基于网络的入侵检测数据集研究综述(A Survey of Network-based Intrusion Detection Data Sets)
A Survey of Network-based Intrusion Detection Data Sets
基于网络的入侵检测数据集研究综述
摘要:标记数据对于基于异常的网络入侵检测系统的训练和评估是必要的。本文对基于网络的入侵检测的数据集进行了文献综述,并详细描述了基于数据包和基于流的网络数据。本文确定了15种不同的属性,以评估个别数据集对特定评估场景的适用性。这些属性涵盖了广泛的标准,并被分为五类,例如用于提供结构化搜索的数据量或记录环境。基于这些性质,对现有数据集进行了全面的概述。这个概述还强调了每个数据集的特性。此外,本工作还简要介绍了基于网络的数据的其他来源,如流量生成器和数据存储库。最后,我们讨论了我们的观察结果,并为基于网络的数据集的使用和创建提供了一些建议。
关键词:入侵检测;IDS;NIDS;数据集;评估; 数据挖掘;
1. 背景
(1)会议/刊物级别
2019 Computers & Security
CCF B
(2)作者团队
(3)论文背景
入侵检测和内部威胁检测都需要具有代表性的网络数据集,基准数据集是评价和比较不同网络入侵检测系统(NIDS)优劣的基础。给定一个标记数据集,其中每个数据点被分配到正常类或攻击类,可以使用检测到的攻击次数或误报次数作为评估标准。不幸的是,有代表性的数据集并不多。根据Sommer和Paxson17,缺乏具有代表性的公开可用数据集构成了基于异常的入侵检测的最大挑战之一。Malowidzki et al.18和Haider et al.19也做了类似的陈述。然而,社区正在研究这个问题,因为在过去几年里已经发布了几个入侵检测数据集。特别是,澳大利亚网络安全中心发布了UNSW-NB15[20]数据集,科堡大学发布了CIDDS-001[21]数据集。
但是,现有数据集没有全面的索引,因此很难跟踪最新的发展。本工作对现有的基于网络的入侵检测数据集进行了文献综述。首先,对基础数据进行了更详细的研究。基于网络的数据以基于数据包或基于流的格式出现。**基于流的数据只包含关于网络连接的元信息,而基于包的数据也包含负载。**然后,对文献中常用来评价网络数据集质量的不同数据集属性进行分析和分组。本调查的主要贡献是一个详尽的文献综述,基于网络的数据集和分析,哪些数据集满足哪些数据集属性。本文重点研究了数据集内的攻击场景,并强调了数据集之间的关系。此外,除了典型的数据集之外,我们还简要介绍了流量生成器和数据存储库作为网络流量的进一步来源,并提供了一些观察结果和建议。作为主要的好处,该调查建立了一组数据集属性,作为比较可用数据集和确定适当数据集的基础,给出了特定的评估场景。此外,我们创建了一个网站1,其中引用了所有提到的数据集和数据存储库,我们打算更新这个网站。本文的其余部分组织如下。下一节讨论相关工作。第三节更详细地分析了基于数据包和流量的网络数据。第四节讨论了文献中常用来评估入侵检测数据集质量的典型数据集属性。第五节概述了现有的数据集,并根据第四节确定的属性检查每个数据集。第六节简要地讨论了基于网络的数据的进一步来源。第七节讨论了意见和建议,并在论文最后作了总结。
2.相关工作
