1. 背景
先理一下自动化测试的概念,从广义上来说,一切通过工具(程序)的方式来代替或者辅助手工测试的行为都可以成为自动化。从狭义上来说,通过编写脚本的方式,模拟手工测试的过程,从而替代人工对系统的功能进行验证。
有赞是一家互联网行业的创业公司,测试起步较晚,发布非常频繁,就算每次只回归核心功能,对人数极少的几个测试人员来说工作量巨大,且基本是重复劳动,极其枯燥,持续时间长了也容易出错。
所以初期我们测试自动化切入的思路非常简单:从实际用户的角度出发,模拟真实的操作,替代现有的手工测试用例的执行。这样一来,每次重复的工作就可以用自动化来替代,测试人员只需要关注每次发布的增量需求即可。
随着脚本数量的增加,这种自动化覆盖的方式的弊端也逐渐暴露:
- 执行效率低下
- 构建成功率低(误报率高)。
- 受前端样式变更影响大
- 外部依赖较多,不是所有用例都能自动化
- 覆盖能力有限
虽然我们在测试框架和工具层面通过结合selenium-grid实现了脚本并发执行和失败用例重试机制以提高执行效率和降低误报率,但是这种方式只能缓解问题,并不能从根本解决覆盖不全的问题。
正好赶上公司的SOA服务化进程,测试这边也开始配合的做自动化方面的转变,从原来的黑盒系统级自动化测试向分层自动化测试转变。
2. 分层自动化测试
在谈分层测试之前,先回顾几个概念:
- 单元测试:对软件中的最小可测试单元进行检查和验证。具体的说就是开发者编写的一小段代码,用于检验被测代码的一个很小的、很明确的功能是否正确。通常而言,一个单元测试是用于判断某个特定条件(或者场景)下某个特定函数的行为。
- 集成测试:集成测试是在单元测试的基础上,测试在将所有的软件单元按照概要设计规格说明的要求组装成模块、子系统或系统的过程中各部分工作是否达到或实现相应技术指标及要求的活动。也就是说,在集成测试之前,单元测试应该已经完成。这一点很重要,因为如果不经过单元测试,那么集成测试的效果将会受到很大影响,并且会大幅增加软件单元代码纠错的代价。
- 系统测试:将需测试的软件,作为整个基于计算机系统的一个元素,与计算机硬件、外设、某些支持软件、数据和人员等其他系统元素及环境结合在一起测试。系统测试的目的在于通过与系统的需求定义作比较,发现软件与系统定义不符合或与之矛盾的地方。
接下来我们谈谈有赞是如何随着系统拆分SOA服务化推进分层自动化测试的。先来看看经典的测试金字塔:
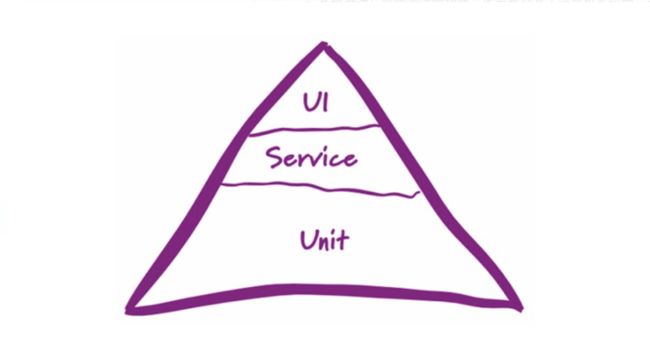
其中Unit代表单元测试,Service代表服务集成测试,UI代表页面级的系统测试。分层的自动化测试倡导产品的不同层次都需要自动化测试,这个金字塔也正表示不同层次需要投入的精力和工作量。下面我会逐层介绍有赞的分层自动化实践。
2.1 Unit-单元测试
在系统拆分之前,有赞只有一个庞大的巨无霸系统,单元测试极度缺失。在系统逐渐SOA服务化的过程中,我们逐渐提出了对单元测试覆盖率的要求。
我们的单元测试会分别做DAO层和服务层的测试。DAO层的单元测试主要保障SQL脚本的正确性,在做服务层的单元测试时就可以以DAO层是正确的前提进行用例编写了。
为了做细粒度的测试,需要解决单元测试的外部依赖。系统和模块之间的依赖可以通过Mock框架(Mockito/EasyMock)解耦,同时可以结合h2database解决对数据库的依赖,使得测试用例尽可能做到可以随时随地运行。
这一层发现并解决问题付出的成本相对来说最低,自动化用例的维护成本也不高,总的来说自动化测试的投入产出比最高。
单元测试的责任主体一般来说是开发人员,写单元测试也是开发人员对自己的代码进行检查的一个过程。
2.2 Service-服务集成测试
我们在服务层的测试首要考虑的是各系统(子系统)的集成测试。因为在经过单元测试这一层的保障之后,在服务层我们更关注的是某个系统的输入输出功能是否正确,以及若干个系统间的交互是否和业务场景的要求一致。
先来看看我们系统拆分之后的SOA系统应用架构图:

- 展现层:老的Iron应用,代码为php。拆分之后iron只剩下和前端交互的展现层逻辑,以及调用核心业务的API层
- 核心业务:Iron系统拆分出来的核心业务
这一层的被测对象是抽离了展现层的代码(前端以及部分后端展现层逻辑)。
鉴于有赞的测试起步较晚(应该很多创业公司都有类似情况),测试资源紧缺,代码覆盖率低得可怜。所以我们的初期自动化用例覆盖策略是这样的:
