GBDT模型
GBDT(Gradient Boosting Decision Tree,梯度提升树)属于一种有监督的集成学习算法,与前面几章介绍的监督算法类似,同样可用于分类问题的识别和预测问题的解决。该集成算法体现了三方面的优势,分别是提升Boosting、梯度Gradient和决策树Decision Tree。
“提升”是指将多个弱分类器通过线下组合实现强分类器的过程;
“梯度”是指算法在Boosting过程中求解损失函数时增强了灵活性和便捷性,
“决策树”是指算法所使用的弱分类器为CART决策树,该决策树具有简单直观、通俗易懂的特性。
单棵决策树和随机森林相关的知识点以及两者的差异,在可信度和稳定
性上,通常随机森林要比单棵决策树更强。随机森林实质上是利用Bootstrap抽样技术生成多个数据集,然后通过这些数据集构造多棵决策树,进而运用投票或平均的思想实现分类和预测问题的解决。但是这样的随机性会导致树与树之间并没有太多的相关性,往往会导致随机森林算法在拟合效果上遇到瓶颈,为了解决这个问题,Friedman等人提出了“提升”的概念,即通
过改变样本点的权值和各个弱分类器的权重,并将这些弱分类器完成组合,实现预测准确性的突破。更进一步,为了使提升算法在求解损失函数时更加容易和方便,Friedman又提出了梯度提升算法,即GBDT。
GBDT模型对数据类型不做任何限制,既可以是连续的数值型,也可以是离散的字符型(但在Python的落地过程中,需要将字符型变量做数值化处理或哑变量处理)。相对于SVM模型来说,较少参数的GBDT具有更高的准确率和更少的运算时间,GBDT模型在面对异常数据时具有更强的稳定性
提升树算法
AdaBoost算法
sklearn的子模块ensemble,并从中调入AdaBoostClassifier类或AdaBoostRegressor类,其中AdaBoostClassifier用于解决分类问题,AdaBoostRegressor则用于解决预测问题
AdaBoostClassifier(base_estimator=None, n_estimators=50,
learning_rate=1.0, algorithm='SAMME.R', random_state=None)
AdaBoostRegressor(base_estimator=None, n_estimators=50,
learning_rate=1.0, loss='linear', random_state=None)
base_estimator:用于指定提升算法所应用的基础分类器,默认为分类决策树(CART),也可以是其他基础分类器,但分类器必须支持带样本权重的学习,如神经网络。
n_estimators:用于指定基础分类器的数量,默认为50个,当模型在训练数据集中得到完美的拟合后,可以提前结束算法,不一定非得构建完指定个数的基础分类器。
learning_rate:用于指定模型迭代的学习率或步长,即对应的提升模型F(x)可以表示为F(x)=Fm-1(x)+υαmfm(x),其中的υ就是该参数的指定值,默认值为1;对于较小的学习率υ而言,则需要迭代更多次的基础分类器,通常情况下需要利用交叉验证法确定合理的基础分类器个数和学习率。
algorithm:用于指定AdaBoostClassifier分类器的算法,默认为'SAMME.R',也可以使用'SAMME';使用'SAMME.R'时,基础模型必须能够计算类别的概率值;一般而言,'SAMME.R'算法相比于'SAMME'算法,收敛更快、误差更小、迭代数量更少。
loss:用于指定AdaBoostRegressor回归提升树的损失函数,可以是'linear',表示使用线性损失函数;也可以是'square',表示使用平方损失函数;还可以是'exponential',表示使用指数损失函数;该参数的默认值为'linear'。
random_state:用于指定随机数生成器的种子。
需要说明的是,不管是提升分类器还是提升回归器,如果基础分类器使用默认的CART决策树,都可以调整决策树的最大特征数、树的深度、内部节点的最少样本量和叶子节点的最少样本量等;对于回归提升树AdaBoostRegressor而言,在不同的损失函数中,第k个基础分类器样本点损失值的计算也不相同。
提升树之Adaboost算法的应用
本节中关于提升树的应用实战将以信用卡违约数据为例,该数据集来源于UCI网站,一共包含30 000条记录和25个变量,其中自变量包含客户的性别、受教育水平、年龄、婚姻状况、信用额度、6个月的历史还款状态、账单金额以及还款金额,因变量y表示用户在下个月的信用卡还款中是否存在违约的情况(1表示违约,0表示不违约)。首先绘制饼图,查看因变量中各类别
的比例差异
# 导入第三方包
import pandas as pd
import matplotlib.pyplot as plt
# 读入数据
default = pd.read_excel(r'default of credit card.xls')
# 数据集中是否违约的客户比例
# 为确保绘制的饼图为圆形,需执行如下代码
plt.axes(aspect = 'equal')
# 中文乱码和坐标轴负号的处理
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 统计客户是否违约的频数
counts = default.y.value_counts()
# 绘制饼图
plt.pie(x = counts, # 绘图数据
labels=pd.Series(counts.index).map({0:'不违约',1:'违约'}), # 添加文字标签
autopct='%.1f%%' # 设置百分比的格式,这里保留一位小数
)
# 显示图形
plt.show()
default.head()
out:
ID LIMIT_BAL SEX EDUCATION MARRIAGE AGE PAY_0 PAY_2 PAY_3 PAY_4 ... BILL_AMT4 BILL_AMT5 BILL_AMT6 PAY_AMT1 PAY_AMT2 PAY_AMT3 PAY_AMT4 PAY_AMT5 PAY_AMT6 y