本节回顾了基于网络的入侵检测数据集的相关工作。需要注意的是,本文没有考虑像ADFA[23]这样的基于主机的入侵检测数据集。感兴趣的读者可以在Glass-Vanderlan等人的[24]中找到关于基于主机的入侵检测数据的详细信息。Malowidzki等人[18]讨论了缺失数据集作为入侵检测的一个重要问题,提出了对良好数据集的要求,并列出了可用的数据集。Koch等[25]提供入侵检测数据集的另一个概述,分析13个数据源,并根据8个数据集属性对它们进行评估。Nehinbe[26]为入侵防御系统和入侵防御系统(IPS)提供了关键的数据集评估。作者研究了来自不同来源的7个数据集(例如DARPA数据集和DEFCON数据集),强调了它们的局限性,并提出了创建更现实的数据集的方法。由于过去四年发布了很多数据集,我们延续了之前2011年到2015年的工作[18],[25],[26],但提供了比我们的前辈更最新更详细的概述。
虽然许多数据集论文(如CIDDS-002 [27], ISCX[28]或UGR 16[29])只是简单概述了一些入侵检测数据集,Sharafaldin等人的[30]提供了更详尽的综述。他们的主要贡献是一个生成入侵检测数据集的新框架。Sharafaldin等人也分析了11个可用的入侵检测数据集,并根据11个数据集属性对它们进行了评估。与早期的数据集论文相比,我们的工作侧重于提供基于网络的现有数据集的中立概述,而不是提供额外的数据集。
最近的其他论文也涉及到基于网络的数据集,但主要关注点不同。Bhuyan等人[31]对网络异常检测进行了全面的综述。作者描述了9个现有的数据集,并分析了现有异常检测方法使用的数据集。同样,Nisioti等人的[32]关注于入侵检测的无监督方法,并简要参考了12个现有的基于网络的数据集。Yavanoglu和Aydos[33]分析和比较入侵检测最常用的数据集。然而,他们的审查只包含7个数据集,包括其他数据集,如HTTP CSIC 2010[34]。总而言之,这些工作的研究目标往往不同,对基于网络的数据集的接触也比较有限。
3.数据
通常,以基于包或基于流的格式捕获网络流量。捕获数据包级别的网络流量通常通过镜像网络设备上的端口来完成。基于数据包的数据包含完整的有效载荷信息。基于流的数据更聚合,通常只包含来自网络连接的元数据。
3.1 基于包的数据
基于数据包的数据通常以pcap格式捕获,并包含有效负载。可用的元数据取决于所使用的网络和传输协议。有许多不同的协议,最重要的是TCP, UDP, ICMP和IP。图1说明了不同的标题。TCP是一个可靠的传输协议,包括元数据序列号、确认号、TCP标志或校验和值。UDP是一种无连接的传输协议,其报头比TCP小,TCP报头只包含源端口、目的端口、长度和校验和四个字段。与TCP和UDP相比,ICMP是一种支持协议,包含状态消息,因此更小。通常,在传输协议的头旁边还有一个IP头可用。IP报头提供了源和目的IP地址等信息,如图1所示。

3.2 基于流的数据
基于流的网络数据是一种更压缩的格式,主要包含关于网络连接的元信息。基于流的数据将在一个时间窗口内共享某些属性的所有数据包聚合到一个流中,通常不包含任何有效负载。五元组定义,即源IP地址、源端口、目的IP地址、目的端口和传输协议[37],被广泛使用在流数据中。
流可以以单向或双向的形式出现。单向格式将主机A到主机B的所有具有上述属性的数据包聚合成一个流。所有从主机B到主机A的数据包被聚合成另一个单向流。相反,双向流汇总了主机a和主机B之间的所有报文,而不考虑方向。典型的基于flow的格式有NetFlow[38]、IPFIX[37]、sFlow[39]和OpenFlow[40]。

表I给出了基于流的网络流量中的典型属性的概述。根据特定的流格式和流导出器,可以提取额外的属性,如每秒字节数、每个包字节数、第一个包的TCP标志,甚至负载的计算熵。此外,使用像nfdump2或YAF3这样的工具,可以将基于包的数据转换为基于流的数据(但反之不行)。对流输出器之间的差异感兴趣的读者可以在[41]中找到更多的细节,以及对不同流输出器如何影响僵尸网络分类的分析。
