Elasticsearch 入门及使用
目录
一、前言
二、ES的概念及使用场景
三、基本概念
3.1、文档(Document)
3.2、类型(Type)
3.3、索引(Index)
3.4、节点(node)
3.5、分片(shard)
3.6、副本分片(replica shard)
四、极速安装配置
五、基础使用
5.1、索引基础操作
创建一个空索引
修改副本
删除索引
5.2、数据增删改查
插入数据
修改数据
查询数据
删除数据
六、SpringBoot集成ES
1.pom.xml
2.application.properties
3.创建员工对象实体类 和 分页类
4.创建config类
5.创建ES操作工具类
6.创建controller
七、总结
一、前言
本文版本说明:
ElasticSearch版本:7.7 (目前最新版)
Kibana版本:7.7(目前最新版)
ElasticSearch在实际生产里通常和LogStash,Kibana,FileBeat一起构成Elastic Stack来使用,它是这些组件里面最核心的一个。因此学好ElasticSearch的必要性不言而喻,但是由于ElasticSearch官方更新太过频繁且文档陈旧,同时在Linux下安装配置的过程较繁杂,不利于入门使用。
为了帮助大家快速入门ElasticSearch,并掌握ElasticSearch和Kibana的使用。本文会把最新版的ElasticSearch的知识点用通俗易懂的语言来展现,并会在核心概念上和MySql对比,同时给大家介绍百分百成功的极速安装配置方法,让大家可以把时间更多的用在技术研究上。
注意:下文咱们把ElasticSearch简称为ES,对可能出现的疑问进行标红并解释。 
二、ES的概念及使用场景
ElasticSearch是一个分布式,高性能、高可用、可伸缩、RESTful 风格的搜索和数据分析引擎。通常作为Elastic Stack的核心来使用,Elastic Stack大致是如下这样组成的: 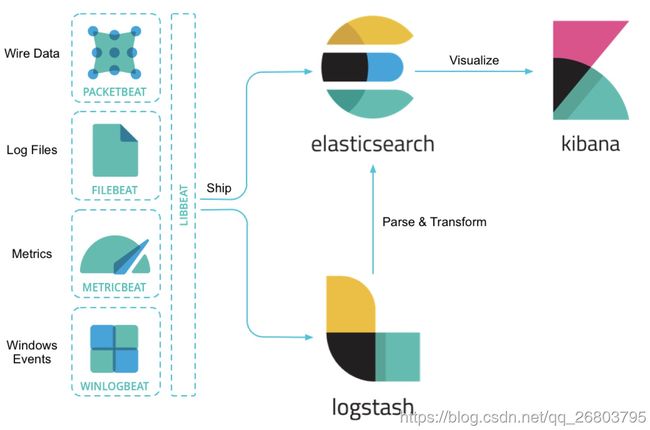
ES是一个近实时(NRT)的搜索引擎,一般从添加数据到能被搜索到只有很少的延迟(大约是1s),而查询数据是实时的。一般我们可以把ES配合logstash,kibana来做日志分析系统,或者是搜索方面的系统功能,比如在网上商城系统里实现搜索商品的功能也会用到ES。
疑问一:搜索商品的时候为啥要用ES呢?用sql的like进行模糊查询,它不香吗?
我们假设一个场景:我们要买苹果吃,咱们想买天水特产的花牛苹果,然后在搜索框输入
天水花牛苹果,这时候咱们希望搜索到所有的售卖天水花牛苹果的商家,但是如果咱们技术上根据这个天水花牛苹果使用sql的like模糊查询,是不能匹配到诸如天水特产花牛苹果,天水正宗,果园直送精品花牛苹果这类的不连续的店铺的。所以sql的like进行模糊查询来搜索商品还真不香!
三、基本概念
很多人第一次学习ES,看到基本概念后瞬间懵逼了,这是啥玩意呀,乱七八糟!别急,我整理了一下ES和mysql相关的基本概念的对比表格,先看一下:
| ES | MySql |
|---|---|
| 字段 | 列 |
| 文档 | 一行数据 |
| 类型(已废弃) | 表 |
| 索引 | 数据库 |
看完这个表格后,建议像背单词那样盖住右半部分的MySql,通过左边的概念来联想在MySql里的概念,加深记忆! 然后我们组合起来,所谓ES里的数据其实就是指索引下的类型里面的JSON格式的数据。
下面我们对这些概念分别进行详细的解释:
3.1、文档(Document)
-
我们知道Java是面向对象的,而Elasticsearch是面向文档的,也就是说文档是所有可搜索数据的最小单元。ES的文档就像MySql中的一条记录,只是ES的文档会被序列化成json格式,保存在Elasticsearch中;
-
这个json对象是由字段组成,字段就相当于Mysql的列,每个字段都有自己的类型(字符串、数值、布尔、二进制、日期范围类型);
-
当我们创建文档时,如果不指定字段的类型,Elasticsearch会帮我们自动匹配类型;
-
每个文档都有一个ID,类似MySql的主键,咱们可以自己指定,也可以让Elasticsearch自动生成;
-
文档的json格式支持数组/嵌套,在一个索引(数据库)或类型(表)里面,你可以存储任意多的文档。
注意:虽然在实际存储上,文档存在于某个索引里,但是文档必须被赋予一个索引下的类型才可以。
3.2、类型(Type)
类型就相当于MySql里的表,我们知道MySql里一个库下可以有很多表,最原始的时候ES也是这样,一个索引下可以有很多类型,但是从6.0版本开始,type已经被逐渐废弃,但是这时候一个索引仍然可以设置多个类型,一直到7.0版本开始,一个索引就只能创建一个类型了(_doc)。这一点,大家要注意,网上很多资料都是旧版本的,没有对这点进行说明。
3.3、索引(Index)
-
索引就相当于MySql里的数据库,它是具有某种相似特性的文档集合。反过来说不同特性的文档一般都放在不同的索引里;
-
索引的名称必须全部是小写;
-
在单个集群中,可以定义任意多个索引;
-
索引具有mapping和setting的概念,mapping用来定义文档字段的类型,setting用来定义不同数据的分布。
除了这些常用的概念,我们还需要知道节点概念的作用,因此咱们接着往下看!
