1. Introduction
google服务器集群的管理系统,类似于百度的Matrix,阿里的fuxi,腾讯的台风平台等等,还有开源的mesos

Borg provides three main benefits: it
- hides the details of resource management and failure handling so its users can focus on application development instead;
- operates with very high reliability and availability, and supports applications that do the same; and
- lets us run workloads across tens of thousands of machines effectively.
2. The user perspective
borg主要面向于系统管理员和google开发者,这些用户在borg上面运行他们的服务和应用程序,用户以job的形式提交任务,每个job包含一个或者多个tasks,每个job运行在一个cell里,cell是机器的集合,可以理解为是一个逻辑的IDC
2.1 The workload
borg上运行的服务通常可以分为两类:
- prod:long-running服务,几乎不停机,时延敏感,例如gmail,google docs,google搜索等等,另外还有一些google内部的基础架构平台,例如bigtable,GFS
- non-prod:batch型任务,时延不敏感,通常几小时或者几天即可跑完
这两种不通类型的任务在borg的cell里通常是混部的,同时又需要结合不同类型任务的特点,以及IDC属性,等等做出不同的调度策略。例如end-user-facing服务利用率通常都会有一个固定的模式,白天的时候利用率很高,晚上机器又很闲,深夜可能几乎没什么访问量等等,另外Batch型任务执行时间段,一般上来跑个几分钟,几小时就完成任务了。等等。
borg最主要的目的,就是要提高机器的利用率。
在google内部,很多应用程序框架都是构建在borg之上的,例如mapreduce系统,FlumeJava,Millwheel,Pregel,还有google的分布式存储服务,例如GFS,Bigtable,Megastore。像mapreduce,flumejava这种服务,master和他们的job都是跑在borg上的,这里的master和job区别于borg里的master和job
In a representative cell, prod jobs are allocated about 70% of the total CPU resources and represent about 60% of the total CPU usage; they are allocated about 55% of the total memory and represent about 85% of the total memory usage.
2.2 Clusters and cells
数据中心 > 集群 > cell
A cluster usually hosts one large cell and may have a few smaller-scale test or special-purpose cells. We assiduously avoid any single point of failure. 中等规模的cell大约10k台服务器左右,不包括测试cell,我的理解这些smaller-scale test cell的主要作用是小流量专用?每个机器上可供调度的资源类型包括:cpu,内存,网络,磁盘,甚至是处理器性能,类型,以及ssd,ip地址等等(我的理解,对于某些类型的服务,是需要固定IP,而不允许随意调度,例如存储系统)。
用户在提交job的时候申请资源,然后borg将它们调度到某机器上执行,监控他们的状态,如果有必要在job的状态failed后重启它们
2.3 Jobs and tasks
job的属性包括:名称,owner,tasks,同时还包括一些调度的约束条件,例如处理器架构,os版本,ip地址等等,这些会影响borg-master调度的结果,当然这些条件不一定是强制约束的,分hard和soft两种。
一个job只能跑在一个cell里,每个job会有N个task,每个task运行期间会有多个进程,google并没有使用虚拟机的方式来进行task之间的资源隔离,而是使用轻量级的容器技术cgroup。
task也有自己的属性:资源需求和一个index,大部分时候一个job里的所有task的资源需求都是一样的。
Users operate on jobs by issuing remote procedure calls (RPCs) to Borg, most commonly from a command-line tool, other Borg jobs, or our monitoring systems
