五、k8s 生命周期管理和服务发现
文章目录
-
- 前言
- 深入理解 Pod 的生命周期
-
- Pod 的完整生命周期
- 如何确保 Pod 的高可用
- 健康检查探针
- 优雅启停案例
- Service 对象
-
- Service 对象
- Endpoint 对象
- EndpointSlice 对象
- Service、Endpoint 和 Pod 的对应关系
- kube-proxy
-
- Netfilter 和 iptables
- kube-proxy 工作原理
- DNS 与 域名服务
-
- k8s 中的域名解析
- k8s 负载均衡与 ingress
-
- Ingress
前言
- Pod 的生命周期是怎么样的?Pod的状态是如何计算出来的?
- k8s 中的服务发现是如何实现的?
- 微服务如何利用云原生实现高可用?
深入理解 Pod 的生命周期
Pod 的完整生命周期

pending
用户发起创建 Pod 的命令到达 API Server, API Server 会将节点信息写入 etcd, 此时 Pod 还未被 scheduler 调度处于 pending 状态。
ContainerCreating:
scheduler 此时会根据对应的亲和性,容忍度等调度策略,开始将Pod 绑定至对应节点并且创建容器,此时 Pod 处于 ContainerCreating 状态。
Running:
当 Pod 与节点绑定后,kubelet 开始调用CRI, CNI, CSI 来吊起Pod对应的容器,如何吊起成功,此时 Pod 将处于 Succeeded状态,如果吊起失败将处于 Failed 状态。
Unknown:
在kubelet 吊起Pod 的过程中,有可能由于网络问题原因等,无法获取 Pod 状态,此时 Pod 将处于Unknown 状态。
Evicted:
由于节点资源问题,可能导致 Pod 处于被驱逐状态。
具体的状态机如下:

从 Pod 的完整生命周期中可以发现 Pod 在启停的过程中有很多的status, 但是在状态机流转中却主要有五种状态,这几种状态被称为 **Pod Phase, **他们代表着 Pod 主生命周期的状态:
- Pending
- Running
- Succeeded
- Failed
- Unknown
Pod 的实际状态是由Pod Phase 主生命周期状态与该周期内的具体时间点的状态组成的,查看一看运行中 Pod 的yaml 如下:
apiVersion: v1
kind: Pod
metadata:
...
spec:
...
status:
conditions:
- lastProbeTime: null
lastTransitionTime: "2022-11-22T01:50:26Z"
status: "True"
type: Initialized
- lastProbeTime: null
lastTransitionTime: "2022-11-22T01:50:27Z"
status: "True"
type: Ready
- lastProbeTime: null
lastTransitionTime: "2022-11-22T01:50:27Z"
status: "True"
type: ContainersReady
- lastProbeTime: null
lastTransitionTime: "2022-11-22T01:50:26Z"
status: "True"
type: PodScheduled
containerStatuses:
- containerID: containerd://715cd04ba10ebd75a296e29d61f16ff6636935057dda116794c9c94100c21bc5
image: docker.io/library/nginx:alpine
imageID: docker.io/library/nginx@sha256:455c39afebd4d98ef26dd70284aa86e6810b0485af5f4f222b19b89758cabf1e
lastState: {}
name: nginx
ready: true
restartCount: 0
started: true
state:
running:
startedAt: "2022-11-22T01:50:27Z"
hostIP: 192.168.146.190
phase: Running
podIP: 10.10.1.27
podIPs:
- ip: 10.10.1.27
qosClass: BestEffort
startTime: "2022-11-22T01:50:26Z"
可以发现此时Pod 的主生命周期 Phase 为 Running 状态,具体细节状态 conditions 包括 Initialized, Ready, ContainersReady, PodScheduled
在我们执行 get pod 命令查看 pod 运行状态的结果就是根据 Pod Phase 与 Conditions 状态计算出此时时间点 Pod 的状态:

