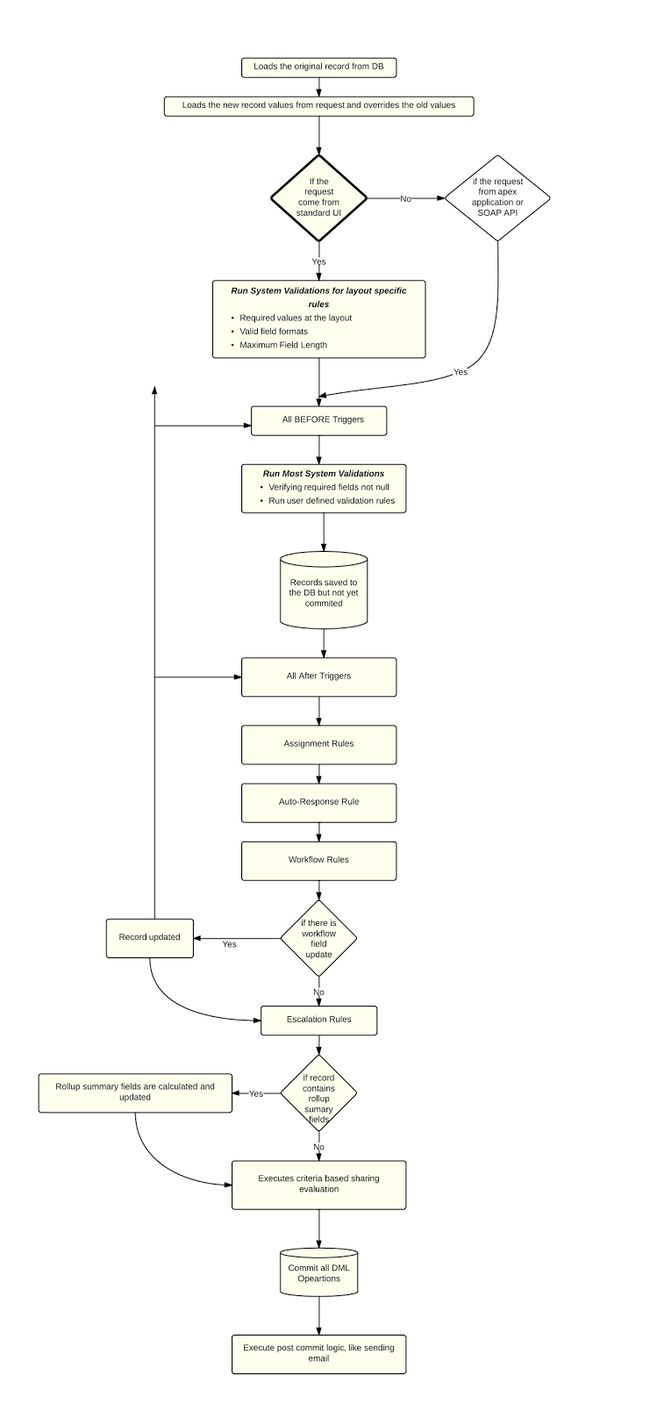
salesforce开发中,我们会对object进行很多的操作,比如对object设置字段的必填性唯一性等,设置validation rule实现一下相关的字段的逻辑校验,设置workflow实现某个字段的更改或者发送邮件等,设置trigger实现before和after的数据相关逻辑处理,设置sharing setting实现数据share,设置master detail的rollup summary字段等。当这些操作铺天盖地的上来时,你还搞得清楚当新增/修改一条记录以后到底怎么运行的吗?有了下面的图以后(从国外博客盗的图,忘记了链接,不好意思),相信可以以后对于这些操作的处理顺序变得游刃有余。
1.当数据进行新增/修改操作时,从DB中获取原始数据;
2.从request中加载新数据的value;
3.如果请求来自标准的UI,UI上面可以自动check相关的pagelayout上的必填性校验等,相关字段必填性配置可以放在page layout做限制;
4.如果请求来自自定义的VF页面或者apex进行匿名块操作,则先忽略相关pagelayout上的必填性校验,执行before trigger内容;
5.运行系统的校验,比如字段级别的必填性,validation rule;
6.当通过validation rule以后,执行save操作,此时数据保存到DB,不过事务上还没有commit,在after trigger及以后如果此obj有addError类似操作,会导致数据的rollback,简单demo:
1 trigger GoodsTrigger on Goods__c (after insert) { 2 if(trigger.isAfter) { 3 if(trigger.isInsert) { 4 ListgoodsList = trigger.new; 5 for(Goods__c goods : goodsList) { 6 goods.addError('测试错误提示信息'); 7 } 8 } 9 } 10 }
理论上after trigger以前数据已经保存到DB上了,但是因为after操作对object进行了addError操作,导致事务回滚,添加失败。

7.执行after trigger操作;
8.通过sharing rule分配相关数据共享操作;
9.执行workflow rules,workflow rules可以执行field update,如果进行了field update以后会重新执行before trigger,workflow rules可以设置field update只是进行一次还是每次更改都会进入workflow rules,这里根据需求好好选择,避免和trigger作用发生死循环;
10.如果有rollup summary字段,更新rollup summary;
11.提交事务,此时才真正事务commit,7-10期间 如果有addError类似操作便会使数据rollback;
12.如果有email send操作,发送邮件。
总结:了解数据处理的顺序无论对初学者还是有经验的人来说都是必要的,因为有的时候,因为执行顺序的问题可能导致意想不到的错误发生。千里之行,始于足下,打好基础方能放眼未来。如果篇中有描述错误的地方欢迎指出,有问题欢迎留言。
