高并发秒杀系统分析
转载于 :http://blog.csdn.net/jeffleo/article/details/56015710
本文是学习了immoc网视频之后的个人理解和知识汇总
项目源码:https://github.com/jeff-leo/SpikeSystem,希望大家能star和fork
一、秒杀系统中存在高并发的点
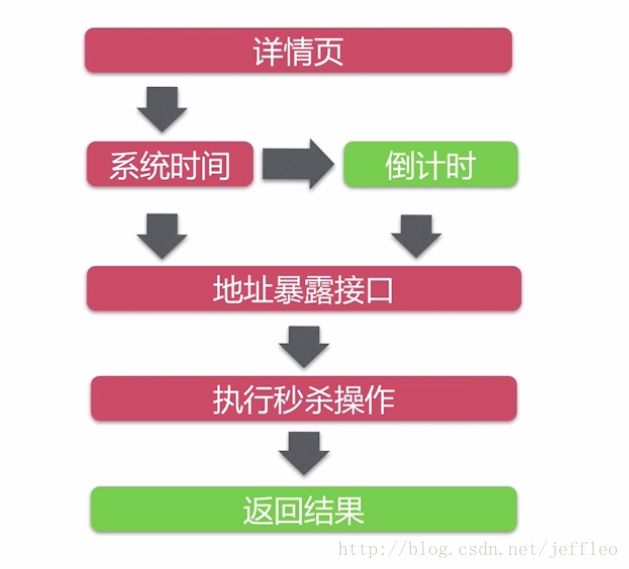
一个秒杀系统的基本流程基本如上所示
用户请求详情页,系统时间,请求秒杀接口,执行秒杀操作都是位于服务端,都会被大量访问,那么我们优化系统高并发就是从这四点着手
1. 请求详情页的优化
详情页是属于静态济源,例如css,js等,对于这些静态资源,如果全部放在服务端主机中,势必对服务主机造成很大的压力,并发量也得不到支持,我们可以使用CDN来进行优化
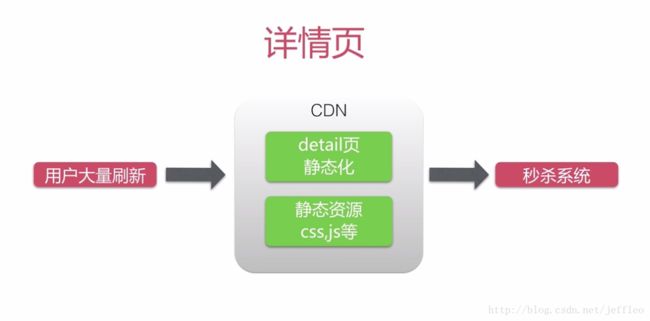
什么是CDN?