3.4、节点(node)
-
一个节点就是一个ES实例,其实本质上就是一个java进程;
-
节点的名称可以通过配置文件配置,或者在启动的时候使用
-E node.name=ropledata指定,默认是随机分配的。建议咱们自己指定,因为节点名称对于管理目的很重要,咱们可以通过节点名称确定网络中的哪些服务器对应于ES集群中的哪些节点; -
ES的节点类型主要分为如下几种:
-
Master Eligible节点:每个节点启动后,默认就是Master Eligible节点,可以通过设置
node.master: false来禁止。Master Eligible可以参加选主流程,并成为Master节点(当第一个节点启动后,它会将自己选为Master节点);注意:每个节点都保存了集群的状态,只有Master节点才能修改集群的状态信息。 -
Data节点:可以保存数据的节点。主要负责保存分片数据,利于数据扩展。
-
Coordinating 节点:负责接收客户端请求,将请求发送到合适的节点,最终把结果汇集到一起
-
-
注意:每个节点默认都起到了Coordinating node的职责。一般在开发环境中一个节点可以承担多个角色,但是在生产环境中,还是设置单一的角色比较好,因为有助于提高性能。
3.5、分片(shard)
了解分布式或者学过mysql分库分表的应该对分片的概念比较熟悉,ES里面的索引可能存储大量数据,这些数据可能会超出单个节点的硬件限制。
为了解决这个问题,ES提供了将索引细分为多个碎片的功能,这就是分片。这里咱们可以简单去理解,在创建索引时,只需要咱们定义所需的碎片数量就可以了,其实每个分片都可以看作是一个完全功能性和独立的索引,可以托管在集群中的任何节点上。
疑问二:分片有什么好处和注意事项呢?
通过分片技术,咱们可以水平拆分数据量,同时它还支持跨碎片(可能在多个节点上)分布和并行操作,从而提高性能/吞吐量;
ES可以完全自动管理分片的分配和文档的聚合来完成搜索请求,并且对用户完全透明;
主分片数在索引创建时指定,后续只能通过Reindex修改,但是较麻烦,一般不进行修改。
3.6、副本分片(replica shard)
熟悉分布式的朋友应该对副本对概念不陌生,为了实现高可用、遇到问题时实现分片的故障转移机制,ElasticSearch允许将索引分片的一个或多个复制成所谓的副本分片。
疑问三:副本分片有什么作用和注意事项呢?
当分片或者节点发生故障时提供高可用性。因此,需要注意的是,副本分片永远不会分配到复制它的原始或主分片所在的节点上;
可以提高扩展搜索量和吞吐量,因为ES允许在所有副本上并行执行搜索;
默认情况下,ES中的每个索引都分配5个主分片,并为每个主分片分配1个副本分片。主分片在创建索引时指定,不能修改,副本分片可以修改。
看到这里,各位一定对ES有所了解了,那么接下来就是安装配置并使用了!有不少朋友初学时查阅资料,选择安装win版本,这里我不推荐,因为实际工作中,ES不可能安装在win下。但是根据官方文档安装Linux版本时,又会遇到各种奇葩问题,咋办呢?别急,我这里有一本极速安装方法,百分百不出错,咱们接着往下看! 
四、极速安装配置
咱们如果想很爽的使用ES,需要安装3个东西:ES、Kibana、ElasticSearch Head。通过Kibana可以对ES进行便捷的可视化操作,通过ElasticSearch Head可以查看ES的状态及数据,可以理解为ES的图形化界面。
那如何进行极速且不出错的安装配置呢?答案很简单,站在巨人的肩膀上!用docker启动前辈们已经配置好的ES环境不就可以了吗?!咱们做开发的应该把时间花在刀刃上,而不是花费大量时间去安装配置。
首先开始安装ES、Kibana,同时安装这两个加启动,一共需要3步,3行代码搞定:
-
搜索docker镜像库里可用的ES镜像:
docker search elasticsearch 1
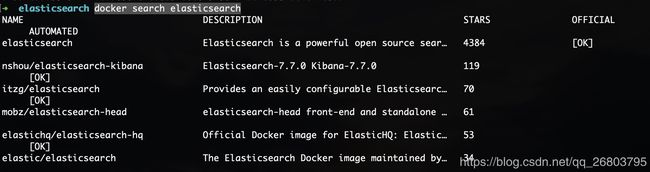
可以看到,stars排名第一的是官方的ES镜像,第二是大牛已经融合了ES7.7和Kibana7.7的镜像,那咱们就用第二个了。
-
把这个镜像从镜像库拉下来:
docker pull nshou/elasticsearch-kibana 1
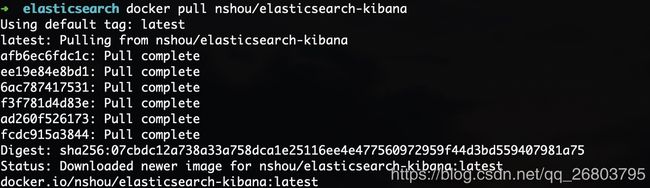
-
最后咱们把镜像启动为容器就可以了,端口映射保持不变,咱们给这个容器命名为eskibana,到这里ES和Kibana就安装配置完成了!容器启动后,它们也就启动了,一般不会出错,是不是非常方便?节省大把时间放到开发上来,这也是我一直推荐docker的原因。
docker run -d -p 9200:9200 -p 9300:9300 -p 5601:5601 --name eskibana nshou/elasticsearch-kibana 1

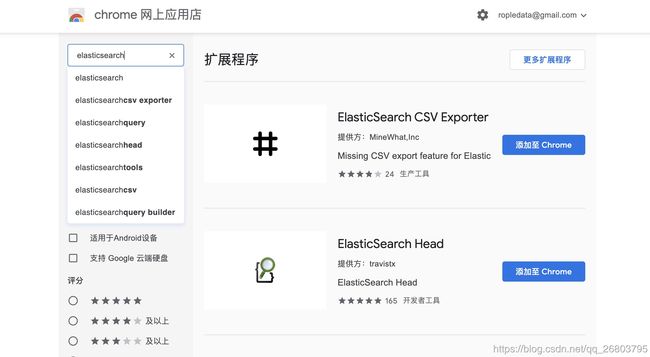
咱们还需要安装ElasticSearch Head,它相当于是ES的图形化界面,这个更简单,它是一个浏览器的扩展程序,直接在chrome浏览器扩展程序里下载安装即可:
-
打开chrome浏览器,在扩展程序chrome应用商店那里,搜索elasticsearch:
-
选择ElasticSearch Head,点击
添加至Chrome,进行扩展程序的安装即可:
到这里咱们的ES、Kibana、ElasticSearch Head都已经安装完成了,下面咱们验证一下,看是否安装成功!
