AI绘画:快速上手stable diffusion
点击↑上方↑蓝色“编了个程”关注我~

这是Yasin的第 89 篇原创文章
![]()
mj vs sd
最近随着Chat GPT的大火,AI绘画也火了起来。尤其是midjourney(以下简称mj),能够通过文本关键词生成AI图片,还能指定各种风格,简直是我们这种又菜又爱玩的福音。
下面是我用mj随便画的一些图:

mj上手比较容易,我这里就不详细讲了,感兴趣的同学可以去b站或者抖音搜索,有较多的教程。友情提示:「使用mj需要科学上网」。
在了解mj的过程中,我又了解到另一款AI绘画工具,叫stable diffustion(以下简称sd)。发现相比于mj,sd有以下的优势:
本地运行,不用科学上网:下载完对应的资源后,就不用科学上网了;
开源免费:sd是开源免费的绘画平台,而mj是收费的,每个账号有免费的额度,可以画几十张图;
高度定制化:sd有开源的各种模型和插件,也可以自己训练风格、局部修改、细节调整,甚至可以用自己的照片、宠物的照片高度定制化属于自己期望风格的AI绘画。
所以今天整理一下sd上手的基本资料,供大家参考。
安装
sd是一个AI绘画平台,底层是各种AI绘画模型(其中以SD模型为base),上层是UI界面。
首先需要安装sd的web界面。是一个github开源项目,地址是:GitHub - AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI。
对于mac os M系列的芯片而言,有专门的安装文档:Installation on Apple Silicon · AUTOMATIC1111/stable-diffusion-webui Wiki · GitHub
安装过程比较慢,需要下载大量的python资源,可以用这个命令设置python源为国内清华大学的,这样下载速度会快很多:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple安装完web界面后,可以下载对应的sdk模型。应该是内置了sd 1.5的,不过2.0对风景类型的有一些优化,也可以安装一个2.0和2.1的,后面可以随时切换。
还有一个叫easy diffusion的网站,号称能一键安装,但我自己实操下来中途安装失败了,没有找到解决办法,所以还是自己去上面的github地址安装的。
界面操作
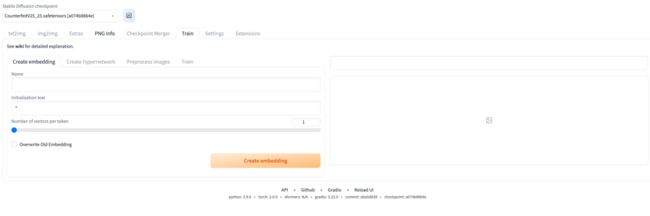
安装好后,运行webui.sh就可以启动了。打开界面一般长这样:
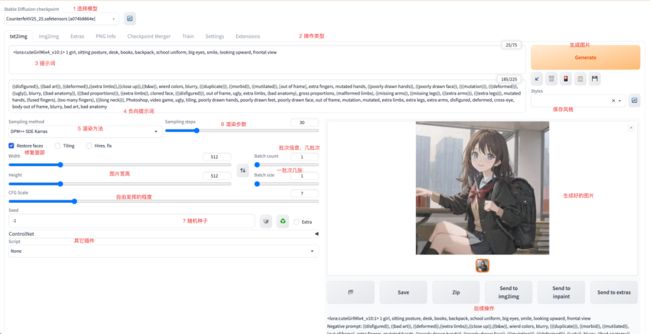
大概解释一下:
模型选择:可以选择官方的模型,或者自己加载的第三方模型,比如我目前这个就是社区里面基于sd1.5训练的二次元风格模型。点击旁边的刷新按钮可以刷新刚刚安装好的模型。
操作类型,比较常用的就是文字到图片,图片到图片。后面的有些是训练的插件,不展开讲。
提示词:生成图片最重要的部分,就是用文字来描述自己的需求,其中又有负面提示词,用来去掉某些元素。提示词有一些特殊的规则,后面单独开文章讲。
参数设置区,有很多参数。一般画人都会勾选面部修复,然后设置好图片的宽高,自由发挥的程度。越低越自由,越高越贴合你的词,一般推荐7~10。可以设置每批几张、一共跑几批。
图片操作区,可以把生成好的图片保存,或者发到图生图进行后续处理。
模型和Lora
sd官方的模型就是上面安装页面的1.5, 2.0, 2.1这些,也可以去huggingface.co 这个网站下载。
而社区模型比较推荐的是civitai.com这个网站。里面有大量的别人训练好的模型或者Lora,有各种风格。虽然我不知道为什么基本都是妹子的模型...