- 从老的Iron应用的API接口作为业务场景覆盖的切入点
- 优先覆盖核心业务的场景
- 配合系统拆分,优先覆盖拆分出去的系统
- 已拆分出去的系统,做好系统服务层的测试覆盖(全面覆盖该服务的接口)
- 测试依赖的数据准备优先选择调用系统接口的方式(为了增加业务覆盖面)
- 测试方式逐渐从黑盒向灰盒/白盒转变
这样做的好处是,可以快速增加业务场景的覆盖面,同时事先准备好的API接口用例,可以作为系统拆分后的冒烟测试用例,起到核心老功能的回归作用(只是做系统拆分,业务逻辑以及对展现层暴露的接口行为不变)。毕竟在自动化测试的过程中,最怕的就是变化,会带来更多的脚本维护工作,而以这种方式覆盖的用例,目前来看维护成本很低。
再介绍一下这一层的初期我们用例的基本形态:
- 专注于业务场景,和UI脚本一致,只是脚本从操作页面变成了调用接口。相对于UI自动化,服务层的接口测试更加稳定,测试用例也更容易维护。服务层接口测试可以更关注与系统整体的逻辑(业务)验证,而UI自动化则会转变为页面展示逻辑及界面前端与服务的集成验证(这个在UI层会介绍)。
- 暂时不做系统间的Mock。更多的考虑系统之间的耦合和依赖。
- 搭建MockServer解决系统的外部依赖,主要是类似于支付等第三方系统(关于我们的MockServer会有专门的文章介绍)。
结合我们的交易系统举个例子:比如交易系统会依赖于商品和营销活动,那我们的下单场景的用例会依次调用商品和营销这几个系统的API构造数据作为用例的前置条件,然后按照下单的业务场景调用交易系统的下单接口,校验返回值以及写入DB的数据,最后做好数据清理的工作。
我们在这一层的测试框架选择是基于公司通用的服务框架(Nova)基础之上搭建的,架构图如下:
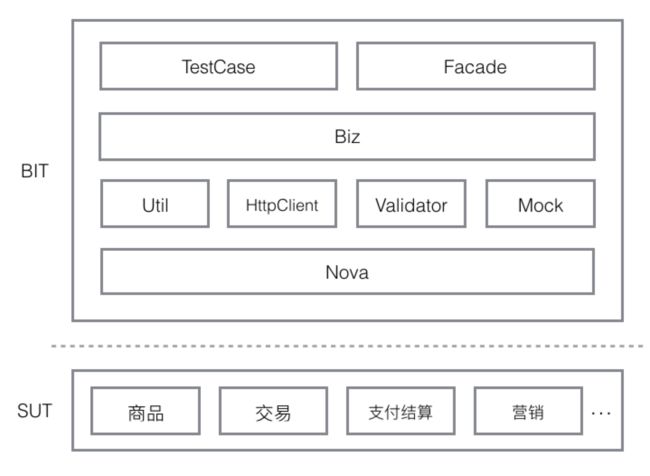
BIT :服务接口集成测试(Business Interface&Integration Test)
SUT:被测系统(System Under Test)
- Validator:各个业务的数据库结果验证封装
- Mock:用例前置条件依赖的数据Mock服务
- HttpClient:根据IRON系统的接口封装了返回通用的RPCResult对象
- Util:常用工具类封装
- Biz:在此封装了所有被测系统对外暴露的接口,供测试用例直接调用
- TestCase:我们服务接口测试又分为SDV(System design Verify-系统设计验证)和SIT(System Integration Test-系统集成测试)。按照上面提到的用例覆盖策略,我们是在系统拆分之前,先根据该系统的业务场景和REST接口补充核心的接口集成测试用例,后续可以作为系统拆分之后的冒烟用例。在系统拆分之后,详细补充该系统的测试用例,粒度更细。
- Facade:结合了Nova框架,对外发布各个业务的数据构造的REST接口,同时可以作为测试数据构造系统,辅助测试人员的手工测试
这一层的测试覆盖主要是由测试人员进行,是测试人员大展身手的地方。
我们不需要非常详细的了解代码的实现,但是我们的用例里充分体现了我们对系统的结构,模块之间关系等的充分的理解。
后续我们对于Service层自动化测试的推进策略是:
- 逐渐丰富SDV层的测试用例,并且在一定程度上进行用例依赖的系统的解耦,比如数据构造从调用接口向直接往数据库写入数据转变。
- 逐渐细化拆分业务场景,做好用例的解耦。
- 优先做场景覆盖,之后再考虑代码覆盖。
2.3 UI-展现测试
先提一个问题,既然在文章开篇提到了UI自动化测试有这么多弊端,这么劳民伤财,那么是否还有必要进行UI层的自动化呢?答案是肯定的,因为UI层是我们的产品最终呈现给用户的东西。所以在做好上面两层的测试覆盖之后,测试人员可以投入更多的精力到UI层的测试上。正是因为测试人员会在UI层投入较大精力,我们还是有必要通过自动化来帮助我们解放部分重复劳动力。
根据我们的UI层自动化实践,提一下我们的UI层自动化覆盖的原则:
- 能在底层做自动化覆盖,就尽量不在UI层做自动化覆盖
- 只做最核心的功能的自动化覆盖,脚本可维护性尽可能提高
我们提高UI脚本可维护性的方法是遵循Page Object设计模式。
Page Object
Page Object模式是为了避免在测试代码中直接操作HTML元素,对Web页面的抽象。好处有:
- 减少测试代码的冗余