当Pod 处于异常状态的时候,可以通过上表大致推算出 Pod 异常的位置,然后再排查。
如何确保 Pod 的高可用
资源限制
对于k8s 来说确保 Pod 的高可用其实就是确保 Pod 在节点上的资源是够用的,但是一个节点不可能只运行一个 Pod, 此时高可用策略就是 Pod 在节点上的 Qos 策略,根据资源限制的 limits 和 requests 的不同比例,Pod 的 Qos 主要分为三大类:

-
Guaranteed
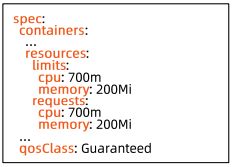
此时 Limits 限制和 requests 限制完全一致,保证 Pod 在节点上拥有充足的资源。 -
Burstable

此时 limits 上限大于 requests,此时节点上的 Pod 中的进程适合错峰运行。 -
BestEffort

此时没有资源限制,也就是说Pod 间对资源存在竞争,当节点不可压缩资源不足时,就会按照驱逐优先级驱逐对应的 Pod。
每种类型的 Qos 都有不同的适用环境,只有根据实际情况制定不同的资源限制,才能保证既不会造成资源浪费又保证 Pod 正常运行:
- 定义Guaranteed 类型的资源需求来保护重要的 Pod。
- 合理设置 limit 和 request,有利于将集群资源利用率控制在合理范围,并且减少 Pod 被驱逐的现象。
- 尽量避免将 Pod 设置为 BestEffort,Burstable 适用于大多数场景。
基于 Taint 的 Evictions
当节点不可达或节点重启时,需要驱逐该节点上的 Pod 至其他节点,此时 k8s 会为 Pod 自动增加 Toleration:


但是有的 Pod 依赖本地存储,不希望被驱逐,就可以增加tolerationSeconds 以避免被驱逐,等待节点重启完毕。
健康检查探针
健康检查探针主要分为三种:
- livenessProbe
探活,当检查失败时,意味着该应用进程已经无法正常提供服务,kubelet 会终止该容器进程并按照restartPolicy 决定是否重启。 - ReadinessProbe
就绪状态检查,当检查失败时,意味着应用进程正在运行,但因为某些原因不能提供服务,Pod 状态会被标记为 NotReady。 - startupProbe
在初始化阶段进行的健康检查,通常用来避免过于频繁的监测影响应用启动。
探测方法包括:
- ExecAction: 在容器内部运行指定命令,当返回码为0时,探测结果为成功。
- TCPSocketAction: 由kubelet 发起,通过 TCP 协议检查容器 IP 和端口,当端口可达时,探测结果为成功。
- HTTPGetAction: 由 kubelet 发起,对 Pod 的 IP 和指定端口以及路径进行 HTTPGet 操作,当返回码为200-400 之间时,探测结果为成功。
探针属性:

ReadinessGates:
- Readiness 允许在 k8s 自带的 pod Conditions 之外引入自定义的就绪条件。
- 新引入的 readinessGates condition 需要为 True 后,加上内置的 conditions, Pod 才可以为就绪状态。
- 该状态应该由某个控制器修改。
Post-start 和 Pre-Stop Hook
有时候需要在容器启动前作一些动作或者优雅停止容器,k8s 提供了对应的 hook:

-
postStart 结束之前,容器不会被标记为 running 状态,但是无法保证 postStart 脚本和容器的Entrypoint 哪个先执行。

-
只有当 Pod 被终止时, k8s 才会执行 prestop 脚本,意味着当 Pod 完成或容器退出时,preStop 脚本不会被执行。
-
terminationGracePeriodSecons 的分解
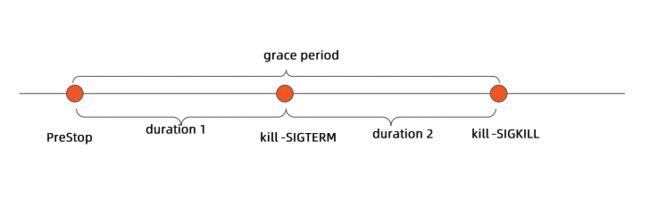
删除 Pod 有一个默认时间为30s, 该时间段分为两段,duration1 用于执行优雅停止脚本,当优雅停止脚本执行完后,duration2 就开始执行删除杀死命令。
优雅启停案例
优雅启动
-
执行 exec 命令进行 readiness 探活
apiVersion: v1 kind: Pod metadata: name: initial-delay spec: containers: - name: initial-delay image: centos args: - /bin/sh - -c - touch /tmp/healthy; sleep 300; readinessProbe: exec: command: - cat - /tmp/healthy initialDelaySeconds: 30 periodSeconds: 5执行 httpGet 请求进行 readiness 探活
apiVersion: v1 kind: Pod metadata: name: http-probe spec: containers: - name: http-probe image: nginx readinessProbe: httpGet: ### this probe will fail with 404 error code ### only httpcode between 200-400 is retreated as success path: /healthz port: 80 initialDelaySeconds: 30 periodSeconds: 5 successThreshold: 2 -
liveness 探活
apiVersion: v1 kind: Pod metadata: name: liveness1 spec: containers: - name: liveness image: centos args: - /bin/sh - -c - touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600 livenessProbe: exec: command: - cat - /tmp/healthy initialDelaySeconds: 10 periodSeconds: 5
liveness 探活在容器创建完成后就立即处于 running 状态。 -
启动前执行脚本命令
apiVersion: v1 kind: Pod metadata: name: poststart spec: containers: - name: lifecycle-demo-container image: nginx lifecycle: postStart: exec: command: ["/bin/sh", "-c", "echo Hello from the postStart handler > /usr/share/message"] -
readiness-gate 等待外部条件和容器自身conditions 均处于就绪状态, Pod 才处于 running 状态
apiVersion: v1 kind: Pod metadata: labels: app: readiness-gate name: readiness-gate spec: readinessGates: - conditionType: "www.example.com/feature-1" containers: - name: readiness-gate image: nginx --- apiVersion: v1 kind: Service metadata: name: readiness-gate spec: ports: - port: 80 protocol: TCP targetPort: 80 selector: app: readiness-gate
优雅停止
-
停止前执行脚本命令
apiVersion: v1 kind: Pod metadata: name: prestop spec: containers: - name: lifecycle-demo-container image: nginx lifecycle: preStop: exec: command: [ "/bin/sh","-c","nginx -s quit; while killall -0 nginx; do sleep 1; done" ] -