0 1 20000 2 2 1 24 2 2 -1 -1 ... 0 0 0 0 689 0 0 0 0 1
1 2 120000 2 2 2 26 -1 2 0 0 ... 3272 3455 3261 0 1000 1000 1000 0 2000 1
2 3 90000 2 2 2 34 0 0 0 0 ... 14331 14948 15549 1518 1500 1000 1000 1000 5000 0
3 4 50000 2 2 1 37 0 0 0 0 ... 28314 28959 29547 2000 2019 1200 1100 1069 1000 0
4 5 50000 1 2 1 57 -1 0 -1 0 ... 20940 19146 19131 2000 36681 10000 9000 689 679 0
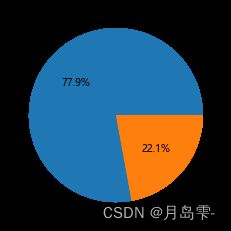
数据集中违约客户占比为22.1%,不违约客户占比为77.9%,总体来说,两
个类别的比例不算失衡(一般而言,如果两个类别比例为9:1,则认为失衡;如果比例为99:1,则认为严重失衡)。接下来,基于这样的数据构建AdaBoost模型
# 将数据集拆分为训练集和测试集
# 导入第三方包
from sklearn import model_selection
from sklearn import ensemble
from sklearn import metrics
# 排除数据集中的ID变量和因变量,剩余的数据用作自变量X
X = default.drop(['ID','y'], axis = 1)
y = default.y
# 数据拆分
X_train,X_test,y_train,y_test = model_selection.train_test_split(X,y,test_size = 0.25, random_state = 1234)
# 构建AdaBoost算法的类
AdaBoost1 = ensemble.AdaBoostClassifier()
# 算法在训练数据集上的拟合
AdaBoost1.fit(X_train,y_train)
# 算法在测试数据集上的预测
pred1 = AdaBoost1.predict(X_test)
# 返回模型的预测效果
print('模型的准确率为:\n',metrics.accuracy_score(y_test, pred1))
print('模型的评估报告:\n',metrics.classification_report(y_test, pred1))
out:
模型的准确率为:
0.8125333333333333
模型的评估报告:
precision recall f1-score support
0 0.83 0.96 0.89 5800
1 0.68 0.32 0.44 1700
accuracy 0.81 7500
macro avg 0.75 0.64 0.66 7500
weighted avg 0.80 0.81 0.79 7500
在调用AdaBoost类构建提升树算法时,使用了“类”中的默认参数值,返回
的模型准确率为81.25%。并且预测客户违约(因变量y取1)的精准率为68%、覆盖率为32%;预测客户不违约(因变量y取0)的精准率为83%、覆盖率为96%。可以基于如上的预测结果,绘制算法在测试数据集上的ROC曲线
# 计算客户违约的概率值,用于生成ROC曲线的数据
y_score = AdaBoost1.predict_proba(X_test)[:,1]
fpr,tpr,threshold = metrics.roc_curve(y_test, y_score)
# 计算AUC的值
roc_auc = metrics.auc(fpr,tpr)
# 绘制面积图
plt.stackplot(fpr, tpr, color='steelblue', alpha = 0.5, edgecolor = 'black')
# 添加边际线
plt.plot(fpr, tpr, color='black', lw = 1)
# 添加对角线
plt.plot([0,1],[0,1], color = 'red', linestyle = '--')
# 添加文本信息
plt.text(0.5,0.3,'ROC curve (area = %0.2f)' % roc_auc)
# 添加x轴与y轴标签
plt.xlabel('1-Specificity')
plt.ylabel('Sensitivity')
# 显示图形
plt.show()
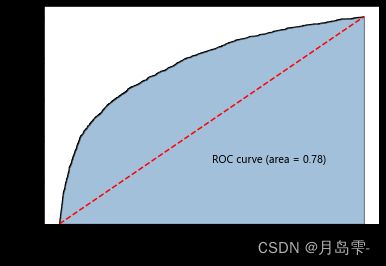
ROC曲线下的面积为0.78,接近于0.8,可知AdaBoost算法在该数据集上的
表现并不是特别突出。试问是否可以通过模型参数的调整改善模型的预测准确率呢?接下来通过交叉验证方法,选择相对合理的参数值。
在参数调优之前,基于如上的模型寻找影响客户是否违约的重要因素,进而做一次特征筛选
# 自变量的重要性排序
importance = pd.Series(AdaBoost1.feature_importances_, index = X.columns)
importance.sort_values().plot(kind = 'barh')
plt.show()
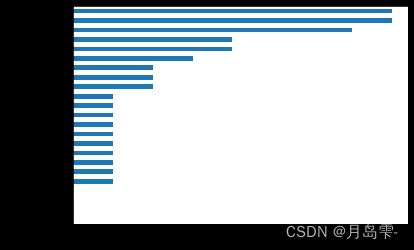
可以一目了然地发现重要的自变量,如客户在近三期的支付状态(PAY_0,
PAY_1,PAY_2)、支付金额(PAY_AMT1、PAY_AMT2、PAY_AMT3)、账单金额(BILL_AMT1、BILL_AMT2、BILL_AMT3)和信用额度(LIMIT_BAL);而客户的性别、受教育水平、年龄、婚姻状况、更早期的支付状态、支付金额等并不是很重要。接下来就基于这些重要的自变量重新建模,并使用交叉验证方法获得最佳的参数组合
# 取出重要性比较高的自变量建模
predictors = list(importance[importance>0.02].index)
predictors