3.3 其他类型数据
这个类别包括所有既不是纯基于数据包也不是纯基于流的数据集。这一类别的一个例子可能是基于流的数据集,这些数据集被来自基于包的数据或基于主机的日志文件的附加信息所充实。KDD CUP 1999[42]数据集是这类数据集的著名代表。每个数据点都有基于网络的属性,如传输源字节数或TCP标志,但也有基于主机的属性,如失败登录的数量。因此,这一类别的每个数据集都有自己的一组属性。由于每个数据集都必须单独分析,所以我们不会对可用属性做任何一般性的说明。
4.数据集属性
为了能够将不同的入侵检测数据集并排比较,帮助研究人员找到适合其特定评估场景的数据集,有必要定义公共属性作为评估依据。
一般概念FAIR[43]定义了学术数据应该实现的四个原则,即可发现性、可访问性、互操作性和可重用性。与此同时,本工作使用更详细的数据集属性来提供基于网络的入侵检测数据集的重点比较。
通常,不同的数据集强调不同的数据集属性。例如,UGR 16数据集[29]强调长时间的记录,以捕捉周期性的效果,而ISCX数据集[28]侧重于准确的标记。由于我们的目标是研究基于网络的入侵检测数据集的更一般的属性,我们试图统一和概括文献中使用的属性,而不是采用所有的属性。例如,一些方法可以评估特定类型攻击的存在,如DoS(拒绝服务)或浏览器注入。某些攻击类型的存在可能是评估这些特定攻击类型的检测方法的相关属性,但对于其他方法来说是没有意义的。因此,我们使用一般属性攻击来描述恶意网络流量的存在(见表三)。第五节详细介绍了数据集中的不同攻击类型,并讨论了其他特定属性。我们没有像Haider et al.[19]或Sharafaldin et al.[30]那样开发一个评价分数,因为我们不想判断不同数据集属性的重要性。我们认为,某些属性的重要性取决于具体的评估场景,一般不应通过调查来判断。相反,应该让读者找到适合自己需要的数据集。因此,我们将下面讨论的数据集属性分为五类,以支持系统搜索。图2总结了所有数据集属性及其值范围。

4.1 一般属性
以下四个属性反映了有关数据集的一般信息,即创建年份、可用性、正常和恶意网络流量的存在。
1)创建年份:由于网络流量存在概念漂移,每天都有新的攻击场景出现,因此入侵检测数据集的年龄非常重要。此属性描述创建的年份。与数据集的发布年份相比,捕获数据集的底层网络流量的年份与最新程度更相关。
2)公开可用性:入侵检测数据集应该公开可用,作为比较不同入侵检测方法的基础。此外,如果数据集是公开的,则只能由第三方检查数据集的质量。表III包含了该属性的三个不同特征:yes、o.r.(根据要求)和no。根据请求,将在向作者或负责人发送消息后授予访问权限。
3)正常用户行为:该属性表示数据集中正常用户行为的可用性,取值为yes或no。yes表示该数据集中存在正常的用户行为,但不表示存在攻击。一般来说,IDS的质量主要由其攻击决定检测率和虚警率。因此,正常用户行为的存在对于评估IDS是必不可少的。然而,正常用户行为的缺失并不意味着数据集不可用,而是表明它必须与其他数据集或现实世界的网络流量合并。这样的合并步骤通常称为叠加或撒盐[44],[45]。
4)攻击流量:IDS数据集应该包含各种攻击场景。该属性指示数据集中存在恶意网络流量,如果数据集中包含至少一次攻击,则该属性的值为yes。表四提供了关于特定攻击类型的附加信息。
4.2 数据性质
这个类别的属性描述数据集的格式和元信息的存在。
