Jhipster 学习
Jhipster 学习
- 认识Jhipste
- Jhipste安装
-
- 1. Node.js 升级与安装。
- 2. 安装JDK11
- 3.Yeoman安装。
- 3.Jhipste安装
- Angular + Spring Boot应用
-
- 运行 jhipster项目
- 创建实体
-
- entity子生成器创建
- Jdl-studio创建
认识Jhipste
Jhipste安装
1. Node.js 升级与安装。
Jhipste的官网最新的Jhipste要求node.js是16.LTS。而大部分都是10、12这就需要升级。如果是windows下安装的node.js就不能通过npm install npm -g命令升级我踩过坑。我们需要到官网下载最新的版本,通过安装覆盖以前的版本。
2. 安装JDK11
下载JDK11–>https://www.oracle.com/java/technologies/javase-downloads.html
安装并配置环境。可以像我这样配置JDK的环境,这样可以轻松管理多个JDK。

3.Yeoman安装。
这是可选,如果你需要使用模块和蓝图(例如从JHipster Marketplace获取),则执行这一步。
npm install -g yo
3.Jhipste安装
1.安装JHipster
npm install -g generator-jhipster
Angular + Spring Boot应用
2.我们在D盘中创建一个文件夹Jhipster。打开终端、并进入Jhipster。
C:\Users\MrChe>d:
D:\>cd Jhipster
我们执行jhipster命令。
D:\Jhipster>jhipster
下面我们就可以看到jhipster的页面。
第一次创建Jhipster项目会问我们是否匿名报告使用统计数据。我们输入Y。
![]()
系统提供三种不同的创建App的方式。上下建可以选择,我们选择第一种创建一个简单项目,回车。

App的名字是什么。可以在后面填写App的名字,可以默认、点击回车会自动创建。
![]()
是否创建Spring WebFlux,我们选择no。
![]()
问package的名字,我们回车默认。
![]()
选择认证方式,我们JWT。

选择一个数据库的type,我们选择SQL.
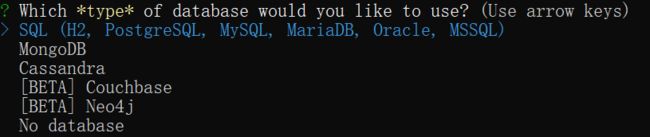
选择生产环境中使用的数据库,我们选择MySQL。

选择开发环境中使用的数据库,我们保持一致选择MySQL。

问需要安装什么缓存,我们先不选择。

问是否需要使用Hibernate 2级缓存?默认Yes。
![]()
使用Maven还是Gradle来构建微服务,选择Maven。

是否安装monitor、scale,我们用不到默认no.
![]()
选择需要用到的技术组件,多选题,有4个选项,使用上下键切换选项,使用空格键选中选项,使用a键全选,使用i键取消全选。根据自己的技术架构规划,选择相应的技术组件,也可以都不选择。
Search engine using ElasticSearch: 对于ES的支持(Spring Data Elasticsearch)
WebSockets using Spring Websocket:使用Spring Websocket的Websocket
Asynchronous messages using Apache Kafka:使用Apache Kafka的异步消息
API first development using OpenAPI-generator:通过OpenAPI-generator而使你的应用采用API优先的开发模式
![]()
选择前端框架选择,我们选择Angular。

是否生成一个admin UI,我们选择Yes
![]()
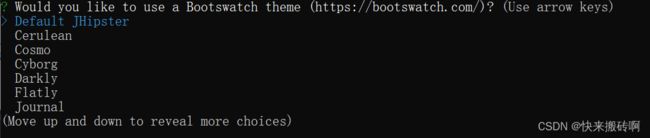
选择一个Bootswatch主题,可以到https://bootswatch.com查看,我查看了 也不知道选啥,我选择了默认。
是否需要国际化支持?默认Yes.
![]()
选择什么语言,当然选择世界通用的汉语。
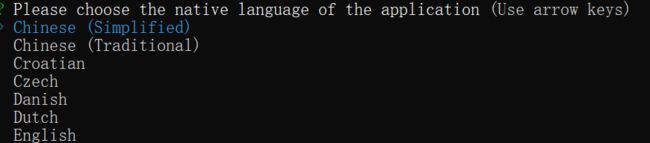
选择国际化支持中的其它语言。空格键选择,回车确认。