-
验证ES:
打开浏览器,输入IP:端口,比如我的:
http://127.0.0.1:9200/,然后就看到了那句经典的:You Know, for Search: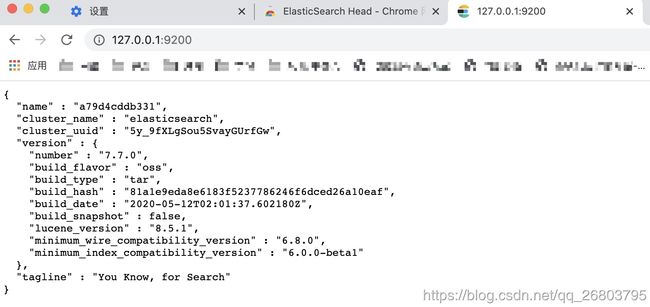
-
验证Kibana:
打开浏览器,输入Kibana的IP:端口,比如我的:
http://127.0.0.1:5601/,然后会看到如下界面: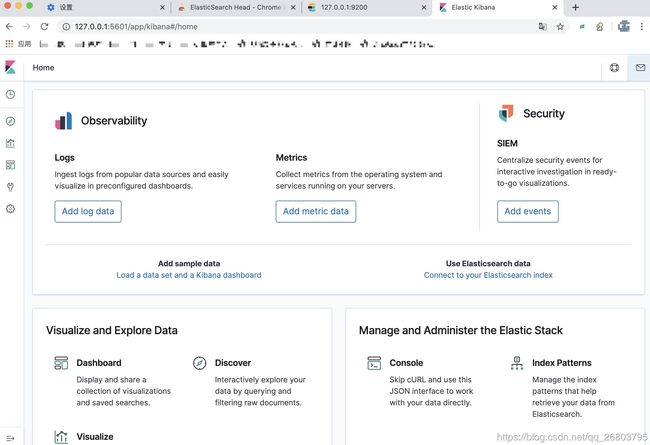
这里面可以提供很多模拟数据,感兴趣的可以自己玩玩,咱们学习期间只要使用左下角那个扳手形状的Dev Tools就可以了,点击后,会出现如下界面:
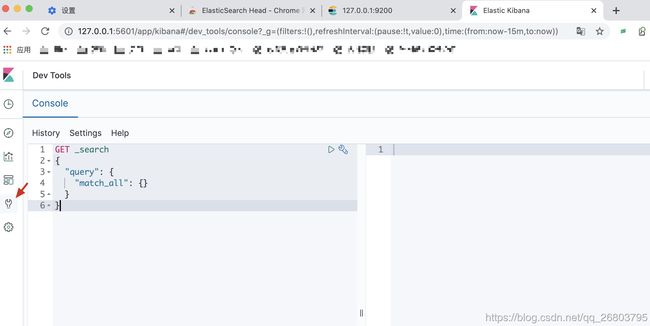
-
验证ES Head:
这个更简单,只需要点击之前咱们安装的那个扩展程序图标就可以了:
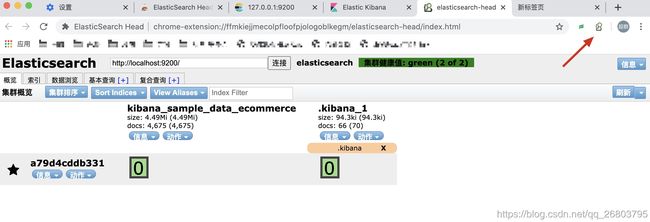 点击信息,还可以看到集群或者索引的信息,很方便,大家没事可以玩一玩,熟悉一下:
点击信息,还可以看到集群或者索引的信息,很方便,大家没事可以玩一玩,熟悉一下: 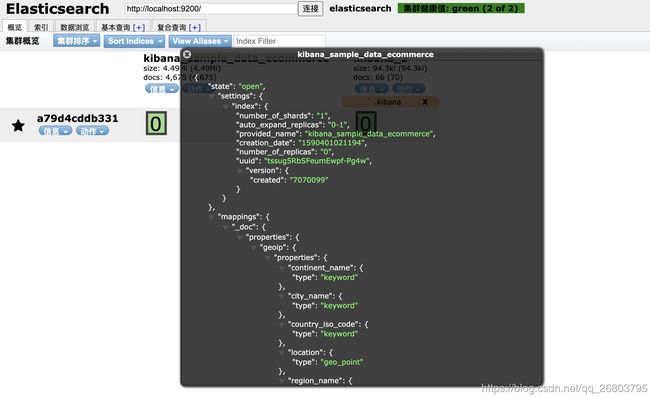
通过验证,我们已经全部安装配置成功了,那么接下来,就让我们一起练习一下基础的增删改查,加深对ES的理解吧!