# 通过网格搜索法选择基础模型所对应的合理参数组合
# 导入第三方包
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
max_depth = [3,4,5,6]
params1 = {'base_estimator__max_depth':max_depth}
base_model = GridSearchCV(estimator = ensemble.AdaBoostClassifier(base_estimator = DecisionTreeClassifier()),
param_grid= params1, scoring = 'roc_auc', cv = 5, n_jobs = 4, verbose = 1)
base_model.fit(X_train[predictors],y_train)
# 返回参数的最佳组合和对应AUC值
base_model.best_params_, base_model.best_score_
out:
Fitting 5 folds for each of 4 candidates, totalling 20 fits
({'base_estimator__max_depth': 3}, 0.7411914674699375)
经过5重交叉验证的训练和测试后,对于基础模型CART决策树来说,最大
的树深度选择为3层比较合理。需要说明的是,在对AdaBoost算法做交叉验证时,有两层参数需要调优,一个是基础模型的参数,即DecisionTreeClassifier类;另一个是提升树模型的参数,即AdaBoostClassifier类。在对基础模型调参时,参数字典params1中的键必须
以“base_estimator__”开头,因为该参数是嵌在AdaBoostClassifier类下的DecisionTreeClassifier类中。
如上是对基础模型CART决策树做的参数调优过程,还需要基于这个结果对AdaBoost算法进行参数调优,代码如下:
# 通过网格搜索法选择提升树的合理参数组合
# 导入第三方包
from sklearn.model_selection import GridSearchCV
n_estimators = [100,200,300]
learning_rate = [0.01,0.05,0.1,0.2]
params2 = {'n_estimators':n_estimators,'learning_rate':learning_rate}
adaboost = GridSearchCV(estimator = ensemble.AdaBoostClassifier(base_estimator = DecisionTreeClassifier(max_depth = 3)),
param_grid= params2, scoring = 'roc_auc', cv = 5, n_jobs = 4, verbose = 1)
adaboost.fit(X_train[predictors] ,y_train)
# 返回参数的最佳组合和对应AUC值
adaboost.best_params_, adaboost.best_score_
Fitting 5 folds for each of 12 candidates, totalling 60 fits
({'learning_rate': 0.05, 'n_estimators': 100}, 0.7693743224892777)
经过5重交叉验证后,得知AdaBoost算法的最佳基础模型个数为300、学习
率为0.01。到目前为止,参数调优过程就结束了(仅仅涉及基础模型CART决策树的深度、提升树中包含的基础模型个数和学习率)。如果还需探索其他更多的参数值,只需对如上代码稍做修改即可(修改params1和params2)。基于如上的调参结果重新构造AdaBoost模型,并检验算法在测试数据集上的预测效果,代码如下
# 使用最佳的参数组合构建AdaBoost模型
AdaBoost2 = ensemble.AdaBoostClassifier(base_estimator = DecisionTreeClassifier(max_depth = 3),
n_estimators = 300, learning_rate = 0.01)
# 算法在训练数据集上的拟合
AdaBoost2.fit(X_train[predictors],y_train)
# 算法在测试数据集上的预测
pred2 = AdaBoost2.predict(X_test[predictors])
# 返回模型的预测效果
print('模型的准确率为:\n',metrics.accuracy_score(y_test, pred2))
print('模型的评估报告:\n',metrics.classification_report(y_test, pred2))
模型的准确率为:
0.816
模型的评估报告:
precision recall f1-score support
0 0.83 0.96 0.89 5800
1 0.69 0.34 0.45 1700
accuracy 0.82 7500
macro avg 0.76 0.65 0.67 7500
weighted avg 0.80 0.82 0.79 7500
如上结果所示,经过调优后,模型在测试数据集上的预测准确率为81.6%,相比于默认参数的AdaBoost模型,准确率仅提高0.35%。算法处理该数据集时,模型的准确率遇到了瓶颈,读者不妨对比测试其他模型,如随机森
林、SVM等。
GBDT算法
GradientBoostingClassifier(loss='deviance', learning_rate=0.1, n_estimators=100, subsample=1.0,
criterion='friedman_mse', min_samples_split=2,
min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_depth=3,