选择单元测试工具,我们默认不选。

还是否需要安装其它工具,默认no。
![]()
开始生成项目。

因为第一次安装,因为要安装Maven的依赖所以会很慢。
运行 jhipster项目
我们用Idea打开我们项目。
找到【src/main/resources/config/application-dev.yml】修改数据库的密码,并在MySQL中创建一个数据库。
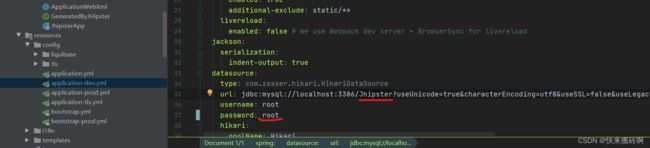
点击Run运行我们的项目。
这样我们的Jhipster服务器就已经启动了。
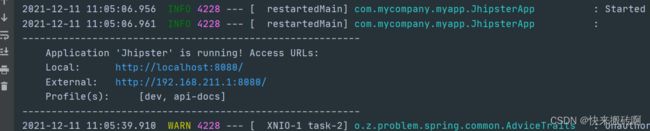
回到我们刚才的终端,输入npm start启动我们的客户端。
D:\Jhipster>npm start
系统会自动跳转Jhipster首页。
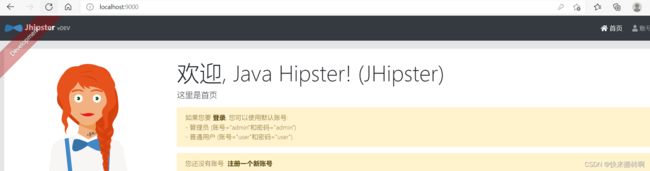
创建实体
官网介绍有种方式创建实体:
“entity”子生成器:使用交互式命令的方式创建实体,只需要和终端进行交互就行,简单的实体创建比较方便,一旦涉及到实体比较多,实体之间的关系复杂时(一对一,一对多,多对多),不推荐这种方式
JHipster UML与JDL Studio:官方不推荐使用UML方式,推荐JDL Studio方式。使用JDL Studio 可以快速创建实体(类似Class),也可以创建实体之间的关系,并且还有可视化的uml类图。
entity子生成器创建
执行命令。
D:\Jhipster>jhipster entity teacher
是添加字段,我们选Yes。
![]()
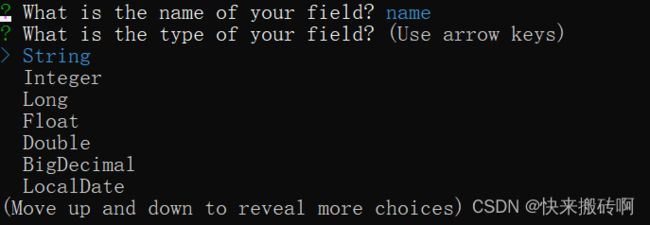
输入指端名字,并选择字段类型。
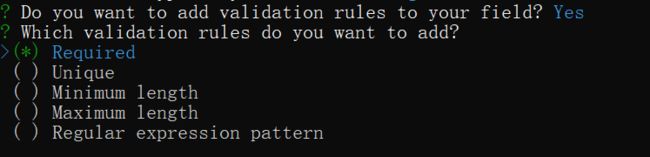
是否添加规则验证。选择Yes,并选择验证规则为Required。
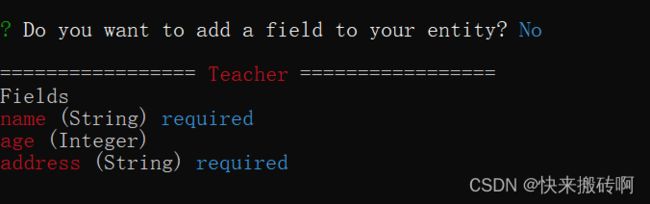
重复上面的步骤我们添加其他的字段。

选择No结束添加。
是否创建服务层,根据自己的需求选择,这里我们需要。

是否创建DTO,我们选Yes.

