python中xpath解析库的讲解及案例分析
目录
一.xpath解析库的安装
二.xpath的初体验
三.xpath常用的查找方式
/text()和//text()的区别:
注意:用text()方法查找到的内容是以一个列表的类型输出数据,要获取属性值的内容就直接/@属性值就可以了
四.xpathhelper工具的下载与安装以及使用方法
分析之前我先给大家介绍一个常用的xpath在浏览器中的一个开发者工具的一个插件xpathhelper,可以帮助大家更快上手xpath解析库
一.安装xpathhelper(以Google浏览器为例(建议使用))
安装方法二:
xpathhelper使用方法:使用快捷键ctrl+shift+x就可(前提是要打开自己要爬取的url的开发者工具)
五.下面是站长素材的案例分析
这里抓取要注意几个点:
最后感谢大家看到这里,可能文章也有很多不妥之处,希望大家多多提建议,大家一起学习一起进步,有问题也可以互相讨论,咱们评论区见!!!
一.xpath解析库的安装
方法一: 在cmd中安装
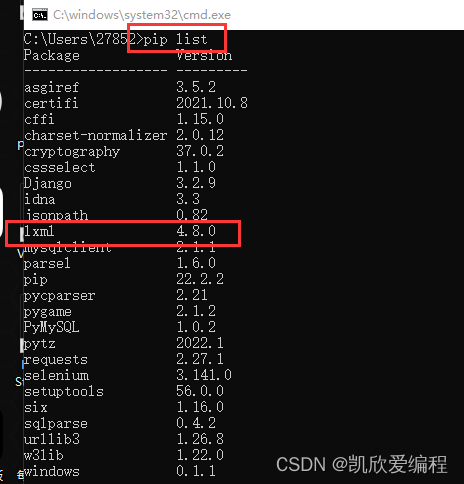
直接在cmd中输入pip install lxml然后回车就可以了 安装完成后在输入pip list 在里面要是能找到lxml说明安装成功
方法二:直接在pycharm编译器终端输入pip install lxml也可以完成安装
二.xpath的初体验
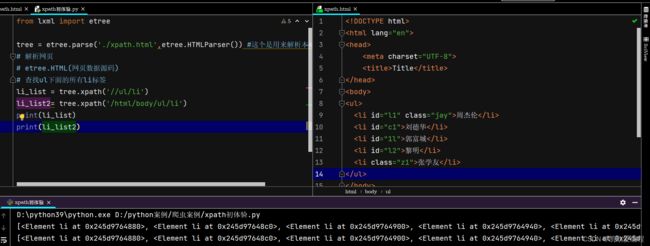
此处我分析一下//和/的区别:
//: 它代表的是查找所有子孙后代,就是不管它前面是否还有其它的父节点,直接定位到你想要定位的子孙节点
/: 它代表的是查找直系的子节点必需按照由外到内一层一层查找
三.xpath常用的查找方式
# 查找ul下含有class属性的小li标签
li_list = tree.xpath('//ul/li[@class]')
print(li_list)
# 查找ul下id属性为l1的li标签
li_list1 = tree.xpath('//ul/li[@id="l1"]')
print(li_list1)
# 查找li的id属性包含l的li标签值
li_list2 = tree.xpath('//ul/li[contains(@id,"l")]/text()')
print(li_list2)
#查找id值以l开头的小li标签值
li_list3= tree.xpath('//ul/li[starts-with(@id,"l")]/text()')
print(li_list3)
#查找id值为l1或者id值为c1的li标签的值
li_list4 = tree.xpath('//ul/li[@id="l1"]/text() | //ul/li[@id="c1"]/text()')
print(li_list4)
#获取class属性为z1的li标签下面的内容
li_content = tree.xpath('//ul/li[@class="z1"]//text()')
print(li_content) 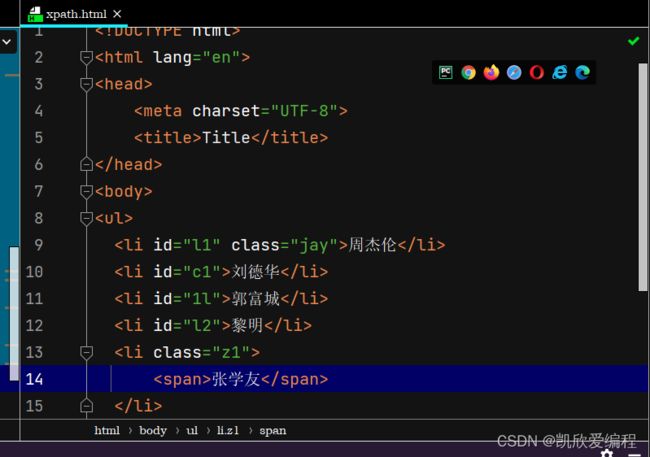
大家可能会看到我第六个查找方法用了//text()而其他方法用了/text()
/text()和//text()的区别:
/text: 就是直接查找标签下面的直系内容
//text: 可以查找到子孙后代下面的所有内容
注意:用text()方法查找到的内容是以一个列表的类型输出数据,要获取属性值的内容就直接/@属性值就可以了
四.xpathhelper工具的下载与安装以及使用方法
分析之前我先给大家介绍一个常用的xpath在浏览器中的一个开发者工具的一个插件xpathhelper,可以帮助大家更快上手xpath解析库
一.安装xpathhelper(以Google浏览器为例(建议使用))
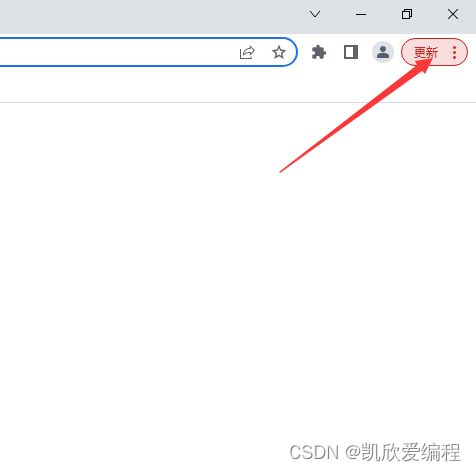