min_impurity_decrease=0.0, min_impurity_split=None, init=None,
random_state=None, max_features=None, verbose=0,
max_leaf_nodes=None, warm_start=False, presort='auto’)
GradientBoostingRegressor(loss='ls', learning_rate=0.1, n_estimators=100, subsample=1.0,
criterion='friedman_mse', min_samples_split=2,
min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_depth=3,
min_impurity_decrease=0.0, min_impurity_split=None, init=None,
random_state=None, max_features=None, alpha=0.9, verbose=0,
max_leaf_nodes=None, warm_start=False, presort='auto’)
loss:用于指定GBDT算法的损失函数,对于分类的GBDT,可以选
择'deviance'和'exponential',分别表示对数似然损失函数和指数损失函数;对于预测的
GBDT,可以选择'ls' 'lad' 'huber'和'quantile',分别表示平方损失函数、绝对值损失函数、
Huber损失函数(前两种损失函数的结合,当误差较小时,使用平方损失,否则使用绝对值损失,误差大小的度量可使用alpha参数指定)和分位数回归损失函数(需通过alpha参数设定分位数)。
learning_rate:用于指定模型迭代的学习率或步长,即对应的梯度提升模型F(x)可以表示为FM(x)=FM-1(x)+υfm(x):,其中的υ就是该参数的指定值,默认值为0.1;对于较小的学习率υ而言,则需要迭代更多次的基础分类器,通常情况下需要利用交叉验证法确定合理的基础模型的个数和学习率。
n_estimators:用于指定基础模型的数量,默认为100个。
subsample:用于指定构建基础模型所使用的抽样比例,默认为1,表示使用原始数据建每一个基础模型;当抽样比例小于1时,表示构建随机梯度提升树模型,通常会导致模型的方差降低,偏差提高。
criterion:用于指定分割质量的度量,默认为'friedman_mse',表示使用Friedman均方误差,还可以使用'mse'和'mae',分别表示均方误差和绝对误差。
min_samples_split:用于指定每个基础模型的根节点或中间节点能够继续分割的最小样本量,默认为2。
min_samples_leaf:用于指定每个基础模型的叶节点所包含的最小样本量,默认为1。
min_weight_fraction_leaf:用于指定每个基础模型叶节点最小的样本权重,默认为0,表示不考虑叶节点的样本权值。
max_depth:用于指定每个基础模型所包含的最大深度,默认为3层。
min_impurity_decrease:用于指定每个基础模型的节点是否继续分割的最小不纯度值,默认为0;如果不纯度超过指定的阈值,则节点需要分割,否则不分割。
min_impurity_split:该参数同min_impurity_decrease参数,在sklearn的0.21版本及之后版本将删除。
init:用于指定初始的基础模型,用于执行初始的分类或预测。
random_state:用于指定随机数生成器的种子,默认为None,表示使用默认的随机数生成器。
max_features:用于指定每个基础模型所包含的最多分割字段数,默认为None,表示分割时使用所有的字段;如果为具体的整数,则考虑使用对应的分割字段数;如果为0~1的浮点数,则考虑对应百分比的字段个数;如果为'sqrt',则表示最多考虑 个字段,与指定'auto'效果一致;如果为'log2',则表示最多使用log2P个字段。其中,P表示数据集所有自变量的个数。
verbose:用于指定GBDT算法在计算过程中是否输出日志信息,默认为0,表示不输出。
alpha:当loss参数为'huber'或'quantile'时,该参数有效,分别用于指定误差的阈值和分位数。
max_leaf_nodes:用于指定每个基础模型最大的叶节点个数,默认为None,表示对叶节点个数不做任何限制。
warm_start:bool类型参数,表示是否使用上一轮的训练结果,默认为False。
presort:bool类型参数,表示是否在构建基础模型时对数据进行预排序(用于快速寻找最佳分割点),默认为'auto'。当数据集比较密集时,该参数自动对数据集做预排序;当数据集比较稀疏时,则无须预排序;对于稀疏数据来说,设置该参数为True时,反而会提高模型的错误率。
GBDT算法的应用
本节的项目实战部分仍然使用上一节中所介绍的客户信用卡违约数据,并对比GBDT算法和AdaBoost算法在该数据集上的效果差异。首先,利用交叉验证方法,测试GBDT算法各参数值的效果,并从中挑选出最佳的参数组合
# 运用网格搜索法选择梯度提升树的合理参数组合
learning_rate = [0.01,0.05,0.1,0.2]
n_estimators = [100,300,500]
max_depth = [3,4,5,6]
params = {'learning_rate':learning_rate,'n_estimators':n_estimators,'max_depth':max_depth}
gbdt_grid = GridSearchCV(estimator = ensemble.GradientBoostingClassifier(),
param_grid= params, scoring = 'roc_auc', cv = 5, n_jobs = 4, verbose = 1)
gbdt_grid.fit(X_train[predictors],y_train)
# 返回参数的最佳组合和对应AUC值
gbdt_grid.best_params_, gbdt_grid.best_score_