job是通过一个google自己实现的BCL语言来描述的,用户可以通过update的方式来更新job的描述文件,基于过程状态机:
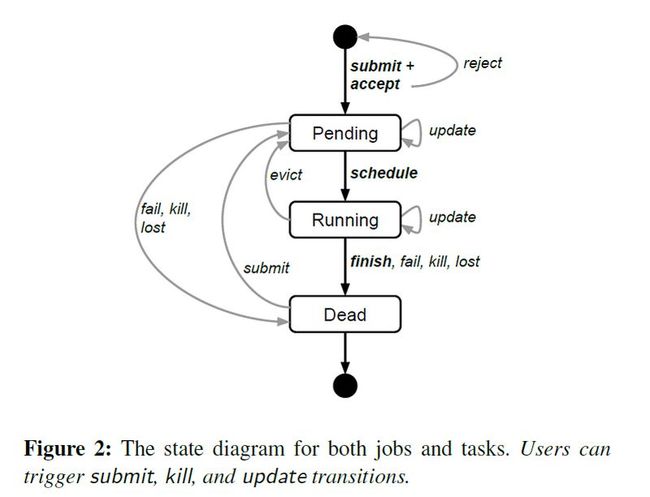
update过程是轻量的,非原子的,而且也是有可能会失败的,Updates are generally done in a rolling fashion, and a limit can be imposed on the number of task disruptions (reschedules or preemptions) an update causes; any changes that would cause more disruptions are skipped
2.4 Allocs
alloc的本质上就是现在的容器,用来运行一个或者多个task,是task的运行环境,是一组资源的描述。只要是alloc里的资源,不管有没有使用,都是已经分配了的(不允许给Batch类型的任务使用)。不过google也提到这个alloc是可以并发使用,也可以是重复利用的,并发的意思是说多个task可以同时跑在一个alloc里,重复利用的意思是说一个task跑完了可以继续分配给另外一个task使用。
并发使用可以举个例子:有两个Job,一个job是web server实例,另一个job是相关的一些task,例如日志收集等等,这两个job的task可以同时跑在一个alloc里,这样日志收集模块可以将web server的日志从local disk传输到分布式文件系统里。
通常一个task会关联一个alloc,一个job会关联一个alloc set
2.5 Priority, quota, and admission control
每个task都会有一个优先级,高优先级的task可以抢占低优先级的task的资源,优先级是一个正整数,borg里将这些优先级分成4类:monitoring, production, batch, and best e ort
如果一个task被抢占了,通常会调度到别的机器上继续运行(同一个cell),we disallow tasks in the production priority band to preempt one another (单指production级别的还是平级的job都不能相互抢占?)
优先级确定是否抢占,quota决定是否可以调度,quota表示所需要的资源,例如cpu,内存,网络带宽,磁盘配额等等
高优先级的task通常会比低优先级的task需要更多的quota,用户申请资源的时候建议申请的比实际的资源占用高一些,以确保task不会因为超发而被kill掉,特别是内存。另外,多申请些资源也可以应对流量突发的情况。
优先级0可以有无穷大的quota,但通常会因为资源不足处于PENDING状态而得不到调度
2.6 Naming and monitoring
仅仅创建和调度task运行是不够的,从服务的角度来说,还需要有一个服务自动发现的机制,调度需要对用户透明,做到用户无感知。borg的Borg name service(BNS)就是为了解决这个问题的。
borg为每个task创建一个BNS名字:cell名 + job名 + task索引,BNS名字和task的hostname + port会被持久化到chubby上,通过DNS解析,用户凭BNS名字就能找到task,另外,Job的task数量和每个task的健康状态也会更新到chubby上,这么做的目的主要是为了服务(这里的服务是指job本身,可能是个web server,也可能是个分布式存储系统等等)的高可用,对用户请求做负载均衡。
每个task都会有一个内置的http服务,暴漏一些task的健康信息和各种性能指标,例如rpc时延等等。borg通过监控某个特定的url来决定task是否正常,如果不正常,比如http返回错误码等,就重启task。
google还有一个叫sigma的系统,用户通过web界面就可以直观的观察到用户自己所有的job,cell状态,甚至是task的健康信息,资源利用率,日志,状态变更历史等等。日志是rotated的,避免打飞磁盘,另外,为了调试方便,即使task运行结束后,log也会保留一段时间。
If a job is not running Borg provides a “why pending?” annotation, together with guidance on how to modify the job’s resource requests to better fit the cell. We publish guidelines for “conforming” resource shapes that are likely to schedule easily.