这里解释一下模型和Lora的大概区别:
模型:基于sd原本的模型,通过大量的图片训练后的模型,可以理解为换了一个画家。
Lora:基于sd原本的模型,训练后的插件,可以结合模型使用,可以理解为加了一层ps。
一般模型比较大(几个GB大小),而Lora比较小,通常在MB级别。还有其他的模型类型,但是我自己一般比较常用的就是基础模型和Lora。具体模型的原理和区别这里也不展开讲了。
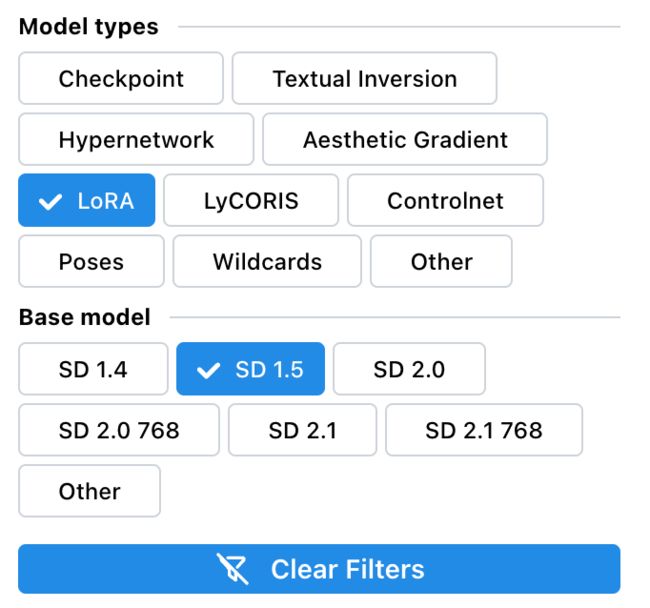
这里推荐几个模型或者插件:
二次元:anything-v3
国风:中国古风游戏角色模型,具有2.5D质感
dreamlike: 接近的mid风格,颜色艳丽,比较炫酷,插画的感觉
真人风格:protogen
高度定制化
细节优化
因为SD目前在一些细节处理上还不够成熟。所以有一些社区的插件来解决这类的问题,比较出名的就是controlnet。
简单来说你可以通过一个草图或者一张已有的图片来控制生成的图片的大体位置和形状。用来控制生成图片的姿势和布局非常有用。
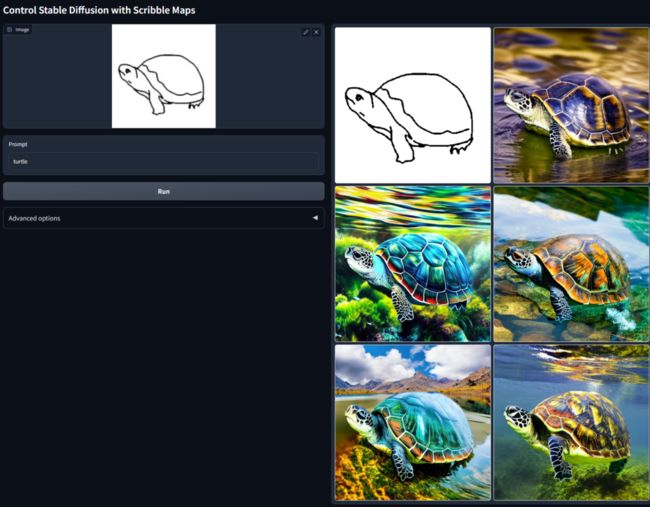
controlnet在b站上有不少的课程,可以学习使用姿势:
训练自己的风格
sd还可以用图片训练属于自己风格的模型(比如画出来的妹子都是你训练的图片的脸型,画出来的狗都跟你训练的狗的图片类似)。也是集成进了web-ui,使用起来比较方便。这块我也还没具体用过,等后面用到了再详细介绍吧。
附赠:今天画的一些图片
下面是同一组词,同一个参数,在不同模型下生成的图片:
prompt: lora:cuteGirlMix4_v10:1 1 girl, sitting posture, desk, books, backpack, school uniform, big eyes, smile, looking upward, frontal view
black prompt: ((disfigured)), ((bad art)), ((deformed)),((extra limbs)),((close up)),((b&w)), wierd colors, blurry, (((duplicate))), ((morbid)), ((mutilated)), [out of frame], extra fingers, mutated hands, ((poorly drawn hands)), ((poorly drawn face)), (((mutation))), (((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))), ((extra limbs)), cloned face, (((disfigured))), out of frame, ugly, extra limbs, (bad anatomy), gross proportions, (malformed limbs), ((missing arms)), ((missing legs)), (((extra arms))), (((extra legs))), mutated hands, (fused fingers), (too many fingers), (((long neck))), Photoshop, video game, ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, mutation, mutated, extra limbs, extra legs, extra arms, disfigured, deformed, cross-eye, body out of frame, blurry, bad art, bad anatomy,




em... 我还是喜欢真人风格,你呢?
![]()
关于作者
我是Yasin,一个爱写博客的技术人
微信公众号:编了个程(blgcheng)
个人网站:https://yasinshaw.com
欢迎关注这个公众号