五、基础使用
前面我们已经介绍过了ES 是RESTful 风格的系统,所以我们需要先掌握RESTful 的四个关键词:PUT(修改),POST(添加),DELETE(删除),GET(查询)。其中在ES里面PUT和POST的界限并不是很分明,有时候PUT也作为添加。 好了,下面就开始愉快的code吧~
5.1、索引基础操作
-
创建一个空索引
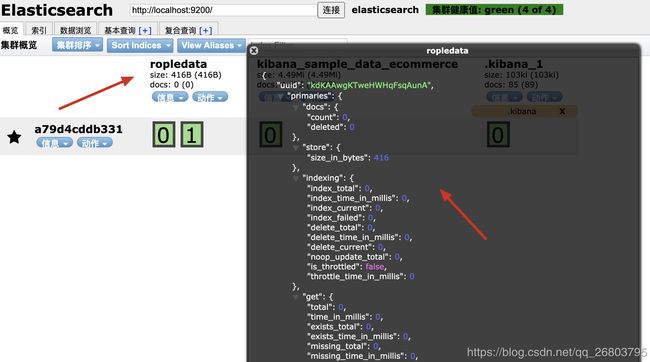
如下代码,咱们创建了一个0副本2分片的ropledata索引,然后咱们可以在Elasticsearch Head里刷新一下,并查看索引的信息:
PUT /ropledata { "settings": { "number_of_shards": "2", "number_of_replicas": "0" } } 1234567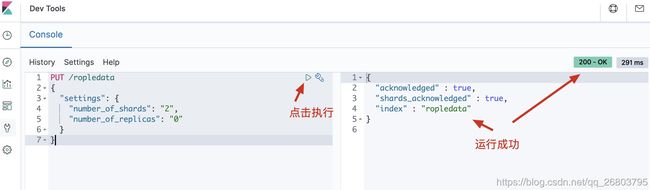
-
修改副本
咱们如果对刚才创建的索引副本数量不满意,可以进行修改,注意:分片不允许修改。
PUT ropledata/_settings { "number_of_replicas" : "2" } 1234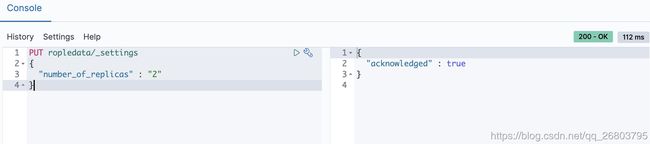
-
删除索引
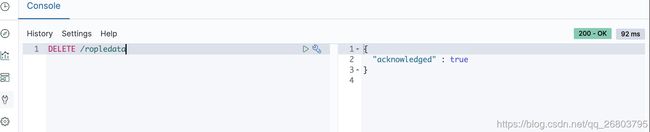
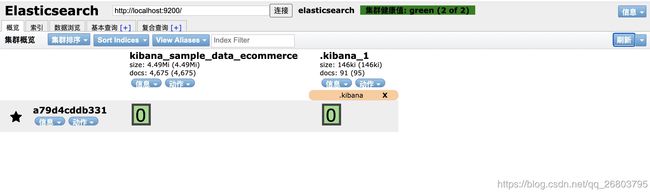
当这个索引不想用了,可以进行删除,执行如下命令即可,执行成功后,刷新ElasticSearch Head可以看到刚才创建的ropledata索引消失了:
DELETE /ropledata 1
5.2、数据增删改查
-
插入数据
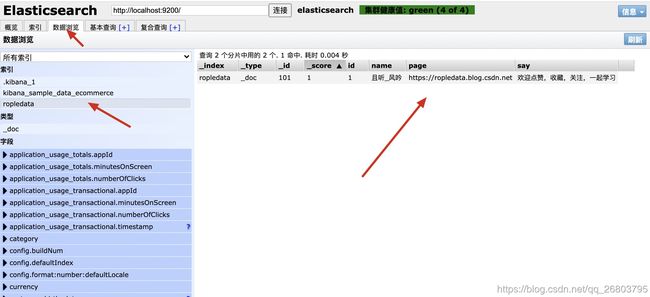
插入数据的时候可以指定id,如果不指定的话,ES会自动帮我们生成。我们以指定id为例,如下代码是我们创建了一个101的文档,创建成功后,可以在Elasticsearch Head的数据浏览模块里看到这些数据,代码及演示如下:
//指定id POST /ropledata/_doc/101 { "id":1, "name":"且听_风吟", "page":"https://ropledata.blog.csdn.net", "say":"欢迎点赞,收藏,关注,一起学习" } 12345678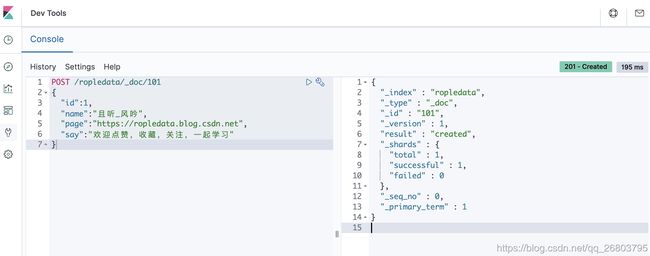
-
修改数据
这里大家要特别注意,ES里的文档是不可以修改的,但是可以覆盖,所以ES修改数据本质上是对文档的覆盖。ES对数据的修改分为全局更新和局部更新,咱们分别进行code并对比:
-
全局更新
PUT /ropledata/_doc/101 { "id":1, "name":"且听_风吟", "page":"https://ropledata.blog.csdn.net", "say":"再次欢迎点赞,收藏,关注,一起学习" } 1234567大家可以多全局更新几次,会发现每次全局更新之后这个文档的
_version都会发生改变!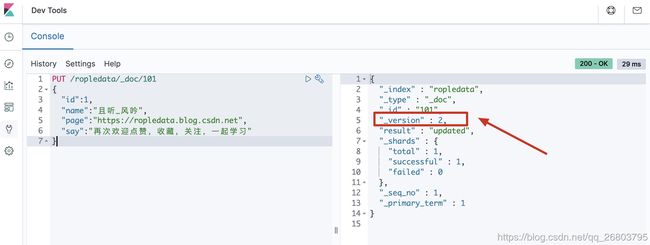
-
局部更新
POST /ropledata/_update/101 { "doc": { "say":"奥力给" } } 1234567这时候我们可以多次去执行上面的局部更新代码,会发现除了第一次执行,后续不管又执行了多少次,
_version都不再变化!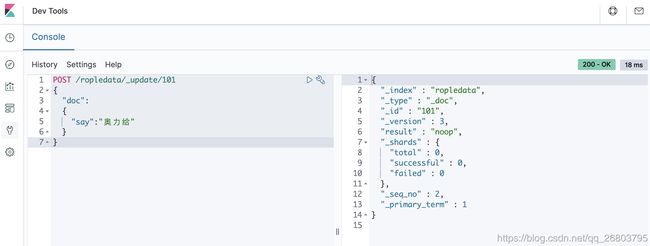
疑问四:局部更新的时候ES底层的流程是怎样的?和全局更新相比性能怎么样?