1)元数据:第三方很难对基于包和基于流的网络流量进行与内容相关的解释。因此,数据集应该与元数据一起提供关于网络结构、IP地址、攻击场景等额外信息。此属性指示是否存在其他元数据。
2)格式:网络入侵检测数据集以不同的格式出现。(1)基于包的网络流量(例如pcap)包含有负载的网络流量。(2)基于流量的网络流量(例如NetFlow)只包含关于网络连接的元信息。(3)其他类型的数据集可能包含,例如,基于流的跟踪带有来自基于包的数据或甚至来自基于主机的日志文件的附加属性。
3)匿名性:通常,由于隐私原因,入侵检测数据集可能不会被发布,或者仅以匿名的形式可用。此属性指示数据是否被匿名化以及哪些属性受到影响。表III中的值none表示未执行过匿名化。值yes (IPs)表示IP地址被匿名化或从数据集中删除。类似地,yes (payload)表示将有效负载信息匿名化或从基于包的网络流量中删除。
4.3 数据量
这类属性根据容量和持续时间来描述数据集。
1)计数:属性计数描述了一个数据集的大小,可以是包含的包/流/点的数量,也可以是物理大小(GB)。
2)持续时间:数据集应覆盖较长时间的网络流量,以捕捉周期性效应(如白天vs.夜晚或工作日vs.周末)[29]。属性duration提供每个数据集的记录时间。
4.4 记录环境
这一类中的属性描述了捕获数据集的网络环境和条件。
1)流量种类:流量种类描述了网络流量的三种可能来源:真实的、模拟的或合成的。真实意味着真实的网络流量是在一个高效的网络环境中捕获的。仿真是指在测试平台或仿真网络环境中捕获真实的网络流量。合成的意思是网络流量是合成的(例如,通过流量生成器)而不是由真实的(或虚拟的)网络设备捕获的。
2)网络类型:中小型公司的网络环境与互联网服务提供商(ISP)有根本的不同。因此,不同的环境需要不同的安全系统,评估数据集应该适应特定的环境。此属性描述在其中创建相应数据集的基础网络环境。
3) Complete Network:这个属性来自Sharafaldin et al.[30],表示数据集是否包含来自一个包含多个主机、路由器等的网络环境的完整网络流量。如果该数据集只包含来自单个主机(如蜜罐)的网络流量,或仅包含来自网络流量的某些协议(如独家SSH流量),则设置为no。
4.5 评估
以下属性与使用基于网络的数据集的入侵检测方法的评估有关。更准确地说,属性表示预定义子集的可用性、数据集的余额和标签的存在。
1)预定义分割:有时很难比较不同IDS的质量,即使它们是在同一数据集上评估的。在这种情况下,必须澄清是否使用相同的子集进行培训和评估。如果数据集附带用于培训和评估的预定义子集,则此属性提供信息。
2) Balanced:通常,机器学习和数据挖掘方法被用于基于异常的入侵检测。在这些方法的训练阶段(例如,决策树分类器),数据集应该根据它们的类标签进行平衡。因此,数据集应该包含来自每个类(正常和攻击)的相同数量的数据点。然而,现实世界的网络流量并不均衡,用户的正常行为多于攻击行为。此属性指示数据集相对于它们的类标签是否平衡。在使用数据挖掘算法之前,应该通过适当的预处理来平衡不平衡的数据集。他和Garcia[46]对从不平衡数据中学习提供了一个很好的概述。
3)有标记的:有标记的数据集对于训练有监督的方法和评估有监督和无监督的入侵检测方法是必要的。此属性指示数据集是否被标记。如果至少有normal和attack两个类,则将此属性设置为yes。这个属性的可能值是:yes, BG的是。(yes with background)、yes (IDS)、indirect和no。Yes with background意思是有第三类背景。属于类背景的报文、流或数据点可能是正常的,也可能是攻击。是(IDS)意味着某种入侵检测系统被用来创建数据集的标签。由于IDS可能不完美,数据集的一些标签可能是错误的。间接的意思是数据集没有显式的标签,但是标签可以自己从其他日志文件创建。