使用CDN会极大地简化网站的系统维护工作量,网站维护人员只需将网站内容注入CDN的系统,通过CDN部署在各个物理位置的服务器进行全网分发,就可以实现跨运营商、跨地域的用户覆盖。由于CDN将内容推送到网络边缘,大量的用户访问被分散在网络边缘,不再构成网站出口、互联互通点的资源挤占,也不再需要跨越长距离IP路由了
传统的B/S架构:
B/S架构,即Browser-Server(浏览器 服务器)架构,是对传统C/S架构的一种变化或者改进架构。在这种架构下,用户只需使用通用浏览器,主要业务逻辑在服务器端实现。B/S架构,主要是利用了不断成熟的WWW浏览器技术,结合浏览器的多种Script语言(VBScript、JavaScript等)和ActiveX等技术,在通用浏览器上实现了C/S架构下需要复杂的软件才能实现的强大功能。
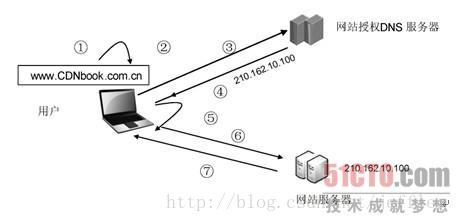
①用户在自己的浏览器中输入要访问的网站域名。
②浏览器向本地DNS服务器请求对该域名的解析。
③本地DNS服务器中如果缓存有这个域名的解析结果,则直接响应用户的解析请求。
④本地DNS服务器中如果没有关于这个域名的解析结果的缓存,则以递归方式向整个DNS系统请求解析,获得应答后将结果反馈给浏览器。
⑤浏览器得到域名解析结果,就是该域名相应的服务设备的IP地址。
⑥浏览器向服务器请求内容。
⑦服务器将用户请求内容传送给浏览器
加入cdn后:
在网站和用户之间加入CDN以后,用户不会有任何与原来不同的感觉。最简单的CDN网络有一个DNS服务器和几台缓存服务器就可以运行了。一个典型的CDN用户访问调度流程
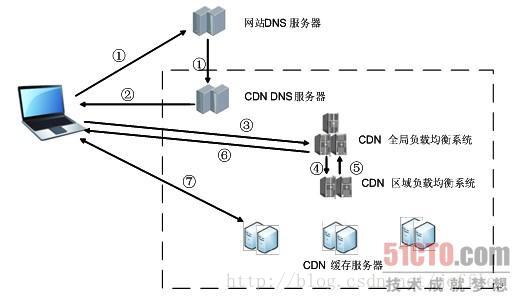
①当用户点击网站页面上的内容URL,经过本地DNS系统解析,DNS系统会最终将域名的解析权交给CNAME指向的CDN专用DNS服务器。
②CDN的DNS服务器将CDN的全局负载均衡设备IP地址返回用户。
③用户向CDN的全局负载均衡设备发起内容URL访问请求。
④CDN全局负载均衡设备根据用户IP地址,以及用户请求的内容URL,选择一台用户所属区域的区域负载均衡设备,告诉用户向这台设备发起请求。
⑤区域负载均衡设备会为用户选择一台合适的缓存服务器提供服务,选择的依据包括:根据用户IP地址,判断哪一台服务器距用户最近;根据用户所请求的URL中携带的内容名称,判断哪一台服务器上有用户所需内容;查询各个服务器当前的负载情况,判断哪一台服务器尚有服务能力。基于以上这些条件的综合分析之后,区域负载均衡设备会向全局负载均衡设备返回一台缓存服务器的IP地址。
⑥全局负载均衡设备把服务器的IP地址返回给用户。
⑦用户向缓存服务器发起请求,缓存服务器响应用户请求,将用户所需内容传送到用户终端。如果这台缓存服务器上并没有用户想要的内容,而区域均衡设备依然将它分配给了用户,那么这台服务器就要向它的上一级缓存服务器请求内容,直至追溯到网站的源服务器将内容拉到本地。
DNS服务器根据用户IP地址,将域名解析成相应节点的缓存服务器IP地址,实现用户就近访问。使用CDN服务的网站,只需将其域名解析权交给CDN的GSLB设备,将需要分发的内容注入CDN,就可以实现内容加速了。
2. 获取系统时间操作的优化
获取系统时间的操作不用优化,Java访问一次内存大概10ns,1,000,000,000 纳秒 = 1秒 ,也就是说1s中可以访问1,000,000,00次内存,所以根本不需要我们去优化!