局部更新的底层流程:
-
内部先获取到对应的文档;
-
将传递过来的字段更新到文档的json中(这一步实质上也是一样的);
-
将老的文档标记为deleted(到一定时候才会物理删除);
-
将修改后的新的文档创建出来。
性能对比:
-
全局更新本质上是替换操作,即使内容一样也会去替换;
-
局部更新本质上是更新操作,只有遇到新的东西才更新,没有新的修改就不更新;
-
局部更新比全局更新的性能好,因此推荐使用局部更新。
-
-
查询数据
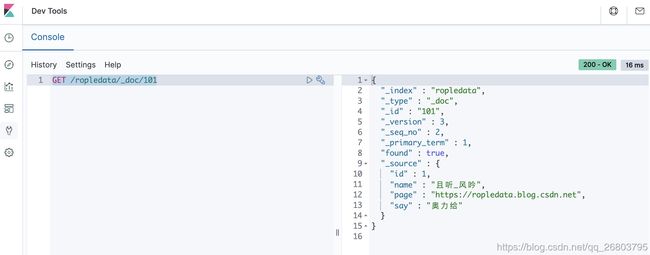
ES的数据查询知识点非常多,也非常复杂,后面我打算单独讲解演示,本文只展示最基本的根据id搜索数据的code:
GET /ropledata/_doc/101 1
-
删除数据
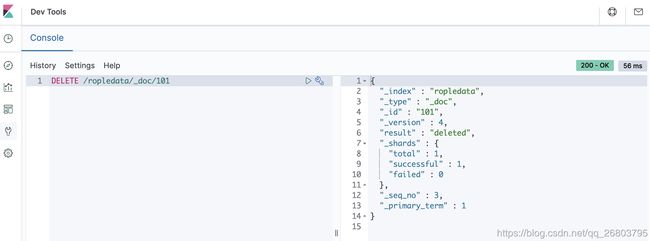
比如我们想把ropledata索引下的id为101的文档删除,可以使用如下命令:
DELETE /ropledata/_doc/101 1
疑问五:查询或者删除的时候指定的ID是文档里面得字段id吗?
不是的,这点容易混淆,查询或者删除时候用到的ID是创建文档时候指定或者ES自动生成的那个id,而不是文档里面的那个叫
id字段!文档里面的文档字段是可以没有id的。
六、SpringBoot集成ES
1.pom.xml
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-starter-test
test
org.elasticsearch
elasticsearch
6.4.2
org.elasticsearch.client
transport
6.4.2
org.elasticsearch
elasticsearch
com.alibaba
fastjson
1.2.39
org.apache.commons
commons-lang3
3.4
org.projectlombok
lombok
1.16.20
commons-httpclient
commons-httpclient
3.1
2.application.properties
# Elasticsearch
# 9200端口是用来让HTTP REST API来访问ElasticSearch,而9300端口是传输层监听的默认端口
elasticsearch.ip=127.0.0.1
elasticsearch.port=9300
elasticsearch.pool=5
#注意cluster.name需要与config/elasticsearch.yml中的cluster.name一致
elasticsearch.cluster.name=elasticsearch_cici
server.port=8181
3.创建员工对象实体类 和 分页类
员工对象实体类
/**
* @Description:Book实体 加上了@Document注解之后,默认情况下这个实体中所有的属性都会被建立索引、并且分词
*/
@Data
@ToString
@NoArgsConstructor
public class Employee {
private String id;
private Long version;
String firstName;
String lastName;
String age;
String[] interests;
}
分页类
@Data
@ToString
public class EsPage {
/**
* 当前页
*/
private int currentPage;
/**
* 每页显示多少条
*/
private int pageSize;
/**
* 总记录数
*/
private int recordCount;
/**
* 本页的数据列表
*/
private List> recordList;
/**
* 总页数
*/
private int pageCount;
/**
* 页码列表的开始索引(包含)
*/
private int beginPageIndex;
/**
* 页码列表的结束索引(包含)
*/
private int endPageIndex;
/**
* 只接受前4个必要的属性,会自动的计算出其他3个属性的值
*
* @param currentPage
* @param pageSize
* @param recordCount
* @param recordList
*/
public EsPage(int currentPage, int pageSize, int recordCount, List> recordList) {
this.currentPage = currentPage;
this.pageSize = pageSize;
this.recordCount = recordCount;
this.recordList = recordList;
// 计算总页码
pageCount = (recordCount + pageSize - 1) / pageSize;
// 计算 beginPageIndex 和 endPageIndex
// >> 总页数不多于10页,则全部显示
if (pageCount <= 10) {
beginPageIndex = 1;
endPageIndex = pageCount;
}
// 总页数多于10页,则显示当前页附近的共10个页码
else {
// 当前页附近的共10个页码(前4个 + 当前页 + 后5个)
beginPageIndex = currentPage - 4;
endPageIndex = currentPage + 5;
// 当前面的页码不足4个时,则显示前10个页码
if (beginPageIndex < 1) {
beginPageIndex = 1;
endPageIndex = 10;
}
// 当后面的页码不足5个时,则显示后10个页码
if (endPageIndex > pageCount) {
endPageIndex = pageCount;
beginPageIndex = pageCount - 10 + 1;
}
}
}
}
4.创建config类
@Configuration
public class ElasticSearchConfig {
private static final Logger LOGGER = LoggerFactory.getLogger(ElasticSearchConfig.class);
/**
* elk集群地址
*/
@Value("${elasticsearch.ip}")
private String hostName;
/**
* 端口
*/
@Value("${elasticsearch.port}")
private String port;
/**
* 集群名称
*/
@Value("${elasticsearch.cluster.name}")
private String clusterName;
/**
* 连接池
*/
@Value("${elasticsearch.pool}")
private String poolSize;
/**
* Bean name default 函数名字
*
* @return
*/
@Bean(name = "transportClient")
public TransportClient transportClient() {
LOGGER.info("Elasticsearch初始化开始。。。。。");
TransportClient transportClient = null;
try {
// 配置信息
Settings esSetting = Settings.builder()
.put("cluster.name", clusterName) //集群名字
.put("client.transport.sniff", true)//增加嗅探机制,找到ES集群
.put("thread_pool.search.size", Integer.parseInt(poolSize))//增加线程池个数,暂时设为5
.build();
//配置信息Settings自定义
transportClient = new PreBuiltTransportClient(esSetting);
TransportAddress transportAddress = new TransportAddress(InetAddress.getByName(hostName), Integer.valueOf(port));
transportClient.addTransportAddresses(transportAddress);
} catch (Exception e) {
LOGGER.error("elasticsearch TransportClient create error!!", e);
}
return transportClient;
}
}
5.创建ES操作工具类
Elasticsearch JAVA操作有三种客户端:
1、TransportClient
2、JestClient
3、RestClient
还有种是2.3中有的NodeClient,在5.5.1中好像没有了。
还有种是spring-data-elasticsearch,这里先以TransportClient为例子。
@Component
public class ElasticsearchUtil {
private static final Logger LOGGER = LoggerFactory.getLogger(ElasticsearchUtil.class);
@Autowired
private TransportClient transportClient;
private static TransportClient client;
/**
* @PostContruct是spring框架的注解 spring容器初始化的时候执行该方法
*/
@PostConstruct
public void init() {
client = this.transportClient;
}
/**
* 创建索引
*
* @param index
* @return
*/
public static boolean createIndex(String index) {
if (!isIndexExist(index)) {
LOGGER.info("Index is not exits!");
}
CreateIndexResponse indexresponse = client.admin().indices().prepareCreate(index).execute().actionGet();
LOGGER.info("执行建立成功?" + indexresponse.isAcknowledged());
return indexresponse.isAcknowledged();
}
/**
* 删除索引
*
* @param index
* @return
*/
public static boolean deleteIndex(String index) {
if (!isIndexExist(index)) {
LOGGER.info("Index is not exits!");
}