kubelet 发送终止信号至容器内进程,然后容器进程自己处理终止信号量,并等待对应时间,默认等待60s
apiVersion: v1 kind: Pod metadata: name: no-sigterm spec: terminationGracePeriodSeconds: 60 containers: - name: no-sigterm image: centos command: ["/bin/sh"] args: ["-c", "while true; do echo hello; sleep 10;done"]
Service 对象
Service 对象
- Service Selector
k8s 允许将Pod 对象通过标签(Label)进行标记,并通过 Service Selector 定义基于 Pod 标签的过滤规则,以便选择服务的上游应用实例 - Ports
Ports 属性中定义了服务的端口、协议目标端口等信息apiVersion: v1 kind: Service metadata: name: nginx-basic spec: type: ClusterIP ports: - port: 80 protocol: TCP name: http selector: app: nginx
Service 对象如果不定义 Selector,Endpoint Controller 不会为该 Service 自动创建 Endpoint。但是用户可以手动创建 Endpoint 对象,并设置任意 IP 地址到 Address 属性,访问该服务的请求会被转发至目标地址。
apiVersion: v1
kind: Service
metadata:
name: service-without-selector
spec:
ports:
- port: 80
protocol: TCP
name: http
通过这种方式可以为集群外的一组 Endpoint 创建服务,比如说有一批不在k8s 集群内的机器需要部署服务,但是需要通过 k8s 的服务发现对外提供访问,这个时候可以创建不带 Selector 的 Service, 然后我们自己在手动创建对应的 endpoint 将该 Service 与对应集群外的机器IP地址绑定,就实现了集群外创建服务。
Service 类型
- clusterIP
- Service 的默认类型,服务被发布至集群内部可见的虚拟 IP 地址上。
- 在 API Server 启动时,需要通过 service-cluster-ip-range 参数配置虚拟 IP 地址段,API Server 中用于分配 IP 地址和端口的组件,当该组件捕获Service 对象并创建事件时,会从配置的虚拟 IP 地址段中取一个有效的 IP 地址,分配给该 Service 对象。
- nodePort
- 在 API Server 启动时,需要通过 node-port-range 参数配置 nodePort 的范围,同样的,API Server 会捕获 Service 对象并创建事件,即从配置好的 nodePort 范围取一个有效端口,分配给该 Service。
- 每个节点的 kube-proxy 会尝试在服务分配的 nodePort 上建立侦听器接收请求,并转发给服务对应的后端 Pod 实例。
- LoadBalancer
- 企业数据中心一般会采购一些负载均衡器,作为外网请求进入数据中心内部的统一流量入口。
- 针对不同的基础架构云平台, k8s Cloud Manager 提供支持不同供应商 API 的 Service Controller。
- Headless Service
- 无头服务是用户将clusterIP 显示定义为 None 的服务。
意味着 k8s 不会为该服务分配统一入口,包括 clusterIP, nodePort 等
- 无头服务是用户将clusterIP 显示定义为 None 的服务。
- ExternalName Service
- 为服务创建一个别名。
apiVersion: v1 kind: Service metadata: name: my-service namespace: prod spec: type: ExternalName externalName: tencent.com
Service Topology
- 一个网络调用的延迟受客户端和服务器所处位置的影响,两者是否在同一节点、统一机架、同一可用区、同一数据中心,都会影响参与数据传输的设备数量。
- 在分布式系统中,为保证系统的高可用,往往需要控制应用的错误域,比如通过反亲和性配置,讲一个应用的多个副本部署在不同的机架,甚至不同的数据中心。
- k8s 提供通用标签来标记节点所处的物理位置:

Service 引入了 topologyKeys 属性,可以通过如下设置来控制流量:
- 当 topologyKeys 设置为 [“kubernetes.io/hostname”] 时,调用服务的客户端所在节点上如果有服务实例正在运行,则该实例处理请求,否则,调用失败。
≈ - 当 topologyKeys 设置为 [“kubernetes.io/hostname”, “kubernetes.io/zone”, “kubernetes.io/region”] 时,若同一节点有对应的服务实例,则请求会优先转发至该实例。否则,顺序查找当前 zone 及当前 region 是否有服务实例,并将请求按顺序转发。
- 当 topologyKeys 设置为 [“kubernetes.io/zone”, “*”] 时, 请求会被优先转发至当前 zone 的服务实例。如果当前 zone 不存在服务实例,则请求会被转发至任意服务实例。
apiVersion: v1 kind: Service metadata: name: prefer-nodelocal spec: ports: - port: 80 protocol: TCP name: http selector: app: nginx topologyKeys: - "kubernetes.io/hostname" - "topology.kubernetes.io/zone" - "topology.kubernetes.io/region" - "*"
Endpoint 对象
- 当 Service 的 selector 不为空时,k8s Endpoint Controller 会侦听服务创建事件,创建与 Service 同名的 Endpoint 对象。
- Selector 能够选取的所有 PodIP 都会被配置到 addresses 属性中:
- 如果此时 selector 所对应的 filter 查询不到对应的 Pod, 则 addresses 列表为空。
- 默认配置下,如果此时对应的 Pod 为 not ready 状态,则对应的 PodIP 只会出现在 subsets 的 notReadyAddresses 属性中,意味着对应的 Pod 还没准备好提供服务,不能作为流量转发的目标。
- 如果设置了 PublishNotReadyAddresses 为 True, 则无论 Pod 是否就绪都会被加入 readyAddress list。
Pod 处于ready 状态的 addresses 列表:
[admin@ali-jkt-dc-bnc-airflow-test02 k8s]$ kubectl get endpoints ngx-hpa-svc -o yaml
apiVersion: v1
kind: Endpoints
metadata:
creationTimestamp: "2022-11-21T15:18:56Z"
name: ngx-hpa-svc
namespace: default
resourceVersion: "724452"
uid: 35780a4b-4e21-4e4c-aee1-b8b1d63f2d40
subsets:
- addresses:
- ip: 10.10.1.14
nodeName: ali-jkt-dc-bnc-airflow-test03
targetRef:
kind: Pod
name: ngx-hpa-dep-75b9d99c9b-nvbwk
namespace: default
uid: 6af07c2f-5c21-4bb8-b71b-e14b56ad473e
- ip: 10.10.1.15
nodeName: ali-jkt-dc-bnc-airflow-test03
targetRef:
kind: Pod
name: ngx-hpa-dep-75b9d99c9b-djcwh
namespace: default
uid: 5128ae39-5719-4855-a88e-2b0989d5eb22
ports:
- port: 80
protocol: TCP
创建一个处于 unready 状态的 Pod 和 对应的 Service:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
readinessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
################
apiVersion: v1
kind: Service
metadata:
name: nginx-basic
spec:
type: ClusterIP
ports:
- port: 80
protocol: TCP
name: http
selector:
app: nginx
查看 endpoints 处于 notReadyAddresses 状态:
[admin@ali-jkt-dc-bnc-airflow-test02 k8s]$ kubectl get endpoints nginx-basic -o yaml
apiVersion: v1
kind: Endpoints
metadata:
annotations:
endpoints.kubernetes.io/last-change-trigger-time: "2023-03-08T00:50:03Z"
creationTimestamp: "2023-03-08T00:50:03Z"
name: nginx-basic
namespace: default
resourceVersion: "13629154"
uid: 7f315e16-3092-4686-a46a-0d6ed938cd9b
subsets:
- notReadyAddresses:
- ip: 10.10.2.23
nodeName: ali-jkt-dc-bnc-airflow-test01
targetRef:
kind: Pod
name: nginx-deployment-6bdf5fd58d-vzhcf
namespace: default
uid: e61ec9b9-0b5d-4477-8d40-9396a7e55bc4
ports:
- name: http
port: 80
protocol: TCP
设置 PublishNotReadyAddresses 为 True :
apiVersion: v1
kind: Service
metadata:
name: nginx-publish-notready
spec:
publishNotReadyAddresses: true
type: ClusterIP
ports:
- port: 80
protocol: TCP
name: http
selector:
app: nginx
再次查看对应endpoint 中的 addresses 都处于 ready 状态:
[admin@ali-jkt-dc-bnc-airflow-test02 k8s]$ kubectl get endpoints nginx-publish-notready -o yaml
apiVersion: v1
kind: Endpoints
metadata:
annotations:
endpoints.kubernetes.io/last-change-trigger-time: "2023-03-08T00:54:42Z"
creationTimestamp: "2023-03-08T00:54:42Z"
name: nginx-publish-notready
namespace: default
resourceVersion: "13629581"
uid: c87192d8-7cf2-4704-a5bb-e6d5b7f2d9f1
subsets:
- addresses:
- ip: 10.10.2.23
nodeName: ali-jkt-dc-bnc-airflow-test01
targetRef:
kind: Pod
name: nginx-deployment-6bdf5fd58d-vzhcf
namespace: default
uid: e61ec9b9-0b5d-4477-8d40-9396a7e55bc4
ports:
- name: http
port: 80
protocol: TCP
EndpointSlice 对象
- 当某个Service 对应的 backend Pod 较多时, Endpoint 对象就会因保存的地址信息过多而变得异常庞大。
- Pod 状态变更会引起 Endpoint 的变更,Endpoint 的变更会被推送至所有节点,从而导致持续占用大量网络带宽。
- EndpointSlice 对象,用于对 Pod 较多的 Endpoint 进行切片,切片大小可以自定义。
apiVersion: discovery.k8s.io/v1
kind: EndpointSlice
metadata:
name: example-abc
labels:
kubernetes.io/service-name: example
addressType: IPv4
ports:
- name: http
protocol: TCP
port: 80
endpoints:
- addresses:
- "10.1.2.3"
conditions:
ready: true
hostname: pod-1
nodeName: node-1
zone: us-west2-a
Service、Endpoint 和 Pod 的对应关系