out:
Fitting 5 folds for each of 48 candidates, totalling 240 fits
({'learning_rate': 0.1, 'max_depth': 4, 'n_estimators': 100},
0.774450061929645)
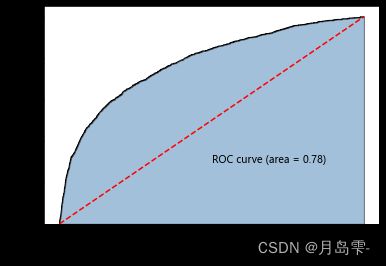
如上结果所示,运用5重交叉验证方法对基础模型树的深度、基础模型个数以及提升树模型的学习率三个参数进行调优,得到的最佳组合值为5、100和0.05。而且验证后的最佳AUC值为0.77,进而利用这样的参数组合,对测试数据集进行预测
# 基于最佳参数组合的GBDT模型,对测试数据集进行预测
pred = gbdt_grid.predict(X_test[predictors])
# 返回模型的预测效果
print('模型的准确率为:\n',metrics.accuracy_score(y_test, pred))
print('模型的评估报告:\n',metrics.classification_report(y_test, pred))
out:
模型的准确率为:
0.8133333333333334
模型的评估报告:
precision recall f1-score support
0 0.83 0.95 0.89 5800
1 0.67 0.35 0.46 1700
accuracy 0.81 7500
macro avg 0.75 0.65 0.67 7500
weighted avg 0.80 0.81 0.79 7500
如上结果所示,GBDT模型在测试数据集上的预测效果与AdaBoost算法基本一致,进而可以说明GBDT算法采用一阶导函数的值近似残差是合理的,并且这种近似功能也提升了AdaBoost算法求解目标函数时的便捷性。基于GBDT算法的预测结果,也可以绘制一幅ROC曲线图
# 计算违约客户的概率值,用于生成ROC曲线的数据
y_score = gbdt_grid.predict_proba(X_test[predictors])[:,1]
fpr,tpr,threshold = metrics.roc_curve(y_test, y_score)
# 计算AUC的值
roc_auc = metrics.auc(fpr,tpr)
# 绘制面积图
plt.stackplot(fpr, tpr, color='steelblue', alpha = 0.5, edgecolor = 'black')
# 添加边际线
plt.plot(fpr, tpr, color='black', lw = 1)
# 添加对角线
plt.plot([0,1],[0,1], color = 'red', linestyle = '--')
# 添加文本信息
plt.text(0.5,0.3,'ROC curve (area = %0.2f)' % roc_auc)
# 添加x轴与y轴标签
plt.xlabel('1-Specificity')
plt.ylabel('Sensitivity')
# 显示图形
plt.show()
非平衡数据
在实际应用中,可能会碰到一种比较头疼的问题,那就是分类问题中类别型的因变量可能存在严重的偏倚,即类别之间的比例严重失调。如欺诈问题中,欺诈类观测在样本集中毕竟占少数;客户流失问题中,忠实的客户往往也是占很少一部分;在某营销活动的响应问题中,真正参与活动的客户也同样只是少部分
最简单粗暴的办法就是构造1:1的数据,要么将多的那一类砍掉一部分(欠采样),要么将少的那一类进行Bootstrap抽样(过采样)。但这样做会存
在问题,对于第一种方法,砍掉的数据会导致某些隐含信息的丢失;而第二种方法中,有放回的抽样形成的简单复制,又会使模型产生过拟合。
为了解决数据的非平衡问题,2002年Chawla提出了SMOTE算法,即合成少数过采样技术,它是基于随机过采样算法的一种改进方案。该技术是目前处理非平衡数据的常用手段,并受到学术界和工业界的一致认同,接下来简单描述一下该算法的理论思想。SMOTE算法的基本思想就是对少数类别样本进行分析和模拟,并将人工模拟的新样本添加到数据集中,进而使原始数据中的类别不再严重失衡。该算法的模拟过程采用了KNN技术,模拟生成新样本的步骤如下:
(1)采样最邻近算法,计算出每个少数类样本的K个近邻。
(2)从K个近邻中随机挑选N个样本进行随机线性插值。
(3)构造新的少数类样本。
(4)将新样本与原数据合成,产生新的训练集。
SMOTE算法的
SMOTE(ratio='auto', random_state=None, k_neighbors=5, m_neighbors=10,
out_step=0.5, kind='regular', svm_estimator=None, n_jobs=1)
ratio:用于指定重抽样的比例,如果指定字符型的值,可以是'minority'(表示对少数类别的样本进行抽样)、'majority'(表示对多数类别的样本进行抽样)、'not minority'(表示采用欠采样方法)、'all'(表示采用过采样方法),默认为'auto',等同于'all'和'not minority'。如果指定字典型的值,其中键为各个类别标签,值为类别下的样本量。
random_state:用于指定随机数生成器的种子,默认为None,表示使用默认的随机数生成器。
k_neighbors:指定近邻个数,默认为5个。
m_neighbors:指定从近邻样本中随机挑选的样本个数,默认为10个。
kind:用于指定SMOTE算法在生成新样本时所使用的选项,默认为'regular',表示对少数类别的样本进行随机采样,也可以是'borderline1' 'borderline2'和'svm'。
svm_estimator:用于指定SVM分类器,默认为sklearn.svm.SVC,该参数的目的是利用支持向量机分类器生成支持向量,然后生成新的少数类别的样本。
n_jobs:用于指定SMOTE算法在过采样时所需的CPU数量,默认为1表示仅使用1个CPU运行算法,即不使用并行运算功能。