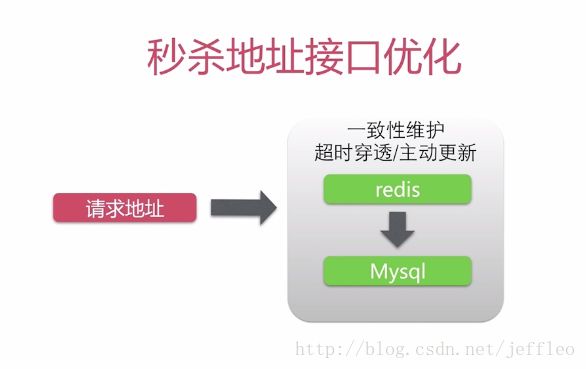
3. 秒杀地址接口获取的优化
cdn适合存放不变的内容,例如css,js等静态内存,所以它不适合放在cdn中缓存,但是适合在服务端缓存,例如Redis,甚至可以做redis集群。
4. 秒杀操作高并发的问题(重点)
1. 这个也是不能使用cdn缓存的,但是能不能使用redis做缓存呢?秒杀首先会在数据库中减库存,那我们能在redis缓存中做减库存操作吗?肯定不可以,因为这会导致数据一致性的问题,凡是需要进行写操作的数据都不适合做缓存。
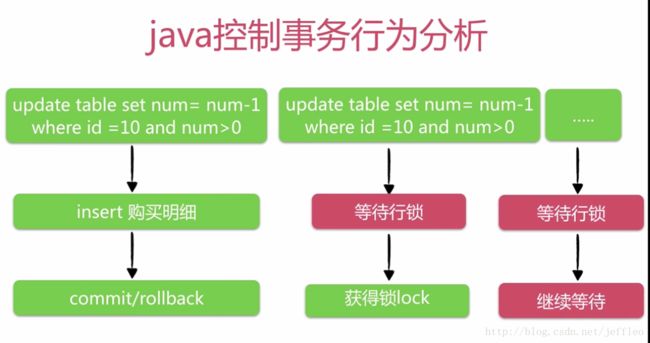
2. 高并发的点还在于,热点商品竞争上。当多个用户在秒杀同一个商品时,由于MySQL的事务机制和行级锁,一个用户在获取该商品额行级锁进行减库存操作时,其它的用户只能等待,这就变成了串行的操作,这就是秒杀操作高并发中最困难的优化点
二、如何优化秒杀操作
第一个方案:
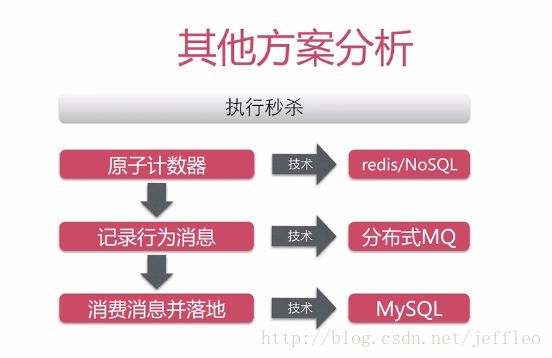
首先,可以用NoSQL例如redis作为一个原子计数器,记录商品的库存,当用户秒杀该商品时,该计数器便减1;
然后记录哪个用户秒杀了该商品,作为一个消息,存储到分布式mq中(例如alibaba的rocketMQ);
最后由服务端的服务去执行数据库的update操作。
这个方案有什么问题呢?
1. 运维和不稳定性,NoSQL不如MySQL稳定,所以需要高水平的运维团队
2. 重发秒杀的问题。在记录行为信息中,分布式MQ只知道记录哪个用户在秒杀该商品,但是不知道该用户是否已经重复秒杀过该商品,因此还需要另外维护一个NoSQL,来记录哪些用户已经秒杀了哪些商品,加大了成本
第二个方案:在mysql上优化
我们之所以考虑第一个方案,就是因为MySQL低效,为什么低效
我们来看看mysql执行一条update的并发量:
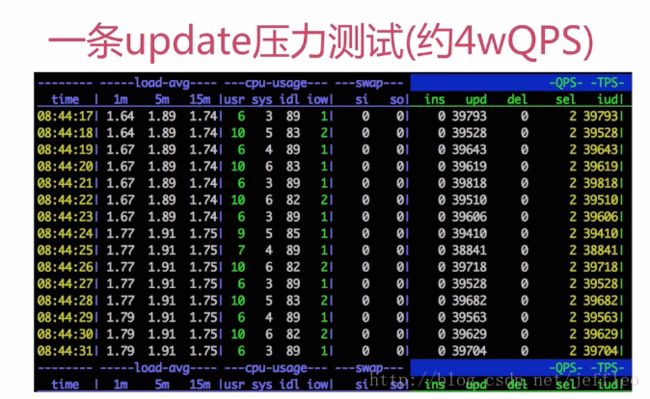
可以看到,mysql可以抗住大约4wQPS,那么MySQL本身是不低效的,但是是什么地方使得它低效呢?