5.数据集
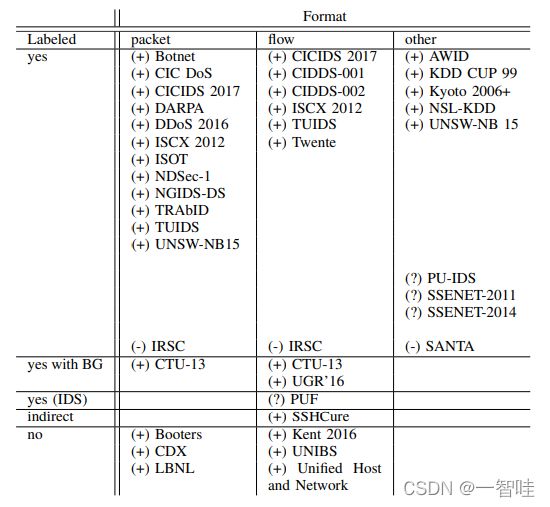
我们认为,在寻找合适的网络数据集时,数据集的标签属性和格式属性是最重要的。入侵检测方法(有监督的或无监督的)决定是否需要标签,以及需要哪种类型的数据(包、流或其他)。因此,表二就这两个属性对所有研究过的基于网络的数据集进行了分类。表三根据第四节的数据集属性对基于网络的入侵检测数据集进行了更详细的概述。在搜索基于网络的数据集时,特定攻击场景的存在是一个重要方面。因此,表三表示攻击流量的存在情况,表四表示数据集中具体的攻击情况。有关数据集的论文描述了不同抽象级别上的攻击。例如,Vasudevan et al.[47]在他们的数据集(SSENET2011)中对攻击流量进行了如下描述:“Nmap、Nessus、Angry IP scanner、Port scanner、Metaploit、Backtrack OS、LOIC等是参与者用来发起攻击的一些攻击工具。”相比之下,Ring等人在他们的CIDDS-002数据集[27]中指定了执行的端口扫描的数量和不同类型。因此,在表四中攻击描述的抽象级别可能有所不同。对所有攻击类型的详细描述超出了本工作的范围。相反,我们建议感兴趣的读者阅读Anwar等人撰写的开放获取论文《从入侵检测到入侵响应系统:基础、需求和未来方向》。此外,一些数据集是其他数据集的修改或组合。图3显示了几个知名数据集之间的相互关系。
6. 其他数据源
除了基于网络的数据集之外,还有一些用于基于包和基于流的网络流量的其他数据源。在下面的文章中,我们将简要讨论数据存储库和流量生成器。
6.1 数据仓库
除了传统的数据集,在互联网上还可以找到一些数据存储库。由于这些存储库的类型和结构有很大的不同,所以我们不采用表格比较。相反,我们按字母顺序给出一个简短的文本概述。关于现状,已于2019年2月26日检查了存储库。AZSecure37。AZSecure是亚利桑那大学的一个网络数据存储库,供研究社区使用。它包括pcap、arff和其他格式的各种数据集,其中一些有标签,而另一些没有。AZSecure包括CTU-13数据集[3]或统一主机和网络数据集[73]。存储库被管理并包含一些最新的数据集————。。。
6.2 流量生成器
用于入侵检测研究的另一个网络流量来源是流量生成器。流量生成器是生成合成网络流量的模型。在大多数情况下,流量生成器使用用户自定义的参数或提取真实网络流量的基本属性来创建新的合成网络流量。**虽然数据集和数据存储库提供固定的数据,但流量生成器允许生成能够适应特定网络结构的网络流量。例如,流量生成器FLAME[79]和ID2T[80]使用真实的网络流量作为输入。这个输入流量应该作为正常用户行为的基线。然后,FLAME和ID2T通过编辑添加恶意网络流量考虑典型的攻击模式,输入流量或注入合成流的值。**Siska等人[81]提出了一种基于图的流生成器,它从真实的网络流量中提取流量模板。然后,他们的生成器使用这些流量模板来创建新的基于流量的合成网络流量。Ring等[82]对gan进行了改进,以生成合成网络流量。作者使用改进的Wasserstein生成对抗网络(WGAN-GP)来创建基于流的网络流量。WGAN-GP使用真实的网络流量进行训练,学习流量特征。经过训练后,WGAN-GP能够创建具有相似特征的基于合成流的网络流量。Erlacher和Dressler的流量生成器GENESIDS[83]根据用户定义的攻击描述生成HTTP攻击流量。为了简洁起见,这里没有讨论许多附加的交通生成器。除了这些交通生成器,还有许多其他交通生成器不在这里讨论。相反,我们参考Molnár等人[84]对交通生成器的概述。