XGBoost算法
XGBoost是由传统的GBDT模型发展而来的,在上一节中,GBDT模型在求解最优化问题时应用了一阶导技术,而XGBoost则使用损失函数的一阶和二阶导,更神奇的是用户可以自定义损失函数,只要损失函数可一阶和二阶求导。除此,XGBoost算法相比于GBDT算法还有其他优点,例如支持并行计算,大大提高算法的运行效率;XGBoost在损失函数中加入了正则项,用来控制模型的复杂度,进而可以防止模型的过拟合;XGBoost除了支持CART基础模型,还支持线性基础模型;XGBoost采用了随机森林的思想,对字段进行抽样,既可以防止过拟合,也可以降低模型的计算量。
XGBClassifier(max_depth=3, learning_rate=0.1, n_estimators=100, silent=True,
objective='binary:logistic', booster='gbtree', n_jobs=1, nthread=None,
gamma=0, min_child_weight=1, max_delta_step=0, subsample=1,
colsample_bytree=1, colsample_bylevel=1, reg_alpha=0, reg_lambda=1,
scale_pos_weight=1, base_score=0.5, random_state=0, seed=None, missing=None)
XGBRegressor(max_depth=3, learning_rate=0.1, n_estimators=100, silent=True,
objective='reg:linear', booster='gbtree', n_jobs=1, nthread=None,
gamma=0, min_child_weight=1, max_delta_step=0, subsample=1,
colsample_bytree=1, colsample_bylevel=1, reg_alpha=0, reg_lambda=1,
scale_pos_weight=1, base_score=0.5, random_state=0, seed=None, missing=None)
max_depth:用于指定每个基础模型所包含的最大深度,默认为3层。
learning_rate:用于指定模型迭代的学习率或步长,默认为0.1,即对应的梯度提升模型FT(x)可以表示为FT(x)=FT-1(x)+υft(x):,其中的υ就是该参数的指定值,默认值为1;对于较小的学习率υ而言,则需要迭代更多次的基础分类器,通常情况下需要利用交叉验证法确定合理的基础模型的个数和学习率。
n_estimators:用于指定基础模型的数量,默认为100个。
silent:bool类型参数,是否输出算法运行过程中的日志信息,默认为True。
objective:用于指定目标函数中的损失函数类型,对于分类型的XGBoost算法,默认的损失函数为二分类的Logistic损失(模型返回概率值),也可以是'multi:softmax',表示用于处理多分类的损失函数(模型返回类别值),还可以是'multi:softprob',与'multi:softmax'相同,所不同的是模型返回各类别对应的概率值;对于预测型的XGBoost算法,默认的损失函数为线性回归损失。
booster:用于指定基础模型的类型,默认为'gbtree',即CART模型,也可以是'gblinear',表示基础模型为线性模型。
n_jobs:用于指定XGBoost算法在并行计算时所需的CPU数量,默认为1表示仅使用1个CPU运行算法,即不使用并行运算功能。
nthread:用于指定XGBoost算法在运行时所使用的线程数,默认为None,表示使用计算机最大可能的线程数。
gamma:用于指定节点分割所需的最小损失函数下降值,即增益值Gain的阈值,默认为0。
min_child_weight:用于指定叶子节点中各样本点二阶导之和的最小值,即Hj的最小值,默认为1,该参数的值越小,模型越容易过拟合。
max_delta_step:用于指定模型在更新过程中的步长,如果为0,表示没有约束;如果取值为某个较小的正数,就会导致模型更加保守。
subsample:用于指定构建基础模型所使用的抽样比例,默认为1,表示使用原始数据构建每一个基础模型;当抽样比例小于1时,表示构建随机梯度提升树模型,通常会导致模型的方差降低,偏差提高。
colsample_bytree:用于指定每个基础模型所需的采样字段比例,默认为1,表示使用原始数据的所有字段。
colsample_bylevel:用于指定每个基础模型在节点分割时所需的采样字段比例,默认为1,表示使用原始数据的所有字段。
reg_alpha:用于指定L1正则项的系数,默认为0。
reg_lambda:用于指定L2正则项的系数,默认为1。
scale_pos_weight:当各类别样本的比例十分不平衡时,通过设定该参数设定为一个正值,可以使算法更快收敛。
base_score:用于指定所有样本的初始化预测得分,默认为0.5。
random_state:用于指定随机数生成器的种子,默认为0,表示使用默认的随机数生成器。
seed:同random_state参数。
missing:用于指定缺失值的表示方法,默认为None,表示NaN即为默认值。
XGBoost算法的应用
本节的应用实战部分将以信用卡欺诈数据为例,该数据集来源于Kaggle网站,一共包含284 807条记录和25个变量,其中因变量Class表示用户在交易中是否发生欺诈行为(1表示欺诈交易,0表示正常交易)。由于数据中涉及敏感信息,已将原始数据做了主成分分析(PCA)处理,一共包含28个主成分。此外,原始数据中仅包含两个变量没有做PCA处理,即“Time”和“Amount”,分别表示交易时间间隔和交易金额。首先,需要探索一下因变量Class中各类别的比例差异,查看是否存在不平衡状态
# 读入数据
creditcard = pd.read_csv(r'creditcard.csv')
