(车载网络-读书笔记)Source Identification Using Signal Characteristics in Controller Area Networks
目录
摘要
动机和相关的工作
CAN的模式和帧的格式
之前的来源识别方法
本文方法的背景
本文方法有关的前人的工作
信号处理工具
实验结果
A.来源识别
1.基于MSE进行分离
2.基于卷积分离
3.基于平均值的分离
B.识别成功率
摘要
目前的汽车内的ECU(电子控制单元,类似于行车电脑)之间的互相连接都遵循的是CAN(Controller Area Networks)协议,这也是大多数汽车都遵循的事实协议。CAN协议有广播式发送信息和以ID为导向进行通信的特点,网络中每个节点对于接收到的信息的来源都是不清楚的,因此也很难进行来源识别。很多在CAN网络上的这方面的研究是在协议层采用加密的特点设计网络,这有时候不太可行,因为会增加通信和计算的开销,并且很难向后兼容。这篇文章提出的方法是对CAN总线上每个节点里的帧的独特的物理特性进行身份验证。也就是通过测量电压,过滤信号并检验均方误差和卷积的方式来分析这些帧,这就能帮助识别可能的发送者。
动机和相关的工作
CAN的模式和帧的格式
做这项工作的背景是汽车的网络发展的越来越复杂,而CAN这种广播式的总线在车内的通信上面越来越被发现很危险,这种通信方式缺乏来源识别,很容易遭受到攻击。CAN总线典型的模式就试图一这样子,有两根差分总线,有n个节点会连在总线上,这些节点都是能发送CAN数据帧的收发器。在这条线上传输的每个帧都是带着标识符(ID),这决定了它的优先级,另外还携带着64位的数据和15位的CRC码。
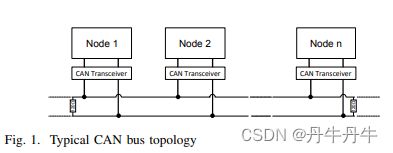
之前的来源识别方法
1.帧的格式表明了用确保加密的方法不可行,因为其需要在每个帧的这8比特中加入认证的标签和消息。2.另外如果添加独立的用于认证的帧就会加大总线的负载量,CAN的传输速度被限制在了1Mbps,在很多实际的场景的应用中,这已经达到上限了。3.Message Authentication Codes (MACs)也是一种用于消息认证的密码学的工具,但它需要128位,如果把它阶段然后放到通信的64位的消息中也是不太可能的。4.还有学者提的CAN+模式,把验证位藏在常规的CAN帧里面也还不太可行。还有一系列的方法,但是这些方法太局限,本文采用的是完全独立的方法,基于的是信号模式。
本文方法的背景
本文方法利用的是CAN网络的物理层还有很多实现上的自由可行性,所以很多制造商生产的收发器发送出来的信号并不是相同的,而且每个电子元件都有独特的物理特性,即使是同一个厂商制造的收发器生成的信号生成的信号也有不一样的物理特性,这也就有利于对发送信号的收发器的识别。
本文方法有关的前人的工作
在物理层安全这方面也有了一定的前人的工作,1.用射频指纹进行网络的入侵检测;2.物理层上用波束成形和人工噪声,保证在可能有人窃听的情况下能安全通信;3.用匹配滤波器帧的方法识别以太网卡...
信号处理工具
介绍一些本文方法用到的数学工具,主要是为了对识别发送消息的收发器进行更精细的分析。
1.低通滤波器:从CAN的帧中提取的特征要跟储存的指纹进行比较,下图里显示的就表明信号中是有很多噪声的,并且有很多是重叠的,简单的去比较两个信号不太可能。那么我们进行的第一步就是要过滤信号移除掉噪音;图中过滤前和过滤后分别在左右,图里面是三个收发器发送的字段的信号,可以看出来过滤前后都是有着很相似的行为特征,而且左图没经过滤的信号还有这大量的重叠。
那么本文用的低通滤波器就是来过滤信号的,并且这种基本的操作会在两个信号间产生一个明显的差异,不过这还不足够区分两个很相似的信号,就好像图中右边还是很难完全区分三个信号。

