Doris 学习总结
自从今年鼎石科技公开了自家的DorisDB后(相关视频见B站), Apache Doris 在社区中掀起了一波热潮, 我也跟风来学习一下,相关总结与大家分享。
首先简单的说下啥是Doris吧,Doris是一个基于mpp的交互式SQL数据仓库,是一个面向多种数据分析场景的、 兼容MySQL协议的, 高性能的, 分布式关系型列式数据库,用于报告和分析。它最初的名字是Palo,由百度开发。在于2018年捐赠给Apache软件基金会后,它被命名为Doris。Doris主要集成了谷歌Mesa和Apache Impala技术,基于面向列的存储引擎,可以通过MySQL客户端进行通信。
现在你了解了啥是Doris,我想你肯定想知道它适合应用在那些场景中,目前Doris可以满足企业级用户的多种分析需求,包括OLAP多维分析,定制报表,实时数据分析,Ad-hoc数据分析等。具体的业务场景包括:
- 数据仓库建设
- OLAP/BI分析
- 用户行为分析
- 广告数据分析
- 系统监控分析
- 探针分析 APM(Application Performance Management)
简单的来说,传统数仓能做的事Doris也能做,查询分析引擎能干的事Doris也能搞定,总之一句话,存储、计算、查询Doris统一搞定,实时、离线统一数据源。要问Doris 为啥这么牛逼,一出生就决定了,没办法,就这么的牛!
把Doris吹的有点过了,接下来让我们好好了解了解它吧。
DorisDB基本概念
- FE:FrontEnd Doris的前端节点,负责管理元数据,管理客户端连接,进行查询规划,查询调度等工作。
- BE:BackEnd Doris的后端节点,负责数据存储,计算执行,以及compaction,副本管理等工作。
- Broker:Doris中和外部HDFS/对象存储等外部数据对接的中转服务,辅助提供导入导出功能。
- Tablet:Doris 表的逻辑分片,也是Doris中副本管理的基本单位,每个表根据分区和分桶机制被划分成多个Tablet存储在不同BE节点上。
架构图
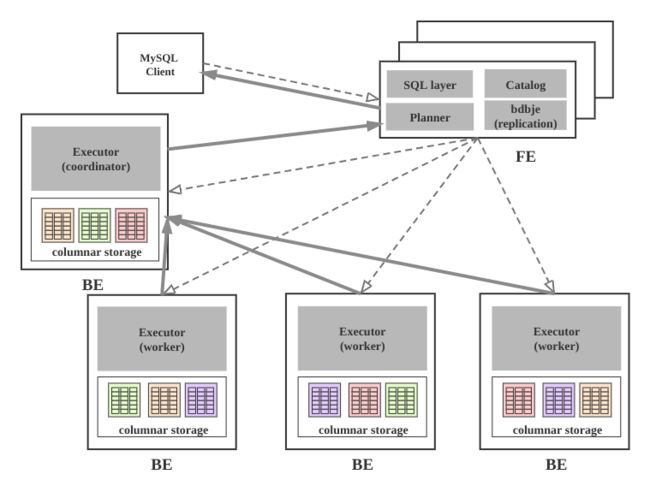
组件介绍
Doris 集群由FE和BE构成, 可以使用MySQL客户端访问Doris集群。
FE
FE接收MySQL客户端的连接, 解析并执行SQL语句。
- 管理元数据, 执行SQL DDL命令, 用Catalog记录库, 表, 分区, tablet副本等信息。
- FE高可用部署, 使用复制协议选主和主从同步元数据, 所有的元数据修改操作, 由FE leader节点完成, FE follower节点可执行读操作。 元数据的读写满足顺序一致性。 FE的节点数目采用2n+1, 可容忍n个节点故障。 当FE leader故障时, 从现有的follower节点重新选主, 完成故障切换。
- FE的SQL layer对用户提交的SQL进行解析, 分析, 改写, 语义分析和关系代数优化, 生产逻辑执行计划。