是否创建过滤,我们添加。

是否只读,选No.
![]()
是否添加分页,我们添加。

是否覆盖,我们就覆盖吧输入Y并回车。
![]()
虽然搞不懂它字段的填充规则,但是这样就添加完成了。
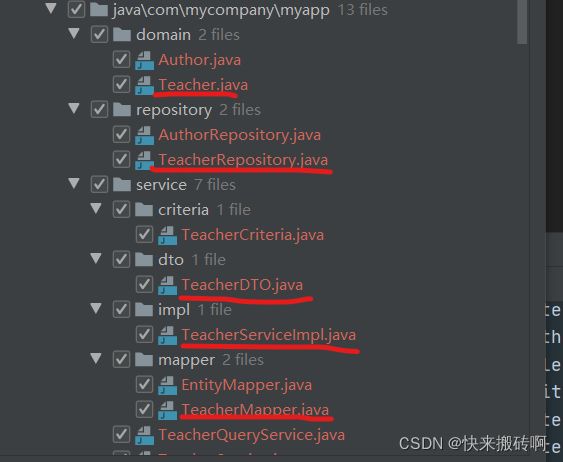
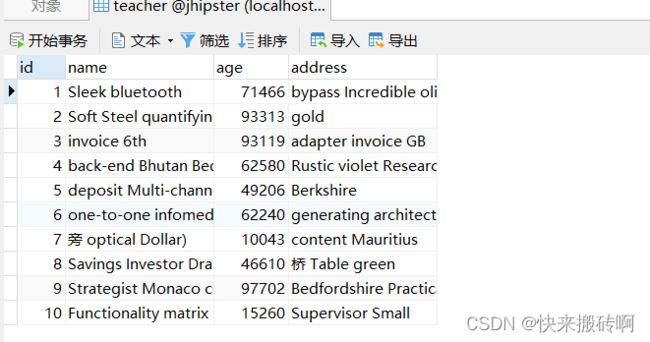
管理页面也看到我们的表,我们可以进行增删改查了。
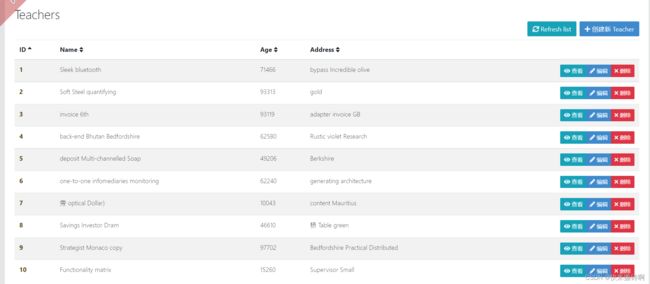
Jdl-studio创建
我们可以在线编写JDL后,将文件保存到本地,然后再项目根目录执行命令。
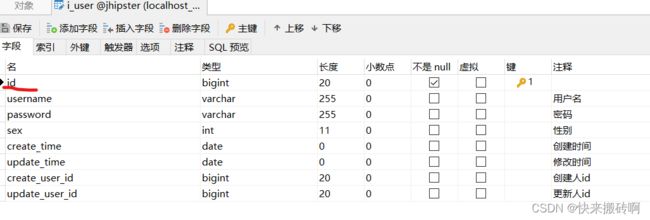
我们编写的一个用户角色菜单的实体,其中t_User 是用户实体,t_Role 是角色实体,t_Menu 是菜单实体,t_UserRole用户角色中间表实体,t_RoleMenu角色菜单中间表实体。然后在建立一对一、一对多的关系,并添加了业务层(默认不会创建Service)。
这里的jdl文件,我在每个实体和属性都创建了注释,这样java类会创建注释,数据库也会创建注释。
在使用实体之间的关系时,不能预先创建关联的id属性,系统会自动生成。
/**
* 用户表
*/
entity IUser {
/**
* 用户名
*/
username String,
/**
* 密码
*/
password String,
/**
* 性别
*/
sex Integer,
/**
* 创建时间
*/
createTime LocalDate,
/**
* 修改时间
*/
updateTime LocalDate,
/**
* 创建人id
*/
createUserId Long,
/**
* 更新人id
*/
updateUserId Long,
}
/**
* 角色表
*/
entity IRole {
/**
* 角色名
*/
roleName String,
/**
* 备注
*/
remark String,
/**
* 创建时间
*/
createTime LocalDate,
/**
* 修改时间
*/
updateTime LocalDate,
/**
* 创建人id
*/
createUserId Long,
/**
* 更新人id
*/
updateUserId Long,
}
/**
* 用户角色中间表
*/
entity IUserRole
/**
* 菜单表
*/
entity IMenu {
/**
* 菜单路由
*/
url String,
/**
* 菜单名字
*/
menuName String,
/**
* 父级菜单id
*/
parentId Long,
/**
* 创建时间
*/
createTime LocalDate,
/**
* 修改时间
*/
updateTime LocalDate,
/**
* 创建人id
*/
createUserId Long,
/**
* 更新人id
*/
updateUserId Long,
}
/**
* 菜单角色中间表
*/
entity IRoleMenu
relationship OneToOne {
IRole{users} to IUserRole{role},
IRole{menus} to IRoleMenu{role},
}
relationship OneToMany {
IUser{roles} to IUserRole{user},
IMenu{roles} to IRoleMenu{menu},
}
// 设置分页信息
paginate IUser, IRole with infinite-scroll
paginate IMenu with pagination
// Use Data Transfer Objects (DTO)
// dto * with mapstruct
// 设置服务层
service all with serviceImpl except IUser, IRole, IMenu
执行命令 jhipster jdl D:\Jhipster\jhipster-jdl.jdl
jhipster jdl D:\Jhipster\jhipster-jdl.jdl
创建成功。
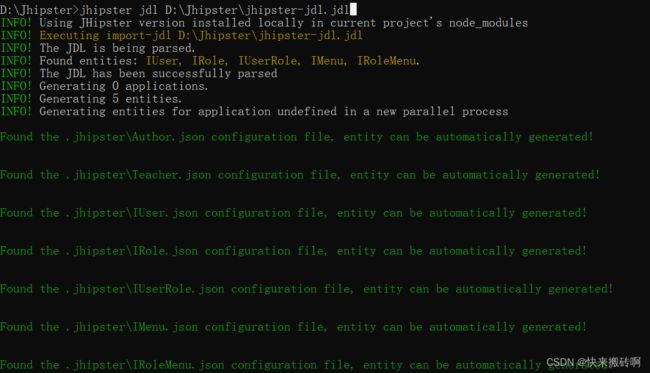
系统会自动添加id。