点击右上角的三个点-->找到"更多工具"--->"扩展程序"
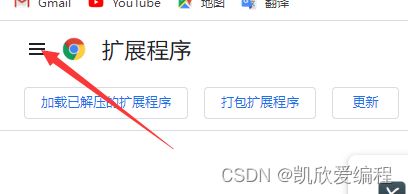
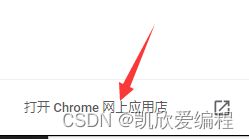
注意:在里面下载就好了,但是在下载之前要先打开电脑的科学上网工具
安装方法二:
直接在百度搜索xpathhelper进行下载
下载链接: https://chrome.zzzmh.cn/info?token=hgimnogjllphhhkhlmebbmlgjoejdpjl
下载完成解压后会有一个.crx为扩展名的文件,只需要把文件复制到扩展程序里面去就好了
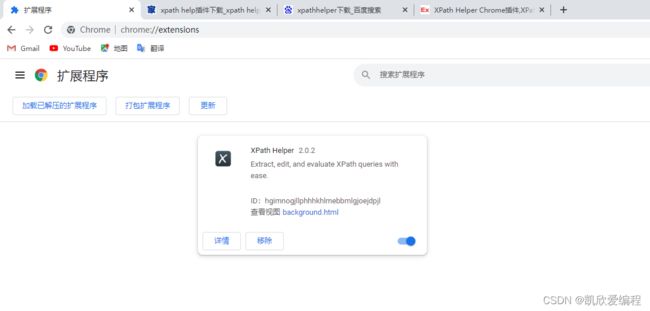
xpathhelper使用方法:使用快捷键ctrl+shift+x就可(前提是要打开自己要爬取的url的开发者工具)
五.下面是站长素材的案例分析
import urllib.request
from lxml import etree
import os
# https://sc.chinaz.com/tupian/qinglvtupian.html
# https://sc.chinaz.com/tupian/qinglvtupian_1.html
# https://sc.chinaz.com/tupian/qinglvtupian_2.html 2
# https://sc.chinaz.com/tupian/qinglvtupian_3.html 3
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
if not os.path.exists('./站长素材'):
os.mkdir('./站长素材')
for index in range(1, 5):
if index == 1:
url = 'https://sc.chinaz.com/tupian/qinglvtupian.html'
else:
url = f'https://sc.chinaz.com/tupian/qinglvtupian_{str(index)}.html'
# 请求对象的定制
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
html = response.read().decode('utf-8')
# print(html)
# 数据解析
tree = etree.HTML(html)
div_list = tree.xpath('//div[@id="container"]/div')
for div in div_list:
name = div.xpath("./div/a/img/@alt")[0] # 图片名称
src = 'http:' + div.xpath('./div/a/img/@src')[0] # 图片链接
suffix = src.split('.')[-1] # 后缀
# print(src)
# 图片下载
urllib.request.urlretrieve(url=src, filename='./站长素材/' + name + '.' + suffix)
print(f'{name}-保存成功!')
print(f'*****************第{index}页,抓取完成!******************')
这里抓取要注意几个点:
1.在进行分页抓取时要观察每一页的url联系然后通过for循环抓取
2.headers的作用:他就是将我们用户进行一个ua伪装,防止被浏览器发现
3.os是一个模块,是用来操作文件文件夹的模块用于创建删除都可以
4.有时候我们下载过程中会出现报错的情况,我们可以在下载的代码块前面加一个错误捕获(就是try和excpet EXCEPTION)

最后感谢大家看到这里,可能文章也有很多不妥之处,希望大家多多提建议,大家一起学习一起进步,有问题也可以互相讨论,咱们评论区见!!!