spark sql(五)sparksql支持查询哪些数据源,查询hive与查询mysql的区别
1、数据源介绍
sparksql默认查询的数据源是hive数据库,除此之外,它还支持其它类型的数据源查询,具体的到源码中看一下:

可以看到sparksql支持查询的数据源有CSV、parquet、json、orc、txt、jdbc。这些数据源中前面五个我还能理解,最后jdbc数据源我就有了一些疑问,因为很多数据库都支持jdbc连接。那么sparksql是支持所有的jdbc数据源连接吗,sparksql通过jdbc查询还会经过逻辑计划、物理计划这些处理流程吗。还有就是sparksql默认查询的hive数据源是通过jdbc吗?
2、样例代码
针对问题编辑了如下代码:
def main(args: Array[String]): Unit = {
val sparkSession = SparkSession.builder.appName("wyt01bigdata").master("local").enableHiveSupport().getOrCreate
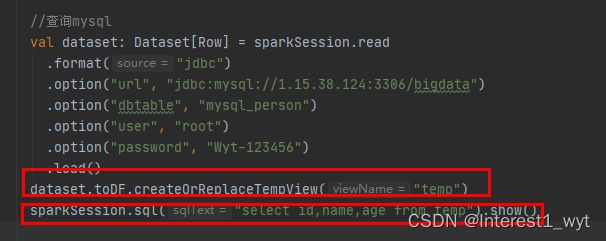
//查询mysql
val dataset: Dataset[Row] = sparkSession.read
.format("jdbc")
.option("url", "jdbc:mysql://1.15.38.124:3306/bigdata")
.option("dbtable", "mysql_person")
.option("user", "root")
.option("password", "Wyt-123456")
.load()
dataset.toDF.createOrReplaceTempView("temp")
sparkSession.sql("select id,name,age from temp").show()
//查询hive
sparkSession.sql("select id,name,age from wyt.hive_person").show()
}下面就带着问题追踪下sparksql的执行代码。
3、源码追踪
在样例代码中,首先是创建一个sparkSession,这是sparksql查询的入口。其次创建DataFrameReader对象,并指定要读取的数据源为jdbc,随后的option方法设定了jdbc的连接参数。接下来的load方法便是重中之重,接下来我们深入看一下。

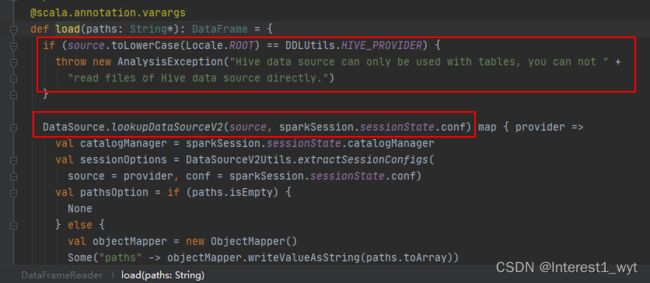
首先看第一块圈起来的代码,这里的source便是样例demo中format方法设置的数据源类型,load方法首先是判断当前的数据源是不是hive,因为hive数据源可以直接查询,所以hive查询调用该方法会抛异常。接下来再看核心方法lookupDataSourceV2。
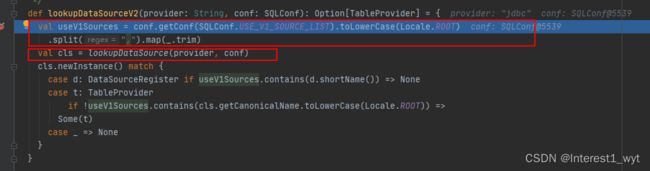
首先获取datasourcev1支持的数据源列表,可以看到其支持的数据源有avro、csv、json、kafka、orc、parquet、text。这比我们从方法类中看到的还多。

其次根据设置的数据源类型,以向后兼容的方式查找数据源对应的定义类。具体的到lookupDataSource方法中查看:

在第一块圈起来的地方backwardCompatibilityMap是一个记录了数据源和对应定义类的集合,然后通过模式匹配进行查找。因为我们的数据源类型是jdbc,所以会直接返回。第二个圈起来的模块是获取当前线程或者spark应用的类加载器,然后将要加载的DataSourceRegister类型和类加载封装成一个服务工具类。第三个圈起来的模块是最难理解的,其关键在于要对迭代遍历有很深的了解。下面我们主要介绍一下:
在第二个圈起来的部分,我们可以知道,当前封装的类加载工具类,包含了一个类加载器和要加载的类型。然后在第三部分用到了filter语句,这明显是一个迭代遍历的过程。迭代遍历一个对象通用的方式就是通过iterator迭代器进行遍历。所以我们到ServiceLoader类中查看一下关键的hasNext和next方法。