3. Borg architecture
每个cell,包含一个控制器,borgmaster,同时cell里的每个机器,都运行着一个叫borglet的agent程序,不管是master和agent,都是用c++写的
3.1 Borgmaster
每个master包含两个进程,一个主进程,一个调度进程,主进程处理用户请求,例如创建job,查询job等等,It also manages state machines for all of the objects in the system (machines, tasks, allocs, etc.), communicates with the Borglets, and offers a web UI as a backup to Sigma.
master有5个副本,每个副本维护一份整个cell状态的内存拷贝,并持久化到一个 highly-available, distributed, Paxos-based store 的本地磁盘上。通过paxos选出一个leader,负责处理cell状态变更的所有请求,例如用户提交一个job,停止一个job等。如果leader宕机之后,chubby会选举出另外一个leader来提供服务,整个过程大概需要10s左右,如果cell规模很大,这个时间可能会持续到1分钟。
master会定期checkpoint,snapshot + change log,这样可以将borgmaster恢复到以往任意的一个时间点,fixing it by hand in extremis; building a persistent log of events for future queries; and offline simulations.
TODO: Fauxmaster
3.2 Scheduling
当用户提交一个job时,borgmaster会将job的元数据存储到一个基于paxos的存储系统里,同时将job的task放到pending队列,如上面我们提到的master架构,这个队列会被另外一个调度器进程定期异步地扫描,调度器进程一旦发现某个机器能够满足task的运行条件(例如资源是否足够,是否符合某些特定约束,处理器架构,内核版本等等),就将task调度到改机器上运行(注意:调度器调度的对象是task而不是job)
The scan proceeds from high to low priority, modulated by a round-robin scheme within a priority to ensure fairness across users and avoid head-of-line blocking behind a large job.
调度算法包括两部分:
- feasibility checking: to find machines on which the task could run,
- scoring: which picks one of the feasible machines.
在feasibility checking阶段,调度器检查机器是否满足job的约束条件以及是否有足够的可用资源(包括已经分配给低优先级job的资源,这些资源是可以被抢占的)。这里可用资源的定义是:
- 如果task的优先级是prod的,那么机器的可用资源需要减去task的limit
- 如果task的优先级是non-prod的,那么机器上的可用资源只需要减去task已使用资源
在scoring阶段,对机器进行打分,挑选出最合适的一个机器运行task,打分机制:
- 主要是根据borg内置的各种优化指标给候选调度结果打分,如最小化被抢占的Task数,尽量选择已经下载了相同package的机器,降低硬件故障会影响的Task数,高低优先级混部等
- 也支持用户直接传入的一些偏好设置
打分模型主要有两种:
- E-PVM,通过多个维度计算出一个单一的指标,但是实际操作上,E-PVM算法经常会将task打散到不同的机器上,这样的好处是让机器保留一点资源以应对峰值负载,坏处是资源碎片太多,会导致某些大型的task调度不上来。所以这种算法也叫worst fit
- 和worst fit对立的是best fit,就是尽可能的将task紧凑地调度到一个机器上,好处是减少资源碎片,有利于大型作业的调度,坏处是对Batch型任务不友好,而且无法应对任务的峰值负载
borg目前使用的是介于worst fit和best fit之间的一个变种:hybrid,尽可能的减少闲置资源。
如果打分后选择出来的机器可用资源不足,那么抢占就会发生,低优先级的作业首先会被踢掉,直到有足够的空闲资源为止。被抢占的作业重新回到borgmaster的PENDING队列里等待迁移(如果得不到资源也有饿死的可能)。
由于大部分包都是不会被修改的,所以borg在调度的时候还有一些优化的策略,为了减少每次部署时下载包的时间(平均25s左右),borg在调度时会优先选择那些已经存在这个包的机器。(由于包很少被修改的特性,包是可以被cache的)
3.3 Borglet
borglet是borg运行在单机上的agent程序,borglet的职责如下:
- 启/停任务
- 如果任务失败,负责任务重启
- 任务之间的资源隔离,主要通过修改内核参数来实现,例如cgroup等等
- 日志
- 监控&报告 任务状态