Brogi等人[85]提出了另一个想法,在某种程度上类似交通发电机。从出于隐私考虑而共享数据集的问题出发,他们提出了Moirai,这是一个允许用户共享完整场景而不是数据集的框架。Moirai背后的想法是在虚拟机中重现攻击场景,这样用户就可以动态生成数据。第三种方法——也被归类为流量生成器的更大上下文——是支持用户标记真实网络流量的框架。Rajasinghe等人提出了这样一个名为inss - dcs的框架[86],它在网络设备上捕获网络流量,或者使用pcap文件中已经捕获的网络流量作为输入。然后,inss - dcs将数据流划分为时间窗口,提取具有相应属性的数据点,并根据攻击者自定义的IP地址列表对网络流量进行标记。因此,inss - dcs的重点是对网络流量进行标记,提取有意义的属性。Aparicio-Navarro等人[87]提出了一种使用无监督的基于异常的IDS的自动数据集标记方法。由于没有一个IDS能够将每个数据点分类到正确的类,因此作者采取了一些中间立场,以减少误报和真报的数量。IDS为正常类和攻击类的每个数据点分配信念值。如果这两个类的置信值之间的差值小于一个预定义的阈值,则该数据点将从数据集中删除。这种方法提高了标签的质量,但可能会丢弃数据集中最有趣的数据点。
7. 观察和建议
标注数据集对于训练分类算法等有监督数据挖掘方法是不可避免的,并且有助于评估有监督和无监督数据挖掘方法。因此,标记的基于网络的数据集可以用来比较不同的NIDS之间的质量。然而,在任何情况下,数据集必须具有代表性,才能适合这些任务。社区意识到现实的基于网络的数据的重要性,这项调查显示,有许多数据来源(数据集、数据存储库和流量生成器)。此外,这项工作建立了一个数据集属性的集合,作为比较可用数据集的基础,并为确定合适的数据集,给出特定的评估场景。
8. 总结
标记的基于网络的数据集是训练和评估NIDS所必需的。本文提供了一个文献调查可用的网络入侵检测数据集。为此,更详细地分析了基于网络的标准数据格式。此外,确定了15个属性,可用于评估数据集的适宜性。这些属性分为五类:一般信息、数据性质、数据量、记录环境和评价。本文的主要贡献是对34个数据集的全面概述,指出了每个数据集的特点。因此,我们将重点放在数据集内部的攻击场景及其相互关系上。此外,根据第一步中开发的分类方案的属性评估每个数据集。
详细的调查旨在支持读者识别数据集为他们的目的。对数据集的回顾表明,研究界已经注意到缺乏公开可用的基于网络的数据集,并试图通过在过去几年中发布大量的数据集来克服这一不足。由于一些研究小组在这一领域很活跃,预计不久将会有更多的入侵检测数据集和改进。
作为网络流量的进一步来源,流量生成器和数据存储库将在第六节中讨论。流量生成器创建合成网络流量,并可用于为特定场景创建适应的网络流量。数据存储库是互联网上不同网络轨迹的集合。与第五节中的数据集相比,数据存储库通常提供有限的文档、非标记的数据集或特定场景的网络流量(例如,独家FTP连接)。但是,在搜索合适的数据时,应该考虑到这些数据源,特别是对于特定的场景。最后,我们讨论了基于网络的入侵检测数据集的使用和生成的一些观察和建议。我们鼓励用户在多个数据集上评估他们的方法,以避免对某个数据集过度拟合,并减少某个数据集的人工影响。此外,我们提倡标准格式的数据集,包括预定义的训练和测试子集。总的来说,可能不会有一个完美的数据集,但有许多非常好的数据集可用,社区可以从更密切的合作中受益。