在hasNext中,会根据上下文情况分成两个处理逻辑,但是核心都是调用hasNextService,所以我们接着到hasNextService中看一下处理逻辑(因为下面的代码逻辑比较绕,所以没有贴图片)。
private boolean hasNextService() {
//如果下次迭代的类全路径名称存在,则直接返回
if (nextName != null) {
return true;
}
//如果资源文件枚举为空
if (configs == null) {
try {
//要加载的资源文件全路径名称 META-INF/services/org.apache.spark.sql.sources.DataSourceRegister(该文件中包含的是数据源提供类的全路径名称)
String fullName = PREFIX + service.getName();
//获取要加载的资源文件枚举对象
if (loader == null)
configs = ClassLoader.getSystemResources(fullName);
else
configs = loader.getResources(fullName);
} catch (IOException x) {
fail(service, "Error locating configuration files", x);
}
}
//获取每个资源文件中记录的类全路径名称
//每个文件中可能会包含多个类全路径名称,这些都放在pending中,当pending中迭代完之后,会再次迭代configs获取下一个资源文件中的所有全路径名称,并赋值给pending
while ((pending == null) || !pending.hasNext()) {
if (!configs.hasMoreElements()) {
return false;
}
//解析资源文件中的类全路径名称
pending = parse(service, configs.nextElement());
}
nextName = pending.next();
return true;
}
理解这段代码的关键是要知道资源文件迭代和资源文件中的内容迭代,其中资源文件迭代是configs,它迭代的是所有依赖jar包中的META-INF/services/org.apache.spark.sql.sources.DataSourceRegister文件,,其次资源文件中的内容迭代是pending,每个资源文件可能包含多个URL类信息(类全路径名称)。然后再来看下next方法:

next方法也是根据上下文情况分成两种处理逻辑,但是核心也是调用nextService方法,所以我们来看下nextService方法:

nextService方法中主要做了两件事,一个是将全路径类加载到jvm中,另一个则是通过加载的类创建实例并放入集合中。
另外需要注意next方法返回的值,这个值就是filter方法中的入参,而且这个值的类型是Class。至此我们可以推断出filter方法的作用是迭代加载所有的数据源提供者,并过滤出"jdbc"数据源提供者。
接下来我们在看过滤之后的匹配处理,总共有三个大的处理逻辑:
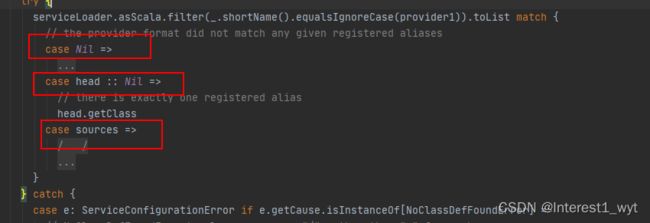
一是如果没有任何匹配的数据源提供类,则直接加载数据源类型,如果加载失败则抛异常。
二是如果只匹配了一个数据源,则直接返回对应的class类。
三是如果找到了多个指定的数据源提供类,则会查找是否有org.apache.spark开头的类,如果没有则抛异常声明找到多个类。
因为只找到了一个jdbc类,所以会走第二个逻辑直接返回,我们再回到上一层:
 因为没有匹配jdbc的情况,所以最终返回none。接着我们再回到上一层查看逻辑。
因为没有匹配jdbc的情况,所以最终返回none。接着我们再回到上一层查看逻辑。
 可以看到当lookupDataSourceV2方法为空时,最后的getOrElse会被执行,所以接着到loadV1Source中方法中查看。
可以看到当lookupDataSourceV2方法为空时,最后的getOrElse会被执行,所以接着到loadV1Source中方法中查看。

可以看到loadV1Source方法中首先创建一个数据源实例,然后调用该实例的resolveRelation方法(注意该方法最终返回的是一个DataFrame对象)。那接下来我们再到resolveRelation方法中看一下。