borgmaster会定期轮询所有的borglet,收集处理所有任务的运行状态。master连agent的好处是有利于master控制负载,也有大部分分布式系统是agent去连master的,好处是master的异常处理逻辑相对简单。
前面我们提到master是多副本的,leader负责向agent发送心跳,并根据agent的返回结果更新master的状态,为了提高性能,心跳的内容可能会被压缩,只传输diff。另外,如果一个borglet长期不响应master的心跳,则master会认为该机器已经宕机,并且这机器上的所有task都会被重新调度。如果borglet突然恢复,则master会让该机器kill掉所有的task。
master宕机并不影响borglet以及正在运行的task,另外,borglet进程挂了也是不影响正在运行的task的。
3.4 Scalability
在google里,平均每个borgmaster需要管理数千台机器(前面我们提过,一个中等规模的cell大约是1w台服务器左右),有些cell每分钟提交的任务数就超过1w个,一个繁忙的borgmaster甚至可以用到10-14核,超过50G的内存。那么google如何解决集群规模不断扩展带来的可扩展性问题呢?
早期的borgmaster只有一个简单的,同步的循环过程:
- 接收用户请求
- 调度任务
- 和borglets通讯
为了解决大集群,borgmaster分离出一个调度进程,两个进程并行协作,当然,灾备是有的。
分离出来的调度进程职责是:
- 从elected master接收cell状态 (including both assigned and pending work);
- 更新本地拷贝
- 预调度task(并非真正的调度)
- 通知master确认调度结果(可能成功or失败,例如过期)
这个过程和Omega里的乐观并发控制精神是一致的,borg最近还新增了一个feature,针对不同的workload类型使用不同的调度器
此外,borg针对可扩展性还做了几个优化:
- Score caching: 给机器打分的开销是很大的,而且通常机器的属性静态的,task的属性也不会经常发生变化,所以,这个结果可以cache,除非机器或者task属性发生变化
- Equivalence classes: 同一个job里的task通常都有一致的资源需求和约束条件,borg这将这些具有相同配置的task进行分类,打分的时候只按照分类给机器打分
- Relaxed randomization: 只随机取一部分机器或者纬度来进行打分,以提升效率。
4. Availability
在一个大型的分布式系统里,单点故障是常态,运行在borg中的task,故障的原因既可能是机器宕机,也可能是被抢占调度,下图是borg测试数据里发现的被抢占情况:
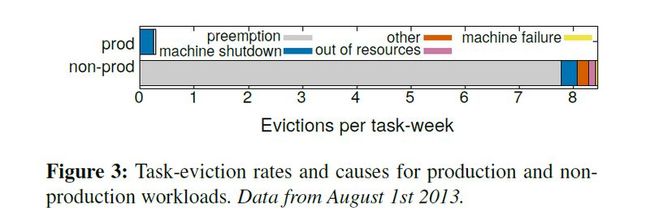
除了应用程序自身需要考虑容灾之外,borg在此方面也做了不少事情,来提高job的可用性:
- automatically reschedules evicted tasks, on a new machine if necessary
- reduces correlated failures by spreading tasks of a job across failure domains such as machines, racks, and power domains
- limits the allowed rate of task disruptions and the number of tasks from a job that can be simultaneously down during maintenance activities such as OS or machine upgrades
- uses declarative desired-state representations and idempotent mutating operations, so that a failed client can harmlessly resubmit any forgotten requests
- rate-limits finding new places for tasks from machines that become unreachable, because it cannot distinguish between large-scale machine failure and a network partition
- avoids repeating task::machine pairings that cause task or machine crashes
- recovers critical intermediate data written to local disk by repeatedly re-running a logsaver task (x2.4), even if the alloc it was attached to is terminated or moved to another machine. Users can set how long the system keeps trying; a few days is common