- FE的Planner负载把逻辑计划转化为可分布式执行的物理计划, 分发给一组BE。
- FE监督BE, 管理BE的上下线, 根据BE的存活和健康状态, 维持tablet副本的数量。
- FE协调数据导入, 保证数据导入的一致性。
BE
- BE管理tablet副本, tablet是table经过分区分桶形成的子表, 采用列式存储。
- BE受FE指导, 创建或删除子表。
- BE接收FE分发的物理执行计划并指定BE coordinator节点, 在BE coordinator的调度下, 与其他BE worker共同协作完成执行。
- BE读本地的列存储引擎, 获取数据, 通过索引和谓词下沉快速过滤数据。
- BE后台执行compact任务, 减少查询时的读放大。
- 数据导入时, 由FE指定BE coordinator, 将数据以fanout的形式写入到tablet多副本所在的BE上。
其他组件
- Hdfs Broker: 用于从Hdfs中导入数据到Doris集群。
数据流和控制流
查询
查询流程图:
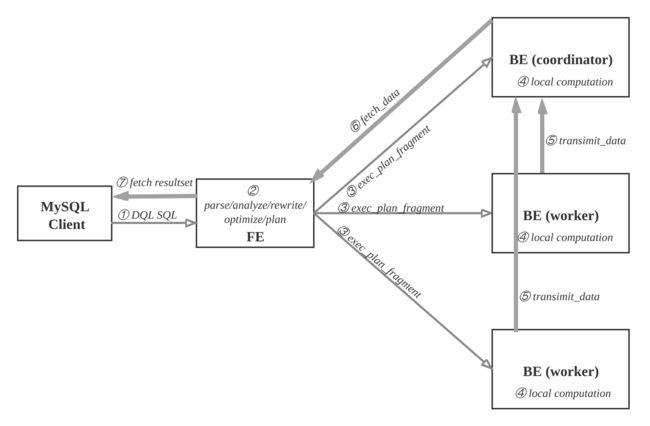
用户可使用MySQL客户端连接FE,执行SQL查询, 获得结果。
查询流程如下:
- ① MySQL客户端执行DQL SQL命令。
- ② FE解析, 分析, 改写, 优化和规划, 生成分布式执行计划。
- ③ 分布式执行计划由 若干个可在单台be上执行的plan fragment构成, FE执行exec_plan_fragment, 将plan fragment分发给BE,指定其中一台BE为coordinator。
- ④ BE执行本地计算, 比如扫描数据。
- ⑤ 其他BE调用transimit_data将中间结果发送给BE coordinator节点汇总为最终结果。
- ⑥ FE调用fetch_data获取最终结果。
- ⑦ FE将最终结果发送给MySQL client。
执行计划在BE上的实际执行过程比较复杂, 采用向量化执行方式,比如一个算子产生4096个结果,输出到下一个算子参与计算,而非batch方式或者one-tuple-at-a-time。
**思考:**在开篇中我说了Doris继承了Apache Impala的技术,这里Doris为什么要指定其中一台BE为coordinator呢,这里和Impala的查询过程中有何不同呢,在这里Doris做了什么优化呢?
数据导入
数据导入功能是将原始数据按照相应的模型进行清洗转换并加载到Doris中,方便查询使用。Doris提供了多种导入方式,用户可以根据数据量大小、导入频率等要求选择最适合自己业务需求的导入方式。
用户创建表之后, 导入数据填充表.
- 支持导入数据源有: 本地文件, HDFS、Kafka和S3等。
- 支持导入方式有: 批量导入, 流式导入, 实时导入.
- 支持的数据格式有: CSV, Parquet, ORC等.
- 导入发起方式有: 用RESTful接口, 执行SQL命令.
