order by id) lead_score,-- score数列向前推动2位,后面就腾空了2个位置
Lag(score,2) over(order by id) lag_score, -- score数列向后推2位,腾空2个位置
lag(score,2,666) over(order by id) lag_score_3 -- score数列向后推动2位,空值被填充为666
FROM exam_record;
结果
(三)其他函数详解
(1)datediff() 详解
①详解
- datediff(时间1,时间2):计算两个日期之间间隔的天数,单位为日
- timestampdiff(时间单位,开始时间,结束时间):两个日期的时间差,返回的时间差形式由时间单位决定(日,周,月,年)
- date_add(日期,INTERVAL n 时间单位) :返回加上n个时间单位后的日期
- date_sub(日期,INTERVAL n 时间单位 ):返回减去n个时间单位后的日期
- date_format(时间,‘%Y-%m-%d’):强制转换时间为所需要的格式
②示例

(2)datediff、timestampdiff() 详解
①详解
- datediff()函数的作用是求日期差,也就是把一个时间的日期部分取出来求差。例如:'2021-09-05 12:00:00’和’2021-09-04 11:00:00’这两个日期,datediff只取2021-09-05和2021-09-04求日期差,并不会管后面的时间部分。
- timestampdiff()函数的作用则是求时间戳的差,例如:'2021-09-05 12:00:00’和’2021-09-04 11:00:00’这两个日期,datediff只会先求出这个日期的时分秒差,之后再转换成天数来求日期差。
直接说可能有点懵,看完差别后,具体来看下面这个例子:
②示例1
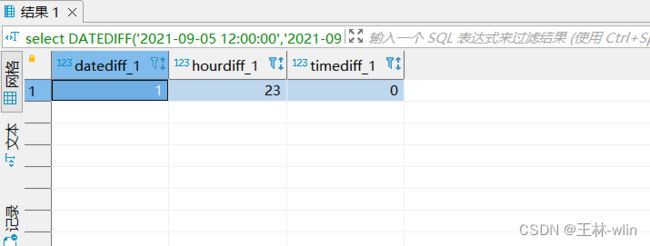
先看第一组时间差是23小时,日期差(9月5日-9月4日)是1天
#先看第一组时间差是23小时,日期差(9月5日-9月4日)是1天
select DATEDIFF('2021-09-05 12:00:00','2021-09-04 11:00:00') datediff_1,
TIMESTAMPDIFF(hour,'2021-09-04 12:00:00','2021-09-05 11:00:00') hourdiff_1,
TIMESTAMPDIFF(day,'2021-09-04 12:00:00','2021-09-05 11:00:00')timediff_1;
③示例2
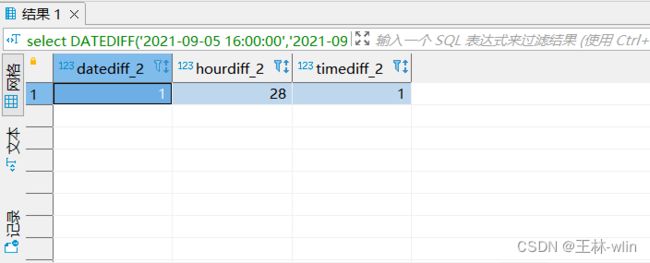
再看第二组时间差是28小时,日期差(9月5日-9月4日)是1天
#再看第二组时间差是28小时,日期差(9月5日-9月4日)是1天
select DATEDIFF('2021-09-05 16:00:00','2021-09-04 11:00:00') datediff_2,
TIMESTAMPDIFF(hour,'2021-09-04 12:00:00','2021-09-05 16:00:00') hourdiff_2,
TIMESTAMPDIFF(day,'2021-09-04 12:00:00','2021-09-05 16:00:00')timediff_2;
看完这个是不是就很容易理解啦~
二、窗口函数SQL
(1)示例1
select tag,uid,ranking
from (
select b.tag,a.uid,max(a.score),min(a.score),
row_number() over(partition by b.tag order by max(a.score) desc,min(a.score) desc,a.uid desc) ranking
from exam_record a
left join examination_info b on a.exam_id = b.exam_id
group by b.tag,a.uid
) t
where ranking < 4
(2)示例2
select exam_id,duration,release_time
from (
select exam_id,duration,release_time,
sum(case when rk_desc=2 then time_diff
when rk_asc=2 then - time_diff else 0 end) sum_time
from (
select
a.exam_id,b.duration ,timestampdiff(minute,a.start_time,a.submit_time) time_diff,b.release_time,
row_number() over(partition by a.exam_id order by timestampdiff(minute,a.start_time,a.submit_time) desc ) rk_desc,
row_number() over(partition by a.exam_id order by timestampdiff(minute,a.start_time,a.submit_time) asc) rk_asc
from exam_record a left join examination_info b on a.exam_id=b.exam_id
where a.submit_time is not null
) t1 group by exam_id
) t2
where sum_time*2 >= duration
order by exam_id desc
(3)示例3
WITH t2 AS (
SELECT
uid,
COUNT(start_time) total, -- 用户2021年作答的次数
DATEDIFF(MAX(start_time),MIN(start_time))+1 diff_time, -- 头尾作答时间窗
MAX(DATEDIFF(next_time,start_time))+1 days_window -- 最大间隔天数
FROM (
SELECT uid,start_time,
LEAD(start_time,1)OVER(PARTITION BY uid ORDER BY start_time) AS next_time -- 第二次作答时间
FROM exam_record
WHERE YEAR(start_time)=2021 -- 2021年的数据
) t1
GROUP BY uid
)
SELECT uid,days_window,ROUND(total* days_window/diff_time,2) avg_exam_cnt
FROM t2
WHERE diff_time>1
ORDER BY days_window DESC,avg_exam_cnt DESC
关注林哥,持续更新哦!!!★,°:.☆( ̄▽ ̄)/$:.°★ 。