DeleteIndexResponse dResponse = client.admin().indices().prepareDelete(index).execute().actionGet();
if (dResponse.isAcknowledged()) {
LOGGER.info("delete index " + index + " successfully!");
} else {
LOGGER.info("Fail to delete index " + index);
}
return dResponse.isAcknowledged();
}
/**
* 判断索引是否存在
*
* @param index
* @return
*/
public static boolean isIndexExist(String index) {
IndicesExistsResponse inExistsResponse = client.admin().indices().exists(new IndicesExistsRequest(index)).actionGet();
if (inExistsResponse.isExists()) {
LOGGER.info("Index [" + index + "] is exist!");
} else {
LOGGER.info("Index [" + index + "] is not exist!");
}
return inExistsResponse.isExists();
}
/**
* @Description: 判断inde下指定type是否存在
*/
public boolean isTypeExist(String index, String type) {
return isIndexExist(index)
? client.admin().indices().prepareTypesExists(index).setTypes(type).execute().actionGet().isExists()
: false;
}
/**
* 数据添加,正定ID
*
* @param jsonObject 要增加的数据
* @param index 索引,类似数据库
* @param type 类型,类似表
* @param id 数据ID
* @return
*/
public static String addData(JSONObject jsonObject, String index, String type, String id) {
IndexResponse response = client.prepareIndex(index, type, id).setSource(jsonObject).get();
LOGGER.info("addData response status:{},id:{}", response.status().getStatus(), response.getId());
return response.getId();
}
/**
* 数据添加
*
* @param jsonObject 要增加的数据
* @param index 索引,类似数据库
* @param type 类型,类似表
* @return
*/
public static String addData(JSONObject jsonObject, String index, String type) {
return addData(jsonObject, index, type, UUID.randomUUID().toString().replaceAll("-", "").toUpperCase());
}
/**
* 通过ID删除数据
*
* @param index 索引,类似数据库
* @param type 类型,类似表
* @param id 数据ID
*/
public static void deleteDataById(String index, String type, String id) {
DeleteResponse response = client.prepareDelete(index, type, id).execute().actionGet();
LOGGER.info("deleteDataById response status:{},id:{}", response.status().getStatus(), response.getId());
}
/**
* 通过ID 更新数据
*
* @param jsonObject 要增加的数据
* @param index 索引,类似数据库
* @param type 类型,类似表
* @param id 数据ID
* @return
*/
public static void updateDataById(JSONObject jsonObject, String index, String type, String id) {
UpdateRequest updateRequest = new UpdateRequest();
updateRequest.index(index).type(type).id(id).doc(jsonObject);
client.update(updateRequest);
}
/**
* 通过ID获取数据
*
* @param index 索引,类似数据库
* @param type 类型,类似表
* @param id 数据ID
* @param fields 需要显示的字段,逗号分隔(缺省为全部字段)
* @return
*/
public static Map searchDataById(String index, String type, String id, String fields) {
GetRequestBuilder getRequestBuilder = client.prepareGet(index, type, id);
if (StringUtils.isNotEmpty(fields)) {
getRequestBuilder.setFetchSource(fields.split(","), null);
}
GetResponse getResponse = getRequestBuilder.execute().actionGet();
return getResponse.getSource();
}
/**
* 使用分词查询,并分页
*
* @param index 索引名称
* @param type 类型名称,可传入多个type逗号分隔
* @param startPage 当前页
* @param pageSize 每页显示条数
* @param query 查询条件
* @param fields 需要显示的字段,逗号分隔(缺省为全部字段)
* @param sortField 排序字段
* @param highlightField 高亮字段
* @return
*/
public static EsPage searchDataPage(String index, String type, int startPage, int pageSize, QueryBuilder query, String fields, String sortField, String highlightField) {
SearchRequestBuilder searchRequestBuilder = client.prepareSearch(index);
if (StringUtils.isNotEmpty(type)) {
searchRequestBuilder.setTypes(type.split(","));
}
searchRequestBuilder.setSearchType(SearchType.QUERY_THEN_FETCH);
// 需要显示的字段,逗号分隔(缺省为全部字段)
if (StringUtils.isNotEmpty(fields)) {
searchRequestBuilder.setFetchSource(fields.split(","), null);
}
//排序字段
if (StringUtils.isNotEmpty(sortField)) {
searchRequestBuilder.addSort(sortField, SortOrder.DESC);
}
// 高亮(xxx=111,aaa=222)
if (StringUtils.isNotEmpty(highlightField)) {
HighlightBuilder highlightBuilder = new HighlightBuilder();
//highlightBuilder.preTags("");//设置前缀
//highlightBuilder.postTags("");//设置后缀
// 设置高亮字段
highlightBuilder.field(highlightField);
searchRequestBuilder.highlighter(highlightBuilder);
}
//searchRequestBuilder.setQuery(QueryBuilders.matchAllQuery());
searchRequestBuilder.setQuery(query);
// 分页应用
searchRequestBuilder.setFrom(startPage).setSize(pageSize);
// 设置是否按查询匹配度排序
searchRequestBuilder.setExplain(true);
//打印的内容 可以在 Elasticsearch head 和 Kibana 上执行查询
LOGGER.info("\n{}", searchRequestBuilder);
// 执行搜索,返回搜索响应信息
SearchResponse searchResponse = searchRequestBuilder.execute().actionGet();
long totalHits = searchResponse.getHits().totalHits;
long length = searchResponse.getHits().getHits().length;
LOGGER.debug("共查询到[{}]条数据,处理数据条数[{}]", totalHits, length);
if (searchResponse.status().getStatus() == 200) {
// 解析对象
List> sourceList = setSearchResponse(searchResponse, highlightField);
return new EsPage(startPage, pageSize, (int) totalHits, sourceList);
}
return null;
}
/**
* 使用分词查询
*
* @param index 索引名称
* @param type 类型名称,可传入多个type逗号分隔
* @param query 查询条件
* @param size 文档大小限制
* @param fields 需要显示的字段,逗号分隔(缺省为全部字段)
* @param sortField 排序字段
* @param highlightField 高亮字段