我们分析一下瓶颈所在:

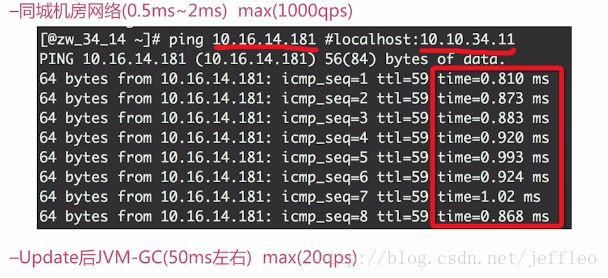
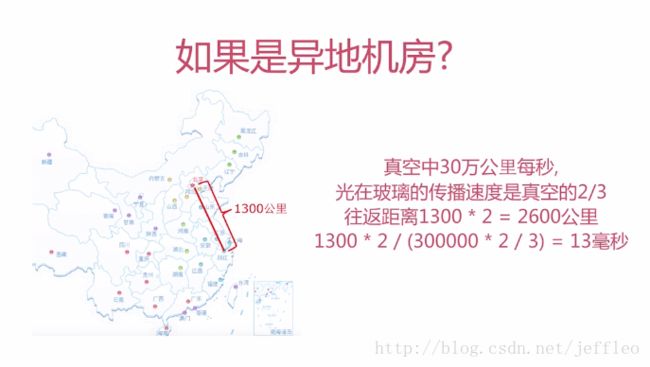
服务端的程序和数据库一般放在不同的主机上,当服务端进行减库存操作时,会发送update的sql语句到数据库中,这里会存在一个网络延迟和gc,同样insert语句记录秒杀明细也会存在网络延迟和gc,假如一次的网络延迟和gc加起来的总延迟是2ms,那么1s就只能进行500次的秒杀操作
同城机房:
异地机房:
优化:把服务器的执行逻辑放在mysql服务端,避免网络延迟和gc延迟
两种方案:
1. 定制sql方案:update /* + [auto_commit] + */,需要修改mysql源码(太困难)
2. 使用存储过程,在mysql中去完成整个秒杀操作的事务(即把下面这个操作放到存储过程中),虽然存储过程在互联网中很少用,但是在
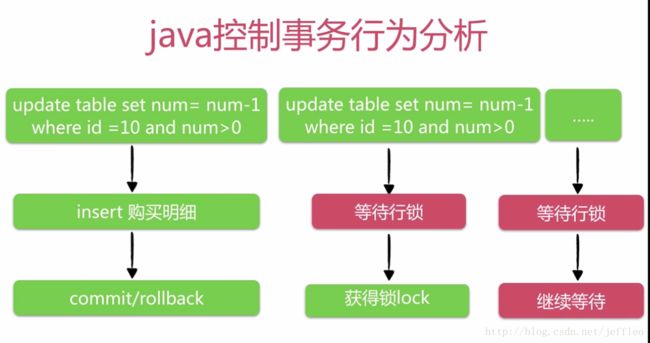
因此,在项目中我们会使用到存储过程来实现秒杀操作
三、使用存储过程来优化秒杀操作
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
参考:
CDN的基本工作过程
imooc
更多关于系统架构和分布式的了解:
分布式架构的演进