2.均方误差MSE:均方误差主要计算的是本身储存的信号指纹和要检验的信号指纹之间的一个均方误差。它的作用在于要检验的这个信号可以跟指定的CAN的ID储存的所有的指纹去进行比较验证,或者也可以跟所有的指纹的平均值去比较计算,如果这个正在接受检验的信号确实是CAN上的合法节点发送的,它就应该和对应存储的所有指纹或所有指纹的平均值之间有最小的均方误差。
3.卷积:信号处理的过程中很容易发生要比较的两个信号对不准的问题,如果信号没法完全对齐就影响实验结果。这个问题可以通过对比信号的卷积来缓解,也就是两个要比较的输入向量的长度是m和n,操作的结果是生成一个n+m-1长度的向量。我们这个例子中要对比的一对向量长度都是l,那输出的向量长度自然也就是2l-1。我们认为卷积向量的最大值代表了要验证的信号和参照的信号之间的相似性,因为最大值标志着是最佳对齐点。
实验结果
本文做的实验是在两个不同类型的设备产生的CAN帧上,USB-CAN适配器和嵌入式开发板。
A.来源识别
很明显不同的设备产生的信号是不同的,这不需要额外的处理就能显现。而对于同一种设备,也就是同一种收发器,发出的信号很相似,这就需要额外的处理了。
1.基于MSE进行分离
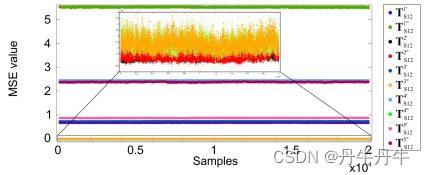
下图就是MSE的计算值,检验的信号是从USB-CAN的模块里发出的,一共10种信号,图中下部分的是红色的部分是第四种,就以它作为参考,可以从图中看出大部分的设备收发器发出的信号还是能与第4种区分开的,但是橘色的第6种和紫色的第1种跟第4种很接近,可以看到都有很大重叠部分。

上面那个是在USB-CAN上,而从选的5个嵌入式开发板的收发器发出的信号之间的对比,能从下图看出来也有非常相似的情况,5个开发板每个上面都有2个收发器,因此也是10种信号,而从图中可以看出来有三个收发器产生的信号非常相似,容易混淆。
2.基于卷积分离
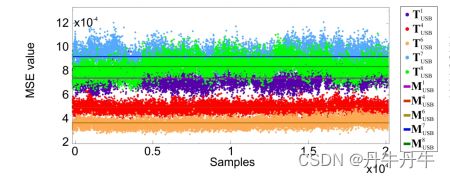
下图展示的就是使用卷积的方式在相同的数据集上进行操作后的结果,可以明显地看出来在在10个USB板的设备收发器上,第4个和第6个有很大重叠,而第7个也覆盖了第4个的一小部分,剩下其他的都很容易区分。当把卷积操作应用到开发板的信号上去的时候,结果也就是图6所示的,还是有3个收发器产生的信号难以区分。

3.基于平均值的分离
根据上面的一些操作分析,在一些情况下,收集的单一的一个特征没法准确地确定到底是哪个收发器发出的信号,那么为了提高准确性就要选很多的特征,那么就需要计算基于多种特征的平均值并与相同方式获取的指纹进行比较,并将结果画成一条平均线,每组收集到的特征的平均值化成一条线画在图中。
B.识别成功率
由于使用MSE的识别成功率和使用卷积很相似,所以就采用MSE的结果,而基于均值的方法又需要采集太多信号,所以很麻烦也不切合实际。
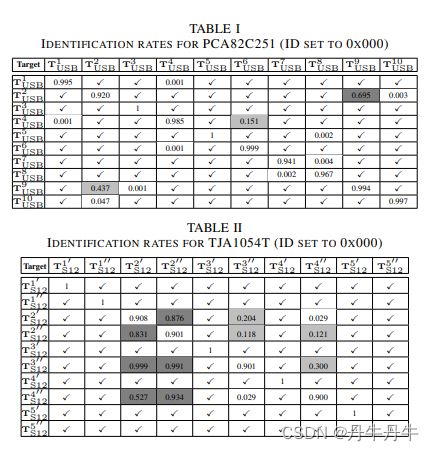
表一表二呈现的就是一个在采用MSE的检测的情况下,对检测精度的测量,每个格子包括的是一个收发器和指定的目标收发器之间检测的结果,每行的第一个格子是目标收发器,所以表格的意思也就是打对勾的表示两种收发器之间不存在混淆的情况,而有值的就是这个收发器被当作目标收发器的可能性。那么要设定一个阈值,也就是大于多少就会造成可能比较严重的后果。
当然也可以从表格中看得出来表一的这组的收发器更容易区分,最大的误检率69.5%,也就是T9被认作T2的可能性。而表二的这组就严重得多,有些信号可能太相似了没法正确区分。
表三则是通过改变分配标识符ID的方式后的一个识别的结果,也就是为特定的收发器巧妙地分配ID就有可能产生很高的识别率。这也是一种可能的改善方式。