- 提高测试代码的可读性和稳定性
- 提高测试代码的可维护性
一个简单的例子
以有赞首页的登录操作为例(Ruby):
class LoginPage include HeaderNav def login(account, password) text_account.wait_until_present.set(account) text_password.set(password) button_login.wait_until_present.click return MainPage.new(@browser) end private def text_account @browser.text_field(:name => 'account') end def text_password @browser.text_field(:name => 'password') end def button_login @browser.button(:class => 'login-btn') end end
- public方法对外暴露页面的服务,对于登录页面来说就是登录行为
- 页面的UI细节设为private方法对外隐藏
- 跳转到新的页面后在此方法中return之后的页面的对象,比如登录之后跳转到首页(MainPage)。甚至同一页面也可以返回self做链式操作。
- 各个页面的公共部分,如页面顶部导航,可以封装成Module供各个页面对象直接include
下面我们来看看测试用例:
class TestLogin < Test::Unit::TestCase def testLogin @browser = Browser.new @browser.goto 'youzan.com' main_page = @browser.login_page.login('xx', '123') #断言 end end
这样最终的测试脚本呈现的就是单纯的页面操作逻辑,更贴近文本测试用例。
下面来看一下我们的测试框架:
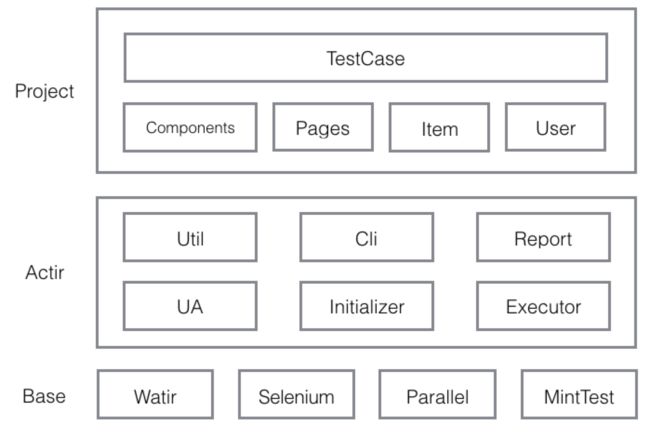
- Base:这一层和大多数UI测试框架大同小异,使用的是selenium和watir,用例管理方面并没有使用Ruby领域炙手可热的BDD框架cucumber,而是最基本的单元测试框架MiniTest。同时还引入了ruby的多线程包,配合UI脚本的并发执行。
- Actir:我们自己封装的测试框架
-
- Initializer:自动按照约定的工程结构加载所有的ruby文件,并根据Page的类名和反射自动生成了所有页面类的对象实例。
- UA:封装好测试需要的浏览器User-Agent。
- Executor:用例执行器。基于ruby的多线程包以及selenium-grid,实现了所有用例的调度及分布式执行,可以一定程度上大大提升UI脚本的执行效率。执行器还包括了失败用例重试机制。
- Util:工具类,包括了配置文件读写、数据驱动等。
- Report:根据UI测试脚本执行的最终结果(失败重试的用例以最终的结果为准)自动生成HTML格式的测试报告。
- Cli:根据Actir框架的上述功能,封装出的命令行工具,方便持续集成。
- Project
-
- Pages:基于PageObject模式包装出的页面的对象
- Components:各个页面的公用的部分或者插件,如图片上传、地址选择等。包装成Module供各个页面对象需要时直接include。
- Item:根据系统业务抽象出的对象,如订单、优惠券、商品等
- User:根据系统业务抽象出的角色及其Action,如买家的购买行为、买家的退款、发货等。
随着服务层自动化覆盖率越来越高,UI层的自动化覆盖会逐渐转变为页面展示逻辑及界面前端与服务的展现层交互的集成验证。我们后续对于UI层自动化的演进规划是这样的:
- 依赖环境的Mock,解除UI脚本的外部依赖
- 完善的数据准备,可以通过后端服务接口的mock使UI自动化更关注页面业务逻辑的自动校验。
- 页面截图比对校验UI样式。
UI层的自动化测试也是由测试人员负责,在覆盖了核心业务核心场景之后,不应该在这层的自动化覆盖上投入太多的精力和资源。就算我们在一定程度上提高了脚本的可维护性,可是毕竟自动化测试最怕的就是变化,而UI界面是变化频率最高的一层,所以还是得投入一定的精力维护,不是么?
