一文彻底理解Go语言栈内存/堆内存
系列导读
本文基于64位平台、1Page=8KB、Go1.6
本文为《Go语言轻松进阶》系列第二章「内存与垃圾回收」的第三小节。第二章目录:
知识预备
指针的大小(完结)
TCMalloc内存分配原理(完结)
Go内存设计与实现
内存管理架构(完结)
内存管理单元mspan(完结)
栈内存/堆内存(本文内容)
Go的垃圾回收原理(未开始)
查看本系列完整内容请访问
http://tigerb.cn/go/#/kernal/
本文导读
本文将从6个方向层层递进,帮助大家彻底理解Go语言的栈内存和堆内存:
计算机为什么需要内存?
为什么需要栈内存?
为什么需要堆内存?
Go语言分配的是虚拟内存
Go语言栈内存的分配
分配时机
分配过程
Go语言堆内存的分配
分配时机
分配过程
计算机为什么需要内存?
计算机是运行自动化程序的载体,程序(或称之为进程)由可执行代码被执行后产生。那么计算机在运行程序的过程中为什么需要「内存」呢?为了轻松理解这个问题,我们先来简单看看:
代码的本质
可执行代码被执行后,程序的运行过程
代码的本质
简单来看代码主要包含两部分:
指令部分:中央处理器CPU可执行的指令
数据部分:常量等
代码包含了指令,代码被转化为可执行二进制文件,被执行后加载到内存中,中央处理器CPU通过内存获取指令,图示如下:

详细请移步历史文章「回到本真,代码到底是什么?」
程序的运行过程
可执行代码文件被执行之后,代码中的待执行指令被加载到了内存当中。这时CPU就可以从内存中获取指令、并执行指令。
CPU执行指令简易过程分为三步:
取指:CPU控制单元从内存中获取指令
译指:CPU控制单元解析从内存中获取指令
执行:CPU运算单元负责执行具体的指令操作
我们通过一个简易的时序图来看看CPU获取并执行指令的过程:

详细请移步历史文章「回到本真,代码是如何运行的?」
内存的作用
通过以上我们可以基本看出「内存」在计算机中扮演的角色:
暂存二进制可执行代码文件中的指令、预置数据(常量)等
暂存指令执行过程中的中间数据
等等
至此我们基本明白了内存存在的意义。但是呢,我们又经常会听到关于「栈内存」、「堆内存」的概念,那「栈内存」和「堆内存」到底是什么呢?接下来我们继续来看看这个问题。
为什么需要栈内存?
程序在使用内存的过程中,不仅仅只需要关注内存的分配问题,还需要关注到内存使用完毕的回收问题,这就是内存管理中面临的最大两个问题:
内存的分配
内存的回收
有没有简单、高效、且通用的办法统一解决这个内存分配问题呢?
答:最简单、高效的分配和回收方式就是对一段连续内存的「线性分配」,「栈内存」的分配就采用了这种方式。
「栈内存」的简易管理过程:
1. 栈内存分配逻辑:current - alloc

2. 栈内存释放逻辑:current + alloc

通过利用「栈内存」,CPU在执行指令过程中可以高效地存储临时变量。其次:
栈内存的分配过程:看起来像不像数据结构「栈」的入栈过程。
栈内存的释放过程:看起来像不像数据结构「栈」的出栈过程。
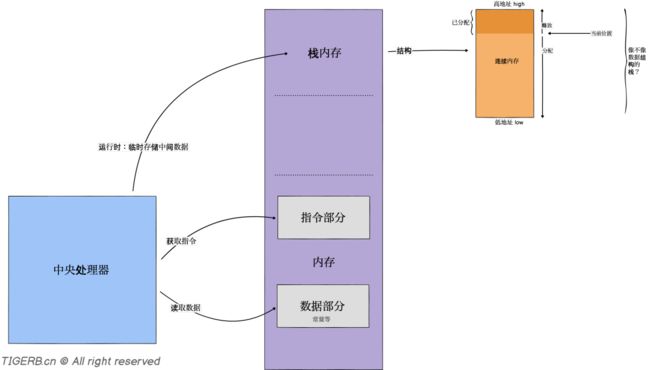
所以同时你应该也理解了「为什么称之为栈内存?」。「栈内存」是计算机对连续内存的采取的「线性分配」管理方式,便于高效存储指令运行过程中的临时变量。
为什么需要堆内存?
假如函数A内变量是个指针且被函数B外的代码依赖,如果对应变量内存被回收,这个指针就成了野指针不安全。怎么解决这个问题呢?
答:这就是「堆内存」存在的意义,Go语言会在代码编译期间通过「逃逸分析」把分配在「栈」上的变量分配到「堆」上去。