* @return
*/
public static List> searchListData(
String index, String type, QueryBuilder query, Integer size,
String fields, String sortField, String highlightField) {
SearchRequestBuilder searchRequestBuilder = client.prepareSearch(index);
if (StringUtils.isNotEmpty(type)) {
searchRequestBuilder.setTypes(type.split(","));
}
if (StringUtils.isNotEmpty(highlightField)) {
HighlightBuilder highlightBuilder = new HighlightBuilder();
// 设置高亮字段
highlightBuilder.field(highlightField);
searchRequestBuilder.highlighter(highlightBuilder);
}
searchRequestBuilder.setQuery(query);
if (StringUtils.isNotEmpty(fields)) {
searchRequestBuilder.setFetchSource(fields.split(","), null);
}
searchRequestBuilder.setFetchSource(true);
if (StringUtils.isNotEmpty(sortField)) {
searchRequestBuilder.addSort(sortField, SortOrder.DESC);
}
if (size != null && size > 0) {
searchRequestBuilder.setSize(size);
}
//打印的内容 可以在 Elasticsearch head 和 Kibana 上执行查询
LOGGER.info("\n{}", searchRequestBuilder);
SearchResponse searchResponse = searchRequestBuilder.execute().actionGet();
long totalHits = searchResponse.getHits().totalHits;
long length = searchResponse.getHits().getHits().length;
LOGGER.info("共查询到[{}]条数据,处理数据条数[{}]", totalHits, length);
if (searchResponse.status().getStatus() == 200) {
// 解析对象
return setSearchResponse(searchResponse, highlightField);
}
return null;
}
/**
* 高亮结果集 特殊处理
*
* @param searchResponse
* @param highlightField
*/
private static List> setSearchResponse(SearchResponse searchResponse, String highlightField) {
List> sourceList = new ArrayList>();
StringBuffer stringBuffer = new StringBuffer();
for (SearchHit searchHit : searchResponse.getHits().getHits()) {
searchHit.getSourceAsMap().put("id", searchHit.getId());
if (StringUtils.isNotEmpty(highlightField)) {
System.out.println("遍历 高亮结果集,覆盖 正常结果集" + searchHit.getSourceAsMap());
Text[] text = searchHit.getHighlightFields().get(highlightField).getFragments();
if (text != null) {
for (Text str : text) {
stringBuffer.append(str.string());
}
//遍历 高亮结果集,覆盖 正常结果集
searchHit.getSourceAsMap().put(highlightField, stringBuffer.toString());
}
}
sourceList.add(searchHit.getSourceAsMap());
}
return sourceList;
}
}
6.创建controller
@RestController
@RequestMapping("/es")
public class EsController {
/**
* 测试索引
*/
private String indexName = "megacorp";
/**
* 类型
*/
private String esType = "employee";
/**
* 创建索引
* http://127.0.0.1:8080/es/createIndex
* @param request
* @param response
* @return
*/
@RequestMapping("/createIndex")
public String createIndex(HttpServletRequest request, HttpServletResponse response) {
if (!ElasticsearchUtil.isIndexExist(indexName)) {
ElasticsearchUtil.createIndex(indexName);
} else {
return "索引已经存在";
}
return "索引创建成功";
}
/**
* 插入记录
*
* @return
*/
@RequestMapping("/insertJson")
public String insertJson() {
JSONObject jsonObject = new JSONObject();
jsonObject.put("id", DateUtil.formatDate(new Date()));
jsonObject.put("age", 25);
jsonObject.put("first_name", "j-" + new Random(100).nextInt());
jsonObject.put("last_name", "cccc");
jsonObject.put("about", "i like xiaofeng baby");
jsonObject.put("date", new Date());
String id = ElasticsearchUtil.addData(jsonObject, indexName, esType, jsonObject.getString("id"));
return id;
}
/**
* 插入记录
*
* @return
*/
@RequestMapping("/insertModel")
public String insertModel() {
Employee employee = new Employee();
employee.setId("66");
employee.setFirstName("m-" + new Random(100).nextInt());
employee.setAge("24");
JSONObject jsonObject = (JSONObject) JSONObject.toJSON(employee);
String id = ElasticsearchUtil.addData(jsonObject, indexName, esType, jsonObject.getString("id"));
return id;
}
/**
* 删除记录
*
* @return
*/
@RequestMapping("/delete")
public String delete(String id) {
if (StringUtils.isNotBlank(id)) {
ElasticsearchUtil.deleteDataById(indexName, esType, id);
return "删除id=" + id;
} else {
return "id为空";
}
}
/**
* 更新数据
*
* @return
*/
@RequestMapping("/update")
public String update(String id) {
if (StringUtils.isNotBlank(id)) {
JSONObject jsonObject = new JSONObject();
jsonObject.put("id", id);
jsonObject.put("age", 31);
jsonObject.put("name", "修改");
jsonObject.put("date", new Date());
ElasticsearchUtil.updateDataById(jsonObject, indexName, esType, id);
return "id=" + id;
} else {
return "id为空";
}
}
/**
* 获取数据
* http://127.0.0.1:8080/es/getData?id=2018-04-25%2016:33:44
*
* @param id
* @return
*/
@RequestMapping("/getData")
public String getData(String id) {
if (StringUtils.isNotBlank(id)) {
Map map = ElasticsearchUtil.searchDataById(indexName, esType, id, null);
return JSONObject.toJSONString(map);
} else {
return "id为空";
}
}
/**
* 查询数据
* 模糊查询
*
* @return
*/
@RequestMapping("/queryMatchData")
public String queryMatchData() {
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
boolean matchPhrase = false;
if (matchPhrase == Boolean.TRUE) {
//不进行分词搜索
boolQuery.must(QueryBuilders.matchPhraseQuery("first_name", "cici"));
} else {
boolQuery.must(QueryBuilders.matchQuery("last_name", "cici"));
}
List> list = ElasticsearchUtil.