kube-proxy
每台机器上都运行一个 kube-proxy 服务,它监听 API Server 中 service 和 endpoint 的变化情况,并通过 iptables 等来为服务配置负载均衡(仅支持TCP和UDP)。
kube-proxy 可以直接运行在物理机上,也可以以static pod 或者 DaemonSet 的方式运行。
kube-proxy 当前支持以下几种实现:
- userspace: 最早的负载均衡方案,它在用户空间监听一个端口,所有服务通过 iptables 转发到这个端口,然后在其内部负载均衡到实际的Pod。该方式最主要的问题是效率低,有明显的性能瓶颈。
- iptables: 目前推荐的方案,完全以 iptables 规则的方式来实现 service 负载均衡。该方式最主要的问题是在服务多的时候产生太多的 iptables 规则,非增量式更新会引入一定的时延,大规模情况下有明显的性能问题。
- ipvs: 为解决 iptables 模式的性能问题,采用增量式更新,保证 service 更新期间连接保持不断开。
- winuserspace: 同 userspace, 仅工作在 windows 上。
Netfilter 和 iptables
在了解 kube-proxy 工作原理前,需要对 Netfilter 和 iptables 的有个初步的了解。
Linux 内核处理数据包:Netfilter 框架

上图展现的是一个数据包,被一个Linux 系统接收以后,内核在处理数据包的时候会经过哪些流转,数据包流转的过程称为 Netfilter.
关于Netfilter 更多介绍的可以看这篇文章:
走进Linux内核之Netfilter框架
iptables 与 Netfilter 交互流程
iptables 就是 Netfilter 框架中运行在用户态空间的一个网络地址转发组件。

用户可以在 iptbales 中定义 NAT(网络地址转发)规则,iptables 配合 Netfilter 就实现了负载均衡。
一个网络数据包被网卡接收到以后,就会告诉CPU需要处理,此时CPU将会被硬件中断,但是硬件中断的过程中CPU 是没办法处理别的事情了,所以硬件中断需要快速恢复,此时 CPU 会调用软中断 softIRQ Handler。
网卡在接收到数据包时会快速复制一份数据到 Linux kernel 中,此时 softIRQ 就会读取这份数据,构造 SKB(SK Buffer)数据包,包含数据的 Header 和 Data, Header 中包含了地址信息。
softIRQ 在构造完 SKB 数据包后,会告诉Netfilter,Netfilter 就会从用户态的 iptables 中读取用户定义的地址转发规则,然后根据 NAT 规则修改数据包头,后续数据包将被转发到对应的地址。
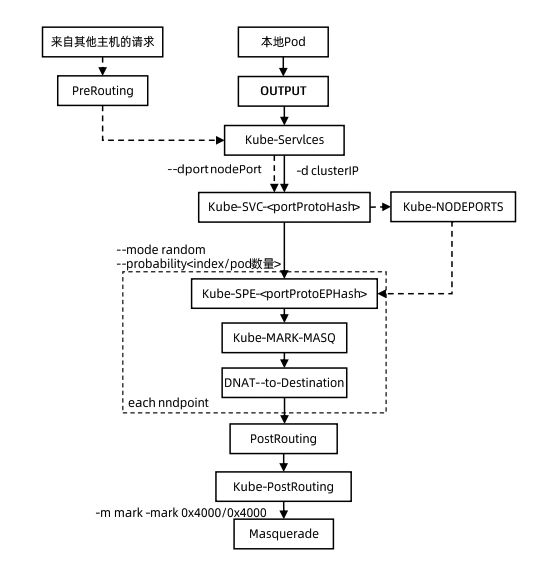
iptables