「堆内存」如何回收呢?
答:堆内存通过「垃圾回收器」回收,关于「垃圾回收器」后续我们详解。
Go语言分配的是虚拟内存
通过以上我们了解了「内存」、「栈内存」、「堆内存」存在的意义。除此之外,还有一个重要的知识点:程序和操作系统实际操作的都是虚拟内存,最终由CPU通过内存管理单元MMU(Memory Manage Unit)把虚拟内存的地址转化为实际的物理内存地址。图示如下:

使用虚拟内存的原因:
对于我们的进程而言,可使用的内存是连续的
安全,防止了进程直接对物理内存的操作(如果进程可以直接操作物理内存,那么存在某个进程篡改其他进程数据的可能)
提升物理内存的利用率,当进程真正要使用物理内存时再分配
虚拟内存和物理内存是通过MMU(管理单元内存Memory Management Unit)映射的
所以,一个很重要的知识点:
结论:Go语言源代码对「栈内存」和「堆内存」的分配、释放等操作,都是对虚拟内存的操作,最终中央处理器CPU会统一通过MMU(管理单元内存Memory Management Unit)转化为实际的物理内存。
也就是说Go语言源代码中:
「栈内存」的分配或释放都是对虚拟内存的操作
「堆内存」的分配或释放都是对虚拟内存的操作

接着我们分别通过分配时机、分配过程两部分,来看看Go语言栈内存和堆内存的分配。
Go语言栈内存的分配
Go语言栈内存分配的时机
创建
Goroutinue时
1.1 创建
g01.2 创建
g
栈扩容时
栈内存分配时机-创建Goroutinue时
创建g0函数代码片段:
// src/runtime/proc.go::1720
// 创建 m
func allocm(_p_ *p, fn func(), id int64) *m {
// ...略
if iscgo || mStackIsSystemAllocated() {
mp.g0 = malg(-1)
} else {
// 创建g0 并申请8KB栈内存
// 依赖的malg函数
mp.g0 = malg(8192 * sys.StackGuardMultiplier)
}
// ...略
}创建g函数代码片段:
// src/runtime/proc.go::3999
// 创建一个带有任务fn的goroutine
func newproc1(fn *funcval, argp unsafe.Pointer, narg int32, callergp *g, callerpc uintptr) *g {
// ...略
newg := gfget(_p_)
if newg == nil {
// 全局队列、本地队列找不到g 则 创建一个全新的goroutine
// _StackMin = 2048
// 申请2KB栈内存
// 依赖的malg函数
newg = malg(_StackMin)
casgstatus(newg, _Gidle, _Gdead)
allgadd(newg)
}
// ...略
}以上都依赖malg函数代码片段,其作用是创建一个全新g:
// src/runtime/proc.go::3943
// 创建一个指定栈内存的g
func malg(stacksize int32) *g {
newg := new(g)
if stacksize >= 0 {
// ...略
systemstack(func() {
// 分配栈内存
newg.stack = stackalloc(uint32(stacksize))
})
// ...略
}
return newg
}栈内存分配时机-栈扩容
// src/runtime/stack.go::838
func copystack(gp *g, newsize uintptr) {
// ...略
// 分配新的栈空间
new := stackalloc(uint32(newsize))
// ...略
}结论:创建Goroutine和栈扩容时,栈内存的分配都是由函数stackalloc分配。

所以,我们通过分析stackalloc函数就可以知道栈内存的分配过程了,具体如下。
栈内存分配过程
Go语言栈内存的分配按待分配的栈大小分为两大类:
小于32KB的栈内存
大于等于32KB的栈内存
小于32KB栈分配过程
1. 先去M线程缓存mcache的栈内存缓存stackcache中分配:

2. 如果stackcache内存不足,则从全局栈内存缓存池stackpool中分配:

3. 如果stackpool内存不足,则从逻辑处理器结构p中的p.pagecache中分配:

4. 如果p.pagecache内存不足,则从堆mheap中分配:

大于等于32KB栈分配过程
1. 直接从全局栈内存缓存池stackLarge中分配:

2. 全局栈内存缓存池stackLarge不足,则从逻辑处理器结构p中的p.pagecache中分配,如果p.pagecache则去堆上mheap分配:

Go语言堆内存的分配
想要更好的理解Go堆内存分配需要先了解Go的内存三层架构以及Go的内存管理单元mspan。历史文章请查看:
「浅析Go内存管理架构」
「9张图轻松吃透Go内存管理单元」
Go语言堆内存分配时机
判断一个变量是否应该分配到「堆内存」的关键点就是:代码编译阶段,编译器会通过逃逸分析判断并标记上该变量是否需要分配到堆上。
通常我们在创建如下变量时,变量都有可能被分配到堆上:
切片
Slice创建切片时
切片扩容时
拷贝切片时
创建数组时
创建
Channel时Map
创建
Map时Map扩容时
等等
涉及相关数据类型的写操作函数整理如下:
表格可左右滑动查看
| 类型 | 名称 | 描述 | 代码位置 |
|---|---|---|---|
| 切片 | makeslice(et *_type, len, cap int) unsafe.Pointer |
创建切片 | src/runtime/slice.go::83 |
| 切片 | growslice(et *_type, old slice, cap int) slice |
切片扩容 | src/runtime/slice.go::125 |
| 切片 | makeslicecopy(et *_type, tolen int, fromlen int, from unsafe.Pointer) unsafe.Pointer |
copy切片 | src/runtime/slice.go::36 |
| 字节字符串 | gobytes(p *byte, n int) (b []byte) |
转换字符串string为[]byte类型 |
src/runtime/string.go::301 |
| 字节字符串 | slicebytetostring(buf *tmpBuf, ptr *byte, n int) (str string) |
转换字节字符串[]byte为类型string |
src/runtime/string.go::80 |
| 字节字符串 | rawstring(size int) (s string, b []byte) |
按大小初始化一个新的string类型 |
src/runtime/string.go::83 |
| 字节字符串 | rawbyteslice(size int) (b []byte) |
按大小初始化一个新的[]byte类型 |
src/runtime/string.go::83 |
| 字节字符串 | rawruneslice(size int) (b []rune) |
按大小初始化一个新的[]rune类型 |
src/runtime/string.go::83 |
| Channel | makechan(t *chantype, size int) *hchan |
创建一个chan |
src/runtime/chan.go::71 |
| 数组 | func newarray(typ *_type, n int) unsafe.Pointer |
初始化一个数组 | src/runtime/malloc.go::1191 |
| Map | mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer |
map申请内存 | src/runtime/map.go::571 |
| Map | func (h *hmap) newoverflow(t *maptype, b *bmap) *bmap |
map申请溢出桶 | src/runtime/map.go::245 |
| 等等 | ... | ... |
这里我们以初始化切片的源代码为例来看看切片何时被分配到堆上的逻辑判断:
理论上直接分配到栈内存上
编译器进行逃逸分析,判断并标记该变量是否需要分配到堆上
否:直接分配在栈上
是:调用
src/runtime/slice.go::makeslice()分配到堆上
切片分配过程源代码如下:
// 代码位置:src/cmd/compile/internal/gc/walk.go::1316
// 初始化切片
case OMAKESLICE:
// ...略...
// 逃逸标识,是否需要逃逸到堆上
if n.Esc == EscNone {
// ...略...
// 不需要逃逸
// 直接栈上分配内存
t = types.NewArray(t.Elem(), i) // [r]T
// ...略...
} else {
// 需要内存逃逸到堆上
// ...略...
// 默认使用makeslice64函数从堆上分配内存
fnname := "makeslice64"
argtype := types.Types[TINT64]
// ...略...
if (len.Type.IsKind(TIDEAL) || maxintval[len.Type.Etype].Cmp(maxintval[TUINT]) <= 0) &&
(cap.Type.IsKind(TIDEAL) || maxintval[cap.Type.Etype].Cmp(maxintval[TUINT]) <= 0) {
// 校验通过,则
// 使用makeslice函数从堆上分配内存
fnname = "makeslice"
argtype = types.Types[TINT]
}
// ...略...
// 调用上面指定的runtime函数
m.Left = mkcall1(fn, types.Types[TUNSAFEPTR], init, typename(t.Elem()), conv(len, argtype), conv(cap, argtype))
// ...略...
}最终分配堆内存的地方都会依赖函数mallocgc,我们通过阅读mallocgc的代码就可以看到堆内存的分配过程。

Go语言堆内存分配过程
堆内存的分配按对象的大小分,主要分为三大类:
微对象 0 < Micro Object < 16B
小对象 16B =< Small Object <= 32KB
大对象 32KB < Large Object
「微对象」和「小对象」通常通过逻辑处理器结构P的线程缓存mcache分配,「大对象」直接从堆上mheap中分配,如下图所示:

线程缓存
mcache的tiny结构主要负责分配「微对象」线程缓存
mcache的alloc结构主要负责分配「小对象」

微对象的分配过程
微对象 0 < Micro Object < 16B
1. 线程缓存mcache的tiny内存充足,则直接分配「微对象」所需内存,图示如下:

2. 线程缓存mcache的tiny内存不足,先去线程缓存mcache的alloc申请16B给tiny,再分配「微对象」所需内存,简易图示如下:

申请16B详细过程图示如下:
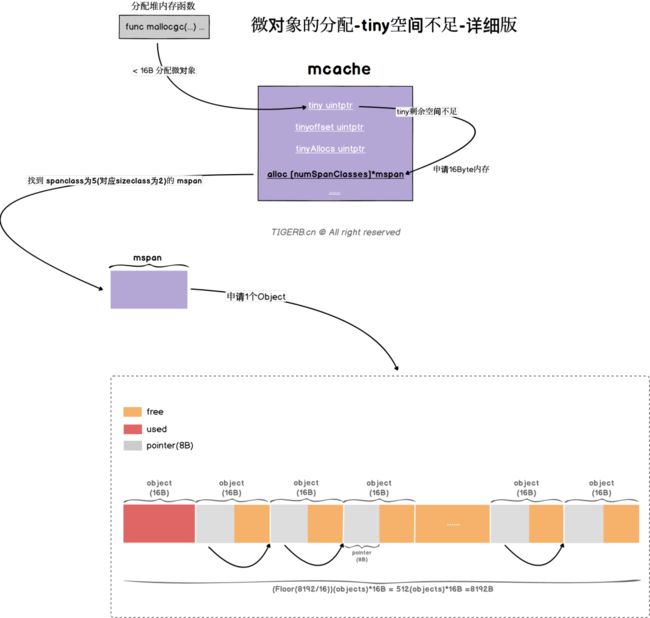
小对象的分配过程
小对象 16B =< Small Object <= 32KB
1. 线程缓存mcache的alloc充足,则直接分配「小对象」所需内存,简易图示如下:

详细分配过程图示如下:

2. 线程缓存mcache的alloc不足,则去中央缓存mcentral获取一个mspan,再分配「小对象」所需内存,图示如下:

3. 线程缓存mcache的alloc不足,且中央缓存mcentral不足,则去逻辑处理器结构的pagecache分配,如果pagecache直接去堆上mheap获取一个mspan,再分配「小对象」所需内存,图示如下:

大对象的分配过程
大对象 32KB < Large Object
1. 逻辑处理器结构的pagecache充足,则直接分配「大对象」所需内存,图示如下:

2. 逻辑处理器结构的pagecache不足,则直接去堆上mheap分配「大对象」所需内存,图示如下:

总结
Go语言源代码中「栈内存」和「堆内存」的分配都是虚拟内存,最终CPU在执行指令过程中通过内部的MMU把虚拟内存转化为物理内存。
Go语言编译期间会进行逃逸分析,判断并标记变量是否需要分配到堆上,比如创建
Map、Slice时。栈内存分配
小于32KB的栈内存
来源优先级1:线程缓存
mcache来源优先级2:全局缓存
stackpool来源优先级3:逻辑处理器结构
p.pagecache来源优先级4:堆
mheap
大于等于32KB的栈内存
来源优先级1:全局缓存
stackLarge来源优先级2:逻辑处理器结构
p.pagecache来源优先级3:堆
mheap
堆内存分配
微对象 0 < Micro Object < 16B
来源优先级1:线程缓存
mcache.tiny来源优先级2:线程缓存
mcache.alloc
小对象 16B =< Small Object <= 32KB
来源优先级1:线程缓存
mcache.alloc来源优先级2:中央缓存
mcentral来源优先级3:逻辑处理器结构
p.pagecache来源优先级4:堆
mheap
大对象 32KB < Large Object
来源优先级1:逻辑处理器结构
p.pagecache来源优先级2:堆
mheap
「栈内存」也来源于堆
mheap

Go轻松进阶系列 更多文章
由浅到深,入门Go语言Map实现原理
为什么说Go的Map是无序的?
64位平台下,指针自身的大小为什么是8字节?
18张图解密新时代内存分配器TCMalloc
浅析Go内存管理架构
关于Go内存架构,一个有趣的问题
9张图轻松吃透Go内存管理单元
![]()
![]()