数据导入的流程如下:
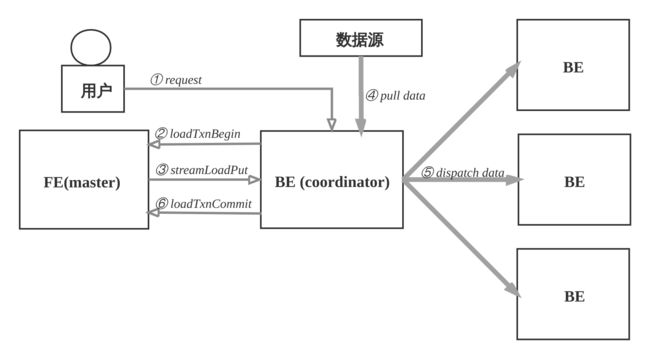
- ① 用户选择一台BE作为协调者, 发起数据导入请求, 传入数据格式, 数据源和标识此次数据导入的label, label用于避免数据重复导入. 用户也可以向FE发起请求, FE会把请求重定向给BE。
- ② BE收到请求后, 向FE master节点上报, 执行loadTxnBegin, 创建全局事务。 因为导入过程中, 需要同时更新base表和物化索引的多个bucket, 为了保证数据导入的一致性, 用事务控制本次导入的原子性。
- ③ BE创建事务成功后, 执行streamLoadPut调用, 从FE获得本次数据导入的计划. 数据导入, 可以看成是将数据分发到所涉及的全部的tablet副本上, BE从FE获取的导入计划包含数据的schema信息和tablet副本信息。
- ④ BE从数据源拉取数据, 根据base表和物化索引表的schema信息, 构造内部数据格式。
- ⑤ BE根据分区分桶的规则和副本位置信息, 将发往同一个BE的数据, 批量打包, 发送给BE, BE收到数据后, 将数据写入到对应的tablet副本中。
- ⑥ 当BE coordinator节点完成此次数据导入, 向FE master节点执行loadTxnCommit, 提交全局事务, 发送本次数据导入的 执行情况, FE master确认所有涉及的tablet的多数副本都成功完成, 则发布本次数据导入使数据对外可见, 否则, 导入失败, 数据不可见, 后台负责清理掉不一致的数据。
关于数据导入详情见:数据导入
更改元数据
更改元数据的操作有: 创建数据库, 创建表, 创建物化视图, 修改schema等等. 这样的操作需要:
- 持久化到永久存储的设备上;
- 保证高可用, 复制FE多实例上, 避免单点故障;
- 有的操作需要在BE上生效, 比如创建表时, 需要在BE上创建tablet副本.
元数据的更新操作流程如下:
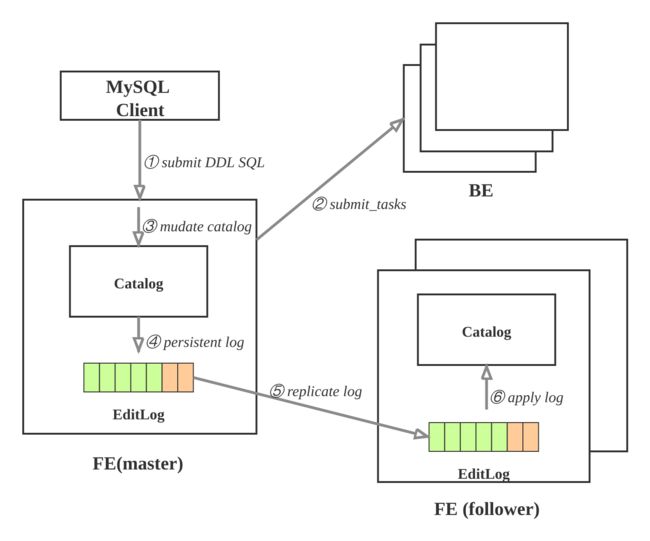
- ① 用户使用MySQL client执行SQL的DDL命令, 向FE的master节点发起请求; 比如: 创建表.
- ② FE检查请求合法性, 然后向BE发起同步命令, 使操作在BE上生效; 比如: FE确定表的列类型是否合法, 计算tablet的副本的放置位置, 向BE发起请求, 创建tablet副本.
- ③ BE执行成功, 则修改内存的Catalog. 比如: 将 table, partition, index, tablet 的副本信息保存在Catalog中.
- ④ FE追加本次操作到EditLog并且持久化.
- ⑤ FE通过复制协议将EditLog的新增操作项同步到FE的follower节点.
- ⑥ FE的follower节点收到新追加的操作项后, 在自己的Catalog上按顺序播放, 使得自己状态追上FE master节点.