网络数据包进入会先经过 PREROUTING 然后根据路由判断是不是进入本机进程,如果是进程本地,就走LOCAL_IN 否则就走 FORWARD 转发至 POSTROUTING 进入网络。
本地数据包处理完后,如果需要转出,就需要走 LOCAL_OUT 然后进入 POSTROUTING 进入网络。
数据包在每一个流转环节都有对应的 hook,通过 hook 就可以修改数据包流转地址。
kube-proxy 想要实现网络地址转换就需要通过 nat 相关的 hook 去修改数据包的流转,对应上图就是修改 PREROUTING 的 raw/mangle/dnat 和 LOCAL_OUT 的 raw/mangle/dnat/filter/snat。
kube-proxy 工作原理
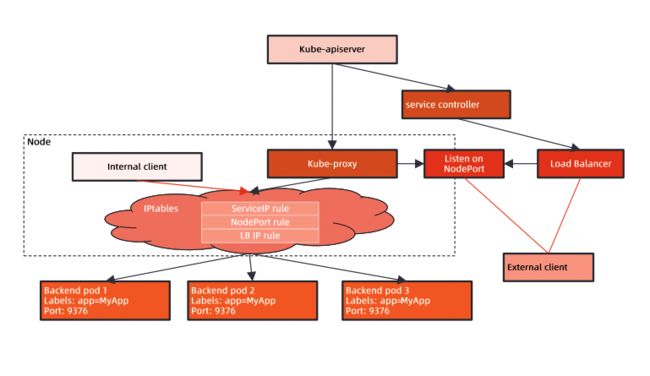
kube-proxy 会watch apiserver ,创建对应的 IPtables 规则,将请求转发到对应的 Pod 地址。
kube-proxy 会在 iptbales 中注册一个 kube-services 的规则,所有 Pod 的网络请求或者外部请求都会进过 kube-services,kube-services 接收到请求后会根据集群中 Pod 具体的 IP 地址修改 iptables 规则,并且根据规则进行转换(上图中虚线框内的)。
如果说一个 Deployment 启了三个不同 ip 的Pod, 然后通过Service 访问 Deployment, 那么 kube-proxy 会将请求转发至哪个 Pod 呢?
这个就和 iptables 的路由规则有关了, kube-proxy 会根据 --mode random 生成三条规则对应三个 IP,每条规则被转发的几率分别为33%, 50%,100%,在进行转发的时候会自上而下转发。
IPVS
kube-proxy引入了IPVS模式,IPVS模式与iptables同样基于Netfilter,但是ipvs采用的hash表,iptables采用一条条的规则列表。iptables又是为了防火墙设计的,集群数量越多iptables规则就越多,而iptables规则是从上到下匹配,所以效率就越是低下。因此当service数量达到一定规模时,hash查表的速度优势就会显现出来,从而提高service的服务性能
每个节点的kube-proxy负责监听API server中service和endpoint的变化情况。将变化信息写入本地userspace、iptables、ipvs来实现service负载均衡,使用NAT将vip流量转至endpoint中。由于userspace模式因为可靠性和性能(频繁切换内核/用户空间)早已经淘汰,所有的客户端请求svc,先经过iptables,然后再经过kube-proxy到pod,所以性能很差。
ipvs和iptables都是基于netfilter的,两者差别如下:
- ipvs 为大型集群提供了更好的可扩展性和性能
- ipvs 支持比 iptables 更复杂的负载均衡算法(最小负载、最少连接、加权等等)
- ipvs 支持服务器健康检查和连接重试等功能
DNS 与 域名服务
k8s Service 通过虚 IP 地址或者节点端口为用户应用提供访问入口,然而这些 IP 地址和端口是动态分配的,如果用户重建一个服务,其分配的 clusterIP 和 nodePort,以及 LoadBalancerIP 都是会变化的,无法把一个可变的入口发布出去供他人访问。
k8s 提供了内置的域名服务,用户定义的服务会自动获得域名,而无论服务重建多少次,只要服务名不改变,其对应的域名就不会改变。
CoreDNS
k8s 内部域名解析时由CoreDNS 服务实现的,CoreDNS 包含一个内存态 DNS,以及与其他 controller 类似的控制器。
CoreDNS 的实现原理是,控制器监听Service 和 Endpoint 的变化并配置 DNS,客户端 Pod 在进行域名解析时,从 CoreDNS 中查询服务对应的地址记录。