Time V1 V2 V3 V4 V5 V6 V7 V8 V9 ... V21 V22 V23 V24 V25 V26 V27 V28 Amount Class
0 0.0 -1.359807 -0.072781 2.536347 1.378155 -0.338321 0.462388 0.239599 0.098698 0.363787 ... -0.018307 0.277838 -0.110474 0.066928 0.128539 -0.189115 0.133558 -0.021053 149.62 0
1 0.0 1.191857 0.266151 0.166480 0.448154 0.060018 -0.082361 -0.078803 0.085102 -0.255425 ... -0.225775 -0.638672 0.101288 -0.339846 0.167170 0.125895 -0.008983 0.014724 2.69 0
2 1.0 -1.358354 -1.340163 1.773209 0.379780 -0.503198 1.800499 0.791461 0.247676 -1.514654 ... 0.247998 0.771679 0.909412 -0.689281 -0.327642 -0.139097 -0.055353 -0.059752 378.66 0
3 1.0 -0.966272 -0.185226 1.792993 -0.863291 -0.010309 1.247203 0.237609 0.377436 -1.387024 ... -0.108300 0.005274 -0.190321 -1.175575 0.647376 -0.221929 0.062723 0.061458 123.50 0
4 2.0 -1.158233 0.877737 1.548718 0.403034 -0.407193 0.095921 0.592941 -0.270533 0.817739 ... -0.009431 0.798278 -0.137458 0.141267 -0.206010 0.502292 0.219422 0.215153 69.99 0
# 为确保绘制的饼图为圆形,需执行如下代码
plt.axes(aspect = 'equal')
# 统计交易是否为欺诈的频数
counts = creditcard.Class.value_counts()
# 绘制饼图
plt.pie(x = counts, # 绘图数据
labels=pd.Series(counts.index).map({0:'正常',1:'欺诈'}), # 添加文字标签
autopct='%.2f%%' # 设置百分比的格式,这里保留一位小数
)
# 显示图形
plt.show()
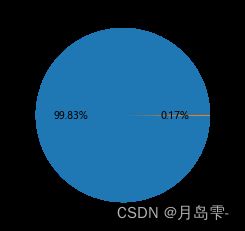
在284 807条信用卡交易中,欺诈交易仅占0.17%,两个类别的比例存在严
重的不平衡现象。对于这样的数据,如果直接拿来建模,效果一定会非常差,因为模型的准确率会偏向于多数类别的样本。换句话说,即使不建模,对于这样的二元问题,正确猜测某条交易为正常交易的概率值都是99.83%,而正确猜测交易为欺诈的概率几乎为0。试问是否可以通过建模手段,提高欺诈交易的预测准确率,这里不妨使用XGBoost算法对数据建模。建模之前,需要将不平衡数据通过SMOTE算法转换为相对平衡的数据,代码如下
# 将数据拆分为训练集和测试集
# 删除自变量中的Time变量
X = creditcard.drop(['Time','Class'], axis = 1)
y = creditcard.Class
# 数据拆分
X_train,X_test,y_train,y_test = model_selection.train_test_split(X,y,test_size = 0.3, random_state = 1234)
# 导入第三方包
from imblearn.over_sampling import SMOTE
# 运用SMOTE算法实现训练数据集的平衡
over_samples = SMOTE(random_state=1234)
over_samples_X,over_samples_y = over_samples.fit_resample(X_train, y_train)
#over_samples_X, over_samples_y = over_samples.fit_sample(X_train.values,y_train.values.ravel())
# 重抽样前的类别比例
print(y_train.value_counts()/len(y_train))
# 重抽样后的类别比例
print(pd.Series(over_samples_y).value_counts()/len(over_samples_y))
0 0.998239
1 0.001761
Name: Class, dtype: float64
0 0.5
1 0.5
Name: Class, dtype: float64
首先将数据集拆分为训练集和测试集,并运用训练数据集构建XGBoost模
型,其中测试数据集占30%的比重。由于训练数据集中因变量Class对应的类别存在严重的不平衡,即打印结果中欺诈交易占0.175%、正常交易占99.825%,所以需要使用SMOTE算法对其做平衡处理。如上结果所示,经SMOTE算法重抽样后,两个类别的比例达到平衡。接下来,利用重抽样后的数据构建XGBoost模型,
# 导入第三方包
import xgboost
import numpy as np
# 构建XGBoost分类器
xgboost1 = xgboost.XGBClassifier()
# 使用重抽样后的数据,对其建模
xgboost1.fit(over_samples_X,over_samples_y)
# 将模型运用到测试数据集中
resample_pred = xgboost1.predict(np.array(X_test))
# 返回模型的预测效果
print('模型的准确率为:\n',metrics.accuracy_score(y_test, resample_pred))