上述执行环节出现失败, 则本次元数据修改失败。
**思考:**为什么操作先要在BE上生效再修改内存的Catalog呢?在开篇中我说了Doris继承了Apache Impala的技术,那么Impala在修改元数据的时候具体流程又是如呢?
Doris元数据设计
名词解释
- FE:Frontend,即 Doris 的前端节点。主要负责接收和返回客户端请求、元数据以及集群管理、查询计划生成等工作。
- BE:Backend,即 Doris 的后端节点。主要负责数据存储与管理、查询计划执行等工作。
- bdbje:Oracle Berkeley DB Java Edition。在 Doris 中,我们使用 bdbje 完成元数据操作日志的持久化、FE 高可用等功能。
整体架构
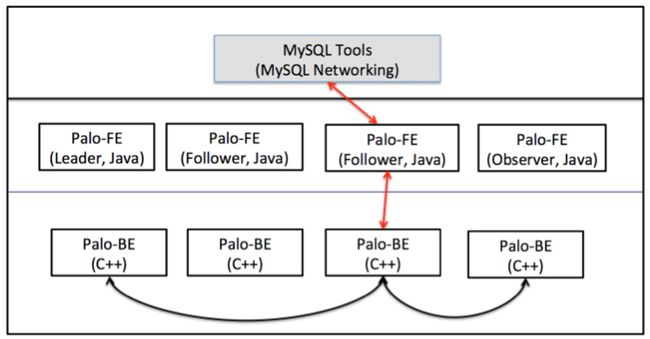
如上图,Doris 的整体架构分为两层。多个 FE 组成第一层,提供 FE 的横向扩展和高可用。多个 BE 组成第二层,负责数据存储于管理。这里主要介绍 FE 这一层中,元数据的设计与实现方式。
-
FE 节点分为 follower 和 observer 两类。各个 FE 之间,通过 bdbje(BerkeleyDB Java Edition)进行 leader 选举,数据同步等工作。
-
follower 节点通过选举,其中一个 follower 成为 leader 节点,负责元数据的写入操作。当 leader 节点宕机后,其他 follower 节点会重新选举出一个 leader,保证服务的高可用。
-
observer 节点仅从 leader 节点进行元数据同步,不参与选举。可以横向扩展以提供元数据的读服务的扩展性。
元数据结构
Doris 的元数据是全内存的。每个 FE 内存中,都维护一个完整的元数据镜像。在百度内部,一个包含2500张表,100万个分片(300万副本)的集群,元数据在内存中仅占用约 2GB。(当然,查询所使用的中间对象、各种作业信息等内存开销,需要根据实际情况估算。但总体依然维持在一个较低的内存开销范围内。)
同时,元数据在内存中整体采用树状的层级结构存储,并且通过添加辅助结构,能够快速访问各个层级的元数据信息。
下图是 Doris 元信息所存储的内容。

如上图,Doris 的元数据主要存储4类数据:
- 用户数据信息。包括数据库、表的 Schema、分片信息等。
- 各类作业信息。如导入作业,Clone 作业、SchemaChange 作业等。
- 用户及权限信息。
- 集群及节点信息。
数据流
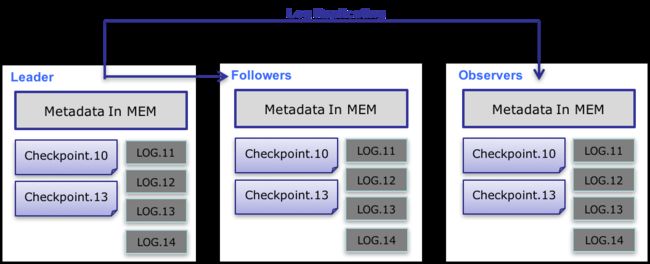
元数据的数据流具体过程如下:
- 只有 leader FE 可以对元数据进行写操作。写操作在修改 leader 的内存后,会序列化为一条log,按照 key-value 的形式写入 bdbje。其中 key 为连续的整型,作为 log id,value 即为序列化后的操作日志。
- 日志写入 bdbje 后,bdbje 会根据策略(写多数/全写),将日志复制到其他 non-leader 的 FE 节点。non-leader FE 节点通过对日志回放,修改自身的元数据内存镜像,完成与 leader 节点的元数据同步。
- leader 节点的日志条数达到阈值后(默认 10w 条),会启动 checkpoint 线程。checkpoint 会读取已有的 image 文件,和其之后的日志,重新在内存中回放出一份新的元数据镜像副本。然后将该副本写入到磁盘,形成一个新的 image。之所以是重新生成一份镜像副本,而不是将已有镜像写成 image,主要是考虑写 image 加读锁期间,会阻塞写操作。所以每次 checkpoint 会占用双倍内存空间。
- image 文件生成后,leader 节点会通知其他 non-leader 节点新的 image 已生成。non-leader 主动通过 http 拉取最新的 image 文件,来更换本地的旧文件。