3. 持续集成
有了上述各层的自动化测试脚本,下面我们需要建立起持续集成体系。 持续集成的目的:
- 流程自动化,提高工作效率
- 最大化自动化测试脚本的价值
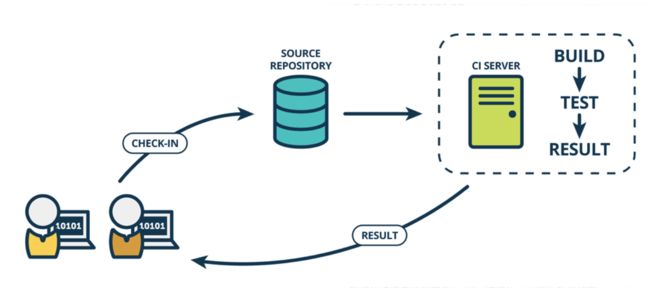
我们的持续集成是基于Jenkins搭建的,主要的动作如下:
- 代码提交自动执行单元测试
- 单元测试通过后自动部署整体的环境
- 自动执行集成自动化测试(Service/UI)
- 自动生成构建的详细测试报告,同时自动通知相关人员
持续集成所需的支撑有:
- 测试环境自动部署脚本
- 代码覆盖率自动收集
-
- Java应用 基于JaCoCo+Jenkins插件的方式
- php应用 通Xdebug+phpunit的方式
- 测试报告相关插件及脚本
- 代码静态检查等
对于持续集成我们后续的演进规划是朝着持续交付和持续部署的方向努力,在持续集成的基础之上,自动将代码部署到测试环境上方便测试人员进行手工测试。
4. 总结
本文主要从整体上介绍了在有赞SOA化的进程中,测试推行的分层自动化实践,以及后续的发展方向,同时简单介绍了相关的测试框架结构。下面再从整体回顾一下我们的分层自动化的要点:
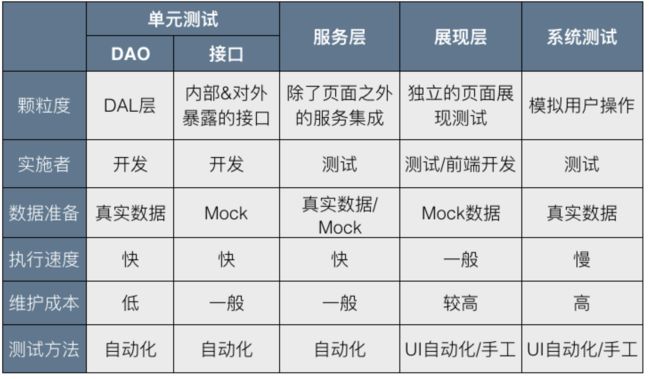
- 单元测试:
-
- 优先级最高
- 粒度最细、覆盖面最全
- 开发实施
- 服务测试
-
- 对测试来说优先级最高
- 从业务场景的角度切入
- 系统外部接口100%覆盖
- 关注系统间的依赖和调用
- 测试实施
- 页面测试
-
- 优先级相对最低
- 只保证核心功能的自动化覆盖,只关注UI层的问题
- 通过数据mock的方式减少对后台数据的依赖。
- 测试实施
至于各层投入的具体比重,还是需要根据项目的需求来实际规划。在《google 测试之道》一书,对于google产品,70%的投入为单元测试,20%为集成、接口测试,10% 为UI层的自动化测试。
最后再提一些观点吧:
- 越底层的自动化,收益越高
- 质量不是测试人员一个人的事情
- 自动化测试的目的不是为了减少手工测试,而是为了测试人员做更多更有意义的手工测试