不同类型服务的DNS 记录解析方式也不同:
- 普通 Service
- ClusterIP、nodePort、LoadBalancer 类型的 Service 都拥有 API Server 分配的 ClusterIP, CoreDNS 会为这些 Service 创建 FQDN 格式为 s v c n a m e . svcname. svcname.namespace.svc.$clusterdomain:clusterIP 的 A记录及 PTR 记录,并为端口创建 SRV 记录。
- Headless Service
- 用户在Spec 显式指定 ClusterIP 为 None 的 Service, 对于这类 Service, API Server 不会为其分配 ClusterIP。CoreDNS 为此类 Service 创建多条 A 记录,并且目标为每个就绪的 PodIP。
- 另外,每个 Pod 会拥有一个FQDN 格式为 s v c n a m e . svcname. svcname.namespace.svc.$clusterdomain 的 A 记录只想 PodIP。
- ExternalName Service
- 此类 Service 用来引用一个已经存在的域名, CoreDNS 会为该 Service 创建一个 Cname 记录指向目标域名。
k8s 中的域名解析
-
k8s Pod 有一个与 DNS 策略相关的属性 DNSPolicy, 默认值是 ClusterFirst。
-
Pod 启动后的 /etc/resolv.conf 会被改写,所有的地址解析优先发送至 CoreDNS。

这里的 ndots:5 意思是在通过域名访问Pod的时候,5个点以下分割的短域名查询将按照 search 中的查询顺序自动补全,并且按照补全后的长域名进行查询。当 Pod 启动时,同一 Namespace 的所有 Service 都会以环境变量的形式设置到容器内。
k8s 负载均衡与 ingress
k8s 中的负载均衡主要有两种,一种是基于iptables/ipvs 的分布式四层负载均衡技术,kube-proxy 基于 iptables rules 为 k8s 形成全局统一的分布式负载均衡。
一种是基于七层应用层的 ingress, 该负载均衡方式将使业务开发人员与运维动作分离,可以使开发人员更加关注业务开发。
L4 与 L7 负载均衡对比
基于 L4 的服务

- 每个应用独占 ELB , 浪费资源。
- 为每个服务动态创建 DNS 记录,频繁的 DNS 更新。
- 支持TCP 和 UDP,业务部门需要启动 HTTPS 服务,自己管理证书。
基于 L7 的 ingress

- 多个应用共享 ELB,节省资源。
- 多个应用共享一个 Domain, 可采用静态 DNS配置。
- TLS termination 发生在 ingress 层,可集中管理证书。
- 更多复杂性,更多的网络 hop。
Ingress
ingress 是一层代理,负责根据 hostname 和 path 将流量转发到不同的服务上,使得一个负载均衡器用于多个后台应用,k8s ingress Spec 是转发规则的集合。

Service 根据 Label 筛选出提供服务的 Pod,Ingress 在根据访问路径,将请求转发至对应的 Service,同时 Ingress 层可以根据需要配置对应的访问证书,在该层统一解密管理证书,解耦业务与运维视角。
Ingress Contoller
和其他的资源对象一样,Ingress 也有对应的 Controller ,它会监听 Ingress 对象,生成对应的负载均衡配置文件,保证实际状态与期望状态一致。
Ingress Controller 的定位是非常简单灵活的,就是只负责请求的接入和转发,定位简单的同时也成为了单一 Controller 不足的表现,没办法提供更多的功能,比如说:证书版本选择,加密算法选择,流量统计等。
为了弥补不足与适用各种状况,社区就产生了很多不同种类的 Ingress Controller,目前比较流行的就是 Nginx Ingress,这里就不展开讲解,感兴趣的可以看下这篇文章:
浅谈Kubernetes Ingress控制器的技术选型