在该方法中首先会根据我们的全路径类名创建一个数据源提供类,然后进行模式匹配,因为我们匹配上的是jdbc数据源提供类,所以在createRelation方法中会调用JdbcRelationProvider的方法。我们再接着看下:
override def createRelation(
sqlContext: SQLContext,
parameters: Map[String, String]): BaseRelation = {
//获取代码中输入的jdbc连接参数
val jdbcOptions = new JDBCOptions(parameters)
val resolver = sqlContext.conf.resolver
val timeZoneId = sqlContext.conf.sessionLocalTimeZone
//获取表的字段信息
val schema = JDBCRelation.getSchema(resolver, jdbcOptions)
//根据配置获取表的分区信息(如果配置了多分区,那么会针对不同的分区生成不同where语句,进而加快查询效率)
val parts = JDBCRelation.columnPartition(schema, resolver, timeZoneId, jdbcOptions)
JDBCRelation(schema, parts, jdbcOptions)(sqlContext.sparkSession)
}该方法中比较关键的是获取表的字段信息和获取分区信息,由于分区比较复杂,为避免文章内容跟标题不符合,所以不过多讲解,感兴趣的可以自行查看。我们看下如何获取表的字段信息:



可以看到最终其实是通过sql语句查询不存在的表数据,进而获得的表字段信息。然后让我们再顺着流程走,最后通过jdbc连接获得了一个DataFrame。该DataFrame记录了表字段信息和jdbc数据源连接信息。
回到写的样例demo中,我们接着向下看:
接着将数据源注册成一个临时视图,并进行查询(这块的逻辑计划过程再前面的文章中有讲,物理计划的执行过程因为没总结完善所以暂时没发布)。 查询时逻辑计划的处理过程都是一样的,但是在物理计划执行的时候不同的数据源有不同的逻辑。
至此我们jdbc的查询讲解结束了,接下来我们看下hive的查询过程,看看hive是不是也通过jdbc查询的数据。
在前面的文章中我们讲解了sql库表解析主要依赖于Analyzer的ResolveRelations规则,我们直接到该解析规则中进行查看。

首先源码中会解析视图,由于没有注册hive_person视图是,所以会跳到第二个红框中执行。



接着执行getTable时,externalCatalog对象是一个trait,可以从debug断点中查看具体的对象名称,然后接着向下看:




至此可以看到,sparksql查询hive时,其元数据是通过client客户端进行交互获取的,至于client客户端的最底层是通过什么原理获取表数据,这里不再追究。感兴趣的可以自行查阅。另外上述比较关键的delegate为什么是HiveExeternalCatalog,这个主要是因为demo中使用了enableHiveSupport,这个展开讲篇幅又会很多,所以这里只留个提示。有兴趣的同样可以自行查阅。
上面说了hive元数据的获取是通过client的方式,那么具体数据的读取是通过什么方式呢,这个可以到具体的物理算子HiveTableScanExec中查看,可以看到其是通过hadoopReader进行的数据读取。

至此,hive的查询过程也大致讲解完毕,因为时间和个人能力问题。有些地方讲解的不够细致,希望没有给兄弟们带来误导。
4、总结
1)sparksql支持的数据源有avro、csv、json、kafka、orc、parquet、text、jdbc、hive等,也支持自定义数据源(下一章会讲解自定义数据源用法)
2)sparksql支持所有的jdbc连接,所有的jdbc sql会统一经历 sql->语法树->逻辑计划->物理计划->sql的过程。
3)sparksql查询hive是通过client和hadoopReader。
4)查询hive和查询mysql主要的区别就是一个通过jdbc一个不通过jdbc。
5)META-INF/services/org.apache.spark.sql.sources.DataSourceRegister中包含的数据源提供者的全路径名称
5、引申
5.1 DataSourceV2和DataSourceV1区别
DataSource API v1 版本于 Spark 1.3 发布。根据社区反馈,它具有下面的限制:
1)由于其输入参数包括 DataFrame / SQLContext,因此 DataSource API 兼容性取决于这些上层的 API。
2)物理存储信息(例如,划分和排序)不会从数据源传播,并且因此,Spark 的优化器无法利用。
3)可扩展性不好,并且算子的下推能力受限。
4)缺少高性能的列式读取接口。
5)写入接口是如此普遍,不支持事务。
由于上面的限制和问题, Spark SQL 内置的数据源实现(如 Parquet,JSON等)不使用这个公共 DataSource API。相反,他们使用内部/非公共的接口。这样很难使得外部的数据源实现像内置的一样快。在这样的背景下,DataSource API v2 版本应运而生。DataSource API v2版本旨在提供一个高性能的,易于维护的,易于扩展的外部数据源接口。
5.2 如果hive中的表和注册的视图同名,那么最终会查询哪个数据。
会查视图,因为源码中查询的顺序是先查视图再查数据源