searchListData(indexName, esType, boolQuery, 10, "first_name", null, "last_name");
return JSONObject.toJSONString(list);
}
/**
* 通配符查询数据
* 通配符查询 ?用来匹配1个任意字符,*用来匹配零个或者多个字符
*
* @return
*/
@RequestMapping("/queryWildcardData")
public String queryWildcardData() {
QueryBuilder queryBuilder = QueryBuilders.wildcardQuery("first_name.keyword", "cici");
List> list = ElasticsearchUtil.searchListData(indexName, esType, queryBuilder, 10, null, null, null);
return JSONObject.toJSONString(list);
}
/**
* 正则查询
*
* @return
*/
@RequestMapping("/queryRegexpData")
public String queryRegexpData() {
QueryBuilder queryBuilder = QueryBuilders.regexpQuery("first_name.keyword", "m--[0-9]{1,11}");
List> list = ElasticsearchUtil.searchListData(indexName, esType, queryBuilder, 10, null, null, null);
return JSONObject.toJSONString(list);
}
/**
* 查询数字范围数据
*
* @return
*/
@RequestMapping("/queryIntRangeData")
public String queryIntRangeData() {
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
boolQuery.must(QueryBuilders.rangeQuery("age").from(24)
.to(25));
List> list = ElasticsearchUtil.searchListData(indexName, esType, boolQuery, 10, null, null, null);
return JSONObject.toJSONString(list);
}
/**
* 查询日期范围数据
*
* @return
*/
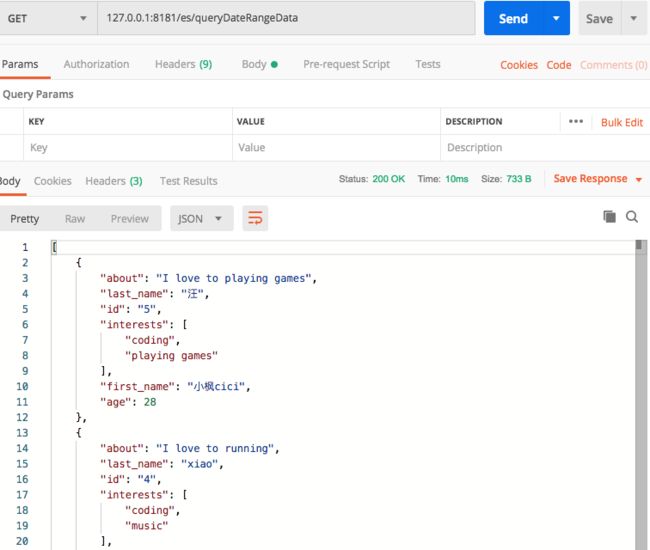
@RequestMapping("/queryDateRangeData")
public String queryDateRangeData() {
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
boolQuery.must(QueryBuilders.rangeQuery("age").from("20")
.to("50"));
List> list = ElasticsearchUtil.searchListData(indexName, esType, boolQuery, 10, null, null, null);
return JSONObject.toJSONString(list);
}
/**
* 查询分页
*
* @param startPage 第几条记录开始
* 从0开始
* 第1页 :http://127.0.0.1:8080/es/queryPage?startPage=0&pageSize=2
* 第2页 :http://127.0.0.1:8080/es/queryPage?startPage=2&pageSize=2
* @param pageSize 每页大小
* @return
*/
@RequestMapping("/queryPage")
public String queryPage(String startPage, String pageSize) {
if (StringUtils.isNotBlank(startPage) && StringUtils.isNotBlank(pageSize)) {
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
boolQuery.must(QueryBuilders.rangeQuery("age").from("20")
.to("100"));
EsPage list = ElasticsearchUtil.searchDataPage(indexName, esType, Integer.parseInt(startPage), Integer.parseInt(pageSize), boolQuery, null, null, null);
return JSONObject.toJSONString(list);
} else {
return "startPage或者pageSize缺失";
}
}
}
利用postman一个个请求。
截取结果如下:方法都能正常准确访问
七、总结
本文我们对ES的基本概念进行了清晰的解释,并用最有效率的方式进行了安装配置,也对基础的增删改查进行了图文并茂的演示。掌握了这些可以说对ES已经入门了,写这篇文章的目的也已经达到了!ES还有很多复杂的查询,中文分词,倒排索引等技术点需要我们去掌握,后续我将会整理出来,咱们一起学习!
如果您对我的文章感兴趣,欢迎关注点赞收藏,如果您有疑惑或发现文中有不对的地方,还请不吝赐教,非常感谢!!
扩展参考:
Elasticsearch面试题(2021最新版)
elasticsearch 常见查询及聚合的JAVA API