- bdbje 中的日志,在 image 做完后,会定期删除旧的日志。
元数据目录
- 元数据目录通过 FE 的配置项
meta_dir指定。 bdb/目录下为 bdbje 的数据存放目录。image/目录下为 image 文件的存放目录。image.[logid]是最新的 image 文件。后缀logid表明 image 所包含的最后一条日志的 id。image.ckpt是正在写入的 image 文件,如果写入成功,会重命名为image.[logid],并替换掉旧的 image 文件。VERSION文件中记录着cluster_id。cluster_id唯一标识一个 Doris 集群。是在 leader 第一次启动时随机生成的一个 32 位整型。也可以通过 fe 配置项cluster_id来指定一个 cluster id。ROLE文件中记录的 FE 自身的角色。只有FOLLOWER和OBSERVER两种。其中FOLLOWER表示 FE 为一个可选举的节点。(注意:即使是 leader 节点,其角色也为FOLLOWER)
元数据读写与同步
-
用户可以使用 mysql 连接任意一个 FE 节点进行元数据的读写访问。如果连接的是 non-leader 节点,则该节点会将写操作转发给 leader 节点。leader 写成功后,会返回一个 leader 当前最新的 log id。之后,non-leader 节点会等待自身回放的 log id 大于回传的 log id 后,才将命令成功的消息返回给客户端。这种方式保证了任意 FE 节点的 Read-Your-Write 语义。
注:一些非写操作,也会转发给 leader 执行。比如
SHOW LOAD操作。因为这些命令通常需要读取一些作业的中间状态,而这些中间状态是不写 bdbje 的,因此 non-leader 节点的内存中,是没有这些中间状态的。(FE 之间的元数据同步完全依赖 bdbje 的日志回放,如果一个元数据修改操作不写 bdbje 日志,则在其他 non-leader 节点中是看不到该操作修改后的结果的。) -
leader 节点会启动一个 TimePrinter 线程。该线程会定期向 bdbje 中写入一个当前时间的 key-value 条目。其余 non-leader 节点通过回放这条日志,读取日志中记录的时间,和本地时间进行比较,如果发现和本地时间的落后大于指定的阈值(配置项:
meta_delay_toleration_second。写入间隔为该配置项的一半),则该节点会处于不可读的状态。此机制解决了 non-leader 节点在长时间和 leader 失联后,仍然提供过期的元数据服务的问题。 -
各个 FE 的元数据只保证最终一致性。正常情况下,不一致的窗口期仅为毫秒级。我们保证同一 session 中,元数据访问的单调一致性。但是如果同一 client 连接不同 FE,则可能出现元数据回退的现象。(但对于批量更新系统,该问题影响很小)
宕机恢复
- leader 节点宕机后,其余 follower 会立即选举出一个新的 leader 节点提供服务。
- 当多数 follower 节点宕机时,元数据不可写入。当元数据处于不可写入状态下,如果这时发生写操作请求,目前的处理流程是 FE 进程直接退出。后续会优化这个逻辑,在不可写状态下,依然提供读服务。
- observer 节点宕机,不会影响任何其他节点的状态。也不会影响元数据在其他节点的读写。
思考:
1、如果只留一个 leader节点,其他follower 节点都宕机,那么按理来说 Doris 依然能正常提供服务
2、如过这里 leader节点宕机,只留下一个 follower 节点那么 Doris 还能正常提供服务嘛
移动端见个人公众号文章: 大数据理论与实战
个人博客网站见: 个人博客