print('模型的评估报告:\n',metrics.classification_report(y_test, resample_pred))
模型的准确率为:
0.9992977774656788
模型的评估报告:
precision recall f1-score support
0 1.00 1.00 1.00 85302
1 0.78 0.81 0.79 141
accuracy 1.00 85443
macro avg 0.89 0.90 0.90 85443
weighted avg 1.00 1.00 1.00 85443
如上结果所示,经过重抽样之后计算的模型在测试数据集上的表现非常优秀,模型的预测准确率超过99%,而且模型对欺诈交易的覆盖率高达88%(即正确预测为欺诈的交易量/实际为欺诈的交易量),对正常交易的覆盖率高达99%。如上的模型结果是基于默认参数的计算,读者可以进一步利用交叉验证方法获得更佳的参数组合,进而可以提升模型的预测效果。接下来,可以运用ROC曲线验证模型在测试数据集上的表现,代码如下
# 计算欺诈交易的概率值,用于生成ROC曲线的数据
y_score = xgboost1.predict_proba(np.array(X_test))[:,1]
fpr,tpr,threshold = metrics.roc_curve(y_test, y_score)
# 计算AUC的值
roc_auc = metrics.auc(fpr,tpr)
# 绘制面积图
plt.stackplot(fpr, tpr, color='steelblue', alpha = 0.5, edgecolor = 'black')
# 添加边际线
plt.plot(fpr, tpr, color='black', lw = 1)
# 添加对角线
plt.plot([0,1],[0,1], color = 'red', linestyle = '--')
# 添加文本信息
plt.text(0.5,0.3,'ROC curve (area = %0.2f)' % roc_auc)
# 添加x轴与y轴标签
plt.xlabel('1-Specificity')
plt.ylabel('Sensitivity')
# 显示图形
plt.show()
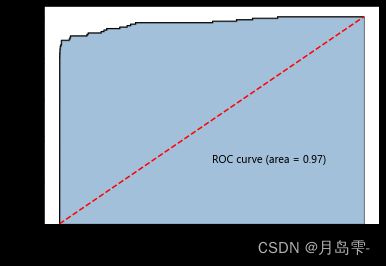
ROC曲线下的面积高达0.98,接近于1,说明XGBoost算法在该数据集上的
拟合效果非常优秀。为了体现SMOTE算法在非平衡数据上的价值,这里不妨利用XGBoost算法直接在非平衡数据上重新建模,并比较重抽样前后模型在测试数据集上的预测效果,
# 构建XGBoost分类器
xgboost2 = xgboost.XGBClassifier()
# 使用非平衡的训练数据集拟合模型
xgboost2.fit(X_train,y_train)
# 基于拟合的模型对测试数据集进行预测
pred2 = xgboost2.predict(X_test)
# 混淆矩阵
pd.crosstab(pred2,y_test)
Class 0 1
row_0
0 85292 32
1 10 109
# 返回模型的预测效果
print('模型的准确率为:\n',metrics.accuracy_score(y_test, pred2))
print('模型的评估报告:\n',metrics.classification_report(y_test, pred2))
模型的准确率为:
0.9995084442259752
模型的评估报告:
precision recall f1-score support
0 1.00 1.00 1.00 85302
1 0.92 0.77 0.84 141
accuracy 1.00 85443
macro avg 0.96 0.89 0.92 85443
weighted avg 1.00 1.00 1.00 85443
如上结果所示,对于非平衡数据而言,利用XGBoost算法对其建模,产生的预测准确率非常高,几乎为100%,要比平衡数据构建的模型所得的准确率高出近1%。但是,由于数据的不平衡性,导致该模型预测的结果是有偏的,对正常交易的预测覆盖率为100%,而对欺诈交易的预测覆盖率不足75%。再对比平衡数据构建的模型,虽然正常交易的预测覆盖率下降1%,但是促使欺诈交易的预测覆盖率提升了近15%,这样的提升是有必要的,降低了欺诈交易所产生的损失。同理,也基于非平衡数据构造的模型,绘制其在测试数据集上的ROC曲线,并通过比对AUC的值,比对前后两个模型的好坏
# 计算欺诈交易的概率值,用于生成ROC曲线的数据
y_score = xgboost2.predict_proba(X_test)[:,1]
fpr,tpr,threshold = metrics.roc_curve(y_test, y_score)
# 计算AUC的值
roc_auc = metrics.auc(fpr,tpr)
# 绘制面积图
plt.stackplot(fpr, tpr, color='steelblue', alpha = 0.5, edgecolor = 'black')
# 添加边际线
plt.plot(fpr, tpr, color='black', lw = 1)
# 添加对角线
plt.plot([0,1],[0,1], color = 'red', linestyle = '--')
# 添加文本信息
plt.text(0.5,0.3,'ROC curve (area = %0.2f)' % roc_auc)
# 添加x轴与y轴标签
plt.xlabel('1-Specificity')
plt.ylabel('Sensitivity')
# 显示图形
plt.show()
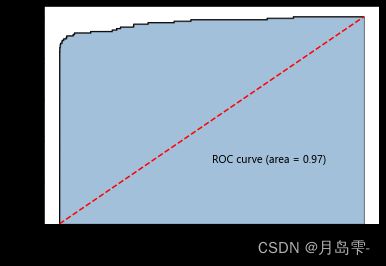
,尽管AUC的值也是非常高的,但相对于平衡数据所构建的模型,AUC值要
小0.1,进而验证了利用SMOTE算法实现数据的平衡是有必要的。通过平衡数据,可以获得更加稳定和更具泛化能力的模型。